基于結構和語義的代碼分類以及聚類方法
2023-08-10 03:17:56金巖磊秦冠軍史志成
計算機應用與軟件 2023年7期
金巖磊 秦冠軍 姜 凱 甘 迪 史志成 周 宇*
1(南京南瑞繼保電氣有限公司 江蘇 南京 211106) 2(南京航空航天大學計算機科學與技術學院 江蘇 南京 211106)
0 引 言
如何利用深度學習對代碼進行高質量的特征提取是近幾年研究的一個熱點問題。代碼語言與自然語言有很多相似的特征,都是由單詞組成的,都可以生成AST的樹形結構,二者最大的不同就是代碼元素之間的依賴關系更強,且代碼段的長度遠遠超過自然語句的長度,因此如何提取代碼中的結構信息一直是軟件工程領域研究的熱點和難點。Tai等[1]提出了TreeLSTM模型,該模型的核心思想是通過將LSTM[2]的鏈狀結構拓展為樹狀結構來提取自然語言的結構信息,軟件工程領域內的很多模型將Tree-LSTM作為它們模型的一個子模塊,例如Wei等[3]就將Tree-LSTM作為克隆檢測模型CDLH的子模塊來協助提取代碼的結構信息,Wan等[4]則借助Tree-LSTM。Alon等[5-6]通過提取AST的路徑,利用路徑的中間節點提取代碼的結構信息,路徑的兩端節點提取代碼的語義信息,以此進行方法名生成、變量名預測工作。Ou等[7]、Allamanis等[8]則使用圖網絡對代碼進行特征提取。
本文將基于卷積和循環神經網絡生成高質量的代碼向量完成代碼分類以及聚類任務。該任務的主要目的是根據代碼的結構和語義信息給出對應的代碼標記。自動代碼分類能夠推動軟件工程領域內眾多任務的發展,如程序理解(program comprehension)[9]、概念定位(concept location)[10]、代碼剽竊檢測(code plagiarism detection)[11]、惡意軟件檢測(malware detection)等。代碼分類的標簽可以看作代碼內部含義的一個總結,該標簽能夠協助后續代碼模塊化、分析、重用等工作的進行。當下代碼分類的模型主要以深度學習模型為主,例如:Zhang等[12]設計的基于遞歸以及循環神經網絡的ASTNN模型;Mou等[13]構建的基于自定義樹卷積的TBCNN模型。除了借助AST提取代碼信息之外,Ben-Num等[14]則借助LLVM獲得代碼的中間表示并結合循環神經網絡對代碼進行特征提取。通過中間表示可以生成代碼的程序依賴圖。然而中間表示一個明顯的弊端就是無法獲得變量最原始定義的標識符,這類模型在強化結構信息提取的同時卻丟失了代碼的語義信息。該領域使用最廣泛的數據集就是Mou等[13]整理的104代碼分類數據集,該數據集共有104個類,每個類別下有500條代碼。當下在該數據集取得最高分類精度的就是ASTNN模型,分類的準確率達到98.2%。本文在后面的實驗也將與ASTNN模型進行對比。
與很多學者的研究方法類似,本文也借助AST來提取代碼的特征,通過對Zhang等提出的ASTNN模型以及Mou等提出的TBCNN模型進行結合,將ASTNN中的遞歸神經網絡替換成TBCNN中自定義的速度更快的卷積網絡,構建了一個基于卷積和循環神經網絡的深度學習模型CVRNN,并基于該模型對代碼分類展開研究。該模型在與ASTNN模型分類準確率十分接近的情況下,速度卻是該模型的1.55倍。在我們之前相似代碼搜索任務上[15]該模型也得到了成功的應用,此模型是原模型改進后的版本。
在使用分類訓練好的CVRNN模型對代碼進行編碼,并將得到的代碼向量進行降維打印后發現,代碼功能越相似,對應代碼向量之間的幾何距離就越短。由于K-means的損失函數是樣本與其所屬類的中心之間的距離總和,具體距離的定義是歐氏距離的平方。因此,本文還基于CVRNN生成的代碼向量利用K-means進行了聚類實驗,聚類效果對比TBCNN有明顯的優勢,除了FMI指標與ASTNN持平,其他指標均高于ASTNN。
電力監控系統是整個電力系統運轉的核心部分,為輸電、變電、配電提供基礎性的服務,若其因受到惡意代碼攻擊進而導致系統癱瘓將會造成巨大的經濟損失。隨著計算機技術的飛速進步,電力監控系統面臨惡意代碼攻擊的問題愈發嚴峻。在該領域主要使用可信軟件白名單對惡意代碼進行防御[16],其中白名單維護所有可信軟件的版本號、Hash指紋等相關的參數,通過比對這些參數是否匹配判斷該軟件是否是可信軟件。很明顯該方式是一個完全靜態的方法,一方面,這個白名單很難進行實時維護,另一方面,將導致所有未記錄在名單上的軟件都給攔截掉。本文的工作是解決該問題的一個探索性工作,未來我們將試圖將代碼壓縮成代碼向量,首先使用白名單進行攔截,若在名單內,則可直接運行,否則通過計算代碼向量之間的距離并設置一個閾值來判斷該代碼是否是惡意代碼,使系統更加智能化,使得未在白名單中出現的非惡意代碼也能夠正常運行。矩陣的運算速度極快,經我們測試,即使一個千萬級別的代碼數據庫,也能在毫秒級別完成計算,在保證系統正常運行的同時也保證系統的運行效率。
1 方法介紹
代碼向量是本文進行分類和聚類任務的基石,代碼向量具體的生成過程如圖1所示。首先使用srcml工具生成代碼的AST,然后通過先序遍歷獲得AST節點的展開序列,根據該序列應用Word2vec生成AST節點的詞向量并存入到一個矩陣當中,訓練得到的詞向量能夠將節點之間的某些潛藏關系編碼進詞向量中,如“if”“while”“for”表示程序的控制流關系,編碼后得到的這三個詞向量在向量空間上也是彼此鄰近的。為了解決因AST規模過于龐大而引發的梯度消失問題,本文并沒有簡單地將完整的AST作為模型的輸入,而是將AST切割成由循環以及條件子樹構成的序列。圖2給出了具體的切割樣例,每個代碼塊都與一棵AST相對應,①號代碼塊將被切分成②③④⑤四個部分,其中②號代碼塊主要包含不屬于條件判斷以及循環執行的剩余代碼,例如異常拋出語句沒有包含在任何循環和條件判斷的代碼塊中,因此將其放入到第一個代碼塊中,剩余代碼塊均屬于條件判斷或者循環執行,它們AST對應的根節點一定在{“if”,”while”,“for”}集合當中。由此可以得到一個子樹序列,這個序列可以看作是源代碼的控制流。通過之前得到的詞向量矩陣,可以將這些子樹節點由原先的字符串形式映射成詞向量的形式,然后將該子樹序列輸入到我們設計的CVRNN(Convolutional and Recurrent Neural Network)模型中得到代碼的向量表示。
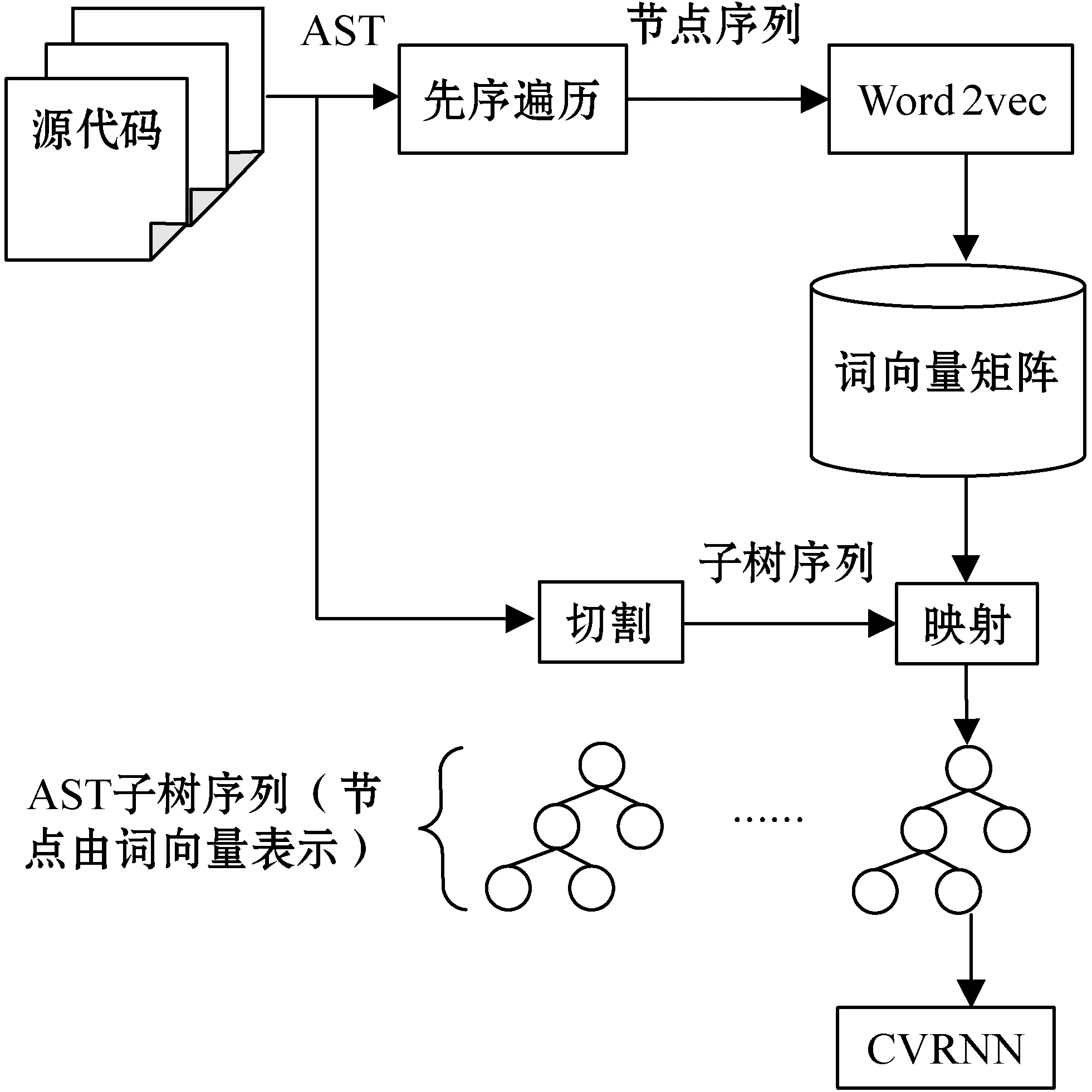
圖1 生成代碼向量流程

圖2 切割樣例
圖3展示了CVRNN模型的執行過程,該模型使用TBCNN對輸入到模型中的AST進行編碼,得到每棵AST的向量表示。圖4展示了TBCNN樹卷積的過程。該模型設置了一個固定深度的滑動窗口,自上而下地遍歷AST中的所有節點,圖4中滑動窗口的深度是2,滑動窗口內的節點將被編碼成一個向量,如圖4左邊①號三角形區域中的節點將被編碼進右邊所標注的①號向量,②號三角形區域同理。具體的編碼公式如式(1)-式(5)所示。
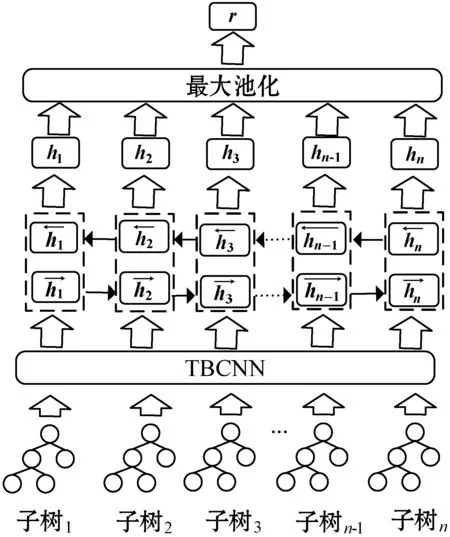
圖3 CVRNN模型
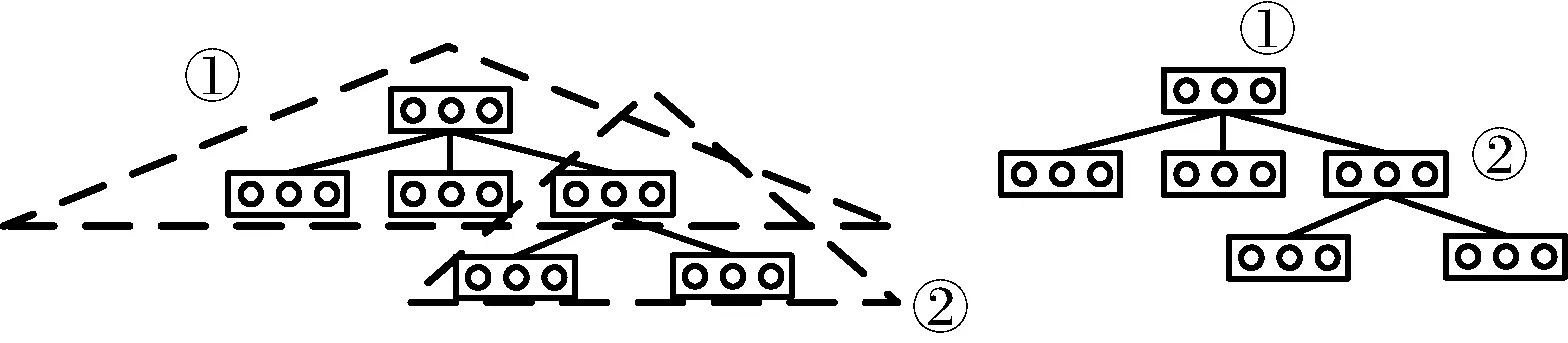
圖4 TBCNN樹卷積
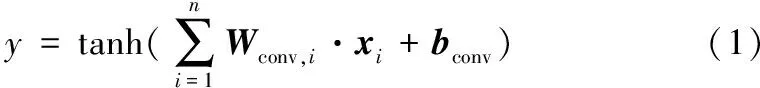
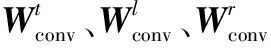
經過樹卷積之后,原先AST中的特征將被提取到新生成的AST中,新AST中每個節點向量包含了一個區域內的節點信息,該AST與原AST有相同的結構,之后再經過動態池化[16]以及一層全連接神經網絡將AST轉化為一個固定長度的代碼向量,因此子樹序列將轉化成一個向量序列[v1,v2,…,vn],在TBCNN之上再疊加一層雙向循環神經網絡(Bidirectional Recurrent Neural Network,BiRNN)以提取代碼塊之間的序列信息。與單向RNN不同的是,BiRNN將從過去和未來兩個時間方向對當前時間步進行編碼,因此會綜合考慮代碼上文和下文的信息。BiRNN內部神經元選取的是LSTM,相對于GRU[17],LSTM多了一個記憶單元,能夠更好地保存過去的時間信息以緩解長期依賴導致的梯度消失問題,最終每個時間步的輸出向量是兩個時間方向隱層單元拼接得到的向量,例如時間步t最終的輸出向量可以使用以下公式得出:
將每個時間步所生成的代碼向量ht都存放到矩陣中,然后使用最大池化提取每個特征維度的最大值作為該維度上的值,將矩陣壓縮成一個代碼向量。最大池化可結合圖5進行理解,其中有陰影的圓圈表示這個維度上的最大值,空白圓圈則表示非最大值,依次選取當前維度的最大值作為代碼向量在該維度的值。

圖5 最大池化
2 實驗驗證
2.1 數據集
代碼分類以及聚類均使用的是Mou等[13]公開的104代碼分類數據集。表1列出了使用葉子節點和不使用葉子節點的情況下,AST節點數目以及深度的最大值和平均值。從統計信息也可以看出原始的AST的結構十分龐大,若不對其進行切割而直接對整棵樹進行提取必然會影響代碼特征提取的效果。
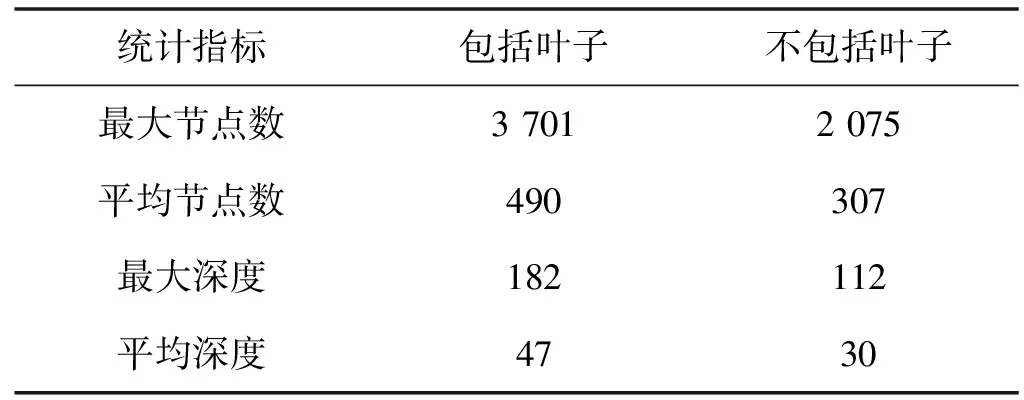
表1 數據集統計信息
2.2 評估指標
2.2.1代碼分類指標
Accuracy準確率,簡稱ACC:
式中:k表示代碼類別的數目,在該任務中,值為104;nTP,i表示第i個類別被正確分類的數目;n表示樣本總量。
2.2.2代碼聚類度量指標
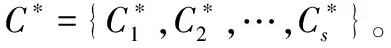
(1) Jaccard系數,簡稱JC:
(2) FM指數,簡稱FMI:
(3) ACC。計算公式與代碼分類準確率公式相同。在計算該指標的時候,聚類標簽要與真實標簽相統一,因此實驗過程中還增加了一個標簽映射的過程,這里映射方法使用的是Kuhn-Munkres算法。
2.3 CVRNN參數設置以及實驗平臺
該模型核心配置參數如表2所示,使用葉子節點和不使用葉子節點在參數配置上唯一的不同就是詞向量的維度。因為不使用葉子節點所需要訓練的詞匯表只有60,而使用葉子節點詞匯表擴充至6 156。為了降低頻詞對模型的影響,具體的實驗過程中只選取了詞頻大于等于5的單詞納入詞匯表。在分類模型的訓練過程中,以交叉熵作為訓練的損失函數并選取Adam作為優化器。仿照Mou等[13]的工作,該模型同樣沒有設置正則化項來降低模型過擬合的風險。深度學習框架使用的是TensorFlow 1.14,操作系統是Ubuntu 16.04,GPU型號是RTX2060,CPU型號是AMD Ryzen 7 2700。
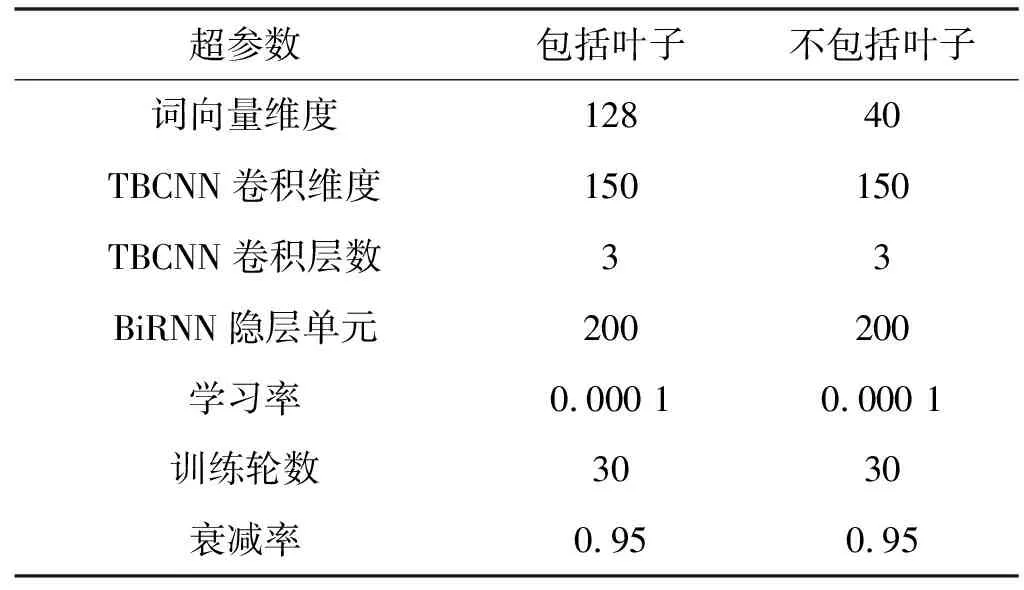
表2 模型參數
2.4 任 務
2.4.1代碼分類
該實驗將104數據集按3∶1∶1劃分訓練集、驗證集和測試集,對比模型選取的是Ben-Num等[14]的inst2vec模型、Zhang等[12]的ASTNN模型,具體的實驗結果如表3所示。因為inst2vec模型并沒有使用AST,所以表3直接展示了原論文中的實驗結果。ASTNN原文中使用的AST生成工具是javalang,為了對比的公平性,表3中展示的結果是使用srcml作為AST生成工具重新訓練得到的實驗結果。兩個模型均訓練了30輪,表3和表5分別展示了實驗結果和訓練時間。可以看出,ASTNN與CVRNN分類的準確率很接近,而CVRNN的運行速度大約是其的1.55倍,此外還進行了另一個與ASTNN的對比實驗,不使用AST的葉子節點,僅使用srcml符號表中定義的節點對代碼進行分類,表4和表5分別展示了實驗結果和訓練時間。CVRNN在速度和準確率上都要優于ASTNN模型。

表3 代碼分類測試集準確率

表4 不使用葉子節點測試集代碼分類的準確率

表5 30輪的訓練時間
使用已訓練的CVRNN對測試集中的代碼進行編碼生成代碼向量(對應圖3中的r向量)并使用TSNE進行降維打印,打印結果如圖6所示,相同灰度的表示屬于同一個類。可以看出,屬于同種類別的代碼形成一個簇,功能相近的代碼經過CVRNN編碼后得到的代碼向量之間的幾何距離也是彼此臨近的。

圖6 降維后測試集代碼向量
2.4.2代碼聚類
上面的代碼分類任務中,盡管測試集中的代碼與訓練集樣本不重疊,然而兩個數據集代碼的類別相同,在實際的代碼分類場景下,測試集代碼的類別大部分與訓練集不同,為了探究CVRNN模型是否能夠對訓練過程中未出現過類別的代碼進行正確分類,我們借助K-means設計了代碼聚類實驗,并根據代碼的真實標簽對聚類效果進行度量。
聚類模型整體架構如圖7所示。首先將104個類別的代碼數據庫分為兩部分,其中84個類別作為訓練集,剩下的20個類別作為測試集。首先使用84個類別的代碼數據庫對CVRNN模型進行訓練,然后應用訓練好的CVRNN對20個類別構成的代碼庫進行編碼得到的代碼向量再使用TSNE進行降維,將降維后的代碼向量輸入到K-means中進行聚類,由此可以得到每個代碼的預測標記。計算JC和FMI度量指標不需要預測標記和真實標記之間實現統一,因此可以直接計算出這兩個度量指標的值。由于準確率ACC要統一真實標簽和預測標簽,例如得到的預測進行聚類,聚類的數目設為20。標簽是(0,0,1,2,2,2,2,2),而真實標簽是(1,1,2,0,0,0,2,0),就要將預測標簽0映射為1,標簽1映射為2,標簽2映射為0,再計算準確率。這里使用的是Kuhn-Munkres算法完成標簽的映射。具體的做法是將預測標簽與真實標簽進行組合得到一個矩陣,這里測試集共有20類,因此可以得到一個20×20的矩陣,矩陣中的每個值表示該標簽組合情況下數據的重合數量,例如下面得到的標簽混合矩陣:

圖7 聚類整體架構
第1行第2列數字為380,表示真實標簽為1與預測標簽為2的樣本重合數為380,然后基于該矩陣計算最低代價的映射。將預測標簽與真實標簽實現統一之后,便可以計算準確率的值。對比模型選取的依然是TBCNN和ASTNN,因為K-means聚類度量指標可能會出現4到5百分點的波動,因此最終取10次實驗結果的平均值來避免偶然性,結果如表6所示。可以看出CVRNN在3個模型的對比過程中各項度量指標均占有優勢。圖8給出了CVRNN模型聚類后的區域劃分,同一灰度的點表示對應的代碼向量屬于同一個類。可以看出同一個區域下的點的灰度大致相同。
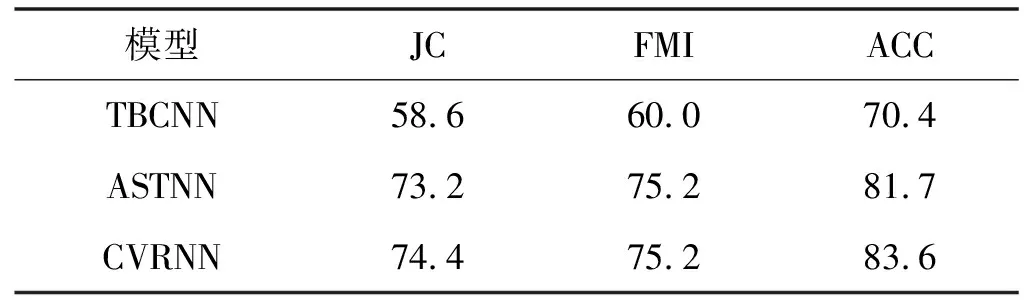
表6 聚類結果(%)

圖8 CVRNN 聚類效果
3 結 語
本文通過卷積以及循環神經網絡對代碼的結構以及語義信息進行提取來獲得高質量的代碼向量并基于此對代碼分類以及聚類展開研究,中間還應用Word2vec預訓練AST節點的詞向量來增強其初始語義。在代碼分類以及聚類任務上對比當下最前沿的幾個模型占有優勢。實驗選取的數據集是該領域內公開的標準數據集,代碼也在GitHub上開源,方便后續工作的復現參考。因為該研究涉及的實驗所采用的數據均來源于Mou等[13]提供的104代碼分類數據集,然而該數據集經過精細化的人工預處理,數據集的噪聲很少,而現實環境中很難有如此良好的數據集。因此在后面的工作中,我們還將對包含眾多噪音的數據集展開研究,提高模型的魯棒性。此外,該模型只在C/C++語言上進行了測試,未來還將在其他語言上進行嘗試。當下不少的研究還制定了一系列啟發式規則將AST由原來的樹形結構轉化成具有更強表達能力的圖的結構,未來我們也將在這一方向進行深入的探索,根據AST的樹形結構,進一步挖掘代碼元素之間的依賴關系,將原來的樹形結構拓展為圖形結構,并設計構建圖神經網絡對代碼的特征進行更深入的提取,將更多的代碼特征編碼進生成的代碼向量中。
未來將對電力監控領域內的源代碼以及常見的惡意代碼進行分析,使得模型更適合該領域內代碼的特征,生成能夠提取該領域內代碼特征的代碼向量,在保證電力系統穩定運行的前提下,實現對損害電力系統的惡意代碼進行有效攔截。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
