基于Transformer和重要詞識(shí)別的句子融合方法
2023-08-10 07:03:52譚紅葉李飛艷
計(jì)算機(jī)應(yīng)用與軟件 2023年7期
譚紅葉 李飛艷
1(山西大學(xué)計(jì)算機(jī)與信息技術(shù)學(xué)院 山西 太原 030006)2(山西大學(xué)計(jì)算智能與中文信息處理教育部重點(diǎn)實(shí)驗(yàn)室 山西 太原 030006)
0 引 言
文本生成是指給定文本或非文本輸入,輸出流暢、連貫且符合要求的文本。句子融合是一種典型的文本到文本的生成任務(wù),旨在為給定的一組相關(guān)句子(或一個(gè)比較長(zhǎng)的句子)生成一個(gè)較短的概括性句子,且保留其中的重要信息。句子融合與文本摘要有類(lèi)似之處,但也有區(qū)別。主要區(qū)別包括:(1) 輸入不同,句子融合的輸入為一個(gè)或多個(gè)句子,而文本摘要的輸入為單文檔或多文檔。一般來(lái)說(shuō)后者輸入句子數(shù)多于前者,因此后者壓縮率大于前者。(2) 目標(biāo)不同,句子融合側(cè)重于去除相關(guān)句子的冗余信息,生成簡(jiǎn)短的句子,而文本摘要旨在獲得概括篇章內(nèi)容的多個(gè)句子。(3) 句子融合可以作為文本摘要的一個(gè)中間技術(shù)。如:在抽取式摘要中,句子融合可以將其結(jié)果作為輸入,進(jìn)一步融合后,得到更為靈活緊湊的摘要。
句子融合的具體示例如圖1所示。可以看出,融合句不僅剔除了冗余和不重要的信息,而且生成了原句中未出現(xiàn)過(guò)的詞。如:示例1中的融合句剔除了原句中“中新網(wǎng)7月21日電”“妻子王洪濤反映”等不重要的短語(yǔ),同時(shí)生成了“網(wǎng)曝”“綏化”和“檢方”等新詞。從示例2可以看出融合句結(jié)構(gòu)與原句也有不同。

原句1:“中新網(wǎng)7月21日電 據(jù)安縣人民政府網(wǎng)站消息,2015年7月21日上午,新浪微博出現(xiàn)一則慶安縣公安局經(jīng)刑偵大隊(duì)副大隊(duì)長(zhǎng)姚永軍的妻子王洪濤反映其利用職務(wù)之便,貪污受賄、實(shí)施家暴的視頻。目前已被停職,慶安縣人民檢察院已介入調(diào)查。”標(biāo)準(zhǔn)融合句:“網(wǎng)曝綏化慶安刑偵大隊(duì)副大隊(duì)長(zhǎng)利用職務(wù)之便,貪污受賄、實(shí)施家暴,目前已被停職,檢方介入調(diào)查。”原句2:“人民網(wǎng):北京11月29日電 今天,記者從中國(guó)鐵路總公司獲悉,自11月30日起,中國(guó)鐵路客戶(hù)服務(wù)中心12306網(wǎng)站支付寶賬戶(hù)支付服務(wù)功能上線(xiàn)試運(yùn)行,旅客網(wǎng)購(gòu)火車(chē)票新增一種支付方式。”標(biāo)準(zhǔn)融合句:“人民網(wǎng):12306網(wǎng)站明日起新增支付寶支付服務(wù)功能。”
目前,由于句子融合相關(guān)的數(shù)據(jù)集規(guī)模小,句子融合方法主要為基于無(wú)監(jiān)督的方法。如,文獻(xiàn)[1]中使用了詞圖方法,從原句復(fù)制重要信息片段到融合句。Clarke等[2]提出了一種基于句法樹(shù)的方法,通過(guò)使用整數(shù)線(xiàn)性規(guī)劃將句子壓縮任務(wù)視為優(yōu)化問(wèn)題。但由于上述方法未考慮上下文信息和句子結(jié)構(gòu),生成的融合句缺乏重要信息或有語(yǔ)法錯(cuò)誤。
有監(jiān)督的文本生成的主流方法是基于神經(jīng)網(wǎng)絡(luò)的編碼器-解碼器框架。在編碼器-解碼器框架基礎(chǔ)上,文獻(xiàn)[3]提出Structure-infused復(fù)制機(jī)制,將原句的重要詞和關(guān)系復(fù)制到摘要句,以確保生成的結(jié)果包含原句重要信息。文獻(xiàn)[4]提出一種新穎的Focus-attention機(jī)制對(duì)句子進(jìn)行編碼,并設(shè)計(jì)了一個(gè)獨(dú)立的顯性選擇網(wǎng)絡(luò)管理信息流,來(lái)區(qū)分并強(qiáng)調(diào)原句重要信息。然而,這些方法還不能令人滿(mǎn)意,主要表現(xiàn)在生成的文本不包含重要信息,或者用詞偏離原句語(yǔ)義。
為了解決上述問(wèn)題,本文采用Transformer架構(gòu),利用多頭注意力機(jī)制學(xué)習(xí)文本的長(zhǎng)距離依賴(lài)關(guān)系,并結(jié)合重要詞識(shí)別模塊進(jìn)行句子融合。該方法主要包括兩個(gè)模塊:重要詞識(shí)別模塊與句子融合模塊。其中,重要詞識(shí)別模塊利用BiLSTM-CRF序列標(biāo)注模型識(shí)別原句重要詞;句子融合模塊將重要詞與原句輸入Transformer框架,利用BERT進(jìn)行語(yǔ)義表示,并在全連接層引入基于原句和詞表獲得的向量作為先驗(yàn)知識(shí)生成融合句。該模型通過(guò)重要詞識(shí)別模塊加強(qiáng)了模型對(duì)重要詞的理解與關(guān)注,并且通過(guò)引入先驗(yàn)知識(shí),確保融合過(guò)程中包含更多原句中的詞,使得結(jié)果與原句語(yǔ)義一致。此外,本文還基于NLPCC2017會(huì)議上的單文檔摘要評(píng)測(cè)數(shù)據(jù)集,利用相似度計(jì)算方法獲得了一定規(guī)模的漢語(yǔ)句子融合數(shù)據(jù)集(大約包含35 000多個(gè)樣例)來(lái)訓(xùn)練模型。相關(guān)實(shí)驗(yàn)表明,本文所提模型性能明顯優(yōu)于基線(xiàn)系統(tǒng)。
1 相關(guān)工作
關(guān)于句子融合。由于可獲得的句子融合數(shù)據(jù)集規(guī)模較小,因此大多數(shù)研究都使用無(wú)監(jiān)督的方法。如:文獻(xiàn)[7]提出了簡(jiǎn)單的詞圖方法,從不同的輸入語(yǔ)句中復(fù)制片段并將它們連接起來(lái)形成最終句子。在此基礎(chǔ)上,研究者嘗試使用多種策略(如關(guān)鍵短語(yǔ)重新排名)改善詞圖方法[5-7]。為了改善融合后句子的語(yǔ)法合理性及新詞包含率,文獻(xiàn)[11]通過(guò)無(wú)監(jiān)督手段引入語(yǔ)義一致的句子對(duì)來(lái)訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型,具體思想為:首先利用詞圖方法產(chǎn)生粗粒度壓縮文本B,然后用較短的同義詞替換壓縮文本中的詞產(chǎn)生新句子C,最后利用所獲得的語(yǔ)義一致的句子對(duì)(B,C)訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型。
關(guān)于文本生成。現(xiàn)有的主流文本生成方法主要采用基于序列到序列(Seq2seq)的基本框架。在此基礎(chǔ)上,一些研究者通過(guò)使用注意力機(jī)制來(lái)選擇重要詞,如:文獻(xiàn)[15]在基于Attention的Seq2seq生成模型中引入VAE結(jié)構(gòu),將句子固定結(jié)構(gòu)特征作為潛在向量并采用VAE作為生成框架來(lái)解決推理生成問(wèn)題。也有研究者引入復(fù)制機(jī)制來(lái)獲取句子重要信息,如:Song等[3]采用結(jié)構(gòu)注入復(fù)制機(jī)制將原句重要詞和依賴(lài)關(guān)系復(fù)制到目標(biāo)句子。隨著B(niǎo)ERT的出現(xiàn),研究者嘗試在Seq2seq框架上引入BERT獲得了更好的系統(tǒng)性能。如:Liu等[10]在目標(biāo)數(shù)據(jù)集上調(diào)整預(yù)訓(xùn)練的BERT獲得文檔的輸入表示,并與Transformer解碼器相結(jié)合完成生成任務(wù),獲得了比之前模型更好的性能。然而,基于Transformer的方法仍存在一些局限,如:生成的融合句未包括原句重要信息,或者偏離原句內(nèi)容。
關(guān)于相關(guān)數(shù)據(jù)集。目前關(guān)于句子融合的大規(guī)模數(shù)據(jù)集較少,且多為英文數(shù)據(jù)集。較早的句子融合數(shù)據(jù)集來(lái)自于Newsblaster摘要系統(tǒng)的新聞報(bào)道并由人標(biāo)注產(chǎn)生,共包含3 000個(gè)樣例[11]。文獻(xiàn)[12]從Thomson-Reuters新聞專(zhuān)線(xiàn)中使用基于Bigram計(jì)數(shù)重疊的簡(jiǎn)單貪婪方法來(lái)對(duì)齊句子,構(gòu)建了融合句-摘要句對(duì)形式數(shù)據(jù)集(約300個(gè)樣例)。文獻(xiàn)[13]為了探索有監(jiān)督的句子融合方法,通過(guò)制定一些規(guī)則從摘要任務(wù)數(shù)據(jù)集構(gòu)造了1 858個(gè)樣例。James等[2]在大規(guī)模新聞?wù)Z料Gigaword上,通過(guò)提取每篇文章的第一句和標(biāo)題并經(jīng)過(guò)數(shù)據(jù)清理,來(lái)獲得句子和標(biāo)題對(duì)作為句子融合的訓(xùn)練語(yǔ)料。
2 方 法
2.1 任務(wù)定義
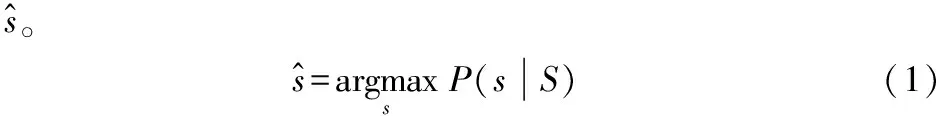
本文提出了一種基于Transformer和重要詞識(shí)別的句子融合方法。該方法的模型總體架構(gòu)如圖2所示,主要包括句子重要詞識(shí)別和句子融合兩個(gè)模塊。其中,重要詞識(shí)別模塊利用BiLSTM-CRF序列標(biāo)注模型識(shí)別原句重要詞;句子融合模塊將重要詞與原句作為T(mén)ransformer框架的輸入,利用BERT進(jìn)行語(yǔ)義表示,并在全連接層引入基于原句和詞表獲得的向量作為先驗(yàn)知識(shí)生成融合句。
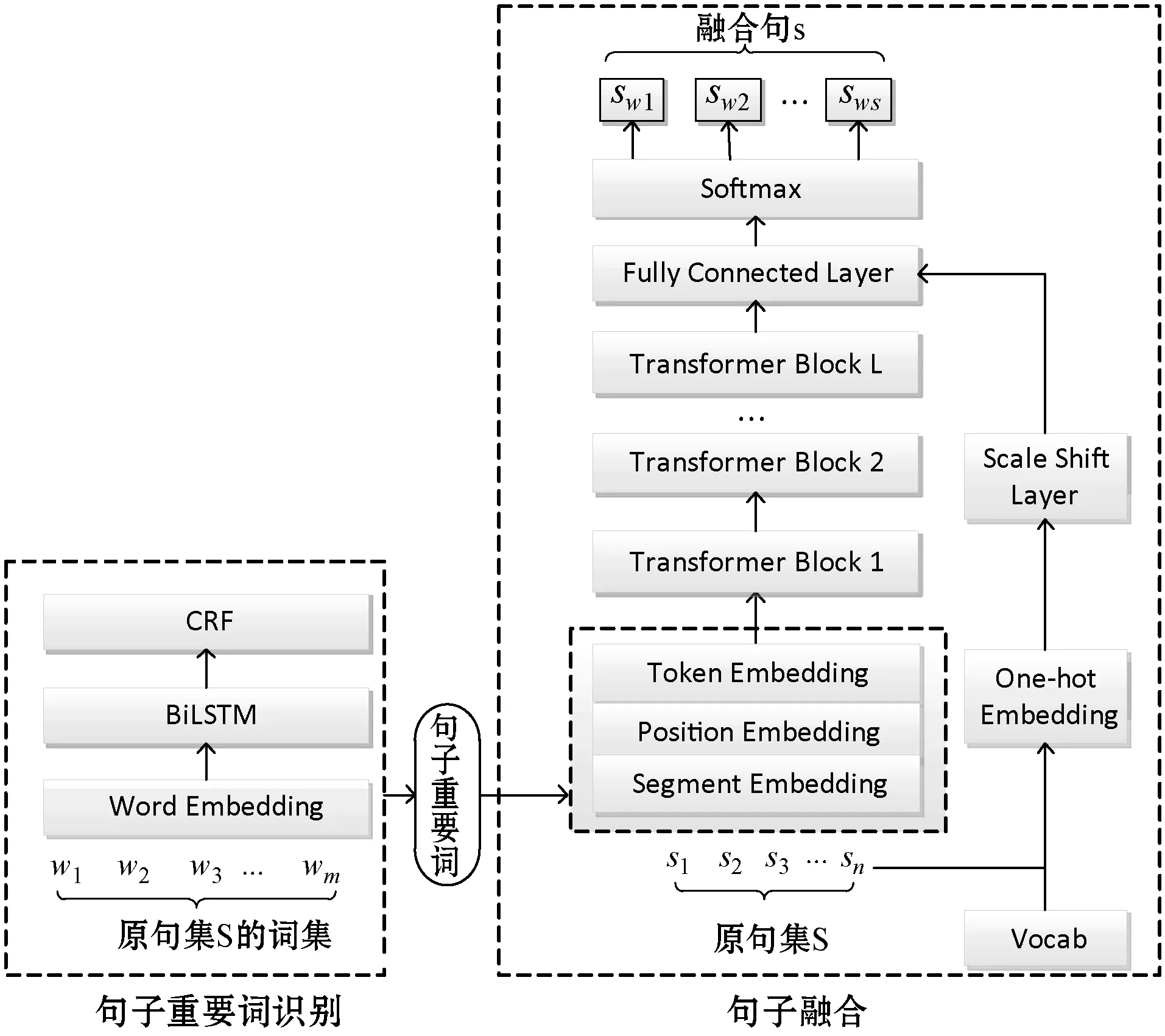
圖2 本文的句子融合模型框架
2.2 句子重要詞識(shí)別
為了使模型更好地捕捉原句重要信息,本文引入句子重要詞的相關(guān)概念,并基于BiLSTM-CRF模型進(jìn)行句子重要詞的識(shí)別。
句子重要詞是反映句子重要語(yǔ)義信息的詞,具體識(shí)別時(shí)以同時(shí)出現(xiàn)在原句與融合句中的實(shí)詞(主要指:名詞、動(dòng)詞和形容詞)為判別依據(jù)。
本文將句子重要詞識(shí)別任務(wù)看作序列標(biāo)注問(wèn)題,并通過(guò)式(2)來(lái)刻畫(huà)。
式中:W={w1,w2,…,wm}為輸入句子的詞序列,T*={t1,t2,…,tm}為輸出的最優(yōu)標(biāo)注序列。其中的標(biāo)記為1、0。1代表該詞為重要詞,反之則為0。
具體采用BiLSTM-CRF模型來(lái)識(shí)別,具體如圖2左部的模塊。該模型包括表示層、BiLSTM層和CRF層。其中,表示層將句子中的每個(gè)詞表示為詞向量;BiLSTM層負(fù)責(zé)將詞向量作為輸入對(duì)句子建模,同時(shí)更好地捕捉長(zhǎng)距離依賴(lài)關(guān)系;CRF層為標(biāo)簽預(yù)測(cè)添加一些約束來(lái)保證預(yù)測(cè)標(biāo)簽的準(zhǔn)確性,并輸出句子中每個(gè)詞的標(biāo)簽得分以獲得最優(yōu)標(biāo)簽序列的概率。
2.3 句子融合
句子融合模塊采用Transformer框架(Dong等[14])實(shí)現(xiàn)編碼與解碼。該模塊首先對(duì)輸入句子集利用BERT獲得字的上下文語(yǔ)義表示H0={xw1,xw2,…,xwn}(n為輸入字序列的長(zhǎng)度)。具體操作時(shí),在輸入序列的首部添加[CLS]標(biāo)記,在每個(gè)句子末尾添加[SEP]標(biāo)記。然后,將BERT語(yǔ)義表示(Token Embedding)與位置嵌入(Position Embedding)、段嵌入(Segment Embedding)拼接形成輸入的向量表示。其中,段嵌入用來(lái)標(biāo)識(shí)原句和融合句,0對(duì)應(yīng)原句,1對(duì)應(yīng)融合句。
需要注意的是,本文使用的掩碼矩陣允許原句的字從前后兩個(gè)方向計(jì)算注意力值,而融合句的字只能對(duì)([MASK])及之前的字,以及原句的字計(jì)算注意力值。
式中:s和t為訓(xùn)練參數(shù)。
2.4 損失函數(shù)
對(duì)于重要詞識(shí)別任務(wù)和句子融合任務(wù),使用交叉熵函數(shù)作為句子融合模型訓(xùn)練的損失函數(shù),其計(jì)算式為:
式中:y表示真實(shí)結(jié)果;y′表示模型預(yù)測(cè)結(jié)果。
3 實(shí)驗(yàn)與結(jié)果分析
3.1 數(shù)據(jù)集
如本文第1節(jié)所述,目前已公開(kāi)的句子融合數(shù)據(jù)集主要為英文數(shù)據(jù)集,但規(guī)模都較小。對(duì)于中文來(lái)說(shuō),幾乎沒(méi)有公開(kāi)的句子融合數(shù)據(jù)集。
本文基于NLPCC2017會(huì)議的中文單文檔摘要評(píng)測(cè)任務(wù)數(shù)據(jù)集構(gòu)建了句子融合數(shù)據(jù)集。該評(píng)測(cè)數(shù)據(jù)集共包含52 000個(gè)篇章-摘要形式的樣例,且摘要中包含一些原文沒(méi)有出現(xiàn)的詞。其中的篇章為今日頭條中文新聞文本,涉及的主題有體育、食品、娛樂(lè)、政治、科技、金融等。在該數(shù)據(jù)集的基礎(chǔ)上,我們按照如下方法構(gòu)建了句子融合數(shù)據(jù)集和句子重要詞識(shí)別的數(shù)據(jù)集。
句子融合數(shù)據(jù)集。對(duì)于每個(gè)篇章-摘要樣例,首先按標(biāo)點(diǎn)符號(hào)將摘要句切分為短句,然后用兩個(gè)句子中的共現(xiàn)詞數(shù)與句子長(zhǎng)度之和的比值來(lái)度量其相似度,其計(jì)算式為:
式中:WSi表示第i個(gè)句子的詞集合;wk表示詞;|Si|表示第i個(gè)句子的長(zhǎng)度。
然后,選擇原文最相似的句子構(gòu)成該摘要句的待融合句子集,從而形成原句-融合句(摘要句)形式的樣例。通過(guò)去重、剔除詞重疊率小于0.45的樣例,最終得到35 488條數(shù)據(jù)。其中,訓(xùn)練集31 488條,驗(yàn)證集2 000條,測(cè)試集2 000條。
本文從新詞率、原詞率和壓縮率等方面對(duì)句子融合測(cè)試集進(jìn)行了分析。其中,新詞率指融合句中新詞(未出現(xiàn)在原句的詞)在原句的占比;原詞率指融合句中的原詞(出現(xiàn)在原句的詞)在原句的占比;壓縮率指融合句長(zhǎng)度與原句長(zhǎng)度之比。具體結(jié)果如表1所示,從原詞率、新詞率、壓縮率可以看出融合過(guò)程中,部分原詞被保留,大部分冗余信息被刪除,同時(shí)包含未在原句出現(xiàn)的詞,表明句子融合任務(wù)不是簡(jiǎn)單地去除冗余信息,還需要生成一些新的詞語(yǔ)。

表1 句子融合測(cè)試集相關(guān)分析
句子重要詞識(shí)別數(shù)據(jù)集。在句子融合數(shù)據(jù)集上,通過(guò)對(duì)比原句與融合句中重疊的實(shí)詞自動(dòng)標(biāo)注獲得重要詞數(shù)據(jù)集。具體過(guò)程為:如果原句中的實(shí)詞出現(xiàn)在融合句中,則標(biāo)注為1,否則為0。訓(xùn)練集、驗(yàn)證集和測(cè)試集的比例與句子融合數(shù)據(jù)集相同。
3.2 實(shí)驗(yàn)設(shè)置與評(píng)價(jià)指標(biāo)
對(duì)于句子重要詞識(shí)別,模型參數(shù)設(shè)置為:詞向量維度為300,隱藏層數(shù)為3,隱藏層單元個(gè)數(shù)為200,詞的最大長(zhǎng)度為4,批次大小為32,學(xué)習(xí)率為0.015,訓(xùn)練1 000輪,優(yōu)化函數(shù)為Adam。
對(duì)于句子融合,為了節(jié)省計(jì)算量,對(duì)詞表進(jìn)行精簡(jiǎn),詞表規(guī)模|V|=13 584。模型其他參數(shù)設(shè)置為:字向量維度為768,隱藏狀態(tài)大小為768,具有12個(gè)注意力頭。根據(jù)對(duì)數(shù)據(jù)集的分析,句子長(zhǎng)度都比較短,故將文本輸入的最大長(zhǎng)設(shè)為256,輸出的最大長(zhǎng)度設(shè)為110。批處理大小為16,學(xué)習(xí)率設(shè)為1e-5,訓(xùn)練100輪,優(yōu)化函數(shù)為Adam。
重要詞識(shí)別評(píng)價(jià)指標(biāo)。利用精確率、召回率和F1值來(lái)評(píng)價(jià)重要詞識(shí)別情況。
句子融合評(píng)價(jià)指標(biāo)。對(duì)模型生成的融合句,使用ROUGE-L、ROUGE-2、ROUGE-1和BLEU指標(biāo)進(jìn)行自動(dòng)評(píng)估。ROUGRE-L是通過(guò)計(jì)算標(biāo)準(zhǔn)融合句和生成的融合句之間的最大公共子序列的統(tǒng)計(jì)量,來(lái)評(píng)價(jià)生成的融合句所含的信息量。BLEU通過(guò)統(tǒng)計(jì)生成的融合句與標(biāo)準(zhǔn)的融合句之間的匹配片段的個(gè)數(shù),來(lái)評(píng)價(jià)生成的融合句的合理性與流暢性。
3.3 句子融合的基線(xiàn)系統(tǒng)
由于句子融合是很多生成式摘要系統(tǒng)的重要子任務(wù),所以本文采用性能比較好的摘要生成系統(tǒng)作為對(duì)比基線(xiàn)系統(tǒng)。
(1) DRGD模型[9]。該模型面向摘要生成基于深度GRU遞歸模型學(xué)習(xí)目標(biāo)摘要中隱含的結(jié)構(gòu)信息,同時(shí)采用VAE作為生成框架來(lái)解決推理生成問(wèn)題,以提高摘要質(zhì)量。
(2) Struct+2Way+Relation模型[3]。該模型在基于BiLSTM框架的摘要系統(tǒng)中引入Structure-Infused復(fù)制機(jī)制,將重要詞和句法依賴(lài)關(guān)系從原句復(fù)制到摘要句,提升了系統(tǒng)性能。
(3) UNILM模型[14]。該模型是融合了自然語(yǔ)言理解和自然語(yǔ)言生成能力的Transformer統(tǒng)一框架,其核心是通過(guò)特殊的Attention Mask來(lái)實(shí)現(xiàn)不同的語(yǔ)言模型。
本文沒(méi)有專(zhuān)門(mén)與文獻(xiàn)[10]中所提基于Transformer架構(gòu)的模型進(jìn)行對(duì)比是因?yàn)楸疚膶?shí)驗(yàn)是在基于Transformer框架的UNILM上進(jìn)行改進(jìn),已包含該框架的對(duì)比結(jié)果。
根據(jù)相應(yīng)文獻(xiàn)來(lái)源找到對(duì)應(yīng)模型代碼,將實(shí)驗(yàn)數(shù)據(jù)換為本文實(shí)驗(yàn)所用數(shù)據(jù),實(shí)驗(yàn)其他設(shè)置與原論文保持一致。
本文系統(tǒng)基于UNILM模型結(jié)合任務(wù)特點(diǎn)進(jìn)行了改進(jìn),實(shí)現(xiàn)了較好的實(shí)驗(yàn)結(jié)果。
3.4 結(jié)果分析
3.4.1句子融合結(jié)果分析
句子融合的具體實(shí)驗(yàn)結(jié)果如表2所示。
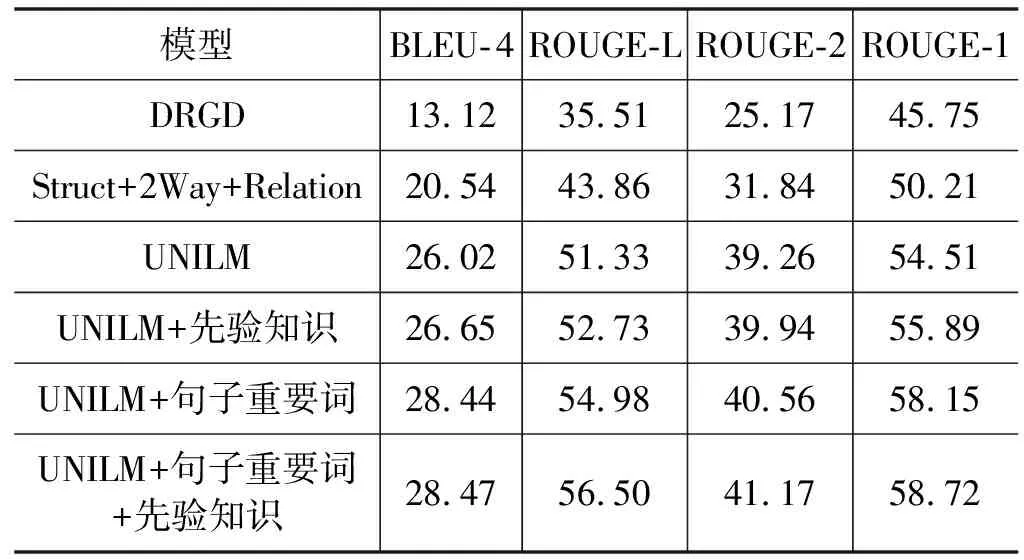
表2 句子融合結(jié)果(%)
從表2可以看出,本文所提方法同其他方法相比獲得了最好性能。當(dāng)“UNILM”模型中同時(shí)加入先驗(yàn)知識(shí)以及句子重要詞時(shí),BLEU-4值提升了約2%,ROUGE-L值提升了約5%,ROUGE-2、ROUGE-1也有明顯提升,而且加入句子重要詞提升效果比加入先驗(yàn)知識(shí)更明顯,表明如果模型可以正確識(shí)別句子的重要信息,就可以得到更準(zhǔn)確、流暢的結(jié)果。當(dāng)模型中僅加入先驗(yàn)知識(shí)時(shí),BLEU-4、ROUGE-L、ROUGE-2和ROUGE-1也有改進(jìn),表明先驗(yàn)知識(shí)的引入在一定程度上可以提升句子融合的質(zhì)量。此外,還發(fā)現(xiàn)“UNILM”模型比“DRGD”模型、“Struct+2Way+Relation”模型的效果要好,表明“UNILM”模型擁有更強(qiáng)大的學(xué)習(xí)能力。
本文從實(shí)驗(yàn)結(jié)果中隨機(jī)抽取了100條數(shù)據(jù)進(jìn)行分析,部分?jǐn)?shù)據(jù)如圖3所示。

原句1:“中新網(wǎng)7月21日電據(jù)安縣人民政府網(wǎng)站消息,2015年7月21日上午,新浪微博出現(xiàn)一則慶安縣公安局經(jīng)刑偵大隊(duì)副大隊(duì)長(zhǎng)姚永軍的妻子王洪濤反映其利用職務(wù)之便,貪污受賄、實(shí)施家暴的視頻。目前已被停職,慶安縣人民檢察院已介入調(diào)查。”標(biāo)準(zhǔn)融合句:“網(wǎng)曝綏化慶安刑偵大隊(duì)副大隊(duì)長(zhǎng)利用職務(wù)之便,貪污受賄、實(shí)施家暴,目前已被停職,檢方介入調(diào)查。”UNILM:“安慶慶安縣公安局經(jīng)刑偵大隊(duì)副大隊(duì)長(zhǎng)姚永軍妻子王洪濤被舉報(bào),其妻子王洪濤已被刑拘,檢方已介入調(diào)查。”UNILM+先驗(yàn)知識(shí):“慶安縣公安局經(jīng)刑偵大隊(duì)長(zhǎng)妻子王洪濤貪污受賄、實(shí)施家暴,目前,慶安縣檢察院已介入調(diào)查。”UNILM+先驗(yàn)知識(shí)+句子重要詞:“慶安刑偵大隊(duì)副大隊(duì)長(zhǎng)利用職務(wù)之便,貪污受賄、實(shí)施家暴,目前已被介入調(diào)查。”原句2:“人民網(wǎng):北京11月29日電(記者孝金波)今天,記者從中國(guó)鐵路總公司獲悉,自11月30日起,中國(guó)鐵路客戶(hù)服務(wù)中心12306網(wǎng)站支付寶賬戶(hù)支付服務(wù)功能上線(xiàn)試運(yùn)行,旅客網(wǎng)購(gòu)火車(chē)票新增一種支付方式。”標(biāo)準(zhǔn)融合句:“人民網(wǎng):12306網(wǎng)站明日起新增支付寶支付服務(wù)功能。”UNILM:“鐵路客戶(hù)服務(wù)中心12306網(wǎng)站支付寶賬戶(hù)支付服務(wù)功能上線(xiàn)試運(yùn)行,旅客網(wǎng)購(gòu)火車(chē)票新增一種支付方式。”UNILM+先驗(yàn)知識(shí):“自11月30日起,中國(guó)鐵路客戶(hù)服務(wù)中心12306網(wǎng)站支付寶賬戶(hù)支付功能上線(xiàn)試運(yùn)行,新增一種支付方式。”UNILM+先驗(yàn)知識(shí)+句子重要詞:“12306網(wǎng)站新增支付寶支付服務(wù)功能。”原句3:“中新網(wǎng)4月27日電:據(jù)外媒報(bào)道,《星期日泰晤士報(bào)》27日發(fā)布年度富豪榜,出生在烏克蘭的布拉瓦特尼克成為英國(guó)首富。伊麗莎白女王的財(cái)富增長(zhǎng)1 000萬(wàn)英鎊至3.4億英鎊,但卻首次跌出了該國(guó)的富豪前300強(qiáng)。”標(biāo)準(zhǔn)融合句:“英國(guó)公布年度富豪榜:烏克蘭裔商人131億英鎊居首,女王3.4億英鎊,首次跌出前300。”UNILM:“英國(guó)發(fā)布年度富豪榜,出生在烏克蘭的布拉瓦特尼克成為英國(guó)首富,但首次跌出該國(guó)富豪前300強(qiáng)。”UNILM+先驗(yàn)知識(shí):“英國(guó)首富布拉瓦特尼克成英國(guó)首富,伊麗莎白女王財(cái)富增長(zhǎng)1000萬(wàn)英鎊至3.4億英鎊,但首次跌出該國(guó)富豪前300強(qiáng)。”UNILM+先驗(yàn)知識(shí)+句子重要詞:“英國(guó)富豪榜:烏克蘭女王成英國(guó)首富,女王財(cái)富3.4億英鎊,但首次跌出前300強(qiáng)。”
從結(jié)果的整體上看,加入先驗(yàn)知識(shí)和句子重要詞識(shí)別兩個(gè)模塊后,在一定程度上改善了融合句子的準(zhǔn)確性和流暢性。例如,在示例1中,“UNILM+先驗(yàn)知識(shí)”模型輸出句子中有更多的詞來(lái)源于原句;“UNILM+句子重要詞+先驗(yàn)知識(shí)”模型比“UNILM+先驗(yàn)知識(shí)”模型更準(zhǔn)確地識(shí)別到了原句重要信息,輸出的句子更接近于標(biāo)準(zhǔn)融合句。
然而,模型的輸出還存一些局限。如示例3中,由于句子中出現(xiàn)多個(gè)實(shí)體詞:“出生在烏克蘭的布拉瓦特尼克”和“伊麗莎白女王”,本文模型輸出了錯(cuò)誤的實(shí)體匹配結(jié)構(gòu),導(dǎo)致融合的句子質(zhì)量變差。所以,對(duì)于出現(xiàn)多個(gè)同類(lèi)實(shí)體的情況,還需要進(jìn)一步進(jìn)行研究和改進(jìn)。
3.4.2句子重要詞識(shí)別
原句重要詞識(shí)別實(shí)驗(yàn)結(jié)果如表3所示。
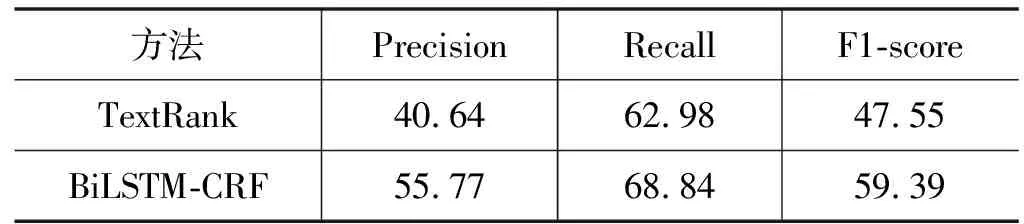
表3 句子重要詞識(shí)別結(jié)果(%)
實(shí)驗(yàn)結(jié)果顯示BiLSTM-CRF模型識(shí)別的精確度更高。本文在采用TextRank算法時(shí),在句子中過(guò)濾掉停用詞,只保留指定詞性的詞,迭代得到每個(gè)詞的權(quán)重,根據(jù)原句子和融合句子的原詞率(見(jiàn)表1),本文選取前N(N=m×2/5,其中m為句子的長(zhǎng)度)個(gè)權(quán)重較大的句子重要詞。在此過(guò)程中,并未考慮句子結(jié)構(gòu)信息,導(dǎo)致標(biāo)注了部分不重要的詞。對(duì)于BiLSTM-CRF模型,其考慮了句法信息,以及融合句與原句子的交互信息。從結(jié)果數(shù)據(jù)看,該模型結(jié)果雖有提升,但還不理想。所以,提升句子重要詞的預(yù)測(cè)能力將是下一步研究重點(diǎn)。
4 結(jié) 語(yǔ)
為了解決句子融合后存在重要信息缺失、語(yǔ)義偏離原句等問(wèn)題,本文提出了一種基于Transformer和重要詞識(shí)別的句子融合方法。該方法主要分為兩個(gè)模塊:句子重要詞識(shí)別模塊負(fù)責(zé)識(shí)別原句的重要信息;句子融合模塊基于原句重要信息和先驗(yàn)知識(shí)生成融合句。實(shí)驗(yàn)結(jié)果表明,模型取得了較好效果。
然而模型還存在一些局限,如:未能準(zhǔn)確獲取句子中的實(shí)體匹配關(guān)系導(dǎo)致融合結(jié)果不夠好;詞語(yǔ)特征構(gòu)建不充分引起句子重要詞識(shí)別還不夠理想。未來(lái),我們將加強(qiáng)句子重要信息的識(shí)別與句子語(yǔ)義關(guān)系分析,進(jìn)一步提升句子融合效果。
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
