基于BERT和LDA模型的酒店評論文本挖掘
2023-08-10 03:18:04綦方中田宇陽
計算機應用與軟件 2023年7期
綦方中 田宇陽
(浙江工業大學管理學院 浙江 杭州 310023)
0 引 言
近年來,隨著我國經濟的飛速發展,人們外出旅游、出差等活動的需求大大提高,這也給時下酒店行業的崛起創造了良好的條件。旅客可線上預訂住宿和餐飲等服務,在訂單完成后根據自身體驗進行在線點評,而在線評論文本包含了用戶對酒店位置、硬件設施、房間質量、服務態度等多個維度的信息,能夠反映顧客對入住體驗的直觀感受。酒店管理者需要將在線評論文本轉化為核心洞察力,從中全面探知用戶的關注和偏好,發現隱藏在其中的問題并解決,以保持強大的市場競爭力。因此,對酒店評論文本進行情感分類和主題挖掘是十分重要的。
情感分類的目的是通過分析某條評論文本的具體內容,將其劃分為正向情感類或負向情感類。常見的情感分類方法有兩種,一種是基于情感詞典的方法,如何構建高質量的情感詞典是此方法的關鍵,例如,趙妍妍等[1]使用文本統計算法構建了一個詞匯量達到十萬的情感詞典。周劍峰等[2]根據匹配模型在語料中獲取情感詞,結合統計方法和PMI-MB算法構建了微博情感詞典。Yu等[3]將現有情感詞典中的詞語作為種子詞,用PMI算法計算出每個詞語的情感極性從而判斷出文本的情感傾向。另一種情感分類方法則是有監督的機器學習方法,該方法通常是將帶有情感極性標注的文本作為訓練集并基于機器學習算法來構造分類器模型,例如,Pang等[4]最早將機器學習算法應用于情感分類中,分別使用樸素貝葉斯、最大熵模型和支持向量機來構建分類器。李杰等[5]則將深度學習方法應用到了情感分類任務中,該方法借助卷積神經網絡強大的特征學習能力成功克服了特征抽取中的困難。
文本主題挖掘通常要用到主題概率模型,目前常見的主題概率模型有PLSA(Probabilistic Latent Semantic Analysis)和LDA,且LDA模型實質上就是在PLSA的基礎上加入了Dirichlet先驗分布[6],張敏[7]以某電商平臺上的購買用戶評論數據為基礎,構建了LDA主題模型,實現了對文本主題的提取和隱藏信息的挖掘。王少鵬等[8]將TF-IDF算法與LDA模型相結合來計算文本的相似度,進而將高校論壇數據進行了文本聚類。
在酒店評論領域,基于中文語料的相關研究尚處于起步階段,研究方法種類眾多且主要以定量研究為主,陳柯宇等[9]利用Word2Vec工具擴充公共情感詞典從而得到了酒店領域的情感詞典。李勝宇等[10]結合酒店評論的句式特征和語法特點,解決了此前情感詞匹配出現錯誤的問題。熊偉等[11]利用文本挖掘技術的批量處理功能結合時間序列分析法預測了某商務酒店未來的發展趨勢。吳維芳等[12]從評論文本的角度建立了消費者滿意度與酒店特征之間的關系,發現了用戶滿意度的影響因素。高保俊等[13]引入訂滿率取代評論數量,研究了酒店的用戶推薦比率和位置評分等因素對酒店訂滿率的影響。朱曉晴等[14]分析了酒店在線評論與酒店服務質量之間的關系并總結了影響服務質量的因素。整體而言,基于中文語料的酒店評論文本的研究成果正在逐年上升,但適用性較高的模型還未形成。已有研究主要是考慮如何構建酒店評論領域的情感詞典或是通過傳統的詞向量模型來生成詞向量并輸入到機器學習模型中進行訓練,但構建情感詞典的成本較高,傳統的詞向量模型又不能很好地捕捉文本的雙語義特征且其計算效率低下。另外,酒店評論文本的數量龐大,存在總結詞和評價詞眾多、轉折詞和關鍵詞出現頻率高、句式口語化嚴重、網絡流行詞和特殊符號泛濫等特點,僅僅通過情感分析的結果顯然無法徹底地挖掘出蘊含在文本內部的深層語義信息。
針對以上問題,本文提出一種適用于酒店評論的BERT-LDA文本挖掘方法。研究思路如下:利用中文維基百科語料庫訓練BERT模型來獲取文本特征向量,將事先經過情感極性標注的酒店評論文本劃分為訓練集和測試集結合深度學習算法訓練情感極性分類器,通過網絡爬蟲獲取“攜程旅行”平臺上的評論語料,經預處理后傳入情感極性分類器得到評論語料的情感二分類結果,依據分類結果分別對正向評論和負向評論進行LDA主題模型的構建以獲取特征主題詞及對應的概率分布,最后系統化地梳理和概括主題聚類的結果,對酒店管理者提出可供參考的建議。
1 相關理論分析
1.1 BERT
BERT是谷歌于2018年提出的Transformer模型中衍生出來的預訓練語言模型,目前Transformer模型在自然語言處理領域已經擁有了廣泛的應用。作為一種Seq2Seq模型,Transformer由編碼器(Encoder)和解碼器(Decoder)兩大部分組成,BERT模型便是Transformer的編碼器部分。在此前的研究中,解決序列問題的方法通常是基于循環神經網絡(RNN)實現的,但RNN反復循環迭代的訓練方式使得其計算速度較慢,Transformer卻能通過并行訓練的方式大幅度提升計算的效率。
BERT的結構如圖1所示。模型的每個基本層包含兩個子層,其中,一個是采用多頭注意力機制(Multi-Head Attention)的自注意力(Self-Attention)層;另一個則是全連接的前饋神經網絡層(Feed Forward),每個子層的輸出都會經過一個Add&Norm層。此外,模型還引入一個位置編碼(Position Encoding)的概念來解決傳入到自注意力層中的特征缺乏位置信息的問題。
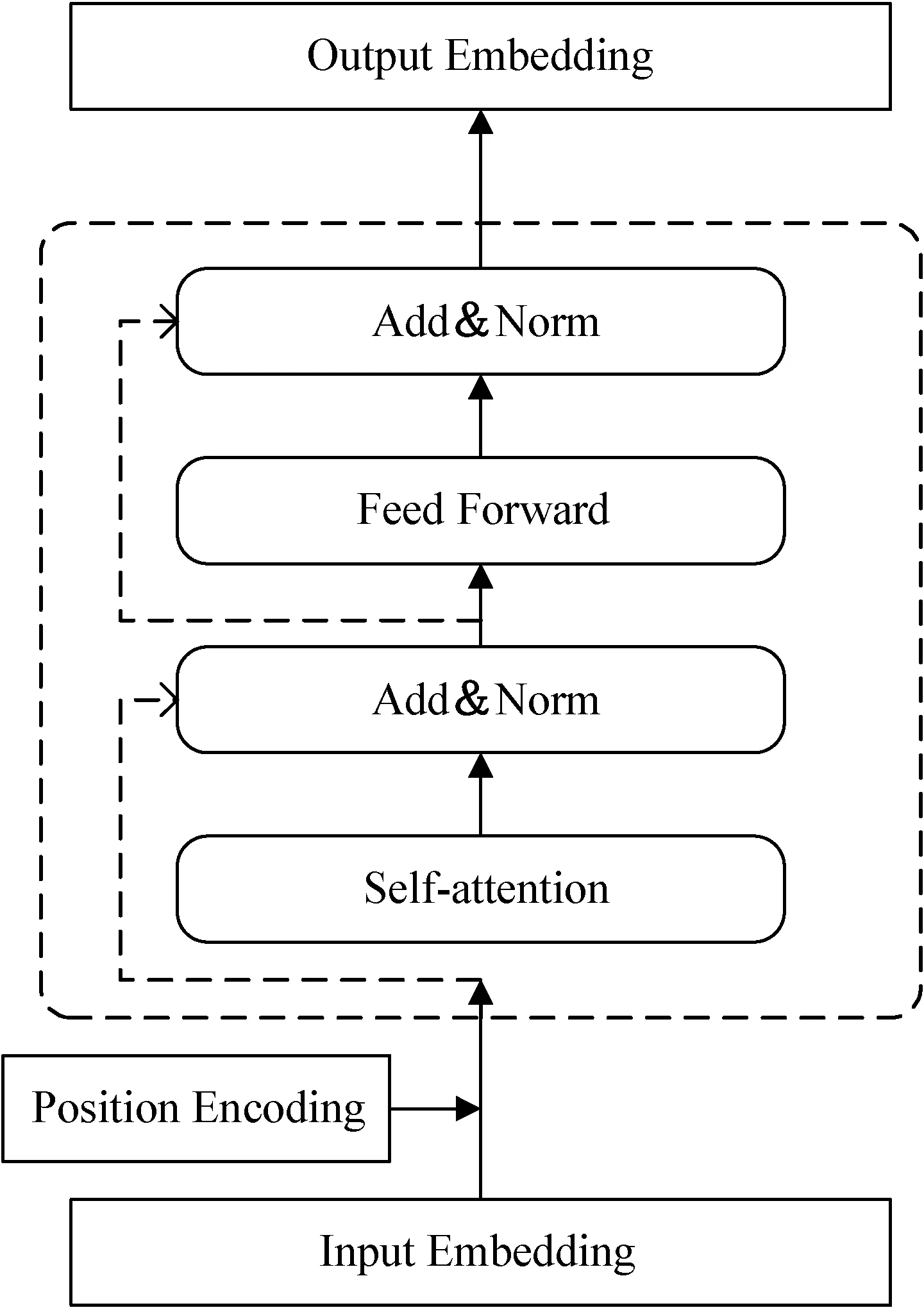
圖1 BERT模型結構
Transformer模型沒有類似于RNN的循環迭代操作,因此需通過位置編碼來給模型提供每個字的位置信息,從而模型才擁有了識別語言序列中順序關系的能力。位置編碼使用了不同頻率的正弦函數和余弦函數來替代每一處位置信息,文獻[15]給出了計算公式。
PE(pos,2i)=sin(pos/10 0002i/dmodel)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(1)
式中:pos指句子中字的位置,i是字向量的維度,dmodel是嵌入的維度,公式所得到的位置編碼的維度和dmodel相同,故二者可以相加。分別用正弦和余弦函數做處理可以產生不同的周期性變化,模型由此可以獲取位置之間的關系和語言的時序特性。
自注意力機制(self-attention)是BERT的核心部分,為了清晰地解釋其原理,這里引入相關公式加以描述。S是由若干句子組成的集合,它的維度為batch_size×sequence_length,其中batch_size指句子的數量,sequence_length指句子長度,在字向量表中獲取相應的嵌入Embedding(S)再加上位置編碼特征Position Encoding得到最終的嵌入特征Sembedding,它的維度為batch_size×sequence_length×embedding_dimension,其中embedding_dimension表示字向量的維度即每個字的特征表達,具體公式表達為:
Sembedding=Embedding(S)+PositionEncoding
(2)
接下來對每一個特征輸入做線性映射,分配三個權重矩陣WQ、WK和WV,它們的維度都是embedding_dimension×embedding_dimension,線性映射以后,便可得到每個輸入的Query向量(Q)、Key向量(K)和Value向量(V),并且三個向量的維度與線性映射前的維度一致。線性映射的計算方法為:
Q=SembeddingWQ
K=SembeddingWK
V=SembeddingWV
(3)
多頭注意力機制便是將Q、K和V在embedding_dimension這個維度平均分割成h份,h是人為設定的一個超參數即為頭(head)的數量。對于每個注意力頭,計算公式為:
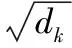
Add&Norm層(殘差連接和層歸一化)的存在是為了解決深度學習中的退化問題。在得到Attention(Q、K、V)之后,接下來每經過一個模塊的運算,都要將運算前后的結果相加,這便是Add(殘差連接)的操作,這可使得在訓練過程中后層的梯度跨層反傳到初始層從而防止梯度消失現象的發生。Norm(層歸一化)可以將神經網絡中的隱藏層歸一化為標準正態分布,以起到加快訓練速度的作用。
此外,BERT模型主要以MLM(Masked Language Model)和NSP(Next Sentence Prediction)兩種方式來進行訓練。其中MLM是隨機遮蓋或替換一句話中的某些字或詞,然后讓模型去預測和還原被遮蓋或被替換的部分。NSP則是隨機地給定兩句話,模型通過訓練來判斷這兩句話是否有上下文關系。在實際訓練中,通常會將MLM和NSP相結合,以這種方式訓練出的模型能夠更加全面地刻畫出語言序列中的語義信息。
經由BERT輸出的文本嵌入特征能夠適用于各種實際的任務,相較于傳統的詞嵌入技術(如Word2Vec或Glove),BERT充分考慮了句子中每一個字對上下文中其他字的影響以及在不同語境下同一種表達的不同含義。自BERT模型公布以來,就以其卓越的表現深受開發者們的喜愛,作為自然語言處理領域近幾年來研究成果的集大成者,BERT也為詞嵌入表示的研究提供了很好的思路[16]。
1.2 LDA模型
LDA模型是Blei等[6]于2003年提出的一種主題模型。作為一種無監督的機器學習方法,將給定的文檔集傳入到模型中,便可得到文檔集中每一篇文檔主題的概率分布,以該主題的概率分布為依據可以進行文本分類和主題聚類等任務。自提出以來,LDA已經有了諸多的算法改進及變形算法,并且在文本挖掘、信息檢索和情感分析等領域得到了廣泛應用。LDA是一種描述了文檔、主題和詞匯之間關系的3層貝葉斯模型,模型結構如圖2所示。
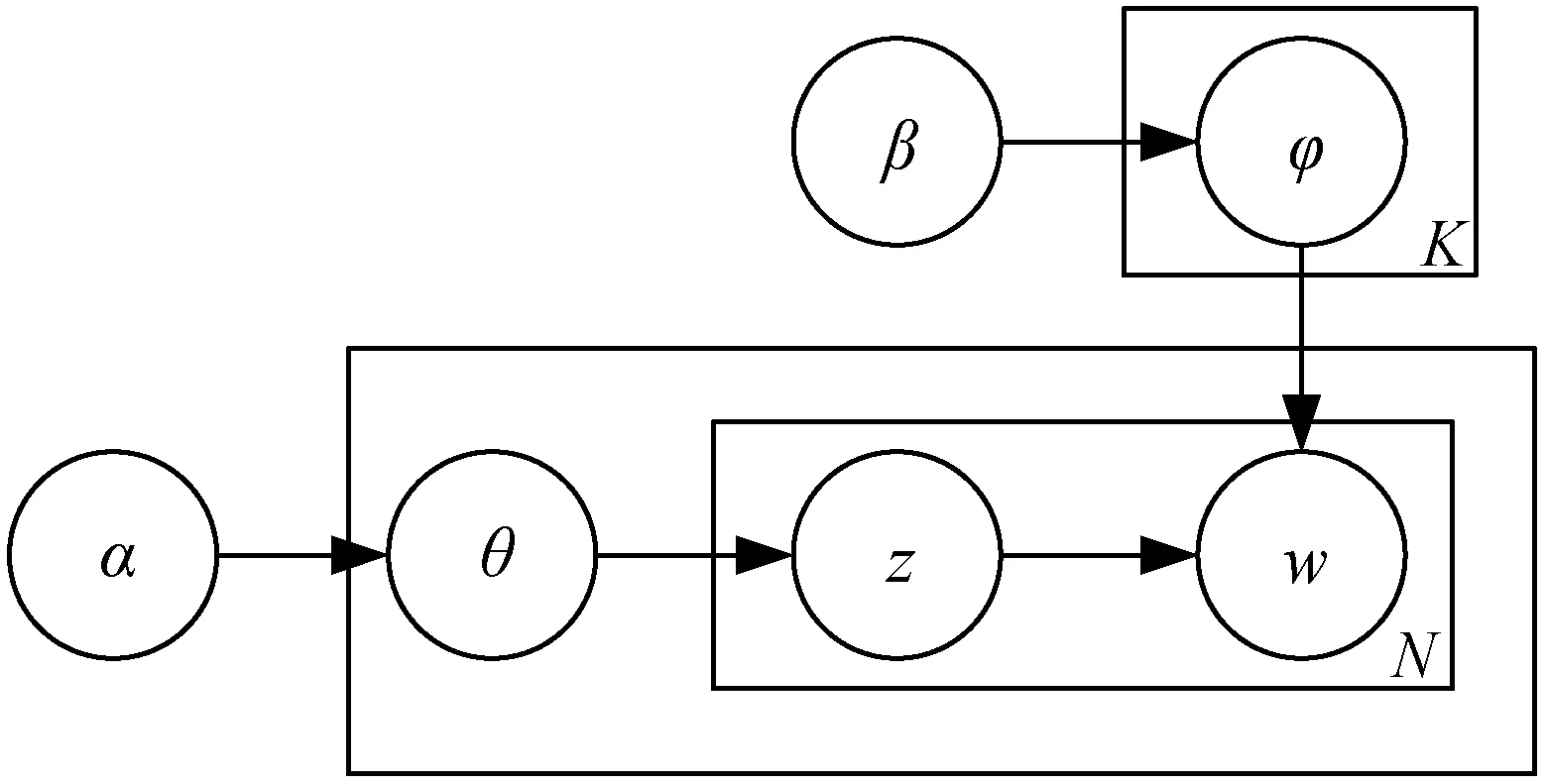
圖2 LDA模型結構
圖2中,每個符號的含義見表1,變量間的箭頭表示條件依賴性(Conditional Dependency),方框表示重復抽樣,方框右下角的字母指代重復抽樣的次數。
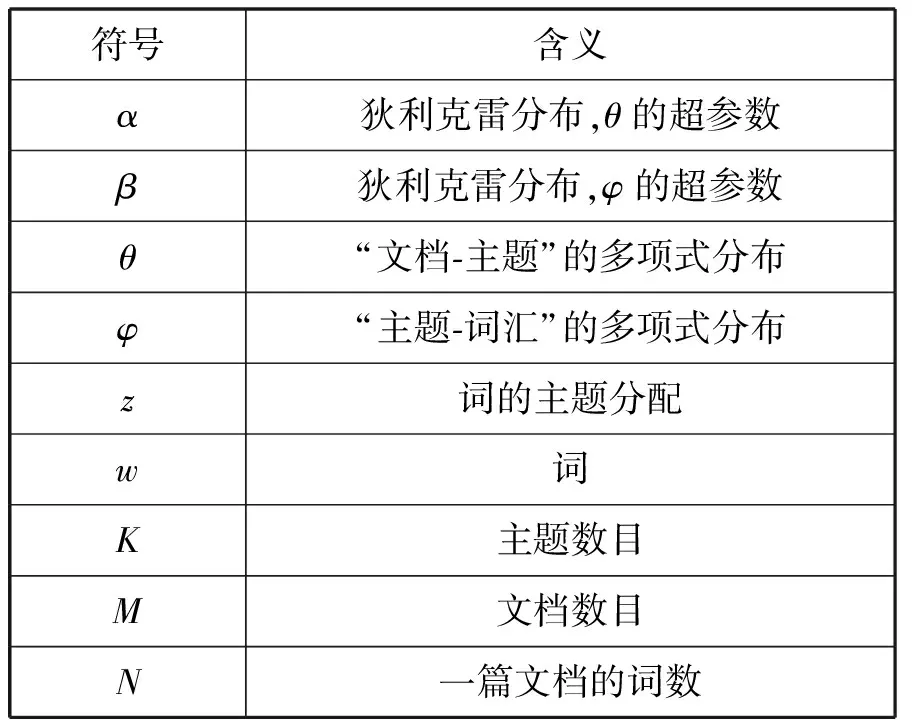
表1 LDA符號含義對照表
在LDA模型中,一篇文檔的生成步驟如下:
Step1以先驗概率P(dm)選定一篇文檔dm;
Step2取樣生成文檔dm的主題分布θm,其中θm服從超參數為α狄利克雷分布,即θm~Dir(α);
Step3從主題分布θm中取樣生成文檔dm的第n個詞的主題zm,n,其中zm,n服從θm的多項式分布,即zm,n~Mult(θm);
Step4取樣生成主題zm,n的詞語分布φzm,n,其中φzm,n~Dir(β);
Step5從詞語分布φzm,n中生成詞語wm,n,且wm,n~Mult(φzm,n);
Step6重復Step2-Step5共N次,最終生成一篇總詞數為N的文檔dm。
2 實驗及其結果分析
2.1 BERT模型的預訓練
為了驗證BERT-LDA方法的有效性,本文進行了大量實驗加以驗證,本文詳細地闡述了實驗的步驟和模型相關參數的設置,整個實驗過程如圖3所示。
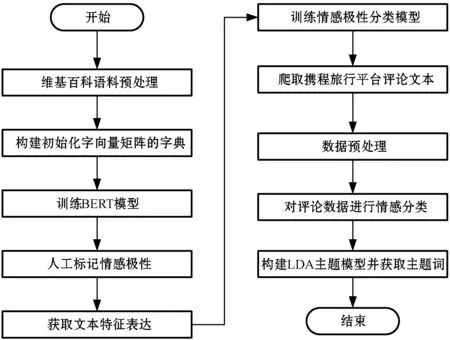
圖3 BERT-LDA方法流程
BERT預訓練模型所用的訓練數據是中文維基百科語料。在語料的預處理階段,利用中文維基百科語料制作了一個字典用來初始化BERT模型的字向量矩陣,除了語料中的中文字以外,字典中還新定義了一些特殊字符以適應BERT模型的訓練模式,最終制作出來的字典共計包含了20 193個字。
谷歌官方給出的BERT基準模型總參數量達到了1.1億個,考慮到訓練這個參數規模的模型需要十分充裕的計算資源并且在實際運用中這個參數的性能存在過剩的情況,最終本文預訓練的BERT模型參數設置見表2。
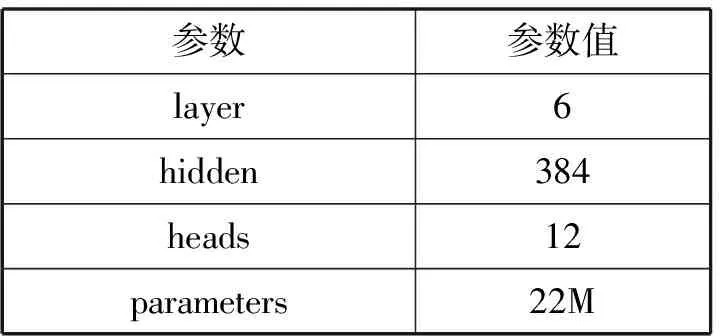
表2 BERT模型參數
2.2 情感分類
在完成BERT模型的訓練后,在BERT的輸出端添加了全連接網絡并使用sigmoid函數激活。所使用的訓練語料是已經過人工標記處理的酒店評論文本,其中正面評論和負面評論各7 000條,分別標記為1代表情感極性為正和0代表情感極性為負,其中10 000條評論作為訓練集,剩余4 000條作為測試集。考慮到在實際生活中,正面評論的數量往往要遠高于負面評論的數量,對于這類分布不均衡的樣本,使用準確率(Accuracy)作為分類器性能的衡量指標并不合理,故在訓練過程中將AUC(Area Under The Curve Of ROC)作為分類器性能的衡量標準。設置初始學習率為1e-6,在每個epoch訓練結束后記下當前epoch的AUC,再與上一個epoch的AUC進行比較,如果AUC未獲得提升,則降低當前學習率的20%,若連續15個epoch的AUC都沒有提升,則提前終止訓練。
在相同的酒店評論數據集上將BERT模型和其他兩種混合模型的性能優劣做了比較,即分別用不同分類器對測試集進行了情感分類實驗,實驗結果見表3。對比表中BERT和其他兩種常用模型,可以看出BERT在各項模型性能衡量指標中皆有明顯優勢,這說明BERT模型在該酒店評論數據集上的情感分類效果較好。
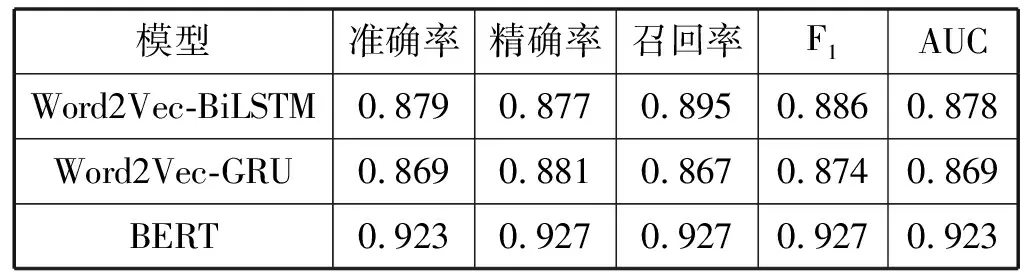
表3 實驗對比結果
2.3 LDA主題建模
接下來通過Python網絡爬蟲技術在“攜程旅行”平臺上獲取了561家酒店從2018年7月至2020年6月期間產生的共計16萬余條評論文本信息。酒店評論文本存在語言多樣化、規范性較差和無意義評論數量較多等缺點,所以對獲取到的評論文本進行數據清洗操作就顯得尤為重要。首先去掉數據集中所有非評論文本的部分,僅保留評論文本并刪除重復評論和少于8個漢字的評論,隨后利用Jieba分詞工具和哈工大停用詞表對文本進行分詞處理并去除停用詞及特殊符號。得到處理完畢的規范評論文本后,將其傳入到情感分類模型中,便得到所有文本情感極性的分類結果。整個特征提取與情感分類過程如圖4所示。
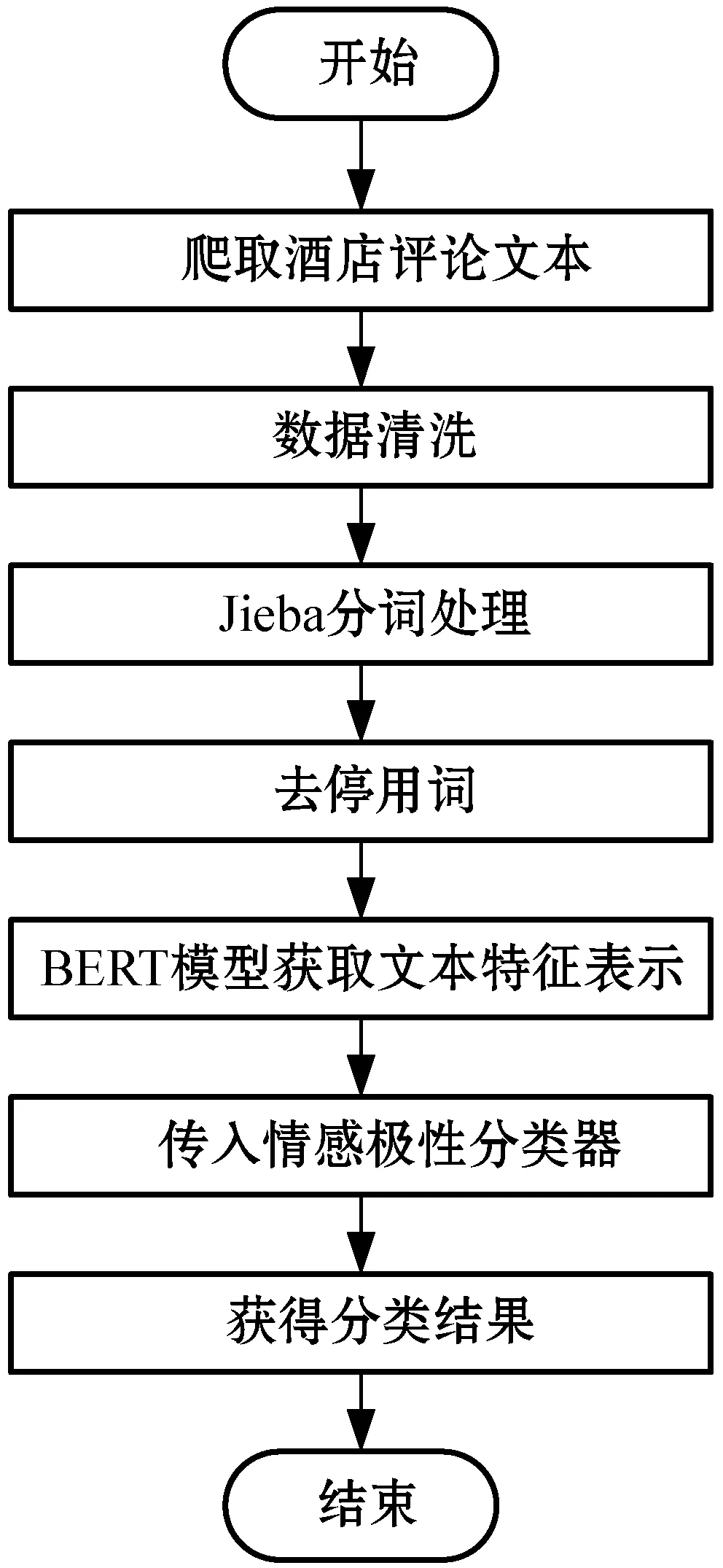
圖4 特征提取和情感分類
接下來分別對情感分類結果為正和負的評論文本進行LDA文本聚類。文獻中對于LDA模型的參數α和β的常用設置為α=50/K,β=0.01,其中K是文本的主題數量,其取值是根據困惑度指標評定法來獲得,困惑度計算公式為:
式中:M為文本總數,Nm為第m條文本的詞數,P(wn|zk)表示詞語wn在主題zk下的概率,P(zk|dm)表示文本dm在主題zk下的概率。隨著K的增大,模型的困惑度會逐漸降低。但K過大會導致不同主題間的內容模糊化,因此在實際應用中,一般將困惑度下降速度趨于“平緩點”處的主題數作為參數K的取值。經過多次實驗,最終本文的LDA模型中,參數α=10,β=0.01,K=5,迭代次數iter=1 000。
2.4 實驗結果分析
依據LDA模型得到的P(topic|doc)分別對正面評論文本和負面評論文本進行聚類,對每個主題提取出概率最高的10個關鍵詞列出其P(word|topic)的概率分布結果見表4和表5。
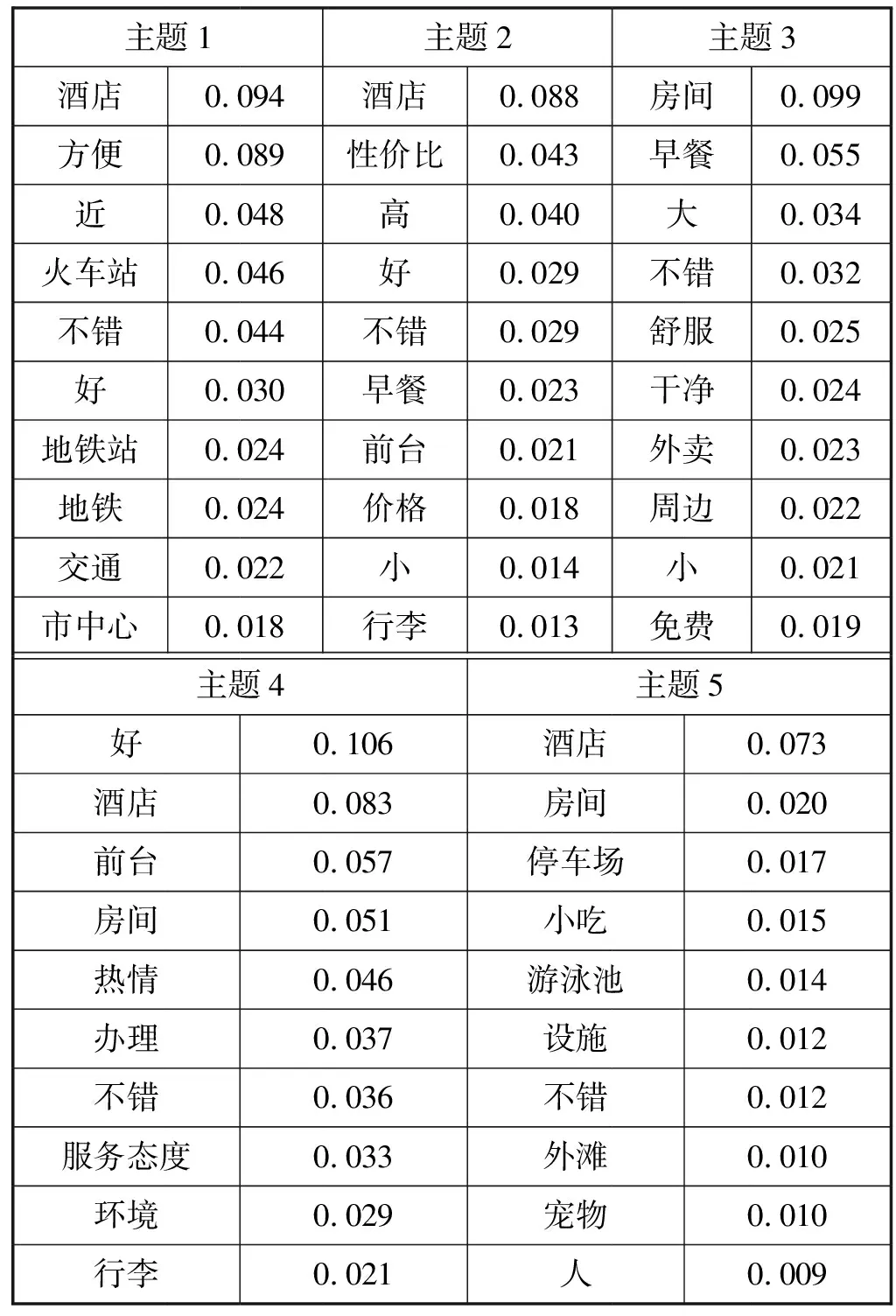
表4 LDA模型下正面評論的P(word|topic)
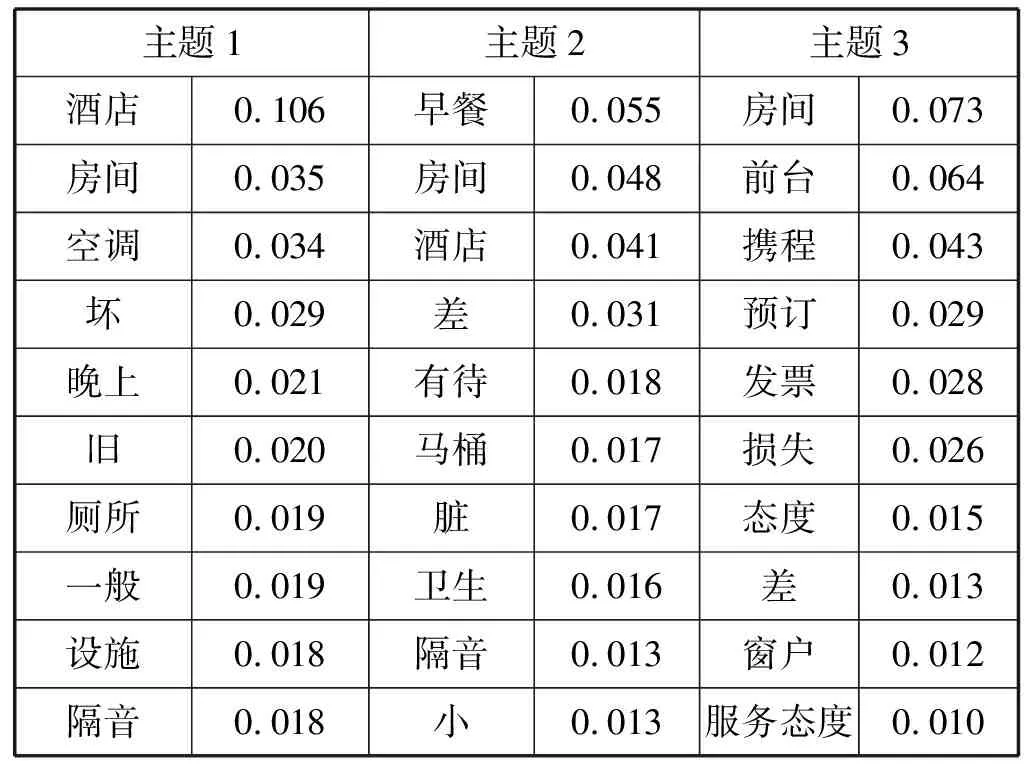
表5 LDA模型下負面評論的P(word|topic)
從表4可以看出,用戶對一家酒店持肯定態度的原因可以概括為五個方面:
(1) 地理位置:主題中的高頻詞有“火車站”“地鐵”和“市中心”等詞匯。說明用戶較為關注酒店周邊的交通樞紐、商圈等,好的地理位置能給用戶帶來優質的入住體驗。
(2) 性價比:主題高頻詞有“性價比”,這說明酒店的定價與服務水平相匹配是提高顧客滿意度的關鍵所在。
(3) 餐飲:“早餐”“外賣”等詞匯在該主題中頻頻出現,酒店免費提供早餐和送外賣上門服務可以給舟車勞頓、行程忙碌的用戶提供極大的方便。
(4) 服務態度:主題高頻詞有“前臺”“熱情”“服務態度”和“行李”等詞匯。在用戶辦理入住、退房等手續時,酒店工作人員的服務態度能給用戶留下最為直觀的印象并直接影響著用戶對酒店的評價。
(5) 硬件設施:主題高頻詞有“停車場”“游泳池”和“寵物”等。對于一家定位高端,追求高品質服務的酒店,游泳池、健身房和停車場等硬件設施會極大地提升酒店的整體水平,而有這方面需求的用戶也必然會選擇配備有這些硬件設施的酒店。
反觀表5,可將用戶對酒店持負面評價的原因歸納為客房質量較差和對酒店工作人員的服務態度不滿兩個方面,例如空調故障、房間隔音效果差、衛生條件簡陋、酒店工作人員的服務水平不夠專業、服務態度不夠友好等。
對于酒店行業而言,只有不斷完善管理制度,提升服務水平,才能發揮自身優勢,提升市場競爭力。結合以上主題,本文給出的建議是:絕大多數客戶最為關注酒店的地理位置、性價比、餐飲、服務態度和硬件設施這五個方面,在保證一定成本的情況下,要全面提升工作人員的服務水平和服務態度,努力提高房間內部的舒適度,盡可能完善硬件設施并依據房型精確定價,加大衛生保潔工作力度,避免出現客戶有需求卻得不到回復的情況。高標準做到以上幾點就能有效提高用戶的滿意度進而吸引更多用戶前來入住。
3 結 語
本文提出了一種適用于酒店評論的BERT-LDA文本挖掘方法,借助BERT捕捉文本雙語義特征的能力,有效地提高了情感分類的準確率,結合LDA主題建模完成了對海量用戶評論的主題聚類和文本挖掘工作,為今后的酒店評論文本研究提供了一種新的分析思路。在訓練BERT模型時,所使用的訓練語料是當前內容覆蓋最為全面的中文維基百科語料庫,因此本文提出的方法同樣適用于其他領域的短文本分類和聚類。但是本研究仍存在不足,如訓練情感極性分類器時作為訓練集的評論語料還相對較少,評論文本的情感極性還可進一步劃分等。在收集數據過程中還發現旅行類型為商務出差的樣本數量要遠遠高于其他旅行類型的樣本,但商務出差用戶給出的平均評分卻是最低的。針對此問題,我們將對商務出差用戶的評論文本做更進一步的研究。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
