基于稀疏字典表示的無監督域適應學習算法
2023-08-10 03:18:56王賽男鄭雄風
計算機應用與軟件 2023年7期
王賽男 鄭雄風
1(江蘇聯合職業技術學院南京工程分院 江蘇 南京 211135) 2(南京郵電大學計算機學院 江蘇 南京 210023)
0 引 言
遷移學習同人類的學習思想一樣,利用以往學習過的相關經驗,遷移到目標領域或任務的學習當中。遷移學習的主要學習形式是利用相關的源域知識輔助目標域學習,以解決目標域數據或數據標簽稀缺的問題。人類對于遷移學習的能力則是與生俱來的,一些成語如“舉一反三”“照貓畫虎”和“依葫蘆畫瓢”等也俱能反映出人類的遷移學習能力很強。但是,這種遷移能力往往體現在兩種相同的事物中,如學會自行車的騎行可以較好地幫助學習騎電動自行車,自行車和電動自行車在大體結構上是相同的。學會象棋的人也能較為容易地學會國際象棋,因為兩種棋類有很多的共通知識。因此,遷移學習的主要方法就是尋找源領域和目標領域中有相同或相近知識的部分,完成知識的遷移。
對于不同的遷移學習場景,有不同的遷移學習方法[1],大致可分為四種基于特征[2-4]的遷移學習、基于樣本[5-6]的遷移學習、基于參數[7-9]的遷移學習、基于關系[10-11]的遷移學習。Pan等[5]提出遷移成分分析方法(Transfer Component Analysis,TCA),利用MMD來計算源域和目標域的邊緣分布差異,然后在再生核Hilbert空間中學習其潛在特征,在保持源域數據結構的同時,找出兩個域之間具有相同分布的潛在特征。最終利用其他傳統的機器學習方法訓練目標分類模型。
Pan等[5]提出了核均值匹配(Kernel Mean Matching,KMM)的方法,在再生核希爾伯特空間(Reproducing Kernel Hilbert Space,RKHS)中對源域和目標域中的樣本的概率分布進行估計,通過對樣本進行均值差異匹配,獲得源域樣本的權值,使得加權后源域樣本的概率分布與目標域樣本盡可能接近。Yang等[7]提出一種自適應支持向量機(Adaptive Support Vector Machine,A-SVM)方法用于目標域分類器的訓練,ASVM假設源域分類器和目標域分類器之間存在一個偏差,隨后將這個偏差加入到源域分類器上,從而得到一個新的分類器,并應用在目標域的分類任務上。Mihalkova等[10]基于馬爾可夫邏輯網絡提出一種對相關聯知識的自主映射和修正遷移學習方法。
為了找到與目標域相關的源域知識,部分研究方法通過創建中間表示信息來拉近源域和目標域的樣本分布,但這些表示信息不能完全地重構出源數據和目標數據的概率分布,此類方法常用于解決源域和目標域之間分布差異較大的場景,如異構遷移學習,因此無法取得最佳分類性能。基于樣本選擇或樣本加權的域適應方法通過找到與目標域數據最相關的源域樣本,使得改變后的源域樣本分布和目標域樣本分布匹配。但是,這類方法不能解決以下場景:圖像特征本身可能已因域偏差而失真,并且某些圖像特征可能特定于某一個域,因此與另一域的分類無關。
針對上述問題,提出一種基于稀疏字典表示的無監督學習框架。算法共分為兩個階段,第一階段通過字典學習分別對源域樣本和目標域樣本進行重構,在真實還原源域和目標域樣本的同時,約束源域和目標域的樣本在稀疏表示空間上盡可能接近;第二階段通過對源域的樣本表示空間進行學習得到分類器參數,再對目標域進行分類。SRDA利用字典學習拉近了兩個域樣本的稀疏表示,使得源域和目標域在稀疏表示空間可以共享同一個分類器,完成知識遷移。SRDA完全忽略目標域的標簽信息,因此也是一種無監督的域適應學習框架。
1 相關工作
1.1 字典學習
字典學習方法廣泛應用于解決各種計算機視覺和圖像分析的問題,如圖像去噪、圖像分類和圖像恢復等。稀疏表示與字典學習通常是一個相互交替的過程,首先是為輸入的樣本找到一個合適的稀疏表示,然后再通過樣本的稀疏表示來優化字典。字典學習旨在為輸入數據找到合適的字典,將其轉化為稀疏表達形式,從而可以挖掘數據的有用特征,在簡化學習任務的同時,降低模型的復雜度。對于一個原始的訓練樣本集合X={x1,x2,…,xm}∈Rd×m,其中:m代表樣本的數量;xi∈Rd代表第i個d維樣本。字典學習損失函數可概括為如下公式:
(1)
式中:D=(d1,d2,…,dk)是含有k個原子的字典矩陣;A是X的稀疏表示;第一項使得稀疏矩陣A能夠通過字典D更好地重構樣本矩陣X;第二項則是讓稀疏矩陣A更好地保持稀疏性;λ表示正則參數。因此,通過對字典中的原子進行簡單的線性組合來表示原先的樣本,可以使得重構后的樣本的分類性能有效提升。
1.2 基于標簽一致性的K-SVD算法
在機器學習中,對于通用的分類器參數W∈Rm×K,損失函數定義如下:
(2)
式中:m是類別數量;L是分類損失函數,如平方損失或者鉸鏈損失等。
在學習分類器參數時,如果將字典學習的過程和分類器的學習過程分開,那么學習得到的分類器的分類性能有可能達不到最好的效果,所以一部分研究專注于將字典與分類參數聯合在一起,在完成分類任務的同時對字典進行優化,其公式定義如下:
s.t.?i,‖xi‖0≤T
(3)
在實際實驗中,這些方法往往要求學習一個相對較大的詞典才能實現良好的分類性能,但是這樣將會導致較高的計算成本。在某些只能使用基于多個成對的分類器或“一對一”分類器的分類架構才能獲得良好分類結果的場景時,這種問題帶來的影響會更加嚴重。
為了解決以上問題,Jiang等[12]提出一種基于標簽一致性的K-SVD(Label Consistent K-SVD,LC-KSVD)算法,將字典學習方法用于圖像識別當中,LC-KSVD認為樣本的稀疏編碼也可以看作是一種可以分類的特征。損失函數如式(4)所示。
式中:字典D是在稀疏編碼階段隱式求解。同樣,可以通過梯度下降法對字典D求解。本文的實驗表明,單獨使用字典和一個多分類分類器能有效提升樣本的分類性能。
2 本文算法
首先,與其他無監督域適應算法不同,SRDA算法通過對源域樣本的特征進行重構,然后學習在樣本重構的稀疏表示空間上的分類參數,在源域和目標域的公共樣本重構空間上對目標域的分類。SRDA在源域和目標域的重構后的稀疏表示空間上添加約束,使得在源域樣本的稀疏表示空間上學習得到的分類器可以在目標域樣本的稀疏表示空間上取得較好的性能。圖1給出了SRDA的模型框架。
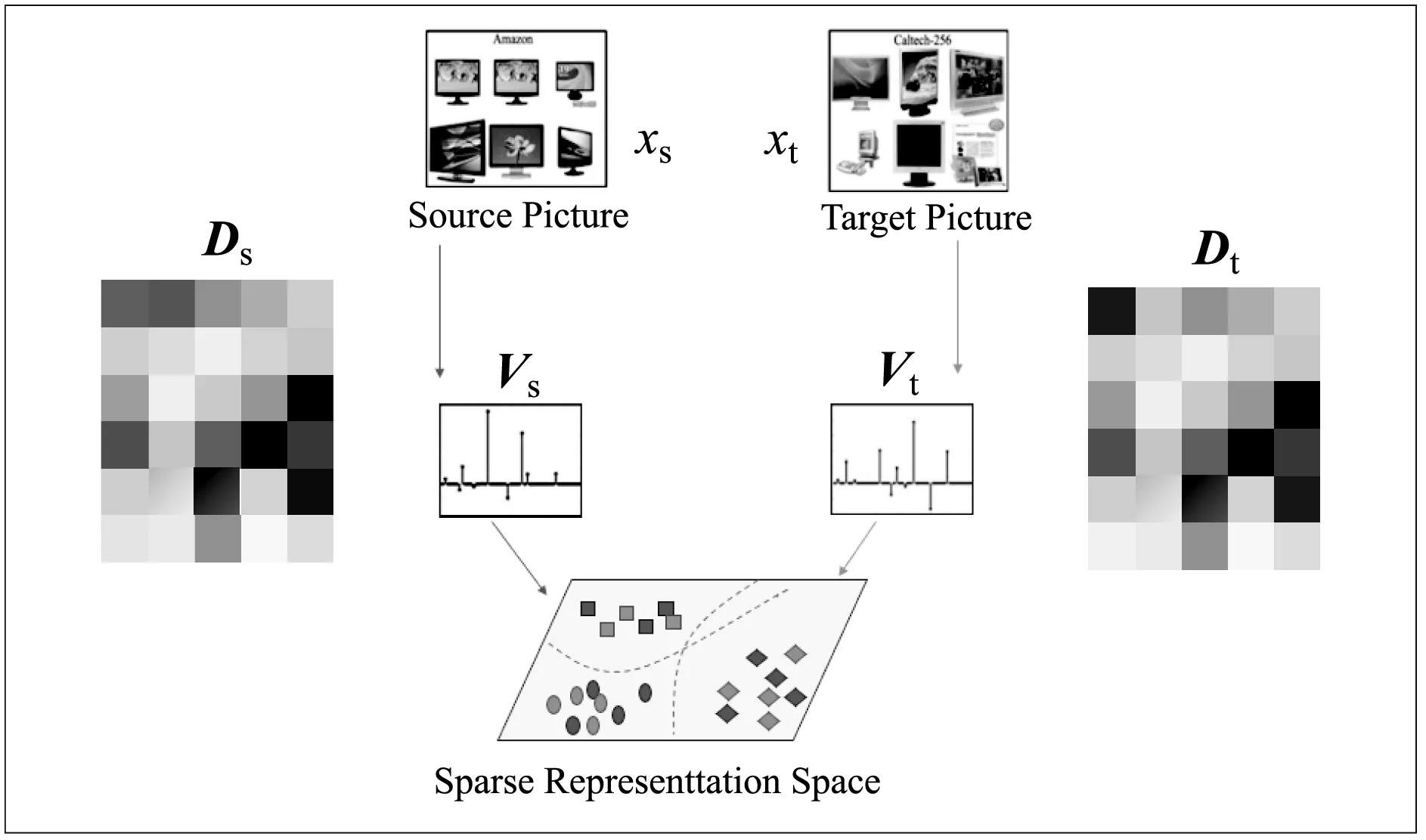
圖1 基于稀疏字典表示的無監督域適應學習模型框架
2.1 基于源域樣本的字典學習
SRDA算法與LC-KSVD算法一樣,都希望可以從源域樣本的稀疏表示空間中學習得到合適的分類器參數,而LC-KSVD僅僅是基于一個監督學習的字典學習方法,SRDA則將其擴展到了無監督域適應學習中。基于源域樣本的學習框架可概括為如下公式:
(5)
式中:Xs={x1,x2,…,xns},表示源域的樣本空間;Vs是源域樣本的稀疏編碼。Ds={d1,d2,…,dk} 為從源域中學習到的字典;Ys=[y1,y2,…,yns]∈Rm×ns為源域樣本Xs對應的類標簽,yi=[0,…,1,…,0];W是從源域的稀疏表示空間中學習到的分類器參數。式(5)中:第一項為控制分類器模型復雜度,防止模型出現過擬合現象;第二項為源域樣本在稀疏空間中的分類損失;第三項為字典學習項,學習源域樣本的字典與稀疏表示;第四項控制源域樣本在稀疏空間中盡可能稀疏。α、β和λs為正則化參數。
2.2 聯合目標域樣本的字典學習
為了更好地利用源域的知識,使得從源域中學習得到的分類器能夠適用于目標域分類器,首先對于目標域進行字典學習和稀疏表示。
(6)
式中:Xt={x1,x2,…,xnt},表示目標域樣本空間;Dt為從目標域樣本的特征中學習到的字典;Vt是目標域樣本的稀疏表示。基于目標域的字典學習同普通的字典學習一致,可通過交替優化方法優化字典項Dt和系數項Vt。
聯合式(5)和式(6),結合源域的字典學習與目標域的字典學習,有如下公式:
λs‖Vs‖2,1+λt‖Vt‖2,1
(7)
此外,在字典學習的框架內,希望可以通過一個約束項使源域和目標域之間的分布差異減小,從而使得在源域中學習到的分類器參數可以應用于目標域分類任務。文獻[13]中提出,通過拉近稀疏表示空間Vs與Vt的距離,等同于在一個潛在的公共稀疏表示空間中,源域樣本和目標域樣本的分布基本一致。盡管此時的源域和目標域樣本分布相近,但是仍然存在少許差異。因此,在式(7)中加入一個源域與目標域之間的約束項,最終基于稀疏字典表示的無監督域適應學習算法可表示為:
(8)
與文獻[12]類似,通過最小化‖Vs-Vt‖F來刻畫源域樣本與目標域樣本在公共稀疏表示空間的距離。α、β、γ、λs、λt為正則化參數。
2.3 模型求解
式(8)的優化是一個雙凸問題,根據文獻[14]中的理論,可以將其分解為兩個凸優化問題,隨后通過交替迭代方法進行求解。實驗中,每個參數都進行隨機初始化。接下來將展示每個參數的求解方法。
(1) 固定Vs,更新W。式(8)可簡化為:
(9)
式中:J表示式(8)。
令W偏導為0,可得:
(10)
(2) 固定Vs、Vt,更新Ds、Dt。式(8)可簡化為:
(11)
(12)
分別令Ds、Dt偏導為0,可得:
(13)
(14)
(3) 固定Ds、Dt,更新Vs、Vt。
分別令Vs、Vt偏導為0,可得:
2λ1MsVs+γ(Vs-Vt)=0
(17)
γ(Vs-Vt)=0
(18)
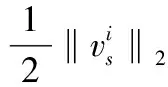
最終,算法中關于W、Ds、Dt、Vs、Vt的閉式解如下:
(19)
具體算法流程如算法1所示。
算法1SRDA算法
輸入:源域和目標域數據集Xs、Xt,正則化參數α、β、γ、λ1、λ2,字典大小r迭代停止閾值ε。
輸出:源域和目標域共享分類器參數W。
1. 初始化W,Ds,Dt,Vs,Vt;
2.初始化迭代次數k=1,目標函數初始值為J0=INF;
3. Repeat:
4. 根據式(19)更新W;
5.根據式(19)更新Ds;
6.根據式(19)更新Dt;
7.更新Vs,Vt;
9. Repeat:

13. Until收斂:
14. 更新目標函數Jk;
15. 若|Jk-Jk-1|<ε;
16. Break;
17. 結束,輸出W。
3 實驗與結果分析
為了評估SRDA的性能,將SRDA與目前一些常見的經典的分類方法進行比較,其中包括SVM、GFK、TCA,以及一些其他新穎的算法,如ARTL。每個算法都在多個數據集上進行了多次實驗。
3.1 數據集
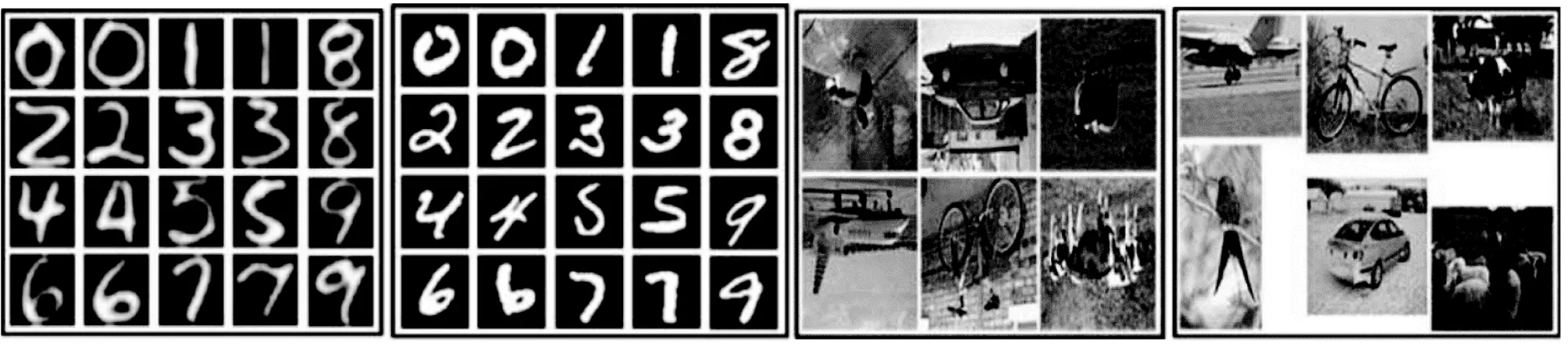
如圖2所示,在實驗中,采用USPS、MNIST、MSRC、VOC2007、Office和Caltech256等數據集,這些數據集均是用于評估計算機視覺與模式識別等領域的算法的常用數據集。
(a) USPS(b) MNIST (c) MSRC(d) VOC2007
(1) USPS數據集中共有7 291幅訓練樣本圖像和2 007幅測試樣本圖像,大小是16×16。
(2) MNIST數據集中共有60 000個訓練樣本圖像和10 000個測試樣本圖像,大小都是28×28。
從圖2中可以看出,USPS和MNIST的數據分布是不一樣的,但是它們共享10個類別的數字圖像,因MNIST數據集圖片數量過大,所以每次實驗都隨機抽取一些樣本,在USPS to MNIST實驗中,從USPS數據集中隨機選取1 200個樣本作為源域數據,從MNIST數據集中隨機選取1 500個樣本作為目標域數據,MNIS to SPS也做同樣操作。同時實驗中將所有樣本圖像統一縮放為16×16大小,并通過對灰度像素值重新編碼得到表示每個圖像特征向量。如此,源數據和目標數據就可以共享相同的特征空間。
(3) MSRC數據集由Microsoft Research Cambridge提供,其中包含18個類別共4 323幅標記的圖像。
(4) VOC2007數據集共包含20個類別共5 011幅圖像。
圖2(c)和圖(d)的分布明顯不同,因為MSRC都是基于評估而采集的標準數據圖像,而VOC2007的圖片采集較為隨意。MSRC與VOC2007共享6個類別:“飛機”“自行車”“鳥”“汽車”“牛”和“羊”。同樣,在MSRC to VOC2007的實驗中,分別從MSRC中選取1 269幅圖像作為源域數據、VOC2007中選取1 530幅圖像作為目標域數據構成數據集,在VOC2007 to MSRC的實驗中交換數據構成數據集即可。為方便實驗進行,所有圖像均被縮放至256個像素,提取其128維的SIFT特征。
(5) Office數據集中共有4 652幅圖片數據,包含了31個類別,也是計算機視覺領域較為流行的基準評估數據集。
(6) Caltech-256一般用于目標識別實驗,由30 607幅數據圖像和256個類別組成。
本文的實驗采用一個較小的Office to Caltech數據集,該數據集共享10個類別,所有的圖片都進行特征提取并量化為帶有碼本計算的800-bin直方圖。實驗一共包含四個數據域:C(Caltech-256)、A(Amazon)、W(Webcam)和D(DSLR),每次實驗隨機選擇兩個不同的域作為源域和目標域,一共可以構建出12個跨域對象識別數據集:C to W,C to A,C to D,…,D to W。
3.2 實驗設置
本實驗為基于稀疏字典表示的無監督域適應學習,即在源域中所有的數據都是有標簽數據,而目標域所有數據都沒有標簽。實驗中共涉及到5個超參數:α、β、γ、λs、λt,以及字典大小r。對于參數優化,實驗中采取網格搜索方式,具體如表1所示。
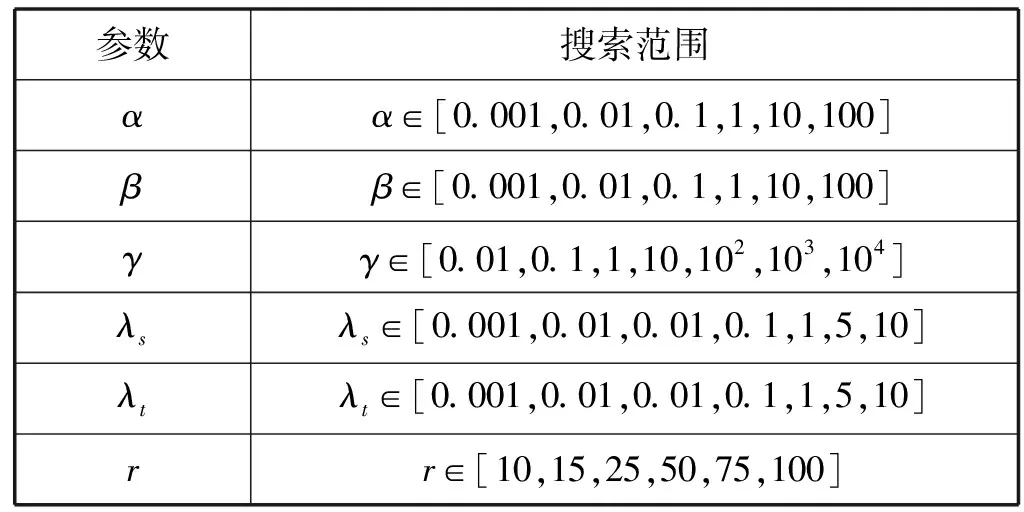
表1 各超參數搜索范圍表
3.3 性能評價指標
本實驗采用測試數據(目標域無標簽樣本)的分類準確率作為算法評價指標,這種評價標準在很多算法中都有使用。
(20)
式中:yT(x)表示測試樣本(目標域無標簽樣本)x的真實標簽;fT(x)是最終應用在目標域樣本x的預測函數;fT(x)的值則是對樣本x預測標簽;|x:x∈DTu∧fT(x)=yT(x)|表示預測正確的樣本數量;|x:x∈DTu|代表總的測試樣本數量。
為保證實驗結果的穩定性及有效性,對于本文算法以及其他對比實驗方法,在實驗中將每種組合的數據集實驗運行10次,取平均值作為最終的算法評價準確率。
3.4 實驗結果
本文將所提出的SRDA方法與其他4種對比方法進行比較,實驗共在16組數據集上進行,實驗結果如表2所示。基于實驗結果,可得出以下結論:

表2 真實數據集的性能比較
(1) 在所有數據子集組合的實驗中,除了SVM算法,其他幾種算法均是基于遷移的分類學習方法,這表明了遷移學習對于目標域數據分類是有幫助的,源域中的分類知識可以有效地遷移到目標域,幫助目標域實現更好的分類結果。
(2) 在USPS to MNIST手寫體數據集和MSRC to VOC圖像數據集上,本文提出的SRDA明顯優于其他無監督域適應方法,這表明字典學習可以真實地還原出源域和目標與圖像,同時在樣本的稀疏表示空間拉近源域和目標域樣本,達到減小域之間的分布差異的目的。
(3) 在Office to Caltech 圖像數據集中,本文提出的SRDA框架性能在大部分實驗組合里表現也優于其他算法,這表明相對于其他基于特征遷移的域適應方法,SRDA可以有效地利用源域樣本的特征,減少負遷移的產生。
3.5 實驗結果分析與對比
本文提出的SRDA是一個迭代算法,通過不斷迭代求解參數W、Ds,Dt、Vs、Vt,從圖3中可以看出,在A to W、MSRC to VOC、USPS to MINST實驗數據組中,隨著迭代次數的增加,SRDA模型的目標函數值快速地下降,在迭代4次之后目標函數值收斂,得到局部最優解。這表明運行SRDA模型所耗時間很短,模型效率較高。
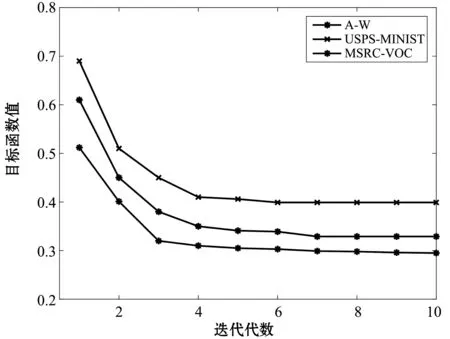
圖3 目標函數值隨迭代次數的變化
實驗采用了16組數據集組合和5種算法進行對比,分類準確率對比結果如表3所示,其中SRDA列準確率下標代表10次測試結果的標準差,用于表示結果誤差。本節針對USPS to MNIST數據集組合對SRDA算法中的各個參數進行分析。首先是字典大小r,SRDA方法中目標域的分類使用從源域的稀疏表示空間學習的分類器,因此源域字典與目標域字典大小相同。參數r表示字典的詞匯量,從圖4中可知,詞匯量的大小與目標域的分類精度密切相關,對于參數r,其搜索范圍為[10,15,25,50,75,100],當r=25時,目標域準確率最高,當r>25時,分類精度有所下降并趨于穩定,這表明了過完備的字典包含了更多的無用信息(即基于源域稀疏表示的字典特征空間存在特征冗余),這些特征也會影響目標域的分類準確率。
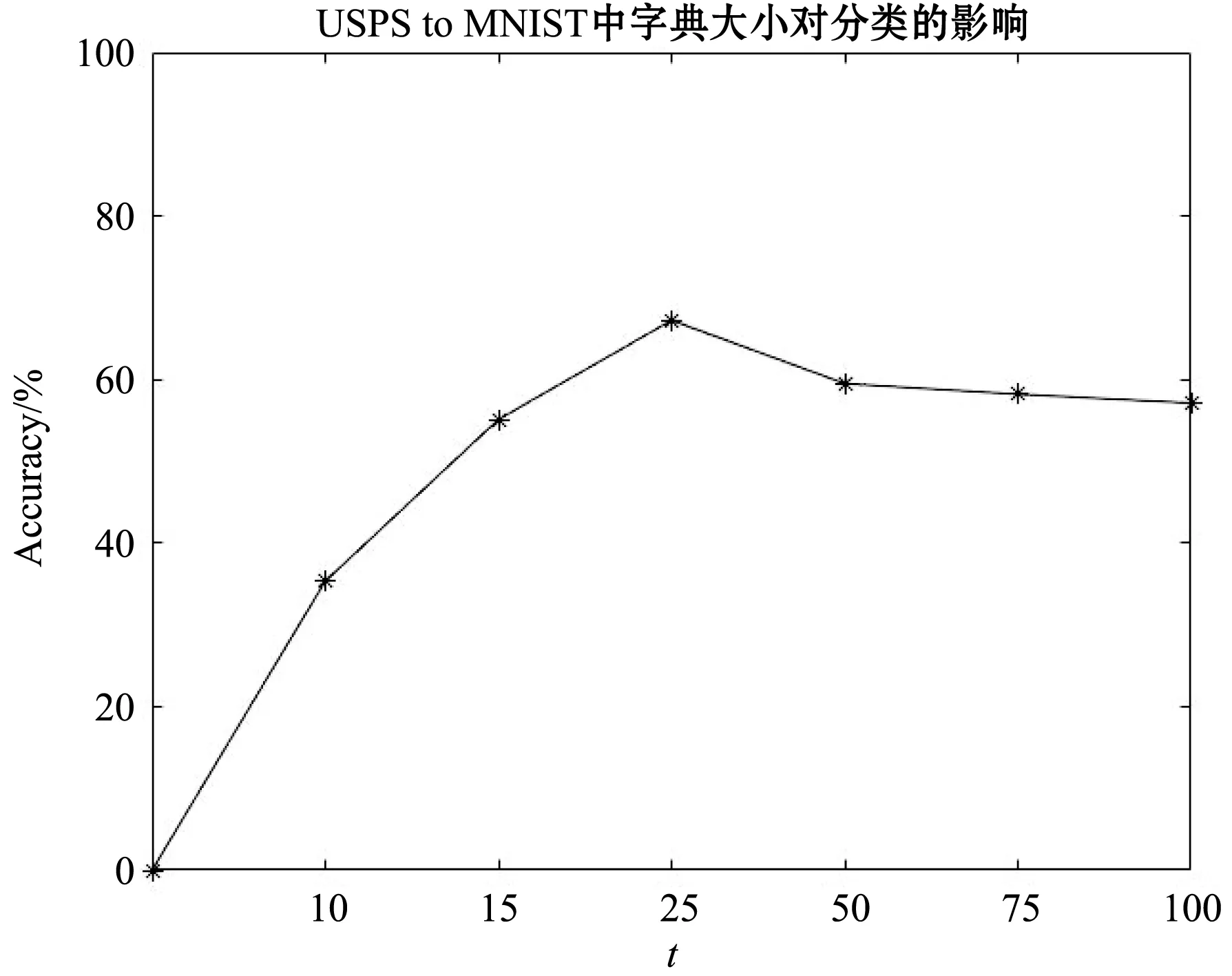
圖4 字典大小分析圖
在圖5中,分別從USPS to MNIST和MNIST to USPS兩個數據組合分析了源域與目標域的稀疏參數λs、λt、正則化參數γ對目標域分類性能的影響。圖5(a)和圖5(b)是固定正則化參數,僅對λs和λt進行分析,圖5(c)和圖5(d)是對λs和γ的分析,圖5(e)和圖5(f)是對λt和γ的分析。從中可以得到如下結論:
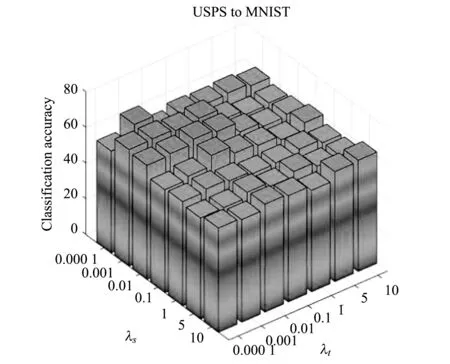
(a)
(1)λs=0.01、λt=0.01,目標域可以取得最好的分類性能,此時從源域和目標域學習到的樣本的稀疏表示均能較為完美地重構原樣本。
(2)γ=1 000時,目標域分類性能達到最佳,這表明在SRDA算法中,對于源域和目標域樣本的稀疏表示進行約束,能夠有效拉近樣本之間的距離,減少源域和目標域之間的差異,從而使得從源域稀疏表示空間學習得到的分類器可以應用于目標域稀疏表示空間的分類。
4 結 語
本文提出一種基于稀疏字典表示的無監督域適應學習算法SRDA,本文算法與其他基于特征的遷移學習算法不同,SRDA通過引入字典學習方法,通過相似性約束挖掘源域和目標域樣本之間的內在聯系,以此提升目標域的分類性能。大多數特征遷移算法主要學習一種映射函數,通過映射后的特征來最小化源域和目標域的分布差異。在分類器的學習過程中,大部分域適應研究都是針對源域樣本進行學習得到分類器參數,SRDA則借鑒稀疏表示學習中的一些技巧,即在樣本的稀疏表示空間學習分類器參數,而在樣本的稀疏表示空間學習到的分類器參數也能有效地完成源域和目標域的分類任務,相比在樣本空間上進行分類,其性能會有很大的提升。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
