一種車載數字相機與激光雷達融合算法設計
2023-08-24 19:25:05康炳翔秦忠鑫查欣然丁士航胡江飛
專用汽車 2023年8期
康炳翔 秦忠鑫 查欣然 丁士航 胡江飛


摘要:環境感知是智能輔助駕駛的底層模塊,單傳感器感知存在易受干擾、所需配置傳感器數量多和感知效果差等弊端,為此提出一種車載數字相機與激光雷達融合算法。綜合考慮信息融合高效性與系統魯棒性采取決策級融合策略,利用CENTER POINT算法對雷達點云數據進行處理,再利用Yolo v3算法進行密集型數據訓練處理圖像數據,最后使用交并比匹配(IOU)和已有文獻的D-S論據實現數據融合并輸出決策結果。經過KITTI數據集驗證,該融合算法輸出的識別效果優于單傳感器,且在多種路況上均有良好的目標檢測效果。
關鍵詞:環境感知;激光雷達;Yolo;融合算法;目標檢測
中圖分類號:U462? 收稿日期:2023-04-19
DOI:10.19999/j.cnki.1004-0226.2023.08.006
1 前言
近年來,芯片算力與網絡技術的快速發展,使得智能輔助駕駛技術走向成熟。環境感知作為核心技術,包括利用機器視覺的圖像識別技術、利用雷達(激光、毫米波、超聲波)的周邊障礙物檢測技術、多源信息融合技術、傳感器冗余設計技術等[1]。若僅通過單一類別傳感器獲取信息,則準確度低、受環境影響大、系統魯棒性差,容易出現誤判漏判的情況,因此常采取多傳感器并采用多源信息融合技術實現車輛的環境感知。
多傳感器信息融合能夠很好地克服單一傳感器所出現的問題,實現環境信息最大利用化,從而提高系統的可靠性和抗干擾能力。一些學者對此進行了研究[2-3],然而大多數研究往往在融合的網絡架構上尋求突破,試圖通過跨層級的數據特征融合實現目標檢測的高性能。此類方法對于算法的復雜程度有較高的要求,也要求車載處理器性能優異,對于設備依賴較高。據此,本文提出一種車載數字相機與激光雷達融合算法,并進行了驗證分析。
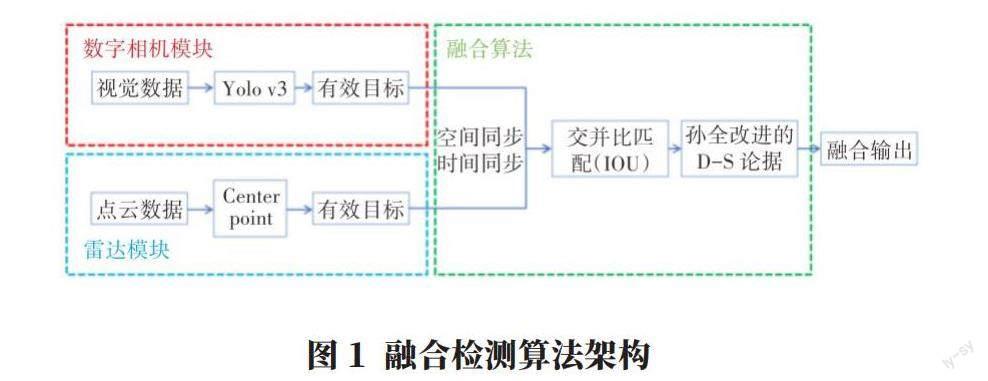
2 融合檢測算法架構
多傳感器信息融合可以實現各傳感器感知優勢互補,提高車輛感知系統靈敏性與可靠性,當前有三種策略:數據級融合、特征級融合、決策級融合[4]。
決策級融合具有層級較高、處理數據量較少、實時性好、算法魯棒性較強等優點。因此,本文采用決策級信息融合方法。融合檢測算法架構如圖1所示,包含數字相機模塊、雷達模塊和融合模塊共三個模塊。數字相機模塊使用Yolo v3算法處理視覺數據并框出檢測目標的二維框與置信度;雷達模塊使用center point算法處理點云數據并框出檢測目標的三維框與置信度;融合模塊利用交并比匹配(IOU)與孫全等[5]的D-S論據進行邊界框融合與置信度融合,實現多傳感器融合。
3 視覺數據和激光雷達點云處理
3.1 基于Yolo v3的視覺目標檢測
數字相機模塊基于深度學習利用Yolo v3算法進行密集型數據訓練模型。此算法主干網絡是Darknet-53,因其網絡結構中含有53層卷積層,并且相較于之前版本Yolo算法增加了多尺度特征融合目標檢測方法。跨尺度特征融合可以兼顧高低感受及不同尺寸的目標檢測,極大地提高了視覺目標檢測的準確率。
選取KITTI數據集,模型訓練預權重設置為在COCO數據集訓練的權重,首先將KITTI數據集轉為VOC系列數據集格式,數據集共包含7 481條數據,并且以訓練集∶驗證集≈6∶1的比例劃分,即訓練集6 413條,驗證集1 068條。數據庫搭建完成后進行環境配置與模型部署,設置迭代次數為270輪,開始訓練模型。數字相機模塊充分利用基于神經網絡的深度學習技術,通過密集型數據高重復訓練得到一個參數優異的視覺目標檢測模型。具體實現流程如圖2所示。
3.2 基于Center point的3D目標檢測
雷達模塊基于深度學習利用Center Point算法[4]實現目標檢測。首先以點云數據作為輸入,輸出物體的細化檢測框與置信度,相較于邊框預測,壓縮了對象檢測器的搜索空間,提高了檢測性能;在面向目標尺寸復雜的場景,該算法精度更高。因此本文選用Center Point算法對點云數據進行處理,完成目標檢測。
具體流程如下:輸入點云數據,基于基礎的3D backbone網絡處理得到特征地圖。其維度M為:
式中,w是寬;h是長;k是通道數。
Center heatmap head預測目標中心點,生成一個大小為k的通道,同時算法會擴大每個對象中心的Gaussian peak,從而改善點云稀疏導致的目標漏檢;Regression head處理數據得到3D框的類別、置信度,構成3D候選框。最終從3D候選框的每個面提取額外的特征點,通過對特征地圖輸出的M進行雙線性插值獲得特征。然后拼接這些額外的特征點輸入到MLP,輸出與類別無關的置信度與細化邊界框,將此置信度與3D候選框所得置信度相乘再開方,得到最終置信度。
4 多傳感器信息融合
4.1 空間同步
激光雷達獲取的點云數據與數字相機獲取的圖像數據的融合首先需要進行空間同步,在此進行的兩種傳感器坐標標定是指將三維坐標系的點云數據投影至圖像數據的二維坐標系。三維坐標系依次經過旋轉平移、投影變換和離散化轉為像素坐標系,如圖3所示。
具體的兩傳感器空間同步坐標轉換公式表述如下:
式中,u,v為數字相機獲取的圖像數據二維坐標系點坐標用;fu、fv為數字相機X軸、Y軸方向尺度因子;u0、v0是數字相機圖像坐標系的中心點坐標;(x,y,z)為激光雷達獲取的三維坐標系點云的坐標;R為旋轉矩陣;t為平移矢量;M是投影矩陣。
4.2 基于目標檢測交并比匹配的融合
在獲得點云3D目標以及視覺目標后,將為點云目標3D檢測框建立最小矩形邊界框,再與YOLO檢測出的邊界框進行融合。設點云目標邊界框的面積為SLIDAR,視覺目標邊界框的面積為SCAMERA。重合區域面積為SRADER∩CAMERA(圖4)。則交并比(IOU)計算公式為:
本文選用常用的閾值設計,即閾值取0.5、0.85,用來判斷預測的邊界框是否正確,IOU越高,邊界框越精確。在此,設定交并比小于0.5,認為是兩個獨立目標,在0.5~0.85時,將相交的區域設為融合目標區域。在0.85~1時,本文認為二者完全重合,設定最小邊界框住兩個邊界框,將其作為融合目標區域。
4.3 基于孫全等[5]的D-S證據算法的融合
基于孫全等[5]的D-S論據改進方法,對經過交并比匹配融合后的兩種傳感器邊界框的置信度進行融合。以下對D-S論據原理[6]進行簡單的介紹。
在證據理論中,對于一個問題可能有多種答案,各個答案之間是互斥的,一個答案就是一種假設,共有m種假設,所有假設的集合構成一個識別框架Θ,Θ={A1,A2,…,Ai,…,Am},其中Ai是識別框架中的某一種假設。在識別框架Θ下還存在n個證據E1,E2,…,En,每個證據對識別框架下的每一種假設都有一個預測概率,該證據對所有假設的預測概率的和為1。
對于本文的融合來說,設有一個識別框架Θ,Θ中有兩個假設:“是某種類別”“不是某種類別”。在Θ下有兩個證據E1(圖像)、E2(點云),其構成的基本概率賦值表如表1所示。
表中m1(A1)、m2(A1)分別是圖像檢測框和點云檢測框對某種類別的置信度,m1(A2)=1-m1(A1),m2(A2)=1-m2(A1)。然后用孫全等[5]的D-S論據改進方法求出的m(A)就是需要求出的融合置信度。
5 實驗分析
5.1 Yolo v3訓練分析
本文Yolo v3模型訓練工作站配置方案如表2所示。
實驗選取KITTI數據集進行模型訓練,將完整KITTI數據集以訓練集和驗證集約為6∶1的比例劃分,所訓練模型的map=80.33%,具有較高的精度。
5.2 融合數據分析
同一場景目標檢測定量分析如表格,選取其中三個融合結果進行分析,融合后的置信度如表3所示。
不同路況行駛場景目標檢測效果圖見圖5。
單獨使用激光雷達檢測并不具有很高的置信度,而與數字相機所檢測結果融合之后置信度提高,有效地改善了激光雷達所識別物體置信度不足的問題。注意到融合置信度小于數字相機單檢測的置信度,其降低了因完全依賴數字相機誤判而引發危險的可能。該融合算法在多種路況上均表現良好的目標檢測效果。
6 結語
本文提出了一種車載數字相機與激光雷達融合算法設計,利用center point算法對雷達點云數據進行處理,利用Yolo v3算法進行密集型數據訓練處理圖像數據,并使用交并比匹配(IOU)和孫全改進的D-S論據實現數據融合并輸出決策結果。結果表明:該融合算法在不增加算法網絡架構復雜度,不提高硬件成本的情況下,輸出的識別效果優于單傳感器,且在多種路況上均表現良好的目標檢測效果。但值得注意的是,在街邊行人檢測和密集的街口等復雜場景,此算法會出現一定的漏檢與誤檢情況。
參考文獻:
[1]李克強,戴一凡,李升波,等.智能網聯汽車(ICV)技術的發展現狀及趨勢[J].汽車安全與節能學報,2017,8(1):1-14.
[2]Pang S,Morris D,Radha H. Fast-CLOCs:Fast camera-LiDAR object candidates fusion for 3D object detection[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision.2022:187-196.
[3]Wang L,Zhang X,Qin W,et al.CAMO-MOT:combined appearance-motion optimization for 3D multi-Object tracking with camera-LiDAR fusion[J].arXiv preprint arXiv:2209.02540,2022.
[4]Yin T,Zhou X,Kr?henbühl P.Center-based 3D object detection and tracking[C]//2021 IEEE/CVF conference on computer vision and pattern recognition(CVPR).Nashville,TN,USA,2021:11779-11788.
[5]孫全,葉秀清,顧偉康.一種新的基于證據理論的合成公式[J].電子學報,2000,28(8):117-119.
[6]Smith A F M,Shafer G.A mathematical theory of evidence[J].Biometrics,1976,32(3):17-24.
作者簡介:
康炳翔,男,2002年生,研究方向為基于深度學習的智能汽車感知與規劃控制。
