基于多尺度殘差注意力網絡的全色銳化方法
2023-09-13 12:53:02吳燕燕王亞杰謝延延
重慶理工大學學報(自然科學) 2023年8期
吳燕燕,王亞杰,謝延延
(沈陽航空航天大學 工程訓練中心, 沈陽 110136)
0 引言
遙感圖像全色銳化(pan-sharpening)是指將高空間分辨率的全色(panchromatic,PAN)圖像與低空間分辨率的多光譜(low-resolution multi-spectral,LRMS)圖像進行融合[1-2],以合理利用和整合星載全色多光譜圖像信息,獲得高空間分辨率多光譜圖像(high spatial resolution multispectral images,HRMS),便于目標探測、土地覆蓋分類及檢測[3-4]。全色圖像具有較高的空間分辨率,包含較多地理位置信息、紋理和邊緣;多光譜圖像具有豐富的光譜信息,能很好地對各種地物進行解譯、分類,利用兩者信息的互補性可以有效提高監測效率和改善視覺效果[5-6]。
遙感圖像融合方法主要包括成分替換法(component substitution,CS)[7-9]、多分辨率分析法(multi-resolution analysis,MRA)[10-11]、模型優化法[12-14]、深度學習方法[15-16]。其中,基于深度學習的遙感圖像融合算法是近年研究的熱點。2016年,Masi等[17]開創性地提出了一種應用在遙感圖像融合中的卷積神經網絡方法(pansharpening by convolutional neural networks,PNN),該方法采用三層卷積神經網絡(convolutional neural network,CNN)和一些輔助的非線性指數,將遙感圖像融合當成一個端到端的問題,在不增加網絡復雜性的同時提高了算法性能。之后,大量使用卷積神經網絡的全色銳化方法被提出。2017年,Rao等[18]在CNN網絡中加入了殘差網絡,改善了融合圖像的光譜失真問題。2018年,Scarpa等[19]為了改進網絡的性能,使得到的融合圖像包含更多的信息,在CNN網絡中加入了目標自適應函數。2020年,Liu等[20]提出了一種兩流融合遙感圖像融合方法,使用2個子網絡分別提取LRMS和PAN圖像的信息,并且在重建HRMS部分中加入了殘差網絡,既保留了大量光譜信息也提高了圖像的清晰度。
然而,基于CNN的遙感圖像融合方法大多使用相同的網絡結構提取源圖像的特征,或者是將源圖像疊加后經過淺層卷積提取圖像的特征,會導致融合后的圖像存在光譜或空間信息丟失,因此多尺度卷積神經網絡被提出[21]。此外,CNN網絡中的所有通道被平等對待,不能靈活地判別通道之間不同頻度的信息,而注意力機制網絡被證實能夠學習通道之間更深的相互依賴性[22-23]。
綜上所述,提出了一種基于多尺度殘差注意力網絡的遙感圖像全色銳化方法。先將LRMS圖像經過雙三次插值上采樣,與PAN圖像進行級聯作為輸入;設計3個不同的子網絡并行提取源圖像的高頻和低頻特征,每個網絡中包含多個含有殘差注意力機制的多尺度塊,一方面,可以使用不同的卷積核提取多尺度特征,另一方面,可以自適應地考慮通道信息特征,使融合圖像在包含較多光譜信息的同時保留更多的空間信息,處理過程包含淺層特征提取、深層特征提取、特征融合和特征重建;最后將3個子網絡的輸出結果進行級聯得到最終融合圖像。同時,將平均絕對誤差(mean absolute error,MAE)、光譜角映射(spectral angle mapper,SAM)和幾何梯度(geometric gradient,GG)作為一種新的損失函數來進行訓練,進一步改善融合效果。
1 多尺度殘差注意力網絡
多尺度殘差注意力網絡主要包含4個部分:淺層特征提取層、深層特征提取層、特征融合層和特征重建層,網絡框架如圖1所示。
1) 淺層特征提取層
淺層特征提取層以三層卷積神經網絡[24]為基礎,提取輸入圖像不同頻度的淺層特征,得到原始圖像不同角度的淺層特征圖。
2) 深層特征提取層
根據原始圖像結構特點,使用不同數量的多尺度殘差注意力模塊(multi-scale residual attention,MRA)進行深層特征提取,充分提取原始圖像不同頻度上的空間和光譜特征,準確地表示特征并全面重建HRMS,每個MRA包括2個部分:多尺度特征提取網絡和殘差通道-空間注意力網絡,結構如圖2所示。
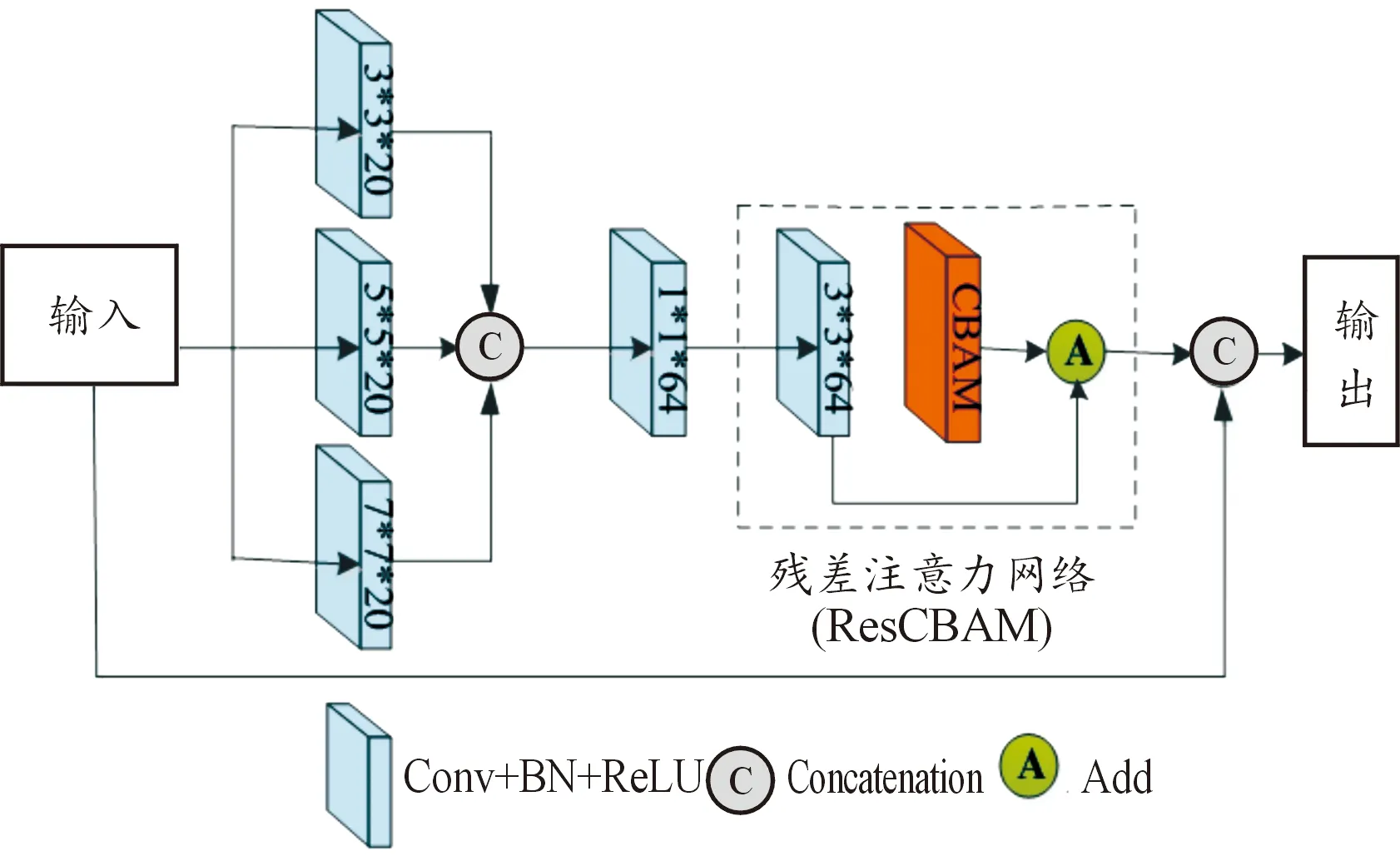
圖2 MRA多尺度殘差注意力模塊
在多尺度特征提取網絡部分,使用卷積核分別為3×3、5×5、7×7,步長為1,邊界填充值為0的卷積神經網絡提取輸入的特征圖中不同尺度的特征,每個尺度得到的特征數都是20。為了增強得到的特征,將多個尺度提取的特征進行級聯,經過一個卷積核為1×1,步幅為1,邊界填充值為0的卷積神經網絡后,輸出特征數為64。在殘差注意力網絡部分使用的注意力網絡是一種通道-空間注意力聯合的卷積鎖注意力機制(convolutional block attention module,CBAM)網絡[25],與其他的通道注意力網絡和空間注意力網絡相比,CBAM可以從通道和空間兩方面學習和表示圖像的特征。由于殘差網絡在計算機視覺和圖像處理領域表現出了顯著優越性,在使用CBAM注意力機制時,將CBAM和殘差網絡進行結合,用于保留更多重要的特征,如圖2中虛框所示,并且為了防止過擬合和特征丟失,每個MRA網絡中都使用了局部跳連接操作。
3) 特征融合層
特征融合層的任務是將多個MRA獲得的特征數進行級聯,并使用卷積神經網絡將級聯后的特征進行融合,減少參數量和保留更多重要的特征。
4) 特征重建層
在特征重建層,使用輸出特征數為原始圖像通道數的卷積神經網絡獲得包含不同頻度特征的HRMS圖像。
2 基于多尺度殘差注意力網絡的遙感圖像融合
2.1 具體的融合過程
為了充分保留原始圖像的空間信息和光譜信息,該算法使用了3個并行的多尺度殘差注意力網絡分別提取圖像不同級別的特征,將這3個子網絡分別表示為M1、M2、M3,其中M1提取輸入圖像的低頻特征,M2和M3提取輸入圖像的高頻特征,通過3個子網絡輸出結果的跳連接可以獲得最終融合圖像。基于多尺度殘差注意力網絡的遙感圖像全色銳化過程如圖3所示。
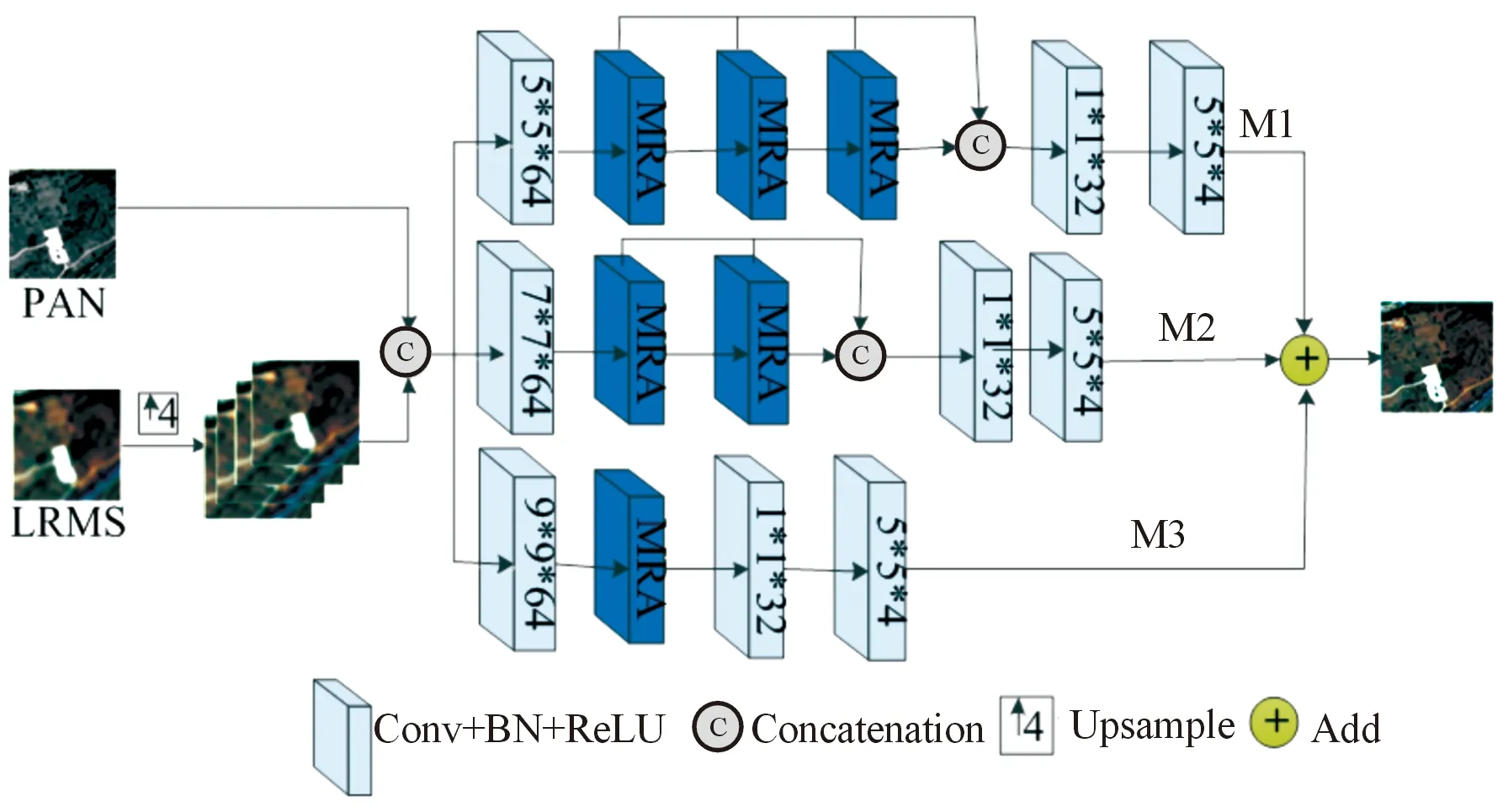
圖3 基于多尺度殘差注意力網絡的遙感圖像全色銳化
將LRMS圖像經過雙三次插值上采樣后與PAN圖像級聯,得到一個5通道圖像作為整個網絡的輸入,具體融合過程如下。
1)在淺層特征提取層,在M1、M2、M3中分別使用了卷積核為5×5、7×7、9×9,步長為1,邊界填充值為0的卷積神經網絡[26]實現淺層特征的提取,每個卷積神經網絡提取的特征數都是64。
2)在深層特征提取層,考慮到參數爆炸的問題,在M1中使用了3個MRA,在M2中使用了2個MRA,在M3中使用了1個MRA。
3)在特征融合層,將多個MRA獲得的特征數進行級聯,在M1、M2、M3 3個子網絡中分別使用卷積核為1×1,步長為1,邊界填充值為0,輸出特征數為32的卷積神經網絡將級聯后的特征進行融合,以減少參數量和保留更多重要特征。
4)在圖像重建階段,每個子網絡中使用相同的卷積核為5×5,步長為1,邊界填充值為0,輸出特征數為4(原始LRMS上采樣后的通道數)的卷積神經網絡獲得3個包含不同頻度的融合圖像。
5) 將每個子網絡獲得的不同頻度的HRMS圖像進行級聯,獲得最終的高空間分辨率多光譜圖像。
為了防止訓練過程中出現梯度爆炸和過擬合現象,整個網絡除了最后一層5×5的卷積神經網絡外,在每個卷積層的后面都加上了歸一化層,并且每一個卷積層使用的激勵函數都是Relu,由于殘差學習的優越性,該算法使用了多個短跳過連接和長跳過連接,以減少空間和光譜損失。
2.2 多尺度殘差注意力網絡的損失函數
損失函數是為了衡量目標圖像與生成圖像之間的誤差,為了更進一步改善圖像融合的效果,減少目標圖像與融合圖像之間的差異,選擇MAE、 SAM和GG作為損失函數來訓練網絡參數,與均方差(mean square error,MSE)相比,MAE收斂性能更好[26]。將參考圖像表示為I、融合圖像表示為F,所設計的損失函數如式(1)所示。
Lloss=αL1(I,F)+SAM(I,F)+βGG(I,F)
(1)
式中:L1表示MAE,其函數如式(2)所示,計算的是參考圖像和融合圖像之間的平均絕對誤差值,在實際計算時,α和β的取值各為0.5。
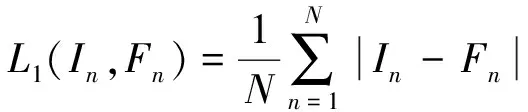
(2)
式中:N表示圖像的數量;|·|表示絕對值;In表示參考圖像;Fn表示融合后的圖像。
SAM是指目標圖像與生成圖像之間的光譜損失真度,計算的是在相同像素內融合圖像和參考圖像光譜向量之間的角度[27]。SAM的值與光譜失真度是正相關的關系,SAM越小,融合圖像的光譜失真率越低,當SAM的值為0時,則表示融合圖像沒有出現光譜失真的問題,是最理想的融合結果。SAM的計算如式(3)所示,在損失函數中引入SAM函數能使融合的圖像包含更多光譜信息。

(3)
幾何梯度GG表示融合圖像和參考圖像的幾何空間細節損失[28],用于改善融合圖像的空間失真,如式(4)所示。
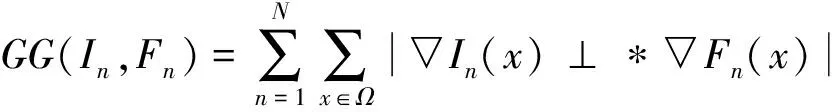
(4)
式中:N表示圖像的數量;Ω表示圖像的像素域;▽表示梯度計算。
3 實驗結果與分析
3.1 數據集的制作與參數設置
為了驗證該算法的有效性,采用WorldView-3和WorldView-2衛星數據進行實驗,并與其他算法進行比較。選擇WorldView-3數據中的3對LRMS圖像和PAN圖像,其中2對做訓練和驗證,1對做測試。同樣從WorldView-2數據中選取3對LRMS圖像和PAN圖像,2對做訓練和驗證,1對做測試。首先依據Wald’s協議分別對原始的LRMS圖像和PAN圖像進行下采樣[29],將原始的LRMS圖像作為參考圖像;其次將下采樣后的LRMS圖像進行雙三次插值與PAN圖像的分辨率保持一致;最后將獲得的上采樣后的LRMS圖像、PAN圖像、參考圖像裁剪為128×128的尺寸,將裁剪得到的數據集的70%作為訓練集,30%作為驗證集,并取與訓練圖像不同的另一對圖像數據,將其裁剪成400×400的小塊作為測試集。
使用Keras搭建網絡框架,在PyCharm上實現,并利用自適應矩估計(adaptive moment estimation,Adam)優化器對模型進行優化,學習率設置為0.000 1,beta1設置為0.9,beta2設置為0.99,Batchsize設置為8,超參數α=100,β=0.05。 實驗環境的配置是AMD和RTX2080TI。為了驗證所提算法的性能,將該算法與自適應施密特正交(gram-schmidt adapative,GSA)方法[30]、基于調制變換參數和高斯濾波的廣義拉普拉斯變換(modulation transfer function (MTF) matched filter,MTFGLP)方法[31]、GFPCA[32]、PNN[17]、高通濾波和殘差網絡結合的PanNet算法[33]、FusionNet[34]、ResTFnet[20]7種方法進行對比,并使用有參考評價指標SAM、空間相關系數(Spatial CC,SCC)[35]、全局融合誤差(ERGAS)[36]、峰值信噪比(PSNR)[37]和無參考評價指標Dλ、Ds與QNR[38]評價不同算法得到的融合圖像質量。SCC越高,說明融合圖像中包含的空間信息越多;ERGAS計算融合圖像和參考圖像之間的波段誤差,ERGAS值越小,說明融合圖像與參考圖像的差異越小,融合結果越好;PSNR計算融合圖像的最大峰值和2幅圖像的均方誤差的比值,PSNR值越大,融合圖像的失真程度越小;空間失真指數Dλ評估融合圖像和源全色圖像的空間差異;光譜失真指數Ds評估融合圖像和源多光譜圖像之間的光譜差異,兩者的值越小,融合圖像質量越高;QNR用來評估融合圖像總體的光譜和空間信息,數值越大,融合圖像質量越好,最大值是1。
3.2 融合實驗結果分析
圖4和圖5展示了不同的算法在低分辨率設置下得到的2種衛星圖像融合結果,(a)和(b)分別為原始的LRMS圖像與PAN圖像;(c)為GFPCA算法得到的融合結果;(d)為GSA算法得到的融合結果;(e)為MTFGLP算法得到的融合結果;(f)為PNN 算法得到的融合結果;(g)為PanNet算法得到的融合結果;(h)為FusionNet 算法的融合結果;(i)為ResTFnet 算法的融合結果;(j)為本文融合結果。

圖4 WorldView-2圖像融合結果

圖5 WorldView-3圖像融合結果
從圖4 WorldView-2數據集的融合結果看出,GFPCA的融合圖像清晰度較低(如紅色框所示),但包含的色彩信息較多;GSA和MTFGLP的融合圖像包含的清晰度較高,但是產生了光譜失真的現象;PNN得到的圖像包含的細節信息較多,但有顏色丟失的現象;PanNet得到的融合圖像保留了大量的顏色信息,但存在某些空間細節表現不足的問題,如圖中紅框所示建筑物的邊緣較本文的稍模糊;FusionNet的融合圖像較為模糊,存在顏色過飽和;ResTFnet融合結果的顏色和清晰度均表現不錯,但紅框中所示的建筑物存在顏色失真的問題。相比而言,本文方法得到的融合圖像包含了更多的空間細節和光譜信息。
圖5為各種融合方法在WorldView-3數據集上的融合結果,可以看出GFPCA的融合圖像較模糊(如圖中紅框所示);GSA和MTFGLP的融合圖像的清晰度較GFPCA算法高,但是產生了光譜失真;PNN得到的融合結果包含的細節較多,顏色接近自然色;PanNet得到的融合圖像顏色信息豐富,但依然存在局部空間細節保留不佳的問題,例如圖中大紅色框所示的建筑物和地表信息與本文相比,清晰度略顯遜色;FusionNet的融合圖像清晰度欠佳,但顏色信息較豐富;ResTFnet整體融合效果較好,但存在部分細節丟失。對比可見,本文方法得到的融合圖像在空間細節和光譜信息保持方面具有一定的優勢。
不同遙感圖像融合算法在WorldView-2數據集上得到的評價結果如表1所示。
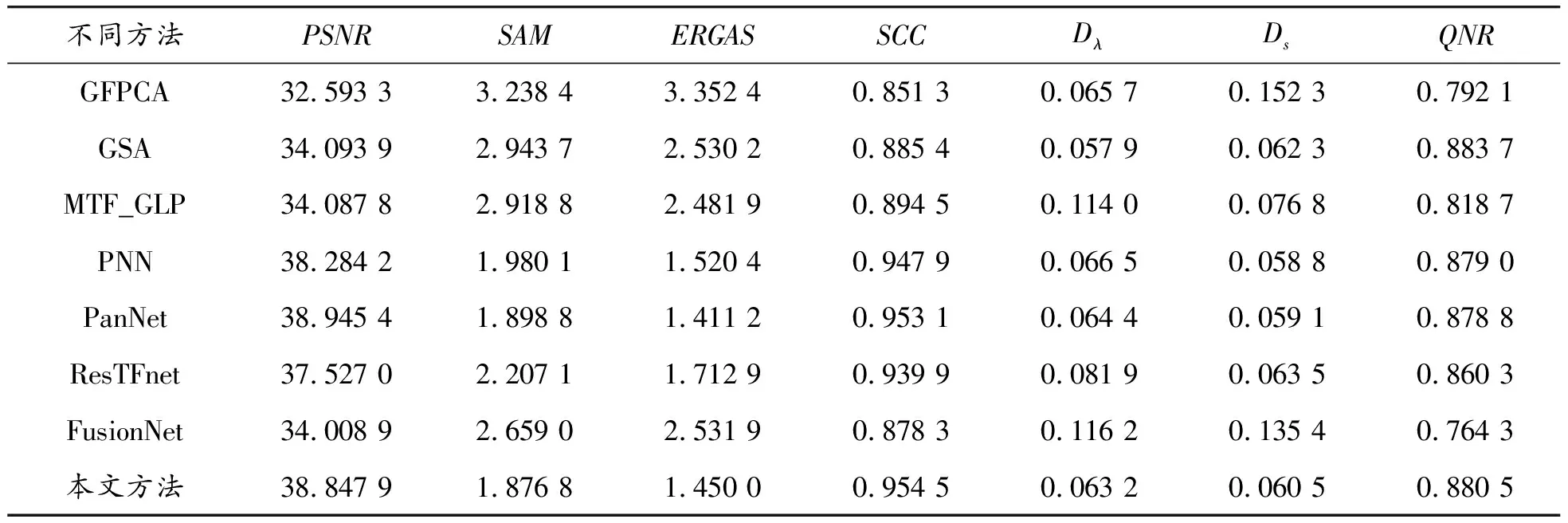
表1 WorldView-2數據集上的評價結果
由表1可知, 雖然PanNet在PSNR和ERGAS上獲得的評價結果優于其他深度學習的遙感圖像融合方法,但是本文方法在表征光譜信息和空間信息的評價指標SAM、SCC上表現最好,Dλ評價結果也優于其他深度學習方法,僅次于GSA。客觀驗證了本文方法在WorldView-2遙感圖像融合方面能夠保留較多源圖像的光譜信息和空間信息。
為了進一步驗證該方法的有效性,表2給出了不同遙感圖像融合算法在WorldView-3數據集上的客觀評價結果。
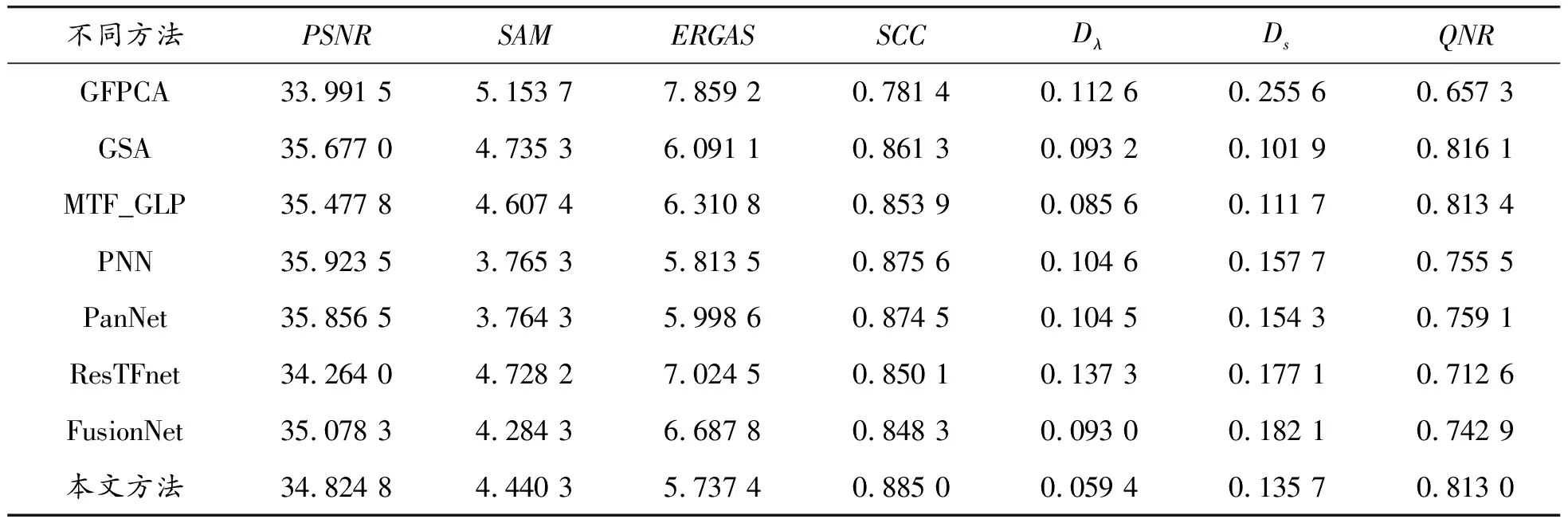
表2 WorldView-3數據集上的評價結果
從表2的評價結果可以看出,本文方法在ERGAS和SCC上獲得的融合圖像評價結果最好,說明本文方法在遙感圖像融合過程中保留了更多源圖像的空間特征。在無參考評價指標中,本文方法的Dλ和Ds值小于其他的深度學習算法,說明本文得到的融合圖像包含的顏色信息和紋理信息多于其他對比的深度學習融合方法,本文的QNR值高于其他深度學習融合算法,說明融合質量高,客觀地證明了該方法能夠在WorldView-3全分辨率圖像融合中保留更多光譜信息和空間信息。
3.3 損失函數及模型優越性分析
為了測試模型和損失函數的性能,在WorldView-3數據集上分別對不同的注意力機制模型和損失函數進行了實驗分析,評估結果如表3所示。使用平均絕對誤差MAE作為損失函數進行評估,記為L1;在MRA中使用通道注意力機制壓縮-激勵(squeeze-and-excitation,SE)網絡[22]和CBAM[25],分別記為SE和CBAM,并與本文方法進行比較。

表3 不同損失函數和網絡結構的融合結果
從表3中可以看出,使用本文的損失函數訓練網絡結構所得到的融合結果,除了Ds一項指標外,其他指標均優于L1、SE和CBAM,說明改進的損失函數提高了網絡性能,獲得了更好的融合效果,而且在遙感圖像全色銳化時使用殘差網絡與CBAM結合比單獨使用SE和CBAM獲得的融合圖像效果要好,證明了殘差注意力網絡可以提高圖像的特征表達能力,使融合圖像包含更多的光譜信息和空間信息,減少顏色畸變和空間細節丟失的現象。
4 結論
提出了一種基于多尺度殘差注意力網絡的全色圖像和多光譜圖像融合方法,有效改善了傳統基于深度學習的全色銳化方法導致的空間信息丟失和光譜信息失真的問題。該網絡由3個并行的多尺度殘差注意力網絡構成,分別提取源圖像不同頻度的特征信息;殘差注意力多尺度模塊的引入,保證了從空間和通道兩方面提取更多源圖像的特征,使融合圖像包含較多光譜信息和空間信息。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
