基于權重詞向量與改進TextCNN的中文新聞分類
2023-09-15 03:34:06黃樹成
軟件導刊 2023年9期
萬 錚,王 芳,黃樹成
(江蘇科技大學 計算機學院,江蘇 鎮(zhèn)江 212114)
0 引言
文本分類是自然語言處理領域的一項基礎且重要的任務,在新聞推薦、搜索引擎、垃圾郵件檢測等方面都有著重要應用。盡管文本分類已經有著多年的發(fā)展歷史,但仍存在著一些不足之處。目前文本分類仍是自然語言處理領域研究的一個熱點問題。文本分類是指通過一定的算法,給輸入的文本分配一個或多個預先設定好的標簽[1]。若只為每個文本分配一個標簽,則稱為單標簽文本分類;若為每個文本分配一個及以上的標簽,則稱為多標簽文本分類。
隨著信息技術的快速發(fā)展,人們進入了一個信息爆炸的時代,互聯網已經成為人們日常生活中獲取信息的主要途徑之一。其中絕大部分信息都是以文本形式存在的,面對著鋪天蓋地的文本信息,光靠人力維護是不可能的。那么如何通過機器自動將這些文本信息進行分類以方便人們更好地獲取,成為當下的一個研究難題。人們最先把機器學習方法用于文本分類,如改進的TF-IDF、支持向量機[2]、樸素貝葉斯[3]等。傳統(tǒng)的機器學習分類方法將整個文本分類問題拆分成特征工程和分類器兩部分。特征工程分為文本預處理、特征提取、文本表示3 部分,最終目的是把文本轉換成計算機可理解的數字,并封裝足夠用于分類的信息,再進行分類[4]。雖然這些方法在一定程度上解決了文本分類問題,但仍存在著一些弊端。這些方法過于依賴人工設計的特征,并且對于文本的表示還存在數據稀疏和特征向量緯度過高的問題,對于網絡新聞中出現的大量新詞不能很好地表示其語義特征。
隨著深度學習技術的不斷發(fā)展,涌現出越來越多性能良好的深度學習模型。這些模型不僅能很好地解決傳統(tǒng)機器學習方法存在的數據稀疏和特征向量維度過高的問題,而且準確度也明顯提升。但是單一的深度學習模型也有其局限性,如TextCNN 只關注到了局部信息,而往往會忽略掉全局語義,造成分類效果不佳。基于此,本文提出一種混合多神經網絡的BA-InfoCNN-BiLSTM 模型。
1 相關工作
若想要讓計算機處理語句或文檔,首先需要將這些語句或文檔轉換成數字,將字或詞轉換為向量的過程稱為詞嵌入。最開始采用One-Hot 編碼,用于判斷文本中是否具有該詞語。后來發(fā)展成根據詞語在文本中的分布情況對詞進行表示。近年來,隨著深度學習的發(fā)展,直接推動了詞嵌入技術的變革,使得分布式的詞語表達得到了大量使用。分布式表示可以克服獨熱表示的缺點,解決了詞匯表示與位置無關的問題。分布式表示通過計算向量之間的距離(歐氏距離、余弦距離)體現詞與詞之間的相似性。Bengio 等[5]最早使用神經網絡來構建語言模型。2013 年,Mikolov 等[6]提出一種淺層神經網絡概模型Word2Vec,其包括Continuous Bag-of-Words[7]和 Skip-Gram[8]兩種模型訓練方法,通過分布式假設(如果兩個詞的上下文是相似的,其語義也是相似的)直接學習詞的詞向量,同時為了減少輸出層的計算量,使用層次softmax 和負采樣對其進行優(yōu)化。但該方式只考慮了文本的局部信息,未能有效利用整體信息。針對此問題,Pennington 等[9]提出全局詞向量(Global Vectors,Glove)模型,同時考慮了文本的局部信息與整體信息。但無論是Word2Vec 還是Glove,本質上都是一種靜態(tài)的詞嵌入方式,無法解決一詞多義的問題。2018年,谷歌提出的BERT 模型解決了一詞多義的問題[10]。BERT 模型通過聯合調節(jié)所有層中的左右上下文來預訓練未標記的文本深度雙向表示,此外還通過組裝長句作為輸入,增強了對長距離語義的理解。
在捕獲文本特征方面,Hochreiter 等[11]提出的長短時記憶神經網絡解決了梯度爆炸和梯度消失問題;Kalchbrenner 等[12]提出動態(tài)卷積神經網絡模型處理長度不同的文本,將卷積神經網絡應用于NLP;Kim[13]提出文本分類模型TextCNN,該模型結構更簡單,利用多個大小不同的卷積核提取文本中的特征,然后對這些不同粒度的特征進行池化操作,從而得到更準確的局部特征;陳珂等[14]利用多通道卷積神經網絡模型,從多方面的特征表示學習輸入句子的文本信息;Long 等[15]將雙向長短時記憶網絡與多頭注意力機制相結合對社交媒體文本進行分類,克服了傳統(tǒng)機器學習中的不足。本文在前人研究的基礎上,通過融入前文信息對傳統(tǒng)的TextCNN 作出了改進。
2 模型設計
本文提出的BA-InfoCNN-BiLSTM 模型通過在詞嵌入層后加入注意力機制進行殘差連接來提升重要詞的比重,再通過改進的卷積神經網絡與雙向長短時記憶網絡分別提取局部和全局特征,最后將特征進行融合后用于分類。模型整體結構如圖1 所示,由輸入層、BERT 嵌入層、權重詞向量層、改進的卷積層、雙向長短時記憶網絡層和輸出層組成。
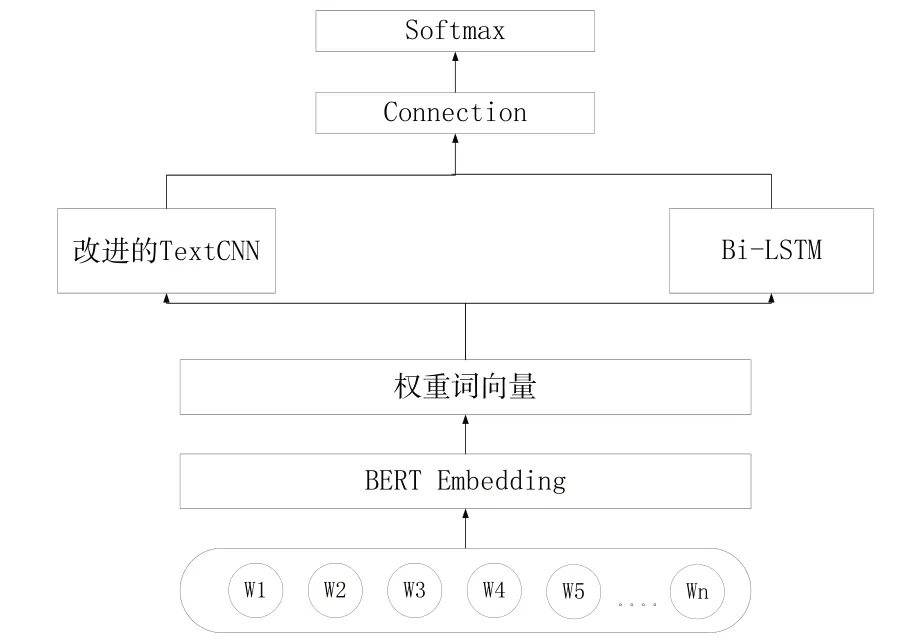
Fig.1 BA-InfoCNN-BiLSTM model structure圖1 BA-InfoCNN-BiLSTM 模型結構
2.1 詞嵌入層
本模型嵌入層的目的是將文本轉化為詞向量,首先需要解決的問題就是分詞。對于英文文本,單詞與單詞之間本就以空格隔開,所以英文文本不需要進行額外的分詞操作。與英文文本不同的是,中文文本是由字構成,字本身就可以表達出一定的含義,而字與字之間又可以組成詞,表達出新的語義。如今兩種比較流行的分詞方式是:一是像英文文本分詞那樣,以字為粒度,直接將文本中的字映射為一個向量,這種做法雖然方便,但是往往會割裂文本中字與字所組成的詞的意思;二是利用像Jieba 這樣的分詞工具先對文本進行分詞,再將得到的詞轉化為詞向量,但這種方式存在著更嚴重的弊端,因為分詞的好壞會在很大程度上影響最后的分類結果。
如今的分詞工具對于陌生詞的分詞效果較差,在專業(yè)名詞上更是嚴重依賴于用戶構建的詞典,并且對長詞的分詞效果較差。而新聞標題中往往會產生大量新詞,嚴重影響分詞的正確性,從而干擾最后的分類效果。因此,模型使用基于字粒度的詞嵌入方式來彌補該弊端。BERT 的中文版本正是以字為單位進行嵌入的,十分適合作為嵌入層。BERT 的兩大功能分別是預訓練和微調。預訓練有兩大任務:一是掩碼語言模型,即隨機遮掩一部分詞,然后讓模型預測這些詞;二是下一句預測,即判斷兩個句子之間是否有上下文關系來增強模型對句子的理解能力。微調則是在進行下游任務時,模型不斷調整其參數的過程,但由于BERT 的結構是由12 個Transformer 編碼器構成,計算量較大,十分消耗時間,所以本實驗過程中并沒有選擇進行微調,而只是使用在大規(guī)模語料上預訓練過的BERT 模型參數完成字到詞向量的轉換。設有文本T={t1,t2,t3...tn},文本長度為n,將其送入BERT 模型,得到該文本的詞向量矩陣E={e1,e2,e3...en}。矩陣大小是n*d,其中d 是每個字的維度。然后將BERT 生成的矩陣E作為注意力層的輸入。
2.2 權重詞向量層
本模型在BERT 之后引入注意力機制。注意力機制最早是由Bahdanau 等提出的,用于模擬人腦的注意力模型,最早用于圖像處理方面。Vaswani 等[16]提出的Transformer便是基于自注意力機制獲得單詞間的長距離依賴關系。本模型之所以在嵌入層后引入注意力機制,是由于在嵌入層中只使用了BERT 在其他語料上預訓練得到的詞向量。但是為了避免大量運算,在實驗過程中并沒有進行微調,沒有發(fā)揮BERT 中自注意力機制的作用,而在新的語義環(huán)境中,每個詞在新聞標題中的重要程度也會有所不同。所以在得到詞向量之后,需要通過注意力機制對字詞權重重新進行分配,以體現不同詞對文本全局語義特征的重要程度。注意力分數計算如式(1)所示。其中,Wa是可訓練參數,ba是偏置項,tanh 是激活函數,va是可學習的上下文向量。at是經過softmax 函數后得到的ei的權重(見式(2)),然后將每個詞向量加權后進行殘差連接得到si(見式(3)),最后將得到加權的詞嵌入矩陣S={s1,s2,s3...sn}分別送入改進的卷積層和Bi-LSTM 層。
2.3 改進的卷積層
在注意力機制之后引入改進的TextCNN 來提升模型對特征的捕捉能力。TextCNN 能夠通過使用不同大小的卷積核實現對N-Gram 特征的提取,從而獲取到不同層級的語義特征。但其短板是TextCNN 通過卷積只能獲得文本的局部依賴關系,而忽視了遠距離語義的影響。所以針對該問題,本模型對TextCNN 的卷積層進行了一些改進。從整體上而言,對語義的理解是以從左到右的順序進行的,所以進行卷積操作的詞之前的文本信息是十分重要的。為解決TextCNN 只關注局部信息的問題,在進行卷積操作的過程中,通過不斷融入前文信息來提升模型性能。InfoCNN 過程如圖2所示。
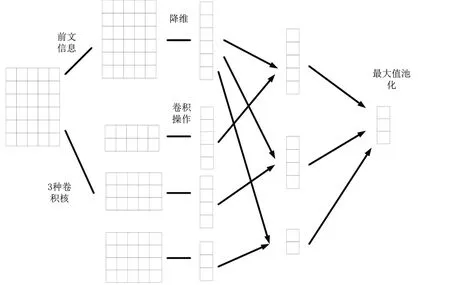
Fig.2 InfoCNN process圖2 InfoCNN過程
首先根據詞向量矩陣S={s1,s2,s3...sn}生成其前文語義矩陣R={r0,r1,r2...rn},如式(4)所示:
其中,r0為零向量,然后用全連接層進行降維,得到前文信息向量G={g0,g1,g2...gn}。接著再用窗口大小為2、3、4 的卷積核W 進行卷積操作,每次卷積操作得到特征ci,提取局部特征的公式如式(5)所示:
其中,h為卷積核Wh滑動窗口的大小,卷積核Wh的大小是h*d,d是詞向量維度。Si:i+h-1為從S中第i行到i+h-1行的局部文本矩陣,bh為偏置項,f代表非線性激活函數。最后,結合提取的局部特征和前文信息特征,最終得到的卷積結果ui如式(6)所示:
最后,在得到的結果U中,采用最大值池化策略獲取每個通道的最大值,將這些值送入最后的輸出層。
2.4 BiLSTM 層
由于循環(huán)神經網絡特別適合處理序列數據,已被成功應用于自然語言處理等眾多時序問題中。為了能有效解決傳統(tǒng)循環(huán)神經網絡的梯度消失或爆炸問題,本模型使用Bi-LSTM 對BERT 和注意力機制得到的權重詞向量矩陣進行特征提取。長短時記憶網絡結構如圖3所示。
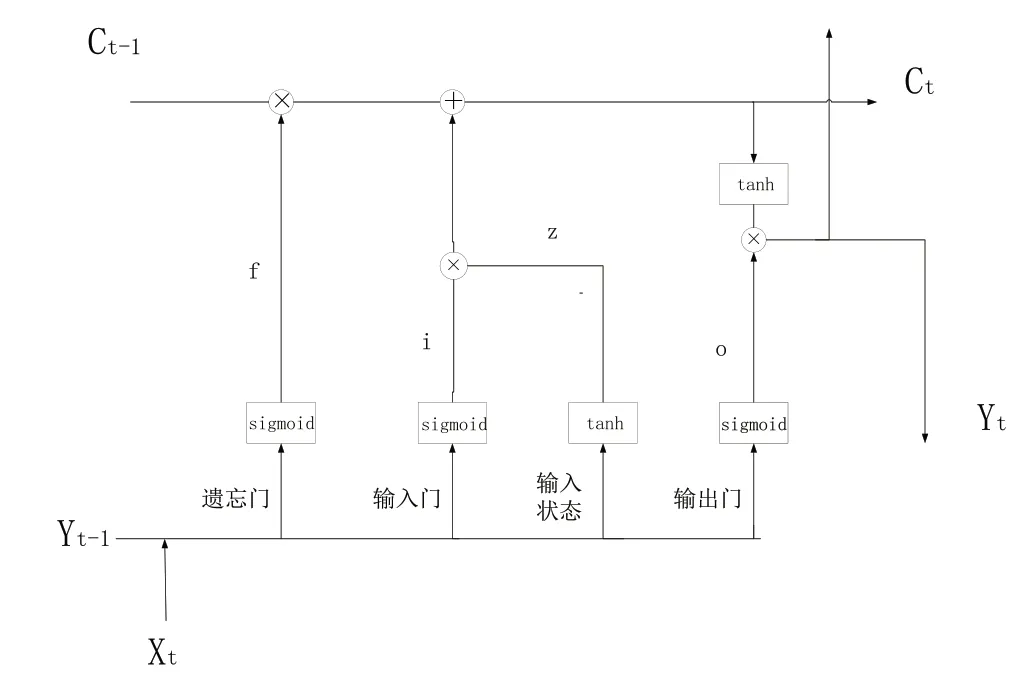
Fig.3 LSTM structure圖3 LSTM 結構
該網絡有3 個門:一是遺忘門,用來控制上一時刻Ct-1保存到當前時刻Ct的特征信息,如式(7)所示;二是輸入門,其控制了此時網絡的輸入Xt保存到當前時刻Ct的特征信息,計算方式如式(8)、式(9)所示;三是輸出門,用來控制當前時刻Ct的輸出值Yt,計算方式如式(10)—式(12)所示:
但由于長短時記憶網絡當前時刻的輸出信息是由前一時刻的輸出信息和當前時刻的輸入信息共同決定的,即當前時刻的輸出信息只考慮了該時刻與該時刻之前的信息,而沒有考慮該時刻之后的信息,沒有充分利用上下文信息。為了解決這一問題,Graves 等[17]提出雙向長短時記憶網絡。雙向長短時記憶網絡通過正向和逆向的LSTM 獲得第t時刻正向隱藏層狀態(tài)向量Ylt與逆向隱藏層狀態(tài)向量Yrt,并將Ylt和Yrt拼接起來作為最終的隱藏層狀態(tài)向量Yt,該向量包含了上下文信息。計算方式如式(13)所示:
2.5 輸出層
模型最后的輸出層是把改進的卷積層得到的結果與Bi-LSTM 層得到的結果進行拼接融合,然后引入全連接層進行降維,之后用Dropout 方法讓降維后的特征向量以一定的概率失活,從而避免出現過擬合現象。最后送入softmax函數[18]進行分類,得到最終的預測結果。
3 實驗與分析
3.1 實驗數據集
為了驗證本模型在新聞主題文本分類任務上的有效性,本文使用兩個以新聞為主題的數據集進行實驗,如表1所示。

Table 1 Data set information表1 數據集信息
(1)新浪新聞數據集。新浪新聞數據集中的數據來自于新浪新聞2018—2022 年間產生的新聞標題。通過收集這些新聞標題,然后經反復篩選壓縮及過濾后,整理生成新浪新聞數據集。該數據集共包含20 萬條短文本,分為電子競技、地產、體育、股市、科學、財經、時事、教育、政治、明星10個類別,每類包含2萬條數據。
(2)搜狐新聞數據集。通過網絡開源搜狐新聞數據集進行數據清洗,去除部分缺少標簽的數據,并去除新聞內容,只保留新聞主題。數據集包含旅游、電子競技、地產、軍事、體育、股市、科學、財經、時事、教育、政治、明星共 12個類別。
3.2 實驗設置
(1)實驗環(huán)境。本實驗在PyCharm 上進行代碼編寫,編程語言選擇Python 3.7 版本,深度學習框架選擇Pytorch 1.1 版本,CPU 型號為AMD EPYC 7302 16-Core Processor,內存為252GB,GPU 型號為GeForce RTX 3080,顯存為10GB。
(2)實驗參數。由于模型使用BERT 的中文版本進行詞嵌入,所以詞向量的維度設為768。卷積層中使用3 種大小不同的二維卷積核,卷積核的高度分別為2、3 和4,卷積核寬度與詞向量維度相同,每種卷積核的數量為256。BiLSTM 層中的隱藏單元個數為128,dropout 的參數大小設置為0.1。每次訓練的批次batch_size 大小為128,學習率大小為0.000 5,每句話的最大長度為32,epoch 數為3。
3.3 實驗結果與分析
本文將BA-InfoCNN-BiLSTM 模型與當前較流行的幾種分類方法進行了比較。
(1)TextCNN。由Kim[13]提出的TextCNN 在CNN 概念的基礎上,讓卷積核寬度與詞向量維度保持一致進行特征提取,然后拼接最大值池化后的特征,最后送入softmax 函數進行分類。
(2)TextRNN。由Liu[19]提出的TextRNN 在LSTM 概念的基礎上,取單向LSTM 最后一個時間步的隱藏層狀態(tài)向量作為新聞標題的語義表示,然后將該向量送入softmax 函數中進行分類。
(3)DPCNN。由Johnson 等[20]提出的一種通過增加卷積神經網絡的深度來獲取長距離語義關系的模型。
(4)FastText。Facebook 于2016 年開源的一種文本分類方法,FastText 在保證與CNN 和RNN 等深層網絡同等準確率的基礎上,提升了訓練速度。
(5)Att-BiLSTM。通過在雙向長短時記憶網絡后引入注意力機制,對雙向長短時記憶網絡提取的特征分配不同權重,從而突出重要詞的作用。
(6)BERT。BERT 是一個多層雙向的Transformer Encoder 模型,主要分為兩個階段:預訓練和微調。在預訓練階段,模型會在大量沒有標注的語料上進行訓練;在微調階段,模型會對預訓練得到的參數進行初始化,然后在進行下游任務過程中對參數進行調整。
本文使用準確率作為評估指標,實驗結果如表2、圖4所示。
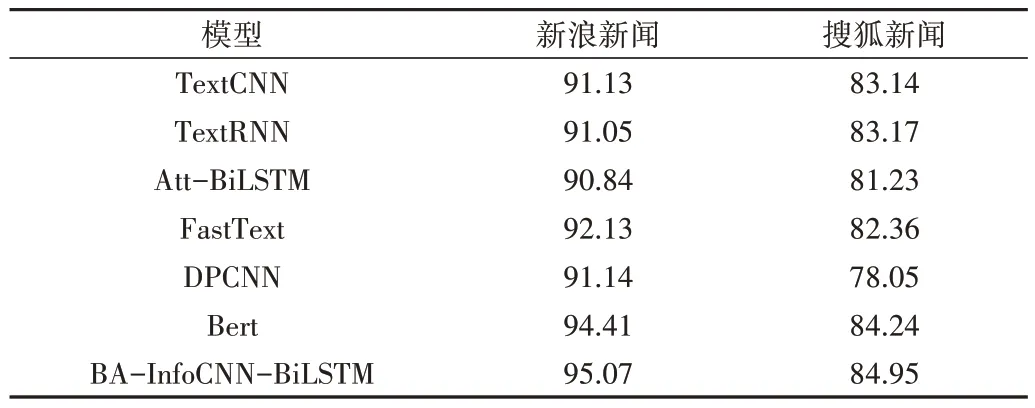
Table 2 Accuracy表2 準確率 %
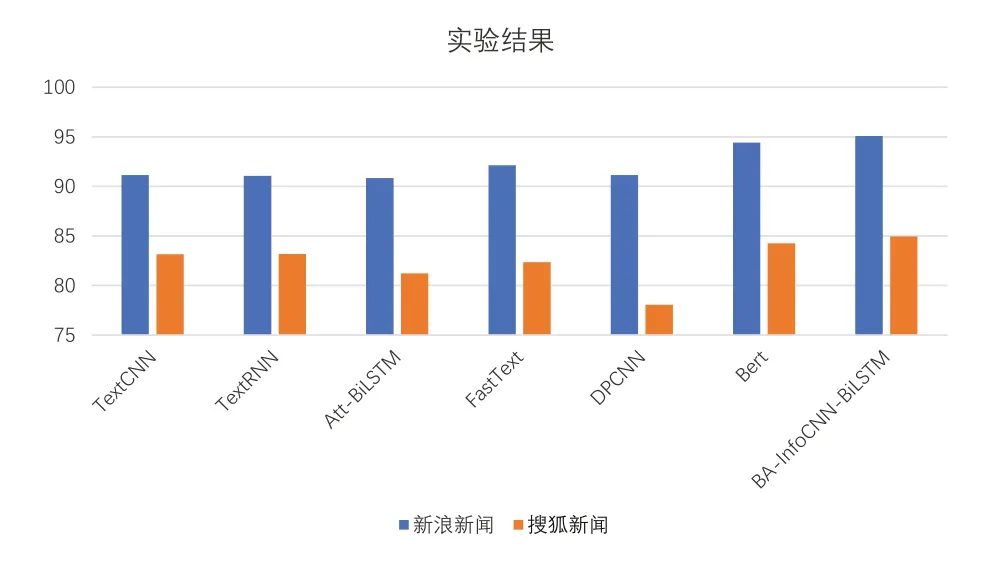
Fig.4 Experimental results圖4 實驗結果
BA-InfoCNN-BiLSTM 模型在新浪新聞數據集和搜狐新聞數據集上分別獲得了95.07%與84.95%的準確率。與前6 個模型相比,BA-InfoCNN-BiLSTM 模型取得了最好的效果。與6 個模型中效果最好的Bert 模型相比,BA-Info-CNN-BiLSTM 模型在新浪新聞數據集上的準確率提升了0.66%,在搜狐新聞數據集上的準確率提升了0.71%,從而證明了BA-InfoCNN-BiLSTM 模型通過在詞嵌入后加入注意力機制補充詞的重要程度,再分別捕獲多粒度下的局部信息和全局語義信息,可以有效提升模型的準確率。
3.4 消融實驗
為了驗證BA-InfoCNN-BiLSTM 模型中不同組件對于模型的有效性,本文通過消融實驗進行驗證。BA-BiLSTM為原模型中去掉了改進TextCNN 層的模型,僅將BiLSTM最后一個時間步的隱藏狀態(tài)向量作為全局語義特征用于分類輸出。BERT-InfoCNN-BiLSTM 為原模型中去掉了注意力機制的模型,在嵌入層后使用改進的TextCNN 層和BiLSTM 層分別捕捉局部與全局特征,將兩種特征融合后輸出。BA-InfoCNN 為原模型中去掉了BiLSTM 層的模型,使用改進的TextCNN 層捕捉多個粒度下的局部語義特征并將其用于分類,同時將輸出改為直接輸出。BA-CNNBiLSTM 為了去掉原模型中對TextCNN 的改進部分,使用融合后的結果用于分類。消融實驗結果如表3所示。
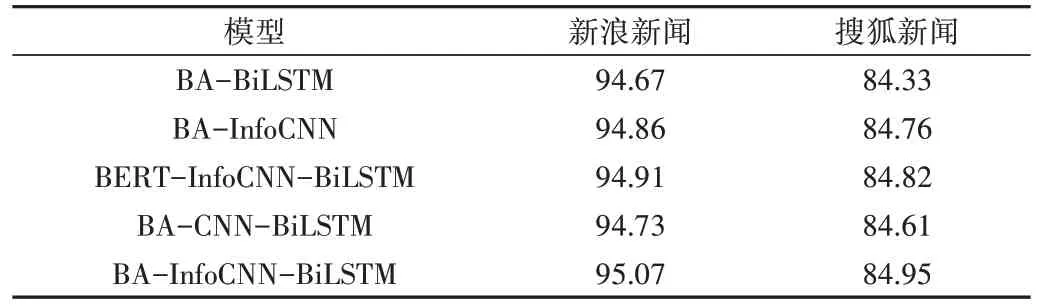
Table 3 Ablation experiment results表3 消融實驗結果 %
首先將BA-BiLSTM 的實驗結果與本文提出的BA-InfoCNN-BiLSTM(以下簡稱BAIB)進行對比,在兩個數據集上BAIB 的效果都明顯優(yōu)于BA-BiLSTM,說明提取局部信息對分類結果有一定影響。將BA-InfoCNN 的實驗結果與BAIB 相比,BAIB 的效果要優(yōu)于BA-InfoCNN,說明BiLSTM能夠有效提取全文信息特征,提升模型效果。BAIB 去除注意力機制之后的效果也不如BAIB,說明使用注意力機制凸出詞在句子中的重要性對于提升分類效果也是很有必要的。最有意義的是,將沒有改進的BAA-CNN-BiLSTM 融合模型與BAIB 進行比較,發(fā)現融入前文信息的卷積網絡分類更準確,模型對文本語義的理解更充分。
4 結語
本文提出的文本分類模型BA-InfoCNN-BiLSTM 通過融合改進的卷積神經網絡和循環(huán)神經網絡,解決了傳統(tǒng)的單一深度學習網絡提取信息不充分、分類效果差的問題。相比于其他融合模型,本模型直接在詞嵌入后加入注意力機制,生成權重詞向量,突出重要詞對整體語義的影響,然后分別送入卷積神經網絡和循環(huán)神經網絡,同時對卷積神經網絡進行了改進。在進行卷積操作過程中融入部分前文信息,讓卷積神經網絡不再僅關注局部信息。最終的實驗結果表明,該方法對分類的準確率有一定提升。接下來為了使模型得到進一步優(yōu)化,可以從以下方面入手:考慮到文本進行分類時,文中存在較多干擾信息以及一些專業(yè)性較強的名詞,可以在詞向量動態(tài)訓練過程中加入對抗擾動,以進一步提升生成的新聞文本詞向量的魯棒性以及表征能力。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
