
基于預訓練模型的命名實體識別研究
2023-09-18 18:55:23胡叮叮張琛王之原
現代信息科技 2023年15期
胡叮叮 張琛 王之原
摘? 要:目前中文命名實體識別存在的主要的問題有:實體的邊界模糊,實體邊界和非實體之間也存在邊界模糊問題,并且在小數據集下模型識別效果不明顯。為了解決以上問題,通過加強對文本上下文語義特征的提取能力,使模型能夠根據上下文語義特征來精準地推測出實體,提出一種BERT_BiLSTM_CRF的模型,BERT可以根據文本上下文信息,使每個詞在文本語義中對應一個低緯的稠密的詞向量,BiLSTM可以捕獲時序特征,并且使用CRF來對輸出標簽的順序進行約束。經實驗表明,使用預訓練模型獲取的動態詞向量比隨機初始化的詞嵌入有顯著提高。
關鍵詞:預訓練模型;命名實體識別;動態詞向量;BiLSTM;CRF
中圖分類號:TP391.1;TP183 文獻標識碼:A 文章編號:2096-4706(2023)15-0078-05
Research on Named Entity Recognition Based on Pre-training Model
HU Dingding, ZHANG Chen, WANG Zhiyuan
(Gansu University of Political Science and Law, Lanzhou? 730070, China)
Abstract: The main problems in Chinese named entity recognition are the boundary of entities is blurry, the boundary between entity boundary and non-entity is also blurry, and the recognition effect of small data set model is not obvious. In order to solve the above problems, by strengthening the extraction ability of semantic features of the text context, this paper makes the model can accurately infer the entity according to the context semantic features, and proposes a BERT _BiLSTM_ CRF model. According to the text context information, BERT can make each word in the text semantic to correspond to a dense word vector at low latitude. BiLSTM can capture temporal features, and use the CRF to constraint the order of output labels. The experiments show that the acquired dynamic word vector by using the pre-training model improves significantly over the randomly initialized word embedding.
Keywords: pre-training model; named entity recognition; dynamic word vector; BiLSTM; CRF
0? 引? 言
隨著互聯網技術的蓬勃發展,網絡上產生了海量的數據,同時這些海量的數據又促進了數據處理技術的發展。以文本為信息載體的數據形式,即自然語言,在網絡數據中占據一定的比例。研究如何自動化地從這些文本數據中挖掘出有價值的信息,是自然語言處理的一個熱門方向。命名實體識別任務研究如何從文本中自動化地將實體提取出來的一門技術,主要是識別出文本中的人名,地名,機構名等,對下游任務的進行起到基礎性的作用,比如知識圖譜的構建。命名實體作為自然語言處理的上游任務,其抽取的準確率對于后續的文本處理任務具有重要的意義。
命名實體識別[1]任務中最基礎的一步是文本向量表示,一個好的文本向量表示是下游任務的關鍵。文本向量表示最簡單的方式是獨熱編碼(one-hot),但其僅可以獲得詞頻和詞共現的特征,丟失了文本時序信息。隨后Bengio [2]等人2003年提出神經網絡語言模型,通過高維空間連續稠密的詞向量解決one-hot編碼中稀疏的問題,神經網絡獲得更好的泛化能力。并且首次提出詞向量的概念。詞向量的引入解決了統計語言模型部分相似性的問題,為后續NLP(Natural Language Processing)詞向量時代的發展做了鋪墊。但是作為早期的文本表示方法,依然存在一些問題,比如訓練時間長、學習出的詞向量效果一般等。隨后Word2Vec[3]出現,在經過大量的中文語料進行無監督的學習,最終得到的詞向量具有一定的通用性,但Word2Vec是一種靜態的詞向量,Word2Vec無法應對靈活多變的中文多義詞情況,此種情況下對文本的理解會產生歧義,從而導致命名實體識別的識別效果不夠準確。
2018年,預訓練語言模型BERT [4]橫空出世,學者們將BERT應用于NLP各項任務,比如文本分類任務[5]、序列標注任務[6]等,因其可以根據文本上下文動態地表示詞向量,解決了一詞多義問題。Wen等人[7]在中醫中使用BERT進行了實體識別,證明了預訓練的語言模型在中醫文本的命名實體識別任務中的有效性。
本文使用BERT作為命名實體識別的詞向量表示模型。在模型特征提取過程中使用BiLSTM模型,其由兩個單向的長短時記憶神經網絡(Long Short-Term Memory, LSTM)組成,最終形成的詞向量作為該詞的最終特征表達。這種神經網絡結構模型對文本特征的提取效率和性能要優于單個LSTM結構模型。由于CRF(Conditional random field)[8]可以對輸出序列的順序進行約束而被廣泛用于序列標注任務中,本文在模型的最后加上CRF作為模型最終的輸出,進一步提高輸出序列的精度。經過實驗驗證,本文提出的模型在命名實體識別任務上較其他模型的精度有所提高。
1? 相關技術
1.1? 詞向量
詞向量主要有靜態詞向量和動態詞向量。靜態詞向量最典型且使用最廣泛的是Word2Vec,雖然在各個領域上具有一定的通用性,但其無法解決一詞多義問題,即一個詞只對應一個固定的向量,而現實情況是,根據不同的語境,同一個詞會有多種含義,使用靜態詞向量就會導致無法正確理解文本的含義。而動態詞向量,顧名思義,是可以根據文本上下文信息來動態地表示每個詞在文本中的意思。例如“我喜歡蘋果”這句話,如果沒有下文,“蘋果”一般會被認為是一種實體,但是接了下文,比如“像素高”,“蘋果”和“像素高”產生了關聯,那么“蘋果”對應的詞向量表示會大不一樣。而靜態詞向量,即一個詞只能有一個固定的含義,而現實情況是,中文在不同的語境下有多種含義,靜態詞向量容易產生歧義。而動態詞向量是通過周圍詞的關聯來確定的,就不存在多義詞問題,獲取動態詞向量的方式主要介紹兩種:隨機初始化的Embedding和預訓練模型。
隨機初始化Embedding,主要的實現過程是先統計出整個語料所有不同字的字數為n,并且預先設定每個字以多少維度的向量表示,假設以d維向量表示每個字,隨機初始化一個二維的矩陣H n×d,H相當于一個詞表,通過梯度下降,更新這個詞表。假設Embedding層的輸入形狀為b×m(b為batch_size,m是序列的長度),則輸出的形狀是b×m×d。
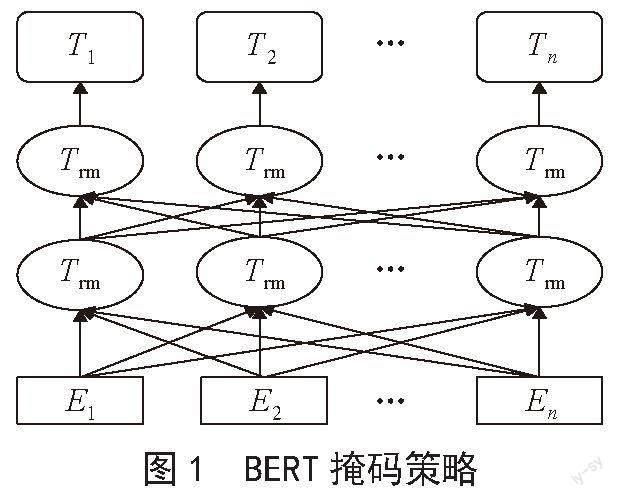
預訓練模型是設計較為復雜的神經網絡模型,由雙向的Tranformer的encoder組成,整體是一個自編碼語言模型,從損壞的輸入數據中預測重建原始數據,核心技術就是自注意力機制[9],如圖1所示。第一個任務是采用MaskLM的方式來訓練語言模型,思路是在輸入一句話,隨機地選15%的進行掩蓋,用一個特殊的符號[mask]來代替被掩蓋的詞,然后讓模型根據所給的標簽去預測這些被掩蓋的詞。第二個任務是在雙向語言模型的基礎上增加了一個句子級別的連續性預測任務,即預測輸入BERT的兩段文本是否為連續的文本,引入這個任務可以更好地讓模型學到連續的文本片段之間的關系。BERT相較于原來的RNN、LSTM可以做到并發執行,同時提取詞在句子中的關系特征,并且能在多個角度提取關系特征,進而更全面反映句子語義。相較于Word2Vec,其又能根據句子上下文獲取詞義,從而避免歧義出現。BERT作為一種預訓練模型,在特定場景使用時不需要用大量的語料來進行訓練,節約時間效率高效,泛化能力較強,在小數據集下通過微調,也能夠取得不錯的效果。BERT是一種端到端的模型,不需要調整網絡結構,只需根據下游任務在最后加上特定的輸出層即可。
1.2? BiLSTM模型
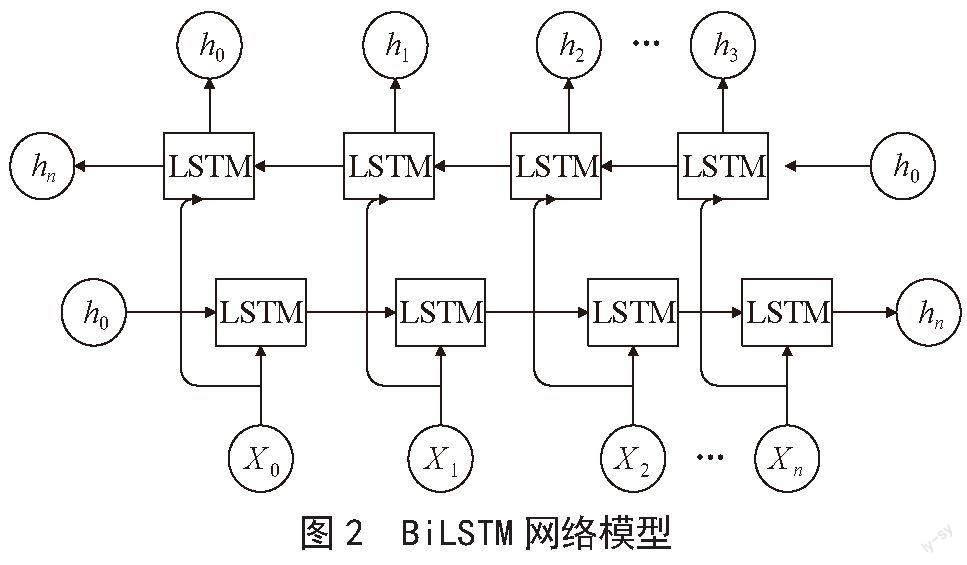
長短時記憶網絡LSTM是屬于循環神經網絡的一種,在時序數據預測上表現出不錯的效果,例如語音識別、文本翻譯等領域。LSTM作為RNN的有效改進,解決了長距離信息丟失的問題。在命名實體識別領域,LSTM可以有效提取文本時序特征,從而能夠更好地理解文本內容。而雙向長短時記憶網絡BiLSTM在提取文本特征上更進一步。BiLSTM由前向LSTM與后向LSTM組合而成,在時序數據的序列輸入中,當前的輸出不僅與前面的文本有關系,也與后面的文本有關系,單向的LSTM只能按照從前往后的順序進行更新隱藏層狀態,無法利用序列的后文信息,而BiLSTM可以捕捉雙向語義,即可以捕獲輸出序列從前往后的信息,也可以獲得輸出序列的從后往前的信息。最后將兩者不同的順序進行結合,得到BiLSTM模型的輸出,BiLSTM的結構如圖2所示。
1.3? 條件隨機場
條件隨機場(CRF)是一種判別式的模型,在通過輸入文本序列中建立遠程依賴關系,從全局的角度獲得最優的預測標簽序列。假設給定輸入文本序列x,和對應的標簽序列y。對文本序列對應的打分如下:
式中:A表示轉移概率矩陣,是序列標簽的個數,另外兩維是起始狀態和結束狀態, 表示由標簽轉移到標簽的轉移得分,Pij表示第i個字為j的概率得分,整個序列的分數總數等于各個位置的打分之和。因為預測的序列有很多種情況,種類為標簽的排列組合大小。只需選取得分最大的組合,通過神經網絡訓練使得最大得分的Score在所有Score中的比重越大越好。最后使用Softmax函數歸一化得到所有的標簽序列的概率。如式所示:
1.4? 序列標注
在命名實體識別任務中通常采用序列標注的形式,即對文本中每一個漢字給出一個對應的標簽,例如使用最簡單的BIO標注方式。B表示實體的開頭,I表示實體的除了開頭的其他部分,O表示其他的詞。如B-PER、I-PER代表人名首字、人名非首字的其他部分,B-LOC、I-LOC代表地名的首字、地名非首字的其他部分,而B-ORG、I-ORG同理代表組織機構的相應位置。模型通過大量的訓練,最后預測出輸入文本對應的標簽。
2? 模型構建
2.1? 模型整體架構
提出的模型由BERT、BiLSTM和CRF三部分組成,如圖3所示。輸入序列經過BERT得到序列中每個字的向量表示,然后在特征提取層,使用BiLSTM層提取序列的時序特征,最后將經過BiLSTM得到的輸出作為CRF算法的輸入,對標簽序列的順序進行約束,得到最終輸出的標簽序列。
2.2? BERT層
首先將文本輸入序列的每個字進行id映射,變成機器能夠識別的數值型,此過程為文本的token嵌入,再將輸入序列進行位置編碼,融入每個字的位置信息,然后進行分段編碼,分段編碼將整個輸入句子編碼為0,最后將三個嵌入向量對應位置進行相加,得到BERT的輸入。由于訓練BERT預訓練模型需要花費大量的時間和算力,因此本文下載已經訓練好的模型參數作為初始化參數。假設xi表示輸入句子的第i個詞的id,經過BERT模型,每個字對應的輸出維度是768,每個字對應的動態向量具體為:
vwi=BERT(wi)(3)
2.3? BiLSTM層
前向LSTM和后向LSTM同時進行訓練,輸出也是由前向隱藏狀態和后向隱藏狀態共同決定,即將雙向的LSTM的每個時刻的輸出進行向量拼接,得到某一時刻的狀態輸出,t時刻的BiLSTM的輸出如下:
2.4? CRF層
CRF層的作用就是對最終序列標注進行約束,由式(2)得到每個輸出序列標簽的概率,目標是使得其中的一組輸出序列的概率最大。假設y′表示真實標簽,Yc表示所有可能標簽的集合空間,然后使用最大似然函作為損失函數來優化模型參數,最后利用維特比算法求得全局最優序列,最優序列為最終序列標注任務的標簽序列結果。最終的損失函數如下:
模型以預測出概率最高的標注序列為目標進行訓練,通過梯度下降法,使得Loss的值下降,最終轉為求Loss最小值的數學問題。
3? 實驗及結果分析
3.1? 實驗數據集
本章所有實驗數據來源自Aishell 3語音對應的文本內容,經分析發現該數據集含有大量的實體數據,涉及智能家具、無人駕駛、工業生產等11個領域,因此作為本實驗的訓練語料。在實驗數據上選取了句子長度在5個到25個之間的數據,選取了5 000條數據作為模型的訓練集,500條作為模型的驗證集。
3.2? 預訓練模型的微調方式
訓練BERT模型需大量的時間和算力,而且需要大量的語料作為訓練集,并且從頭開始訓練,對于BERT具有千萬參數量的大型神經網絡是不現實的。因此本文采用訓練好的已經發布的“bert-base-chinese”模型,并在此基礎上進行微調。微調的方式有以下兩種:
1)固定預訓練模型的所有參數,只對自定義的網絡參數進行訓練。
2)不固定任何的參數,將預訓練模型的參數作為整個模型的初始化,并且更新整個網絡的參數。
第一種方式因為只訓練自定義的網絡,更新的參數量少,節省計算時間和成本,但是只訓練自定義的網絡,在一些非通用數據集上效果往往不明顯。因此,本文選擇第二種方式,使用經過大量語料訓練后的預訓練模型參數進行模型的部分初始化,然后在本文提出的數據集上進行模型的訓練,在訓練過程中不斷地更新網絡中的所有參數。
3.3? 參數設置
優化器使用Adam(Adaptive Moment Estimation),學習率設為0.001,批處理為64,BERT的隱藏單元數為768,BiLSTM的隱藏單元為768,為了防止模型過擬合,除了Embedding模型,所有的模型都設置了dropout,且都設為0.2。
3.4? 評價指標
為了準確評估所提出模型的命名實體識別性能,使用精確率P(precision)、召回率R(recall)和F1評價指標在驗證集上來衡量模型的準確度。混淆矩陣的一般形式如表1所示。
評價方法:采用精確率P,召回率R,和F1為模型評價指標,其計算式如下。
P的公式可以表示:
3.5? 實驗結果與分析
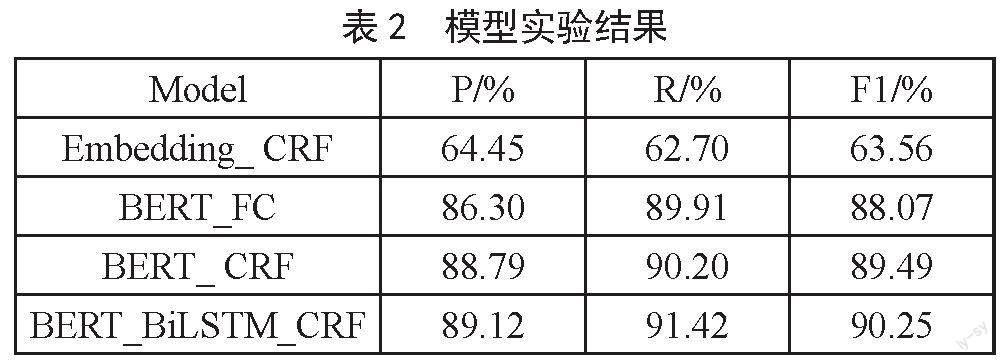
為了驗證BERT對文本表示向量的準確性,選取了隨機初始化的Embedding作為模型的對比,也為了驗證加入的深度學習模型BiLSTM和CRF能夠提高命名實體識別性能,設置了一組消融實驗,如只有簡單的BERT和全連接層FC、BERT_CRF,并在自選的小數據集上進行實驗驗證。實驗結果如圖表2所示。
從表2可以看出,隨機初始化的詞嵌入模型Embedding_CRF模型和使用BERT_CRF模型的F1的值相差約26%,由此可見使用BERT模型具有明顯的優勢,說明經過大量的中文語料的學習,預訓練模型可以學習到更多的文本語義信息。隨機初始化的Embedding雖然可以經過反向傳播進行更新網絡參數,學習到詞與詞之間的關系,但是所得的動態詞向量依然達不到文本表示向量精確度的要求,并且和預訓練模型存在較大的差距。分析其原因有:第一,在小數據集下,訓練文本語料不足,而預訓練模型是經過大量的文本語料的學習從而模型具有強大的泛化能力,在小數據集上同樣也表現出較好的效果。第二,網絡的設計,Embedding模型的網絡結構簡單,最重要的網絡結構只有線性層網絡,而BERT的網絡結構設計復雜,有多頭注意力層、歸一化層、前饋神經網絡層和殘差網絡,其中最重要的多頭注意力層可以從文本的多個角度來提取文本特征,從而使得BERT在文本表示上具有顯著的效果。
BERT和BERT_CRF模型的對比實驗中加入了CRF,F1的值提升了1%,說明CRF對模型的最終輸出序列的順序起到了約束的作用,這種約束規范有助于提高模型的準確率。模型BERT_BiLSTM_CRF和模型BERT_CRF對比實驗,發現加入了BiLSTM比沒有加入的模型,提取效果有了一定的提高,說明BiLSTM捕獲雙向的時序信息,對模型的準確率起到了一定的作用。
4? 結? 論
針對命名實體存在邊界模糊和在小數據集下效果不明顯的問題,本文主要從提高文本表示能力角度出發,提出使用預訓練模型獲得動態詞向量。該動態詞向量攜帶了大量的語義信息,可以更加精確地表示文本。在特征提取模塊,選擇了BiLSTM,可以從文本前后兩個角度深入提取文本特征,在最終輸出的標簽序列使用CRF對標簽序列輸出順序進行約束,減少非法的輸出,來獲得最優的輸出序列。實驗和隨機初始化的詞嵌入方式進行對比,發現預訓練模型在命名實體識別中,效果有顯著提高,說明了預訓練模型作為文本表示具有明顯的而優勢,并且通過消融實驗發現,加入了BiLSTM和CRF模型具有更好的特征提取能力。
雖然使用預訓練模型進行中文命名實體識別取得了較好的效果,但是依然存在一些問題,如BERT預訓練模型的參數量大,導致訓練時間過長,后續的研究將選取一個輕量級的預訓練模型,并搭配不同的神經網絡模型,進一步尋找文本序列內部聯系。
參考文獻:
[1] 王穎潔,張程燁,白鳳波,等.中文命名實體識別研究綜述[J].計算機科學與探索,2023,17(2):324-341.
[2] BENGIO Y,DUCHARME R,VINCENT P,et al. A Neural Probabilistic Language Model [J].Journal of Machine Learning Research,2003(3):1137–1155.
[3] MIKOLOV T,CHEN K,CORRADO G,et al. Efficient Estimation of Word Representations in Vector Space [J/OL].arXiv: 1301.3781 [cs.CL].(2013-01-16).https://arxiv.org/abs/1301.3781v1.
[4] DEVLIN J,CHANG W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv: 1810.04805 [cs.CL].(2018-10-11).https://arxiv.org/abs/1810.04805.
[5] 苗將,張仰森,李劍龍.基于BERT的中文新聞標題分類[J].計算機工程與設計,2022,43(8):2311-2316.
[6] 李雪思,張智雄,劉歡.一種基于序列標注的概念短語抽取方法[J].圖書情報工作,2022,66(11):121-128.
[7] WEN S,ZENG B,LIAO W X. Named entity recognition for instructions of Chinese medicine based on pre-trained language model [C]//Proceedings of the 2021 3rd International Conference on Natural Language Processing.Piscataway:IEEE,2021:139-144.
[8] 宋功鵬,李陽,安新周,等.基于CRF和LSTM的文本序列標注方法研究[J].信息技術與信息化,2022(7):129-132.
[9] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates Inc,2017:6000-6010.
