基于個性化聯邦學習的多源域MRI左心室分割
2023-09-19 05:46:36李純真
電視技術 2023年8期
關鍵詞:模型
李純真
(福州大學 先進制造學院,福建 泉州 362200)
0 引 言
近年來,國家相關部委為推進“互聯網+醫療健康”戰略,多次發文倡導各醫療機構加快信息互通共享,推進信息化和數字化建設,全面推進醫院轉型發展。其中,醫學影像對最終診斷病情起到了不可替代的作用,醫院在常規臨床診斷中產生了大量的影像數據。這些影像數據需要經驗豐富的醫生耗費大量時間進行標注,并且由于一些法律和道德的限制,收集患者數據并進行統一存儲并不可行。利用分布式技術對存儲在不同醫院的影像數據進自動分析,成為未來醫療健康大數據的發展方向。
聯邦學習提供了一種去中心化的隱私保護解決方案,可以在不共享本地數據的情況下,利用這些分散的數據在幾個機構之間協同訓練神經網絡模型[1]。在一些醫學影像分析任務如新冠肺炎檢測[2]、乳腺癌分類[3]、腦腫瘤分割[4]上,聯邦學習已經被證明與集中數據訓練的模型性能相差無幾。然而,上述任務所采用的數據集來源于單一的臨床中心和相同的成像協議,無法模擬聯邦學習面臨的實際環境。實際上,由于成像儀器、患者的人口特征以及地域不同,不同醫療機構之間的采集的心臟磁共振成像(Magnetic Resonance Imaging,MRI)圖像存在一些如圖1所示的差異。傳統聯邦學習的做法是訓練一個全局模型。盡管該模型在所有客戶端上可以取得較高的平均性能,但是對于數據分布差異較大的客戶端來說,該模型并不適配本地數據,造成性能損失。
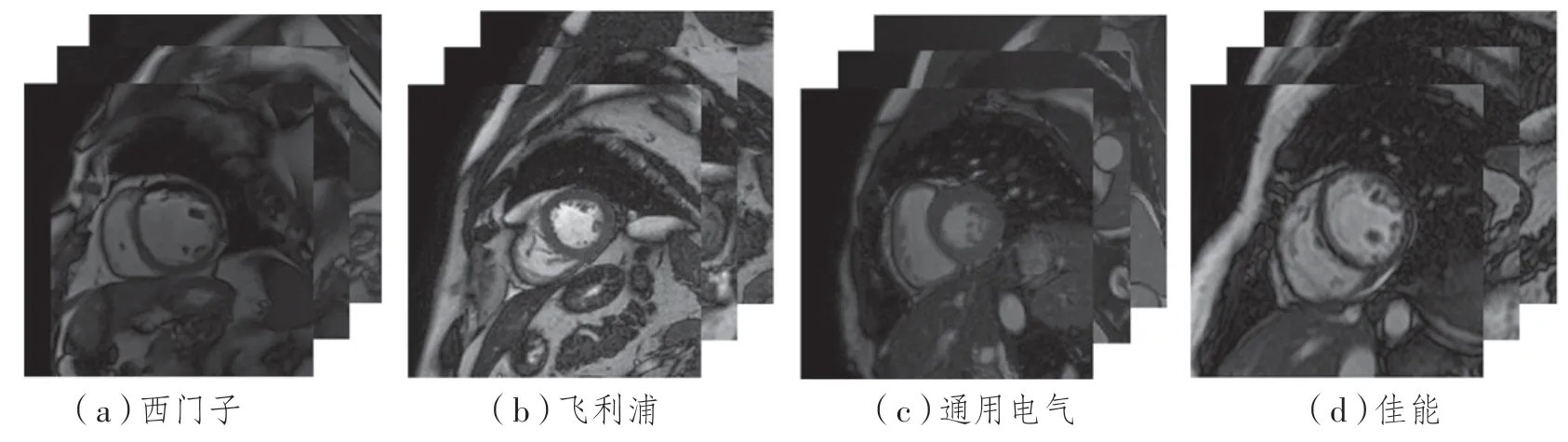
圖1 不同制造商的MRI成像對比
與傳統聯邦學習對本地模型進行加權聚合的做法不同,個性化聯邦學習是以分散的方式為每個客戶學習個性化的模型。主流的個性化方法包括多任務學習、模型分層以及模型插值方法。DENG等人提出的自適應個性化聯邦學習(Adaptive Personalized Federated Learning,APFL)算法將本地模型與全局模型進行自適應加權,獲得個性化模型[5]。ARIVAZHAGAN等人將模型分成個性化層和基礎層,所有客戶端模型共享基本層,不同客戶端具有不同的個性化頂層來適應本地數據分布[6]。THAPA等提出將模型最后一層保留在本地客戶端,減少因標簽傳輸導致的通信成本增加問題和數據泄露問題[7]。FALLAH等借鑒元學習思想,將服務器發送給客戶端的模型進行初始化,然后,客戶端根據自身私有數據再進行若干次訓練,從而達到聯邦個性化元學習的效果[8]。
目前,聯邦學習在醫學影像分析上的研究,致力于在多個非獨立同分布漂移的客戶端數據集上學習到一個健壯的全局模型。例如,CHANG K等人[9]采用聯邦學習在幾個醫療機構之間聯合對Kaggle糖尿病視網膜病變分類任務進行建模,取得了與集中性訓練相當的實驗結果。JIANG等人[10]通過協調局部和全局漂移解決數據異質性引起的整體非獨立同分布漂移問題,幫助全局模型向收斂最優解優化。以上這些工作通過生成對抗網絡和模型正則化等方法有效降低了數據異質性的影響,但是,目前針對個性化聯邦學習在多源域心臟MRI數據的可行性與性能表現的研究依然較少。
為了解決上述問題,本文提出了一種聯邦學習個性化方法來對左心室進行多源域聯合分割。在聯邦學習框架下引入直方圖匹配,減少客戶端灰度分布差異,提高全局模型的健壯性,并在此基礎上進行本地微調訓練以適應客戶端數據分布,從全局和本地兩個方面解決非獨立同分布問題,提升分割的準確性。
1 方 法
1.1 聯邦學習
在醫療領域,聯邦學習一般由多家醫院與一個可信第三方作為中心服務器組成客戶-服務器架構,如圖2所示。
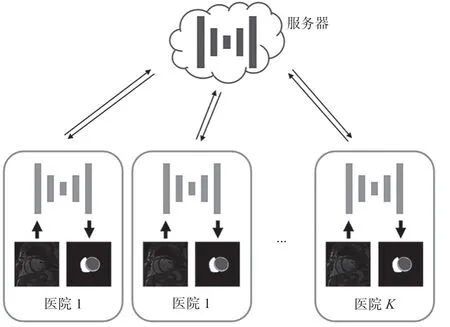
圖2 聯邦學習任務場景
假設一共有K個醫療機構參與聯邦建模,這些機構是數據的擁有方,pk表示第k個機構的數據分布。服務器用于模型參數的聚合,是模型的擁有方。首先,中心服務器將初始化的全局模型發送給各機構。然后,每個客戶端使用學習率η和梯度gk在其各自的本地數據集上進行至少一輪的更新,使更新完成的模型權重被發送到服務器,以與每個中心的樣本數量成比例的方式聚合到全局模型中:
聚合后,服務器將新模型重新分配給客戶端,以執行下一輪本地模型訓練。當達到設置的迭代輪次或者收斂條件,訓練結束,并獲得最終的全局模型。
1.2 直方圖匹配
針對不同醫療中心數據之間的分布漂移問題,本文提出基于灰度直方圖匹配的數據增強方法,使用直方圖匹配來縮小多源之間的數據分布差異。由于灰度直方圖描述了MRI圖像中每種灰度級出現的頻率,且不會提供有關像素之間空間關系的任何信息,因此,共享均勻化的灰度直方圖序列并不會導致信息泄露。直方圖匹配主要分為局部累加和全局平均兩個過程。首先,給定來自第k個客戶端的樣本灰度級在[0,L-1]內,其直方圖是一個離散函數,定義為
式中:n是像素總數,nk是第k個灰度級的像素總數,rk是第k個灰度級,k=0,1,…,L-1。灰度直方圖反映了圖像的灰度分布信息。客戶端對本地圖像的直方圖進行累加并平均,以獲得局部灰度直方圖H k:
其次,中心服務器通過一輪通信,得到K個參與方的局部灰度直方圖,進行全局平均:
最后,本地客戶端對本地數據進行直方圖匹配,使輸出圖像的概率密度函數等于全局灰度直方圖H。圖3展示了源圖像、目標圖像和增強圖像的一些樣本。

圖3 源圖像經過直方圖匹配后的效果
2 實驗結果及分析
2.1 實驗細節
2.1.1 數據集及客戶端設置
為了模擬真實的聯邦學習環境,本文設計了一個獨特的數據集。該數據集由來自M&Ms多中心心臟圖像分割挑戰賽數據集[11]的5個中心和ACDC2017心臟病自動診斷挑戰賽數據集[12]的1個子集作為第6個中心組成,使用的數據集詳細信息如表1所示。該數據集一共包含380個受試者的T1加權心臟Cine-MRI序列,并根據受試者來源分為6個醫院。每個醫院按照0.50∶0.25∶0.25的比例隨機劃分為訓練集、驗證集和測試集。

表1 數據集所含的各醫療中心信息
原始數據集軸向平面上包括大小從196×240 px到320×320 px不等的圖像,通過計算掩碼質心,繼而中心裁剪獲得128×128 px大小的感興趣區域(Region of Interest,ROI),減少無用信息的同時使心臟區域具有相似的視野,并通過直方圖匹配將不同醫院數據的灰度分布進行均衡化,如圖4所示。
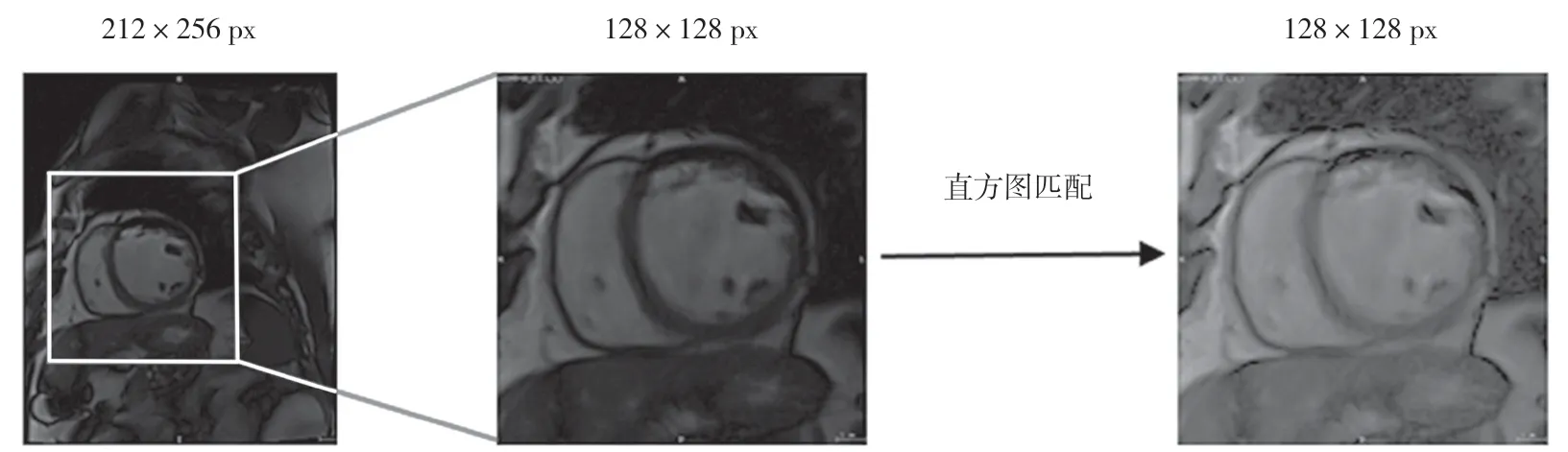
圖4 圖片預處理
2.1.2 超參數
在聯邦訓練過程中,將每個數據來源視為一個醫院,所有醫院使用相同的超參數設置。采用學習率為0.000 1,動量為0.9和0.99的Adam優化器對本地模型進行訓練,批大小均設置為16。根據McMahan等的實驗結果,較大的本地訓練次數有助于減少通信成本,但是性能略有損失。通信成本不是本文所考慮的問題,因此,每一輪的本地訓練次數Epoch設置為1。
2.2 實驗結果
為了驗證本文個性化聯邦學習的有效性,分別對本地訓練、集中式學習、增量學習和傳統聯邦學習在MRI左心室分割任務上的性能進行對比。表2為本文方法和其他聯邦學習方法在左心室分割任務上的實驗結果。集中訓練表示收集各醫療機構數據進行傳統深度學習訓練。由表2的結果能夠看出,本文方法在左心室分割精度上分別比增量學習和聯邦平均高出4.79%和1.12%,并且達到集中訓練的理論上限結果的99.63%,證明了本文個性化聯邦學習方法在多機構協同合作與隱私保護方面的巨大潛力。

表2 左心室分割任務實驗結果
3 結 語
本文針對聯邦學習在面對醫學影像分析任務時遇到的非獨立同分布問題,提出了一種個性化聯邦學習的方法,主要在不同客戶端之間進行直方圖匹配以減少客戶端數據差異,提高全局模型的健壯性,在本地利用模型微調的方法獲得個性化模型。相較于其他隱私保護分布式學習方法,本文方法在多中心心臟MRI數據集以及左心室分割任務上均取得了更高的精度。實驗結果表明,本文所提的個性化方法可以在非獨立同分布設置下提高聯邦學習的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
