基于大數據方法的大連系統性金融風險監測預警
2023-09-25 01:31:20李艷玲陳丹丹
中阿科技論壇(中英文) 2023年9期
李艷玲 陳丹丹
(大連財經學院,遼寧 大連 116622)
1 緒論
1.1 研究背景及意義
黨的二十大報告指出,防范金融風險還須解決許多重大問題。要強化金融穩定保障體系,守住不發生系統性風險底線。這為新時代處置重大金融風險、維護人民財產安全提供了重要遵循和根本指南。大連是東北地區對外開放的窗口,經濟不斷發展,不同金融市場之間的聯動逐漸加強,金融機構之間的業務交叉日趨密切,金融產品創新不斷涌現,金融體系的復雜性變得更加突出。因此,加強對系統性金融風險的監管變得尤為重要。
大數據前沿技術逐漸滲透到各個領域,引發了現代金融業革命性的變革。苗子清等(2020)研究指出,大數據方法因具備及時性、精準性、高顆粒度、大樣本量等優勢[1],能夠很好地完成金融領域的數據分析和信息處理,進一步豐富了監測預警系統性金融風險的手段和工具。將大數據方法應用在監測預警大連系統性金融風險中,一方面可以降低監管成本,另一方面能夠及早發現危機信號,采取有效措施,從而進行有效治理,對維護大連經濟健康具有重要的現實意義。
1.2 國內外研究現狀
國外大數據技術在金融監管領域的應用較為成熟,主要有以下方面:一是綜合指數法,此方法基于宏觀經濟和金融市場指標,采用各種統計學加總方法,構建可用于實時監測金融體系風險狀況的綜合指數,例如Illing等(2006)提出的加拿大金融壓力指數[2]。二是邏輯回歸法,例如Kumar等(2002)提出的Simple Logit模型用于貨幣危機預警[3]。三是研究風險傳遞和金融行業系統性關聯的方法,如Nyman等(2021)利用大數據分析法對系統性風險進行評估[4]。
我國學者借鑒國外方法,結合中國特色,創造性地建立了中國的系統性金融風險監測預警模型。李夢雨(2012)利用BP神經網絡打造金融風險預警系統[5];劉曉星等(2012)為了更加全面測度我國系統性金融風險,構建了一個完備的金融壓力指數測度模型體系[6];李敏波等(2021)通過馬爾可夫區制轉換模型,對金融市場壓力狀態進行辨識[7]。綜上所述,國內研究學者都是基于國家層面來使用大數據方法對系統性金融風險進行監測預警,但對區域系統性金融風險的監測預警也應同樣重視。所以本文選擇大連這一區域,使用大數據方法對其系統性金融風險進行監測預警。
2 大連系統性金融風險監測預警模型構建
2.1 指標選擇原則
王克達(2019)認為針對不同金融風險的成因、影響范圍和監管機構等因素,在建立風險預警指標體系時需要選取不同的具體指標[8]。雖然各指標的選擇方式不相同,但是要保證指標體系的科學性與完整性,還必須遵守科學性、典型性和可得性原則。
2.2 構建大連系統性金融風險預警指標體系
本文構建的大連系統性金融風險預警指標體系在遵循以上預警指標選取原則的基礎上,參考了相關的金融監管機構的監管指標,并結合國內外學者的研究成果。在指標選擇過程中,充分考慮了各種因素,并綜合考慮其實際操作性和數據獲取難易程度,最終以外部經濟、大連宏觀經濟和大連金融機構這3個維度作為一級指標,并在此基礎上選擇了相應的10個二級指標。同時,本文借鑒相關文獻的風險等級臨界參數,設定劃分指標內的預警界限,各指標具體的預警界限如表1所示。

表1 大連系統性金融風險指標預警界限
3 基于徑向基神經網絡的大連系統性金融風險預警實證
3.1 模型數據的處理和期望值確定
本文樣本選擇2005—2020年的年度數據,選擇的原因是數據的可得和全面。數據來源于歷年《中國統計年鑒》、歷年《大連統計年鑒》和萬方數據庫等。由于所選指標的計量單位不同,無法直接進行指標間的比較。另外,在數據分析過程中,需考慮徑向基(RBF)神經網絡的收斂問題。為消除數據量級和量綱對分析過程的影響,本文先對各指標的原始數據進行了處理。接下來,本文確定了輸出節點和期望輸出值,主要在Jupyter Notebook中使用python對10個輸入樣本進行主成分分析。
3.1.1 數據的處理
首先對指標數據進行標準化處理,從而使選出的指標可以相互比較。將收集到的原始指標數據導入Jupyter Notebook中,使用StandardScaler函數對數據進行歸一化處理,并返回歸一化后的結果。StandardScaler是Sklearn庫中提供的歸一化函數,它能夠將數據中的每個特征轉化為均值為0、方差為1的標準正態分布的數據。
3.1.2 主成分分析
主成分分析(PCA)的核心思想是利用數據降維,對多個指數進行線性變換,得到若干不相干的綜合指數。各主元分量均為原變量線性合成,各主元分量間無相關性。用這種方法得到的主要元素擁有更好的性能,變量能更好地抓住問題的本質,從而簡化了系統結構。在PCA中,需要確定的是特征值大于1并且累積方差貢獻率大于85%的前n個主成分。經過分析,本文前三個主成分滿足這些要求,這三個主成分的方差貢獻率分別為0.650 35、0.160 04和0.081 99。通過三個主成分的方差貢獻率,可以得到整體金融風險情況F的得分,具體如表2所示。
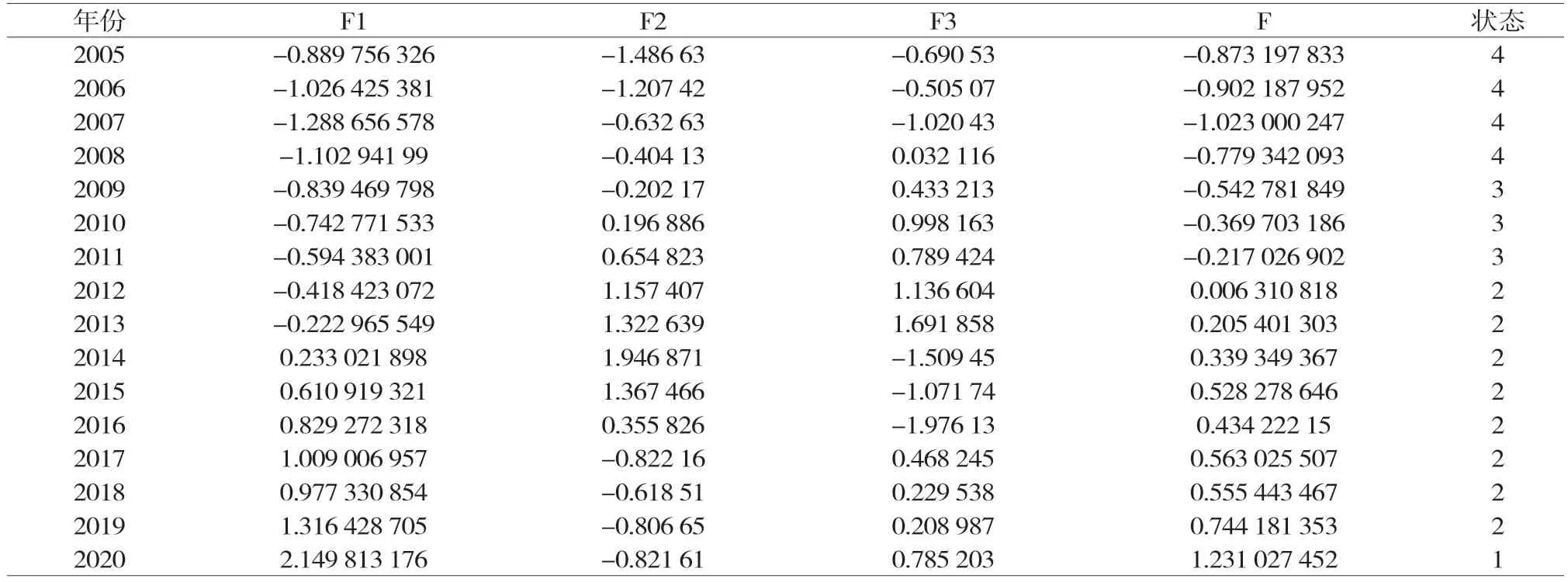
表2 各主成分得分及綜合得分表
從表2數據可以看出,大連的系統性金融風險一直在降低。20世紀90年代大連經濟飛速發展,雖然從2000年開始大連GDP增速有所減緩,但前期經濟高速發展使其金融體系變得不穩定,2005—2008年雖然系統性金融風險一直降低,但仍處于較大風險狀態。而到2008年以后,國家宏觀經濟增速放緩,大連的系統性金融風險也逐漸降低,到2012年進入相對安全狀態。本文使用SPSS對上述數據進行了聚類分析,根據數據之間的相似度對它們進行分類,結果如圖1所示。經過聚類分析,將數據分為四類:“較大風險”“警惕”“相對安全”以及“安全”。
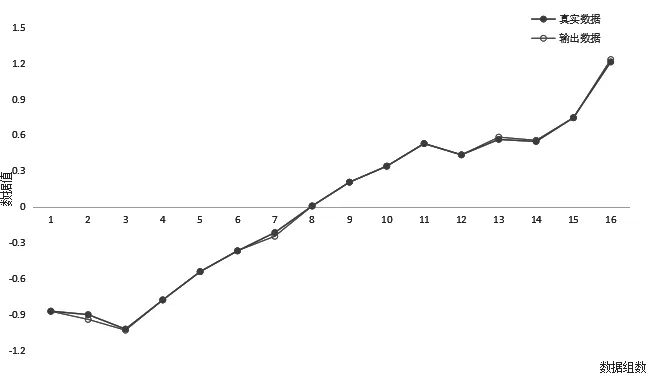
圖1 數據擬合圖
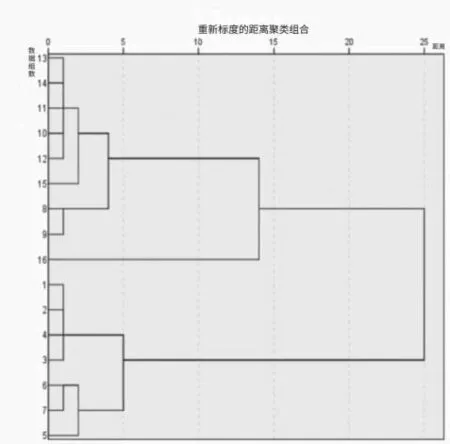
圖1 各主成分及綜合得分聚類分析結果圖
通過分析得出,本文將大連系統性金融風險閾值劃分為較大風險(-∞,-0.8]、警惕(-0.8,0.006]、相對安全(0.006,1.2]和安全(1.2,+∞)。
3.2 徑向基神經網絡模型的訓練與測試
徑向基神經網絡(RBFNN)是一種非線性模型,它基于神經網絡,具備出色的逼近能力和泛化能力。它的工作原理是將輸入數據映射到高維空間中,然后使用線性模型進行分類或回歸等任務。RBFNN的結構包含三個部分:輸入層、隱含層和輸出層。輸入層接收原始數據,并將其傳遞到隱含層。隱含層由一組徑向基函數組成,這些函數將輸入數據映射到高維空間中。徑向基函數通常是高斯函數或者多項式函數等。隱含層的每個神經元都代表一個徑向基函數,其輸出值是輸入數據與該函數中心點之間的距離。隱含層的輸出被送到輸出層,通過權重矩陣和偏置項進行線性組合,得到最終的輸出結果。本文主要基于徑向基神經網絡模型,來對系統性金融風險達到預警目的。在Jupyter Notebook中使用randperm()函數,從2005—2020年的數據樣本中隨機選取了13年的數據作為訓練集,剩下3年的數據則作為測試集。這樣能夠保證模型的公正性與有效性,提高訓練結果在實證中的可靠性。
3.2.1 模型構建和參數設置
靠近地平線的太陽,像一團快要熄滅的火球,幾乎被那些混混沌沌的濃霧同蒸氣遮沒了,讓你覺得它好像是什么密密團團,然而輪廓模糊、不可捉摸的東西。這個人單腿立著休息,掏出了他的表,現在是四點鐘,在這種七月底或者八月初的季節里——他說不出一兩個星期之內的確切的日期——他知道太陽大約是在西北方。他瞧了瞧南面,知道在那些荒涼的小山后面就是大熊湖;同時,他還知道在那個方向,北極圈的禁區界線深入到加拿大凍土地帶之內。他所站的地方,是銅礦河的一條支流,銅礦河本身則向北流去,通向加冕灣和北冰洋。他從來沒到過那兒,但是,有一次,他在赫德森灣公司的地圖上曾經瞧見過那地方。
模型的構建需要確定輸入層、隱含層以及輸出層的節點數。對數據進行聚類獲得徑向基函數的寬度向量、輸出層的連接權值以及閾值進行隨機初始化,模型初始化完成。本文將模型的隱含層節點數設置為8,輸入層節點數設置為3,輸出層節點數為1,最大訓練次數為1 000,停止迭代訓練條件0.000 8,學習率為0.01。
3.2.2 模型的訓練和測試
為了訓練模型,需要將模型的輸出結果與前面的數據進行比較,并計算兩者之間的誤差值。在此基礎上,對輸入層、隱含層、輸出層三個層次的連接權值進行了調整。這個過程需要重復進行,直到整個樣本的誤差值符合預先設定的準確度要求。通過這種迭代循環的方式,能夠得到更加準確、穩定以及實用的預測模型。當迭代到一定次數,損失值變化不明顯,優化成功。
根據訓練結果,保存更新的權值和偏置,模型訓練結束。將保存好的權值和偏置代入訓練好的模型,使用測試集來核驗模型的正確性。將2005—2020年的訓練集與測試集的模型輸出值與相應年度的真實值進行對比得到圖1,從圖1可以看出,模型輸出數據與真實數據擬合基本一致。
3.3 大連系統性金融風險預測
4 結論
本文運用主成分分析、徑向基神經網絡模型和聚類分析這三種大數據方法對大連系統性金融風險預警進行了實證研究,選取了10個指標構建大連系統性金融風險預警指標體系,對大連系統性金融風險狀態進行了判定。結果顯示,大連在2005—2008年處于較大風險狀態;2009—2011年處于警惕狀態;從2012年開始大連進入相對安全狀態。基于訓練測試完畢的徑向基神經網絡模型輸入大連2021年的指標數據對大連2022年的系統性金融風險做出了預測,結果顯示2022年大連系統性金融風險為安全狀態。總體來說,大數據技術在系統性金融風險研究中的應用,可以幫助金融機構更加準確地識別風險因素,并進行風險預測和決策,更好地實現風險監測和控制,從而降低金融風險的發生概率和影響程度,其應用前景將會越來越廣闊。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
臨床誤診誤治(2021年12期)2021-12-04 00:25:45
中國新聞周刊(2021年9期)2021-03-29 20:33:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
現代檢驗醫學雜志(2015年1期)2015-02-06 01:59:26
西南軍醫(2015年5期)2015-01-23 01:25:06
名作欣賞(2014年29期)2014-02-28 11:24:31
