基于改進的YOLOv5 城市道路車輛行人檢測方法
2023-09-27 10:43:00羅江宏袁梓麒易志雄
電子制作 2023年19期
羅江宏,袁梓麒,易志雄
(湖南科技大學 信息與電氣工程學院,湖南湘潭,411100)
0 引言
自動駕駛的本質是構造反射,即汽車感知外部世界的變化,并做出相應反饋。自動駕駛汽車的環境感知功能需要提供可靠的外部環境信息,自動駕駛汽車才能準確地判斷自身位置以及周邊駕駛狀態并做出可靠的駕駛決策。其中行人與車輛識別是自動駕駛汽車環境感知功能的重要技術,近年來,深度學習技術得到快速的發展,基于計算機視覺的行人車輛識別功能可行性得到了極大的提高,將基于深度學習的目標檢測算法應用到行人車輛識別技術上,對自動駕駛汽車環境感知功能的研究和應用具有重要意義[1]。
基于深度學習的目標檢測算法一般分為兩類[2],一類是基于候選區域生成的檢測方法(two-stage),其算法分為兩個階段,首先由算法的子網絡生成一系列候選框,然后再對候選框進行分類和定位,R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]等算法都屬于這類算法。另一類是基于回歸檢測的檢測方法(one-stage),這類算法并不會生成候選框,而是直接在輸出特征圖上生成候選邊界框進行分類和定位,其代表為YOLO[6~9]系列算法與SSD[10]算法。two-stage 目標檢測算法往往能達到比較高的目標準確識別率,但缺點是檢測速度慢,模型龐大并不適合需要實時車輛行人檢測的任務[11];one-stage 目標檢測算法檢測速度快,結構簡單,精度相對two-stage 目標檢測算法較低,但近幾年的onestage 目標檢測算法在滿足實時檢測的基礎上,準確率也基本上能達到two-stage 目標檢測算法的水平,因此在車輛行人檢測領域中one-stage 目標檢測算法具有較高的應用研究價值。
然而,對于攝像頭而言,自動駕駛汽車的行駛過程,是運動的、快速的。面對采集到的交通圖像中存在的遮擋目標、行駛路線前方的小尺度目標以及復雜道路上的多尺度目標等情況時傳統的two-stage 目標檢測方法無法達到可靠的實時檢測速度;傳統的one-stage 目標檢測算法又無法達到可靠的實時檢測精度。袁小平等[12]通過在YOLOV3的backbone 上引入密集連接模塊來實現特征重用,提高網絡模型的特征提取能力來提升網絡精度,但引入密集連接模塊使得網絡需要耗費大量的計算資源,導致模型檢測速度下降。顧德英等[13]通過在YOLOv5 中引入更加復雜的P6 網絡結構加深網絡深度來改善網絡對特征的提取能力,但隨著網絡深度的加深,會使得特征圖中每個通道之間的全局信息逐漸丟失。Choi 等[14]發現城市道路圖像數據在高度垂直方向上包含的信息密度要遠少于圖像水平方向上的信息密度,而且城市道路圖像在高度方向的特征上有著明顯的結構性,并結合此特性提出了HANet,雖然通過此特點有效地改進了城市道路語義分割模型的準確性,但是網絡過于依賴圖像在高度方向上的特征信息,忽略了對圖片全局上下文信息的提取。近些年原本應用于自然語言處理(NLP)技術上的Transformer[15]模型開始在CV 領域大放異彩。Transformer 采用多層感知器(MLP)的自注意機制,克服了以往RNN 用于自然語言處理的局限性。自Transformer 出現以來,它在各個領域都得到了相當的重視。早期Transformer 在CV 領域主要用于處理時序特征,直到ViT(Visual Transformer)[16]模型的出現,ViT 模型首次擴大Transformer Encoder 模塊的使用范圍,代替傳統的CNN 卷積應用于計算機視覺領域中。
基于以上分析,為解決自動駕駛汽車對車輛行人識別算法的速度、精度要求,本文以YOLOv5 算法為基礎,結合城市道路圖像高度方向明顯結構性的特點,結合Transform 結構提出基于改進YOLOv5s 的車輛行人目標檢測算法,并使用公開自動駕駛數據集KITTI 進行算法的比較和分析驗證。
1 YOLOv5 檢測算法
YOLOv5 系列目標檢測算法總共有四種不同的模型,分別為:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。其中YOLOv5s 在其中屬于深度最小、速度最快的模型。YOLOv5系列模型與之前的YOLOv4、YOLOv3 模型結構類似,整體結構依然可以分為Input、Backbone、Neck、Prediction四部分。
在Input 部分YOLOv5s 繼續沿用YOLOv4 中的馬賽克(Mosaic)數據增強來豐富訓練數據集;Backbone 加入了Focus 結構對輸入圖片進行切片操作,新增CSP1_N 和CSP2_N 兩種CSP 結構分別應用在Backbone 和Neck 結構中,并繼續沿用SPP(空間向量金字塔池化)進行多尺度融合;Neck 中采用FPN(Feature Pyramid Network)+PAN(Path Aggregation Network)結構,FPN 結構能夠自上向下傳遞特征,PAN 結構能自下向上傳遞特征,兩種結構相互結合,增強YOLOv5 網絡的特征融合能力;Prediction 采用廣義交并比(Complete Intersection over Union,GIoU)損失作為Bounding box 的損失函數解決區分預測框和目標框大小相同的問題。YOLOv5s 的網絡結構圖如圖1 所示。
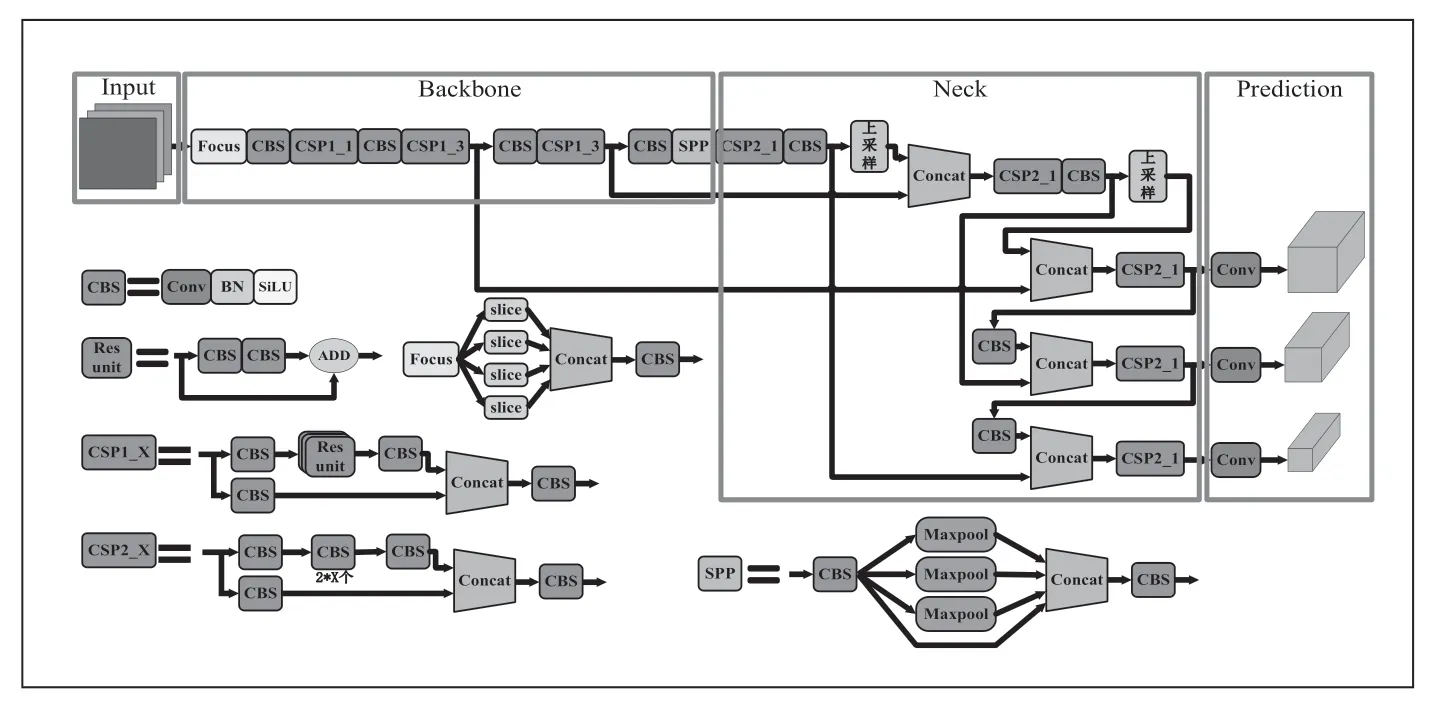
圖1 YOLOv5網絡結構圖
2 基于改進的YOLOv5 檢測算法
■2.1 加入K-means++聚類算法
YOLOv5 系列算法是采用anchor-based 的目標檢測算法,通過K-means 聚類方法得出先檢錨框參數,在網絡算法訓練時預先設定,其YOLOv5s 的默認先驗錨框參數只適合COCO、VOC 等多類別開發數據集。本文中數據集的檢測對象與前者存在較大的差別,若使用YOLOv5s 默認的先驗錨框參數進行訓練,會導致模型的收斂速度變慢并不能得到最佳的檢測效果。
通過K-means 聚類方法計算先驗錨框參數存在一定的缺陷,K-means 是以數據空間中K 個點為中心聚類,對最靠近中心點的對象歸類。通過迭代的方式,逐次更新各聚類中心的值。由于選擇的中心點是隨機的,每次聚類的結果都有一定的差異。K-means++算法在隨機選取一個樣本作為聚類中心后計算每個樣本與當前已經聚類的類中心之間的最短距離,用D(x)表示;接著計算每個樣本點被選為下一個聚類中心的概率,用表P(x)示;最后選擇最大概率值所對應的樣本點作為下一個聚類中心;K-means++算法每選擇一個聚類中心后要對已存在的聚類目標進行再一次的計算,重復此過程直到完整地選出K 個聚類中心;其中計算P(x)公式如下:
所以本文為了獲取具有針對性的初始先驗錨框參數選擇使用K-means++聚類算法重新計算YOLOv5s 的9 個默認先驗錨框參數。表1 展示了聚類方法優化前后,在KITTI數據集上K-means++聚類出的初始先驗錨框參數。
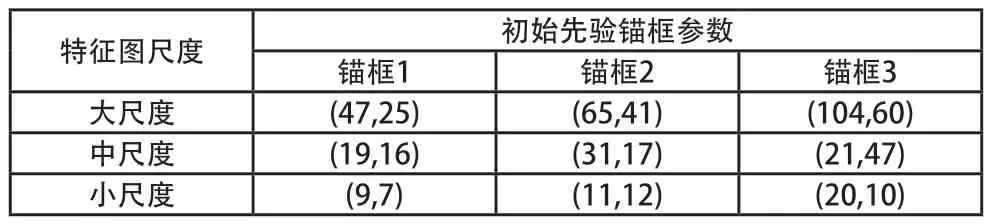
表1 默認先驗錨框參數
■2.2 基于Transformer 的高度上下文注意力模塊
城市道路場景圖像具有與透視幾何[17]和位置模式[18,19]相關的獨特性質。智能車輛對車輛前方圖像信息采集是由安裝在車輛前側的高清攝像頭設備進行采集的,所以采集的圖像包含了大量的城市道路行駛圖像。其中道路圖像在垂直位置上的特征分部非常明顯,這導致了根據空間位置合并共同結構的可能性,尤其是在垂直位置。天空、樹木、建筑等對象主要分布在圖像的頂部像素部分,車輛、行人和道路、車道線等道路上的對象主要分布在圖像的中部和底部,如圖2 所示。

圖2 城市道路場景不同高度部分的類別分布圖
針對城市道路圖像的內在特征,本文提出了一種基于Transformer 的高度上下文注意力模塊稱為HCA 模塊(High Contextual Attention Module),Transformer 能夠通過自我關注學習輸入序列之間的復雜依賴關系,HCA 模塊通過獲取和學習圖像高分辨率特征圖的垂直空間特征后利用Transformer 模塊構建特征長期依賴關系并捕獲垂直空間上的多尺度上下文特征,對低分辨率特征圖施加注意力權重,預測每個水平部分中哪些要素或類比其它要素或類更重要,模塊結構如圖3 所示。

圖3 HCA 模塊結構圖
YOLOv5 的特征提取網絡——CSP-Darknet 是一種在執行特征提取時效率很高的殘差結構網絡,但其結構是通過大量的卷積核堆疊來提取特征,導致網絡越到深層其丟失的全局信息就越嚴重,所以本文提出的HAC-YOLOv5 網絡是在原YOLOv5 特征提取網絡的三個下采樣層之間加入HCA 模塊,讓backbone 輸出的三個特征圖添加全局的高度上下文注意力權重,HCA-YOLOv5 結構圖如圖4 所示。
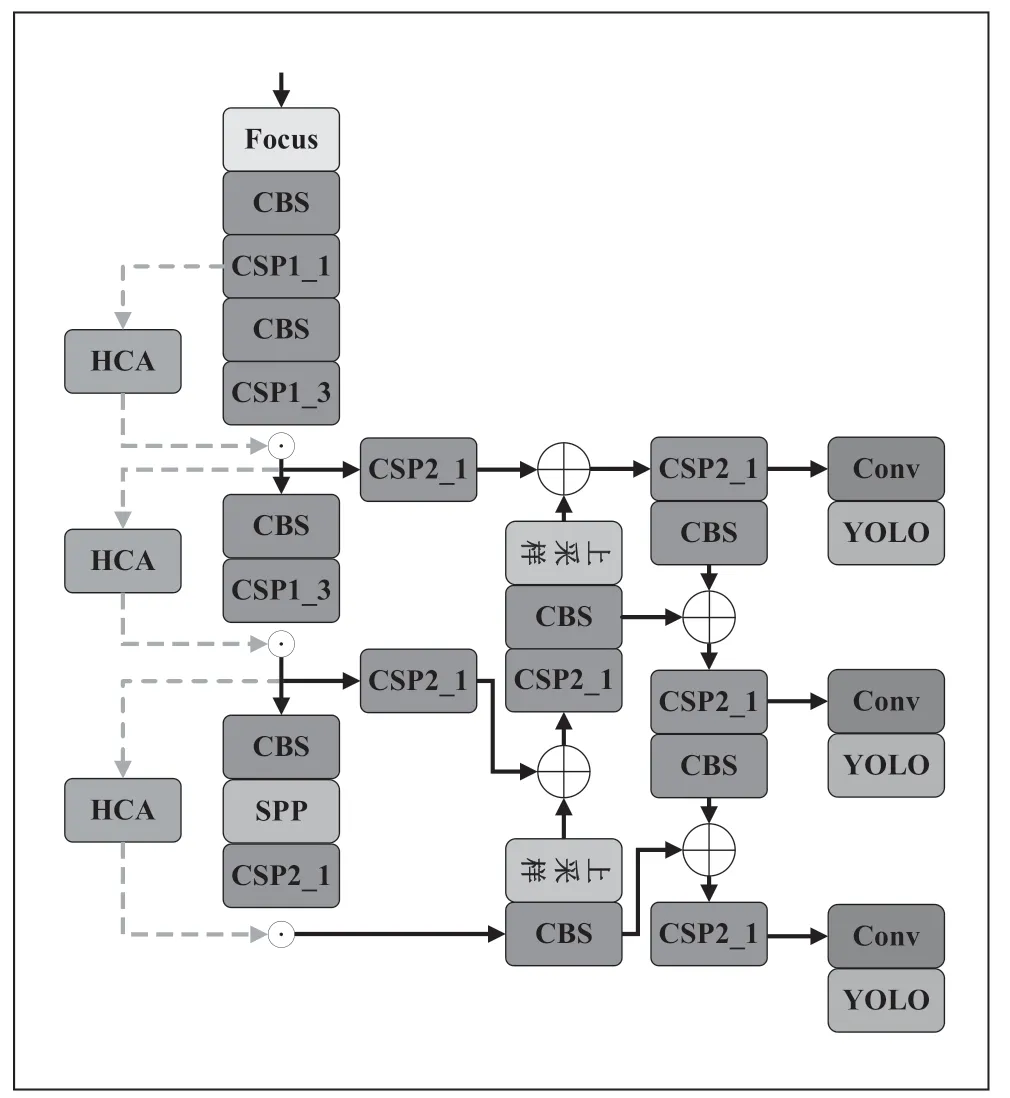
圖4 HAC-YOLOv5結構圖
2.2.1 寬度池化
根據圖像空間位置的不同,在城市道路圖像中,就分類而言,圖像的每一行都有明顯不同的統計信息,所以說Xi每行中的特征信息都在一定程度上表示了當前高度的行信息,對Xi每行進行寬度方向的平均池化操作可以分別捕獲每行的全局信息來估計對應信道在全局的權重。進行寬度方向的池化操作后得到的矩陣用表示,Z矩陣的第h 行向量計算公式如下所示:
2.2.2 粗注意力插值
高分辨特征圖經過寬度方向池化操作得到的矩陣Z中每行包含的高度上下文信息是比較分散的,并非所有的行中的信息都是有效全局信息,每個高度區域之間的類別分別也有較大的差異。因此對矩陣Z進行高度方向的插值下采樣,得到一個粗糙的高度方向的通道注意力特征圖的值本文設為16。因此模塊最后還需要將得到的注意力特征圖經過上采樣轉換成與需要相乘的低分辨率特征圖等效的維度。
2.2.3 Transformer Encoder 模塊
在HANet 模型的Height-driven 注意力模塊中經過寬度池化和粗注意力插值處理得到帶有高度上下文特征的矩陣后,使用多個卷積層對進行連續的卷積操作,并加入位置編碼獲取每個特征點的位置信息。雖然這種方式能夠提取到一定的全局特征信息,但是由于卷積核本身的特性(卷積核的局部計算)限制了其捕獲全局上下文信息的能力。相比之下,變換器能夠全局關注圖像特征塊之間的依賴關系,并通過多頭部自我注意為目標檢測保留足夠的空間信息。即HANet 模型中對矩陣?Z采用的卷積操作很難讓網絡提取到大范圍、大高度差特征信息之間的聯系,無法建立局部特征與全局特征之間的依賴關系。Transformer 結構打破了CNN 有限感受野的局限性,通過結構內的多頭自注意力機制建立特征圖中長遠特征信息的遠程依賴關系,能獲取全局感受野信息加強網絡對圖像全局信息的理解能力,并不需要像CNN 那樣堆疊大量卷積核加深網絡深度來提高感受野來建立圖像特征信息之間的全局聯系。所以本文受ViT 所啟發,將帶有高度全局上下文信息的特征圖?Z經過一層卷積層升維到與需要相乘的低分辨率特征圖Xj相同的空間維度得到矩陣Q,再經過兩個Transformer Encoder 模塊得到帶有高度上下文信息權重的注意力矩陣QN。
本文中Transformer Encoder 的輸入并沒有將輸入矩陣分為多個patch 輸入,而是直接輸入。每個Transformer Encoder 由多頭注意力(Multi-Head Attention)和多層感知機(MLP)兩個子層搭建而成,每層之間使用殘差結構進行連接,其結構圖如圖5 所示。
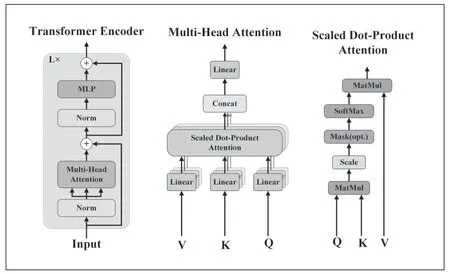
圖5 Transformer Encoder 模塊結構圖
多頭注意力機制是Transformer Encoder 結構中最重要的一層。輸入特征圖序列經過規范層歸一化,然后傳遞給由單頭自注意力組成的多頭注意力層。單頭自注意機制將輸入序列進行三次線性映射,其中包含三個全連接層,分別作為查詢向量(query,Q)、鍵向量(key,K)和值向量(value,V)。查詢向量和鍵向量的值經過矩陣乘法運算(MatMul)、縮放運算(Scale)、掩碼運算(Mask)和SoftMax 函數運算后的輸出序列與值向量相乘,生成有注意力的序列。注意力權重決定了模型應該關注其序列的哪些部分,可以有效提高檢測效率和準確率。單頭自注意的輸出結果可表示為:
其中dK是K的維度數。
網絡得到多個單頭自注意力權重序列后,再將多個權重序列組合成一個多頭注意力塊。Multi-head Attention 的每個head 都有不同的Q、K 和V,可以分別隨機初始化和加權。這個過程使整個注意力塊能夠在不同的關系子空間中合成不同的自注意力信息。將通過多頭注意力運算得到的注意力權重信息進行歸一化處理后最為多層感知器(MLP)的輸入。MLP 由兩個完全連接的層和ReLu 激活功能組成。MLP 過程數學公式表述如下所示:
其中:x是輸入序列即經過歸一化處理的多頭注意力輸出;W1、W2和b1、b2分別為兩個全連接層的權值和偏差。
3 實驗與分析
■3.1 實驗數據集
為驗證本文改進的YOLOv5s 目標檢測算法在道路背景下的有效性,本文使用目前國際上最大的自動駕駛場景下的計算機視覺算法評測數據集之一的KITTI[20]上進行實驗探究。KITTI 數據集集成了高速公路、市區、鄉村等多種場景的真實道路圖像數據,單張圖片中的目標最多可達到30 個行人目標和15 個車輛目標之多,同時KITTI 數據集中包含了許多不同程度的遮擋和截斷目標,對目標檢測算法有較大的挑戰性。KITTI 數據集中總共分為9 個目標類別:Car、Van、Truck、Tram、Pedestrian、Person_sitting、Cyclist、Misc、DontCare。本文在數據預處理階段對數據集的類別重新劃分,去除Misc 和DontCare 類,將Pedestrian、Person_sitting 合并成Pedestrian 類;并對KITTI 數據集總共7481 張帶數據標注的圖像按照8:1:1 的比例隨機劃分數據集、驗證集、測試集,其數據劃分如表2 所示。

表2 KITTI數據集劃分
■3.2 實驗環境和網絡訓練
本文實驗模型的搭建、訓練以及結果測試均是在基于Pytorch 神經網絡框架下完成的,需要調用較好的GPU(Graphics Processing Unit)設備結合CUDA(Computer Unified Device Architecture)并行計算架構解決GPU內部復雜的計算問題,同時使用CU-DNN(Cuda Deep Neural Network library)加速庫實現GPU 運算加速,本文實驗環境具體見表3。
表3 實驗運行環境
對于本文所有的網絡訓練超參數,經過多次參數調優,其輸入圖像分辨率均為416×416 大小,優化器為sgd,網絡訓練迭代次數為900,batch_size 大小為16,不采用預訓練模型訓練的方式,初始學習率為0.07,最小學習率為0.0001,學習率下降函數為cos 函數。
■3.3 實驗評測指標
在目標檢測領域,準確率(Precision)、召回率(Recall)、均值平均檢測精度(mAP)這三項指標能夠準確而且有效的對目標檢測算法的性能和可靠性進行有效的評估,其定義式如下所示。
其中,TP(True Positives)、TN(True Negatives)分別代表被正確分類的正樣本和被正確分類的負樣本;FP(False Positives)、FN(False Negatives)分別代表被錯誤分類的負樣本和被錯誤分類的正樣本。
平均精度(Average Precison,AP)是指某一類所有召回率的可能取值情況下得到的所有精度的平均值,比如AP50 表示在IoU 閾值取0.5 時對應的AP 值。均值平均精度(mAP)為所有類別AP 值相加的平均數。
■3.4 實驗結果對比分析
為更加直觀的體現本文對YOLOv5s 算法的不同改進點對原網絡模型的性能影響,本文對其進行了消融實驗,如表4 所示。可以看出使用K-means++聚類算法更新錨框參數以及加入本文提出的HCA 模塊均可提高網絡的檢測精度,將兩者相互融合可進一步提高網絡模型檢測精度。
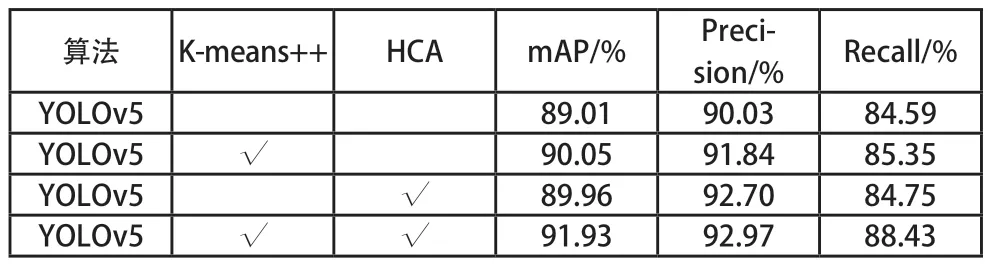
表4 消融實驗
為綜合分析本文所提算法(HCA-YOLOv5)算法的檢測性能,本文選擇在相同的配置條件,相同的數據集的環境下與YOLOv3、YOLOv4、YOLOv5 幾種具有代表性的onestage 目標檢測網絡模型進行對比實驗。其中本文所有對比實驗的網絡IoU 閾值設定均為0.5;實驗結果以準確率(Precision)、召回率(Recall)、均值平均檢測精度(mAP)作為評價指標,具體實驗結果如表5 所示。
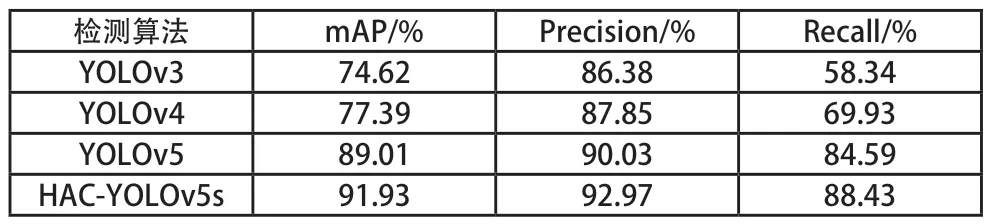
表5 不同目標檢測算法結果對比
由表5 數據分析可知,本文提出的HCA-YOLOv5 檢測算法的mAP 為91.93%,準率為92.97%,召回率為88.43%,相較于其他YOLO 系列經典檢測算法準確率、召回率、均值平均檢測精度上都有一定程度的提升,HCAYOLOv5 網絡在能夠結合城市道路場景中不同類別在不同高度的分布特征,更加有效的檢測出城市道路場景上的車輛行人目標。
為驗證HCA-YOLOv5 可以有效地改進網絡對目標的識別能力,本文提取出不同網絡模型之間的注意力可視化對比見圖6。對照圖6,可以看到HCA-YOLOv5 檢測網絡對目標存在的像素區間相對其他經典網絡模型有更高的關注度,并且關注區間能夠完全覆蓋目標本身,說明網絡能夠更好的學習到目標的特征信息,達到更高的檢測精度。

圖6 不同目標檢測算法注意力可視化對比圖
4 結語
本文結合城市道路場景的內在特性,提出一種基于改進的YOLOv5 城市道路車輛行人檢測算法——HCA-YOLOv5,旨在解決基于目標檢測算法的車輛行人檢測任務中存在目標檢測精度低、檢測位置不精準的問題。首先,使用K-Means++聚類算法對訓練數據集中檢測目標的錨框進行聚類,同時更新網絡的先驗錨框參數,使網絡更適應車輛行人目標的尺度特點。其次,利用城市道路場景圖片中不同類別在不同高度的分布特點,結合Transformer 模塊強大的特征信息采集能力,設計HCA 結構,讓網絡更容易提取到檢測目標的特征信息。實驗結果表明,HCA-YOLOv5 檢測算法有較好的檢測精度,并且網絡對檢測目標的關注度更高。為了提高網絡的檢測精度,HCA-YOLOv5 的模型參數量要略大于YOLOv5 檢測算法,未來將在減少模型參數量的基礎上做進一步提升。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
