基于稠密連接的多形性腺瘤輔助診斷
2023-09-27 01:06:32董立巖張玥敏朱曉冬張小利
吉林大學學報(理學版) 2023年5期
董立巖, 張玥敏, 朱曉冬, 張小利, 趙 博
(1. 吉林大學 計算機科學與技術學院, 長春 130012;2. 吉林大學 符號計算與知識工程教育部重點實驗室, 長春 130012)
多形性腺瘤(pleomorphic adenoma, PA)是最常見的唾液腺上皮性腫瘤, 惡性程度較高, 因其多種結構混雜在一起, 故又稱為“混合瘤”[1]. 在病理上, PA無明顯癥狀, 生長過程緩慢, 不易發現且存在惡變傾向[2], 其診斷需具備專業的醫學知識和臨床經驗, 耗時耗力, 易造成診斷錯誤或遺漏導致病情延誤[3]. 因此, 計算機輔助診斷成為解決該問題的一個有效途徑[4], 借助計算機不僅能提高醫生的工作效率, 還能為后續進行病情分析提供輔助信息[5].
隨著深度學習方法的不斷發展, 計算機被廣泛應用于醫療領域. 在醫學圖像分類領域, Arevalo等[6]通過構造特征學習框架首次解決了基于乳腺X射線照片的病變分類, 并獲得了較優結果. 在輔助診斷領域, Gao等[7]通過融合兩個2D卷積神經網絡對超聲波心電圖的信息特征進行了有效提取, 進而進行視點分類達到較優效果并實現了輔助診斷. 在醫學圖像定位領域, 楊亞男等[8]基于YoloV4構建了虹膜定位算法, 顯著提高了定位速度及效果. 此外, 丁通等[9]基于殘差網絡搭建了輕量級虹膜分類模型, 有效提升了模型學習速度. 在口腔相關疾病領域, Nanditha等[10]開發了一個集合深度學習模型, 該模型結合ResNet50和VGG-16, 并利用擴充的口腔病變圖像進行學習訓練, 基于口腔癌圖像進行癌癥類別確定. Welikala等[11]使用ResNet101結合Faster R-CNN為口腔癌的診斷首次提供了自動化的解決方案. 雖然目前已有很多相關研究[12-16], 但針對多形性腺瘤的輔助診斷還沒有完整的數據集和有效的方法.
基于深度學習模式的輔助診斷模型方法能自動實現醫學影像的疾病診斷, 具有廣泛的應用場景[17], 也為多形性腺瘤的病理診斷提供了新的方向和可能性. 因此, 本文首先構建多形性腺瘤病理切片數據集, 并對圖像進行預處理; 其次通過構建深度學習方法, 使模型能有效提取組織進行分類識別, 實現多形性腺瘤的關鍵特征提取, 準確率達97.7%; 最后根據提取到的特征及其類別概率得分, 利用決策樹進行推理診斷, 訓練得到的決策樹準確率達100%, 具備一定的有效性.
1 數據集構建
1.1 應用領域要求
多形性腺瘤中各組織成分的比例不同, 細胞形態結構多樣, 導致腫瘤的組織結構復雜, 具有結構上多形性的特點. 常見的病理切片如圖1所示.
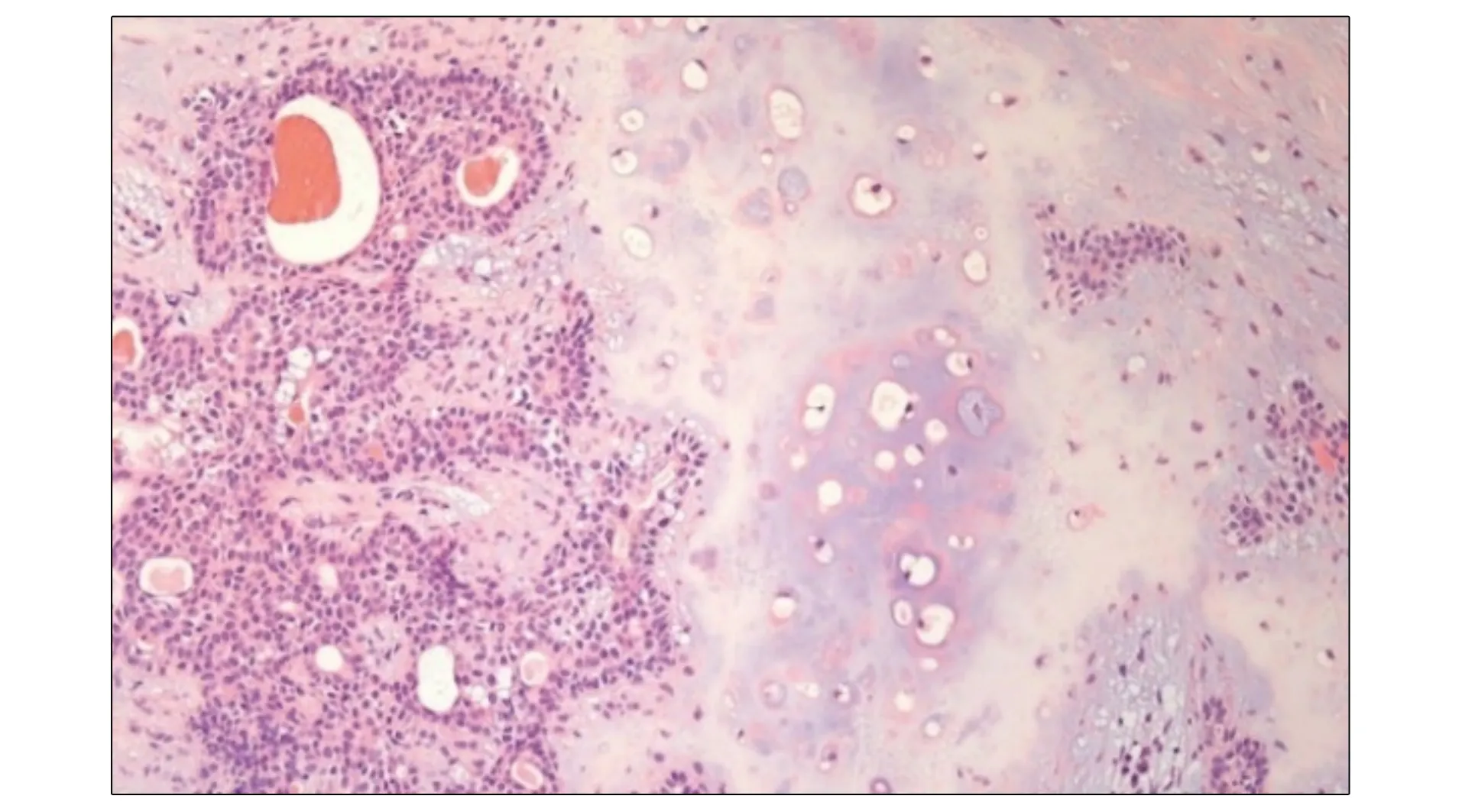
圖1 多形性腺瘤病理切片Fig.1 Pathological section of pleomorphic adenoma
診斷任務中需要識別的4類組織為: 腺管樣結構、 肌上皮細胞、 黏液樣組織和軟骨樣組織[18]. 其中, 腺管結構呈雙層細胞排列, 即內層的腺管上皮細胞和外層的肌上皮細胞. 肌上皮細胞呈梭形和多角形, 界限不清. 黏液樣組織和軟骨樣組織常見片狀, 細胞呈星狀, 有細長突起互相連接. 若細胞呈空泡性變, 核固縮, 則酷似透明軟骨的細胞位于軟骨的“陷窩”內. 多形性腺瘤4類組織結構如圖2所示.

圖2 多形性腺瘤4類腫瘤組織Fig.2 Four types of tumor tissues of pleomorphic adenoma
若病理切片同時存在腺管樣結構及肌上皮組織或黏液樣組織或軟骨樣組織, 則可推理診斷為多形性腺瘤. 因此, 本文需要在結構復雜的病理切片中準確識別出4類目標組織, 并結合識別到的信息進行推理, 給出診斷信息.
1.2 數據集構建及圖像預處理
本文構建的數據集來自于吉林大學口腔醫院多形性腺瘤患者的病理切片圖像, 共采集到13 390張原始病理切片, 樣本在顯微鏡下放大200倍, 像素為1 920×1 080, 其中9 725張為無病樣本, 3 665張為確診樣本.
為達到準確提供診斷信息的目標, 本文通過滑動窗口的方式, 將較大的病理圖片切割為較小的圖片進行識別分類, 達到大致提取特征的目的, 在節省時間的同時具有足夠的有效性.
本文選用大小為512×512, 步長為1/2邊長的滑動窗口進行自動切割, 獲取到有效的小切片共374 740張, 部分切片如圖3所示. 創建5個類別文件夾, 分別為4類目標組織及1類正常組織, 在學習專業醫學知識后人工將切割后的小切片放入對應的類別文件夾中. 共獲取14 826張軟骨組織切片, 59 607張腺管樣組織切片, 4 659張黏液樣組織切片, 58 696張肌上皮組織. 完整數據集中各類組織數量不一, 為避免模型過度依賴某種特征, 在后續的訓練測試中對數據集進行進一步篩選擴充.

圖3 部分切片Fig.3 Partial slicing
2 模型設計
本文構建一個基于神經網絡和決策樹的多形性腺瘤輔助診斷模型, 由特征提取組織分類、 基于決策樹診斷推理和人工輔助3部分構成, 整體結構設計如圖4所示.

圖4 整體結構設計Fig.4 Overall structure design
在特征提取模塊中, 首先對輸入的病理切片使用大小為512×512的滑動窗口進行自動切割處理, 步長為窗口的1/2, 將原圖轉換為合適的大小, 對病理切片進行特征提取分類. 預處理后的數據首先通過一個步長為2、 大小為7×7的卷積層, 卷積核個數為64; 然后利用一個步長為2、 大小為3×3的最大池化操作縮小特征圖. 輸出的特征圖通過構建的分類網絡進行處理, 結構如圖5所示.

圖5 特征提取分類模塊結構Fig.5 Structure of feature extraction and classification module
考慮到低級特征在病理圖片中的重要性, 網絡結構使用了稠密連接[19-20], 使頂層獲取到的特征能傳遞到后面的層. 盡管網絡中每層特征圖都包含了豐富的特征信息, 可以檢測到大感受野的數據, 但仍然難以獲取空間信息并識別隱藏在特征圖中的特征. 因此, 為增強特征圖中重要特征的關注度, 模型在每個塊中添加了通道注意力機制[21-23], 構造了兩種SE-conv塊, 使用注意力向量對當前階段的特征圖進行重新加權, 并引導模型更關注特征.
前兩個SE-conv塊1的結構如圖6(A)所示, 結構中僅使用一次1×1卷積進行降維和3×3卷積提取特征; 后兩個SE-conv塊2的卷積操作則重復兩次, 結構如圖6(B)所示. 為保證每層間輸出的特征圖能進行連接, 需要保持尺寸一致, 因此每個密集塊間需要進行特征圖的壓縮, 結構如圖6(C)所示. 經過反復壓縮, 特征圖會縮小到較小的尺寸, 最后通過全連接層和Softmax輸出對每個切片的結果, 展示具有有效診斷信息的切片, 并提供類別結果信息和概率.
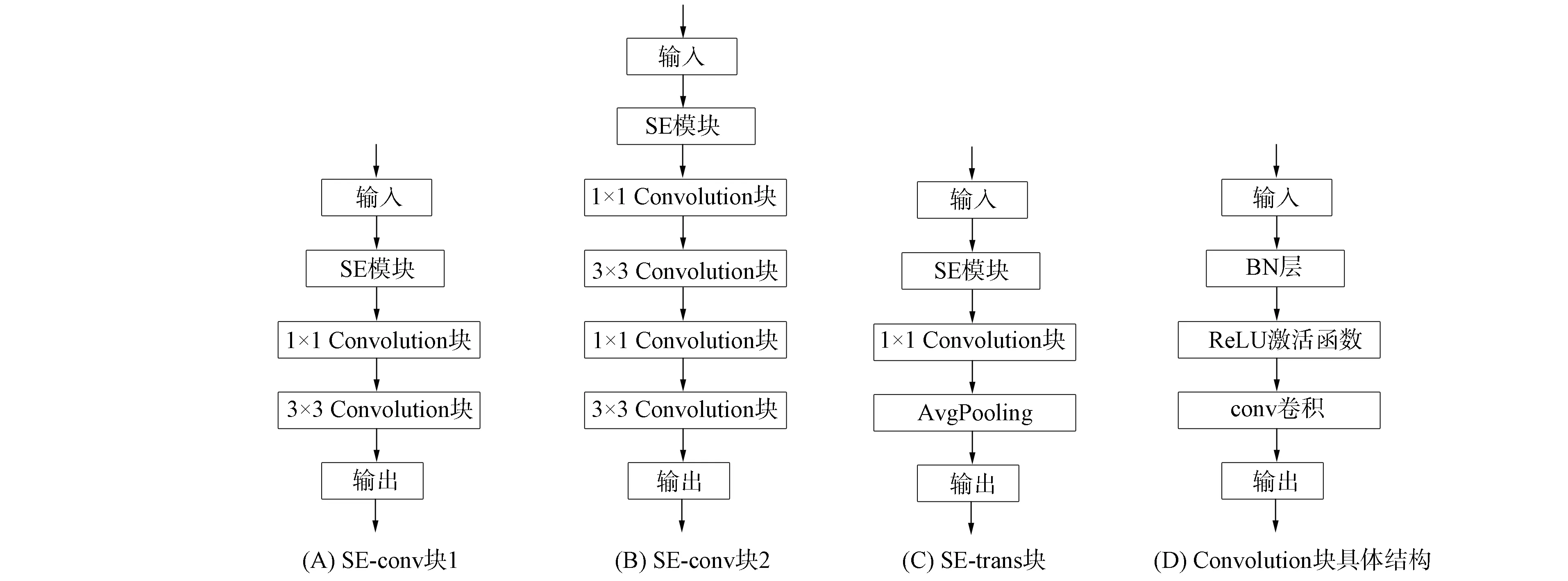
圖6 特征分類提取模塊結構Fig.6 Structure of feature classification extraction module
將通過特征提取后得到的結果進行綜合推理, 其中特征提取后已經得到該病理切片具有哪些類型組織, 僅需要依據醫學知識進行推理, 診斷該病理切片是否為多形性腺瘤. 因此, 本文選用計算量較小的決策樹進行下一步的決策推理. 將提取到的特征輸入訓練好的決策樹中進行推理診斷, 并提供診斷信息. 本文選擇基于Gini指數的CART(classification and regression tree)進行決策推理, 通過有監督訓練得到的決策樹結構如圖7所示.
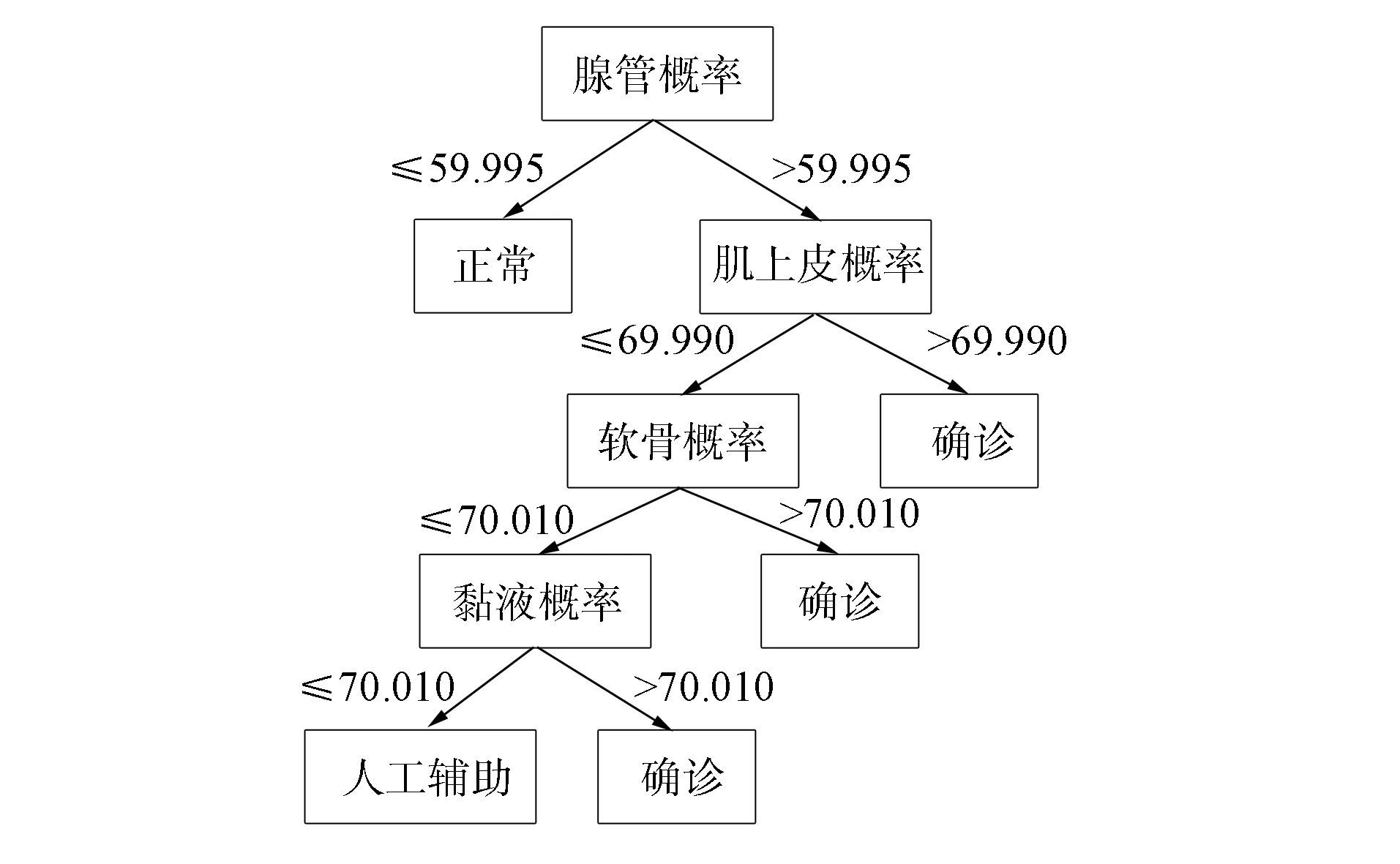
圖7 診斷決策樹Fig.7 Diagnostic decision tree
由圖7可見: 若存在腺管組織結構的概率較低, 即可判斷該病例為PA的可能性較低, 認定為正常組織; 若較高概率存在腺管結構, 則進入下一步判斷, 若存在較高概率為肌上皮組織, 即可認為是PA, 否則進入下一步判斷; 順次對軟骨組織和黏液樣組織進行判斷. 同時, 模型增加了人工輔助分支, 使得整個模型并不完全依賴于計算機, 而是提供一定程度上的人工輔助, 具有更好的魯棒性. 此外, 本文以多形性腺瘤為例進行訓練學習, 實際使用中也可遷移至其他病理切片進行學習使用.
3 實 驗
3.1 數據集構建
本文收集吉林大學口腔醫院多形性腺瘤患者的病理切片圖像作為研究數據, 篩選后用于訓練的數據集共48 230張, 其中9 639張軟骨組織, 9 591張腺管組織, 9 318張黏液組織, 9 794張肌上皮組織, 9 888張非以上4類組織. 其中實際采集到的黏液組織共4 659張, 考慮到訓練模型的效果, 使用數據增廣進行了擴充. 針對輔助診斷任務, 特征提取模塊是任務的核心, 故構造的數據集主要用于驗證評估本文方法中特征提取分類模塊的分類效果.
3.2 實驗參數設定
實驗環境基于Pytorch深度學習框架, 硬件配置采用的GPU為Nvidia RTX 2080 TI, 處理器為Intel i9 10900X, 系統內存為64 GB. 初始學習率為 0.001, 使用余弦衰減方法, 批次大小為32, 迭代次數設為80.
3.3 數據增廣
在原數據集中, 黏液組織樣本與其他類別嚴重不平衡, 為提高模型的效果, 對黏液樣本進行擴充, 利用翻轉操作將原數據集擴大一倍, 使數據集的各類別間達到相對平衡的狀態, 從而更有利于模型優化. 對數據增廣進行對比實驗的結果列于表1. 由表1可見, 擴充數據集后, 能在一定程度上提高模型的效果, 對模型優化有正向作用.

表1 擴充數據集實驗對比Table 1 Comparison of experiments with expanded datasets
3.4 分類識別評價比較
針對本文模型中分類識別模塊, 為驗證本文提出模塊分類的性能和效率, 進行以下對比實驗.
3.4.1 與深度學習算法比較
不同深度模型的實驗對比結果列于表2. 由表2可見, 本文模型的準確率最高, 為97.7%. 為評估模型效率, 表3列出了在輸入圖像分辨率為224×224像素時幾種不同算法的參數量和計算量. 其中: 參數量是模型所含參數數量, 代表了模型文件的大小, 也影響模型推斷時對電腦內存的占用量; 計算量是模型推斷時所需的計算次數. 這兩個指標能評價模型在實際應用中的魯棒性、 可擴展性以及對實際資源的依賴程度.

表2 不同深度模型實驗對比結果Table 2 Experimental comparison results of different depth models

表3 不同深度模型參數量和計算量對比結果Table 3 Comparison results of amount of parameters and calculation for different depth models
上述實驗結果表明, 本文模型具有最高的準確率, 為97.7%. 相比于殘差網絡ResNet34, 本文方法在腺管的精確度、 肌上皮的召回率以及腺管的特異度3個指標上相比降低了1.2%,1.2%,0.3%, 且計算量和參數量分別減少了91.3%和98.1%. 與同結構但層數更多的模型相比, 本文模型相比于21層基線模型, 在軟骨的精確度、 黏液的召回率以及軟骨的特異度3個方面分別降低了1.3%,0.4%,0.3%, 但模型的計算量和參數量分別減少了13.4%和26.3%. 相比于35層基線模型, 分別在黏液的精確度、 非4類的召回率和黏液的特異度3個方面降低了0.7%,1.4%,0.2%, 但模型的計算量和參數量分別減少了48.8%和65%. 在其余指標上, 本文模型均為最優, 同時也具有最少的計算量和參數量. 因此, 本文具有相對最優的效果以及最少的計算量和參數量, 更好的魯棒性、 更優的擴展性以及對資源較低的依賴程度, 能適應更廣泛的應用場景.
3.4.2 消融實驗
為驗證本文構造分類模塊中融合通道注意力機制的有效性, 進行消融對比實驗, 結果列于表4. 由表4可見, 加入SE模塊后重構的模型在準確率方面能提高1.1%, 且各類組織的各項指標上均有明顯提升.

表4 消融實驗對比結果Table 4 Comparison results of ablation experiments
3.4.3 交叉驗證
為充分利用有限數據集中盡可能多的有效特征, 從不同角度挖掘數據中隱含的信息, 避免在訓練過程中模型出現過擬合現象, 驗證模型的泛化能力, 本文選用k=5的交叉驗證對模型進行評估測試, 測試結果列于表5. 由表5可見, 在數據集有限的情況下, 5個類別的平均準確率可達97.38%, top-1準確率可達97.7%. 實驗結果表明, 本文的算法模型具有較好的有效性, 并具有一定的泛化能力.

表5 五折交叉驗證結果Table 5 Fifty-fold cross-validation results
3.5 決策樹構建
針對推理決策部分, 本文利用13 390組樣本數據進行訓練, 其中包括診斷結果為多形性腺瘤的病例3 665例, 診斷為非多形性腺瘤的病例6 101例, 需要人工輔助的病例3 624例. 本文選用CART進行學習, 其中訓練集和測試集按7∶3進行隨機分割. 利用混淆矩陣及準確率進行評估, 得到訓練和測試的混淆矩陣如圖8所示, 其中標簽0表示診斷為正常組織, 標簽0.5表示需要人工輔助診斷, 標簽1表示診斷為多形性腺瘤. 由圖8可見, 訓練集和測試集的準確率均達到1.0.

圖8 混淆矩陣Fig.8 Confusion matrix
3.6 遷移實驗
為驗證本文特征提取模塊的普適性, 將本文特征提取模塊應用于其他醫學類數據集----檢測和分類血細胞亞型進行實驗驗證. 該數據集來源于Kaggle開源數據集[24], 共包含12 500張帶有細胞類型標簽(CSV)的增強血細胞圖像(JPEG). 4種不同細胞類型中的每種都約有3 000張圖像, 這些圖像被分到4個不同的文件夾中(根據細胞類型). 4種細胞類型分別是嗜酸性粒細胞、 淋巴細胞、 單核細胞和中性粒細胞.
在該公開數據集的分類任務中, Laurin[25]以0.75∶0.25劃分訓練集和驗證集, 通過疊加卷積層、 最大池化層、 Dropout操作和全連接層等, 最終達到97.8%的準確率; Yvtsan[26]利用ResNet達到96%的準確率; Kamal[27]利用多種結構的卷積塊疊加構造卷積神經網絡, 最終驗證集準確率達98%, 測試集準確率達98.6%.
本文將數據集按8∶2分為訓練集和測試集, 模型的訓練方式與上述相同, 同樣使用交叉熵函數和Adam作為損失函數和優化方式. 模型訓練結果列于表6. 由表6可見, 本文方法在血細胞分割4個類別的平均準確率達到99.1%, 4個類別的精確率、 召回率和特異度也有優異表現, 驗證了本文方法能適應于其他醫學圖像, 可以進行醫療輔助檢測工作.

表6 遷移實驗結果Table 6 Results of migration experiment
綜上所述, 針對多形性腺瘤的診斷主要依賴于專家對病理切片的分析判斷, 需要占用醫生大量時間且需要充足的專業知識及豐富的臨床經驗的問題, 本文提出了一種端到端的基于稠密連接和通道注意力機制的模型方法, 并結合決策樹推理判斷構成多形性腺瘤的病理輔助診斷方法. 實驗結果表明, 本文方法對多形性腺瘤病理切片的關鍵組織具有良好的識別分類效果, 最高準確率達97.7%, 決策樹推理準確率達100%, 且模型結構較小, 對資源依賴性較低, 能達到輔助醫生診斷多形性腺瘤的目的.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
