改進Apriori算法的高校圖書館圖書智能推薦系統
2023-10-12 09:41:44陳桂菊
微型電腦應用 2023年9期
陳桂菊
(浙江醫藥高等專科學校,圖書館,浙江,寧波 315100)
0 引言
隨著信息化技術的迅猛發展,人們獲取知識的意愿越來越強,圖書作為人們獲取知識的一個重要渠道,尤其是高校圖書館積累了大量的圖書資,閱讀者隨時隨地通過互聯網獲取知識[1]。由于高校閱讀者數量不斷增加以及圖書數量的增多,所有高校均建立了圖書館管理系統,在圖書館管理系統的實際應用過程中,如何從浩瀚的圖書資源中快速、準確地找到閱讀者需要的圖書十分關鍵,提高圖書館的個性化服務水平和圖書資源的利用率,對于圖書館來說是一個面臨的巨大的挑戰,也是當前環境下圖書館需要解決重要課題[2]。高校圖書館圖書智能推薦系統是以閱讀者為中心,根據閱讀者之間的差異性,給閱讀者推薦最合適合圖書的一種系統,因此構建性能優異的高校圖書館圖書智能推薦系統是當有一個熱點[3-4]。
為了獲得更優的高校圖書館圖書智能推薦結果,提出了改進Apriori算法的高校圖書館圖書智能推薦系統。利用改進Apriori算法對借閱者和圖書之間的關聯進行分析和挖掘,建立兩者之間的關聯規則,根據關聯規則進行借閱者的個性化圖書信息推薦,仿真實驗結果表明,改進Apriori算法的高校圖書館圖書推薦精度和推薦時間均優于其它高校圖書館圖書智能推薦系統。
1 相關工作
國外對高校圖書館圖書智能推薦系統的在研究時間比較早,具有代表性的圖書推薦系統為:MyLibrary、Foxtrot,其中MyLibrary是一個基于內容的圖書推薦系統,將圖書館的新資源根據用戶需求特征、用戶的興趣推薦給閱讀者,其技術十分成熟,當前國內許多高校圖書也使用該系統[5]。Foxtrot是一個基于內容和項目的高校圖書館圖書智能推薦系統,引入本體論對閱讀者的行為進行描述,根據閱讀者的行為間的相似度和圖書資源信息進行圖書資源推薦[6]。國外對高校圖書館圖書智能推薦系統雖然很好,但是由于與國內國外對高校圖書館管理模式有一定的差異,因此有時推薦效果不太理想,因此國內一些研究機構和高校,在MyLibrary系統的基礎上,開了適合于自己高校圖書館圖書智能推薦系統,如基于協同過濾的高校圖書館圖書智能推薦系統、基于關聯規則的高校圖書館圖書智能推薦系統、基于數據挖掘技術的高校圖書館圖書智能推薦系統等[7-9],但是它們均存在各自的不足,如沒有考慮圖書資源差異性、存在冷啟動的問題,校圖書館圖書推薦誤差大,推薦結果并非全局最優[10-12]。
2 改進Apriori算法的高校圖書館圖書智能推薦系統
2.1 高校圖書館圖書智能推薦系統的基本構架
高校圖書館圖書智能推薦系統建立的目標為幫助閱讀者從大規模的圖書中快速發現自己真正需要的圖書信息,一個高校圖書館圖書智能推薦系統的基本構架應如圖1所示。
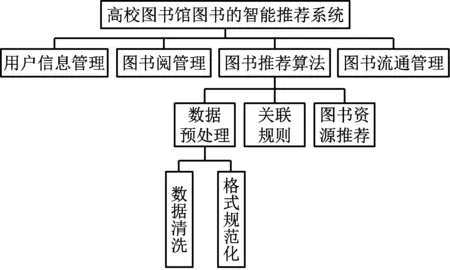
圖1 高校圖書館圖書智能推薦系統的基本構架
圖書推薦模塊主要包括:數據預處理模塊,關聯規則挖掘模塊和圖書推薦模塊,其中數據預處理子模塊功能為:從讀者借閱數據庫中提取圖書以及借閱者相關信息,并搜集數據進行清洗、轉換以及集成處理;關聯規則挖掘子模塊功能為:利用改進Apriori算法將處理后數據作為挖掘項集,挖掘支持度大于最小支持度閾值以及置信度大于最小置信度閾值的強關聯規則,形成關聯規則庫中;個性化圖書推薦子模塊將關聯規則數據庫同借閱者所選圖書進行關聯匹配,向借閱者推送與所讀圖書相關聯圖書信息,實現圖書信息的個性化推薦功能。從圖1可以看出,關聯規則挖掘模塊是核心模塊,直接影響高校圖書館圖書智能推薦系統的性能,本文采用改進Apriori算法實現圖書館圖書智能推薦算法。
2.2 數據的預處理
高校圖書館圖書智能推薦系統的進行工作時,需要對借閱者、圖書數資源據進行數據預處理,主要包括數據清洗和格式規范化,如:讀者信息和圖書信息的清洗,實現系統推薦的圖書數據信息的準確匹配。通常情況下,原始數據清洗主要目的是為了將原有數據中噪聲、不完整數據進行消除。在圖書館推薦系統中,不完整的數據包括同名、但格式同的數據,對它們進行改動或刪除。針對該類型數據,在不影響總體數據庫條件下直接進行刪除;也可以進行修改,將其屬性以及格式進行一致化,具體如式(1)。
(1)
式中,p表示清洗后的圖書推薦數據,∑q0(t)表示清洗前圖書的數據總和,qk(t)表示噪聲,qm(t)表示屬性不一致圖書數據,l表示清洗次數,f(t)表示數據清洗函數。
在對數據清洗理之后,存在數據處理不準確或數據信息丟失的問題,需要對預處理后數據進行格式規范化,即數據轉換和集成,以確保最終系統分析推薦的數據最為準確。在進行數據集成時,考慮數據庫中數據進行集成后會不會產生多余數據,若產生多余數據需進行處理,保證系統空間充足,也可能存在兩個推薦圖書數據信息以及屬性等不一樣,但也存在產生多余數據的可能。
2.3 關聯規則
不同項集合為:I={i1,i2,…,im},任務相關的數據D為事務數據庫的集合,每一個事務T是一組項的集合,那么A?I。設A是一個項集,那么有A?T。關聯規為一個A?B的蘊涵式,同進滿足條件:A?I,B?I,A∩B=Φ。關聯規則有兩個重要概念:支持度和置信度兩個閾值,它們分別定義如式(2)、式(3)。
sup(A?B)=sup(A∩B)
(2)
con(A?B)=sup(A∩B)/sup(A)
(3)
式中,sup為支持度support簡寫。
關聯規則中超過最小支持度(min_sup)和最小置信度(min_conf)的規則,稱之為強關聯規則。
2.4 改進Apriori算法
Apriori算法使用一種稱為逐層搜索的迭代方法,其工作步驟如下。
Step1:生成長度為1的頻繁項集,記為L1。
Step2:在Lk的基礎上,生成候選項目集Ck+1。
Step3:用事務數據庫D中的事務對Ck+1進行支持度測試,生成長度為k+l的頻繁項集Lk+1,計算每個候選項目集的支持度,若大于min_sup,那么加入到Lk+1中。

傳統Apriori算法在實際應用中存在兩個不足,分別如下:
(1) 尋找每個k-頻繁項集需掃描數據庫一次,當k很大時,將耗費時間長,工作效率低。
(2) 在判斷Ck的(k-1)子集是否在Lk-1中,需頻繁掃描Lk-1,當Ck很大時,將耗費時間長,工作效率極低。
針對Apriori算法存在以上的缺陷,本文提出了改進Apriori算法,具體工作步驟:
Step1:產生L1和各子集的支持度計數。
Step2:根據L1對D進行重新組織,刪掉沒有在L1中出現的項,通生成的數據庫Dnew。
Step3:對Dnew進行掃描,初始支持數為0,利用Subset函數找出Dnew的所有子集,不斷重復,直到掃描完整個Dnew,得到全部候選子集的支持度計數。
Step4:將前面得到的所有候選子集與min_sup進行比較,產生集合Lk。
2.5 改進的Apriori算法的高校圖書館圖書智能推薦關聯規則挖掘模型
在本文高校圖書館圖書智能推薦系統中,改進Apriori算法建立圖書智能推薦關聯規則挖掘模型,主用對借閱者和圖書之間的關聯進行分析和挖掘,建立兩者之間的關聯規則通過建立的關聯規則進行借閱者的個性化圖書信息推薦,具體如圖2所示。
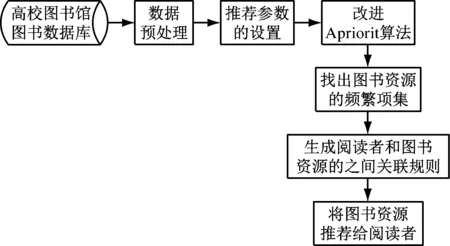
圖2 改進Apriori算法的圖書推薦關聯規則挖掘模型
3 高校圖書館圖書智能推薦系統性能測試
3.1 測試場景
為了分析改進Apriori算法的高校圖書館圖書智能推薦系統的性能,用VC++對編程實現仿真測試,測試場景設置如表1所示。

表1 高校圖書館圖書智能推薦的測試場景
在同樣的測試場景下,選擇傳統Apriori算法的高校圖書館圖書推薦系統、文獻[8]的高校圖書館圖書推薦系統進行對比測試,分析進Apriori算法的高校圖書館圖書智能推薦系統的優越生。
3.2 測試數據
采用高等院校圖書管理系統數的據作為測試數據,借閱者數量為20 000,圖書數量為150 000本,采用隨機方式選擇部分借閱者和圖書作為實驗對象,共進行5次實驗,為了使高校圖書館圖書智能推薦實驗結果具服說服力,每一次實驗的借閱者和圖書數量采用隨機方式選擇,具體分布如表2所示。

表2 仿真測試的借閱者和圖書數量分布
3.3 測試結果與分析
統計3類高校圖書館圖書智能推薦系統的精度,結果如圖3所示。
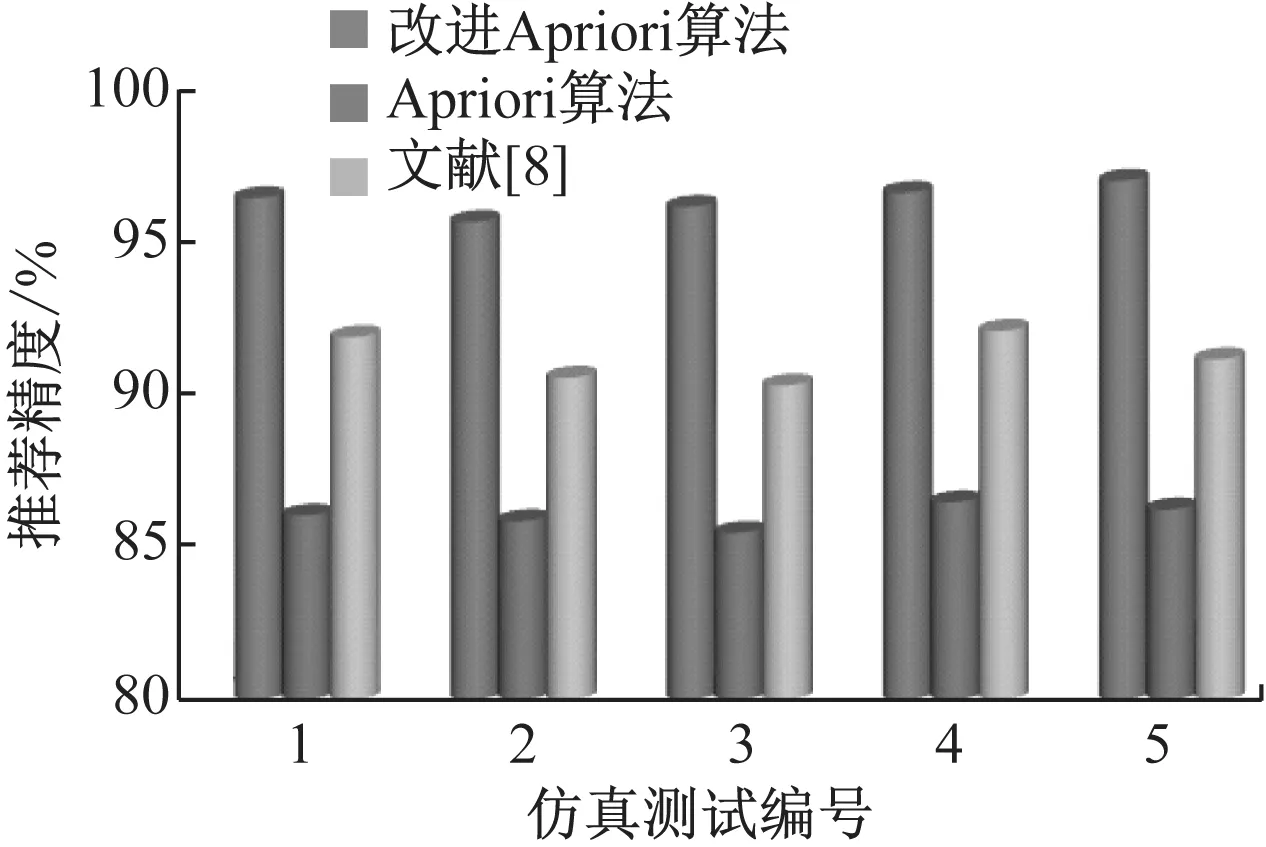
圖3 不同系統的高校圖書館圖書推薦精度對比
從圖3可以看出,改進Apriori算法的高校圖書館圖書智能推薦精度明顯優于傳統Apriori算法,說明本文對Apri-ori算法改進是有效的,同時可以發現,改進Apriori算法的高校圖書館圖書智能推薦精度也要高于文獻[8]的高校圖書館圖書推薦精度,表明改進Apriori算法解決當前高校圖書館圖書推薦過程中存在的不足,降低了高校圖書館圖書推薦錯誤率。
統計3類高校圖書館圖書智能推薦系統的運行時間(秒,s),結果如圖4所示。
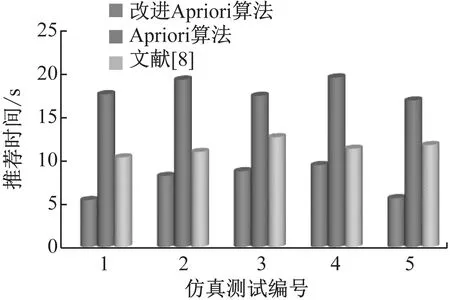
圖4 不同系統的高校圖書館圖書推薦時間對比
從圖4可以發現,改進Apriori算法的高校圖書館圖書智能推薦系統的運行時間平均少于傳統Apriori算法和文獻[8],減少高校圖書館圖書智能推薦的時間復雜度,可以應用于海量借閱者和圖書數量的高校圖書館管理系統,可以從網上在線給借閱者推薦最優的圖書。
4 總結
傳統高校圖書館圖書智能推薦系統存在運行效率低、誤推薦率高等弊端,針對針對Apriori算法的不足,提出了改進Apriori算法的高校圖書館圖書智能推薦系統。收集高校圖書智能推薦系統中的借閱者和圖書相關信息,引入改進Apriori算法建立個性化圖書信息推薦規則,結果表明,改進Apriori算法建立了一種高精度、效率高的高校圖書館圖書推薦系統,可以在短時間為閱讀者推薦最合理的圖書,獲得了比其它高校圖書館圖書推薦系統更高的實際應用價值。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
