融合法條的司法裁判文書摘要生成方法
2023-10-12 01:11:14魏鑫煬秦永彬唐向紅黃瑞章陳艷平
計算機工程與設計 2023年9期
魏鑫煬,秦永彬,2,唐向紅,2+,黃瑞章,2,陳艷平,2
(1.貴州大學 計算機科學與技術學院,貴州 貴陽 550025;2.貴州大學 省部共建公共大數據重點實驗室,貴州 貴陽 550025)
0 引 言
通過對我國法官案件判決過程的調研發現,法官的審判過程中包含有“從案件事實認定,到法律適用選擇,最后得出裁判意見”的審判邏輯脈絡[1]。裁判文書是總結法官審判過程的重要文書,是體現法官審判依據的重要載體,這也意味著裁判文書中蘊含著法官在整個案件審判過程中的審理邏輯脈絡;通過裁判文書我們就能夠從中發現“案件事實,適用法律,裁判意見”之間的關聯關系,這也是裁判文書重要的邏輯結構特點。而文本摘要任務旨在從一篇或多篇相同主題的文本中抽取能夠反映主題的精簡壓縮版本[2,3],這就意味著裁判文書的摘要也蘊含有重要的法官審理邏輯脈絡,如圖1所示。

圖1 專家摘要中法條與案情描述的對應關系
從圖1給出的裁判文書專家摘要示例中可以看出,案件涉及到的主要法條為《中華人民共和國繼承法》第二條、第三條、第五條和第十條,而專家摘要的案情部分均與這幾個法條高度關聯。傳統的文本摘要方法直接應用于司法文本時沒有考慮這一重要的邏輯結構特點,會導致生成的最終摘要丟失了相關的重要信息,從而使摘要性能達不到預期效果。
因此,通過分析這一重要的法官審理邏輯脈絡,我們發現法條的選擇與案件的案情描述有著強烈的聯系。所以本文參考法官這種審理過程中的審判邏輯脈絡,充分利用法條這一外部知識,通過法條輔助生成裁判文書的摘要,使得生成的裁判文書摘要能夠最大程度保留原文中的關鍵信息,提升司法摘要生成的性能。
1 相關工作
自動文本摘要生成算法按實現方式一般分為抽取式(extractive)和生成式(abstractive)[4]。對于傳統的抽取式摘要技術,主要是通過統計文本中的共現信息來進行自動文本摘要生成;Mihalcea等[5]提出的Textrank算法為傳統抽取式摘要生成算法的代表之一。這些算法主要是通過統計文本中的一些文本特征來進行重要成分篩選,但是對于裁判文書,包含有冗長的案情描述部分,甚至一些重要的事實或證據都不會贅述,文本特征并不明顯,運用傳統的統計方法容易將這些重要信息丟失。隨著機器學習的發展,許多研究人員也將機器學習算法運用到文本摘要任務中;Nallapati等[6]提出SummaRuNNer,Liu[7]提出Bertsum,它們均是采用序列標注的方法抽取出重要的句子組成摘要;這類方法需要提前標注好的數據,并且它們都是進行句子級別的建模,從而忽略了文檔中關鍵詞的作用。
相對于抽取摘要來說,生成式摘要的發展時間比較短;See等[8]在基于注意力機制的seq2seq[9]模型基礎之上提出了指針生成網絡,有效緩解了oov(out-of-vocabulary)問題,可讀性問題和重復詞問題;近年來隨著bert[10]的發展,許多基于bert預訓練的文本摘要生成技術被提出,并取得了不錯的效果,如BertSumExt[11]和基于UniLM[12]的方法。生成式文摘方法大多都趨向端到端的過程,這就導致了文本摘要生成過程的封閉性,完全由模型自行訓練,沒有額外信息的輔助,這就會導致原文本中許多重要信息的丟失;在關鍵信息眾多且細微的裁判文書中更是如此。
通過引入外部知識能夠有效幫助指導模型保留文章的重要信息,Kai等[13]通過構建模板從文中抽取出關鍵信息來指導摘要生成;Kundan等[14]通過引入文章的話題作為外部知識輔助摘要的生成;Chen等[15]提出了KIGN模型,該模型通過TextRank抽取出文章中的關鍵信息來輔助文本摘要生成;但是由于裁判文書的結構性以及包含有法官的審判邏輯脈絡,用TextRank對原文本進行關鍵字抽取,依舊會丟失許多重要的信息。因此本文參考法官的審判邏輯脈絡,利用法條逆向輔助保留裁判文書中的重要信息,使得生成的摘要更加符合專家摘要的形式,從而提升摘要生成的性能。
對于司法領域的自動文本摘要,國外的發展要比國內早,目前其主要是利用統計模型,圖模型以及分類模型等傳統文摘模型[16]來對司法文本進行自動化摘要生成[17]。但是由于國內外的司法體系的不同,國外的司法文本摘要方法并不適用于我國的司法文本摘要生成。而國內相關的司法領域摘要研究尚處于初級階段,因此本文主要參考新聞領域的摘要研究方向,結合司法領域特點來進行相關的摘要方法研究。
2 方法介紹
2.1 方法概述
基于法官的審判過程和審理邏輯脈絡,本文通過引入法條作為外部知識,以此來輔助裁判文書的司法摘要生成。首先對于裁判文書原文部分,我們利用經典的指針生成網絡構建一個encoder-decoder框架的抽取式摘要生成模型;然后基于attention機制構建一個關于法條的外部知識編碼器;最后將兩個模型進行融合輸出,通過外部知識來輔助生成最終的司法摘要。整體的模型架構如圖2所示。
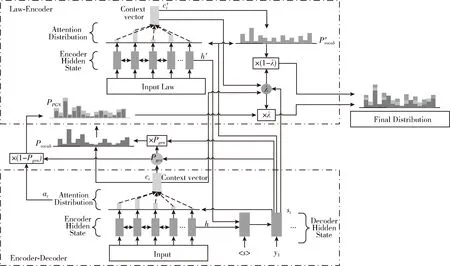
圖2 融合法條的司法裁判文書摘要生成模型
2.2 seq2seq模型
在通用領域的自動文摘技術中,Seq2Seq已經成為了一個主流的模型框架,本文采用的基礎模型也是基于Seq2Seq模型的指針生成網絡。Seq2Seq的模型結構主要包含Encoder和Decoder兩個過程,通過Encoder將源文本映射成一個向量,然后Decoder將中間向量轉換為相應的文本摘要;即首先將擁有N個詞的源文檔S=(w1,w2,w3,…,wN) 依次輸入Encoder端編碼成一個中間層的隱藏狀態,之后用Decoder來將該隱藏狀態進行解碼,最后輸出含有M個詞的序列Y=(y1,y2,y3,…,yM)。
經典的Seq2Seq在Encoder端是一個雙向的LSTM,這個雙向的LSTM可以捕捉原文本的長距離依賴關系以及位置信息,編碼的詞嵌入經過雙向LSTM后得到編碼狀態hi。 在Decoder端,解碼器是一個單向的LSTM;在訓練階段,Decoder端將參考摘要詞依次輸入,在時間步t得到解碼狀態st; 最后結合上下文向量ct計算得到詞典的概率分布Pvocab, 用于預測生成的下一個詞。其中上下文向量ct使用注意力機制計算得到,具體計算過程如下
(1)
at=softmax(et)
(2)
(3)
Pvocab=softmax(f(st,ct))
(4)
其中,v,Wh,Ws,battn均為可學習的參數,f表示一個線性函數;得到的注意力分布at可以看作是源文檔S中詞的概率分布,用來幫助decoder生成下一個詞。
2.3 指針生成網絡
指針生成網絡(pointer-generator network,PGN)是基于Seq2Seq的文本摘要生成模型,它結合傳統的Seq2Seq模型與指針網絡,通過指針(pointer)機制從源文本中復制單詞,有助于準確地復制信息,同時保留通過生成器產生新單詞的能力。
傳統的seq2seq在計算權重之后會對Encoder的狀態進行加權,得到上下文向量c,以此來計算出詞典概率分布Pvocab; 而指針網絡則在計算權重之后選擇概率最大的Encoder狀態作為輸出,即計算得到輸入源文本的詞的概率分布at。 指針網絡使用不同于傳統seq2seq的注意力機制來從輸入序列中選擇合適的詞作為模型的輸出,這有助于準確地復制信息,并且使得模型在輸出序列中可以有機會生成未錄入詞典的新詞。
對于本文的司法摘要任務來說,由于詞典的大小是有限的,許多關鍵的詞語可能不會被收錄在詞典中,這就可能使得在生成最終摘要時丟失了這些關鍵信息。我們可以通過Seq2Seq模型計算得到相應的詞典概率分布Pvocab(w), 以及通過指針網絡計算相應的輸入序列的概率分布at, 最后計算一個合適的權重Pgen將兩個概率分布結合以得到待生成詞的最終概率分布PPGN(w)。 這就使得模型有機會選擇從輸入的源文本或者從詞典中生成合適的詞作為摘要,也就可以將這些丟失的關鍵信息復制到生成的摘要文本中,使得生成的摘要更加準確與合理;下面是具體的計算過程
(5)
(6)

2.4 法條的外部知識編碼器
指針生成網絡作為主流的自動文摘生成模型,在新聞領域取得了非常不錯的性能;但是在司法領域,由于法律文本的特殊性,蘊含有法官審判邏輯脈絡的裁判文書直接使用指針網絡進行摘要的自動生成時,模型可能會忽略了這種隱含的重要審判邏輯脈絡,進一步導致源文本(裁判文書)中重要信息的丟失,從而降低了生成的摘要的性能。因此本文從法官審判邏輯脈絡的角度出發,引入法條作為外部知識,使用一個關于法條的外部知識編碼器,將每篇裁判文書所涉及到的相關法條內容進行知識編碼,結合指針生成網絡來進一步保留源文檔中的重要信息,從而提升司法摘要生成的性能。
本文的法條外部知識編碼器主要是使用一個雙向的LSTM來對法條內容進行編碼,與指針生成網絡中的Encoder端類似,將法條外部知識作為輸入,該外部知識為數據預處理階段得到的關于法條具體條文內容的關鍵詞;之后計算得到一個中間向量,通過中間向量計算得到一個全局的詞典概率分布P′vocab(w), 最后將指針生成網絡計算得到的概率分布PPGN(w)與P′vocab(w) 進行融合得到最終的概率分布Pfinal(w)。 通過這樣的外部知識編碼方式,能夠使得源文檔中與法條內容相關的信息得到加強,從而提升了準確詞語生成的概率,進一步提升了整個司法摘要生成的性能。
如圖2中所示,本文所采用的模型結合了裁判文書原文以及涉及的相關法條內容,共同來生成相應的司法摘要。對于輸入的源文檔(裁判文書)S=(w1,w2,w3,…,wN) 以及相關的法條外部知識K=(k1,k2,k3,…,kM), 均采用一個雙向的LSTM來進行編碼操作,從而分別得到一系列的隱藏狀態 (h1,h2,h3,…,hN) 和 (h′1,h′2,…,h′M), 之后通過將兩個編碼器的最一個隱狀態hN與h′M進行連接轉換后得到Decoder端的初始狀態s0
s0=ReLU(Wf[hN,h′M])
(7)
式中:ReLU=max(0,x),Wf是一個可學習參數。
對于裁判文書和法條外部知識的Encoder部分,參考式(1)、式(2),可計算得到相應的注意力權重分布
eti=vTtanh(Whhi+Wsst+battn)
(8)
e′tj=v′Ttanh(W′hh′j+W′sst+b′attn)
(9)
at=softmax(et)
(10)
a′t=softmax(e′t)
(11)
其中,at為裁判文書Encoder的注意力權重分布,a′t為法條外部知識的注意力權重分布,v,v′,Wh,W′h,Ws,W′s,battn,b′attn均為可學習的參數,而st則為Decoder在時間步t的隱狀態,可通過下式計算得到
st=f(st-1,yt-1,ct-1,c′t-1)
(12)
式中:st-1為Decoder在時間步t-1的隱狀態,yt-1為Decoder在時間步t的輸入,f為一個非線性函數,本文采用LSTM作為函數f;ct-1和c′t-1分別為裁判文書Encoder和法條外部知識Encoder的上下文向量,可通過下式計算得到
(13)
(14)
如圖2所示,本文所采用的模型是通過將指針生成網絡計算得到的概率分布PPGN(w) 與P′vocab(w) 進行結合得到最終的概率分布Pfinal(w)
Pfinal(w)=λPPGN(w)+(1-λ)P′vocab(w)
(15)
式中:PPGN(w) 為裁判文書通過指針生成網絡計算得到的概率分布,可通過式(4)~式(6)、式(12)、式(13)計算得到;P′vocab(w) 為法條外部知識計算得到的詞典概率分布,可通過式(4)、式(12)、式(14)計算得到。對于參數λ,它的作用是調節PPGN(w) 與P′vocab(w) 之間的權重,因此需要能夠根據解碼狀態st, Decoder輸入yt-1, 裁判文書上下文向量ct, 和法條外部知識的上下文向量c′t來進行調整,因此可通過下式進行計算
(16)
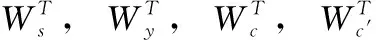
最后,本文使用對數似然函數作為模型的訓練損失函數,損失函數如下
(17)

3 實驗及分析
3.1 數據集

此外,本文通過構建正則表達式,從數據集中提取出每條數據涉及的相關法條進行統計分析,如圖3所示為整個數據集涉及的法條數量分布統計。從圖中我們可以看到,整個數據集中,每條數據中涉及的法條數量在“0~17”條之間,其中涉及到3條法條的數據最多,有709條;而每條數據所涉及的法條數量主要集中在“0~9”條之間。因為法條是案件審理邏輯脈絡的重要組成部分,因此為了確保法條信息的完整性,本文將每條數據涉及的法條均納入后續處理階段。
本文在得到數據集中相關法條的統計數據之后,設計爬蟲將涉及到的法律條款從網絡上爬取,構建了一個法條庫;在數據預處理階段,從法條庫中匹配每篇裁判文書中涉及到的法律條文,將匹配到的條文具體內容作為外部知識;為了降低法律條文中的噪聲影響,進一步通過Textrank算法對條文具體內容中的關鍵詞進行統計抽取過濾,將過濾得到的法條關鍵信息作為外部知識添加到數據集中。
3.2 實驗設置
本文采用pytorch框架進行模型的搭建,對于裁判文書和法條的Encoder端均采用512維的雙向LSTM,對于Decoder端則是采用512維的單向LSTM;在詞向量方面,本文采取隨機初始化的方法,將詞向量的維度設置為512維,其在持續訓練的過程中會不斷調整。此外,在進行詞典構建時,通過將裁判文書與法條進行聯合統計,最終選擇了兩萬個詞語構建詞典。在整個訓練與測試過程中,經過數據預處理階段,輸入的文本長度得到壓縮,因此本文中輸入的源文本最大長度設置為700,經過統計,能夠有效滿足模型和數據的要求;生成的文本摘要詞數最大長度設置為200,法條外部知識的最大長度設置為100。在訓練過程中,本文設置的學習率為0.001,累加器的初始值設置為0.1,訓練的batch大小為32。評價指標則采用通用的ROUGE評價指標進行性能評價,將自動生成的摘要與參考摘要進行比較,其中ROUGE-1衡量unigram匹配情況,ROUGE-2衡量bigram匹配,ROUGE-L記錄最長的公共子序列。
3.3 基線模型
Lead-3[18]:采用抽取文章的前三句文本作為整篇文章的摘要,由于新聞的重要信息通常都集中在文章的前半部分,因此Lead-3算法能夠取得不錯的效果。
Textrank:將句子作為節點,句子之間的相似度作為邊構建圖,通過基于圖的排序算法計算句子的重要度,最后抽取排名高的句子組成摘要。
Bertsum:將摘要過程抽象為分類問題,通過BERT獲取到原文的句子向量表示,之后通過分類器從句向量中獲取到文章的文檔級特征,用于最終的摘要提取。
seq2seq+attention模型以及指針生成網絡模型(PGN)作為本文的基礎對比模型,在2章節中已進行詳細介紹。
3.4 實驗結果與分析
為了進一步驗證我們模型的有效性,本文進行了一系列的對比實驗;將我們的模型同所提基線模型進行實驗對比,實驗結果見表1。

表1 在測試集上模型的ROUGE得分
由表1可以看出,在F1指標上,我們的方法比主流的指針生成網絡性能分別高出(1.37 ROUGE-1,4.91 ROUGE-2,3.91 ROUGE-L);比基礎模型(baseline)性能分別高出(6.57 ROUGE-1,6.64 ROUGE-2,6.44 ROUGE-L);比Textrank性能分別高出(10.63 ROUGE-1,8.26 ROUGE-2,12.14 ROUGE-L);Lead-3模型則獲得了最低的性能。對于抽取式摘要模型,Textrank模型的性能遠遠高于Lead-3模型,這也進一步說明了司法裁判文書和新聞領域文本的不同之處,新聞領域文本中的重要信息主要會集中在文本前半部分,而司法文本的重要信息則是分布在整篇文章之中,因此Lead-3算法用于司法摘要取得了極差的性能。從性能結果來看,生成式摘要模型(baseline,PGN)的性能均明顯高于抽取式摘要模型Textrank,Textrank主要是基于文章中的句子相似度來抽取句子作為文本摘要;在新聞領域,重要的信息通常會在文章中重復出現,而在司法文本中,重要的信息如判決結果等,通常只會出現一遍,因此計算所得的權重會比較低,從而有很大概率不會被抽取作為文章摘要,所以Textrank算法應用于司法領域也具有一定的局限性。
基于BERT的摘要抽取模型在性能上優于Textrank主要是得益于BERT模型在語言表征方面的強大能力,分類器在獲得深層次的句子表示之后能夠較為準確地判斷句子是否屬于摘要句。然而由于模型是基于句子進行文本摘要抽取,最終摘要保留了過多冗余信息,因此性能較基于詞進行摘要的生成式模型偏低。
對于生成式摘要模型,可以看到性能均優于抽取式模型,并且加入了指針網絡的PGN性能也優于基礎模型,符合我們的實驗預期。而我們的模型主要是在生成式模型PGN的基礎上融入了法條作為外部知識信息來輔助生成摘要,我們的模型性能相對于PGN模型和基礎模型(baseline)來說均有了一定的提升,這也佐證了參考法官的審判邏輯脈絡,融入法條作為外部知識,通過法條逆向保留裁判文書重要信息這一方法的有效性。從表1可以看出,在加入法條作為外部信息之后,對于F1值,我們的模型在ROUGE-1提升了1.37,在ROUGE-2和ROUGE-L均提升了3個點以上,而ROUGE-2和ROUGE-L主要代表生成的摘要和專家摘要之間的長序列的重合度。
從表2可以看到我們的摘要模型采用beam search算法生成的摘要與專家摘要的對比,我們可以看到模型自動生成的摘要基本保留了案件的重要事實,生成的摘要也比較通順,在長序列上高度與專家摘要重合,但是對于案件細節,生成摘要與專家摘要仍有部分不足,以及涉及的案件金額生成也仍有欠缺。

表2 生成的摘要與專家摘要對比
對于民事裁判文書的重要邏輯結構:“案件事實,適用法律,裁判意見”,我們模型所生成的摘要也基本保留。并且從表2中可以看到,專家摘要給出的事實描述部分有:“合同有效”、“已支取貸款”、“未如期還款”、“違約”;PGN模型生成的摘要中卻丟失了“已支取貸款”的重要事實;而本文模型生成的摘要則保留了這一案件事實,且對于“已支取貸款”的描述轉化為了“原告按照合同的約定向被告發放了借款”,基本完整保留了與專家摘要一致的案件事實。
這也進一步說明了我們模型生成的摘要與專家摘要擁有更高的相似性,也比較符合我們的實驗預期。
4 結束語
本文中我們提出了一種引入法條作為外部知識編碼的文本摘要生成方法,不同于傳統的自動文摘方法,我們借鑒裁判文書中蘊含的法官重要的審判邏輯脈絡,通過提取案件涉及的法條作為外部知識,逆向輔助模型保留文摘生成過程中裁判文書的重要信息,提升裁判文書摘要生成的性能。實驗驗證,我們提出的方法在實驗效果上可以得到很好的提升。不過,我們意識到法條的相關應用工作仍有不足,如嵌套法條的特殊情況,我們將在下一步工作中繼續深入研究,以期獲得更好的司法摘要生成性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
