基于圖神經網絡的電子設計自動化技術研究進展
2023-10-17 01:14:54田春生婧王卓立龐永江
電子與信息學報 2023年9期
田春生 陳 雷 王 源 王 碩 周 婧王卓立 龐永江 杜 忠
①(北京微電子技術研究所 北京 100076)
②(北京大學集成電路學院 北京 100871)
1 引言
集成電路電子設計自動化(Electronic Design Automation, EDA)軟件依托計算機及相關平臺[1,2],實現集成電路的設計、綜合、驗證、物理設計(包括布局、布線、版圖、設計規則檢查)、硬件安全檢測等功能,極大地提高了集成電路的設計效率,保證了設計的安全性,是整個產業鏈最上游的核心子區域,貫穿了設計、制造以及封裝測試的全部環節[3]。隨著集成電路制造工藝尺寸的不斷縮小,芯片的復雜度和芯片設計成本不斷增加。2001年,國際半導體技術路線圖(International Technology Roadmap for Semiconductors, ITRS)曾指出集成電路設計成本是制約半導體發展的最大威脅[4]。EDA與半導體材料、設備共同構成集成電路的3大基礎,如今的一顆芯片上面至少包含數億到數十億個以上的晶體管,制造和研發的費用也越來越昂貴,多次流片失敗直接導致公司倒閉的案例更是數不勝數,所以在芯片設計環節不允許出現絲毫差錯。EDA工具的發展極大程度提高了芯片的設計效率,一直以來都是推動芯片設計成本保持在合理范圍內的重要方式。實際上,EDA一直都在扮演一種“成本殺手”的角色。根據加州大學圣迭戈分校Andrew Kahng教授在2013年的推測,2011年設計一款消費級處理器芯片的成為約為4×107美元,如果不考慮1993~2009年EDA技術的進步,相關設計成本可能高達7.7×109美元,EDA技術使得設計費用降低了200倍[5]。由此可見,EDA技術的重要性對于整個集成電路產業的發展不言而喻。
EDA工具的工作流程跨越了邏輯綜合、布局規劃、布局、時鐘樹綜合(Clock Tree Synthesis,CTS)、布線、測試等多個階段,此外還囊括硬件安全檢測等多個步驟[6–11],隨著設計復雜度增加、工藝向物理極限推進,EDA工具的設計難度日趨增加。為應對出現的挑戰,越來越多的研究將機器學習技術引入到EDA工具的設計流程中,用以提高建模、搜索和優化過程的性能和效率,從而進一步解決設計規模大、設計目標與約束復雜以及設計流程冗長的問題[12,13]。通過機器學習方法對電路設計過程中的關鍵參數進行提取、可預測性建模以及EDA算法優化可以非常高效地提升芯片設計效率,縮短芯片版圖的生成時間,從而達到敏捷設計的目標[2,14]。但為了做出準確的預測或是更好地優化EDA工具的服務質量(Quality of Service, QoS)信息,機器學習算法需要深度依賴代表底層設計的輸入向量,并且鑒于電路網表的本質是一種圖數據結構,圖神經網絡(Graph Neural Network, GNN)在EDA流程中的應用正變得越來越普遍。
圖是以一種使用節點和邊來表示的數據結構,能夠用來建模一系列實體間的關系。近年來,基于圖的深度學習模型,例如GNN在學術界以及工業界受到了廣泛的關注,GNN遵循消息傳遞方案,其目標是通過遞歸地聚合和轉換初始特征,在整個圖或節點級別構建特征的有效表示方法,正是基于上述特性,GNN被普遍應用于社交網絡[15]、知識圖譜[16]、生物醫學[17]等各個領域,并且許多不同的GNN模型也被提出用來執行在圖上的學習。盡管GNN在這些領域取得了巨大的成功,但目前尚不明確GNN在EDA領域中取得類似成功的緣由。為此,文獻[18]分析了圖神經網絡在EDA流程中應用的有效性來源,即GNN中隱式地嵌入了與特定的超大規模集成電路設計相關知識與歸納偏差。文獻[19]首先回顧了GNN在EDA物理設計中所取得的最新研究進展,在此基礎上,作者分析了GNN之所以能夠在EDA物理設計領域取得上述成就的原因。文獻[20,21]則關注了EDA技術與GNN間的聯系,Ma等人[20]的研究首先指出了GNN在EDA問題求解過程中的巨大潛力,相關的研究表明,圖結構對于布爾函數、網表以及版圖等的表示是非常直觀的,并且在結果質量 (Quality of Result, QoR)的改進效果方面能夠超過傳統的淺層學習或是基于解析式的求解方法,文獻最終以測試點的插入和時序模型的選擇兩種測試用例說明了GNN在EDA技術中應用所具備的優勢。文獻[21]則是對卷積神經網絡在EDA底層的應用進行了回顧,綜述了機器學習等相關技術能夠通過預測設計空間探索、功耗分析、物理設計等不同階段的重要指標來提升設計的QoR的方法。文獻[20,21]的研究明確說明了在EDA流程中引入GNN是非常重要的,但沒有完全給出如何將GNN與EDA兩個研究方向進行有效結合,其關注點仍大部分停留在淺層學習方法在EDA領域的應用。
本文針對基于GNN的EDA問題進行討論,首先對GNN與EDA技術的問題背景與應用框架進行簡要介紹,在此基礎上,對當前國內外基于GNN的EDA技術(高層次綜合、邏輯綜合、布圖規劃與布局、布線、反向工程、硬件木馬檢測以及測試)的相關工作進行綜述,最后總結出基于GNN的EDA設計中所面臨的一系列的挑戰以及相關的解決途徑。
2 GNN與EDA技術概述
2.1 GNN技術概述
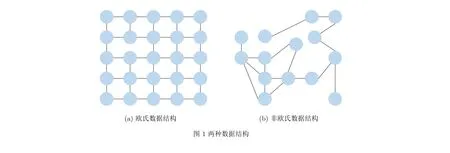
在過去的幾年,隨著人工智能(Artificial Intelligence, AI)和深度學習的不斷發展,深度神經網絡(Deep Neural Network, DNN)已成為深度學習的重要計算模型之一,在越來越多的領域取得了突出乃至超過人類專家的表現。為了具備更好的學習與表達能力,DNN“熱衷”于堆積多層的神經網絡層,這使得DNN能夠高效地處理圖像、語音、文本等形式的歐幾里得(Euclid)數據[22]。圖1(a)所示便是一種歐氏數據結構,其特點可表現為數據結構中的節點包含有固定的排列規則和順序,例如2維網格或是1維序列。但當前越來越多的實際應用中,必須對非歐氏數據加以考慮。例如,作為一類能夠描述關系的通用的數據結構表示方法,圖能夠非常自然地表現出現實場景中實體與實體間的復雜關系,在工業界的應用前景極其廣闊,具體如圖1(b)所示,在該非歐氏數據結構所表示的圖中,節點沒有固定的排列規則和順序,這就使得我們無法將傳統的深度學習模型直接應用到非歐氏結構數據的任務中。如果我們強制將卷積神經網絡(Convolutional Neural Network, CNN)應用至圖1(b)所示的數據結構中,由于非歐氏數據中心節點的鄰居節點數量和排列順序均不固定,并且不滿足平移不變性,導致很難在非歐氏數據中定義卷積核[23]。
為了有效解決上述問題,研究學者開始了GNN技術的研究,GNN起源于2005年,通過將深度學習與圖數據結構進行融合, GNN概念的提出,使得DNN在與圖數據相關的場景中得到了更加廣泛的利用。針對GNN的研究工作,最初始的工作主要針對如何將鄰居節點的數量固定以及如何對鄰居節點進行排序而展開。在完成上述研究工作后,便完成了從非歐氏數據至歐氏數據的轉化過程,在此基礎上便可以利用CNN對轉換后得到的數據進行處理。圖是一種具有節點和邊的典型的非歐氏數據,一般情形下,圖定義為G=(V,E),其中V表示節點的集合,E表示邊的集合。VRvw表示兩頂點之間關系的集合,它是集合E的 子集,若〈v,w〉∈VRvw,則〈v,w〉表示從v到w的一條弧,且稱v為弧頭節點,w表示弧尾或終端節點,此時的圖稱為有向圖;若對于任意的 〈v,w〉∈VRvw必有〈w,v〉∈VRvw,即VR是對稱的,則以無序對(v, w)代替這兩個有序對,表示v和w之間的一條邊,此時稱此圖為無向圖。在實際問題中,可以將各種非歐氏數據問題抽象為圖結構,例如在一個日常生活中所熟知的交通系統內,利用基于圖的學習模型,可以對當前以及未來一段時間內的路況信息進行有效預測。再比如,在計算機視覺模型中,同樣可以將人與物的交互當作是一種基于圖的數據結構,從而進行有效的檢測識別。
研究GNN對于推動EDA技術的發展、深度學習及人類的進步具有重大意義,EDA工具的輸入,即電路網表文件便可以抽象為非歐氏結構數據,由于圖數據的不規則性,傳統的深度學習模型對于這種結構數據的處理顯得力不從心,這便亟需研究設計一種新的DNN模型,而GNN所能夠處理的數據正是這種具有不規則結構的圖數據。此外,圖數據的結構和任務是十分豐富的,這種豐富的數據結構和任務也正與EDA流程中要處理的實際問題相貼合。所以,GNN的研究為解決EDA領域中的實際問題找到了一種新的方法和途徑。
2.2 EDA技術概述
根據 市場研究公司(Research and Markets)相關數據,2025年全球EDA市場規模將達1.45×1010美元,直接支撐起的半導體制造市場規模達7×1010美元,再向上將是繼續支撐起萬億規模的數字經濟,杠桿效應接近200倍。現階段的全球市場上,EDA市場的集中度較高,新思科技(Synopsys)、楷登電子(Cadence)以及Siemens EDA(原Mentor,已被西門子收購)占據了市場的主要份額。在摩爾定律的推動下,5 nm的芯片能夠容納1.25×1010個晶體管,必須依賴EDA工具才能夠完成集成電路設計、版圖設計、版圖驗證、性能分析、硬件木馬檢測等一系列工作[24]。但美國《2022芯片與科學法案》中對5 nm及其以下的最先進制程EDA工具也進行了封鎖,由此可見EDA軟件工具已經成為集成電路芯片設計制造環節中必不可少的戰略支撐要素。
EDA工具的設計流程主要分為前端設計與后端設計兩大組成部分[25],具體如圖2所示,其中前端設計負責邏輯實現并驗證,包含功能設計、系統設計、高層次綜合(High Level Synthesis, HLS)、邏輯綜合與驗證等幾個部分,后端設計負責生成相應邏輯設計的物理實現部分,即將邏輯網表數據映射到物理版圖上,并確保后續制造過程的魯棒性。后端的設計環節具體包含物理設計、物理驗證、掩模設計與驗證以及封裝測試等幾個重要的步驟。在實際設計實現的過程中,由于前端設計與后端設計的各個流程間的信息需要相互依賴,各個步驟之間需要反復迭代才能夠最終實現設計的收斂[25]。此外,硬件安全技術,例如反向工程或是硬件木馬檢測貫穿了上述的各個流程,用以保證集成電路設計過程的安全可靠。
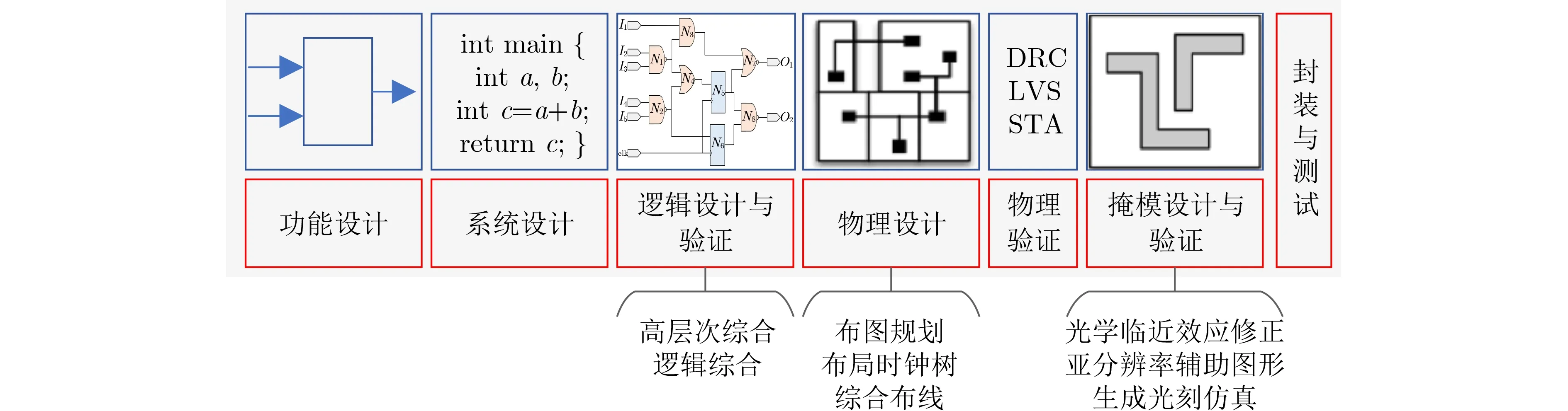
圖2 EDA設計流程
隨著成本的越來越高、分工越來越復雜,不論是學術界或是工業界都在嘗試新的技術與解決方案,試圖超越摩爾法則,以此來實現功耗最低、性能表現最佳、成本最優。特別是在超越摩爾定律的先進集成電路技術這條道路上,即新材料、新器件、新架構或是新集成與新工具等對EDA工具不論是從設計效率、對更強復雜功能設計的支撐能力亦或方法學上的創新都提出了更高的要求。只有這樣我們才能夠在工藝不占優勢的情形下,研制出與先進工藝性能相匹配的高端芯片,從而突破被“卡脖子”的不利局面。幸好,GNN技術的出現為EDA技術的發展指明了一條全新的發展思路,走一條電子設計智能化的新賽道是實現“后摩爾時代先進集成電路技術”彎道超車的有效途徑。
3 基于GNN的EDA技術研究進展
3.1 高層次綜合技術
在邏輯綜合階段,描述硬件設計的寄存器傳輸級(Register-Transfer Level, RTL)設計代碼將被映射為事先定義好的技術映射庫中的一系列邏輯單元,與此同時,上述過程必須滿足相應的時序約束,以便在考慮面積以及功耗等QoR指標的條件下,在所需要的時鐘頻率下能夠正常運行。因此,邏輯綜合是一個可以應用強化學習進行求解的復雜優化問題。在邏輯綜合執行的初期進行QoR預測,可以避免多次重復的迭代。例如,為了更加準確地預測現場可編程門陣列(Field Programmable Gate Array, FPGA)中邏輯單元的延遲信息,文獻[26]對FPGA中算術運算的映射和聚類模式進行了有效的學習,進一步提出了一種全新的架構D型采樣與特征聚合 (D- Sample and AggreGatE, D-SAGE),具體如圖3所示,在D-SAGE工作流程中,HLS的中間表示將被映射為數據流圖(Data Flow Graph,DFG),并在執行技術映射后將DFG操作與網表對象進行匹配。DFG中節點表示相關的操作信息,例如加法或是乘法。邊表示節點間的數據依賴關系,數據的節點類型與位寬信息被視為節點的屬性,隨后根據端到端的任務將節點和邊進行標記即可。即如果節點被映射到DSP模塊或是查找表LUT,則可以分別將它們標記為1或0。類似地,如果邊的連接點映射到相同的邏輯單元,則相應的邊將被標記為1。上述標簽信息將被用于GNN模型的訓練,模型訓練完成后便可以使用訓練好的GNN模型從給定的數據流圖中推斷出相對應的映射模式。D-SAGE可以成功地將操作映射學習到對應的邏輯資源中,從而有效地避免了將HLS子圖匹配到FPGA資源的繁瑣過程。

圖3 算術密集型設計中基于GNN的運算映射與聚類學習
為了盡可能早地從設計階段加快對電路性能的評估,美國加州大學圣塔芭芭拉分校謝源教授團隊[27]提出了一種快速準確的性能建模方法,通過將C/C++程序表示為圖從而充分利用圖神經網絡的特征表示能力,完成性能的預測。本文的具體貢獻主要體現為以下3個方面:(1)首先,構建了一個包含40K的C語言可綜合的測試基準,其中包括綜合程序以及3套來自真實世界的HLS的測試基準,每個程序都在FPGA上進行了實現,用以生成真實的性能指標。(2)在圖上對性能預測問題進行了建模,并利用預測及時性(即早期預測或是晚期預測)與準確性之間的不同權重,提出了多種基于GNN的建模策略。(3)進一步對GNN進行了分層處理,在不犧牲性能預測及時性的前提下,大幅度提升性能預測的準確性。通過對不同測試用例的對比評估,在資源使用和時序預測方面,該方法平均絕對百分比誤差(Mean Absolute Percentage Error,MAPE)對比HLS方法最高降低了近40倍。
此外文獻[27]同時對基于GNN的HLS設計空間探索方法進行了研究,并提出了IRONMAN (Design Space Exploration in High-Level Synthesis via Reinforcement Learning)架構[28],該架構主要由基于GNN的性能預測器(GNN-based Performance Predictor, GPP)、基于強化學習的多目標設計空間探索(RL-based Multi-objective DSE, RLMD)以及代碼轉換器(Code Transformer, CT) 3個部分構成,具體如圖4所示。其中,GPP主要負責HLS設計的性能預測,具體包括邏輯資源(DSP以及LUT)的利用率以及關鍵路徑的時序信息,同時GPP也適用于從DFG中進行性能的預測評估。RLMD主要負責HLS的資源分配,在GPP的協助下,RLMD能夠充分完成用戶指定約束下的資源優化分配策略,同時還能夠提供不同目標之間帕累托最優解決方案,而這正是HLS工具所無法提供的。CT是一個代碼轉換器,能夠從原始的HLS C/C++代碼中提取出DFG,并能夠在RLMD優化后的HLS指令的基礎上,重新生成可綜合的代碼,CT能夠在用戶指定的約束下實現靈活且更細粒度的DSE。通過上述3個模塊的相輔相成,IRONMAN能夠將HLS工具在資源使用上的預測誤差降低10.9倍,關鍵時序信息的預測誤差降低5.7倍。相比遺傳算法或是模擬退火方法,IRONMAN所獲得的帕累托解決方案分別提升了 12.7%與12.9%。并且在實際的測試基準中,IRONMAN能夠尋找到滿足各種DSP約束的解決方案,與HLS工具相比,DSP的數量減少了2.54倍,延遲縮短了6倍,同時相比啟發式方法和HLS工具其求解速度提升了400倍。在上述工作的基礎上,文獻[29]對IRONMAN作了進一步改進,提出了IRONMAN-PRO (Multi-objective Design Space Exploration in High-Level Synthesis via Reinforcement Learning and Graph Neural Network based Model)架構,GPP, RLMD以及CT的性能都得到了進一步的提升。

圖4 IRONMAN體系架構示意圖
3.2 邏輯綜合技術
邏輯綜合是將所設計數字電路的RTL級描述,在滿足約束的條件下,將RTL級描述轉化為指定的工藝庫中單元電路的連接的過程。邏輯綜合主要包括翻譯、優化與工藝映射3個階段。在翻譯階段,硬件描述語言(Hardware Description Language,HDL)將被翻譯為相應的功能塊以及功能塊之間的拓撲結構,在此基礎上,邏輯綜合器將根據所施加的時序和面積約束,按照一定的算法對翻譯結果進行邏輯重組并優化,最后便是從目標邏輯資源庫中搜索符合條件的邏輯單元來構成實際電路的邏輯網表的過程。因此,邏輯綜合是一個非常復雜的設計空間探索的過程。在邏輯綜合階段,電路網表中邏輯單元的位置信息與布線信息并沒有事先確定,GNN概念的引入為上述問題的求解指明了方向,在GNN的模型中,整個網表被抽象為一張有向圖,節點和邊也不再是單個獨立的樣本,而是通過圖結構實現了互聯,這樣整個圖中所包含的信息更加全局化,由此也彌補了在邏輯綜合階段由于電路網表中邏輯單元位置信息和布線信息的缺失而帶來的影響。
2022年謝源教授團隊[30]研究了GNN在EDA邏輯綜合領域的應用,提出了一種全新的性能預測方法,具體如圖5所示。針對邏輯綜合的工作流程,利用混合圖神經網絡提供精度更高的結果指令的預測以及更加強大的泛化能力,該方法的關鍵在于能夠利用來自硬件設計和邏輯綜合流程的空時信息來預測不同設計上各種邏輯綜合流程的性能,主要包括延時以及面積等信息。具體而言,首先使用GNN來提煉出硬件設計內部的結構特征,在此基礎上,利用增加的虛擬節點與傳統GNN模型相結合的方式,將邏輯綜合流程中的時間知識添加到硬件設計上,相關實驗結果表明,該方法能夠更加快速地預測出不同設計在面積以及延時方面的性能,其平均絕對百分比誤差相比現有研究而言分別降低了7倍與15倍。

圖5 HLS性能預測方法體系架構示意圖
3.3 布圖規劃與布局技術
集成電路布圖規劃與布局作為典型的超大規模NP困難組合優化問題,對集成電路的性能指標將產生重大影響。同時由于過去幾十年芯片架構的急劇演進,布圖規劃與布局的流程變得越來越富有挑戰性。隨著越來越大的設計以及越來越復雜化的設計約束和目標,都使得研究人員越來越追求依托更大的計算量和更多的計算資源來尋找滿足所有約束的合法解決方案,但這也導致了更長的物理設計周期以及更慢的性能收斂速度。
基于上述問題,Google公司在2021年提出了一項具有跨時代意義的工作,并將其發表在《Nature》上,Google公司在GNN的基礎上,提出了一種基于邊的神經網絡(Edge-GNN),同時將其納入到強化學習的架構當中以完成對不同狀態的編碼過程,并成功將該方法應用于Google自身的張量處理器(Tensor Processing Unit, TPU)的設計流程中,能夠在數小時內設計出與人類專家QoR相當的設計結果[31]。
為了進一步加速布局的流程,文獻[32]與文獻[33]基于圖采樣與特征聚合(Graph SAmple and aggreGatE, D-SAGE)構建了基于圖學習的體系架構,用來輔助布局工具進行有效的決策,從而加速布局流程的收斂。PL-GNN首先將網表轉換為一個有向的超圖,其中節點和邊的特征是基于層次信息以及線網與內存塊的關聯性而構建的。在此基礎上,GNN模型被用來學習節點的嵌入,并通過加權的K-Means算法完成聚類操作,由此產生的聚類解便是一個最佳的布局解決方案。與商業工具相比較,基于圖學習的體系架構的線長優化了3.9%、功耗優化了2.8%。
除以上方法,上海交通大學嚴駿馳教授團隊[34]針對大規模集成電路中宏模塊與標準單元的布局問題,在2021年提出了一種基于強化學習與GNN的DeepPlace布局框架,即通過強化學習和神經網絡所形成的梯度優化分別完成對宏模塊與標準單元的布局自動化過程,該工作也是學術界內首篇應用神經網絡方法同時考慮宏模塊與標準單元布局的研究工作。
在布局的過程中進行設計規則違例的預測同樣是一項非常重要的研究工作,因為非法的布局將會造成布線擁塞等設計違例問題的出現,進而使得布線資源緊張,從而降低芯片性能[1]。因此,在布局階段進行規則違例預測模型的構建變得極其重要。在違例預測模型構建完成后,便能夠在布局階段進行例如布線后擁塞結果的預測,從而方便對布局方案進行實時調整,提前對布局質量進行優化。隨著GNN相關研究的興起,應用GNN來實現設計規則違例的預測正逐步成為一種趨勢。
國外在這方面的研究起步相對較早,Nvidia公司研究人員首先在2019年提出了一種基于圖的深度學習方法[35],相比于其他方法,擁塞預測準確率提升到了75%。同時,該方法對于大規模的網表文件同樣是適用的,例如,對于一個包含1.3×106標準單元的電路而言,該方法能夠在19 s內給出較為準確的擁塞預測結果,而其他同類方法的耗時為10~60 min。
除國外上述研究外,國內華為公司諾亞方舟實驗室團隊首先在2021年提出了一種基于GNN的擁塞預測方法,并在DREAMPlace以及OpenRoad等開源EDA工具中進行了測試,相關結果表明,該方法能夠有效提升預測性能,并且能夠節省90%以上的運行時間[36]。西南交通大學邸志雄教授團隊[37]在2022年提出了基于GraphSAGE的方法,通過訓練圖神經網絡模型來建立布局的特征與詳細布線后短路違例的關系,以進一步提高預測的精確性。該方法的具體工作流程如圖6所示。整個流程分為物理設計階段、特征提取階段以及訓練與評估階段。在物理設計階段,通過EDA工具的布局器與布線器對指定網表完成布局與布線的操作,在完成布局操作后,文章使用了類似文獻[38]中的方法將布局進行了拆分,形成了一塊一塊的非重疊的正方形的圖塊(Tile),每個圖塊的規模均為3×3的全局布線單元(Global Routing Cell, GRC)。隨后便可以基于圖塊間的位置關系建立鄰接矩陣,并在每個圖塊中提取影響可布線性的關鍵特征因素,例如標準單元的引腳以及線網等信息。最后,用布線后的短路違例來標記這些圖塊,其中包含短路的圖塊標記為正實例(Positive Instance, PI)1,相反則標記為負實例(Negative Instance, NI)0。在此基礎上,將鄰接矩陣、特征信息以及標記好的數據加載到圖神經網絡GraphSAGE模型中進行訓練。模型訓練完成后,將新的布局網表中的鄰接矩陣和特征信息輸入到訓練好的模型中即可快速精確地確定每個圖塊中是否會出現短路違例。最終的實驗結果表明,該預測模型能夠在具有更多短路違例的設計中實現更好的2元分類性能,并且在實際應用中的性能也要優于先前的基于歸納學習的相關工作。
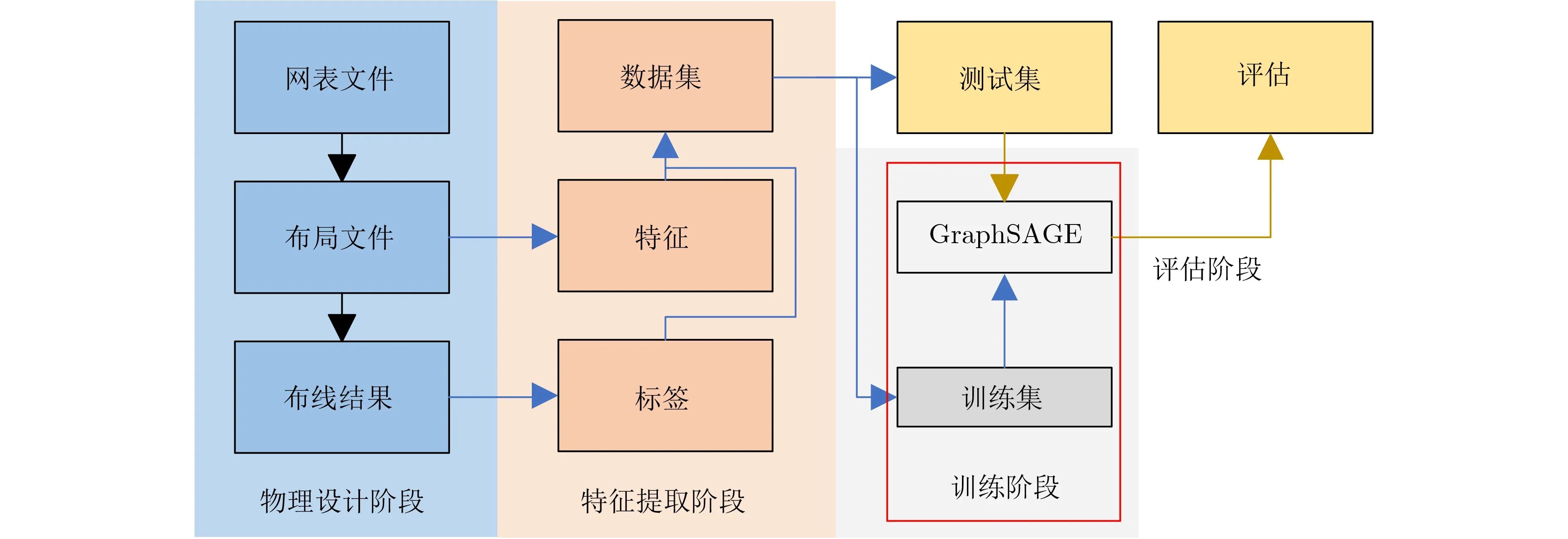
圖6 基于GraphSAGE的短路違例預測方法
3.4 布線技術
在超大規模集成電路設計中,布線的目的是在規定的布線區域內實現電路內部各個模塊間的物理連接,它是超大規模集成電路物理設計階段非常關鍵的步驟之一。隨著工藝的不斷發展,集成電路變得越來越復雜,單位面積中晶體管的數量呈指數增長,元器件間的連接關系也越來越復雜,從而導致超大規模集成電路的布線任務越來越困難。然而現階段的自動布線算法布通率較低且速度緩慢,當前在工業應用中仍然需要大量依賴于工程師手動進行布線,導致了大量的時間和人力資源被消耗在布線工作中。因此,亟需一種能夠實際應用于現代大規模集成電路設計的智能布線算法來提升EDA工具的設計效率。針對當前EDA工具布線智能化程度低、自動化率低、效果差的問題,文獻[34]提出了一種依賴GNN的布線方法。該文提出了兩個強化學習的架構DeepPlace和DeepPR,其中DeepPlace僅僅用來優化布局流程,DeepPR則能夠同時對布局與布線的流程進行優化。DeepPR使用來自GCN的詳細節點嵌入作為強化學習架構的策略網絡,相應的實驗結果表明,DeepPR可以非常高效地從歷史經驗中進行學習,布局、布線后的半周線長(Half-Perimeter Wire-Length, HPWL)指標較現有方法而言優化了8.41%。
3.5 硬件安全技術
隨著現代信息技術的發展,大規模集成電路的應用范圍也越來越廣泛,小至各類電子產品,大至航天器、導彈、雷達等國家戰略軍工產品。集成電路的廣泛應用為我們帶來信息時代紅利的同時,也帶來眾多不可避免的安全問題。近年來,集成電路芯片受到的惡意攻擊和探測出的硬件漏洞層出不窮,甚至集成電路芯片設計流程中,在某些不能做到自主可控的環節鏈條,還可能被進行反向或惡意植入硬件木馬,在國家信息安全被越來越重視的時代,硬件安全引起了國內外研究人員的廣泛關注。
在EDA的工作流程中,反向工程是通過分析芯片的每一層來獲取知識產權(Intellectual Property,IP)或集成電路設計功能的過程。此類分析的結果往往可被用于功能驗證以及安全保護的目的。集成電路的反向工程主要可以分為以下幾個階段,即產品拆解、系統級分析、過程分析以及電路提取[39–42]。產品拆解有助于對集成電路的內部組件進行識別,而系統級分析則有助于完成對底層功能以及邏輯門之間的互連等關系進行分析。過程分析主要是為了對電路的結構和材料進行分析,以此來挖掘出集成電路可制造性方面的信息,最終進行電路提取以完成電路級原理圖的構建。近年來,一些研究學者提出了基于GNN的方法來進一步提升數字集成電路反向工程系統的性能,例如,文獻[43]提出了一種面向門級網表的基于GNN的反向工程方法GNN-RE,用于進行子電路的提取和分類。具體如圖7所示,GNN-RE首先將門級網表映射為一個無向圖,圖中的節點對應于標準門單元,圖中的邊則對應于門單元間的連接關系。在無向圖中,每個節點的特征向量包括當前節點所連接到的主輸入與主輸出的數量、按類型劃分的兩跳連接門的數量以及輸入與輸出的度。此外,GNN-RE還廣泛地比較了不同種類的GNN模型以及計算模塊,最終的實驗結果表明,通過將GAT與GraphSAINT的采樣模塊結合使用可以獲得最佳的結果,在EPFL與ISCAS-85等70余個基準電路上能夠獲得98.82%的平均精度。與GNN-RE相類似,為了解決門級網表中算術塊識別過程所存在的可擴展性問題,文獻[44]提出了一種基于異步雙向圖神經網絡(Asynchronous Bidirectional Graph Neural Network, ABGNN)的方法,專門用于有向無環圖的表示學習。對開源RISCV中央處理器設計的實驗結果表明,相比于傳統方法,該求解方案能夠以最快的運行時間實現最高的預測準確度。

圖7 基于GNN的子電路提取與分類方法示意圖
RTL級的第三方IP復雜而靈活,能夠支持不同應用程序下的多種配置,但同時也為硬件木馬的插入提供了途徑。硬件木馬在龐大的電路設計中所占面積很小。因此,它可以悄悄地隱藏在集成電路的設計中,人們往往很難通過肉眼或者簡單的檢測手段發現硬件木馬的存在。并且在不可信的第三方IP的情況下,IP的Golden模型是無法獲取的,那么便無法使用基于測試或是測信道的方法來進行硬件木馬的檢測。此外,一些破壞性方法,例如反向工程,雖然能夠檢查集成電路是否感染了硬件木馬,但只能在制造后進行。其他的一些硬件木馬檢測方法,例如基于圖相似性的方法,雖然能夠進行硬件木馬的檢測,但其復雜度偏高并且無法對一些未知的硬件木馬進行有效的識別。
為此,文獻[45]提出了一種基于GNN的硬件木馬檢測平臺GNN4TJ, GNN4TJ能夠在事先不了解設計IP或硬件木馬結構的前提下完成硬件木馬的檢測識別,GNN4TJ首先將RTL設計轉換為相應的數據流圖DFG,隨后將DFG輸入到GNN模型內部用以進行特征的提取以及底層設計結構和行為的學習。在此基礎上,GNN將執行圖形分類任務以進行硬件木馬的識別。最后,該文在TrustHub測試基準上對模型進行了驗證,相關的實驗結果表明,GNN4TJ能夠在21.1 ms內以97%的真陽率非常快速地檢測到未知的硬件木馬。除上述研究外,研究人員也提出了其他基于GNN的硬件木馬檢測平臺[46–49],以進行硬件木馬的檢測與定位,相關工作流程與GNN4TJ大致相同,這里不再進行贅述。
3.6 測試技術
為了保證芯片設計過程中的性能與可靠性,僅僅關注硬件安全是遠遠不夠的,還需要對芯片設計過程中的測試驗證環節進行關注。一般情況下,測試的工作發生在封裝的流程之后,設計的規模越大,測試工具的復雜性和執行時間便越高。此外,測試還需保證較高的覆蓋率、避免冗余的測試用例,并且測試在很大程度上需要研究人員的專業知識,通常情況下不具備擴展性[50]。為了克服以上問題,有研究學者將GNN的方法引入到了測試的流程中,例如,為了能夠在設計中通過提供最佳的測試點來降低測試的復雜性,文獻[51]提出了一種高性能的圖卷積神經網絡(Graph Convolution Neural Networks, GCNNs)模型,用于處理數字邏輯電路的不規則圖表示,同時能夠最大限度地提高故障覆蓋率。為了實現上述目標,文獻[51]首先訓練了一個GCNNs分類器來預測網表中的候選觀測點,隨后GCNNs分類器將被用作迭代過程的一部分,基于分類的結果從而進一步給出觀測點的插入位置。相關的實驗結果表明,該文獻所提出的GCNNs模型在一些難以觀測的節點的預測方面具有優于典型機器學習模型的精度,與現有商業可測試性分析工具相比較,文獻[51]所提出的觀測點插入流程實現了類似的故障覆蓋,從而進一步將觀測點減少了11%,觀測模式數量減少了6%。
最后,表1對上述基于GNN的EDA技術進行比較分析。

表1 基于GNN的EDA技術
4 GNN在EDA技術中應用的挑戰
基于GNN的EDA技術的主要目標是EDA工具通過自主學習的過程實現無人參與的設計自動化,盡可能減少人工干預以及設計的返工迭代。隨著集成電路技術的發展,工藝特征的尺寸也在減小,導致當今芯片設計面臨巨大的挑戰,基于GNN的EDA技術可以顯著地提升集成電路的設計效率,是未來實現無人參與的敏捷設計的重要研究內容[2]。目前,基于GNN的EDA技術的研究尚處于起步發展階段,其未來的發展方向也存在著很大的不確定性。因此,接下來將從相關的局限性出發,對基于GNN的EDA技術所面臨的挑戰及其可能的應對措施進行說明。
(1)毋庸置疑,基于GNN的EDA體系架構要明顯優于淺層機器學習、深度學習方法或是一些已有的解決方案,這主要是由于GNN能夠對拓撲結構以及相應的特征信息進行有效的提取,但這同時也是以構建更大的數據集和更長的模型訓練時長為代價的。GNN與其他的神經網絡相類似,其表現形式類似一個黑盒。因此,如果想要在真實的EDA流程中應用GNN, GNN預測的安全性以及可解釋性是我們不可忽視的一個重要問題。
(2)GNN模型的訓練過程通常對運行時間以及對應數據集的大小具有嚴格的要求,需要針對EDA工具的輸出結果對數據進行收集并標記。但現階段相關數據集的獲取是非常困難的,一方面涉及具體商業保密問題,集成電路的設計企業不會主動將這部分數據進行公開。另一方面,開源數據的獲取也同樣缺乏相關渠道,雖然近年來一些研究團隊專門針對基于機器學習的EDA開源數據集進行了研究,例如北京大學林亦波教授團隊在2022年發布了針對機器學習的EDA數據集CircuitNet[52],但這并不是為GNN模型而定制的。針對這一問題,可以采用像訓練其他神經網絡一樣事先進行模型的預訓練過程,進而采用遷移學習的方式,將已訓練好的模型遷移至與之相類似的問題。例如,文獻[31]便采用了遷移學習的策略,能夠大幅度縮短GNN模型的訓練時間以及所需要的訓練數據量。再比如,可以采用“共享”與“微調”相結合的方式,即對于某一類基于GNN的EDA方法而言,可以將GNN模型的構建過程劃分為“共享層”與“微調層”兩個部分,一些EDA求解問題的共性參數可以放到“共享層”中進行訓練,對于某些EDA求解問題所獨有的參數則可以在“微調層”中進行訓練,那么對于一個已預訓練好的GNN模型而言,在向另一個EDA求解問題進行遷移的過程中,便只需針對GNN模型的“微調層”參數進行訓練即可,這對于降低訓練GNN所需要的樣本數量以及訓練時間是非常有利的。
(3)從EDA的角度來看,輸入到GNN模型中的圖數據大多是不同抽象級別的電路網表,通常情況下這些電路網表的規模會非常大,這樣便導致輸入到GNN模型的圖數據需要維護一個非常巨大的并且稀疏的鄰接矩陣,這對計算量的要求是非常巨大的。與一些簡單的有向圖或是無向圖相比較,EDA工作流程中的電路網表往往表現為一個復雜且有向的超圖結構,因此,研究特定的GNN架構以使其能夠更好地處理EDA電路網表的超圖結構數據仍然是一個非常值得探索的研究方向。
(4)現階段GNN架構的實現大多依賴圖形處理器(Graphics Processing Unit, GPU)及其相關的生態環境,例如PyTorch的PyTorch Geometric(PyG),TensorFlow與Keras的Spektral,以及與架構無關的深度圖形庫(Deep Graph Library, DGL)。但需要注意的一點在于上述工具生態距離完全自主可控仍存在較大的差距,現階段仍需依賴國外科技巨頭的GPU顯卡,還做不到相應國產GPU生態的支持,相應的基于GNN的EDA技術仍存在較大的被“卡脖子”的風險,這一點與傳統的基于機器學習的EDA技術相類似,但不同之處在于,傳統的機器學習算子庫的兼容相對而言較易實現,國內外也出現了許多相似的研究,例如,在半定制的FPGA上實現對普通PyTorch庫的兼容,從而可以完美實現對GPU的替代[53]。但GNN相關的研究現階段仍停留在理論探索階段,尚未出現實際替代產品。因此,大力發展國產GNN算子庫相兼容的生態,構建具有自主可控的軟硬件環境是我們下一步需要重點考慮的內容。
(5)上面提到的基于GNN的EDA技術的解決方案最終需要嵌入到實際的EDA工具內部,以此來指導EDA設計流程的優化,依據GNN模型對EDA工具設計流程的影響程度,現階段主要可以總結為以下3類:EDA工具調用GNN模型、將EDA工具與GNN模型進行有效集成以及基于GNN模型的輔助優化決策,在上述3個層次中,無人參與的程度由低到高不斷遞進,在最后一個層次中,可以根據EDA工具的輸出結果給出合理的性能優化建議,這樣可以顯著減少EDA設計流程中由于人為參與所導致的一系列的不確定性因素,提供智能化的輔助設計方法。與此同時,GNN模型優化輸出結果的可兼容性是非常重要的,如何將GNN模型的優化結果與現有主流EDA工具的中間結果相兼容,是實現上述將GNN逐步融入到EDA工具內部的關鍵。
5 結束語
將GNN技術應用于解決EDA流程,通過這種方式EDA工具可以從先前的經驗中進行學習,并能夠更有針對性地解決一些模型構建、性能預測以及最優求解問題。截至目前,GNN技術已在EDA體系的各個流程中得到了應用。本文圍繞基于GNN的EDA技術,將GNN在EDA流程中各不同階段的應用情況進行了綜合性的闡述,在此基礎上,總結了當前基于GNN的EDA技術所面臨的一系列挑戰,給出了相對應的發展建議。作為前沿領域最新的發展方向,基于GNN的EDA技術中仍存在許多未知的問題值得進一步研究,這需要集成電路設計及相關領域的專家學者共同攜手,共同提升現有EDA工具的結果質量。同時作為先進集成電路技術未來的一個重要發展方向,相信隨著相關研究的不斷深入,基于GNN的EDA技術將成為未來我國芯片產業突破“卡脖子”問題的重要途徑。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代裝飾(2020年7期)2020-07-27 01:27:42
數學物理學報(2020年2期)2020-06-02 11:29:24
流行色(2020年1期)2020-04-28 11:16:38
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
