低面積與低延遲開銷的三節點翻轉容忍鎖存器設計
2023-10-17 01:15:14閆愛斌黃正峰
電子與信息學報 2023年9期
關鍵詞:影響
閆愛斌 申 震 崔 杰 黃正峰
①(安徽大學計算機科學與技術學院 合肥 230601)
②(合肥工業大學微電子學院 合肥 230601)
1 引言
隨著CMOS技術的不斷發展,重離子、中子、質子、α粒子和電子等高能輻射粒子的撞擊會導致集成電路發生軟錯誤,如單節點翻轉(Single Node Upset, SNU)、雙節點翻轉(Double Node Upset,DNU)和3節點翻轉(Triple Node Upset, TNU)[1]。軟錯誤是瞬態錯誤,這意味著受影響的電路不會受到物理損壞,并且可以通過數據重新加載或抗輻射加固設計(Radiation Hardening By Design, RHBD)方法消除錯誤。據悉,在深亞微米和納米技術中,單粒子多節點翻轉對電路構成了嚴重威脅[2]。研究表明,電路越來越高度集成,相鄰電路節點的邏輯狀態就容易受到電荷共享機制下單個高能粒子的撞擊的干擾。因此,不僅應考慮SNU和DNU,還應考慮TNU對電路的影響,而研究低面積與低延遲開銷的3節點翻轉容忍鎖存器即變得越來越重要。
為了緩解現有鎖存器加固主要存在的問題,本文基于RHBD方法,提出一種基于雙聯互鎖存儲單元 (Dual-Interlocked-storage-CEll, DICE)和C單元的TNU容忍鎖存器,同時實現低面積與低延遲開銷。本文所提鎖存器主要包括兩個用于存儲邏輯值的SNU自恢復DICE單元和3個用于雙級錯誤攔截(Dual-Level Error-Interception, DLEI)的C單元,為鎖存器提供完備的TNU/DNU/SNU容忍性。由于使用了時鐘門控(Clock-Gating, CG)技術和少量晶體管,所提鎖存器在延遲、面積和延遲功耗面積積(Delay-Power-Area-Product, DPAP)方面的開銷很小。仿真結果表明,與最先進的TNU容忍鎖存器設計相比,所提出的鎖存器具有TNU/DNU/SNU容忍性和低開銷特性。
2 已有的加固結構
目前,國內外學者提出了許多基于RHBD方法的加固鎖存器[3–6]。一類加固方法通過提高節點電容和晶體管尺寸增加節點的關鍵電荷,以提高鎖存器容忍多節點翻轉的能力,但其只能部分容忍多節點翻轉;另一類加固方法通過修改鎖存器的結構,以實現完全容忍,使得鎖存器輸出正確邏輯值[3]。注意到,基于C單元和DICE單元的第2類加固方法較為常用。一些常用的基本元件如圖1所示。圖1分別顯示了雙輸入反相器、傳輸門、DICE單元和C單元的電路圖。

圖1 基本元件
圖1(a)是雙輸入反相器的結構圖,對傳統反相器輸入端進行了分離。圖1(b)是傳輸門的結構圖,即一個PMOS晶體管的柵極連接到反向時鐘信號(Negative system ClocK, NCK),一個NMOS晶體管的柵極連接到時鐘信號(system CLocK, CLK),它的作用相當于時鐘信號的開關器件。圖1(c)是DICE單元的結構圖,DICE單元可以從任何SNU中自恢復,但是它僅能從部分DNU中自恢復。圖1(d)分別是2輸入、3輸入C單元以及基于時鐘門控(CG)的C單元結構圖。當C單元的輸入值相同時,輸出值為輸入值的相反值。但是,當其輸入值變得不同時,C單元將進入高阻態,輸出將暫時保持原先的值。這意味著,如果C單元輸入端的值變化是由錯誤引起的,則C單元可以消除錯誤的影響,即輸出端的值仍然暫時正確。下面介紹一些典型的鎖存器加固設計方案。
圖2(a)為反饋冗余SNU容忍(FEedback Redundant SNU-Tolerant, FERST)鎖存器結構[7]。該結構由多個C單元組成,充分利用3個C單元消除鎖存器內部粒子撞擊造成的影響。該鎖存器通過C單元建立反饋冗余機制,用冗余反饋線控制SNU,以達到容忍SNU的目的。然而,該鎖存器不能容忍DNU及TNU。
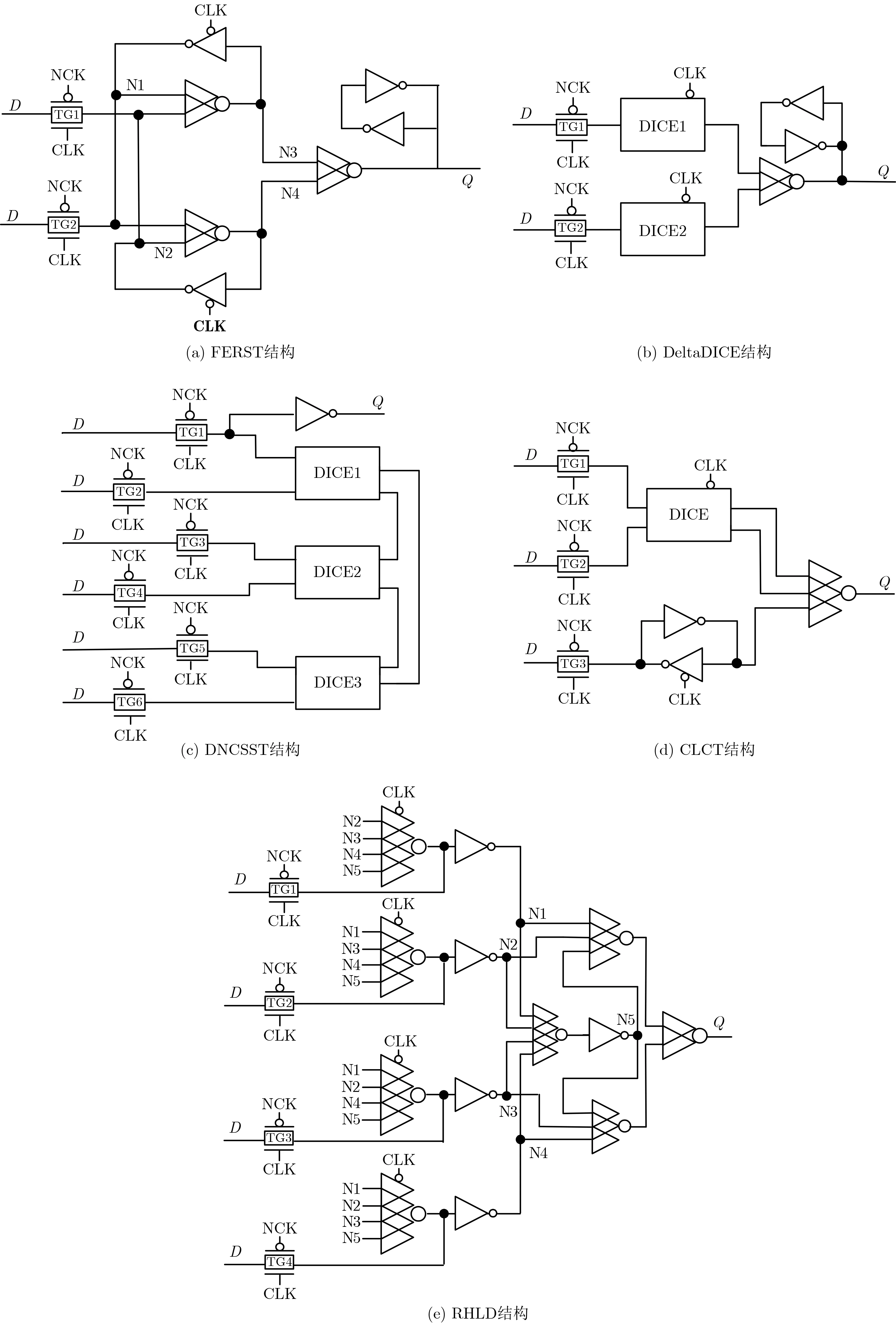
圖2 已有的加固結構
圖2(b)為三角形DICE (Delta Dual-Interlockedstorage-CEll, DeltaDICE)鎖存器結構[8]。該結構不僅能實現SNU容忍,也能實現DNU容忍。該鎖存器由3個DICE單元組成,通過提供足夠的冗余結點來實現SNU容忍以及DNU容忍。然而,該鎖存器使用多個DICE單元不僅使得面積增大,也造成較高的功耗,并且,該鎖存器不能容忍TNU。
圖2(c)為雙節點電荷共享SEU容忍 (Double Node Charge Sharing SEU Tolerant, DNCSST)鎖存器結構[9]。該結構由2個DICE單元、1個2輸入C單元以及1個輸出端電荷保持器組成。該鎖存器能實現SUN容忍。若一個SNU影響任何一個DICE單元,其中儲存的數據都不會發生改變,即該鎖存器的輸出端仍會保持正確的邏輯值,顯然該鎖存器能實現SNU容忍。該鎖存器通過2個DICE單元和1個2輸入C單元組合也可以實現DNU容忍。然而,該鎖存器不能容忍TNU。
圖2(d)為電路和布局組合技術 (Circuit and Layout Combination Technique, CLCT)鎖存器結構[10]。該結構由1個時鐘門控DICE單元、1個反饋環以及1個在輸出端的3輸入C單元組成。通過采用電路結構和布局相結合的方式,可增強多節點翻轉容忍性。該鎖存器中只有4個敏感節點對,可以較大程度地減少敏感節點對。通過調整布局位置,這些敏感節點對盡可能彼此分離,較好地解決了敏感節點對上的錯誤電荷收集問題。該鎖存器不僅可以實現SNU容忍,也可以實現DNU容忍。然而,該鎖存器的傳輸延遲和面積較大,故具有較大的開銷,且并不能實現TNU容忍。
圖2(e)為抗輻射加固鎖存器(Radiation Hardened Latch Design, RHLD)結構[11]。該鎖存器主要利用了C單元的錯誤攔截特性,通過多個C單元及傳輸門建立反饋連接,實現容忍3節點翻轉的功能。但是,由于使用較多的C單元,電路內部節點可能會長時間保持高阻態,導致漏電流,并且該鎖存器使用了80個以上數目的晶體管,具有較大的面積和功耗開銷。
3 本文所提加固鎖存器設計
3.1 電路結構及工作原理
本文所提鎖存器設計的電路原理圖如圖3所示。
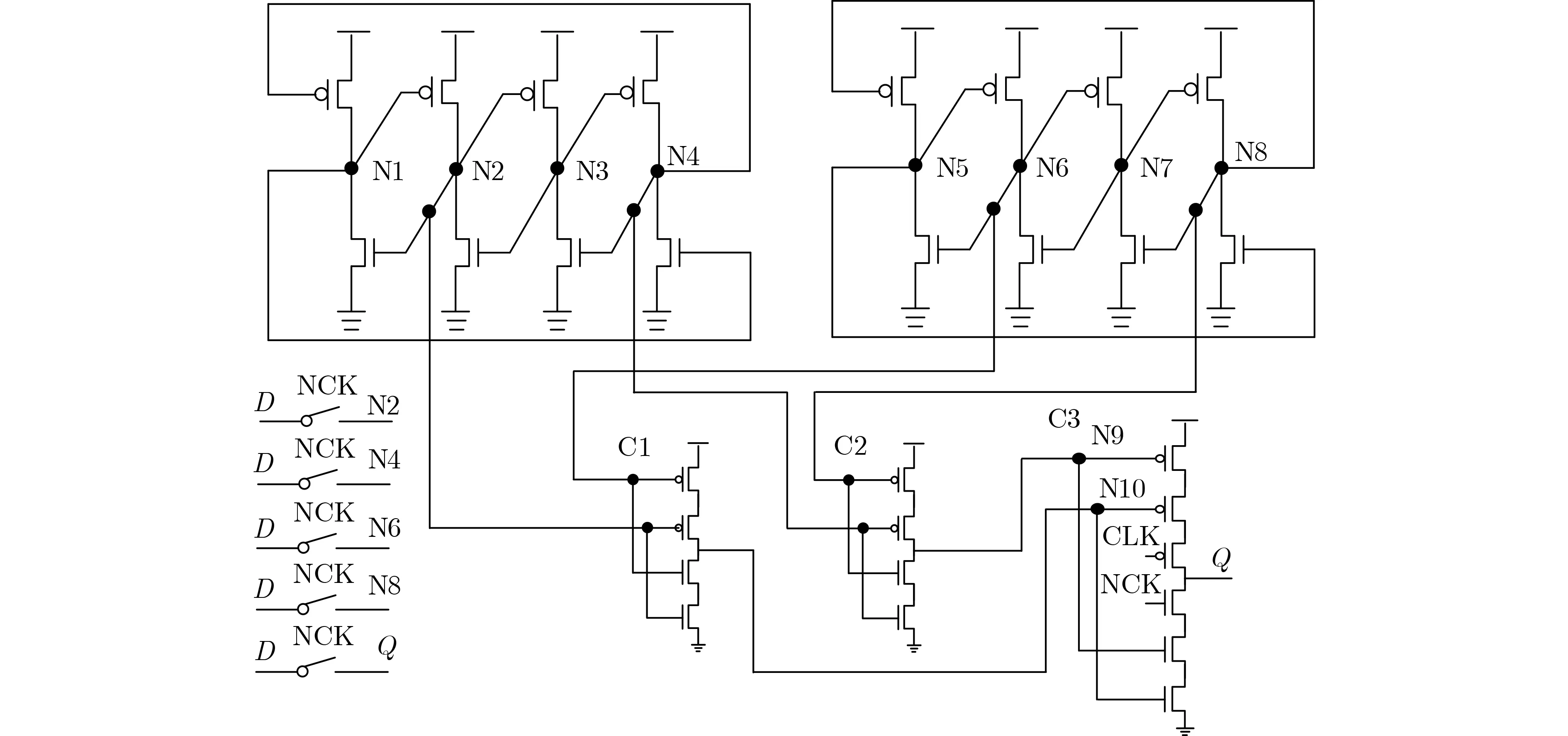
圖3 本文所提鎖存器原理圖
可以看出,鎖存器由2個DICE單元、2個2輸入C單元(C1和C2)、1個基于CG的2輸入C單元(C3)和5個傳輸門(TG)組成。其中,DICE用于存儲值,C1和C2用于1級錯誤攔截,C3用于2級錯誤攔截,TG用于初始化鎖存器的值。在鎖存器中,D, Q,CLK和NCK分別是輸入、輸出、系統時鐘和反向系統時鐘信號。C3使用了鐘控(見圖3),即一個PMOS管連接到時鐘信號,一個NMOS管連接到反向時鐘信號,使該鎖存器在透明期避免各器件同時向Q輸出值所產生的電流競爭,降低了功耗和延遲。圖4顯示了所提出鎖存器的版圖設計。
當CLK=1且NCK=0時,5個傳輸門打開,鎖存器在透明模式下工作。因此,輸入信號D通過傳輸門將信號傳輸至內部節點N2, N4, N6, N8。隨后,可以獲得N1, N3, N5, N7, N9和N10的信號值。需要注意的是,Q是通過傳輸門而不是C3的輸出確定的,因為C3的輸出通過CLK和NCK信號被阻止,以減少透明模式下Q點的電流競爭和D到Q的傳輸延遲。
當CLK=0且NCK=1時,5個傳輸門關閉,鎖存器切換到保持模式。此時傳輸門關閉,但鐘控C單元被打開。因此,Q僅由N9和N10通過C3驅動,C3將存儲值輸出到Q。
3.2 容錯原理
接下來,討論保持模式下鎖存器的SNU/DNU/TNU容錯原理。
首先,考慮電路發生了SNU。某節點發生翻轉,有兩種可能,從0翻轉到1和從1翻轉為0。由于DICE本身具有SNU容忍性且能自恢復[12],因此鎖存器發生SNU也是可以自恢復的,顯然鎖存器可以容忍SNU。
接下來,考慮該鎖存器發生了DNU。由于DICE是對稱構造的,因此只需要考慮以下情況:情況D1:沒有任何DICE受到影響,關鍵節點對有
在(D1)的情況下,由于DICE沒有錯誤,可以消除C3單元節點中的錯誤,即鎖存器是DNU可恢復的。在(D2)的情況下,每個DICE都有一個SNU,但DICE是SNU可自恢復的。因此,可以消除DICE的錯誤,即在這種情況下,鎖存器是DNU自恢復的。在(D3)的情況下,當N1,N2,N3和N4中的兩個受到DNU的影響時,受影響的DICE中的所有節點都將被翻轉為錯誤值,因為受影響的DICE在最壞的情況下無法提供DNU容忍性[12]。但是,由于C1和C2提供的錯誤攔截機制,錯誤的值可以被C1和C2屏蔽,即C1和C2仍然可以輸出正確的值。因此,鎖存器最終輸出值Q依然是正確的。此外,當一個DICE的一個節點以及N9, N10和Q中的一個節點受到DNU的影響時,鎖存器可以從錯誤中自恢復。這是因為,DICE是SNU自恢復的,然后可以消除C3單元節點的錯誤值以返回到正確的狀態。總之,鎖存器可以容忍任何可能的DNU。
最后,考慮電路發生了TNU。由于DICE是對稱構造的,因此只需要考慮以下情況。情況T1:沒有DICE受到影響,關鍵節點列表僅有
在(T1)的情況下,由于DICE沒有錯誤,它們可以消除C3單元節點中的錯誤,即在這種情況下,鎖存器是TNU自恢復的。在(T2)的情況下,如上所述,受影響的DICE在最壞的情況下無法提供DNU容忍性,因此受TNU影響的DICE中的所有節點都將翻轉到錯誤的值。但是,錯誤的值可以被C1和C2屏蔽,即C1和C2仍然可以輸出正確的值。因此,鎖存器輸出值Q依然是正確的。換言之,在這種情況下,鎖存器可以容忍任何可能的TNU。在(T3)的情況下,如果節點列表包含N2和N6,則這種情況類似于(T2)的情況。否則,任何DICE中將只有1個節點受到影響。但是,由于任何DICE都可以從任何SNU自恢復,因此受影響的節點N2和N6(或N2和N7)可以首先從TNU自恢復,從而使DICE消除N9和Q上的錯誤。在這種情況下,鎖存器可以容忍任何可能的TNU。總之,提出的鎖存器可以容忍任何可能的TNU。
3.3 注錯實驗
按照電路中同時發生翻轉的節點數目,分別對SNU, DNU和TNU加以分析,并且使用HSPICE工具進行故障注入分析。仿真條件如下:鎖存器采用22 nm CMOS工藝設計。電源電壓設置為0.8 V并將仿真溫度設定為室溫。使用Synopsys HSPICE進行了仿真實驗。對于故障注入,采用了雙指數電流源模型,電流脈沖的上升和下降時間常數分別設置為0.1 ps和3.0 ps。事實上,該模型在此前的研究中已被廣泛使用[3,13–17]。如文獻[3]采用雙指數電流源模擬高能粒子入射引起的瞬態電流,并將仿真時故障注入電荷量設置為15 fC,文獻[17]將故障注入電荷量選擇性設置為20 fC。本文注入的電荷高達25 fC,這足以考慮最壞的情況,從而驗證所提出的鎖存器的SNU, DNU和TNU容忍性,對所提鎖存器的晶體管尺寸進行了優化,使得PMOS晶體管的W/L為32/22 nm而NMOS晶體管的W/L為28/22 nm。
圖5顯示了該鎖存器無注錯情況下的仿真結果。從中可以看出,當CLK=1時,D上的信號可以傳播到Q;當CLK=0時,D的狀態可以存儲在鎖存器中,即該鎖存器可正常工作。
圖6顯示了考慮所有關鍵SNU節點情況下的仿真結果。當Q=0時,在這些節點上注入SNU的時刻分別為0.30 ns, 0.70 ns, 1.10 ns, 3.70 ns, 4.20 ns和4.70 ns;當Q=1時,在這些節點上注入SNU的時刻分別為1.70 ns, 2.20 ns, 2.70 ns, 5.70 ns, 6.20 ns和6.70 ns。從圖6可以看出,該鎖存器可以從任何可能的SNU中自恢復。因此,該鎖存器具有SNU容忍性和自恢復性。

圖6 SNU注錯實驗
圖7顯示了所有關鍵節點對
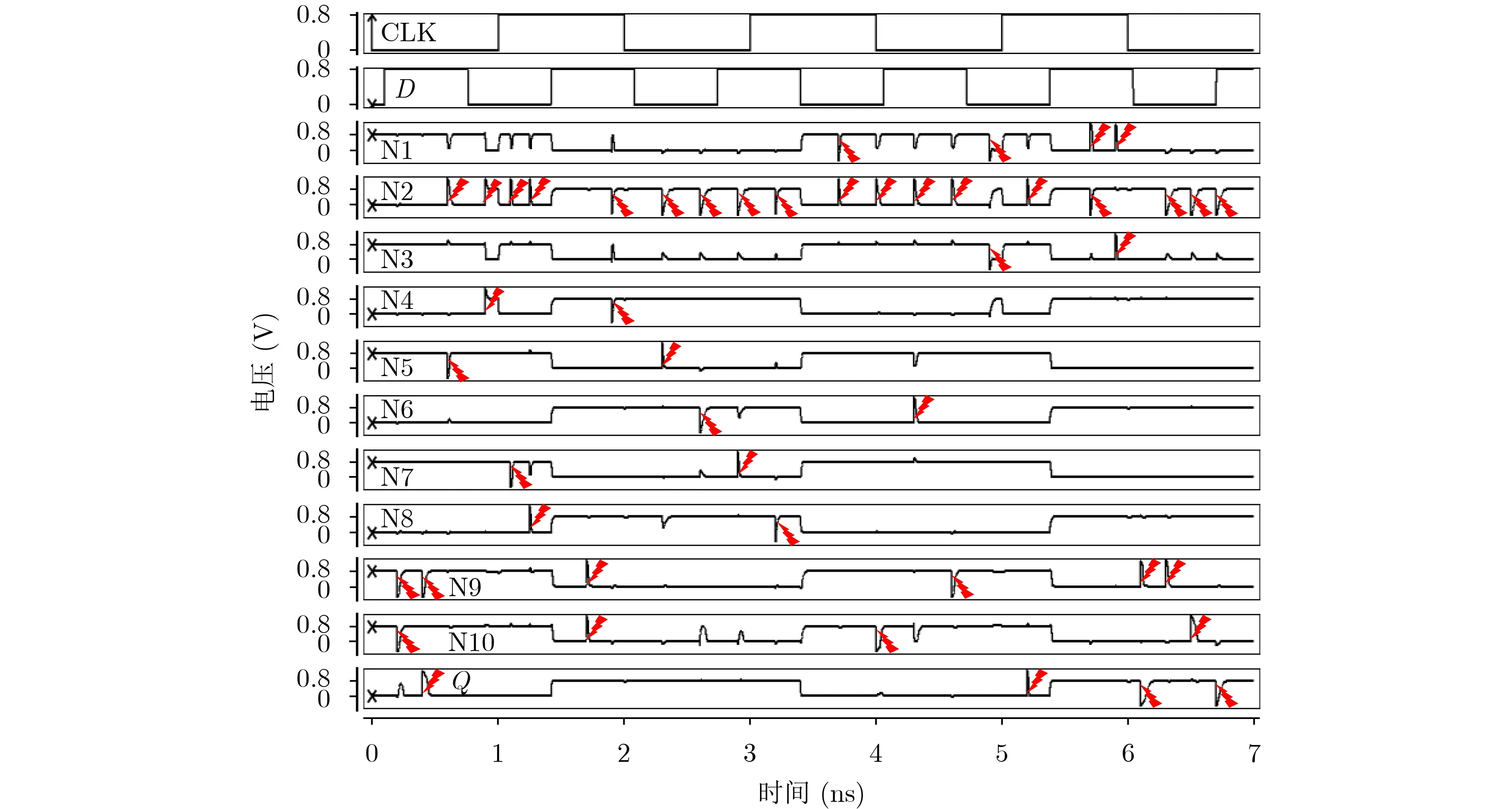
圖7 DNU注錯實驗
圖8顯示了TNU注錯實驗的仿真結果,考慮了關鍵節點列表
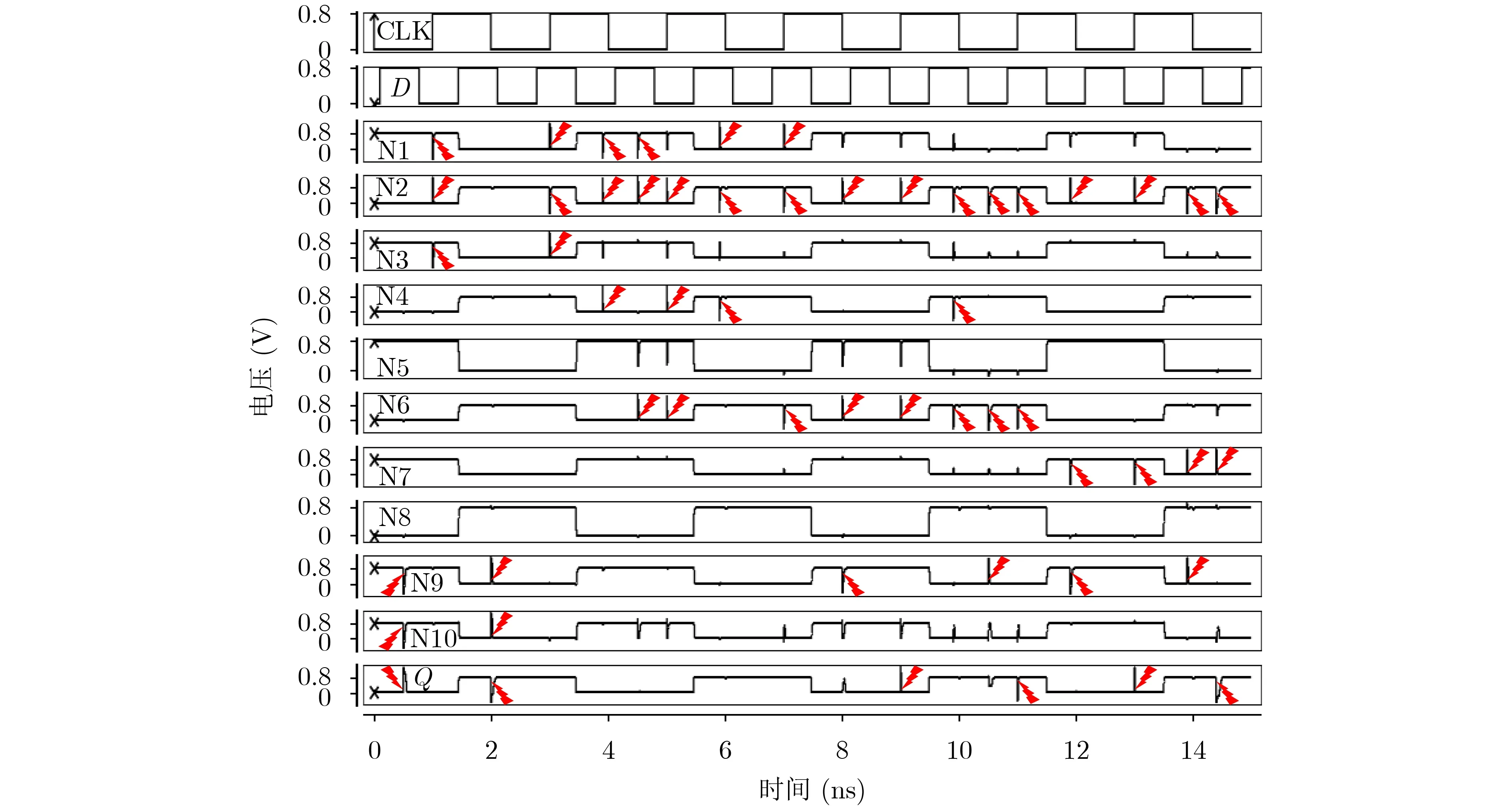
圖8 TNU注錯實驗
4 鎖存器比較
4.1 可靠性比較
為了公平比較,將典型的鎖存器,如FERST、雙節點翻轉恢復(Double Node Upset resilient,DNUR)鎖存器[18]、互鎖軟錯誤加固鎖存器(Interlocking Soft Error Hardened Latch, ISEHL)[19]、三模冗余(Triple Modular Redundancy, TMR)鎖存器[20]、高度可靠單粒子翻轉加固(Highly Reliable SEU/SET hardened, HRUT)鎖存器[21]、三節點翻轉容忍鎖存器( Triple Node Upset Tolerant Latch,TNUTL)[22]、RHLD、低開銷三節點翻轉完全容忍(Low Cost and TNU-completely Tolerant, LCTNUT)鎖存器和三節點翻轉自恢復鎖存器(Triple-Node-Upset self-Recoverable Latch, TNURL),包括未加固的鎖存器(即傳統的靜態D鎖存器),使用與所提鎖存器相同的參數進行了設計。
這些鎖存器的節點翻轉容忍能力比較結果如表1所示。可以看出,未加固的鎖存器不具有SNU,DNU或TNU容忍性。FERST, ISEHL, TMR和HRUT鎖存器具有SNU容忍性。但是,它們不能容忍DNU或TNU。DNUR鎖存器具有DNU容忍性,但是不能容忍TNU。TNUTL, RHLD, LCTNUT,TNUHL, TNURL鎖存器和本文鎖存器可以提供完備的TNU容忍性,因此它們屬于同一類型。但是,TNUTL鎖存器無法長時間存儲值,因為它沒有任何反饋回路。對于其他同類型鎖存器,它們要么具有較大的開銷,要么在其存儲模塊中具有較高的電荷共享發生概率(易發生多節點翻轉)。
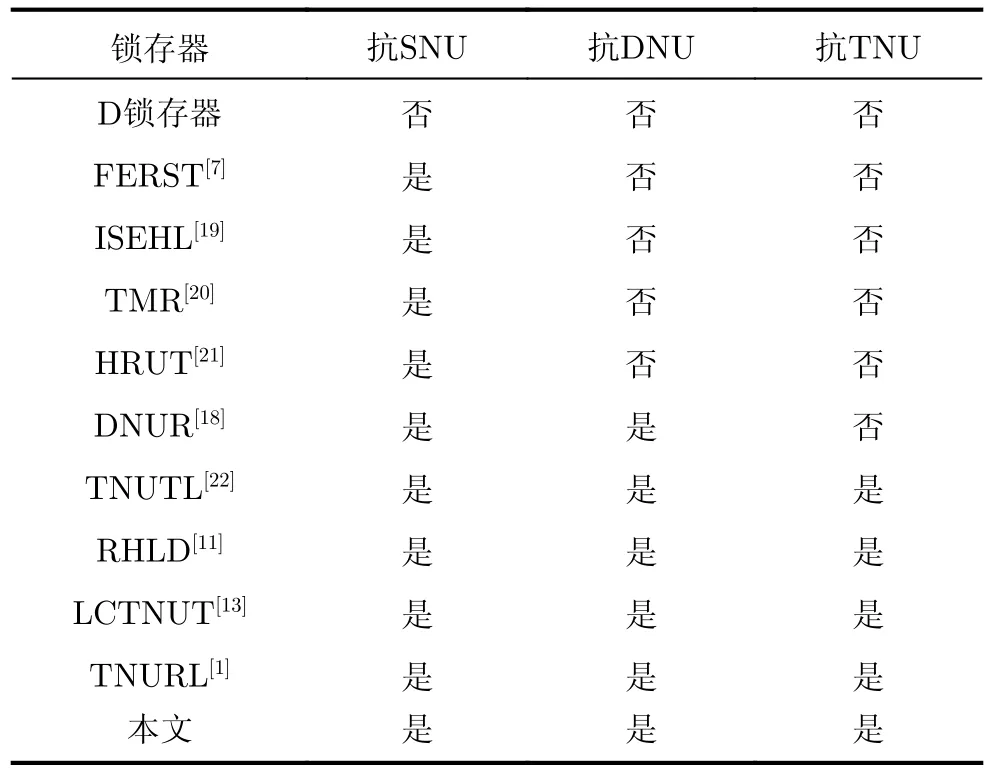
表1 鎖存器可靠性對比結果
4.2 開銷比較
表2分別顯示了鎖存器的D至Q傳輸延遲、平均功耗(動態和靜態)、硅面積和DPAP的開銷比較結果,其中面積是由文獻[13]提出的經典模型計算的。
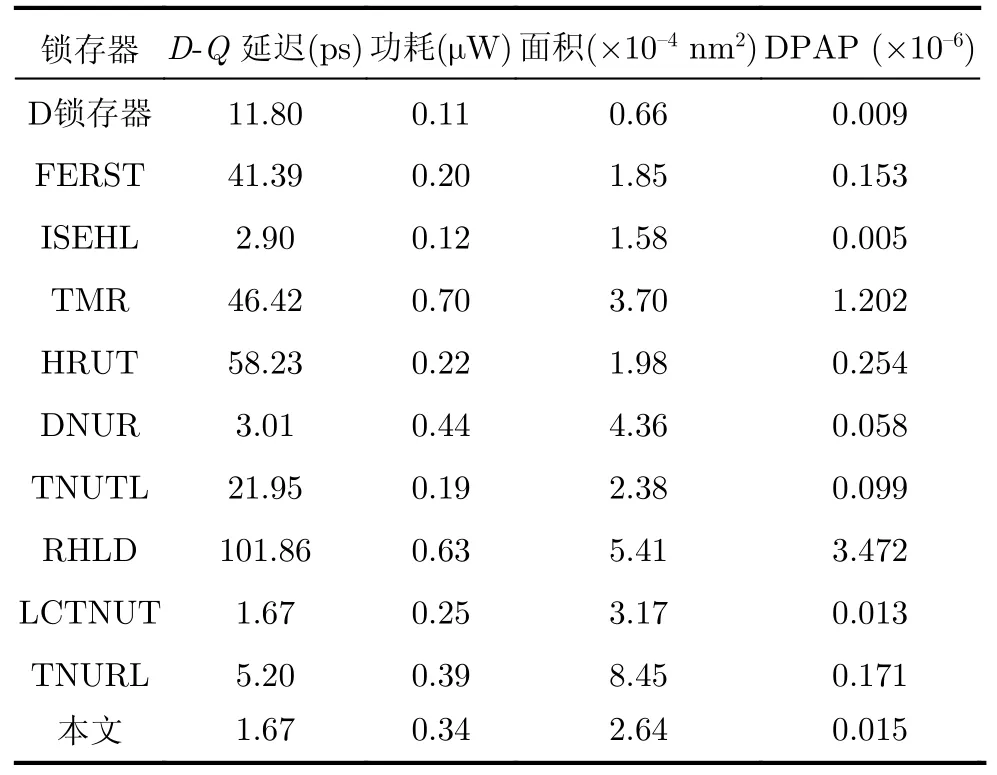
表2 鎖存器性能參數對比結果
從表2可以看出,RHLD鎖存器的D-Q延遲最大。這主要是由于使用多級錯誤攔截(MLEI)機制為鎖存器提供TNU容錯能力所導致的。盡管FERST,TMR, HRUT和TNUTL鎖存器(包括未加固的鎖存器)未采用MLEI機制,但由于從D到Q存在許多單元器件,或者在Q處存在保持器,它們的延遲仍然很大。ISEHL, DNUR, LCTNUT和TNURL鎖存器的延遲(包括本文提出的鎖存器)很小,因為它們使用了從D到Q的高速路徑。部分鎖存器(如TMR,DNUR, RHLD和TNURL)的功耗很大,主要是因為它們的硅面積大或結構中有較多的電流競爭。事實上,與這些鎖存器相比,我們提出鎖存器的功耗也較低。
從表2還可以看出,TNURL鎖存器具有最大的硅面積,因為它采用最多數目的晶體管來保證TNU容忍性。與TNURL鎖存器相比,我們提出的鎖存器的硅面積更小,因為本文使用更少的C單元來創建DLEI機制,這足以提供TNU容忍性。雖然其他鎖存器具有相當的或更小的硅面積,但是其中一些鎖存器并不能提供完備的TNU容忍性,這意味著大多數鎖存器以不可或缺的硅面積開銷為代價來提供高可靠性。
此外,從表2可以看出,RHLD鎖存器的DPAP最大,這主要是由于其最大的硅面積和延遲。TMR鎖存器的DPAP仍然很大,這主要是由于其較大的延遲、功耗和硅面積。ISEHL鎖存器的DPAP最小,這主要是由于其較小的延遲和硅面積。但是,該鎖存器僅能容忍SNU。為了進行定量比較,本文計算了提出鎖存器與其他TNU容忍鎖存器相比的開銷改進比率(Ratios of Overhead Improvements,ROI)
延遲ROI= [(本文所提鎖存器的延遲–已有鎖存器的延遲)/已有鎖存器的延遲]×100% (1)式(1)顯示了延遲ROI的計算公式,從而可以得到延遲ROI的平均值。同樣,可以得到功耗、硅面積和DPAP的ROI計算公式。
如表3所示,可以計算得出,與最先進的TNU容忍鎖存器TNURL相比,提出的鎖存器分別節省了67.88%的延遲、12.82%的功耗、68.76%的面積和91.23%的DPAP。這表明,與TNURL鎖存器相比,提出的鎖存器具有更小的開銷。與LCTNUT鎖存器相比,提出鎖存器的面積減少了16.72%。同樣,與TNU容忍鎖存器RHLD相比,可以計算出所提鎖存器節省了98.36%的延遲、46.03%的功耗、51.20%的面積和99.57%的DPAP。此外,與TNU容忍鎖存器TNUTL相比,可以計算出所提出的鎖存器,使用了額外的78.95%的功耗和10.92%的面積,但是節省了92.39%的延遲和84.85%的DPAP。總體而言,與經典的TNU容忍鎖存器相比,所提出的鎖存器雖然功耗增加了14.03%,但是平均分別節省了64.65%的延遲、31.44%的面積和65.07%的DPAP開銷,這表明了所提出鎖存器的低延遲與低面積開銷特性。表4顯示了抗TNU鎖存器的靜態功耗和動態功耗。
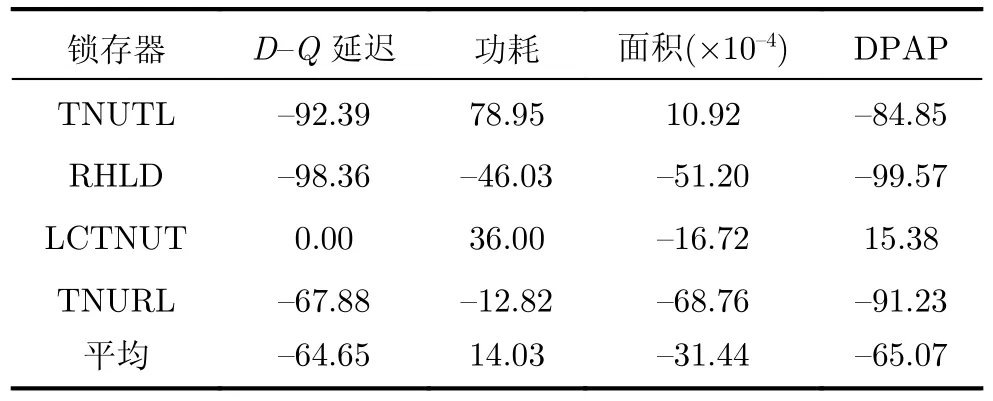
表3 抗TNU鎖存器的相對開銷比較(%)

表4 抗TNU鎖存器的靜態功耗和動態功耗(μW)
4.3 PVT分析
隨著工藝不斷改進,晶體管尺寸迅速縮小,溫度/電壓/工藝波動對納米集成電路的可靠性影響日益嚴重。因此,本文對能容忍3點翻轉的加固鎖存器(TNURL,TNUTL,RHLD,LCTNUT以及本文所提鎖存器)在溫度/電壓/工藝波動下的延遲與功耗進行了評估。圖9顯示了鎖存器的溫度和電源電壓變化對延遲與功耗的影響。鎖存器的正常電源電壓設定為0.8V,電源電壓變化范圍為0.75~1.25V,正常溫度設定為25°C,溫度變化范圍為–20~120°C。圖9(a)和圖9(b)分別為溫度波動對鎖存器延遲與功耗的影響,圖9(c)和圖9(d)分別為電壓波動對鎖存器延遲與功耗的影響。
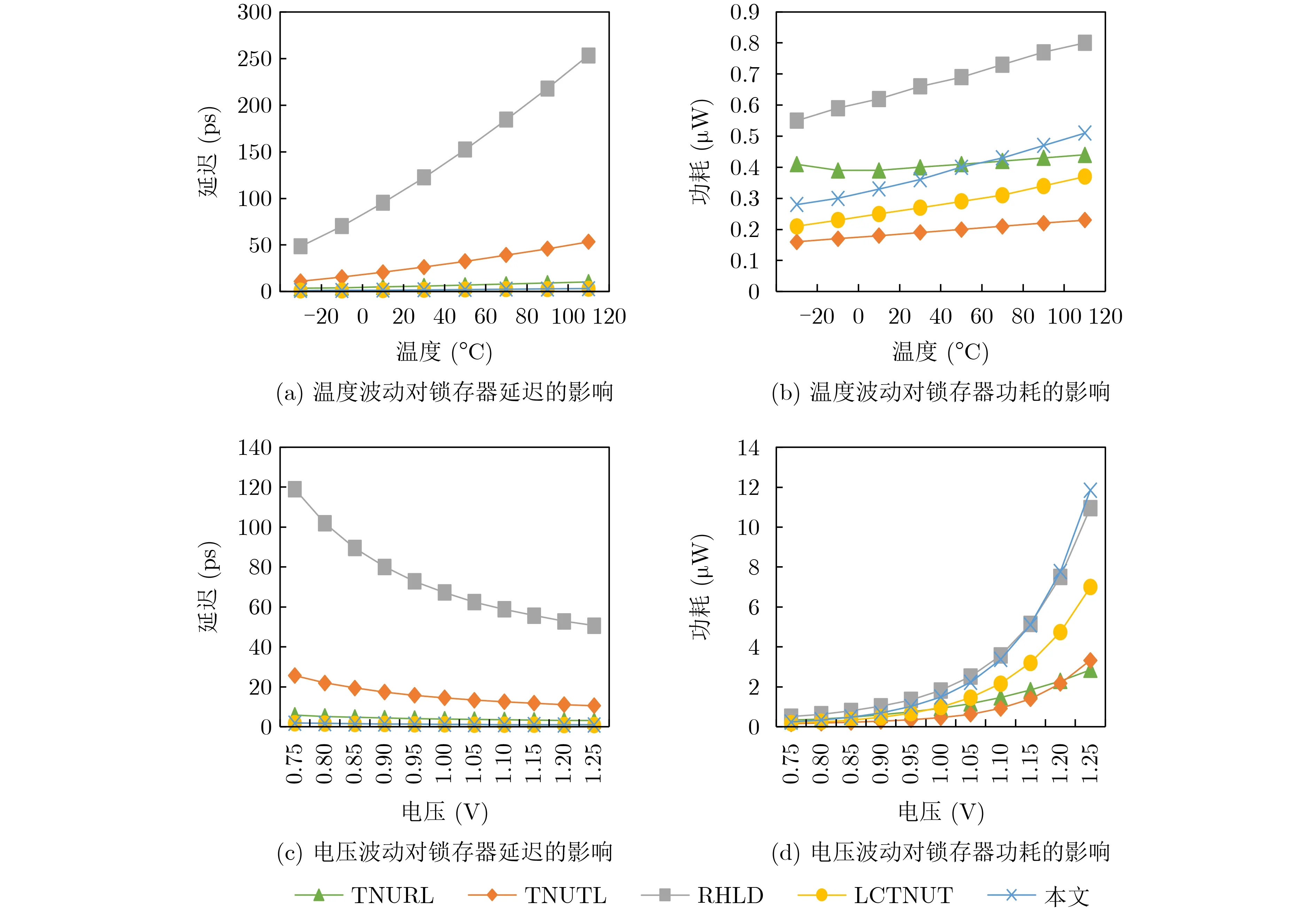
圖9 溫度和電壓變化對鎖存器延遲和功耗的影響
由圖9(a)和圖9(c)可以看出,RHLD鎖存器的延遲對溫度和電壓變化都具有最大的敏感性,因為該鎖存器采用多級C單元來攔截TNU。而TNURL,LCTNUT以及本文提出的鎖存器的延遲對溫度和電壓變化的敏感性低,因為它們均采用了從輸入D直接到輸出Q的高速路徑。由圖9(b)可知,本文所提鎖存器的功耗對溫度變化的敏感度較高。由圖9(d)可以看出,RHLD和本文鎖存器的功耗對電源電壓變化的敏感度較高。
圖10顯示了鎖存器的工藝變化對延遲與功耗的影響。工藝變化包括閾值電壓波動和工藝尺寸波動等。閾值電壓相對變化由1~10表示;工藝尺寸波動范圍為22~30 nm。圖10(a)和圖10(b)分別顯示了閾值電壓波動對鎖存器延遲和功耗的影響。從圖10(a)可以看出,本文鎖存器的延遲受影響程度較小。由圖10(b)可知,本文鎖存器的功耗對閾值電壓變化的敏感度較高。圖10(c)和圖10(d)分別顯示了工藝尺寸波動對鎖存器延遲和功耗的影響。從圖10(c)可以看出,本文鎖存器的延遲對工藝尺寸波動的敏感性低。由圖10(d)可知,本文鎖存器的功耗對工藝尺寸波動的敏感度較高。總之,所提鎖存器具有適當的PVT敏感度,尤其是延遲對PVT波動的敏感度更低。
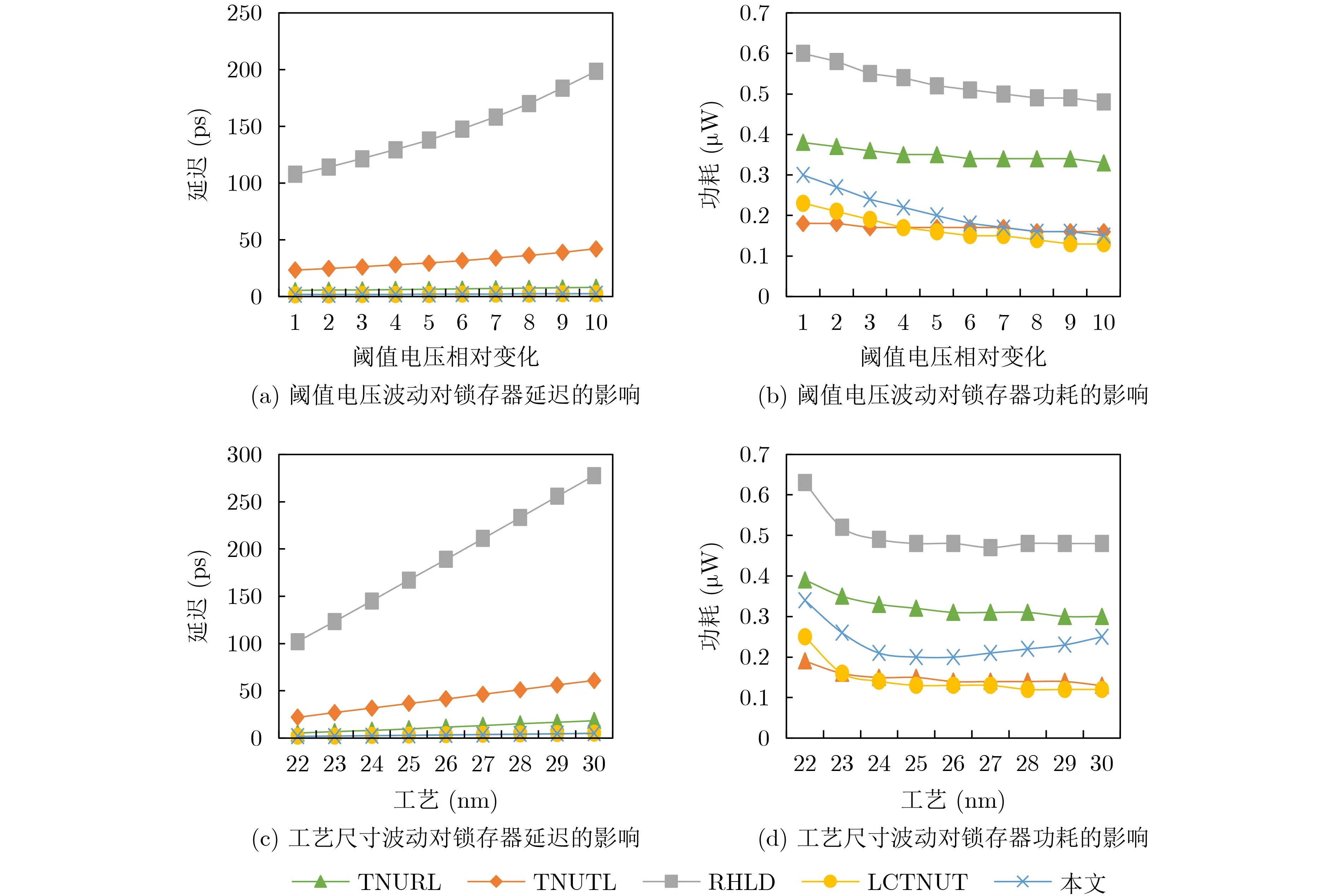
圖10 晶體管工藝變化對鎖存器延遲和功耗的影響
5 結束語
本文基于RHBD方法,提出一種新穎的基于雙DICE和雙輸入C單元的3節點翻轉容忍的鎖存器。本鎖存器可以容忍任何可能的單節點翻轉、雙節點翻轉及3節點翻轉。該鎖存器在D-Q延遲、功耗、硅面積和延遲功耗面積積方面的開銷較低。仿真結果表明,與先進的鎖存器設計相比,所提鎖存器在較低的延遲與面積開銷的情況下,能容忍3節點翻轉,并且具有適當的PVT敏感度。
關于未來工作,會將該鎖存器集成到一定規模的電路中,對整體電路的抗輻照能力進行評估,對時序、性能、面積及功耗等方面進行優化,并分析所設計的鎖存器對降低電路總體故障概率的貢獻。目前,已經嘗試將鎖存器電路放入ISCAS89電路中,這將是未來持續推進的工作。
猜你喜歡
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
家庭影院技術(2020年10期)2020-12-14 07:54:18
媽媽寶寶(2017年3期)2017-02-21 01:22:28
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
知識經濟·中國直銷(2016年3期)2016-02-27 16:15:49
現代檢驗醫學雜志(2014年6期)2014-02-02 03:02:04
閱讀與作文(小學低年級版)(2011年3期)2011-01-01 00:00:00
