考慮競爭環境的聯邦學習多維契約激勵機制研究
2023-10-17 03:45:13楊揚殷紅建王超
計算機應用研究 2023年10期
關鍵詞:激勵機制
楊揚 殷紅建 王超


摘 要:針對現有激勵機制無法滿足競爭環境下聯邦學習(FL)落地實施需要的現實問題,提出了一種適于競爭環境的多維契約激勵機制。首先,引入了競爭強度描述數據擁有者和任務發布者之間的競爭關系;其次,創新性地設計了一種金錢和FL模型使用權相組合的MM(monetary-the FL model)組合激勵;再次,在MM組合激勵的基礎上,分別在完全信息場景和不完全信息場景下,以任務發布者利潤最大化為目標,構建了適于競爭環境的聯邦學習多維契約激勵機制設計優化問題;進一步,通過理論推導分析了契約可行性及契約最優性,并在此基礎上給出了適于競爭環境的聯邦學習最優契約設計算法;最后,實驗結果表明,以MM組合激勵為基礎的多維契約激勵機制提高了競爭環境下數據擁有者參與聯邦學習的意愿。
關鍵詞:競爭環境; 聯邦學習; 契約理論; 激勵機制
中圖分類號:TP391 文獻標志碼:A 文章編號:1001-3695(2023)10-019-3007-09
doi:10.19734/j.issn.1001-3695.2023.02.0080
Incentive mechanism for federated learning in competitive environment:multidimensional contract approach
Yang Yanga, Yin Hongjiana, Wang Chaob
(a.School of Management Engineering & Business, b.School of Information & Electrical Engineering, Hebei University of Engineering, Handan Hebei 056038, China)
Abstract:Aiming at the existing incentive mechanisms cannot satisfy the demand of implementation for federated learning (FL) in competitive environment, this paper proposed a multi-dimensional contract-based incentive mechanism for FL in competitive environment. Firstly, this paper introduced the competition intensity to measure the competition relationship between the data owners and the task publisher. Secondly, this paper designed a novel incentive form named as MM (monetary-the FL model) combined incentive, which combined monetary with usufruct of FL model. Thirdly, based on MM combined incentive, this paper constructed optimization problems of the multi-dimensional contract-based incentive mechanism design for FL in competitive environment for the task publishers profit maximization under complete information scenario and incomplete information scenario respectively. Finally, experimental results show that the multi-dimensional contract-based incentive mechanism based on MM combined incentive improves the willingness of data owners to participate in FL in competitive environment.
Key words:competitive environment; federated learning(FL); contract theory; incentive mechanism
0 引言
大數據時代,企業數字化轉型被視為占領價值鏈高端與構建競爭新優勢的重要契機[1]。“十四五”規劃中明確指出,要支持企業數字化轉型,加快數字化發展,建設數字中國。在企業數字化轉型過程中,企業間的數據共享有利于降低企業數據獲取成本,提升企業競爭優勢[2]。而隨著數據共享程度的加深,數據隱私泄露的風險也逐步上升。因此,數據隱私保護成為企業數字化轉型升級工作中的重點之一。
針對數據隱私泄露問題,聯邦學習(FL)因其保護數據隱私的優勢而受到關注[3]。而在實現FL過程中,數據擁有者需要先行承擔在自身設備上訓練模型和傳輸運算結果所導致的直接成本,這使得數據擁有者缺乏動力參與FL。此外,由于數據擁有者的直接成本屬于私人信息,FL的任務發布者需要在信息不對稱情況下,設計相應補償以激勵數據擁有者參與FL。而契約激勵機制是應對信息不對稱情況下激勵問題的一種有效機制。因此,契約激勵機制作為解決FL中數據擁有者參與動力不足問題的有效手段而廣受關注[4~6]。
然而,現有FL契約激勵機制無法有效激勵競爭環境下的數據擁有者。在競爭環境下,任務發布者與某些數據擁有者之間存在競爭關系,這些數據擁有者參與FL除了承擔相應的直接成本外,還可能因失去競爭優勢而支付額外的間接成本[7]。如某銀行希望通過FL利用其他銀行(數據擁有者)提供的數據來優化自身產品模型。而FL訓練后的產品模型僅由該銀行持有,這可能使得參與FL的其他銀行在未來競爭中因產品模型上的差距而處于競爭劣勢,導致間接成本的產生。現有FL契約激勵機制在設計激勵時并未考慮這一間接成本,因而無法有效激勵競爭環境下的數據擁有者參與FL。此外,現有FL契約激勵機制研究中,金錢激勵[8~11]和金錢—聲譽組合激勵[12, 13]是主要的激勵方式,以上激勵方式無法滿足競爭環境下某些數據擁有者對FL訓練后的產品模型需求。Mai等人[14]設計了一種雙向拍賣FL激勵機制,使得訓練好的模型可以在設備(數據擁有者)和FL平臺(任務發布者)之間自動交易。這種模型激勵方式雖然對具有競爭關系的數據擁有者有較高吸引力,但對競爭環境下與任務發布者不存在競爭關系的數據擁有者缺乏吸引力,因此亟需一種能在競爭環境下激勵所有數據擁有者的激勵方式。
為了有效激勵競爭環境下所有數據擁有者參與FL,本文提出了適于競爭環境的FL多維契約激勵機制,主要貢獻可概括如下:
a)構建了金錢與FL模型使用權結合的MM(monetary-the FL model)組合激勵。與現有FL激勵機制研究中所采用的其他激勵方式不同,本文構建的MM組合激勵考慮到了競爭環境下某些數據擁有者對FL訓練后FL模型的需求,提高了競爭環境下各類型數據擁有者的參與意愿。
b)設計了競爭環境下的多維契約激勵機制。與現有FL契約激勵機制不同,本文所提出的多維契約激勵機制不僅考慮了數據擁有者的數據質量,而且考量了競爭環境下數據擁有者和任務發布者之間的競爭關系。競爭關系的考量完善了任務發布者對于數據擁有者在競爭環境下參與FL成本的認識,并有效促進了FL在競爭環境下的實現。
1 相關工作
FL是一種分布式隱私保護機器學習技術[15~17]。FL激勵機制的研究是當前聯邦學習研究領域熱點之一,根據數據擁有者貢獻評估側重點的不同,主要從數據質量優先、數據數量優先和數據均衡優先三個角度研究FL數據擁有者激勵問題。
在數據質量優先的激勵機制研究中,對于數據可信度和準確率要求更高,需要激勵數據質量較高的數據擁有者參與,適用于醫療和教育等數據質量敏感度較高的企業。如Yuan等人[18]提出了一種基于拍賣的激勵機制,該機制的設計考慮了數據擁有者數據、信道等信息的真實性,以激勵擁有高質量數據的數據擁有者。Le等人[19]設計了一個基于拍賣的激勵機制,通過在機制設計中考慮真實性來保證數據擁有者分配真實可靠的數據參與FL。Sun等人[20]分別設計了靜態FL激勵機制和動態FL激勵機制,利用聲譽識別并激勵高質量的客戶(數據擁有者)。Lin等人[21]設計了一種基于斯塔克爾伯格博弈的激勵機制,以鼓勵數據擁有者以誠實可信的高質量數據參與FL。
在數據數量優先的激勵機制研究中,由于模型性能與數據量大小有關,需要激勵足夠多的數據擁有者參與,適用于工業等數據數量大的行業。如顧永跟等人[22]提出了一種不平衡數據下預算限制的FL激勵機制,該機制激勵客戶端(數據擁有者)數據量最優選擇下參與FL。Lin等人[23]設計了一種基于斯塔克爾伯格博弈的激勵機制,該機制對貢獻更多數據量的數據擁有者給予更高的獎勵。Wang等人[24]針對基于區塊鏈的FL提出了一種聯合資源分配的激勵機制,該機制基于數據量設計FL訓練階段激勵額度。
在數據均衡優先的激勵機制研究中,需要在激勵足夠多的數據擁有者的同時保證一定的數據可信度和準確率,適用于數據可信度、數據質量和模型性能均衡的行業。如Kang等人[12]將聲譽引入FL激勵機制,以激勵高聲譽設備(數據擁有者)在一定數據量基礎上提供高質量數據。Wang等人[25]提出了四種信息場景下基于契約的激勵機制,這些機制根據Shapley值法評價數據擁有者的貢獻(數據量、數據質量)并激勵其參與FL。Wang等人[26]在分層FL中設計了一種基于區塊鏈的激勵機制,該機制確保了在模型訓練過程中貢獻的數據質量和數據量,以提高FL模型的性能。Li等人[27]設計了一種基于無限重復博弈的激勵機制,該機制評價數據擁有者的貢獻時綜合考慮了數據量和數據質量。
目前,FL激勵機制的研究并未考慮任務發布者與某些數據擁有者之間競爭關系導致的FL間接成本,無法有效激勵競爭環境下的數據擁有者參與FL。鑒于此,本文考慮競爭環境的FL數據擁有者激勵問題,提出金錢與模型使用權相結合的MM組合激勵,并在此基礎上設計一種多維契約激勵機制。
2 系統模型
本章考慮一個競爭環境下的FL,它由一個任務發布者和一組數據擁有者N={1,2,…,N}組成,且任務發布者和數據擁有者之間存在競爭關系。首先,引入競爭強度參數來描述這種競爭關系;其次,根據引入的競爭強度輔助劃分數據擁有者類型;最后,給出競爭環境下的任務發布者以及數據擁有者的利潤函數,為下一節設計多維契約激勵機制提供基礎。
2.1 競爭強度
在大數據時代,企業各自擁有的數據作為優化企業自身產品以吸引更多市場渠道的重要資源而備受保護。而企業擁有它們的競爭對手所沒有的市場渠道,便形成了競爭優勢。當任務發布者與數據擁有者之間存在競爭關系時,數據擁有者參與FL可能會間接導致競爭優勢的削弱,從而產生間接成本,影響了數據擁有者的參與意愿。而現有激勵機制并未考慮到競爭關系帶來的間接成本,難以有效激勵競爭環境下的數據擁有者參與FL。
針對上述問題,引入競爭強度β(β∈[0,1])來量化競爭環境下數據擁有者和任務發布者之間的競爭關系。具體來說,競爭強度大小反映數據擁有者和任務發布者之間競爭關系的激烈程度,即競爭程度。競爭強度β=0表示數據擁有者和任務發布者之間不存在競爭關系,數據擁有者參與FL的成本僅為訓練模型和傳輸運算結果所導致的直接成本;競爭強度β>0表示數據擁有者和任務發布者之間存在競爭關系,數據擁有者參與FL的成本為直接成本和因競爭優勢削弱所導致的間接成本。隨著競爭強度β增大,任務發布者與數據擁有者之間的競爭程度上升,數據擁有者參與FL所削弱的競爭優勢更多,數據擁有者參與FL時所導致的間接成本也相應增加。
由于數據擁有者在競爭環境下參與FL時,因競爭關系導致的間接成本屬于數據擁有者的私人信息,任務發布者無法獲取,所以任務發布者需要在信息不對稱的情況下設計激勵機制。考慮到契約激勵機制是應對信息不對稱情況下激勵問題的一種有效機制,擬設計針對競爭環境的FL契約激勵機制。
2.2 數據擁有者類型
根據文獻[12]可知,數據擁有者參與FL時所提供的數據質量Γ(Γ>0)決定局部模型的迭代次數,即Ω=θ/Γ,其中,Ω為全局模型允許誤差固定時局部模型迭代次數上限,θ(θ>0)表示與數據質量相關的局部模型迭代次數轉換系數。當數據擁有者與任務發布者不存在競爭關系時,數據擁有者參與FL所提供的數據質量Γ僅由真實數據質量h決定,即Ω=θ/h[12, 28];當數據擁有者與任務發布者存在競爭關系時,數據擁有者參與FL時所提供的數據質量Γ,由數據擁有者的真實數據質量h、競爭強度β和競爭敏感度δ共同決定,即
其中:競爭敏感度δ表示數據擁有者對競爭的敏感程度,δ∈[0,h/β)。當δ=0時,表明數據擁有者對競爭不敏感,即無論競爭強度β大小,數據擁有者所提供的數據質量Γ均為真實數據質量h;當δ>0時,表明數據擁有者對競爭敏感,也就是說,當數據擁有者與任務發布者存在競爭關系時,為避免在未來競爭中失去競爭優勢,數據擁有者傾向于不提供真實數據質量h,即所提供的數據質量Γ小于其真實數據質量h,而真實數據質量h與所提供的數據質量Γ之間的差額由競爭強度β和競爭敏感度δ共同決定,競爭強度β越大或競爭敏感度δ越高,兩者差額越大,反之,兩者差額越小。
為便于分析,假設有I種真實數據質量H={hi,1≤i≤I},J種競爭強度B={βj,1≤j≤J},K種競爭敏感度D={δk,1≤k≤K}。將I種真實數據質量按遞增順序排列,即h1<…
數據擁有者ijk參與FL所提供的數據質量Γijk由真實數據質量hi、競爭強度βj和競爭敏感度δk共同決定,即Γijk=(hi-δkβj)。接下來,通過Γijk對不同的數據擁有者類型進行比較。
定義1 類型偏好。對于任意兩個數據擁有者類型ijk和i′j′k′,數據擁有者i′j′k′不優于數據擁有者ijk,即i′j′k′ijk,當且僅當Γi′j′k′≤Γijk,其中i,i′∈{1,2,…,I},j,j′∈{1,2,…,J}和k,k′∈{1,2,…,K}。
將數據擁有者所提供的數據質量按非遞減順序排列:
其中:i∈{1,2,…,I},j∈{1,2,…,J}和k∈{1,2,…,K}。為便于分析,將ijk類型數據擁有者在數據擁有者類型排序中的前一項稱為ijk類型的緊前項,表示為(ijk-1);將ijk類型數據擁有者在數據擁有者類型排序中的后一項稱為ijk類型的緊后項,表示為(ijk+1),不難看出,Γijk-1≤Γijk≤Γijk+1。
2.3 利潤函數
為在競爭環境下激勵數據擁有者參與并實現FL,任務發布者需要為不同類型的數據擁有者設計相應的激勵。契約理論是一種有效的工具,可以幫助任務發布者在分別構造任務發布者和數據擁有者的利潤函數的基礎上,設計合理的激勵。基于此,分別給出任務發布者和數據擁有者的利潤函數,以便于設計合理的激勵。
2.3.1 任務發布者的利潤函數
在FL中,任務發布者的利潤是所有數據擁有者的貢獻與支付給他們的報酬之間的差額。
當全局模型允許誤差γ固定時,數據擁有者參與FL的總時長通常被認為是影響任務發布者收益的主要因素[12]。數據擁有者參與FL的總時長為局部模型訓練時長與局部模型傳輸時長之和。局部模型訓練時長由數據擁有者所提供的數據質量和計算資源共同決定,當數據擁有者提供更多的計算資源或更高質量的數據時,可以更快地完成和實現FL的全局迭代并達到預定義的允許誤差。局部模型傳輸時長主要由數據擁有者的傳輸速率和傳輸模型數據量共同決定。
考慮數據擁有者ijk在局部模型訓練中使用的數據量為zijk(zijk>0),數據擁有者ijk貢獻的計算資源(即CPU周期頻率)表示為fijk,單個數據樣本局部迭代一次的CPU周期數為πijk(πijk>0),所有的數據樣本數據規模(即字節數)相同,則數據擁有者ijk的局部模型迭代一次時長Tcmpijk為(πijkzijk)/fijk。全局模型允許誤差γ固定時,數據擁有者ijk的局部模型訓練迭代次數為θ/Γijk,因此,數據擁有者ijk的局部模型訓練時長為
考慮所有數據擁有者的傳輸模型數據量σ(σ>0)相同,且為一個常數,數據擁有者ijk的傳輸速率為eijk,則數據擁有者ijk的局部模型傳輸時長Tcomijk為
其中:eijk=Bln(1+(αijkdijk)/N0);B(B>0)為傳輸帶寬;αijk(αijk>0)為數據擁有者ijk的傳輸功率;dijk(dijk>0)為數據擁有者ijk與任務發布者之間點對點鏈路的信道增益;N0(N0>0)為背景噪聲[12]。
為了在競爭環境下激勵數據擁有者參與FL,任務發布者需要為各種類型的數據擁有者提供激勵。在競爭環境下參與FL,對于任務發布者來說,FL全局模型能夠帶來競爭優勢,對于數據擁有者來說,FL全局模型僅由與其具有競爭關系的任務發布者持有并使用,可能削弱數據擁有者在未來競爭中的競爭優勢。而現有FL契約激勵機制并沒有為競爭環境下數據擁有者削弱的競爭優勢提供補償,這使得數據擁有者參與FL動力不足。
針對數據擁有者在競爭環境下參與FL動力不足問題,本文提出MM(monetary-the FL model)組合激勵,即(R,Rmod),其中R(R>0)表示數據擁有者獲得的MM組合激勵中的金錢激勵,Rmod(Rmod>0)表示數據擁有者獲得的MM組合激勵中的FL模型使用權激勵。本文中FL模型使用權激勵Rmod是指不同類型數據擁有者完成FL訓練后可獲得不同允許誤差的全局模型使用權,數據擁有者可獲得的全局模型允許誤差越小,模型使用權激勵Rmod越大。競爭環境下數據擁有者參與FL可能削弱競爭優勢,而FL模型使用權激勵Rmod旨在補償數據擁有者因競爭優勢削弱而產生的額外成本。在MM組合激勵的基礎上,提出競爭環境下多維契約Q(H,B,D)={Qijk,1≤i≤I,1≤j≤J,1≤k≤K},由I×J×K種契約項Qijk={(Rijk,Rmodijk),fijk}組成,其中Qijk表示數據擁有者ijk所對應的契約項,Rijk表示數據擁有者ijk所對應的金錢激勵,Rmodijk表示數據擁有者ijk所對應的模型使用權激勵,即數據擁有者ijk可獲得的不同允許誤差全局模型,且
其中:η為FL參與者(任務發布者和數據擁有者)能接受的全局模型最高允許誤差,η>γ。當競爭強度βj為0時,代表數據擁有者與任務發布者之間不存在競爭關系,此時MM組合激勵退化為單一金錢激勵;當競爭強度βj大于0時,在全局模型允許誤差γ固定條件下,不同類型數據擁有者獲得的模型使用權激勵由競爭強度決定,競爭強度βj越大,數據擁有者可獲得的模型使用權激勵Rmodijk越大。
當數據擁有者ijk簽訂契約Qijk時,任務發布者從數據擁有者ijk獲得的利潤WTPijk為:任務發布者從數據擁有者ijk貢獻中獲取的收益UTPijk與提供給數據擁有者ijk的報酬Rijk+λRmodijk之差,即
其中:l(l>0)為MM組合激勵(Rijk,Rmodijk)所對應任務發布者的單位成本;λ(λ≥0)是FL模型使用權激勵的單位收益。由于真實數據質量hi越高,則在局部模型訓練中迭代時間Tijk越短,任務發布者能獲得的利潤WTPijk越高,所以
2.3.2 數據擁有者的利潤函數
在FL中,數據擁有者的利潤是任務發布者提供的報酬與數據擁有者參與FL總成本之間的差額。
數據擁有者ijk簽訂契約Qijk時獲得的報酬為Rijk+λRmodijk。在非競爭環境下,數據擁有者參與FL總成本為局部模型訓練成本和局部模型傳輸成本;在競爭環境下,除局部模型訓練成本和局部模型傳輸成本等直接成本以外,數據擁有者參與FL總成本還包括競爭優勢可能削弱的間接成本。如2.1節所述,競爭強度用于反映數據擁有者和任務發布者之間的競爭關系,隨著競爭強度βj增大,數據擁有者參與FL可能削弱的競爭優勢更多,進而導致數據擁有者參與FL時的間接成本也相應增加。為便于分析,假設數據擁有者ijk在競爭環境下參與FL的間接成本Vcmtijk為
激勵機制設計旨在保證契約可行的條件下,確定最優契約Q(H,B,D)={Qijk,1≤i≤I,1≤j≤J,1≤k≤K},以最大化任務發布者的利潤,接下來,在兩種信息場景下構建激勵機制設計優化模型,解決競爭環境下激勵機制設計問題。
3 競爭環境下的多維契約激勵機制設計
本章考慮在如下兩種信息場景中設計競爭環境下聯邦學習多維契約激勵機制。
a)完全信息場景,假設任務發布者知道每個數據擁有者的類型。
b)不完全信息場景,假設任務發布者只知道數據擁有者的類型分布信息。
接下來,在完全信息場景和不完全信息場景中,分別推導多維契約的可行性以及最優性。
3.1 兩種信息場景下契約設計
為了激勵數據擁有者接受任務發布者所設計的契約且誠實可靠地參與FL,任務發布者所設計的契約需要確保數據擁有者參與FL時獲得的利潤高于其不參與FL時的保留收益,且數據擁有者選擇對應其類型的契約時利潤最高,即可行契約需要滿足個體理性(individual rationality,IR)約束和激勵相容(incentive compatibility,IC)約束。
定義2 個體理性。假定數據擁有者不參與FL的保留收益為0,為保證數據擁有者參與FL,任務發布者設計的契約要滿足數據擁有者ijk(1≤i≤I,1≤j≤J,1≤k≤K)接受契約Qijk時可以獲得非負利潤,即
在完全信息場景下,即任務發布者可以獲知每個數據擁有者類型時,研究競爭環境下聯邦學習多維契約設計問題。在完全信息場景下,任務發布者利用了解的所有數據擁有者類型信息,為數據擁有者ijk僅提供不低于其保留效用的利潤,以實現任務發布者利潤最大化,此時,IC約束恒成立,因此,任務發布者僅需設計滿足IR約束和式(24)的I×J×K項契約{(Rijk,Rmodijk),fijk},則完全信息場景下數據擁有者ijk的相應契約可通過式(27)優化問題得到。
將優化問題式(27)的最優解表示為{RCS*ijk,RmodCS*ijk,fCS*ijk},由該最優解得到完全信息場景下數據擁有者ijk的最優契約。如果參與FL的N個數據擁有者的最優契約滿足式(26),則在激勵預算上限Rmax下,N個數據擁有者的FL可以實施,否則,N個數據擁有者的FL無法實施。
在不完全信息場景下,即任務發布者僅獲知數據擁有者類型分布而無法準確獲知其具體類型時,研究競爭環境下聯邦學習多維契約設計問題。在不完全信息場景下,任務發布者還需要確保每個數據擁有者會選擇與其類型相對應的契約,因此,在不完全信息場景下契約設計問題,除了需要滿足式(23)~(25)外,還需要滿足式(26),考慮競爭環境的聯邦學習多維契約設計問題可以表述為
將優化問題式(28)的最優解表示為{RIS*ijk,RmodIS*ijk,fIS*ijk},i∈{1,2,…,I},j∈{1,2,…,J},k∈{1,2,…,K},由該最優解得到不完全信息場景下適于競爭環境的FL最優契約。
接下來,通過推導可行契約IR約束和IC約束的充分條件,對優化問題式(27)和(28)中的約束條件式(23)和(24)進行化簡轉換完成求解。
3.2 契約可行性
在本節中,通過以下引理推導競爭環境的聯邦學習多維契約可行的充分條件。
引理1 對于任意可行契約項Qijk,有fijk≥fi′j′k′,當且僅當Rijk+λRmodijk≥Ri′j′k′+λRmodi′j′k′,且i,i′∈{1,2,…,I},j,j′∈{1,2,…,J},k,k′∈{1,2,…,K}。
證明 上述引理的證明分為兩部分:第一部分,如果高報酬,則有高貢獻Rijk+λRmodijk≥Ri′j′k′+λRmodi′j′k′fijk≥fi′j′k′;第二部分,如果高貢獻,則有高報酬fijk≥fi′j′k′Rijk+λRmodijk≥Ri′j′k′+λRmodi′j′k′。
引理1表明,當數據擁有者貢獻更高的CPU周期頻率時,任務發布者提供的報酬更高;反之,當任務發布者提供更高的報酬時,數據擁有者需要貢獻的CPU周期頻率也相對更高。
引理2 單調性。對于任意可行契約項Qijk,有fi′j′k′≤fijk,當且僅當(hi′,βj′,δk′)(hi,βj,δk),且i,i′∈{1,2,…,I},j,j′∈{1,2,…,J},k,k′∈{1,2,…,K}。
證明 對于數據擁有者ijk和i′j′k′,有IC約束:
引理2表明,當數據擁有者貢獻更高的CPU周期頻率時,在任務發布者劃分的數據擁有者類型中該數據擁有者類型相對排序更高;反之,在任務發布者劃分的數據擁有者類型中,如果某個數據擁有者類型排序更高,該數據擁有者需要貢獻的CPU周期頻率也相對更高。
引理3 簡化IR約束。如果(h1,β1,δ1)類型數據擁有者所對應的契約Q111滿足IR約束,那么其他類型數據擁有者所對應的契約項必然滿足IR約束。
證明 根據IC約束有
優化問題式(63)的目標函數是關于CPU周期頻率fIS*ijk二階導恒小于0的凹函數,且約束條件均為關于CPU周期頻率fIS*ijk的凸函數,因此,優化問題式(63)是凸優化問題。通過MATLAB凸優化問題工具包CVX求解優化問題式(63),得到不完全信息場景下的最優CPU周期頻率fIS*ijk,在此基礎上,根據式(8)和(62)分別得到不完全信息場景下的最優模型使用權激勵和最優金錢激勵,進而給出不完全信息場景下的最優契約{(RIS*ijk,RmodIS*ijk),fIS*ijk},i∈{1,2,…,I},j∈{1,2,…,J},k∈{1,2,…,K}。具體算法如下。
算法1 不完全信息場景下的最優契約設計
輸入:類型信息(hi,βj,δk);類型概率pijk,i∈{1,2,…,I},j∈{1,2,…,J},k∈{1,2,…,K}。
輸出:最優契約{(RIS*ijk,RmodIS*ijk),fIS*ijk}。
a) 初始化決策變量集{fISijk,1≤i≤I,1≤j≤J,1≤k≤K};
b) 調用CVX求解凸優化問題式(63),得到最優CPU周期頻率fIS*ijk,i∈{1,2,…,I},j∈{1,2,…,J},k∈{1,2,…,K};
c) 根據式(8),得到每種類型相對應的最優模型使用權激勵RmodIS*ijk;
d) 根據式(20)(62),得到(Rijk+λRmodijk)IS*;
e) 根據RmodIS*ijk和(Rijk+λRmodijk)IS*,得到最優金錢激勵RIS*ijk;
f) 由fIS*ijk、RmodIS*ijk、RIS*ijk給出最優契約{(RIS*ijk,RmodIS*ijk),fIS*ijk}。
4 實驗與結果分析
4.1 實驗參數設置
為驗證所提激勵機制在競爭環境下的可行性和有效性,本文考慮了1個任務發布者和N=100個數據擁有者的FL。實驗運行環境為聯想ideapad,酷睿i5-6200U,16 GB RAM,Windows 10,MATLAB 2021a。考慮多維契約中數據擁有者類型服從均勻分布:真實數據質量設置為h∈[180,200],競爭強度設置為β∈[0.5,1],競爭敏感度設置為δ∈[50,55]。除非另有說明,仿真中使用的默認參數參考表1。
4.2 實驗結果分析
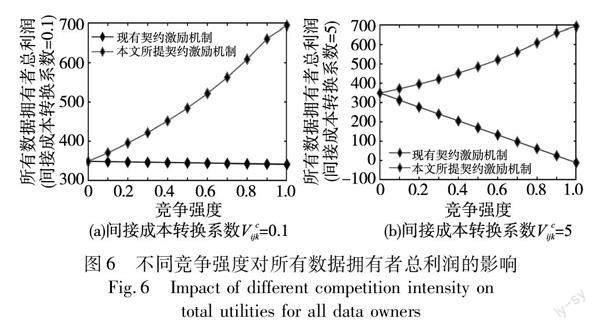
為了驗證本文提出的激勵機制在競爭環境下的可行性,分析比較不同類型數據擁有者的最優MM組合激勵和最優CPU周期頻率。依據三維私有信息:真實數據質量h、競爭強度β和競爭敏感度δ,將數據擁有者初步劃分為8(2×2×2)種類型(hi,βj,δk),i∈{1,2},j∈{1,2},k∈{1,2},數據擁有者屬于某一類型的概率為1/8,其中h1=180 由圖1(a)可知,當數據擁有者類型越高時,數據擁有者獲得的最優MM組合激勵越大;由圖1(b)可知,當數據擁有者類型越高時,數據擁有者需要提供的最優CPU周期頻率越大,這驗證了引理2中當數據擁有者提供更高CPU周期頻率時,數據擁有者類型越高。此外,以上實驗結果表明,最優MM組合激勵和最優CPU周期頻率隨著數據擁有者的類型變化時具有相同的變化趨勢,驗證了引理1中當數據擁有者提供更高的CPU周期頻率時,數據擁有者所獲得的激勵報酬也相應更高。 為驗證不同類型數據擁有者獲得的利潤滿足IR約束和IC約束,分析比較所有類型數據擁有者選擇不同契約項時的利潤,實驗結果見圖2。 由圖2可知,不同類型數據擁有者選擇任務發布者為其設計相應類型的契約項時,其利潤是非負的,因此,本文所設計的激勵機制滿足IR約束。此外,由圖2可知,不同類型數據擁有者只有選擇任務發布者為其設計相應類型的契約項時,才能獲得最大的利潤,因此本文所設計的激勵機制滿足IC約束。 為了探究本文提出的激勵機制對數據擁有者三維私有信息的偏好,分析了真實數據質量、競爭強度以及競爭敏感度變化對最優MM組合激勵和最優CPU周期頻率的影響。將數據擁有者類型總數設置為27(3×3×3)種,并將三維私有信息按照非遞減順序排列:h1 由圖3可知,隨著競爭強度β或競爭敏感度δ上升,數據擁有者獲得的最優MM組合激勵和最優CPU周期頻率均呈下降趨勢;隨著真實數據質量h上升,對應的最優MM組合激勵和最優CPU周期頻率上下限均呈上升趨勢。原因在于擁有更高真實數據質量h的數據擁有者能為任務發布者帶來更高的利潤,反之,對于擁有更高競爭強度β或競爭敏感度δ的數據擁有者導致任務發布者的利潤下降。因此,本文提出的競爭環境下多維契約激勵機制可以在競爭環境中有效激勵更高真實數據質量以及更低競爭強度或競爭敏感度的數據擁有者參與。 為了探究數據擁有者類型總數變化,對任務發布者利潤的影響,分別將數據擁有者真實數據質量類型總數I、競爭強度類型總數J和競爭敏感度類型總數K由1增加到4,得到類型總數變化時的任務發布者利潤,實驗結果見圖4。 由圖4可知,隨著任務發布者設計契約時考慮的數據擁有者私有信息類型總數上升,任務發布者利潤相應增加,原因在于任務發布者設計契約項時考慮的數據擁有者私有信息類型越多,與數據擁有者之間的信息不對稱程度越低,任務發布者提供的激勵報酬總和相應下降,任務發布者利潤則相應增加。 為探究信息對稱與否對任務發布者利潤的影響,將數據擁有者數量N分別設置為100、150和200,分別得到完全信息場景和不完全信息場景下任務發布者利潤,實驗結果見圖5。 由圖5可知,完全信息場景下任務發布者利潤總是高于不完全信息場景,且隨著數據擁有者數量增加,完全信息場景下任務發布者利潤與不完全信息場景下任務發布者利潤之間的差額逐步擴大,原因在于不完全信息場景下,任務發布者僅掌握數據擁有者類型分布信息,而完全信息場景下任務發布者掌握數據擁有者的類型信息,因此,不同于不完全信息場景,完全信息場景下任務發布者可為各類型數據擁有者提供零利潤契約,從而實現任務發布者利潤最大化。 最后,分析比較所提多維契約激勵機制與現有契約激勵機制[12]在競爭環境下實行時,不同競爭強度對所有數據擁有者總利潤的影響。將數據擁有者類型總數設置為3(3×1×1)種,其中,真實數據質量分為3種:h1=180 由圖6可知,當競爭強度為0時,應用本文所提多維契約激勵機制與應用現有契約激勵機制[12],所有數據擁有者獲得的總利潤相同,這意味著當競爭強度為0時,本文所提多維契約激勵機制退化為現有契約激勵機制,即其是現有契約激勵機制的一種拓廣。隨著競爭強度增加,應用本文所提多維契約激勵機制,所有數據擁有者獲得的總利潤上升,而應用現有契約激勵機制,所有數據擁有者獲得的總利潤降低。此外,隨著間接成本轉換系數上升,應用現有契約激勵機制,所有數據擁有者總利潤快速下降甚至為負,原因在于本文所提多維契約激勵機制中模型使用權激勵隨著競爭強度增加而增加,使得數據擁有者收益增加,有效彌補了數據擁有者在競爭環境下參與FL導致的間接成本,所有數據擁有者總利潤得以保證,而現有契約激勵機制并未考慮這部分間接成本,使得所有數據擁有者總利潤降低甚至為負。綜上所述,與現有契約激勵機制相比,本文提出的多維契約激勵機制考慮到了競爭關系對數據擁有者參與FL成本的影響,有效提高了數據擁有者的參與意愿,為競爭環境下FL的落地實施提供有效助力。 5 結束語 本文考慮了競爭環境下數據擁有者的真實數據質量、競爭敏感度和競爭強度三維私有信息,并創新性地設計了金錢與FL模型使用權組合的MM組合激勵,提出了一個適于競爭環境FL的多維契約激勵機制,解決了競爭環境下的FL數據擁有者參與動力不足問題。實驗結果表明,競爭環境下多維契約激勵機制更準確地考慮了競爭環境下數據擁有者參與FL的成本,能顯著提高數據擁有者在競爭環境下的參與意愿,有助于FL在競爭環境的落地實施。 在競爭環境下FL實施過程中,除了任務發布者與數據擁有者之間存在競爭關系外,任務發布者之間或數據擁有者之間也可能存在競爭關系,對FL激勵機制的設計造成不同程度的影響,在今后的工作中,將進一步研究考慮不同競爭關系的FL激勵機制。 參考文獻: [1]李萬利,潘文東,袁凱彬.企業數字化轉型與中國實體經濟發展[J].數量經濟技術經濟研究,2022,39(9):5-25.(Li Wanli, Pan Wendong, Yuan Kaibin. Enterprise digital transformation and the development of Chinas real economy[J].Journal of Quantitative & Technological Economics,2022,39(9):5-25.) [2]孫璐,黃婕.信息交互能力對企業競爭優勢的影響研究[J].商業經濟研究,2022(16):135-141.(Sun Lu, Huang Jie. Research on the impact of information interaction capacity on firm competitive advantage[J].Journal of Commercial economics,2022(16):135-141.) [3]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of the 20th International Conference on Artificial Intelligence and Statistics.New York:PMLR Press,2017:1273-1282. [4]Saputra Y M, Nguyen D, Dinh H T, et al. Federated learning meets contract theory:economic-efficiency framework for electric vehicle networks[J].IEEE Trans on Mobile Computing,2020,21(8):2803-2817. [5]Sun Peng, Che Haoxuan, Wang Zhibo, et al. Pain-FL:personalized privacy-preserving incentive for federated learning[J].IEEE Journal on Selected Areas in Communications,2021,39(12):3805-3820. [6]王鑫,李美慶,王黎明,等.一種基于合同理論的可激勵聯邦學習模型[J].電子與信息學報,2023,45(3):874-883.(Wang Xin, Li Meiqing, Wang Liming, et al. An incentivized federated learning model based on contract theory[J].Journal of Electronics & Information Technology,2023,45(3):874-883.) [7]Yu Han, Liu Zelei, Liu Yang, et al. A fairness-aware incentive scheme for federated learning[C]//Proc of AAAI/ACM Conference on AI, Ethics, and Society.New York:ACM Press,2020:393-399. [8]Wu Maoqiang, Ye Dongdong, Ding Jiahao, et al. Incentivizing diffe-rentially private federated learning: a multidimensional contract app-roach[J].IEEE Internet of Things Journal,2021,8(13):10639-10651. [9]Ding Ningning, Fang Zhixuan, Huang Jianwei. Optimal contract design for efficient federated learning with multi-dimensional private information[J].IEEE Journal on Selected Areas in Communications,2020,39(1):186-200. [10]Lim W Y B, Xiong Zehui, Kang Jiawen, et al. When information freshness meets service latency in federated learning:a task-aware incentive scheme for smart industries[J].IEEE Trans on Industrial Informatics,2022,18(1):457-466. [11]陳喬松,許文杰,何小陽,等.FedSharing:一種雙區塊鏈激勵驅動的數據分享聯邦學習框架[J].計算機應用研究,2023,40(1):33-41.(Chen Qiaosong, Xu Wenjie, He Xiaoyang, et al. FedSharing: federated learning framework for data sharing driven by dual blockchain incentives[J].Application Research of Computers,2023,40(1):33-41.) [12]Kang Jiawen, Xiong Zehui, Niyato D, et al. Incentive mechanism for reliable federated learning: a joint optimization approach to combining reputation and contract theory[J].IEEE Internet of Things Journal,2019,6(6):10700-10714. [13]Wang Yuntao, Su Zhou, Luan T H, et al. Federated learning with fair incentives and robust aggregation for UAV-aided crowdsensing[J].IEEE Trans on Network Science and Engineering,2021,9(5):3179-3196. [14]Mai Tianle, Yao Haipeng, Xu Jiaqi, et al. Automatic double-auction mechanism for federated learning service market in Internet of Things[J].IEEE Trans on Network Science and Engineering,2022,9(5):3123-3135. [15]Dayan I, Roth H R, Zhong Aoxiao, et al. Federated learning for predicting clinical outcomes in patients with COVID-19[J].Nature Medicine,2021,27(10):1735-1743. [16]Bercea C, Wiestler B, Rueckert D, et al. Federated disentangled representation learning for unsupervised brain anomaly detection[J].Nature Machine Intelligence,2022,4(8):685-695. [17]Wu Chuhan, Wu Fangzhao, Lyu Lingjuan, et al. Communication-efficient federated learning via knowledge distillation[J].Nature Communications,2022,13(1):article ID 2032. [18]Yuan Yulan, Jiao Lei, Zhu Konglin, et al. Incentivizing federated learning under long-term energy constraint via online randomized auctions[J].IEEE Trans on Wireless Communications,2022,21(7):5129-5144. [19]Le T H T, Tran N H, Tun Y K, et al. An incentive mechanism for federated learning in wireless cellular networks: an auction approach[J].IEEE Trans on Wireless Communications,2021,20(8):4874-4887. [20]Sun Wen, Xu Ning, Wang Lu, et al. Dynamic digital twin and fede-rated learning with incentives for air-ground networks[J].IEEE Trans on Network Science and Engineering,2022,9(1):321-333. [21]Lin Xi, Wu Jun, Li Jianhua, et al. Friend-as-learner:socially-driven trustworthy and efficient wireless federated edge learning[J].IEEE Trans on Mobile Computing,2023,22(1):269-283. [22]顧永跟,鐘浩天,吳小紅,等.不平衡數據下預算限制的聯邦學習激勵機制[J].計算機應用研究,2022,39(11):3385-3389.(Gu Yonggen, Zhong Haotian, Wu Xiaohong, et al. Incentive mechanism for federated learning with budget constraints under unbalanced data[J].Application Research of Computers,2022,39(11):3385-3389.) [23]Lin Wenting, Chen Guo, Huang Yuhan. Incentive edge-based fede-rated learning for false data injection attack detection on power grid state estimation: a novel mechanism design approach[J].Applied Energy,2022,314:118828. [24]Wang Zhilin, Hu Qin, Li Ruinian, et al. Incentive mechanism design for joint resource allocation in blockchain-based federated lear-ning[J].IEEE Trans on Parallel and Distributed Systems,2023,34(5):1536-1547. [25]Wang Quyuan, Guo Songtao, Liu Guiyan, et al. MotiLearn: contract-based incentive mechanism for heterogeneous edge collaborative training[J].IEEE Trans on Network Science and Engineering,2022,9(4):2895-2909. [26]Wang Xiaofei, Zhao Yunfeng, Qiu Chao, et al. InFEDge:a blockchain-based incentive mechanism in hierarchical federated learning for end-edge-cloud communications[J].IEEE Journal on Selected Areas in Communications,2022,40(12):3325-3342. [27]Li Ying, Wang Xingwei, Zeng Rongfei, et al. VARF: an incentive mechanism of cross-silo federated learning in MEC[J].IEEE Internet of Things Journal,2023,10(17):15115-15132. [28]Tran N H, Bao Wei, Zomaya A, et al. Federated learning over wireless networks: optimization model design and analysis[C]//Proc of IEEE Conference on Computer Communications.Piscataway,NJ:IEEE Press,2019:1387-1395. 收稿日期:2023-02-11;修回日期:2023-04-27 基金項目:河北省高等學校人文社會科學研究項目(SQ2022085);河北省自然科學基金面上項目(A2020402013) 作者簡介:楊揚(1986-),女(通信作者),河北滿城人,副教授,碩導,博士,主要研究方向為機器學習和智能管理(yangyang2015@hebeu.edu.cn);殷紅建(1996-),男,重慶人,碩士研究生,主要研究方向為智能管理;王超(1983-),男,河北徐水人,教授,碩導,博士,主要研究方向為機器學習.
猜你喜歡
大眾投資指南(2021年23期)2021-12-06 05:47:10甘肅教育(2020年14期)2020-09-11 07:57:26現代經濟信息(2020年34期)2020-06-08 06:02:12少先隊活動(2018年10期)2018-12-29 12:51:34環境保護與循環經濟(2017年2期)2017-09-26 11:52:13中國公路(2017年11期)2017-07-31 17:56:31唐山文學(2016年2期)2017-01-15 14:04:09中國商論(2016年33期)2016-03-01 01:59:29現代企業(2015年8期)2015-02-28 18:54:57現代企業(2015年4期)2015-02-28 18:48:02
