基于群稀疏空間光譜總變分的高光譜混合噪聲圖像恢復
2023-10-24 01:43:16徐光憲王澤民
激光與紅外 2023年9期
關鍵詞:模型
徐光憲,王澤民,馬 飛
(遼寧工程技術大學電子與信息工程學院,遼寧 葫蘆島 125100)
1 引 言
隨著高光譜成像傳感器的不斷發展,高光譜圖像(HSI)提供了豐富的光譜信息,在分類[1-2]、超分辨率[3]和解混[4]等方面發揮著重要作用。由于高光譜傳感器在采集數據時容易受到外界環境的影響,數據不可避免地會受到高斯噪聲、脈沖噪聲、死線和條帶等各種混合噪聲污染,從而降低了HSI的質量,限制了其后續的應用。因此,從已被噪聲污染的HSI中恢復干凈的HSI是很重要的。
近年來,魯棒主成分分析框架(RPCA)[5]已被廣泛應用于混合噪聲的去除。通常,假設HSI沿光譜維數[4]具有低秩性質。同時,死線、條紋和脈沖噪聲具有稀疏特性[6]。基于這些假設,Zhang等人的[6]首先提出了經典的低秩矩陣恢復(LRMR),用于HSI混合噪聲的去除。此外,還采用低秩矩陣分解的方法進行了HSI混合噪聲去除[7],以避免了奇異值分解的計算,提高了效率。由于基于低秩矩陣的方法需要將原始的三維HSI重塑為二維矩陣,會忽略了HSI的空間相關性。因此,許多算法引入基于低秩張量的方法來描述HSI的低秩特性。包括Tucker分解[8];和張量奇異值分解(t-SVD)[9]。然而,如文獻[10]所示,低秩正則化并不足以描述HSI的先驗空間信息。
總變分正則化是圖像處理中保持局部空間分段平滑性常用的工具,因此,許多人提出了基于低秩張量分解框架的各種類型的總變分正則化模型,以同時探索HSI的空間和光譜先驗。例如,在文獻[11]中,將低Tucker秩模型和3DTV正則化項組合(LRTDTV)分別利用全局空間譜和光譜相關性,增強空間信息;如范等[12]將SSTV正則化加到低秩張量分解框架中(SSTVLRTF),使用張量核范數(TNN)近似HSI的低秩屬性并同時利用空間和譜域之間的分段光滑性(SSTV正則項)來完成HSI去噪。然而,Tucker分解的不平衡矩陣化方法難以表征全局相關性[13];T-SVD框架在描述所有HSI模式的不同相關性方面缺乏靈活性,導致恢復性能次優。因此,Zheng等[14]將T-SVD推廣到模kT-SVD,提出了纖維秩,并引入了凸代理(3DTNN)和非凸代理(3DLogTNN)來近似張量纖維秩。而在文獻[15]中,Liu等直接約束解的張量纖維秩,并證明直接約束纖維秩與凸代理和非凸代理近似形式相比,更接近干凈HSI的纖維秩。
因此,提出的FRTCSSTV算法也采用直接對張量纖維秩進行約束的方法來表示HSI的全局低秩,并同時利用群稀疏空間光譜總變分正則化,來增強空間信息。通常SSTV正則項采用L1范數范數對空間差分圖像的稀疏先驗進行正則化,但這些方法不能利用差分圖像的共享行稀疏結構[16]。因此,提出的算法使用群稀疏正則化,用L2,1范數表示,來探索一個差異圖像在兩個空間維度上的共享稀疏模式,這與之前的SSTV正則化[12]完全不同。并將其嵌入到對應的低秩模型中,到達去除含有條帶和死線的混合噪聲。
將基于張量低纖維秩約束模型和群稀疏空間光譜總變分正則項結合在一起,對含有混合噪聲的去除有很好的效果。具體來說,我們有以下兩點貢獻。
(1)直接采用張量低纖維秩約束模型并不能很好的去除含有條帶和死線的混合噪聲,因此,將其與群稀疏空間光譜總變分正則項進行了結合,增強了HSI局部空間信息和光譜維度的分段平滑性,來去除圖像中含有的條帶和死線噪聲。
(2)為了求解該模型,我們采用了ADMM(交替方向乘子法)算法來獲得全局最優解,實驗結果表明,該算法易于收斂。并與其他模型相比,本文的模型能夠取得更好的性能。
2 相關工作
HSI退化模型:被混合噪聲污染的HSI數據用Y∈RM*N*p表示,其中M*N為空間域;p為譜帶數。它們可以被建模為:
Y=X+S+N
(1)
其中,X∈RM*N*p為干凈的高光譜數據;S∈RM*N*p和N∈RM*N*p分別為稀疏噪聲和高斯噪聲。
2.1 張量纖維秩
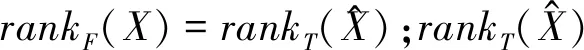
(2)
2.2 SSTV正則項
高光譜圖像X的SSTV范數可以表示為[17]:
(3)
其中,Dh是水平方向上的差分算子,Dv是垂直方向上的差分算子,D是在每個像素的光譜特征上的一維有限差分算子。
而L1范數并不能反映HSI的群稀疏這一特征。L1范數只是要求所有元素的絕對值的和是最小的,沒有對內部結構特性的進一步稀疏性要求。L2,1范數結合了L1范數和L2范數的優點,可以很好地描述HSI群稀疏的特征。一方面,L2,1范數可以保證梯度張量的光譜維數的每個管都是稀疏的。另一方面,也可以保證空間維數的稀疏性[18]。因此采用L2,1范數代替SSTV中的L1范數,新的SSTV可以寫成:
(4)
2.3 FRTCSSTV模型
直接對張量纖維秩進行約束可以表征HSI全局的低秩性,而SSTV是一種研究相鄰像素與相鄰光譜波段相關性的局部模型。我們受到文獻[12]啟發,結合這兩個互補的模型來恢復高光譜數據。綜上所述,提出以下FRTCSSTV模型:
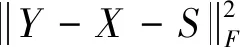
(5)
其中,λ,τ是一個調優參數;r是X的纖維秩的上界。
3 優化FRTCSSTV模型
通過ADMM算法引入輔助變量F,式(5)可以重寫為:
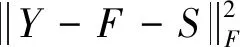
(6)
模型(6)的求解,可使以下的增廣拉格朗日函數最小化:
s.t.rank(F)≤r
(7)
更新Fk+1:
(8)
由文獻[15]中算法2可知,最優的張量纖維秩近似可由一個截斷的T-SVD得到顯式解,具體求解算法可參考文獻[15]中算法2。
Fk+1=RT-SVD(Q,r,p1)
(9)
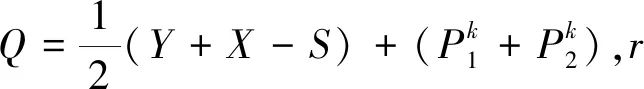
更新Xk+1:
(10)
式(10)可由ADMM算法求解,將上式改寫為:
s.t.A=DhXD,β=DVXD
(11)
問題式(11)可分為以下3個子問題:
(12)
(13)
(14)
問題(12)、(13)可通過軟收縮算子shrink(,)來解決。
(15)
(16)
在(14)中定義的子問題可以用一個迭代的最小二乘求解器來求解,如最小二乘QR分解方法[17,19]。
更新Sk+1:
(17)
更新拉格朗日乘子
(18)
綜上所述,FRTCSSTV模型具體優化求解的步驟如算法1所示。
算法1:FRTCSSTV模型優化
輸入:含噪聲HSIY
輸出:X,S
初始化X=S=F=P1=P2=P3=P4=0,
τ,λ,β,P,收斂條件ε
令k=k+1,迭代以下步驟
(1)通過(9)更新Fk+1
(2)通過(14)更新Xk+1
(3)通過(17)更新Sk+1
4 實驗結果與分析
為了證明所提出模型的優勢,分別對模擬和真實的HSI數據集進行了實驗。實驗中采取了3DTNN[14],3DLogTNN[14],FRCTR-PnP[15],3種模型來進行對比。為了方便數值計算和數據可視化,在恢復前,我們將HSI各波段的灰度值歸一化。
4.1 模擬實驗
模擬實驗中,采用由反射光學系統成像光譜儀(rose-03)收集的Pavia城市中心數據集。Pavia城市中心數據集的一些光譜波段被噪聲污染嚴重,不能作為去噪的參考。因此,去掉該數據的前幾個波段,選取子圖像的大小為200×200×80。由于模擬實驗給出了地面真實度的HSI,采用了3個定量圖像指標進行比較,包括各個波段平均峰值信噪比(MPSNR)、平均結構相似度(MSSIM)和光譜角度映射(SAM)。MPSNR越大,MSSIM和SAM越小,表示模型的去噪性能越好。
Case1:為了更接近真實場景下不同頻段的噪聲強度是不同的。我們對HSI每個波段加入不同強度的高斯噪聲,高斯噪聲的方差在[0,0.2]之間選取。在此基礎上,在所有波段加入脈沖噪聲。不同波段的脈沖噪聲強度不同,其百分比從[0,0.2]選取。 然后在數據集的第44~54波段添加條帶噪聲。條帶噪聲的數量在20~40之間隨機變化。
Case2:在Case1的基礎上,在Pavia City Center數據集的38~48區也增加了死線。上述區域的死線數量在[3,10]之間隨機變化,死線寬度在[1,3]之間隨機變化。
(1)定量比較:在表1,表2中我們將性能最優值都加粗顯示,可以看出,在這兩種噪聲場景下,該FRTCSSTV模型與其他3種模型相比具有更好的去噪性能;當模擬實驗中加入高斯噪聲、脈沖噪聲和條帶和死線噪聲后,由于模型中的群稀疏空間光譜總變分可以更好的表示HSI的空間維度的稀疏性,圖像中的條帶噪聲會被抑制;并且直接對張量纖維秩進行約束可以更好的保持HSI原有結構;所以該模型在去除混合噪聲后各項指標都取得最優值。在表2中,MPSNR比FRCTR-PnP模型提升了1.4 dB左右;同時也保持了HSI原有的結構,MSSIM值也比其他方法更高;與其他3種模型相比SAM值也到達最低。為了更好顯示實驗結果,如圖1所示,將Case2種每個波段的PSNR和SSIM值進行比較。從圖中可以觀察到,該模型在每個波段都能取得很好的PSNR和SSIM值;在噪聲密集的地方,也能夠穩定去除噪聲,而其他3種模型都有很大的波動,對噪聲的去除不是很理想。這證明了提出的模型去除這類混合噪聲的優勢。
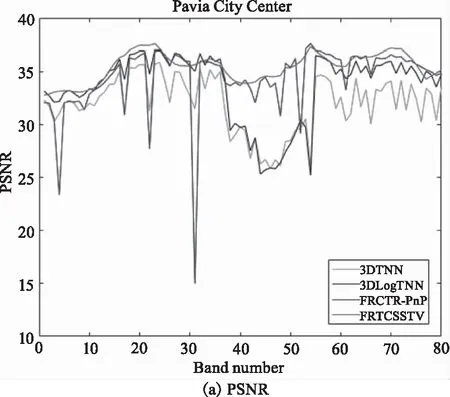
圖1 Case2中不同波段的PSNR值和SSIM值
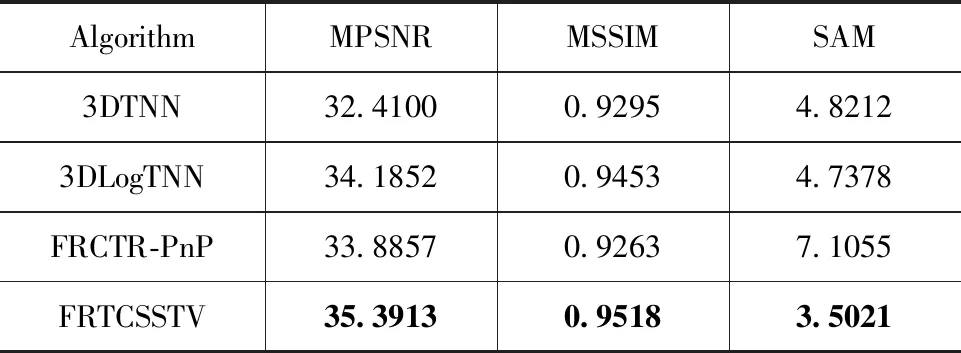
表1 Case1中定量數值評價結果

表2 Case2中定量數值評價結果
(2)視覺質量比較:由于該數據集具有很多波段,從中選取一個同時含有4種混合噪聲的波段進行比較。如圖2中第46波段所示,從圖2(b)中不難看出,圖像已經被混合噪聲完全覆蓋,觀察不到圖像的特征;通過不同的去噪方法后,噪聲都被不同程度的去除。

圖2 Case2中第46波段去噪效果對比
然而由圖2(c)和2(d)可知,3DTNN和3DLogTNN方法去噪后圖像仍會殘留大量的條帶和死線噪聲。在圖2(e)中,FRCTR-PnP方法去除了大部分混合噪聲,但還有少量的條帶噪聲會影響視覺效果。在圖2(f)中,由于群稀疏空間光譜總變分增強了空間的稀疏性,可以更好的去除條帶和死線這類稀疏噪聲,因此,去除噪聲后的圖像的視覺質量與原圖像也最為相似,這也說明了該FRTCSSTV模型去除含有條帶和死線的混合噪聲的優勢。
4.2 真實HSI數據實驗
由于該模型對含有高斯噪聲、脈沖噪聲、條帶和死線噪聲4種混合噪聲的去除具有很好的效果,因此,實驗中我們采用了具有類似真實噪聲的HSI數據集HYDICE Urban進行性能評估。與模擬實驗一樣,在測試恢復實驗之前,將每個圖像波段的灰度值歸一化。不過在圖4(b)、(c)、(d)中,仍然能看到一些條帶噪聲沒能被去除,這說明了3DTNN、3DLogTNN和FRCTR-PnP這3種模型對去除條帶和死線這類稀疏噪聲具有局限性。然而,我們提出的FRTCSSTV模型不僅保持了HSI原有的結構,同時還增強了HSI的空間譜信息和光譜的分段平滑性,可以很好的去除這類噪聲,并同時能保留原圖像大部分的細節特征,這一現象表現出該模型對含有條帶的混合噪聲去除的優勢。圖3給出了4種不同方法對HYDICE Urban數據集第109波段的恢復結果。從圖3(a)中可以觀察到,采集到的圖像已經被混合噪聲污染,很難收集到有用的圖像特征。如圖3所示,經過各種方法去噪后,大部分噪聲被去除,可以得到圖像的一些特征信息。

圖3 第109波段恢復圖像比較
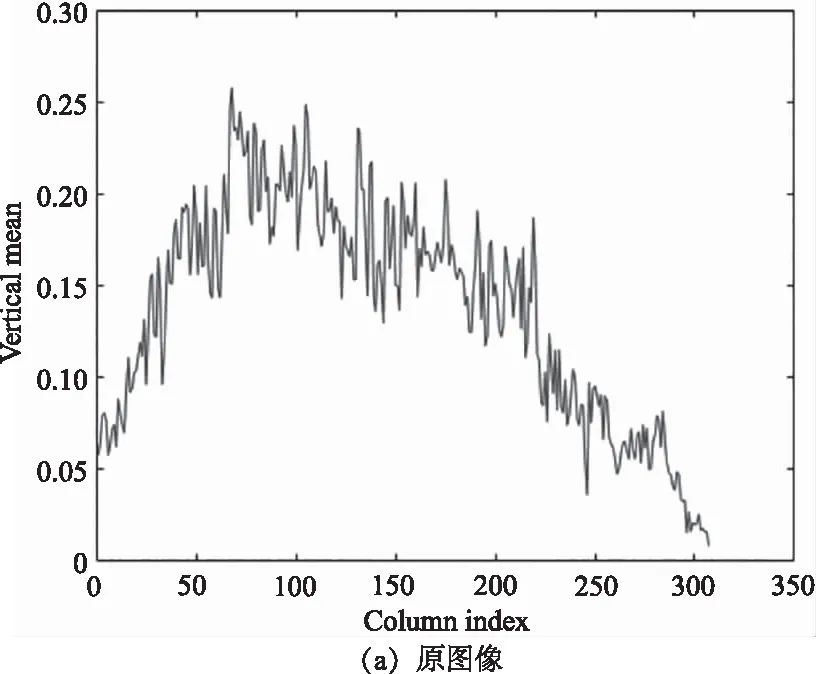
圖4 第109波段垂直平均剖面比較
為了更好地顯示該模型的去噪性能,如圖4所示,我們將109波段去噪后圖像的垂直平均剖面進行了比較。當平均輪廓曲線顯著波動時,表明存在噪聲。如圖(a)所示,該圖像含有大量噪聲,經過去噪后,如圖(b)、(c)所示,大部分噪聲能夠被抑制,但仍含有噪聲未被去除。從圖(c)中可以看到,雖然噪聲被去除,但圖像的輪廓曲線會過于平滑。如圖(e)所示,提出的FRTCSSTV模型在去除混合噪聲的同時,群稀疏空間光譜總變分正則項能夠保留圖像的細節特征,使輪廓曲線不會過于平滑,相比之下,得到了更好的結果。
5 結 論
提出的基于群稀疏空間光譜全變分正則化的高光譜混合噪聲圖像恢復的模型在去除含有條帶和死線這類混合噪聲的高光譜圖像時具有很好的性能。該模型在模擬和真實數據的實驗中,在去噪后的可以保留圖像原有的結構特征和更多的細節特征,對條帶等稀疏噪聲有很好的抑制作用,在去除含有條帶和死線的混合噪聲方面與其他3種模型相比的更具優勢。未來,也可以通過即插即用框架嵌入一些先進深度學習方面的去噪器[20-21],來提高去噪的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
