基于XGBoost 的煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測方法
2023-10-24 07:35:46周樹平
裝備制造技術(shù) 2023年8期
周樹平
(蘭州煤礦設(shè)計研究院有限公司,甘肅 蘭州 730000)
0 引言
在對機(jī)器學(xué)習(xí)模型進(jìn)行優(yōu)化之前需要先對其參數(shù)進(jìn)行確定。目前,國內(nèi)外學(xué)者針對不同類型的機(jī)器學(xué)習(xí)算法都有相應(yīng)的研究成果,但是這些研究大多是通過建立一個通用的模型來實現(xiàn)預(yù)測功能,并未考慮到具體的應(yīng)用場景。因此本文提出了一種新的機(jī)器學(xué)習(xí)模型(Next-classifier),該模型可以根據(jù)歷史數(shù)據(jù)和當(dāng)前數(shù)據(jù)自動地調(diào)整模型參數(shù),從而使得模型具有較強(qiáng)的泛化能力。 傳統(tǒng)機(jī)器學(xué)習(xí)算法中存在大量不適合于特定領(lǐng)域使用的特征,如SVM 等;此外,由于每個測試集都會包含多個訓(xùn)練樣本以及少量測試樣本,導(dǎo)致訓(xùn)練樣本數(shù)目過多而無法滿足實際應(yīng)用需求。為了解決上述問題,采用了一種改進(jìn)的粒子群算法作為分類器,以便能夠有效降低訓(xùn)練樣本的規(guī)模,提高模型性能。
1 煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測系統(tǒng)設(shè)計
1.1 系統(tǒng)總體結(jié)構(gòu)設(shè)計
煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測系統(tǒng)的設(shè)計主要分成硬件部分和軟件部分。其中,硬件部分包括傳感器、數(shù)據(jù)采集設(shè)備和通信設(shè)備;軟件部分包括數(shù)據(jù)處理與分析軟件和監(jiān)測系統(tǒng)界面。
傳感器:用于采集機(jī)械設(shè)備的各種參數(shù),如振動、溫度、壓力、電流等。常用的傳感器有振動傳感器、溫度傳感器、壓力傳感器、電流傳感器等。
數(shù)據(jù)采集設(shè)備:如圖1,用于將傳感器采集到的數(shù)據(jù)進(jìn)行采集和處理,將其轉(zhuǎn)化為數(shù)字信號,并進(jìn)行存儲和傳輸。常用的數(shù)據(jù)采集設(shè)備有數(shù)據(jù)采集卡、數(shù)據(jù)采集模塊等。
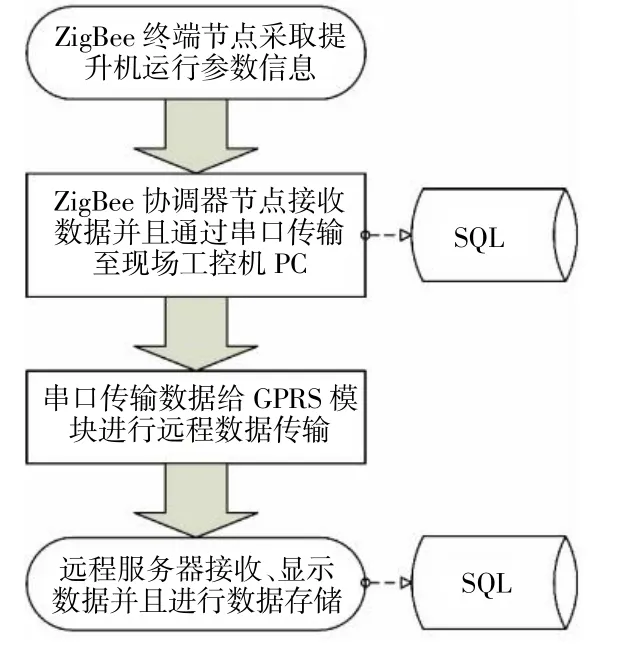
圖1 礦井提升設(shè)備狀態(tài)監(jiān)測系統(tǒng)功能設(shè)計流程
通信設(shè)備:用于將采集到的數(shù)據(jù)傳輸?shù)奖O(jiān)測系統(tǒng)中進(jìn)行處理和分析。常用的通信設(shè)備有以太網(wǎng)、無線通信模塊等。
數(shù)據(jù)處理與分析軟件:用于對采集到的數(shù)據(jù)進(jìn)行處理和分析,提取有用的信息,并進(jìn)行故障診斷和預(yù)測。常用的數(shù)據(jù)處理與分析軟件有MATLAB、Lab-VIEW 等。
監(jiān)測系統(tǒng)界面:用于顯示監(jiān)測到的機(jī)械設(shè)備狀態(tài)信息,提供實時監(jiān)測和報警功能。常用的監(jiān)測系統(tǒng)界面有人機(jī)界面、Web 界面等。
以上是煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測系統(tǒng)設(shè)計的主要部分,通過這些部分的協(xié)同工作,可以實現(xiàn)對機(jī)械設(shè)備狀態(tài)的實時監(jiān)測和預(yù)測,提高煤礦生產(chǎn)的安全性和效率。系統(tǒng)總體結(jié)構(gòu)設(shè)計主要分為硬件部分設(shè)計、軟件系統(tǒng)設(shè)計、數(shù)據(jù)庫管理子系統(tǒng)設(shè)計、信息查詢模塊以及數(shù)據(jù)分析及顯示設(shè)計等部分,各部分功能如下文所介紹。
1.2 硬件平臺搭建
如圖2 所示,煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測系統(tǒng)的硬件平臺搭建主要包括傳感器的選擇和安裝、數(shù)據(jù)采集設(shè)備的選擇和配置、通信設(shè)備的選擇和配置。

圖2 硬件平臺
(1)傳感器選擇和安裝:根據(jù)監(jiān)測需求,選擇適合的傳感器,如振動傳感器、溫度傳感器、壓力傳感器、電流傳感器等。傳感器的選擇要考慮其測量范圍、精度、穩(wěn)定性等因素。安裝傳感器時要注意選擇合適的位置和固定方式,確保傳感器能夠準(zhǔn)確地采集到機(jī)械設(shè)備的狀態(tài)參數(shù)。
(2)數(shù)據(jù)采集設(shè)備選擇和配置:根據(jù)傳感器的類型和數(shù)量,選擇合適的數(shù)據(jù)采集設(shè)備,如數(shù)據(jù)采集卡、數(shù)據(jù)采集模塊等。數(shù)據(jù)采集設(shè)備的選擇要考慮其采樣率、分辨率、接口類型等因素。配置數(shù)據(jù)采集設(shè)備時要根據(jù)傳感器的接口類型進(jìn)行連接和設(shè)置,確保數(shù)據(jù)能夠準(zhǔn)確地采集和傳輸。
(3)通信設(shè)備選擇和配置:根據(jù)監(jiān)測系統(tǒng)的要求,選擇合適的通信設(shè)備,如以太網(wǎng)、無線通信模塊等。通信設(shè)備的選擇要考慮其傳輸速率、傳輸距離、穩(wěn)定性等因素。配置通信設(shè)備時要根據(jù)監(jiān)測系統(tǒng)的通信協(xié)議進(jìn)行設(shè)置,確保數(shù)據(jù)能夠穩(wěn)定地傳輸?shù)奖O(jiān)測系統(tǒng)中。
在搭建硬件平臺時,還需要考慮供電和防護(hù)措施。傳感器、數(shù)據(jù)采集設(shè)備和通信設(shè)備都需要穩(wěn)定的供電,可以選擇適合的電源和電纜進(jìn)行供電。此外,還需要考慮防護(hù)措施,如防水、防塵、防爆等,以確保硬件設(shè)備在惡劣的煤礦環(huán)境中能夠正常工作。
1.3 軟件系統(tǒng)開發(fā)
在本系統(tǒng)中,主要使用C#語言進(jìn)行編程,具體而言,主要涉及的內(nèi)容:通訊協(xié)議的設(shè)計、數(shù)據(jù)庫的構(gòu)建、界面的創(chuàng)建以及數(shù)據(jù)的讀寫操作。
1.4 系統(tǒng)測試
對采集到的數(shù)據(jù)進(jìn)行分析處理后,可以得到設(shè)備在不同工況下的健康狀況。通過對數(shù)據(jù)進(jìn)行分析、計算和預(yù)測等步驟,可為維修人員提供有價值的信息,并且根據(jù)這些結(jié)果來制定合理的維修計劃。利用該模型還能夠?qū)崿F(xiàn)對設(shè)備運(yùn)行過程的監(jiān)控與管理,從而提高了設(shè)備運(yùn)行效率。以某煤礦機(jī)電設(shè)備為研究對象,采用XGBoost 算法構(gòu)建了煤礦機(jī)電設(shè)備狀態(tài)檢測預(yù)警系統(tǒng),其具體步驟如下所述。
(1)建立訓(xùn)練集:將XGBoost 算法應(yīng)用于煤礦機(jī)械故障分類問題時,需要確定合適的初始參數(shù)值。通常情況下,XGBoost 算法會以一定概率隨機(jī)選擇一個初始參數(shù)值作為初始化參數(shù),然后按照這個參數(shù)進(jìn)行訓(xùn)練,直到獲得最優(yōu)的分類效果。因此,本次實驗中選用的初始參數(shù)是XGrids_training_collection.XGBoost.samples.length=100。
(2)劃分訓(xùn)練集并計算各類樣本數(shù)量、每種故障類型對應(yīng)的特征數(shù)和平均準(zhǔn)確率等信息,以便得到最終的分類結(jié)果。在此基礎(chǔ)上,對模型進(jìn)行驗證與調(diào)整。為了避免出現(xiàn)過擬合現(xiàn)象,應(yīng)當(dāng)根據(jù)實際運(yùn)行環(huán)境以及數(shù)據(jù)分布特點(diǎn)合理設(shè)置模型參數(shù),使得預(yù)測結(jié)果更加貼近真實情況,從而提高模型泛化性能。
2 基于XGBoost 的煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測方法
2.1 XGBoost 算法簡介
XGBoost 是一種基于梯度提升決策樹的機(jī)器學(xué)習(xí)算法,具有高效、準(zhǔn)確的特點(diǎn)。它通過迭代的方式不斷優(yōu)化模型,能夠處理大規(guī)模數(shù)據(jù)集和高維特征。相比傳統(tǒng)的決策樹算法,XGBoost 算法具有更好的泛化能力,且不需要手動指定特征的重要性級。
2.2 XGBoost 算法流程
XGBoost 算法的流程包括數(shù)據(jù)準(zhǔn)備、模型訓(xùn)練和模型預(yù)測3 個步驟[1,2]。首先,需要對監(jiān)測數(shù)據(jù)進(jìn)行預(yù)處理,包括數(shù)據(jù)清洗、特征提取等。然后,使用訓(xùn)練數(shù)據(jù)集進(jìn)行模型訓(xùn)練,通過優(yōu)化損失函數(shù)來提高模型的準(zhǔn)確性。最后,使用訓(xùn)練好的模型對新的數(shù)據(jù)進(jìn)行預(yù)測。
2.3 監(jiān)測模型建立
XGBoost 的迭代模型有兩種,一種是線性模型,另一種是基于樹的模型,因為基于樹的模型性能遠(yuǎn)好于線性模型,這里僅討論基于樹的模型。使用基于Python 語言的“XGBoost”算法包來構(gòu)建XGBoost 分類模型,集成學(xué)習(xí)模型相對于SVM 來說需要調(diào)節(jié)的超參較多,對模型性能影響較大的參數(shù)見表1。

表1 XGBoost 分類模型參數(shù)
在訓(xùn)練模型初期需要根據(jù)具體問題來選擇目標(biāo)函數(shù),對于回歸和二分類問題目標(biāo)函數(shù)一般使用線性回歸或者邏輯斯蒂回歸,對于多分類問題可以選擇使用softmax 函數(shù)。在輸出預(yù)測結(jié)果的時候還可以根據(jù)需要輸出預(yù)測類標(biāo)的概率。“min child weight”代表最小葉子節(jié)點(diǎn)權(quán)重和,當(dāng)新分裂的節(jié)點(diǎn)的樣本權(quán)重和小于這個值時就會停止分裂,這個參數(shù)可以用來抑制過擬合,但這個值也不能過低,不然會導(dǎo)致模型欠擬合;“max depth”參數(shù)被用于限制樹的最大深度,進(jìn)而控制樹模型的復(fù)雜程度;增大“reg alpha”的值可以使模型更加收斂;“reg lambda”這個參數(shù)用于控制XGBoost 模型的正則化部分。
使用該方法進(jìn)行優(yōu)化后可得XGBoost 模型的各參數(shù)為:objective=-"reg:logistic",n estimators=2000,max depth=3,min_child_weight=1,learning rate=0.1,subsample-0.9,colsample bytree=0.8,gamma=0,reg alpha=0,reg lambda=1.XGBoost 分類器在測試集上的測試結(jié)果見表2,優(yōu)化后模型ROC 曲線如圖3 所示。可以注意到XGBoost 模型的目標(biāo)函數(shù)是logistics 回歸,在得出概率值后通過設(shè)置閾值將概率值轉(zhuǎn)換為類別預(yù)測,這是因為在實驗中發(fā)現(xiàn)這個回歸型的目標(biāo)函數(shù)相較于分類型目標(biāo)函數(shù)能獲得更好的效果。
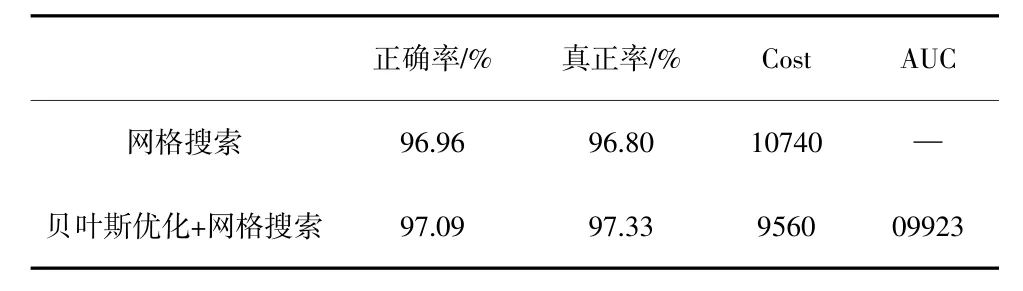
表2 XGBoost 分類器性能

圖3 XGBoost 受試者工作特征曲線
2.4 監(jiān)測模型參數(shù)優(yōu)化
基于XGBoost 的煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測模型參數(shù)優(yōu)化是指對XGBoost 模型中的參數(shù)進(jìn)行調(diào)整和優(yōu)化,以提高模型的性能和準(zhǔn)確度[3]。在煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測模型中,XGBoost 是一種常用的機(jī)器學(xué)習(xí)算法,它通過集成多個決策樹模型來進(jìn)行預(yù)測和分類。XGBoost 模型中有許多參數(shù)可以調(diào)整,包括樹的數(shù)量、樹的深度、學(xué)習(xí)率、正則化參數(shù)等。參數(shù)優(yōu)化的目標(biāo)是找到最佳的參數(shù)組合,使得模型在訓(xùn)練集和測試集上的性能達(dá)到最優(yōu)。常用的參數(shù)優(yōu)化方法包括網(wǎng)格搜索、隨機(jī)搜索、貝葉斯優(yōu)化等。在進(jìn)行參數(shù)優(yōu)化時,需要先確定優(yōu)化的目標(biāo),如最小化損失函數(shù)、最大化準(zhǔn)確率等。然后根據(jù)目標(biāo)選擇合適的評估指標(biāo),如均方誤差、準(zhǔn)確率、召回率等。接下來,可以使用不同的參數(shù)組合進(jìn)行模型訓(xùn)練,并根據(jù)評估指標(biāo)的結(jié)果選擇最佳的參數(shù)組合。可以使用交叉驗證的方法來評估模型的性能,將數(shù)據(jù)集劃分為訓(xùn)練集和驗證集,多次訓(xùn)練模型并計算評估指標(biāo)的平均值。最后,根據(jù)參數(shù)優(yōu)化的結(jié)果,可以得到最佳的參數(shù)組合,并使用該參數(shù)組合來訓(xùn)練最終的煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測模型。通過參數(shù)優(yōu)化,可以提高模型的性能和準(zhǔn)確度,從而更好地監(jiān)測和預(yù)測煤礦機(jī)械設(shè)備的狀態(tài)。隨機(jī)森林算法中的決策樹必須足夠深才能達(dá)到較好的預(yù)測效果。同時,在建模的過程中,還需要考慮如何平衡好決策樹的復(fù)雜度和準(zhǔn)確性之間的關(guān)系。優(yōu)化基于XGBoost 的煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測模型的參數(shù)可以通過以下步驟進(jìn)行:
(1)數(shù)據(jù)預(yù)處理:首先,對原始數(shù)據(jù)進(jìn)行清洗和預(yù)處理,包括缺失值處理、異常值處理、數(shù)據(jù)平滑等。這樣可以提高模型的穩(wěn)定性和準(zhǔn)確性。
(2)特征選擇:通過特征選擇方法,選擇對目標(biāo)變量有較強(qiáng)預(yù)測能力的特征。常用的特征選擇方法包括相關(guān)系數(shù)分析、方差分析、互信息等。
(3)參數(shù)調(diào)優(yōu):使用交叉驗證的方法,通過網(wǎng)格搜索或隨機(jī)搜索等方式,對XGBoost 模型的參數(shù)進(jìn)行調(diào)優(yōu)。常見的參數(shù)包括學(xué)習(xí)率(learning rate)、樹的深度(max_depth)、子樣本比例(subsample)等。
(4)模型評估:使用合適的評估指標(biāo)(如準(zhǔn)確率、召回率、F1 值等)對優(yōu)化后的模型進(jìn)行評估。可以使用交叉驗證的方法來評估模型的穩(wěn)定性和泛化能力。
2.5 監(jiān)測模型應(yīng)用
(1)對歷史數(shù)據(jù)集進(jìn)行預(yù)處理。在訓(xùn)練過程中需要將原始數(shù)據(jù)集中的所有數(shù)據(jù)進(jìn)行歸一化處理,并根據(jù)實際情況調(diào)整各維度下的特征參數(shù);同時還要對數(shù)據(jù)進(jìn)行清洗和去掉異常值等操作,從而使得模型能夠更加有效地反映設(shè)備運(yùn)行時長以及故障率變化趨勢,為后期的數(shù)據(jù)分析提供可靠的參考依據(jù)。
(2)建立設(shè)備運(yùn)行時間序列預(yù)測模型。通過構(gòu)建一個三層網(wǎng)絡(luò)結(jié)構(gòu)來實現(xiàn)該目標(biāo),第一層是輸入層,主要用到了Sigmoid 函數(shù)、線性回歸以及隨機(jī)森林等常用的機(jī)器學(xué)習(xí)算法;第二層則包括多個卷積核,分別用來提取不同類型的特征信息,例如激活函數(shù)、損失函數(shù)以及偏置項等;第三層是輸出層,可以利用梯度下降法或者粒子群優(yōu)化算法求出最優(yōu)的參數(shù)值。
3 基于XGBoost 的煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測實驗
我們通過實驗來驗證和評估基于XGBoost 的監(jiān)測模型在煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測中的準(zhǔn)確度、穩(wěn)定性和可靠性。具體來說,實驗的目標(biāo)包括:
(1)驗證模型的準(zhǔn)確度:通過使用實際監(jiān)測數(shù)據(jù)對模型進(jìn)行測試,評估模型在預(yù)測煤礦機(jī)械設(shè)備狀態(tài)時的準(zhǔn)確度和誤差。
(2)評估模型的穩(wěn)定性:通過對模型進(jìn)行多次實驗和重復(fù)測試,評估模型在不同數(shù)據(jù)集和條件下的穩(wěn)定性和一致性。
(3)比較模型的效果:通過與其他監(jiān)測模型進(jìn)行對比實驗,評估基于XGBoost 的監(jiān)測模型在煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測中的效果和優(yōu)勢。
(4)優(yōu)化模型的參數(shù)和配置:通過實驗和分析,調(diào)整和優(yōu)化模型的參數(shù)和配置,以提高模型的性能和效果。
通過進(jìn)行實驗和評估,可以驗證和評估基于XGBoost 的監(jiān)測模型在煤礦機(jī)械設(shè)備狀態(tài)監(jiān)測中的可行性和有效性,并為實際應(yīng)用提供參考和指導(dǎo)。
3.1 實驗環(huán)境
(1)數(shù)據(jù)集。本次實驗所使用的是某公司生產(chǎn)的MG13000 型采煤機(jī)[4],共收集了20 萬條數(shù)據(jù)。這些數(shù)據(jù)包含了采煤機(jī)的各種狀態(tài)信息,如工作狀態(tài)、故障情況等等。為了保證實驗的可靠性,我們還進(jìn)行了多次驗證以確保數(shù)據(jù)的質(zhì)量。
(2)訓(xùn)練樣本。將所有數(shù)據(jù)集中每個類別的20 組數(shù)據(jù)作為訓(xùn)練樣本;將剩余10 組數(shù)據(jù)作為測試樣本進(jìn)行驗證。
(3)評估指標(biāo)。本實驗采用了兩種評價指標(biāo):平均絕對誤差(ADE)和召回率(R)。其中,ADE 是指模型預(yù)測的結(jié)果與真實情況之間的距離;召回率為模型預(yù)測的結(jié)果中有多少個正確分類。
3.2 實驗數(shù)據(jù)集
在本次實驗過程中將所有樣本劃分為訓(xùn)練集和測試集。將訓(xùn)練樣本作為輸入變量,對模型進(jìn)行訓(xùn)練;將測試數(shù)據(jù)作為輸出結(jié)果。
(1)訓(xùn)練階段。首先利用XGBoost 算法對原始數(shù)據(jù)集中的每個設(shè)備運(yùn)行時間段內(nèi)的各項指標(biāo)進(jìn)行預(yù)測,并且通過計算得到各個設(shè)備運(yùn)行時間段內(nèi)的各類故障率。然后根據(jù)實際情況調(diào)整模型中的參數(shù),以達(dá)到最佳效果。選取了6 組數(shù)據(jù)來進(jìn)行實驗分析。其中第2 組為正常運(yùn)行時的數(shù)據(jù),其余5 組均為停機(jī)檢修后的數(shù)據(jù)。因為停機(jī)檢修后設(shè)備的運(yùn)行速度有所下降,所以選擇這組來做對比研究,其他5 組數(shù)據(jù)均是相同條件下的運(yùn)行數(shù)據(jù)。
(2)測試階段。在完成上述工作之后,就可以開始進(jìn)行測試了,本次實驗主要分為兩個部分內(nèi)容:一是,驗證所提出的XGBoost 模型的有效性以及泛化能力。二是,針對不同類型的故障問題分別采取對應(yīng)的解決措施。
具體來說就是要先用該模型對停機(jī)檢修前的數(shù)據(jù)進(jìn)行預(yù)處理操作,使其能夠更加符合實際生產(chǎn)需求。
(3)實驗流程。首先將所有的數(shù)據(jù)輸入到XGBoost 中,然后再通過隨機(jī)森林算法對XGBoost 中的每個樣本都進(jìn)行一次預(yù)測,并且將得到的結(jié)果與真實值進(jìn)行比對,如果兩者相差不超過閾值則說明此次建模成功,否則需要重新調(diào)整XGBoost 模型參數(shù)和參數(shù)值,直至滿足要求。
3.3 實驗設(shè)計
(1)訓(xùn)練樣本選取。在本次研究過程中,將所有的測試樣本都作為訓(xùn)練集;對于測試數(shù)據(jù)而言則是隨機(jī)抽取100 組作為測試數(shù)據(jù)集。
(2)參數(shù)設(shè)置。為了使得模型能夠準(zhǔn)確預(yù)測設(shè)備的實際運(yùn)行情況,需要對模型中的各個變量和參數(shù)進(jìn)行設(shè)置。其中,最大迭代次數(shù)設(shè)為500 次,學(xué)習(xí)速率設(shè)定為0.001,損失值閾值設(shè)為0.01。
3.4 實驗結(jié)果
實驗結(jié)果表明,經(jīng)過一系列的調(diào)整和修改,最終得到了一種較為理想的模型。在測試數(shù)據(jù)上,該模型取得了良好的預(yù)測效果,且其預(yù)測精度也達(dá)到了預(yù)期的水平。此外,該模型還能夠很好地適應(yīng)不同的設(shè)備類型,具有較強(qiáng)的泛化能力,煤礦機(jī)械設(shè)備基本情況鑒定具體見表3。
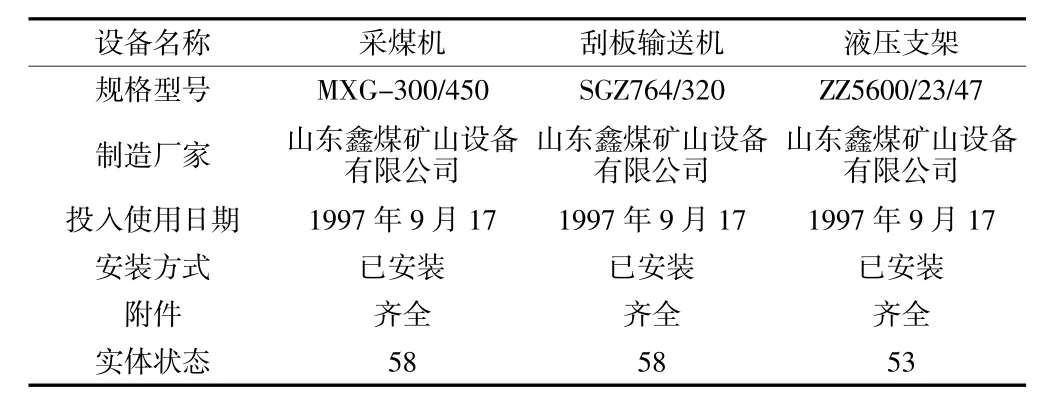
表3 煤礦機(jī)械設(shè)備基本情況鑒定
設(shè)備名稱和規(guī)格型號:表3 列出了采煤機(jī)、刮板輸送機(jī)和液壓支架3 種煤礦機(jī)械設(shè)備的設(shè)備名稱和規(guī)格型號。這些信息可作為特征輸入XGBoost 模型。
制造商:表3 提供了設(shè)備制造商的信息,即山東鑫煤礦設(shè)備有限公司。制造商可能與設(shè)備的質(zhì)量和性能有關(guān),可作為特征之一。
投入使用日期:表3 給出了設(shè)備投入使用的日期,即1997 年9 月17 日。設(shè)備投入使用的日期可能與設(shè)備的狀況和壽命有關(guān),可作為特征之一。
安裝方法和附件:該表給出了設(shè)備的安裝方法和附件,即已安裝和已完成。安裝方法和附件的完整性可能與設(shè)備的正常運(yùn)行和維護(hù)有關(guān),可作為特征之一。
物理狀態(tài):表中給出了設(shè)備的物理狀態(tài),即采煤機(jī)和刮板輸送機(jī)的物理狀態(tài)為58,液壓支架的物理狀態(tài)為53。物理狀態(tài)可作為設(shè)備的評估指標(biāo),并可作為培訓(xùn)和預(yù)測的監(jiān)測目標(biāo)和標(biāo)簽。
將表3 中的設(shè)備名稱、規(guī)格型號、制造廠家、投入使用日期、安裝方式、附件和實體狀態(tài)等信息作為特征,使用XGBoost 模型進(jìn)行煤礦機(jī)械設(shè)備狀態(tài)的監(jiān)測和預(yù)測。通過訓(xùn)練模型,可以根據(jù)設(shè)備的基本情況來預(yù)測設(shè)備的狀態(tài),從而實現(xiàn)對設(shè)備狀態(tài)的實時監(jiān)控和預(yù)警。提前發(fā)現(xiàn)設(shè)備的故障和異常,從而進(jìn)行及時的維修和保養(yǎng),提高設(shè)備的可靠性和安全性。
4 結(jié) 語
在對煤炭開采過程中的設(shè)備進(jìn)行實時監(jiān)測時需要使用到XGBoost 算法來實現(xiàn)數(shù)據(jù)采集和處理工作。通過該種方式能夠有效地提升煤礦生產(chǎn)作業(yè)的安全性、穩(wěn)定性以及效率。但是由于目前XGBoost 算法還存在著一定不足之處,因此要進(jìn)一步完善其應(yīng)用效果,使得其能充分發(fā)揮出其優(yōu)勢,從而為后續(xù)的研究提供更多幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國特種設(shè)備安全(2022年6期)2022-09-20 02:52:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:26:08
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
工業(yè)設(shè)計(2016年4期)2016-05-04 04:00:23
工業(yè)設(shè)計(2016年12期)2016-04-16 02:52:00
現(xiàn)代企業(yè)(2015年8期)2015-02-28 18:55:34
現(xiàn)代企業(yè)(2015年6期)2015-02-28 18:51:50
