基于語料庫的政治類文本英譯中顯化與隱化研究
2023-10-24 06:43:08胡偉華趙子鑫
山東外語教學 2023年1期
胡偉華 趙子鑫
[摘要] 翻譯語言作為獨立于目的語的語言變體,被認為具有翻譯普遍性(以下稱翻譯共性)。本文通過自建小型英語可比語料庫對“顯化”和“隱化”這兩個共性特征進行驗證,以多維分析法為框架對67個語言特征進行考察,并篩選出13個具有顯著差異的特征。研究發現:1)翻譯英語文本中的功能詞使用顯著增加,時體標記高于原創英語文本;2)翻譯英語文本中信息密度降低,詞匯使用和句子結構的變化低于原創英語文本。研究認為翻譯語言具有顯化和隱化共性并簡要探討了原因。
[關鍵詞] 翻譯共性;語料庫;顯化;隱化
[中圖分類號] H059[文獻標識碼] A[文獻編號] 1002-2643(2023)01-0114-11
A Corpus-based Study on Explicitation and Implicitation in Political Texts: Taking Xi Jinping: The Governance of China as an Example[JZ)]
HU Weihua1、2 ZHAO Zixin2
(1.School of Translation Studies,Xian International Studies University, Xian 710061, China;
2. School of Humanities and Social Science, Xian Polytechnic University, Xian 710048, China)
Abstract: Translational language, as a linguistic variant different from target language, is consider to have certain translation universals. The present paper presents a empirical study on explicitation and implicitation hypotheses. Based on a self-built comparable English corpus, the author employs multi-dimension analysis method to examine 67 linguistic features and then take 13 from them as the evidence for translation universal hypotheses. The findings include 1) translational English texts shows the tendency of more frequent uses of functional words and tense markers, 2) translational English presents a lower lexical density compared with original English texts, which results from lower uses of nominal forms and sentence variations. Thus, the author thinks translational variant shows the explicitation and implicitation universals ans briefly discusses the reasons.
Key words: Translation universal; corpus; explicitation; implicitation
1.前言
近年來,隨著量化分析手段與語言研究的不斷結合,語料庫研究方法及相關工具應運而生并不斷更新,語料庫翻譯學成果層出不窮,成為語料庫相關研究的核心領域(Hansen-Schirra et al.,2007:244;劉霞、許家金、劉磊,2014:72;龐雙子,2019:14;胡顯耀等,2020:274)。在描寫性譯學研究的理論和工具的共同推動下,大量學者開展了基于語料庫的翻譯語言變體的語言特征考察,為翻譯共性假說及其動因提供了大量佐證。
根據先前學者對翻譯共性假說的研究,筆者總結梳理現有研究認為相關研究仍存在一定的局限性,理論界定的邊界尚有混淆,實證研究結果仍不足以相互印證(Olohan,2001:428-430;Quirk et al.,1985:34)。翻譯語言是否獨立于原語和目的語,并具有獨立于兩(多)種語言的翻譯共性,若翻譯共性課題確如Baker(1993:237)最初的界定與構想,那么對翻譯共性假說的考察與驗證仍需立足于多維度、多文體、多語言文本,通過對觀測變量不斷的完善和補充,為相關假說提供完備的文本和數據支撐。
基于此,本文通過筆者自建小型英語可比語料庫,考察翻譯英語文本所呈現出的語言特征,并與原創英語文本相比較,梳理翻譯語言特征與顯化和隱化假說之間的關系,分析翻譯英語文本的顯化和隱化特征。擬通過量化數據分析方法解決以下兩個問題:翻譯英語文本與原創英語文本是否存在差異特征,并能夠通過統計分析區分兩者?這些特征在翻譯文本中如何呈現出顯化與隱化特征?
2.顯化與隱化研究綜述
“顯化”和“隱化”最初由Vinay & Darbelnet(1995:472)提出,并將顯化定義為將原文中隱含的信息因語境的關聯而翻譯出來的過程,而隱化則是由目標語語境確定文本在原文中所明示的細節的過程。即顯化是在翻譯中將原文本隱含的卻想要表達的信息在譯語文本中明確表達,而隱化則是將原語文本中某些信息忽略或簡化的結果。Blum-Kulka 對顯化進行了系統的實證研究,并指出顯化特征“無關原語與譯入語的語言差異,而是體現在連接詞”(Blum-Kulka)。Mona Baker(1993:241)將顯化假說納入翻譯普遍特征之一。
為了對顯化假設提供有力的證據,Olohan & Baker(2000:147)以翻譯英語語料庫和英國國家語料庫為研究對象,統計了動詞say和tell后接的可省略that,研究表明翻譯英語語料庫中that的使用頻次顯著高于英國國家語料庫。在后續的句法顯化研究中,Olohan(2001:427)發現,翻譯過程中對可省略that的保留是因為譯者無意識的認知過程的作用,并非是刻意的對其保留。以文學作品為考察對象的相關研究中,不同的文學體裁也呈現出不同的語言特征。詩歌以音韻和精煉著稱;散文更加注重銜接、連貫的作用;戲劇偏向于語言和視覺效果的雙重表達。Kia & Ouliaeinia(2016:87)以11個參考值為變量研究了波斯文學作品英譯本的詞匯顯化。結果表明,除了詩歌中專有名詞和省略無顯著變化外,其余9個變量均存在顯著變化。
國內相關研究仍以實證研究為主。王克非、胡顯耀(2008:17)指出文學文本與非文學文本中,都存在詞匯密度、變化度偏低,常用詞詞頻增加,虛詞顯化,指代顯化的特征。胡顯耀、曾佳(2017;605)以原語干擾為切入點,考察了法語、俄語、日語、漢語、西班牙語等18種翻譯英語的詞匯密度、常用詞詞頻、平均句段長、語法功能詞等語言特征,指出以上語言作為原語的翻譯英語都存在不同程度的顯化和隱化特征。
在口譯研究方面,胡開寶、陶慶(2012:741)通過考察漢英記者招待會的句法操作規范性發現顯化和隱化等句法操作規范不同程度地影響了記者招待會英漢語口譯。謝麗欣、胡開寶(2015:19)對比了記者招待會英漢口譯語料和政府工作報告英譯文本中不定量詞使用的頻率及其特征,指出前者的顯化程度顯著高于后者。同時,也有學者認為翻譯共性研究應當著眼于語言使用的歷時動態過程。龐雙子、王克非(2018:17)通過歷時復合語料庫考察1930年代、1960年代和1990年代三個時期的英漢翻譯文本的顯化特征,發現這三個時期對比結果中,形式顯化程度有所下降,語義顯化程度相對增強。
3.語料庫構建及研究方法
3.1 語料庫構建
目前翻譯共性研究仍處于以文學作品為主要研究對象并向其他文本類型或多語體語料庫發展的轉變階段。本文以《習近平談治國理政》一、二卷英譯本為考察對象自建小型語料庫,其中包括習近平總書記2012-2017年間講話179篇,涵蓋堅持和發展中國特色社會主義、實現中國夢、堅定文化自信、構建人類命運共同體等35個主題,形符數283,766個。該譯本可以作為研究對象的原因在于其由中國外文出版發行事業局相關團隊翻譯、審校,最終出版發行,從譯文質量上保證了研究對象選取的嚴謹性。
同時以白宮官網(www.whitehouse.gov)發布的美國前總統特朗普發言稿為原語文本參考對象構建了可比語料庫。筆者通過對翻譯英語文本和原創英語文本在主題、篇幅、發布時間等方面綜合考量,最終選取2017-2020年間文本179篇,含263,257個形符數。在全部語料清潔后,使用斯坦福詞性標注工具(Stanford POS Tagger)對文本進行標注。
3.2 數據收集與統計分析
翻譯共性假說的實證研究將可能具有顯著差異的語言特征納入考察范圍,根據變量頻次進行數據統計,通過數據顯著性判斷翻譯語體是否符合假設預期。本研究中涉及的工具主要包括語料處理和語料庫建設工具:Editplus、Stanford POS Tagger、Antconc,以及數據分析工具:Multi-dimensional Analysis Tagger、SPSS。
同時,采用Douglas Biber在Variation across Speech and Writing中提出的多維分析法(Multi-dimensional analysis)為理論框架(Biber,1988:61-79),將數據處理與分析劃分為三個維度:
首先,在翻譯英語語料和原創英語語料清潔完成后,以多維分析法的67個語言特征為觀測指標,并將其歸為時體標記、從屬關系、情態動詞、被動結構、名詞結構等16個類別,對每個文本中的相應語言特征加以標注并進行頻次統計,同時做標準化處理(以每100形符數中出現頻次為標準);
其次,通過相關性檢驗對翻譯英語語料和原創英語語料中具有顯著性的語言特征進行篩選,本研究采用非參數檢驗并以顯著性水平p取值0.05為標準,當p<0.05時則認為該特征在翻譯語料和原創語料中具有顯著差異,通過篩選所有具有顯著差異的語言特征進行進一步分析;
最終,為在所有差異特征中得到其共現模式,以因子分析對不同語言特征作出聚類分析,通過特征間的共現模式解讀這些語言特征形成翻譯共性假說的動因。
4.分析與討論
4.1 總體分析
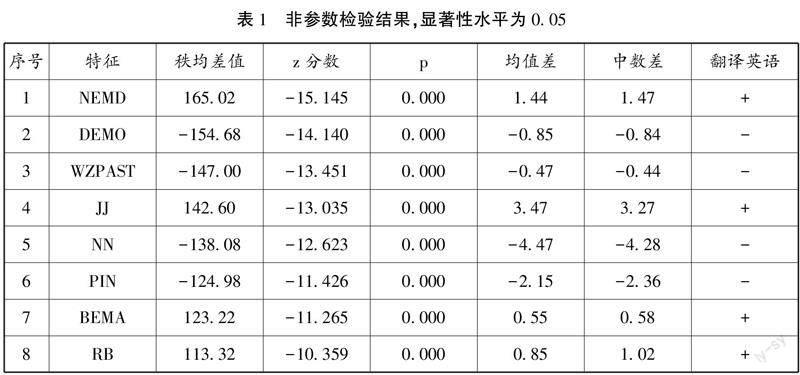
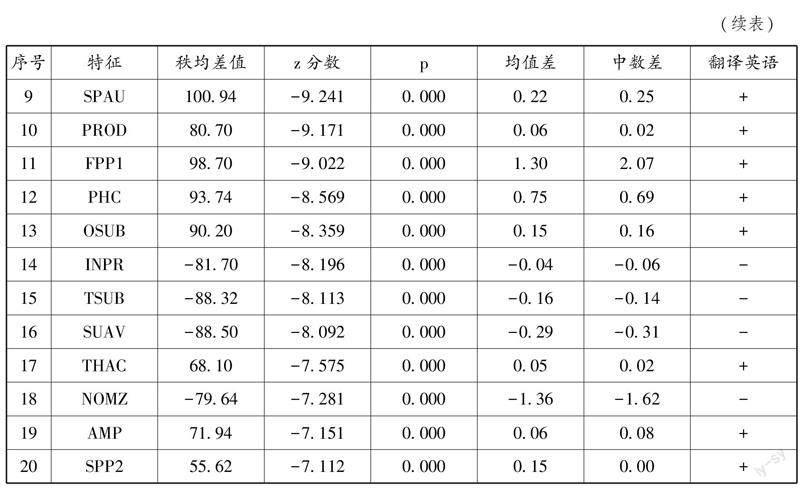
通過對翻譯英語和原創英語文本中67個語言特征的統計后,筆者對兩組數據進行曼-惠特尼相關性檢驗(Mann-Whitney U Test),為避免部分語言特征在實際語用場景中并非呈正態分布,采取非參數檢驗以確保數據效度。
由相關性檢驗可知,翻譯文本的67個觀測值中有46個特征呈現與原創英語文本的顯著差異。其中,必要性情態動詞(NEMD)、指示代詞(DEMO)、過去分詞結構(WZPAST)、定語形容詞(JJ)、所有名詞結構(NN)、介詞短語(PIN)、be作主動詞(BEMA)、副詞(RB)、助動詞(SPAU)、代動詞do(PROD)為翻譯英語和原創英語文本中46個顯著差異特征中差異最大的前十個特征。
除顯著性p值外,筆者選擇秩均差、均值差和中數差三項數值作為觀測值。秩均值差是非參數秩和檢驗的一項參數,通過比較秩均差值,可以避免因具體語言特征在實際使用場景中總體非正態分布的情況而對檢驗結果產生的信度影響,同時也適用于不同性質的變量間比較。秩均差的絕對值越大則該語言特征原語文本與翻譯文本中使用的頻率差別越大。均值差和中數差同時作為參考值可以避免出現極端值的影響。以正負號標識的翻譯影響是指,通過對比翻譯英語文本與原創英語文本,原創漢語文本因翻譯而增強的語言特征由“+”號標識,減弱的特征由“-”標識。在本文所考察相關性檢驗中共46個顯著差異特征,包括29個翻譯英語文本特征呈現增強的趨勢,17個翻譯英語文本特征呈現減弱的趨勢。
4.2 因子分析
通過以上對67個翻譯英語文本語言特征中篩選出具有顯著差異的特征46個,通過因子分析能夠將不同特征從相應的出現頻次歸為不同類別。多維分析的一個重要前提即語言特征共現趨勢強度能夠表明該組特征隱含的共同功能維度(Biber,1988:13)。當某些語言特征共同出現并形成一種共現模式時,對這些特征的共同識別和解讀就能挖掘出特定的語言維度。因子分析即通過對上述具有顯著差異的特征之間的關系進行分析,旨在找出能綜合這些特征的少數幾個因子,通過因子來解釋絕大部分特征的共同作用,通過多元降維處理減少變量數量,增強因子解釋力。
對前文46個顯著特征的因子分析首先需要滿足KMO和Barlette球形度檢驗,只有當KMO適切量數和Barlette球形度檢驗滿足條件,即前者KMO適切量數>0.6,Barlette球形度檢驗顯著性p<0.05時,才能確保當前各個變量間的相關性適合因子分析。筆者所檢驗KMO適切量數為0.770且球形度檢驗p約等于0.000。
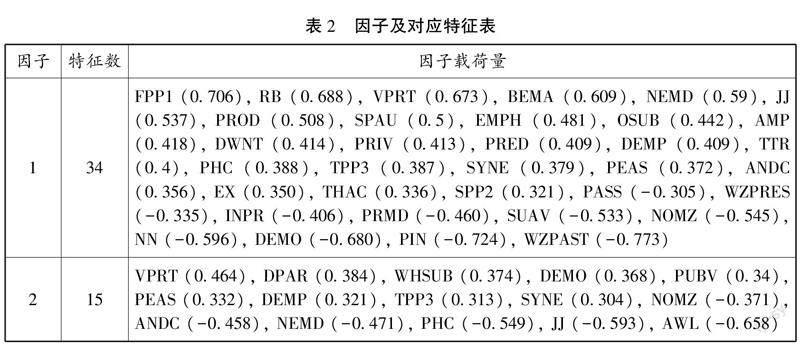
經過因子分析后共得到13個有效因子,共提取62.604%方差,即說明所篩選因子能夠解釋62.3%的因子特征。在此基礎上,選擇最大方差法進行因子旋轉。通過因子旋轉能夠將成分載荷絕對值加以區分,從而區分每個原始特征值對因子的解釋量。受篇幅所限,筆者僅對前兩個與本文密切相關的因子加以闡述。
由表2可見,因子1共包含因子載荷量>0.3的特征34個,其中24個特征載荷量為正值,10個特征載荷量為負值。第一人稱代詞(FPP1)、副詞(RB)、現在時(VPRT)、be作主動詞(BEMA)和必要性情態動詞(NEMD)為正載荷量最大的五個特征。過去分詞結構(WZPAST)、介詞短語(PIN)、指示代詞(DEMO)、所有名詞結構(NN)和典型名詞(NN)為前五個負載荷值絕對值最大的特征。必要性情態動詞(necessity modals)為Biber在多維分析法中對情態動詞做出的分類,包括ought、should和must三個詞。
因子2共包含因子載荷量>0.3的特征15個,其中9個為正載荷值特征,6個為負載荷值特征。現在時(VPRT)、小品詞(DPAR)、wh-型名詞性關系從句(WHSUB)、指示代詞(DEMO)和公動詞(PUBV)為前五個正載荷量最大的特征。平均詞長(AWL)、定語形容詞(JJ)、并列短語結構(PHC)、必要性情態動詞(NEMD)和并列獨立分句(ANDC)為前五個正載荷量最大的特征。公動詞(public verbs)和認知動詞(private verbs)是Quirk et al.(1985)對事實性動詞(factual verbs)所作出的劃分。
4.3 因子解釋
因子分析結果所呈現出包含聚類關系的語言特征分布于14個所標注特征的類別中,主要包括代名詞和代動詞(pronouns and proverbs)、從屬關系(subordination)、形容詞和副詞(adjectives and adverbs)以及詞類(lexical classes)。
代詞類別通常被作為解釋文本信息量的參考指標,另外也是考量文本內所指識別和語體正式程度的參考特征,本文主要分為人稱代詞和非人稱代詞進行討論。第一人稱代詞的使用反映出說話人在當前話題或文本內容的自我參與度;第二人稱代詞的使用表明文本所涉及話題或行為具有明確指向性;第三人稱代詞所指在其文本中呈現出相對不確定指稱的特點。三類人稱代詞的使用在本文所考察翻譯英語語料中經檢驗,秩均差值分別為98.70、55.62和49.56,與原創英語語料相比,上述特征均有過度呈現(overrepresentation)的趨勢。
其次,翻譯英語文本非人稱代詞中指示代詞和代動詞do使用顯著增加,同時不定代詞使用減少。指示代詞可用于指代實體,或做外照應,或做文內前指,讀者通常可以根據原作者所呈現邏輯關系解讀文內邏輯關系。代動詞do的使用通常是以do代替小句內動詞,通過對動詞形式的簡化而保留對句內其他成分的信息焦點。而不定代詞的使用頻次降低,對非明確事物指代減少。
綜上,本文代詞類別下所考察語言特征中,人稱代詞和指示代詞使用頻次明顯增加,文本內指代關系的增加反映出前后文邏輯關系的強度增加。同時,不定代詞的頻次說明翻譯文本對非明確所指的使用較少。以上六個語言特征在因子分析中形成聚類關系,從而反映出翻譯英語文本中邏輯關系增強的特點。
在其他詞類中,形容詞和副詞是文本中闡述和描述信息的關鍵成分,而名詞及名詞性結構是文本本身的信息焦點。前者的秩均差值分別為142.60和112.32,而后者的秩均差值為-79.64和-138.08。形容詞和副詞作為句子中心成分的修飾、限定成分,在翻譯英語文本中的使用顯著高于原創英語文本,而名詞性成分在翻譯英語文本中的使用則明顯降低。那么,是否可以認為翻譯英語中呈現出信息度降低而限定成分增多?
統計還顯示,弱化語和強調語在翻譯英語語料中使用頻次增加。弱化語(downtoners)的使用在文本中對動詞起到降低其強度的效果,和模糊語(hedges)的使用產生類似的文本效果。而強調語(emphatics)和強化語(amplifiers)是多維分析法中對文本內容起到強調作用的兩種詞類。強化語與弱化語可以被認為是相對的概念,對句中動詞效果產生強化的作用。以上三個語言特征雖然分為弱化和強化,但都呈現出翻譯英語文本中對動詞效果的強化,加強文本內容所試圖表達的效果,通過形式上成分添加達到內容顯化的效果。
4.4 顯化與隱化驗證
通過對《習近平談治國理政》英譯本中67個語言特征進行標注、統計,并與原創英語文本進行相關性檢驗、因子分析后,筆者篩選出13個語言特征。該類特征在翻譯英語和原創英語文本中具有顯著差異,并形成聚類因子,對翻譯共性假說具有一定程度的實證解釋力。
分析表3中各項特征,根據這些語言特征本身呈現出的功能及其共現模式和顯化與隱化的界定與表現形式來看,筆者總結了這些共現特征呈現出的三種功能,包括功能詞使用、時體標記和信息量。
在功能詞使用上,助動詞(SPAU)、狀語從屬連詞(OSUB)和指示代詞(DEMP)使用頻次增加常被作為顯化的觀測指標(龐雙子、王克非,2018:18;胡顯耀、肖忠華,2020:279)。英語作為典型的形合語言之一,代詞使用常用于語義的銜接。從特征聚類結果來看,代詞在翻譯英語中作為語義銜接手段,其使用相較于原創英語而言更加頻繁。原因可能在于漢英兩種語言系統的差異導致翻譯過程中對部分特征的過度呈現。
同時,名詞代詞比也是顯化研究的重要指標之一。從名詞和代詞的秩均差來看,名詞及名詞性結構在翻譯英語文本中都出現欠額呈現(underrepresentation)的特點。代詞的增多和名詞頻次降低,同時平均詞長降低這一特征在聚類分析中出現在因子內。即名詞代詞比下降能夠進一步印證翻譯英語具有顯化特征。另外,三類人稱代詞(FPP1、SPP2、TPP3)在翻譯英語中的使用呈現出普遍高于原創英語的現象。顯化研究中,語法銜接的連詞和代詞多被用做衡量翻譯文本顯化特征的指標,其使用頻次的增加被作為翻譯語言顯化特征的高解釋力特征(胡顯耀等,2020:279)。這一結論同時也支撐本文結果之一。人稱代詞使用的增加也有可能與漢語中常省略主語的使用習慣有關,但是三類人稱代詞的使用在相關性和聚類分析中都呈現出顯著差異,表明翻譯英語文本具有形式顯化的特征。
關于時體標記,表3中可以看出翻譯英語文本中現在時(VPRT)和完成時(PEAS)的時體標記使用頻次也明顯高于原創英語文本。因為漢語與英語對時體表達的方式不同,漢語的時體特征更加模糊,而英語的時體變化明確,可以認為在本研究所考察語料翻譯過程中,譯者強化了英語中的時體標記,該特征的產生可能與英漢兩種語言間的語言接觸相關。然而,Douglas Biber在對多維分析法論述中認為就原創英語而言,現在時多用于描述與當前主題相關度高的話題或行為,或多用于正式程度較高的文體中,故不聚焦于事件的時空背景;完成時的使用同樣關注描述事件的行為本身,其使用也與文體的正式程度呈正相關(Douglas Biber,1988:67)。綜上,本文所考察語料中,助動詞、連詞和代詞在與不同語言特征的共現模式中均為顯化共性的存在提供驗證。
信息量中包含五個特征值,分別是所有名詞結構(NN)、典型名詞(NOMZ)、be作主動詞(BEMA)、代動詞do(PROD)和平均詞長。與原創英語相比,典型名詞和名詞結構的使用都呈現出下降的趨勢;平均詞長相對縮短;be作主動詞和代動詞do的統計頻次上升。典型名詞(nominalization)在Douglas Biber的相關文獻中界定為以-tion、-ment、-ness或-ity結尾的單詞,通過典型名詞通常與被動結構和介詞結構同時使用這一現象,指出典型名詞能夠傳達高度抽象的概念和信息。那么,我們可以認為典型名詞的使用是將觀點中信息概括或提煉后而表達的。另外,本文在特征標注過程中,將名詞性結構劃分為三類,典型名詞、動名詞(gerund)和其他名詞結構。從數據結果來看,典型名詞和所有名詞結構的頻次也出現下降的趨勢。同時,綜合考量平均詞長縮短等因素,翻譯英語文本中名詞性結構使用較之于原創英語有所下降。這一觀點同時也得到了另外兩個特征的佐證,be作主動詞(be as main verb)和代動詞do(pro-verb do)。當do充當小句中動詞,相應地句子本身表達出更少的信息焦點,因而降低了文本本身的信息密度。另外,筆者認為be作主動詞也產生了同樣的文本效果。若以句子為文本中的信息單位計算,上述兩種語言特征對句子內主要成分動詞作出標記,因而對主要信息攜帶成分加以限制,降低了文本信息度。以上兩個特征增加的趨勢從結構上進一步對翻譯英語文本的信息量下降提供佐證。綜上所述,從翻譯英語文本的結構來看,名詞性結構和平均詞長的降低為翻譯語體隱化特征提供了論據,同時動詞的使用范圍降低也支撐了這一結論。
4.5 動因分析
我們通過對翻譯英語和原創英語的微觀語言特征分析和因子提取,確能一窺翻譯顯化與隱化的存在。通過文本分析和實驗,筆者將顯化與隱化兩特征的形成動因主要歸于文本特征和譯者行為。
首先,本研究以政治類文本為對象,語料為《習近平談治國理政》英譯本和特朗普演講稿,所得出定量與定性結果與其文本特征、功能和內容在一定程度上存在相關性。
政治類文本之所以逐漸成為當前語料庫翻譯學研究中炙手可熱的文本類型之一,究其原因,無論是在內容亦或文本功能上,都具有其鮮明的特征。即政治類文本通常具有其原文化背景和社會背景下語言內容的權威和不可替代性。如中國國家領導人在講話中慣常使用的修辭手法、古詩詞、文言文以及用來闡述中國政府治國理政政策制定、執行和經驗宣傳的慣用特色表達;美國總統演講稿中經常出現的表現其“人權”“自由”“民主”等意識形態立場的慣用表述以及各類新出臺的經濟、政治、對外關系等主題相關的術語、主題詞等。
其次,《習近平談治國理政》英譯本的(主要)譯者均為源文本母語者。因此筆者推論在翻譯過程中,鑒于文本的使用目的和語言表述的斟酌與推敲,譯者需要在翻譯過程中保證源語文本的權威性,會自覺或不自覺地對原文亦步亦趨(胡開寶,2019:14);同時政治類文本對忠實和準確度要求更高。因此,相較于英語源語文本,翻譯文本則最終呈現“信息密度降低,詞匯使用和句子結構的變化度低”的現象。
由于翻譯過程中譯者的母語遷移作用,漢語本身的語言特點會體現在母語譯者的翻譯文本中。如中國政治類文本中最常出現的平行句式,通常其譯文也會以同樣的結構出現,這不僅導致了句子結構變化度低,也使得翻譯過程中需要借助更多的功能詞,以保證句式結構的對應。因而實驗結果呈現出了“功能詞使用顯著增加”的特點。
5.結語
本文以自建可比語料庫為考察對象,對翻譯文本的67個語言特征進行考察,旨在對翻譯語體的顯化和隱化特征提供佐證。通過相關性檢驗和因子分析等統計學方法,筆者得到翻譯文本與原創英語文本具有顯著差異的13個語言特征。功能詞和時體標記的顯著增加表明所考察語料確實存在顯化特征,信息量降低及句子結構變化度減少可以被看作是隱化共性的呈現方式之一。本文對顯化和隱化共性的存在提供了驗證,但對其影響因素和形成原因的解釋仍然需要更加深入和細致的研究。誠然,翻譯共性作為語料庫翻譯研究領域內的重要課題,在進行原語與譯語語言特征比較研究方面正在受到學界越來越多的重視。但該課題的研究成果若最終試圖與Douglas Biber最初提出翻譯共性時的論述所契合,那么對翻譯共性的驗證仍需從多語言、多語體、多變量三個維度出發,進一步擴充當前我們已經掌握的結論,并采取更加多元的理論框架對其動因加以分析和解讀。
參考文獻
[1]Baker, M.
Corpus linguistics and translation studies: implications and applications. In M. Baker et al. (eds.). Text and Technology: In Honour Of John Sinclair [C]. Amsterdam: John Benjamins, 1993. 233-250.
[2]Biber, D. Variation across Speech and Writing [M]. Cambridge: Cambridge University Press, 1988.
[3]Blum-Kulka, S. Shifts of cohesion and coherence in translation. In J. House & S. Blum-Kulka (eds.). Interlingual and Intercultural Communication: Discourse and Cognition in Translation and Second Language Acquisition Studies [C]. Tubingen: Gunter Narr Verlag, 1986. 17-35.
[4]Hansen-Schirra, S. et al. Cohesive explicitness and explicitation in an English-German translation corpus [J]. Languages in Contrast, 2007, 7(2): 241-266.
[5]Kia, M. V. & H. Ouliaeinia. Explicitation across literary genres: evidence of a strategic device? [J]. The International Journal for Translation & Interpreting Research, 2016, 8(2): 82-95.
[6]Olohan, M. Spelling out the optionals in translation: a corpus study [J]. UCREL Technical Paper, 2001,13(1): 423-432.
[7]Olohan, M. & M. Baker. Reporting that in translated English: evidence for subconscious processes of explicitation? [J]. Across Languages and Cultures, 2000, 1(2): 141-158.
[8]Quirk, R. et al. A Comprehensive Grammar of the English Language [M]. New York: Longman, 1985.
[9]Vinay, J. & J. Darbelnet. Comparative stylistics of French and English: a methodology for translation [J]. Meta, 1995, 41(3):471-473.
[10]謝麗欣,胡開寶. 記者招待會漢英口譯中不定量詞的應用研究 [J]. 外語電化教學, 2015,(1): 17-22.
[11]胡開寶. 中國特色大國外交話語的構建研究:內涵與意義 [J]. 山東外語教學, 2019, (4): 10-20.
[12]胡開寶, 陶慶. 記者招待會漢英口譯句法操作規范研究 [J]. 外語教學與研究, 2012,(5): 738-750.
[13]胡顯耀, 曾佳. 對翻譯英語中原語干擾的文體統計學分析[J]. 外語教學與研究, 2017,(4): 597-607+641.
[14]胡顯耀, 肖忠華, Andrew Hardie. 翻譯英語變體的語料庫文體統計學分析 [J]. 外語教學與研究, 2020,(2): 273-282.
[15]劉霞, 許家金, 劉磊. 基于CiteSpace的國內語料庫語言學研究概述(1998-2013) [J]. 語料庫語言學, 2014,(1): 69-77+112.
[16]龐雙子, 王克非. 翻譯文本語體“顯化”特征的歷時考察 [J]. 中國翻譯, 2018,(5): 13-20+48+127.
[17]龐雙子. 基于歷時類比語料庫的翻譯文本語體顯化特征的計量分析 [J]. 外國語, 2019,(6): 83-94.
[18]王克非, 胡顯耀. 基于語料庫的翻譯漢語詞匯特征研究[J]. 中國翻譯, 2008,(6): 16-21.
[19]習近平. Xi Jinping: The Governance of China [M]. 英文翻譯組譯. 北京: 外文出版社, 2014.
[20]習近平. Xi Jinping: The Governance of China II [M]. 英文翻譯組譯. 北京: 外文出版社, 2017.
(責任編輯:方茗)
收稿日期:2022-04-11;修改稿,2022-09-23;本刊修訂,2023-01-09
基金項目:本文為國家社科基金項目“基于語料庫的國際主流媒體中國形象動態檢測與分析研究”(項目編號:18XYY010)的階段性成果。
作者簡介:胡偉華,博士,教授,博士生導師。研究方向:跨文化翻譯,教育國際化。電子郵箱:523032870@qq.com。趙子鑫,碩士研究生。研究方向;語料庫翻譯學。
引用信息:胡偉華,趙子鑫.基于語料庫的政治類文本英譯中顯化與隱化研究——以《習近平談治國理政》官方英譯本為例[J].山東外語教學,2023,(1):114-124.
