基于深度學習的行人屬性識別及應用
2023-10-27 10:29:27武鑫森
現代信息科技 2023年17期
關鍵詞:深度學習

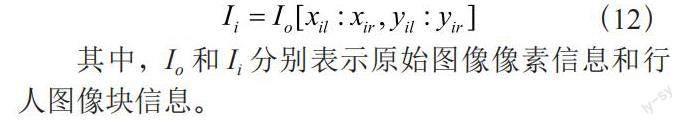
摘? 要:為了提高行人屬性識別的準確率,提出基于多尺度注意力網絡的行人屬性識別算法,并對其進行了改進。將行人屬性分為上身、上身附屬、下身、下身附屬、腳部、朝向、性別、年齡、攜帶物9個類型。在進行初步的二分類屬性預測后,實行進一步的屬性篩選分類,避免互斥屬性同時出現,從而提高屬性識別結果的準確性和合理性。此外,為了有利于行人屬性識別算法的應用,基于模塊化的設計理念,按照原始圖像和目標檢測預測結果中的行人類型和位置信息獲取行人圖像塊信息進行屬性識別,提出目標檢測與行人屬性識別一體化的方法。
關鍵詞:圖像處理;深度學習;行人屬性識別;目標檢測
中圖分類號:TP391.4? 文獻標識碼:A? ? 文章編號:2096-4706(2023)17-0061-06
Pedestrian Attribute Recognition and Application Based on Deep Learning
WU Xinsen
(CRSC Communication & Information Corporation, Beijing? 100070, China)
Abstract: In order to improve the accuracy of pedestrian attribute recognition, a pedestrian attribute recognition algorithm based on multi-scale attention networks is proposed and improved. Divide pedestrian attributes into 9 types: upper body, upper body attachment, lower body, lower body attachment, feet, orientation, gender, age, and carrying items. After preliminary binary attribute prediction, further attribute screening and classification are implemented to avoid the simultaneous occurrence of mutually exclusive attributes, thereby improving the accuracy and rationality of attribute recognition results. In order to facilitate the application of pedestrian attribute recognition algorithms, and based on a modular design concept, pedestrian image block information is obtained from the original image and the pedestrian type and position information in the target detection prediction results for attribute recognition. An integrated method of target detection and pedestrian attribute recognition is proposed.
Keywords: image processing; deep learning; pedestrian attribute recognition; object detection
0? 引? 言
行人屬性識別是近年來發展迅速的一種算法,作為深度學習算法的一個分支,行人屬性識別算法可以有效挖掘出監控場景中行人可被觀察到的一些語義信息,如行人性別、年齡、朝向、發型、帽子、上衣、下衣、鞋子,以及行人是否佩戴眼鏡、口罩、背包等附屬物等,為此該算法在智慧城市、刑事偵查等領域得到廣泛的應用。雖然這些信息可通過人工觀察的方式獲得,但這會十分耗時費力。行人屬性識別無須人工操作,只是將這些信息轉換成可以用于檢索的高級語義信息即可進行計算。如進行行人檢索時可基于屬性快速檢索感興趣的目標[1]。在真實場景中,有些監控攝像頭捕獲的行人圖像分辨率較低,而行人屬性憑借其對比度和光照不變性而具有較高的應用價值[2]。
在行人屬性識別中,不同類別屬性所屬的粒度不同,如發型、帽子、眼鏡、口罩等信息是圖像中行人的局部區域低層信息,而年齡、性別、朝向等信息則為全局的高層語義信息。針對細粒度的屬性(如眼鏡、裝飾),采用直接提取整幅圖像特征的方法無法有效識別這些屬性。因行人的屬性各不相同,識別時對網絡淺層或深層特征,局部或全局特征的需求也各不相同[3]。此外,在視角、光線等信息變化時,采樣到的圖像變化可能很大,但對這些屬性信息的判別結果不應該因受上述環境因素的影響而發生改變。從一張輸入圖像中提取不同尺度的特征完成對應屬性的判別及提升屬性判別的魯棒性,是行人屬性識別的難點所在。在很多的現實場景中,行人往往比較密集,攝像機角度和分辨率等都存有較大的差別。
在研究層面,目前行人屬性識別的研究大都是以單獨完整的行人圖片作為輸入,但是真實場景中的應用往往需要以原始圖片作為輸入,需要實現目標檢測和行人屬性識別算法的有機結合。此外,行人屬性總是表現出語義或視覺空間上的相關性或互斥性,但若是基于多標簽二分類屬性的輸出,因訓練數據集屬性不均衡等原因,有可能會導致不符合常識互斥屬性的出現,比如識別結果為同一個人既穿短褲又穿長褲。所以應采取有效措施避免不符合常識互斥屬性的出現,這將有助于提高檢測結果的準確性和合理性。
在國內外的研究中,隨著深度學習的發展,Li等[4]提出了多標簽屬性學習卷積神經網絡模型(DeepMar),通過卷積神經網絡(CNN)獲得更豐富的特征以代替手工特征,進而從一個網絡模型中同時識別出行人的多個屬性。Sudowe等[5]提出了屬性卷積網絡(ACN),將整個行人圖像作為模型輸入,聯合學習所有屬性的預測。這些方法都是利用網絡中的最后一個特征圖來完成屬性識別任務,不能提高屬性識別的準確率,原因是不同網絡層的特征反映了屬性不同的語義信息。如CNN模型需要從前幾層網絡中提取顏色或紋理等底層特征,這些特征對于衣服顏色和條紋的屬性非常重要,但對于性別、年齡這樣的語義屬性,高層網絡的特征比底層特征更有效[6,7]。為了應對多層次的屬性識別,通過CNN提取行人圖像的特征,構建特征金字塔網絡(FPN)。Li等針對行人屬性識別任務的特點設計了多尺度注意力網絡,采用基礎的殘差網絡ResNet50框架構建特征金字塔網絡(FPN),以融合底層特征和高層特征,并利用通道注意力機制提升特征通道之間的關聯性,以增強網絡的屬性識別能力。
在深度學習領域,目標檢測的實現通常是基于主流的卷積神經網絡構建用于提取特征的基礎網絡,而后在基礎網絡中預先選定的特征提取層后部,通過額外附加的卷積層進一步增加卷積圖的語義深度并調整其維度,使之匹配后面連接的檢測器的輸入要求,最終由檢測器實現對目標的分類和定位等功能。YOLO系列是當下非常流行的單階段實時目標檢測算法,其將目標檢測問題轉化為回歸問題,采用一個單獨的卷積神經網絡實現端到端的目標檢測,具有速度快、準確率高、適用性廣、可擴展性強等特點。Wang等[8]推出的YOLOv7模型針對模型結構重參化和動態標簽分配問題進行了優化,使模型的參數量和計算量大幅度減少,進一步提升了目標檢測性能。
1? 算法介紹
1.1? 行人屬性識別算法
采用基于弱監督多尺度注意力網絡的行人屬性識別算法,能夠融合網絡中不同層次的特征并自適應分配網絡權重,可以以端到端簡單易行的方式進行訓練,并可有效識別行人的各類屬性[2,9]。其以從ImageNet訓練的BN-Inception網絡作為基礎網絡,沿著自底向上的路徑以多個尺度從低層特征圖中提取細節信息,并沿著自頂向下的路徑從高層特征圖中提取語義信息,然后在網絡中添加橫向連接,使得高層的語義特征能夠與底層的細節特征進行融合構建特征金字塔,并通過通道注意力機制自主融合不同通道的特征,提升特征通道之間的關聯性。最后,采用屬性定位模塊將屬性與圖像中的具體區域進行關聯,將屬性標簽與圖像中相應的位置進行匹配和定位,以提供屬性的局部化信息。在對行人的各個屬性進行判斷和預測時,采用sigmoid函數將網絡的輸出映射到0到1之間,表示屬性存在的概率。
但行人屬性識別本身是個多標簽分類問題,若只是對屬性采用sigmoid函數以二分類的形式進行預測,有時會產生一些互斥屬性同時出現的現象,比如識別結果為同時出現短褲和長褲。為了避免互斥屬性的同時出現,將行人屬性分為上身、上身附屬、下身、下身附屬、腳部、朝向、性別、年齡、攜帶物9個類型,并將屬性歸類到9個類型中,如表1所示。通過對行人屬性進行sigmoid二分類,獲取每個屬性存在概率的分值Kij,如式(1)所示,并只保留分值Kij大于閾值αij的屬性。對于攜帶物這個類型中的屬性,允許多項屬性同時存在。而其余8個類型中的屬性,通過softmax函數對其余8個類型中的屬性重新獲得分值gij,如式(2)所示。最后通過argmax函數獲取每個類型存在概率最大值屬性的索引sij,并將該索引對應的屬性xij作為該類型唯一顯示的屬性,如式(3)所示。
其中,xij表示第i個類型的第j個屬性,kij表示屬性xij通過sigmoid獲得的分值,ni表示類型i中的屬性個數,kim表示類型i中每個屬性通過sigmoid獲得的分值,gij表示屬性xij在類型i中通過softmax獲得的分值,sij表示類型i中通過argmax篩選出來的屬性索引。
1.2? 算法結合
在研究層面,通常是目標檢測和行人屬性識別等算法分開單獨研究;而在工程應用層面,需要將目標檢測和行人屬性識別算法有機結合。完整的流程是以原始圖像作為輸入,通過目標檢測算法識別行人類型并獲取其位置坐標,然后將獲取的行人圖像信息傳入改進后的行人屬性識別算法,獲取行人的有效屬性并進行輸出,如圖1所示。
在YOLO系列中,預測的物體邊界框坐標(中心坐標和寬高)通常是相對于輸入圖像的歸一化坐標,取值范圍在[0,1]之間。為了實現進一步的處理,需要將這些歸一化坐標轉換為圖像像素坐標,如式(4)~(7)所示:
其中,xi和yi表示檢測目標i在圖像中歸一化的中心坐標,wi和hi表示歸一化的寬度和高度。wo和ho表示原始圖像的寬度和高度。xip和yip表示檢測目標的中心像素坐標,wip和hip表示檢測目標的寬度和高度。
為了便于獲取圖像中的行人圖像塊信息,將目標在圖像中的中心坐標和寬高轉換為目標左上角和右下角的坐標,如式(8)~(11)所示:
其中,xil和yil表示檢測目標i在圖像中左上角的像素坐標,xir和yir表示檢測目標i在圖像中右下角的像素坐標。
在原圖中獲取行人圖像塊信息的方法如式(12)所示。將行人圖像塊信息傳入行人屬性識別算法,以進行下一步的屬性識別。
其中,Io和Ii分別表示原始圖像像素信息和行人圖像塊信息。
2? 實驗結果
2.1? 實驗測試
服務器使用的是64位Centos 7系統,GPU為NVIDIA RTX 2080 Ti,內存為32 GB。編程語言為Python 3.8,模型訓練使用的深度學習框架為PyTorch。實驗采用的行人屬性數據集為PA-100K,包含由598個室外監控攝像頭采集到的100 000張行人圖像,每張圖像有26個屬性標注,圖像分辨率從50×100到758×454 [9,10]。隨機選擇80 000張圖像用于訓練,10 000張圖像用于驗證,10 000張圖像用于測試。
在行人屬性識別模型中,根據行人圖像的特點將輸入圖像的分辨率統一縮放至256×128,同時使用隨機水平鏡像和數據洗牌等數據增強方法進行行人屬性識別,網絡采用自適應運動估計算法(Adam)進行訓練。總共訓練了60個Epoch,batch-size為32,初始學習率為0.000 1,且每10個Epoch衰減0.1。參數衰減值(weight-decay)為0.000 5,動量因子(momentum)為0.9,模型參數量為1.4×107。
經過60個Epoch訓練,模型訓練結果如表2所示。在第60個Epoch時,當前批次的處理時長(time)為0.721 s,整個訓練過程的平均處理時長為0.769 s;當前批次的損失值(Loss)為0.015 6,整個訓練過程的平均損失值為0.021 4;當前批次的準確率(Accuracy)為1.000,整個訓練過程的平均準確率為1.000。損失值和準確率這兩個指標通常用于監控模型在訓練過程中的性能表現。損失值越低,準確率越高,代表模型的訓練效果越好。
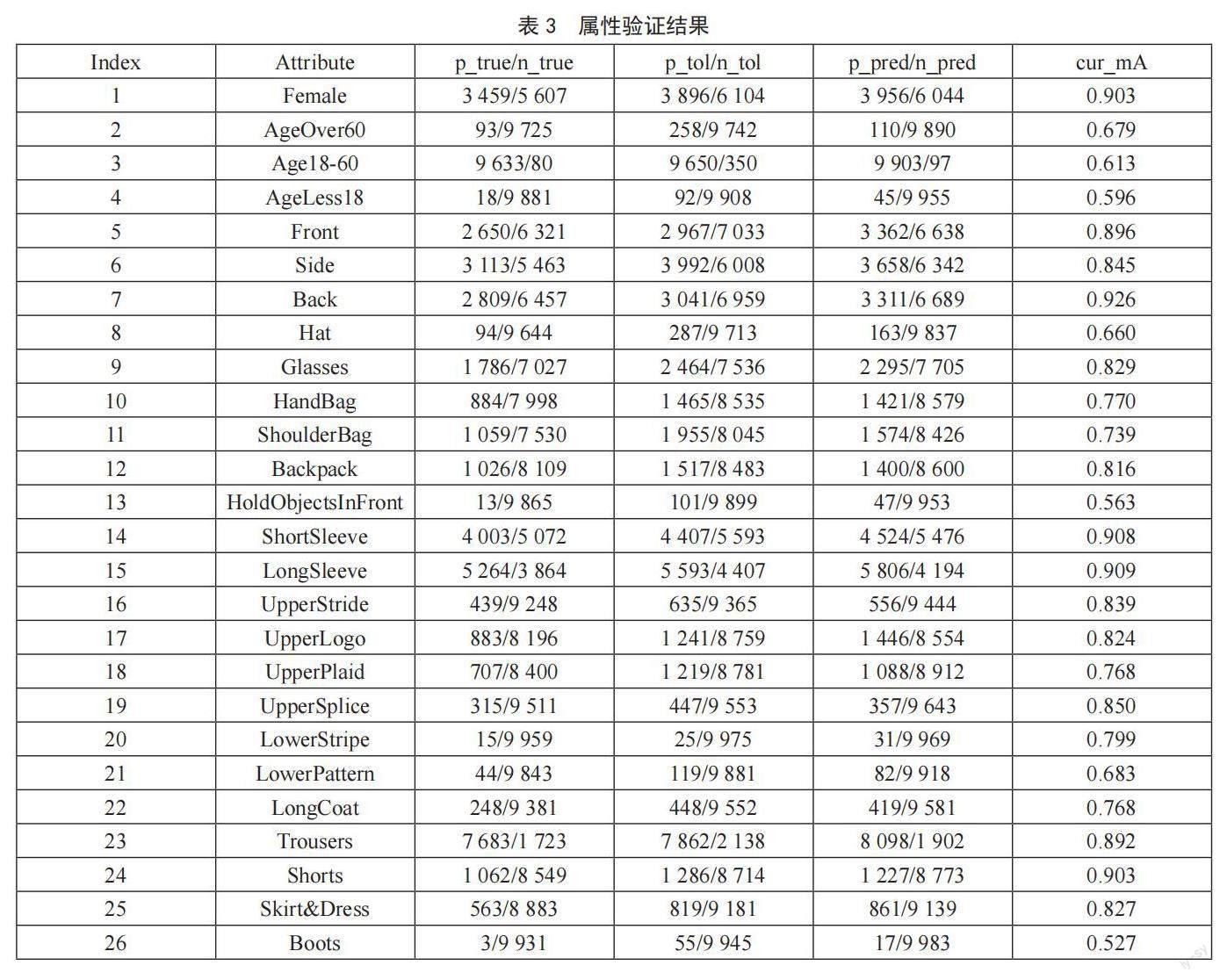
為了避免模型過度擬合訓練數據,在每個Epoch中對模型進行驗證。在第60個Epoch的驗證集中,26個屬性的驗證結果如表3所示。其中,p_true/n_true表示屬性在驗證集中為“真”的正樣本數/總正樣本數,p_tol/n_tol表示屬性在驗證集中為“真”或誤差容忍度范圍內的正樣本數/總正樣本數,p_pred/n_pred表示模型對屬性的預測結果中為“真”的正樣本數/總正樣本數,cur_mA表示當前的平均精度。
衡量行人屬性識別能力的指標通常為基于標簽的評價指標和基于實例的評價指標,前者主要是平均精度均值(mA),后者主要是準確率(Accuracy)、精確率(Precision)、召回率(Recall)和F1_Score[11,12]。其中,在評價屬性識別模型的性能時,主要看mA和F1。經過60個Epoch訓練,行人屬性識別算法的mA為0.782,F1為0.865,取得了較好的效果,如表4所示。
在第60個Epoch的測試集中,模型的準確率為0.939。對PA-100K測試集中行人屬性的預測效果進行可視化展示,如圖2所示。
而對于目標檢測,通常采用平均精度(AP)來評價。YOLOv7模型采用經過MS COCO數據集訓練的模型參數進行各種常見場景的類型檢測,其各項指標APtest/APval為51.4%/51.2%,AP50test為69.7%,AP100test為55.9%[8]。
2.2? 實例測試
真實場景中的行人行為更為復雜多變,以鐵路車站場景的圖片為例進行實例測試,在視頻截圖中可以看到遠近有多名不同性別的行人,其穿戴、朝向、攜帶物等均有差異,如圖3所示。
若僅讓該圖經過YOLOv7目標檢測算法的運算,可以有效識別出行人、火車、背包等各種類別,并可獲取其位置坐標,如圖4所示。
通過目標檢測算法在原圖中篩選出行人類型及其歸一化位置坐標,并將歸一化位置坐標轉換為像素位置坐標。若把每個檢測到的行人裁剪出來,可視化效果如圖5所示。
將每個行人的圖像塊信息傳入改進的行人屬性識別算法進行識別,能夠有效識別出行人的各項屬性(如性別、年齡、朝向、上衣、下衣、穿戴物以及攜帶物等),且沒有互斥屬性出現,如圖6所示。
在實際應用中,已經把目標檢測算法和改進的行人屬性識別算法進行了有機結合,所以輸入原圖可以直接獲得行人屬性識別的效果圖及其屬性識別信息,以便做進一步的處理和分析。
3? 結? 論
采用端到端多尺度特征融合的行人屬性識別算法,基于多層提取特征和自適應分配特征權重的框架,以端到端簡便易行的訓練方式,可以完全由屬性識別的總體標定結果驅動算法進行端到端的位置回歸和類別打分訓練迭代,從而自動獲得屬性識別結果。在此基礎上,將行人屬性分為9個類型進行篩選,實現對行人性別、年齡、朝向、帽子、上衣、下衣、鞋子,及其是否帶有眼鏡、背包等附屬物的自動檢測識別,并避免互斥屬性的同時出現,提高了屬性識別結果的準確性和合理性。
在行人屬性與目標檢測算法結合方面,采用模塊化的設計理念,通過目標檢測對圖像中不同尺度、位置的行人進行檢測。通過目標檢測獲取行人類型和位置信息,進而獲取行人圖像塊信息傳入改進的行人屬性識別模型,以獲得準確的屬性識別結果,可為行人在崗檢測等其他算法的研發應用提供基礎參考。
參考文獻:
[1] SU C,YANG F,ZHANG S L,et al. Multi-task learningwith low rank attribute embedding for multi-cameraperson re-identification [J].IEEE Transactions onPattern Analysis and Machine Intelligence,2018,40(5):1167-1181.
[2] 李娜,武陽陽,劉穎,等.基于多尺度注意力網絡的行人屬性識別算法 [J].激光與光電子學進展,2021,58(4):290-296.
[3] 馬騰飛.自適應特征匹配的行人識別技術研究及實現 [D].北京:中國科學院大學(中國科學院人工智能學院),2021.
[4] LI D W,CHEN X T,HUANG K Q. Multi-attributelearning for pedestrian attribute recognition in surveillance scenarios [C]//2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR). Kuala Lumpur:IEEE,2015:111-115.
[5] SUDOWE P,SPITZER H,LEIBE B. Person attribute recognition with a jointly-trained holistic CNN model [C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops. Santiago:IEEE,2015:87-95.
[6] 袁配配,張良.基于深度學習的行人屬性識別 [J].激光與光電子學進展,2020,57(6):61-67.
[7]林笑.基于人體子部件分割的行人多屬性識別模型研究 [D].北京:北京工業大學,2021.
[8] WANG C Y,BOCHKOVSKIY A,LIAO H M,et al. YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [J/OL].arXiv:2207.02696v1 [cs.CV].[2023-04-20].https://arxiv.org/abs/2207.02696.
[9] TANG C,SHENG L,ZHANG Z X,et al. Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul:IEEE,2019:4996-5005.
[10] SARFRAZ M S,SCHUMANN A,WANG Y,et al. Deep view-sensitive pedestrian attribute inference in an end-to-end model [J/OL].arXiv:1707.06089v1 [cs.CV].[2023-04-13].https://arxiv.org/abs/1707.06089v1.
[11] DENG Y B,LUO P,LOY C C,et al. Learning torecognize pedestrian attribute [J/OL].arXiv:1501.00901v2 [cs.CV].[2023-04-19].https://arxiv.org/pdf/1501.00901.pdf.
[12] ZHAO X,SANG L F,DING G G,et al. Groupingattribute recognition for pedestrian with jointrecurrent learning [C]//Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence.California:AAAI Press,2018:3177-3183.
作者簡介:武鑫森(1990—),男,漢族,河北滄州人,工程師,博士,研究方向:計算機視覺。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
