基于分割區域的配電網異常線損數據辨識與修正
2023-10-31 12:14:40張新鶴何桂雄梁琛馬喜平何振武姜飛
浙江電力 2023年10期
張新鶴,何桂雄,梁琛,馬喜平,何振武,姜飛
(1.中國電力科學研究院有限公司,北京 100192;2.國網甘肅省電力公司電力科學研究院,蘭州 730070;3.長沙理工大學 電氣與信息工程學院,長沙 410076)
0 引言
配電網在我國經濟建設中發揮著重要作用[1]。隨著社會經濟的發展,用電負荷增加,線損問題越來越受重視。在線損管理系統中,基礎數據冗余大,數據共享難度大,數據的一致性、完整性及有效性難以保證[2-4]。準確、快速地識別并修復異常線損數據,為制定合理的降損措施提供依據,是供電企業的重要任務[5-6]。
在異常線損數據辨識方面:文獻[7]考慮拓撲異常對線損率的影響,針對配電網兩種接線方式下的不同異常類型,提出拓撲異常辨識方法,但未考慮數據冗余和數據統計異常對線損率同期統計值的影響;文獻[8]針對數據噪聲對臺區線損數據造成的干擾,分析線損數據時域特征,提出電網臺區線損數據識別方法,但忽略了線損數據異常波動對拓撲異常的影響;文獻[9]提出一種利用改進k-最鄰近和多分類SVM(支持向量機)的循環迭代算法,實現缺失數據的變壓器故障診斷,但該方法只適用于缺失數據的修復,對于錯誤數據不具備辨識能力;文獻[10]考慮用戶動態用電行為的潛在規律性,結合時間序列分解和自相關分析,采用用電相似度判據實現對偽異常點的準確辨識,但欠缺對不同類別負荷用電特性的考量;文獻[11]采用灰色關聯分析篩選出最佳的電氣特征指標,利用自適應遺傳算法改進BP神經網絡對線損進行預測,具有較好的收斂性和準確性;文獻[12]基于相似性比較原則,提出運行狀態相似性評估方法,并通過確定型估計模型和組合概率估計模型對異常狀態進行檢測,但缺乏多組數據來驗證其普適性和實用性;文獻[13]利用用戶歷史用電量與線損電量的關聯關系,通過歸因分析法來識別臺區竊電用戶,但所提方法受信息完整度影響,不能用于檢測零電量竊電用戶。
在異常線損修復方面:文獻[14]提出將擴展卡爾曼濾波和限定記憶最小二乘法用于智能電表遠程估計校準,并根據線損率特征對異常估計值進行濾波;文獻[15]采用聯絡線分區解耦方式對互聯系統進行分布式狀態估計計算,實現了復雜電網的降維計算和子區域估計解耦,分區解耦方式能夠有效計算效率和修正精度;文獻[16]提出基于DAE(降噪自編碼器)和LSTM(長短期記憶)相結合的配電網日線損率預測模型,基于配電線路線損率短期變化趨勢預測日線損率,但時序特征指標的選取對預測的精準度影響較大,系統的魯棒性難以保證;文獻[17]提出一種基于高級量測體系全量測點分區的配電網動態狀態估計方法,并進行多尺度量測數據融合,實現數據快速修正,但實際線路量測狀態較為復雜,缺乏基于實測數據的模型驗證。
基于以上研究,為實現配電網線路異常線損數據的快速修復,本文提出基于分割區域的配電網異常線損數據辨識與修正技術。首先針對節點存在冗余數據的情況,提出采取基于卡爾曼濾波的數據融合技術進行數據預處理。分析線損異常原因,提出配電網線損異常數據識別方法和分割區域的劃分方法。基于分割區域鄰近節點量測數據和不平衡度指標,動態調整區域規模,得到“任意分割”最終劃分結果,并建立節點量測模型、約束模型和估計模型求解異常數據。通過西北某省10 kV什新線和什金線的實測數據進行算例分析,驗證所提基于分割區域的配電網異常線損數據辨識與修正技術的準確性。
1 線損數據異常節點定位
配電網線損數據異常的原因主要有兩種:一是電能表計量故障時,會導致系統采集電量數據缺失和異常,影響線損的計算結果;二是戶變關系錯誤導致某臺區檔案記錄其他臺區用戶的數據和臺區用戶檔案缺失,造成臺區高線損率或臺區負線損率。配電網中,變電站饋線出口,臺區配電變壓器(以下簡稱“配變”)和臺區用戶均裝有電能表,當線損異常時,逐一人工排查工作量大、效率低、周期長。因此,如何有效提高配電網線損管理中異常數據檢測效率成為電網公司的重要研究內容[18-23]。
1.1 功率-電量預處理
臺區配變的功率數據為96節點數據,為便于計算分析,需要對96節點功率數據進行預處理,得到日電量數據。以15 min為采樣間隔采集臺區配變的饋線出線功率數據,每條線路的節點電量E為:
式中:Pt為時刻t采集的功率數值;N為采樣點數,N=96。
1.2 長期高負損臺區配變剔除策略
為實現分割區域異常數據修復,首先需要對配電網線路異常配變進行辨識,但長期高負損配變臺區由于其高負損特性會導致算法的誤判和漏判,因此需剔除長期高負損配變臺區配變,再進行異常數據辨識及分割區域分割模型研究。
對于配電網線路臺區配變取其同期線損時間序列數據,并對比分析線損數據與人工制定標準區間,計算線損數據中異常線損的占比η,設定閾值分析,確定臺區是否長期處于高負損[24]。η的計算公式為:
式中:N2為時間序列中超出標準的線損數據個數;N1為采集的同期線損時間序列數據總個數。若η>5%,則判定為長期高負損臺區,并剔除該臺區配變[24]。
1.3 異常節點數據檢測
數據挖掘作為近幾年熱度較高的一種數據處理方法,能夠高效處理基數大且狀態復雜的數據[25]。為了快速檢測配電網中線損異常臺區配變,引入數據挖掘構建數學模型,檢測識別異常節點數據。采用LOF(局部異常因子)算法分析配電網10 kV線路節點電壓、有功功率、無功功率等數據,初步定位含有異常線損數據的節點。
分別設定節點r的電壓、有功功率、無功功率數據的時間序列數據集Ur(e)、Pr(e)、Qr(e),Ur(e)、Pr(e)、Qr(e)分別表示第r節點第e日的電壓數據、有功功率、無功功率。通過LOF算法給每個數據分配一個依賴于相鄰區域密度的離群因子的離群程度值,計算每個數據周圍數據點的平均密度與該數據密度的比值,通過LOF值來判斷數據點是否為異常數據[18,24]。以有功功率數據集Pr(e)為例,第e日有功功率數據的局部可達密度ρk(e)和LOF值Fk(e)計算公式為:
式中:Nk(e)為數據e的第k距離鄰域;dk(e,f)為第e日有功功率數據與第f日功率數據的歐式距離;v1(e)和v1(f)分別為第e日和第f日功率數據的編號;v2(e)和v2(f)分別為第e日和第f日的功率數據。第e日功率數據的ρk(e)越低,其LOF值越大。當第e日功率數據是離群數據時,則其ρk(e)小而其鄰域數據ρk(e)較大;若e為簇中數據,則數據e與鄰域數據的ρk(e)相差小,其LOF值接近1。因此,采用LOF算法可以消除簇間密度差異帶來的影響,通過判斷Fk(e)大小來確定數據是否離群。
2 分割區域的分割原則
為實現電網運行的在線監測及運維管理,電網公司通常會將現有電網分為若干子區域,實行分區治理,提高計算速度[26]。線損管理可細分為“四分”管理線損率,即分壓線損率、分區線損率、分元件線損率和分臺區線損率,中壓配電網的線損管理采取分線、分臺區管理。傳統基于“四分”管理的中壓配電網線路異常數據通過線路前推回代法和潮流計算得到,但臺區和終端采集數據量龐大,導致計算量較大且精度難以控制。為加強中壓配電網線路異常數據修復效率和精度,提出基于分割區域的估計模型修復異常數據的方法。
2.1 基于GN算法的節點分割
GN(Girvan-Newman)算法是一種經典的社區發現算法,最初由Michelle Girvant和Mark Newman提出。為實現分割區域內異常數據修復,需要先對異常節點分割區域,但由于每臺配變之間存在連接關系,不能直接通過是否相鄰來確定區域劃分的結果。為此,采用GN算法實現各異常節點初步分區,劃分為區域內耦合程度高、區域間耦合程度弱的區域。
GN算法首先需對臺區異常配變之間的連線進行刪除,該過程應保證先刪除區域之間的連線,后刪除區域內的連線[27]。其次,將所有目標配變節點初始化為各個獨立區域,再判斷各區域是否可合并成新區域,并將模塊度M作為分割區域合并過程的指標,若模塊度M增加則可行。最后多次迭代合并區域步驟,直到模塊度M達到最大,停止區域合并,得到區域劃分結果。
模塊度M的計算公式為:
式中:C為配電網絡分割區域;Si,j為分割區域內異常節點集合;ci和cj分別為異常節點i和j所屬的區域;δ(ci,cj)為0-1變量,若節點i和j屬于同個區域,則δ(ci,cj)取1,否則為0;ki為節點i的度,即與節點i相連的所有邊的權重之和;kij為連接節點i和j的邊權重;m為網絡中所有邊的權重之和。網絡模塊度M可以看作各區域的模塊度之和,M的取值范圍為(-1,1),其值越大,說明區域內連結越緊密。
模塊度M是評價區域劃分的指標,模塊度越大,區域劃分的效果越好。在計算模塊度時,需要節點間的連接權重數據kij,節點i和j相距越遠,邊權重越小。kij的計算公式為:
式中:Lij為節點i和j之間的距離;L1和L2為設定的線路距離閾值。
2.2 分割區域動態調整
由于節點數據異常與相鄰節點數據存在關聯關系,可結合線路拓撲關系調整區域規模,實現區域內正常節點數據對異常節點數據的修正。
2.2.1 分割區域動態調整策略
利用線路拓撲關系和基爾霍夫定律對異常數據進行判斷是比較可靠、精準度較高的方法。但直接結合電網拓撲關系和基爾霍夫定律的異常數據識別方法工作量巨大,只適用于樣本數據較少的情況,對于數據量較大的線損管理系統的異常數據辨識難度大、周期長[28]。
為了能夠結合線路拓撲關系實現對異常數據的辨識及修正,采用LOF算法初步識別篩選出異常節點并基于GN算法分割區域,分析各分割區域的拓撲信息,收集區域鄰近節點、線路的運行數據,判斷是否滿足異常節點數據修正條件,動態調整區域規模。
分割區域調整如圖1所示,存在包括異常節點5和3的分割區域,結合線路拓撲可判斷節點1、6、2、7的數據可修正節點5和3的異常數據。若節點6量測數據滿足節點5異常數據的修正條件,則擴大區域至節點6;若節點6量測數據缺失,不滿足對節點5數據的修正條件,繼續擴大區域至節點6的子節點1,通過節點1與節點6、節點6與節點5的關聯模型來修正節點5的異常數據。同理,對異常節點3可采取相同策略進行區域調整,直至滿足區域停止調整條件。在區域動態調整過程中存在某節點同時劃分到兩區域的情況,為滿足區域內部耦合較強、區域間耦合較弱的條件,將含有相同節點的區域融合。
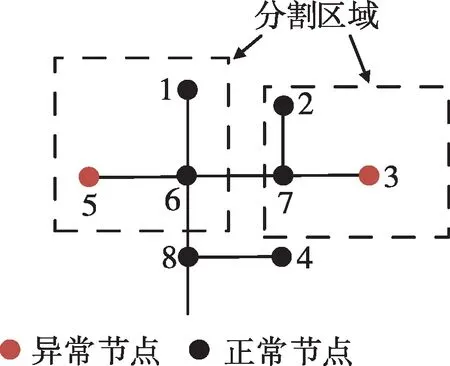
圖1 分割區域調整Fig.1 The segmented region adjustment
2.2.2 分割區域停止調整條件
通過GN算法實現了對異常節點的分割,為滿足分割區域內異常數據的自動修正,需要動態調整分割區域,將區域擴大至鄰近正常節點,通過鄰近正常節點數據和節點間關聯度模型校正異常節點數據。若區域內滿足實現異常數據修正計算的可觀性,則停止分割區域動態調整;反之,則充分考慮相鄰近節點數據的信息,擴大分割區域范圍,直至分割區域內異常數據可實現全部校驗計算。
為判斷區域分割結果是否滿足區域異常數據修正計算可觀性條件,設立復雜配電線路的配變異常節點分區模型中區域量測冗余不平衡度指標G[29]:
式中:b為區域個數;ηa為第a個分割區域的量測冗余度;ma為第a個分割區域的量測量個數;sa為第a個分割區域的狀態量個數。通過量測冗余不平衡度指標能有效判斷區域估計的可觀性和數據估計精度。該指標數據越小,表示分割區域量測冗余度不平衡度越低,各分割區域的估計數據與真值的偏差值越相近,分區越合理[30]。
3 分割區域異常數據辨識及修正模型
3.1 基于卡爾曼濾波的冗余數據融合
通過SCADA(數據采集與監視控制)系統和AMI(高級量測體系)采集的量測數據存在缺失、異常和冗余,為實現異常數據自動辨識,需要對缺失和冗余的數據進行預處理。缺失數據可采用數據填補的算法進行修正。要將實際的量測數據從含有噪聲、諧波的冗余電力信號中分離出來較為困難,因此采用基于卡爾曼濾波的數據融合技術對冗余數據進行預處理[31-33]。
卡爾曼濾波過程具體分為預測和校正兩部分,預測方程為:
式中:k表示當前時刻,k-1表示上一時刻;為k時刻先驗狀態量;為k-1時刻后驗狀態量;A為上一狀態到當前狀態的狀態轉移矩陣;B為控制輸入到當前狀態的狀態轉移矩陣;uk為控制輸入矩陣;為先驗估計誤差協方差矩陣;Pk-1為后驗估計誤差協方差矩陣;Q為過程噪聲協方差矩陣。
校正方程為:
式中:Kk為卡爾曼增益矩陣;H為量測矩陣;R為量測噪聲協方差矩陣;zk為k時刻量測量;I為單位矩陣。
通過卡爾曼濾波可以得到當前時刻系統所需的估計值,該估計值存入系統數據庫中,并通過該數據預測下一時刻的狀態量。
3.2 分割區域異常數據修正
基于區域內正常節點與異常節點的關聯度模型和量測模型,通過區域間的分支線路前推回代對各區域異常數據進行計算修正,可有效提升修正精度和速度。
1)量測方程。通過對異常節點定位和分割,將完整的10 kV線路和線路節點分解為S個區域,用Sλ表示第λ個區域的節點集合,用I表示分割區域的內部節點集合。
若分割區域Sλ內節點r存在鄰近節點(jj=1,2,…,β,j∈I),其功率平衡關系可表示為:
式中:Pr和Qr分別為節點r注入的有功功率和無功功率;Ur和Uj分別為節點r和j的電壓幅值;δrj為節點r和j之間的相位差;Grj和Brj分別為節點r和j間線路的導納實部和虛部。
化簡式(12),可得到節點之間的電壓數據量測模型,通過區域內正常節點修正區域內異常節點,節點r存在β個鄰近節點,則節點r的電壓Ur可表示為:
式中:Prj為節點r和j之間線路的有功功率;Irj為節點r和j之間線路的電流。
2)等式約束。分割網絡內異常節點負荷功率應滿足如下的潮流方程[34]:
式中:Ω為節點r連接的節點集合;PDGr和QDGr分別為節點r的分布式電源系統輸出的有功功率和無功功率,若節點無分布式電源接入,則PDGr=0,QDGr=0;PDr和QDr分別為節點r的有功負荷和無功負荷。
3)估計模型。估計模型是提升量測量和狀態量接近程度的優化過程,基于加權最小二乘法的優化目標[35]為:
式中:x為節點r的狀態量;ξ為分割區域內節點個數;Rr為網絡分割后各區域協方差對角矩陣;Zr為分割后各區域量測量向量;Xr為網絡分割后各區域的狀態量向量;hr(Xr)為網絡分割后各區域量測模型;cr(x)為網絡分割后各區域的等式約束條件;gr(x)為網絡分割后各區域的不等式約束條件。
3.3 分割區域異常數據辨識及修正策略
圖2為分割區域數據辨識及修正流程。首先采用卡爾曼濾波算法對終端冗余數據進行融合,再通過LOF算法確定存在異常線損數據的節點配變;通過判斷區域鄰近節點的數據信息及區域不平衡度指標,動態調整區域邊界,直至全部鄰近節點滿足校驗計算,得到分割區域;最后建立區域內節點量測模型、約束模型和估計模型,通過區域內正常數據修復區域內異常數據。
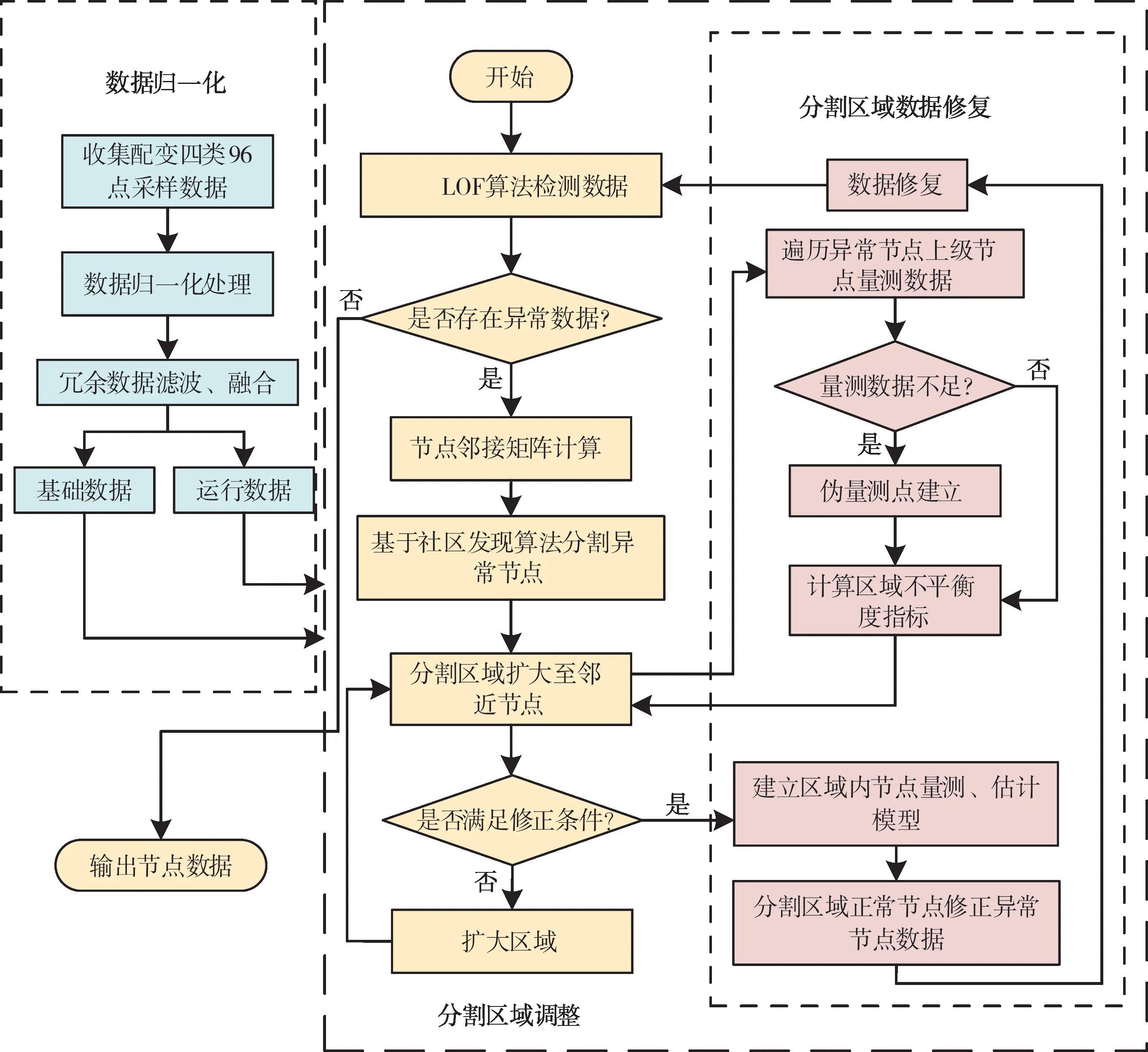
圖2 分割區域數據辨識及修正流程Fig.2 Data identification and correction process in the segmented region
所提分割區域異常線損檢測修復方法具有內部耦合程度高、外部耦合程度弱、異常線損數據檢測精度高等特點。該方法不僅有利于線損管理,還提高了配電網異常線損修正效率。
4 算例分析
為驗證本文所提方法的有效性,以西北某省10 kV什新線和什金線為算例進行分析。如圖3所示:什新線由35 kV什新站饋線接出,取其中19臺配變(編號1—19);10 kV什金線由35 kV什新站接出,取其中17臺配變(編號20—36)。
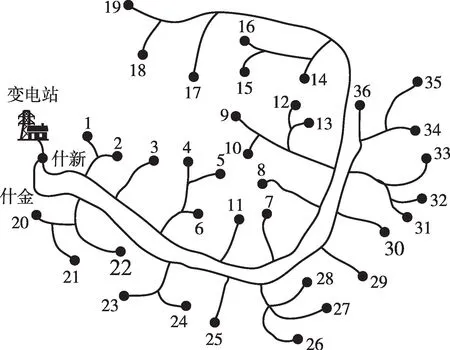
圖3 10 kV什新線、什金線拓撲Fig.3 Topology of 10 kV Shixin line and Shijin line
10 kV線路中存在大型光伏電站接入的情況,光伏電站數據波動對線路線損值影響大。為驗證分割區域劃分模型的有效性,本文所采用的分布式電源數據均為正常值,且在分割區域劃分時不包括光伏電站,單獨分析光伏電站運行數據。
在異常數據辨識和分割區域劃分前,采用卡爾曼濾波算法對存在多組量測值、信號噪聲較大的趙家陽山配變對量測值進行濾波和融合。
趙家陽山配變96點采樣數據測量值和濾波值如圖4所示,相對誤差如圖5所示。功率量測值1、量測值2經卡爾曼濾波后,去除了多余噪聲,并對多組量測數據進行了融合,得到的濾波值與真實值曲線相似度更高。量測值1的平均相對誤差為0.535,量測值2的平均相對誤差為0.922,濾波值的平均相對誤差為0.391,濾波值與真實值之間的相對誤差明顯減小。綜上,卡爾曼濾波算法可有效將實際的量測數據從含有噪聲、諧波的復雜電力信號中分離出來,減小其與真實值的相對誤差。
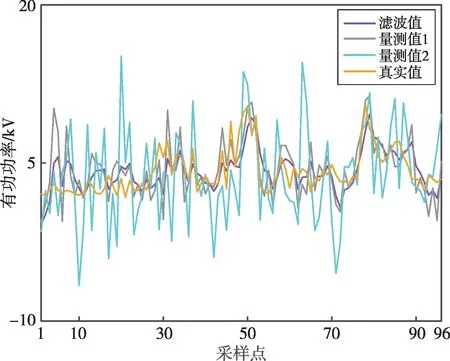
圖4 趙家陽山配變96點數據濾波圖Fig.4 Filter diagram of the data at sampling point 96 of distribution transformer at Zhaojiayangshan
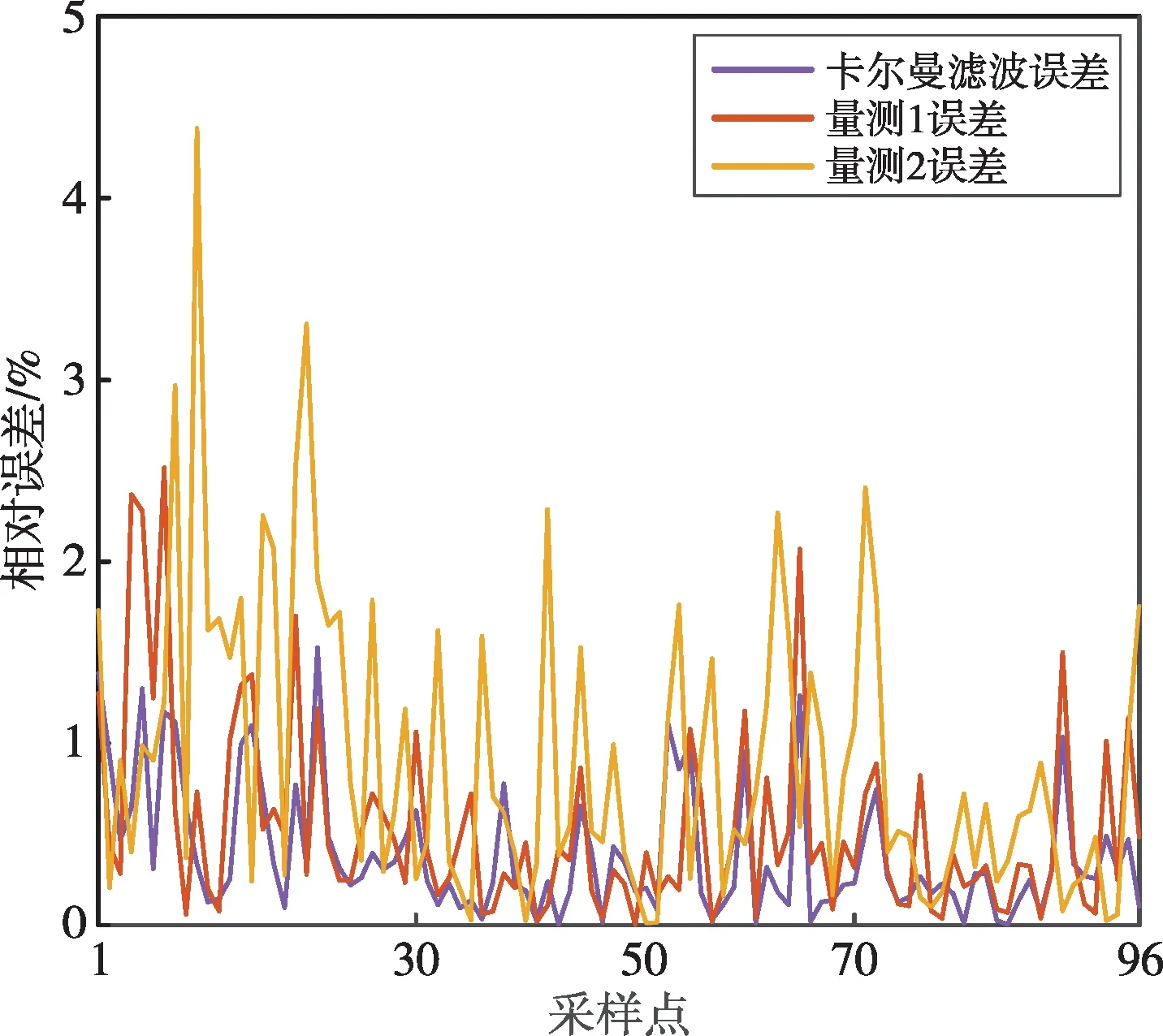
圖5 卡爾曼濾波前后相對誤差圖Fig.5 Diagram of relative errors before and after Kalman filtering
對10 kV什新線和什金線各節點配變臺區饋線出口2022年4月9日采集的電量、有功功率和無功功率數據進行預處理,并采用LOF算法進行檢測,選取閾值為1.8,結果如圖6所示。
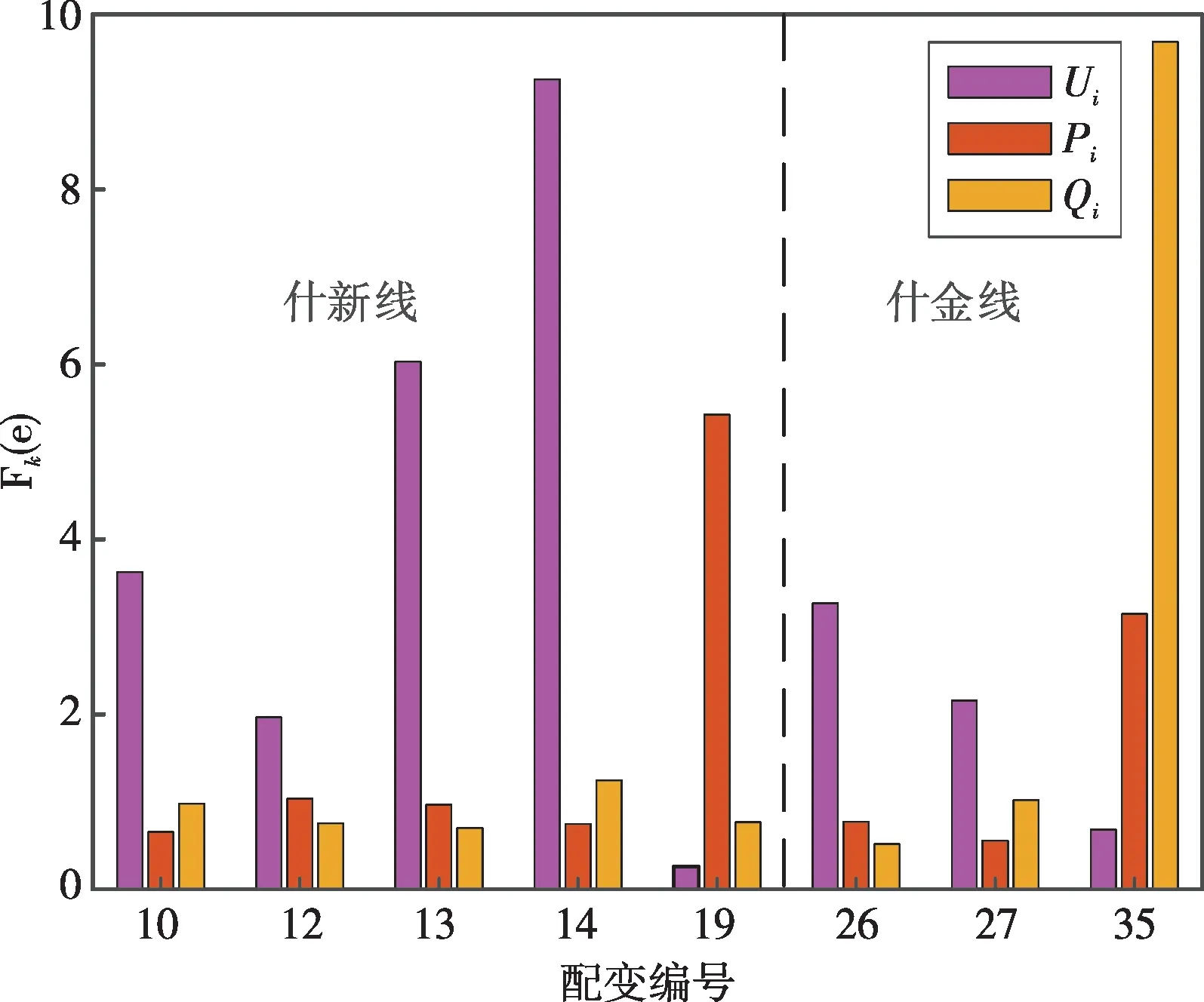
圖6 線損數據LOF值Fig.6 LOF values of line loss data
從圖6中看出:2022年4月9日什新線異常電壓數據的配變節點為10、12、13、14,異常有功功率的配變節點為19,其中13、14、19的LOF值較高,離群程度較大;什金線異常電壓數據的配變節點為26和27,異常無功功率、有功功率的配變節點為35,其中35的LOF值較大,離群程度較大。
采用GN算法計算,通過確定合適的連接閾值來建立節點連線,得到劃分結果如圖7所示。結果表明,什新線中配變節點10、12、13劃分為同一區域,26和27劃分為同一區域,19和35各自單獨劃分為一個區域。
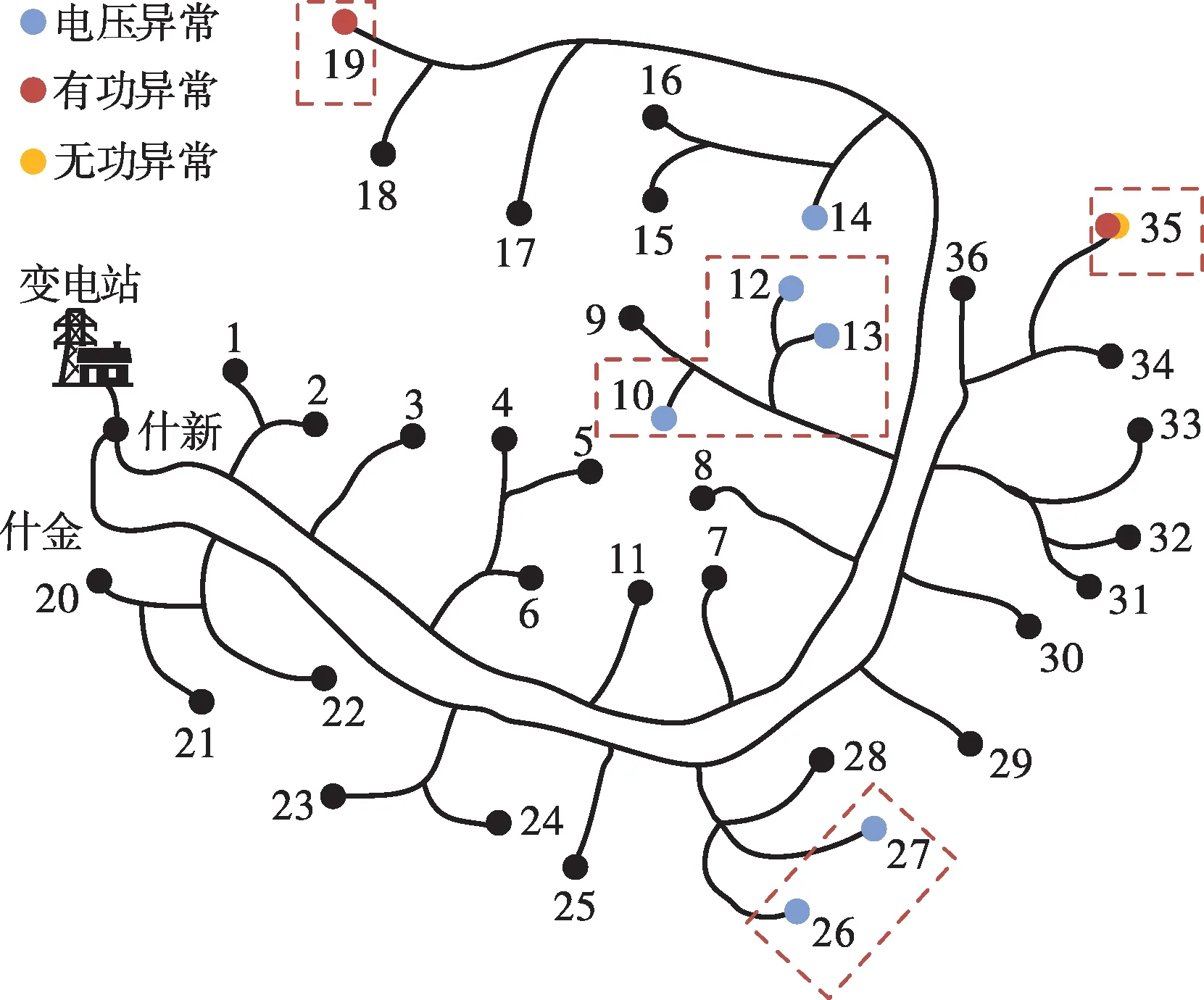
圖7 異常配變劃分結果Fig.7 Segmentation results of anomalous distribution transformers
基于分割區域調整策略擴大、融合區域,在區域動態調整中,通過計算區域量測冗余不平衡度指標,得到最優分區方案,如圖8所示。此時,不平衡度指標G=2,若分割區域繼續擴大,不平衡度指標G會增大,在G=2時目標函數最小,此時的分區方案為最優分區方案。圖8中配變節點9、10、12、13劃分為同一區域,26、27、28劃分為同一區域,19和18劃分為同一區域,34和35劃分為同一區域。
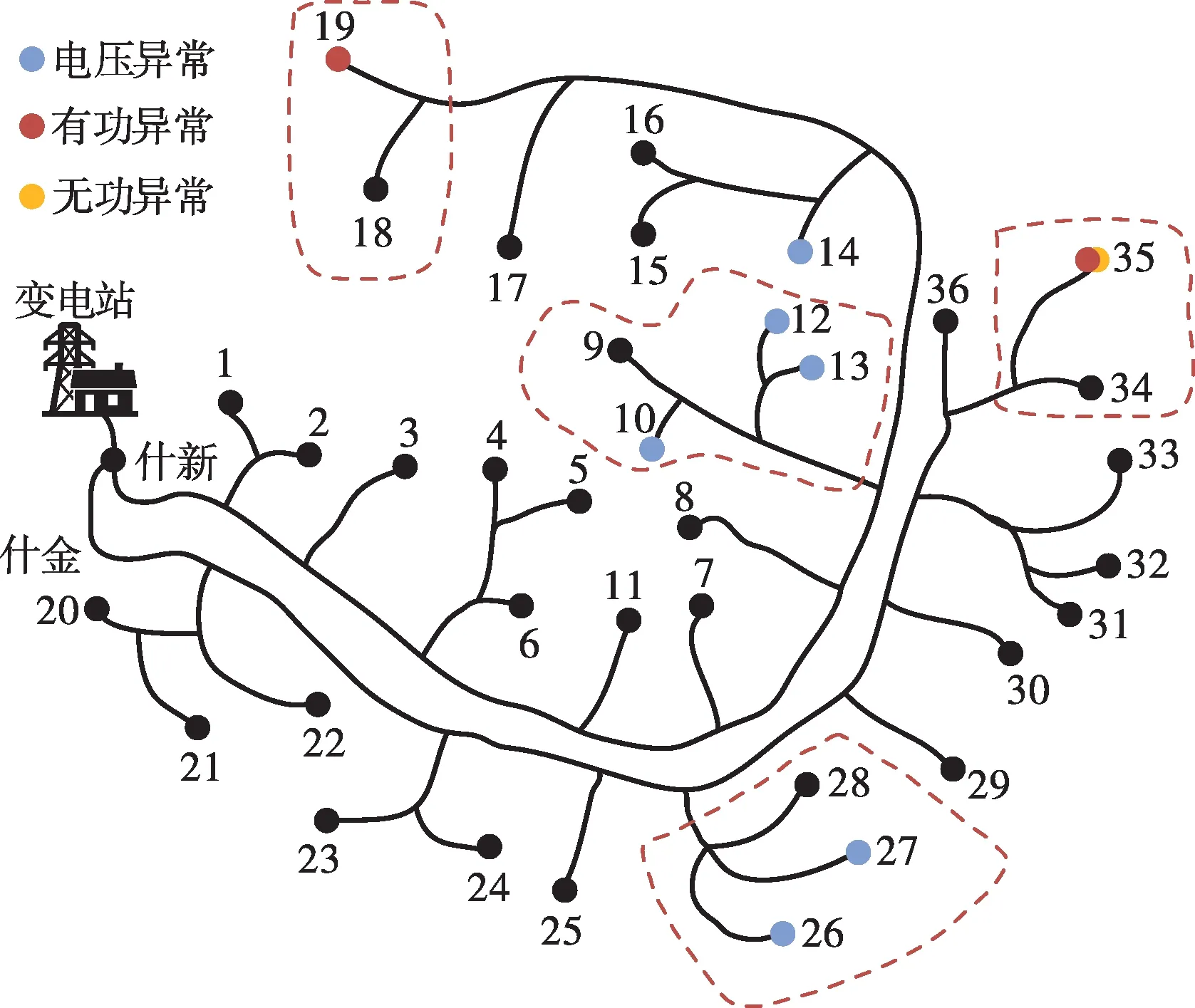
圖8 分割區域最終劃分結果Fig.8 The final division results of the segmented regions
選取什新線節點19和什金線節點35的A相有功功率的估計值和真實值進行對比分析,如圖9所示。圖9(a)中有功功率數據估計值和量測值的96點平均絕對誤差為0.242 kW。圖9(b)中有功功率數據估計值和量測值的96點平均絕對誤差為0.014 kW。綜上,基于分割區域的異常數據修正具有較高的精度。
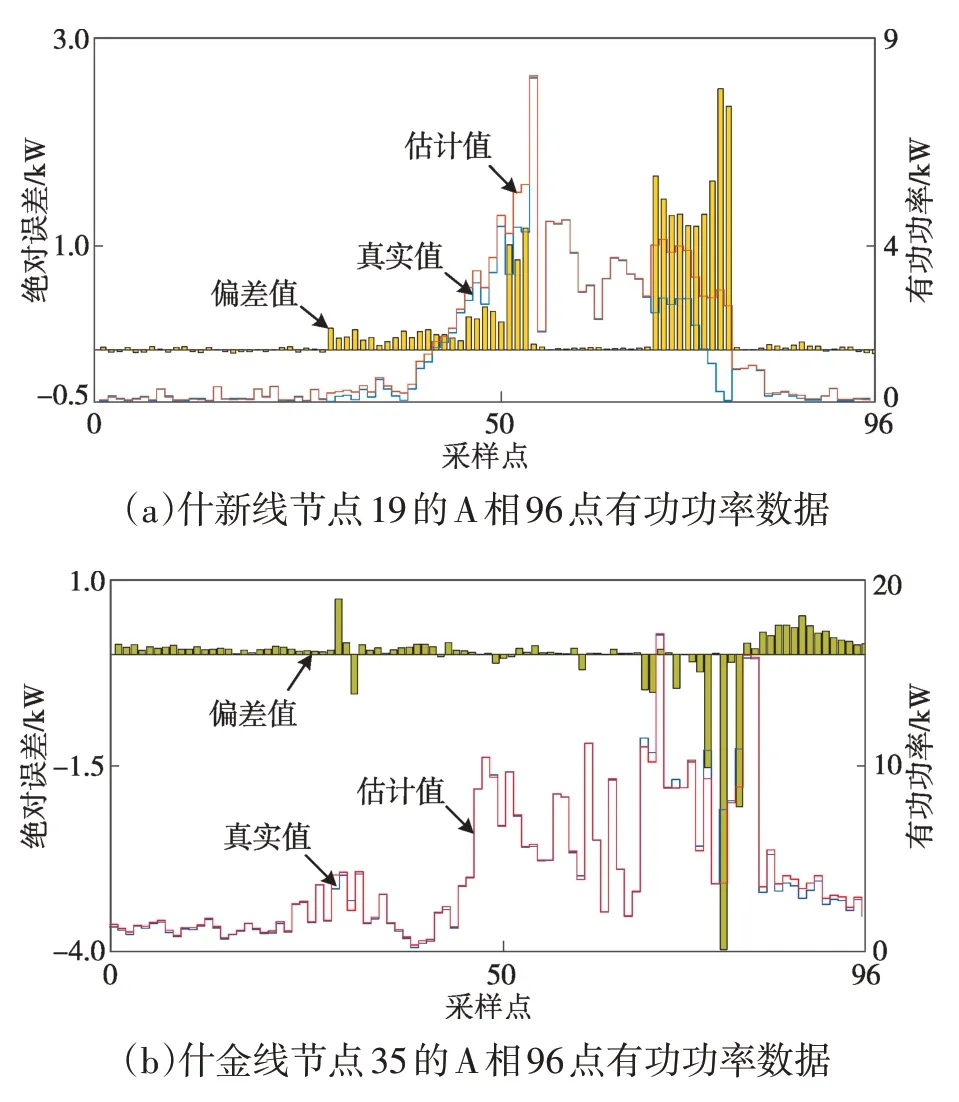
圖9 A相96點有功功率數據Fig.9 The active power data at sampling point 96 on phase A
收集10組異常有功功率數據,分別采用分割區域估計和LSTM算法進行修正,修正結果與真實值比較并求誤差值,修正結果如圖10所示。根據圖10可知,其中2組數據LSTM算法誤差明顯較小,6組數據分割區域估計算法誤差明顯較小,2組數據兩種方法誤差接近。

圖10 異常數據修正結果誤差對比Fig.10 Comparison of errors of the corrected anomalous data
統計分割區域估計算法與LSTM算法修正時間和RMSE(均方根誤差),其中LSTM算法修正時間包括訓練時間和預測時間,結果如表1所示。和LSTM算法相比,分割區域估計算法平均估計時間降低了40%,RMSE降低了23.7%。綜上,分割區域估計算法能有效提高估計精度并減少時間成本。

表1 兩種方法的修正時間和精度對比Table 1 Comparison of the correction time and accuracy of the two methods
5 結語
本文提出基于分割區域的配電網異常線損數據辨識與修正技術,并將其應用于西北某省10 kV什新線、什金線進行驗證,得到以下結論:
1)由于配電網中臺區配變數量大、分布廣,配變數據修正工作量大且檢驗周期長。依托配電網實時檢測平臺采集的大量基礎數據,剔除長期高負損臺區配變,并采用LOF算法對運行數據進行辨識,初步定位異常節點配變,能有效避免長期高負損臺變對LOF算法異常數據辨識的影響,提高異常數據識別效率。
2)分割后各區域異常數據類型特征明顯,區域間耦合關系弱,有利于實現異常數據的快速修正。通過卡爾曼濾波對終端冗余線損數據進行預處理,基于線路節點量測模型、等式約束和估計模型對分割區域失真數據進行修正,能在獲得較高精度的同時減少時間成本。
3)所提方法中所需基礎數據和指標均充分考慮數據獲取難度和對臺區線損率的貢獻度等因素,模型具有一定的實用性和可操作性,可強化線損精細化管理,提升經營效益。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
電測與儀表(2016年5期)2016-04-22 01:14:14
小學生導刊(2016年34期)2016-04-11 00:49:44
河南電力(2016年5期)2016-02-06 02:11:24
電測與儀表(2015年5期)2015-04-09 11:30:52
