基于代價敏感的細粒度服裝圖片檢索
2023-10-31 11:40:02鄒子安何儒漢
軟件導刊 2023年10期
關鍵詞:模型
鄒子安,何儒漢
(1.武漢紡織大學 計算機與人工智能學院;2.紡織服裝智能化湖北省工程研究中心,湖北 武漢 430200)
0 引言
隨著人們需求的進一步精細化,圖片檢索技術逐漸向細粒度方向深入發展。細粒度服裝圖片檢索主要通過對圖像的相似度進行比較實現[1-4],該類方法在服裝圖片像素層面構建檢索模型提取全局或局部特征進行相似度的排序比較。然而,細粒度服裝圖片檢索中廣泛存在類別不平衡問題,即當部分類別數量遠高于其他類別數量時,在學習過程中通常會導入有利于數量占比多類別的分布偏差,導致數量少類別的條件概率被低估,從而影響分類和檢索結果。
由于相同類別服裝圖片之間高度相似,以及部分服裝圖片數據集存在類別不平衡現象,面向服裝圖像的細粒度檢索是一個具有挑戰性的課題。對于非平衡問題,目前算法層面的解決方案主要是優化損失函數。該領域最常使用的損失函數為交叉熵(Cross Entropy,CE)損失函數。經典的交叉熵損失函數對每個數據實例具有同等的重要性,這導致網絡對較少數量的類別缺少優化監督。因此,在類別不平衡情況下的分類、分割和檢索等任務中,CE 損失函數是不適用的。另一種簡單固定權重交叉熵(weighted CE)損失函數被廣泛用于類別不平衡時的檢索任務,其設置類權重與類頻率成反比[5-6],然而這種策略在大規模真實數據集中存在困難樣本時性能很差。Focal 損失函數采用動態策略分配類的權重,重點關注難以訓練的實例,但如果某個樣本標注錯誤,會導致模型訓練效果越來越差[7]。
針對細粒度服裝圖像檢索任務中存在的不平衡數據集問題,本文提出基于代價敏感的細粒度服裝圖片檢索模型。該模型通過聯合預測服裝屬性和關鍵點學習服裝特征,采用基于代價敏感的損失函數處理細粒度服裝類數據集的不平衡問題,對模型中的關鍵點檢測模塊進行改進,提升模型提取特征的性能。為證明該模型的有效性,在DeepFashion 數據集上進行實驗,與文獻[2,8]中的細粒度圖片檢索方法進行比較,與文獻[9]中的方法進行服裝類別、屬性識別性能比較。
1 相關研究
1.1 細粒度圖像檢索
在計算機視覺中,細粒度圖像檢索比基于內容的圖像檢索更為困難,這是由于類別之間的差異較大,但同一類別內的差異很小。目前關于細粒度圖像檢索技術的研究有很多,例如Sathit[8]提出基于自適應深度學習的細粒度文化遺產圖像檢索方法,該模型可以處理新類別的增量流,同時保持其過去在舊類別中的性能,不丟失文化遺產圖像的舊分類。該方法的目標是執行類別檢索任務,同時對新類別進行增量學習以減少重新訓練的過程;Liu 等[9]通過聯合預測服裝屬性和關鍵點學習服裝特征來進行服裝分類和檢索;Zeng 等[10]采用分段交叉熵損失函數增強模型的泛化能力并提高檢索性能;Xu 等[11]提出一個視覺—語義嵌入模型,該模型使用知識庫和文本研究語義嵌入;然后訓練一個端到端卷積神經網絡框架,將圖片線性地映射到豐富的語義嵌入空間中;Liu 等[12]提出一種基于圖嵌入的方法學習圖像與場景草圖之間的相似性度量,該方法對多模態信息(包括對象的大小、外觀以及布局信息)進行建模,在細粒度圖像檢索中有應用潛力;Zhang 等[13]提出一種自動細粒度識別方法,通過匯集深度卷積核空間響應向量并加權組合,從而使訓練和測試階段均不需要任何對象/部件注釋;Xie 等[14]引入一個基線系統,使用細粒度的分類分數表示和共享索引圖像,將語義屬性更好地納入在線查詢階段,并在合理的時間和內存消耗下獲得了良好的搜索結果;Kumar 等[15]提出一種基于卷積神經網絡的內容細粒度圖像檢索框架;Cui 等[16]提出一個端到端可訓練網絡ExchNet,基于注意力機制和注意力約束分別獲得局部和全局特征,并為細粒度圖像生成緊湊的二進制代碼以改善查詢速度慢和冗余存儲成本問題;Wang 等[17]提出一種三向增強的部分感知網絡,該網絡在中層特征空間后加入一個混合的高階注意力模塊,以生成各種高階注意力圖,捕捉中層卷積層中包含的豐富特征。雖然以上研究在細粒度服裝圖像檢索方面取得了一定進展,但在處理數據集類別不平衡問題時仍存在困難。
1.2 數據層面非平衡學習
數據層面的非平衡學習方法采用重新取樣策略改變原始數據中的類分布,以達到平衡數據集的目的[18-20]。最簡單的重抽樣形式包括隨機過量取樣和隨機欠量取樣,前者處理類的不平衡是通過重復少數類中的實例實現的,而后者是隨機從多數類中刪除實例,以便與少數類的數量相匹配。研究表明,數據抽樣策略對分類性能影響不大[19]。雖然抽樣策略被廣泛采用,但這些方法操縱了給定領域的原始類表示,并引入了一些缺點,例如過度采樣有可能會導致過度擬合并加重計算負擔,而欠抽樣則可能消除對歸納過程至關重要的信息。此外,采用抽樣方法人為地平衡數據可能不適用于具有很大差異的數據集[20]。
1.3 算法層面非平衡學習
算法層面的非平衡學習方法可分為集合方法和對成本敏感的方法兩類[21-22]。例如,Liu 等[23]提出一種成本敏感的變分自動編碼分類器,通過引入成本敏感因素將高成本分配給少數群體數據的錯誤分類,從而使分類器偏向少數群體數據以解決不平衡數據分類問題;Wang 等[24]提出一種基于信息熵的兩類成本敏感矩陣化分類模型,將信息熵引入到矩陣化學習框架中以降低錯誤分類成本;An等[25]提出一個基于深度學習的模型,通過強化學習代理指導成本敏感的特征獲取過程,以自適應地為每個實例選擇信息豐富且成本較低的特征;Aram 等[26]引入一種基于支持向量機的濾波方法,通過選取模型對二次最大邊緣特征進行線性化,提高了支持向量機特征選擇的泛化能力,使其適用于各種代價錯誤情況;Losifidis 等[27]針對不平衡數據提出一種成本敏感的提升模型AdaCC,在提升過程中根據模型表現動態地調整錯誤分類成本,而不是使用固定的錯誤分類成本矩陣。
以上研究主要通過引入深度神經網絡模型、修改損失函數或修改原始數據集的方式處理數據不平衡問題。本文在參考以上研究成果的基礎上引入聯合預測服裝屬性與關鍵點的深度網絡模型,通過代價敏感損失函數處理服裝類別、屬性不平衡等問題。主要創新點為:①與固定權重相比,所提出的代價敏感損失函數既采用固定的權重方案,又根據數據實例的預測難度自適應增加動態權重;②動態權重對實例的錯誤預測結果進行懲罰,提高困難樣本的參數優化程度;③優化了服裝關鍵檢測模塊,使得模型保留了特征的空間對應關系,提升了服裝特征提取性能。
2 檢索模型構建
誤差的反向傳播算法通常用于訓練神經網絡,其根據訓練過程中產生的誤差更新模型權重,來自每個類的數據實例錯誤分類具有相同的重要性。本文基于該算法建立基于代價敏感的細粒度服裝圖片檢索模型。
2.1 細粒度服裝圖片檢索模型結構
細粒度服裝圖片檢索模型依靠大量圖片和細粒度標簽等數據進行訓練,通過損失函數誤差反向傳播優化模型參數以學習圖片包含的細粒度服裝屬性。然而,細粒度服裝圖片數據集中的類別不平衡對訓練模型性能有很大影響。數據集類別不平衡的解決方法有數據層面和算法層面兩種,由于本文數據集類別分布過于極端,圖片屬性存在各種復雜的包含關系,采用數據集重組方法存在過擬合和加重計算負擔等缺點,不適合使用數據層面的方法。因此,本文設計了算法層面基于代價敏感的方法解決數據集類別不平衡問題。
聯合預測服裝屬性與關鍵點的細粒度服裝圖片檢索模型結構如圖1 所示。該模型將關鍵點坐標變為熱圖的形式,不破壞卷積網絡與標簽的對應空間關系,有利于服裝特征提取。該模型由4 個部分組成:①主干網絡模塊。用于提取28×28×512 維度的圖片特征;②服裝關鍵點檢測模塊。通過Roi-pooling 層切割圖片關鍵點位置特征,組合成4×4×4 096 維度的卷積層;③服裝類別、屬性分類模塊。服裝類別分類模塊通過下采樣卷積壓縮主干網絡的圖片特征維度至7×7×512,通過全連接分類網絡區分服裝的類別信息;服裝屬性分類模塊壓縮第②部分網絡輸出信息,通過全連接屬性分類網絡識別出服裝屬性;④服裝圖片檢索模塊。該模塊通過深度網絡模型輸出的特征信息建立特征索引庫,實現服裝的檢索查詢。
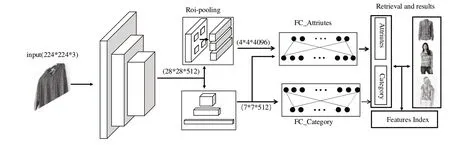
Fig.1 Fine-grained apparel image retrieval model structure圖1 細粒度服裝圖片檢索模型結構
2.2 代價敏感學習
分類損失函數設定包含n 個樣本的數據集表示為D=,其中X?表示圖片的特征空間域,Y?表示標簽的空間域。對于每個數據實例i,xi?X為輸入特征向量,yi?Y={1,2,...,c}為真實的類標 簽。分類器的訓練參數表示為F:=,其將輸入的特征向量映射到標簽空間向量f :X→Y,并通過最小化損失函數學習L(f(x;θ),y)。定義1 個損失函數L:R×Y→R+和1 個分類器F,模型誤差均值被定義為RL(f)=ED[f (x;θ),y],其中期望值與數據集D有關。
模型的細粒度屬性為多標簽性分類,其最后一層為sigmoid激活函數,那么細粒度屬性損失函數的平均誤差可表示為:
式中:θ 為模型的參數集,yij為實例xi的編碼標簽中第j個元素,yi=∈{0,1}c;fj(x;θ)∈Rc為模型輸出,fj為f的第j個元素。
代價敏感損失函數在原分類損失函數的基礎上引入一個代價矩陣的加權分類目標函數,為少數類和難以訓練的實例分配更高權值,表示為:
式中:cost(fj(xi:θ),yij)用于計算模型輸出fj(xi:θ)與真實標簽yij對應的代價權重wij。將代價權重wij作為一個超參數來處理,設置其與該類出現的類頻率成反比,其所有的值表示為一個代價矩陣。
令pj=fj(xi:θ),則代價矩陣定義為:
式中:py表示數據集中真實標簽yij的頻率。
代價權重既有數據集樣本類別不平衡的權重w1=(1-py),又增加了模型預測錯誤的懲罰項其中因此,代價權重函數可簡化為wij=w1+w2,其中w1的特點為數據樣本越小,其權重越大;w2表示模型輸出結果在向量中與正確標簽的距離,作用為控制困難樣本的權重。該代價損失函數有兩個優點:①當一個訓練實例被錯誤分類時,懲罰項w2能起到修正作用;②當一個訓練實例所屬類的數量占比很低時,權重w1能減小其帶來的負面影響。
3 實驗方法與結果分析
3.1 實驗設置
在最新DeepFashion 數據集中選取209 222 個樣本用于訓練,4 萬個樣本用于驗證,4 萬個樣本用于測試。數據集中服裝圖片的類別標簽有50 種,細粒度屬性標簽有1 000種。
進行以下比較實驗:①以使用損失函數(1)為基線;②使用代價敏感損失函數,僅使用平衡加權項w1;③使用代價敏感損失函數,僅使用錯誤懲罰項w2;④使用代價敏感損失函數,采用平衡加權項w1和錯誤懲罰項w2。
3.2 實驗評價
采用3 種指標評估模型性能,分別為:①精度(Precision,Pr)。表示正確預測的正例占所有預測為正例的比例;②召回率(Recall,Re)。表示預測屬于某類,且真正屬于該類的比例;③F1-分數(F1-score)。其為精確和召回率的加權調和平均值。將指定的類j定義為一個正實例,所有其他類定義為負實例,則指定類標簽j的性能指標分別表示為:
式中:TP表示正樣本且預測正確,TN表示負樣本且預測正確,FP表示負樣本但預測為正樣本,FN表示正樣本但預測為負樣本。
3.3 代價敏感損失函數的消融實驗
細粒度服裝共有50 類。如圖2 所示,各類別分布非常不平衡,圖片數量為10 000 張以上的類別有6 個,由少到多分別為第33、17、32、3、18、41 類,其中第41 類圖片有5萬多張;有15 個類別的圖片數量為1 000-10 000 等級;有14 個類別的圖片數量為100-1 000 等級;有15 個類別的圖片數量為0-100 等級。細粒度服裝圖片屬性有1 000 個,而且一個圖片可以有多個細粒度屬性。由于數據集類別不平衡,細粒度的屬性也分布極不平衡。此外,細粒度屬性數量比服裝類別數量更多且為多標簽,因此細粒度服裝屬性的檢索更加困難。
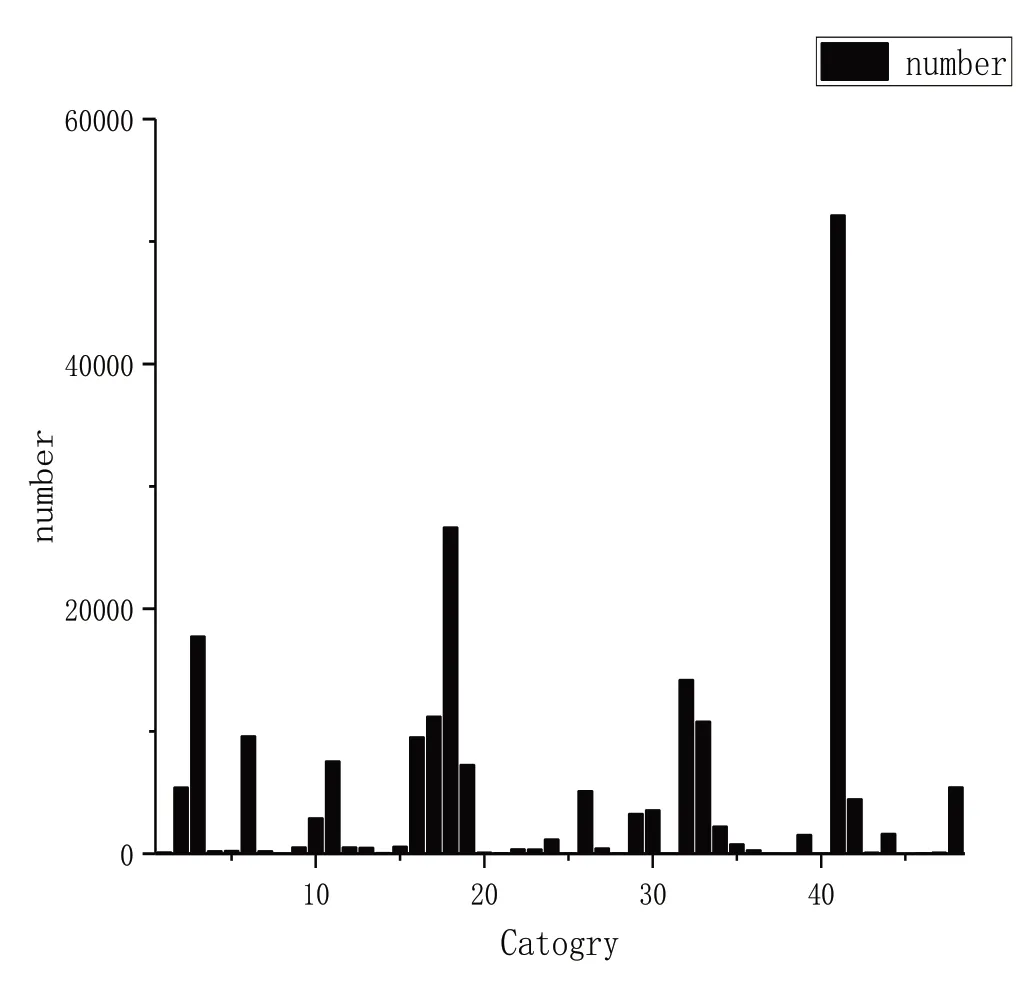
Fig.2 Fine-grained apparel category distribution圖2 細粒度服裝類別分布
代價敏感損失函數固定權重和動態權重的消融實驗結果如表1 所示,其中Category-Average 表示服裝類別的平均性能指標,Attribute-Average 表示服裝屬性的平均性能指標。實驗結果表明,不論是使用w1加權、w2加權還是w1+w2加權,均比使用原損失函數效果好。此外,w1權重的作用大于w2權重,w1和w2權重聯合使用有相互加強的作用。
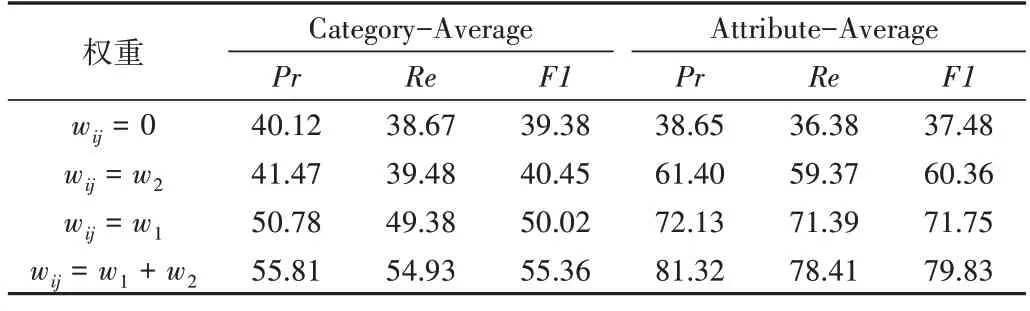
Table 1 Ablation experiment of fixed weight and dynamic weight of cost-sensitive loss function表1 代價敏感損失函數固定權重和動態權重的消融實驗(%)
3.4 代價敏感損失函數性能
細粒度服裝圖片檢索模型使用不同損失函數進行實驗得到的精確率、召回率、F1-分數性能指標結果如表2所示。使用到的比較損失函數包括:①二分類交叉熵損失函數(Binary Cross-Entropy Loss,BCE Loss),其特點為優化整個模型,最小化代價函數。當數據集分布不平衡時,其優化結果偏向于數量更多的類別,因此其實驗結果最差;②固定權重二分類交叉熵損失函數(Weighted Binary Cross-Entropy Loss,Weighted CE),其對不平衡數據進行加權處理,與BCE loss 相比能提升數量少的類別性能;③Focal Loss 與前兩個損失函數相比不僅對不平衡數據進行加權處理,還針對樣本難易增加了權重控制;④本文損失函數除對不平衡數據進行加權處理外,還增加了錯誤懲罰項,對分類錯誤的樣本進行動態加權,使得損失函數優化偏向于分類困難的類別。代價敏感損失函數使用固定權重和動態權重的方法處理數據集的非平衡問題,在關鍵點檢測中通過將坐標轉換為熱圖的方式保留圖像空間特征的對應關系。因此,本文損失函數檢索性能優于其他3個損失函數。

Table 2 Experimental results of using different loss functions for clothing categories and attributes表2 模型使用不同損失函數的實驗結果 (%)
3.5 服裝類別和屬性識別性能
模型檢索性能與其區分服裝屬性的能力有關,因此本文選擇與文獻[18]中的FashionNet(FN)及其相似版本進行服裝屬性識別比較實驗,比較模型包括使用Joints 的關鍵點檢測方法(Joints、Poselets)[28]代替FN 模型關鍵點檢測部分模塊 的FN+Joints 和FN+Poselets;使用VGG-16 與ResNet50 等替換FN 主干網絡的FN-VGG16 和FNResNet50。評價指標包括服裝類別、紋理、布料、形狀、組件、風格等屬性的預測準確率和平均準確率,結果如表3所示。可以看出,在使用top-3、top-5 準確性進行評估時,本文模型表現優于其他比較模型。

Table 3 Experimental results of models for recognizing clothing categories and attributes表3 模型識別服裝類別和屬性實驗結果(%)
3.6 細粒度服裝檢索性能
將本文方法與以下細粒度檢索方法進行比較:①基于局部化三聯體損失的細粒度時尚圖像檢索(Localized Triplet Loss for Fine-grained Fashion Image Retrieval,Localized Triplet)[2];②基于自適應深度學習的細粒度文化遺產圖像檢索(Adaptive Deep Learning for Cultural Heritage Image,ADLCHI)[8];③三向增強的部分感知網絡模型(Three-way Enhanced Part-aware Network,TEPN)[17]。表4 實驗結果表明,本文方法的評價指標優于3種比較方法。

Table 4 Retrieval performance comparison of different methods表4 不同方法檢索性能比較 (%)
4 結語
為提高服裝圖片檢索效果,本文提出一種代價敏感適應加權方法,并引入代價敏感損失函數,其中加權方案基于訓練數據的類頻率和單個數據實例的預測難度實施,動態權重由神經網絡產生的輸出結果分數決定。本文損失函數在細粒度服裝類別和多標簽細粒度服裝屬性檢索中展示出一致結果,表明代價敏感損失函數提升了模型性能,能有效處理數據集類別不平衡問題。如果能獲取更多數據集,模型的檢索準確率可能會更高。目前模型使用K-means 分類的方式加速檢索過程,比傳統窮舉方法速度提升了許多,但檢索準確率有所下降。未來可構建一個分布式檢索系統,以應對大規模檢索數據時速度變慢的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
