Android惡意應用智能化分析方法研究綜述
2023-10-31 11:40:12湯俊偉何儒漢
軟件導刊 2023年10期
張 馳,湯俊偉,何儒漢,徐 微,黃 晉
(1.紡織服裝智能化湖北省工程研究中心;2.湖北省服裝信息化工程技術研究中心;3.武漢紡織大學 計算機與人工智能學院,湖北 武漢 430200)
0 引言
智能手機在日常生活的參與度越來越高,使用率迅速增加,大多數用戶使用社交、游戲、銀行、教育等手機應用程序,包含許多敏感、有價值的數據,例如聯系人信息、照片、銀行信息、密碼等。根據Statcounter 全球統計數據顯示,2022 年10 月全球移動操作系統市場份額Android 占有率為71.6%。目前,Android 成為了受惡意軟件影響最大的移動平臺,托管第三方應用程序的開放架構和應用程序編程接口(API)[1],更是導致各種Android 惡意軟件產品的爆炸性增長[2]。這些惡意軟件執行惡意活動,給用戶帶來了包括資費消耗、隱私竊取、遠程控制等巨大危害。
為此,本文將工作分為以下5 點:①總結Android 惡意應用檢測使用靜態、動態分析方法提取的惡意應用特征類型;②基于機器學習技術分析Android 惡意應用研究;③分析、概述Android 惡意應用分析模型的攻擊方法,從對抗攻擊、防護層面歸納與Android 惡意應用檢測攻防相關的工作;④在共同數據集上,比較分析Android 惡意應用的傳統機器學習和深度學習方法,并歸納對抗分析的研究現狀;⑤討論Android 惡意應用智能化分析方法領域的發展趨勢,從特征、數據集、分析模型方面對未來研究方向和挑戰進行總結。
1 Android惡意應用分析方法特征類型
1.1 靜態分析特征
靜態分析不涉及代碼執行,是對應用程序包進行分析的過程,如圖1所示。

Fig.1 Process of static analysis圖1 靜態分析過程
靜態分析過程主要關注Android 應用程序包(APK)中的清單文件和源代碼文件(class.dex)。清單文件包含有關權限、硬件組件的信息及有關包的其他詳細信息。源代碼文件包含所有編程代碼,例如API 信息、Intent、系統事件等,還可從應用商店中提取元數據信息進行靜態分析,以下示例為靜態分析特征及相關描述。
1.1.1 權限
應用程序需請求各自的特定權限來執行代碼,使得應用程序在未經用戶同意和批準情況下,將無法執行或運行任何后臺活動[3-5]。
1.1.2 Intents
該數據用于組件活動、services 等之間進行通信的消息對象,執行需要系統干預或在其他操作開始時使用,通常用于分析應用程序的惡意行為[3]。
1.1.3 硬件組件
例如,GPS、麥克風、等可能會被惡意軟件應用程序使用,研究和分析這些活動有助于識別惡意軟件應用程序[3,6]。
1.1.4 API calls
將apk 文件中dex 文件轉換成Java 文件,從中提取API調用數據進行靜態分析[3,5-8]。
1.1.5 數據流與函數調用圖
從classes.dex 文件中提取源代碼,創建語句依賴關系圖,假設語句為節點,控制流為節點路徑,將一種惡意代碼模式轉換為圖。創建數據流圖和與函數調用相關的圖來設計惡意應用檢測方法[9-10]。
1.1.6 污點分析
污點分析是檢測來自源和接收器中敏感數據流的方法[11-12]。
1.1.7 操作碼(opcode)/URL
使用通過反匯編得到的dalvik 字節碼中的操作碼進行分析,例如使用Java 代碼中的特定字符串測試、分析網絡流量[13-14]。
1.1.8 Java字節碼/APK-API圖像
將Java 字節碼轉換為圖像用于檢測,將源代碼中的對象和類,根據清單文件的有關權限進行分析或將APK 文件的字節碼轉換為圖像[15],使用機器學習對圖像進行分類[16]。
1.1.9 系統事件
從API 獲取系統服務(使應用程序與系統交互)事件,作為分析特征[17-18]。
1.1.10 元數據信息
Android 應用在應用商店的信息,例如APK 名稱、開發者信息、評分、評論等,可能有助于分類應用[3,6]。
1.2 動態分析特征
動態分析涉及代碼執行與觀察,需要一個隔離環境來運行應用程序并實時觀察信息[3,19],相較于靜態分析更復雜,需要一些資源和技術組合來觀察并得出結論[20],主要將應用程序安裝到沙箱或虛擬機中模擬用戶觸發行為,運行應用程序,并記錄監控模擬運行期間行為。以下為用于動態分析的主要特征及相關描述,圖2為動態分析過程。

Fig.2 Process of dynamic analysis圖2 動態分析過程
1.2.1 系統調用
通過收集系統調用日志,使用系統調用分析檢測惡意活動。
1.2.2 信息流
在污點分析情況下觀察源和目的地。在網絡流量分析中,分析數據包大小、類型、進出的頻率等參數[12]。
1.2.3 函數調用
使用API 框架動態監測函數調用情況,跟蹤使用參數,重建函數調用序列用于分析[3]。
1.2.4 依賴圖
為特定的敏感代碼片斷創建控制流圖,使用該圖對應用程序進行分析分類[21]。
1.2.5 硬件組件
分析運行的硬件組件、系統參數,例如電池數據[3]、內存的利用率、應用程序內存等。
1.2.6 API和權限
應用程序執行時使用的權限和調用的API[22-23]。
1.2.7 通信
短信、電話、URLs、WiFi、GPS 和藍牙能連接系統與外部實體,可作為單一或多個因素的組合進行觀察,以達到檢測目的[23-24]。
1.2.8 代碼注入
在源代碼中注入特殊代碼,運行時執行該代碼跟蹤目標API,并為分析過程創建日志以檢測惡意行為[25]。
2 基于機器學習的Android惡意應用檢測
2.1 傳統機器學習
動態分析的低代碼覆蓋率和低效率,限制了基于動態特征的惡意應用檢測方法的大規模部署[26]。因此,研究者開始利用靜態分析和機器學習提出大量的檢測方法[27-29]。機器學習是在惡意應用檢測過程中應用程序分類技術,包括訓練和測試[30]兩個主要模塊。其中,在訓練模塊從特征集中學習良性和惡意應用程序的行為;在測試模塊中對新的應用程序進行相應分類[31],測試算法準確性。
現有方法已探索了豐富的靜態特征[21,32-33],根據這些特征可構建基于各種機器學習算法的檢測模型,如表1所示。
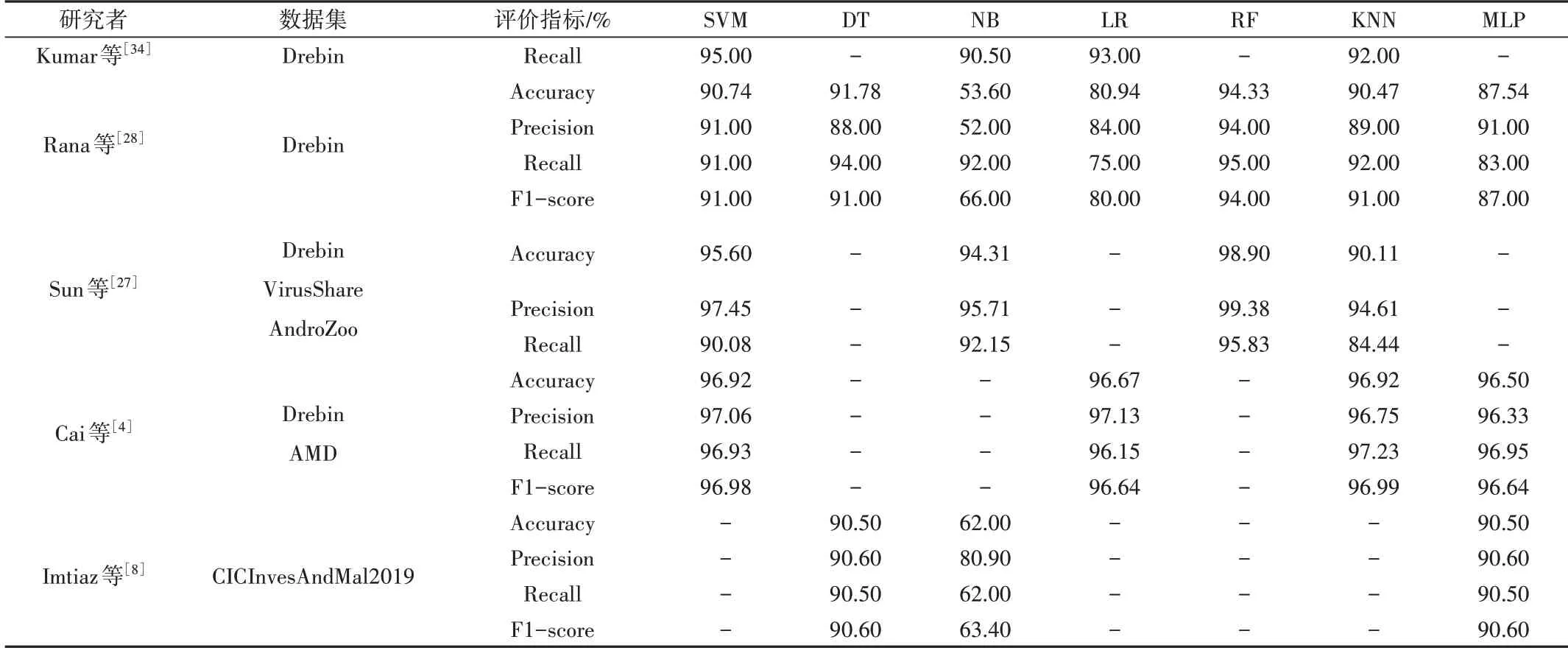
Table 1 Investigation results of traditional machine learning for Android malicious application detection表1 傳統機器學習進行Android惡意應用檢測的調查結果
Rana 等[28]比較各種機器學習算法在惡意應用檢測領域情況下的性能發現,支持向量機(Support Vector Machine,SVM)、隨機森林(Random Forest,RF)和K 最鄰近(K-NearestNeighbo,KNN)相較于其他算法表現良好,準確率超過90%。Kumar 等[34]使用機器學習比較各種算法的提取結果,發現SVM 表現更好,準確率超過95%。
針對特征間的相關性及特征權重的計算,Cai 等[4]采用靜態分析方法,從APK 文件中提取8 個類別的原始特征,使用信息增益(Information Gain,IG)選擇一定數量的最重要特征,通過機器學習模型計算每個選定特征的初始權重并使用權重映射函數將初始權重映射到最終權重,最后使用差分進化(Different Evolution,DE)算法聯合優化權重,映射函數和分類器的參數,在Drebin[28]、AMD[35]上均取得96%以上的精確率。
此外,Chawla 等[36]提出一種基于信號處理和機器學習的方法,利用嵌入式設備的電磁發射來遠程檢測設備上運行的惡意應用程序,開發了基于快速傅里葉變換的特征提取方法,使用SVM、RF 模型檢測惡意應用。Taheri 等[37]使用漢明距離尋找惡意樣本間的相似性,提出第一最近鄰、所有最近鄰、加權所有最近鄰和基于K-medoid 的最近鄰4種惡意應用檢測方法,在Drebin 等3 個數據集上選取API、Intent 和Permission 特征進行實驗,結果表明算法的準確率均超過90%。
2.2 基于深度學習
深度學習在圖像分析、神經機器翻譯及其他領域的突出貢獻,為許多最先進、基于人工智能的應用奠定了基礎[38]。目前,各種深度學習結構已應用于Android 惡意應用的檢測或分類,并取得了良好的效果,惡意應用檢測深度學習體系結構如圖3所示。
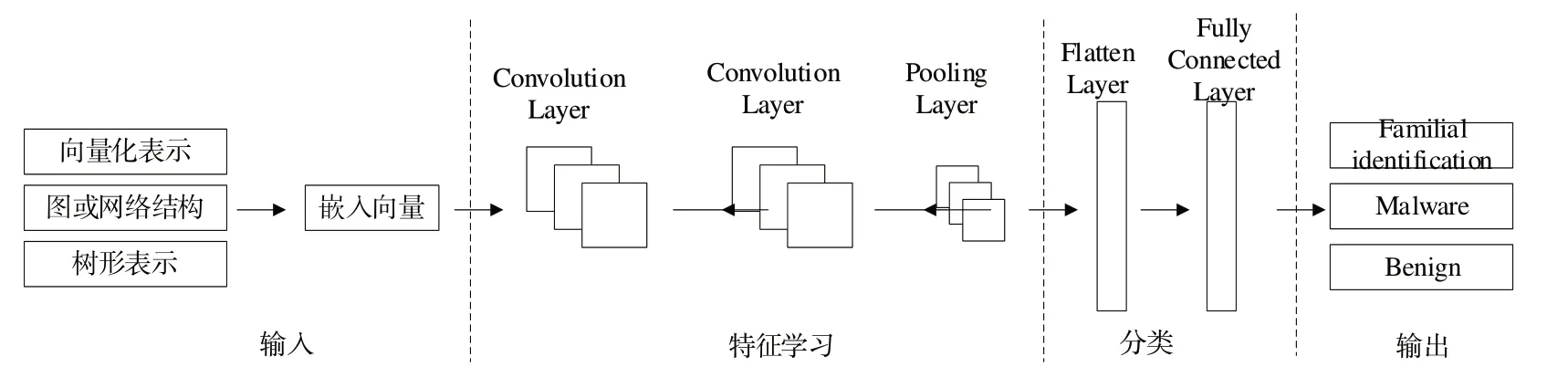
Fig.3 Malicious application detection based on deep learning architecture圖3 基于深度學習體系結構的惡意應用檢測
由圖3 可見,該方法相較于傳統機器學習方法,在Android 惡意應用分析領域的應用中具有以下優點:①深度學習擅長學習應用程序中更復雜模式的高級抽象表示[38];②深度學習能自動學習潛在表示,具有更強的泛化能力,極大減輕了研究者描述Android 應用程序特征時繁瑣、主觀、易出錯的特征工程任務[15,39-40];③深度學習提供了針對不同任務定制特定結構的靈活性。例如,可使用帶有詞嵌入包的長短期記憶(Long Short-Term Memory,LSTM)層,將Android 權限序列編碼成特征,然后將提取的特征通過非線性激活函數送入激活層全連接層進行分類[17]。
Android 應用的原始特征可直接輸入深度學習模型中,學習高級語義特征表示。一方面可通過反編譯從Android 應用中提取操作碼序列,采用深度學習序列數據分類技術處理原始操作碼序列,從而實現深度神經網絡自動學習高級語義特征表示[40];另一方面通過反編譯應用程序提取其中的classes.dex 字節碼,受自然語言處理(Natural Language Processing,NLP)或圖像分類技術的啟發,使用編碼技術將classes.dex 字節碼編碼后的圖像送入深度神經模型自動提取特征和學習[15]。
表2 為使用深度神經網絡模型進行Android 惡意應用檢測或分類的調查研究,展示了每項研究的關鍵點和差異。

Table 2 Investigation results of Android malicious application detection or classification based on deep neural network model表2 基于深度神經網絡模型進行Android惡意應用檢測或分類的調查結果
2.2.1 特征表示方法
向量化表示是Android 惡意應用檢測或分類中最廣泛使用的表示方法。對于提取的語義字符串特征,矢量化表示可使用one-hot 編碼技術、詞頻—逆文檔頻率(TF-IDF)技術[41-42]或word2vec[17]等嵌入技術進行構造。
(1)基于圖像特征的表示。Iadarola 等[15]通過圖像表示移動應用程序,利用梯度加權類激活映射(Grad-CAM)算法,定位圖像中對模型有用的顯著部分,還引入累積熱圖(Cumulative Heatmap)為分類器決策提供可解釋性支持。Vasan 等[16]將原始惡意軟件二進制文件轉換為彩色圖像,結合數據增強方法微調卷積神經網絡架構,檢測和識別惡意軟件家族,在不平衡IoT-android 移動應用數據集上的準確率超過97.35%。李默等[43]將DEX、XML 與JAR文件進行灰度圖像化處理,使用Bilinear 插值算法放縮圖片尺寸,將3 張灰度圖合成一張三維RGB 圖像,通過結合SplitAttention 的ResNeSt 的算法進行訓練分類,在Drebin 數據集上的平均分類準確率達到98.97%。
(2)基于函數調用序列的表示。Imtiaz 等[8]提出使用深度人工神經網絡(Artificial Neural Network,ANN)檢測真實世界惡意應用的方法DeepAMD,并在CICAndMal2019 數據集的實驗表明,該算法在靜態特征集上惡意應用分類、惡意應用類別分類、惡意應用家族分類的最高準確率分別為93.4%、92.5%和90%。此外,為惡意應用程序分配家族標簽,是將具有相同行為的惡意應用歸為一類的常見做法。Mirzaei 等[44]提出從不同家族的聚合調用圖中提取敏感的API,調用集合的Android 惡意應用家族表征系統,指出移動勒索軟件和短信木馬類型惡意應用的惡意操作不一定是同時使用多個敏感的API調用所執行。
(3)基于圖結構特征的表示。目前,各種圖結構已被提出描述Android 應用程序,例如API 調用圖、控制流圖(CFG)等,這些圖可直接提供給深度學習模型,相較于某些Android 惡意應用中的規避技術具有更高的魯棒性。
Huang 等[9]通過選擇與惡意軟件相關的API 特征,并結合API 間的結構關系,將它們映射到一個矩陣作為卷積神經網絡分類器。具體為,基于API 的輸入特征圖選擇API 特征選擇,使用調和平均函數考慮惡意軟件的出現頻率及惡意與良性軟件間的出現頻率差異。Feng 等[45]通過輕量級靜態分析提取近似調用圖和函數內語義信息來表示Android 應用程序,并通過Word2Vec 進一步提取所需權限、安全級別和Smali 指令的語義信息等函數內屬性,以形成圖結構的節點屬性,使用圖神經網絡生成應用程序的向量表示,然后在該表示空間上檢測惡意軟件。Pekta? 等[10]通過對Android 應用程序進行偽動態分析,為每個執行路徑構建API 調用圖,提取執行路徑信息,并將圖嵌入用于訓練深度神經網絡(Deep Neural Networks,DNN)的低維特征向量,利用卷積層從圖嵌入矩陣中檢測、提取隱藏的結構相似性,并依據組合卷積層發現的所有復雜局部特征來確定該應用的屬性。Pei 等[5]提出一種基于聯合特征向量的新型深度學習框架AMalNet,在提取的所有權限、組件和API 靜態特征文本數據中,通過word2vec 嵌入技術將文本數據的詞、字符和詞匯特征作為圖的節點,并映射到向量中,集成圖卷積神經網絡(Graph Convolutional Networks,GCNs)與獨立循環神經網絡(Independent Recurrent Neural Network,RNN,IndRNN)形成檢測模型。
2.2.2 數據集處理
訓練數據可能包含噪聲標簽,是基于機器學習的Android 惡意應用檢測的一個常見問題。Xu 等[46]提出差分訓練(Differential Training)作為通用框架,用于檢測、減少訓練數據中的標簽噪聲。差分訓練在整個噪聲檢測訓練過程中使用輸入樣本的中間狀態,使用下采樣集來最大化錯誤標記樣本與正確標記樣本間的差異,并且異常值檢測算法不依賴一小組正確標記的訓練樣本。同時,使用SDAC[47]、Drebin 和DeepRefiner[39]這3 種不同的Android 惡意應用檢測方法評估差異訓練的有效性。在3 個不同的數據集的實驗結果表明,差分訓練可將錯誤標記的樣本大小分別減少到原始大小的12.6%、17.4%和35.3%,在對噪聲水平約為10%的訓練數據集進行降噪后,差異訓練顯著提升了每種惡意應用檢測方法的性能。
然而,缺乏惡意軟件源代碼是惡意應用安全研究的一大阻礙。Rokon 等[48]提出有效識別惡意軟件源代碼存儲庫的監督學習方法——SourceFinder,識別惡意軟件存儲庫的準確率為89%,創建了擁有7 504 個存儲庫的非商業惡意軟件源代碼檔案庫,研究了惡意軟件存儲庫及其作者的基本屬性和趨勢。
3 Android惡意應用檢測對抗攻擊與防護
3.1 對抗攻擊
對抗樣本攻擊是指故意對輸入樣本添加一些人無法察覺的細微干擾,導致模型以高置信度給出一個錯誤輸出。由于建立模型的內在假設是訓練和測試數據來自相同的分布,然而惡意樣本違反了這種假設,在特征向量中激活一定數量的特征,使其逃避基于人工智能的惡意應用檢測而不影響其惡意功能,因此惡意應用檢測的機器學習模型可能會受到精心設計的對抗樣本攻擊。
在白盒攻擊中,假設對手擁有關于知識矩陣(知識矩陣由訓練數據、特征集、ML/DL 算法的目標函數和模型結構等信息組成)的完整信息;而在黑盒攻擊中,假設對手不知道知識矩陣。基于目標的攻擊者可通過故意注入錯誤標記的樣本來執行針對訓練階段的中毒攻擊,從而降低模型的檢測能力,還可執行規避攻擊修改測試樣本以強制檢測模型錯誤分類。因此,在對抗攻擊時若能在任何實際任務部署前進行驗證,將提升檢測模型的魯棒性。
表3為Android 惡意應用檢測對抗攻擊調查研究結果,展示了每項研究的關鍵點及其差異。Hu 等[49]提出基于生成對抗網絡(Generative Adversarial Network,GAN)的算法(MalGAN),生成對抗性的惡意軟件實例能繞過基于黑盒的機器學習檢測模型,通過替代檢測器適應黑盒惡意軟件檢測系統,能將檢測率降低到接近零,并使基于再訓練的對抗性實例的防御方法難以發揮作用。Chen 等[50]直接在APK 的Dalvik 字節碼上擾動制作對抗樣本,以逃避從Dalvik 字節碼中收集特征(句法或語義特征)來捕獲惡意行為的檢測器,該方法成功地欺騙了Drebin、MaMaDroid[51]等基于機器學習的檢測方法。Grosse 等[18]擴展了Papernot等[52]提出的方法,既調整了處理二進制文件的功能,又保留了應用程序的惡意功能,在Drebin 數據集應用該攻擊的誤導比率高于63%。Demontis 等[53]針對關注0,1 型特征(1表示應用存在某個特征,0表示不存在)的Drebin 模型指出一些潛在的攻擊場景,主要就混淆攻擊進行研究,僅使用Android 應用代碼混淆和加密工具DexGuard 對Drebin 產生一定干擾。

Table 3 Android malicious application counterattack investigation results表3 Android惡意應用對抗攻擊調查結果
Chen 等[54]提出現實世界中的中毒攻擊表現為弱、強和復雜3 種類型,采用基于Jocobian 矩陣的對抗制作算法[52],在語義上以對抗攻擊的攻擊性為特征,使用語法特征生成偽裝樣本可在很大程度上模擬現實世界的攻擊,能誤導Drebin 和MaMaDroid 使用基于機器學習方法的檢測系統。Rathore 等[55]通過中毒/修改惡意樣本讓安卓惡意應用檢測模型錯誤分類,使用經典機器學習、集成(bagging &boosting)算法和深度神經網絡構建各種檢測模型使用規避攻擊策略,在12 種不同惡意應用檢測模型的平均欺騙率均超過50%,基于決策樹的檢測模型欺騙率最高,達到68.54%。Severi 等[56]研究基于特征的機器學習惡意應用分類器分析后門樣本中毒攻擊的敏感性,為解決攻擊者無法控制樣本標記過程的干凈標簽攻擊,提出與模型無關的基于特征使用可解釋機器學習的惡意應用分類器來生成后門樣本,在Drebin 數據集中將30個特征后門樣本作為訓練線性SVM 的原始545 K 維向量,在2%的中毒率下攻擊將后門樣本的模型準確度平均降低到42.9%。
3.2 檢測防護
Sebastián 等[57]在AVclass 等[58]基礎上建立AVclass 2,使其從專門針對惡意應用家族的惡意應用標記工具演變為惡意應用標簽提取工具,自動從反病毒(Anti-Virus,AV)引擎的檢測標簽中提取標簽,并根據惡意應用類別、系列、行為等分類惡意應用樣本。
由于構建了不封閉標簽集的開放分類法,因此既可處理AV 供應商隨時間推移引入的新標簽,還能通過概括反病毒標簽中發現的關系擴展輸入分類法、標記和擴展規則。Demontis 等[53]針對規避攻擊提出對抗感知機器學習檢測器,通過更均勻分布的特征權重提升線性分類系統的安全性,甚至能確保在基于DexGuard 的混淆下仍然具有較強的魯棒性,所提出的安全學習范式減輕了規避攻擊的影響,在沒有攻擊的情況下還略微降低了檢測率。
Chen 等[54]提出兩階段迭代的基于對抗的檢測模型(KUAFUDET),引入自動偽裝檢測器過濾可疑的假陰性,并將其反饋到訓練階段以解決對抗環境,增強了惡意軟件檢測系統的魯棒性,實驗表明該模型可顯著減少假陰性并將檢測準確率提升至少15%。Grosse 等[18]使用DNN 訓練的惡意軟件檢測模型的潛在防御機制,防御蒸餾和對抗再訓練,實驗表明該方法降低了對抗樣本的錯誤分類率,但觀察到的改進通常可忽略不計。
相比之下,在對抗訓練期間引入擾動,僅使用對抗制作的惡意軟件應用程序訓練模型就能提升算法的魯棒性。Rathore 等[55]針對對抗攻擊使用對抗再訓練作為防御機制,以構建穩健的惡意應用檢測模型。防御機制在12 種不同的檢測模型下將同一攻擊的平均欺騙率降低到1/3。Han 等[22]開發了FARM 的檢測器,提出基于標志點的特征變換、基于特征值聚類的特征變換和基于關聯圖的特征變換3 種特征變換技術,用于生成逆向工程難以得到的特征向量,面對偽造API 調用、權限請求和人為減少API 調用次數3種攻擊均表現出良好的魯棒性。
4 未來研究方向
4.1 更有效的特征組合方法
靜態分析對高級別混淆后的應用局限性較高,難以保證動態分析代碼覆蓋率。然而,通過動態分析和靜態分析集成的方法可能是增強準確性,減輕靜態、動態惡意應用分析缺點的解決方案。因此,后續應研究與Android 惡意應用檢測相關的各種因素,例如通過不同策略進行混合分析。
4.2 更完備數據集的生成方法
Android 惡意軟件仍在不斷演變,然而大多數研究并未公開研究數據集,缺乏基準Android 惡意軟件數據集。如果能使用最新應用程序創建數據集并公開,將對研究者評估所提技術具有極大幫助。在數據集處理方面,檢測并減少數據集中的標簽噪聲能有效提升惡意應用檢測方法的性能。此外,最新提出的Android 惡意應用檢測研究在實際應用具有重要意義,但當前針對此類的研究較少、難度更大,有待深入研究。
4.3 更魯棒的深度學習分析模型
Android 惡意應用程序使用的規避技術,在惡意應用開發者和安全研究者間引發了軍備競賽。目前,大多數機器學習模型對對抗示例缺乏魯棒性,在訓練或測試階段可能發生對抗攻擊、中毒攻擊、規避攻擊、模擬攻擊、反轉攻擊等,因此深度學習算法需提升魯棒性和安全性以抵御上述攻擊。
目前,大多數對抗樣本只能欺騙依賴句法特征(請求的權限、API 調用等)的檢測方法,并且只能簡單地修改應用程序清單實現擾動。雖然部分對抗樣本具有欺騙依賴語義特征(控制流圖)的機器學習檢測方法,但需要密切關注惡意應用程序使用的創新規避技術、新型威脅、新型攻擊、防御對抗機器學習攻擊、防御對抗攻擊應用檢測、抗混淆等方法,以便作好準備對其采取防御措施。
4.4 可解釋深度學習的惡意應用檢測
深度學習模型包含隱藏層,解釋算法在決策時缺乏透明度。如何提升深度學習模型的可解釋性(全局和局部可解釋性)和透明度,使其真正在實際場景中應用,是未來的研究方向之一。此外,基于深度學習的算法需要持續再訓練、細致調整超參數。同時,與Android 惡意應用分類相關的維度縮減、處理不平衡數據等問題尚未被深入研究。
5 結語
由于移動應用程序的指數級增長,移動惡意應用已被認為是對企業、政府和個人的主要網絡威脅之一。本文歸納了Android 惡意應用檢測中靜態、動態分析常用的特征,分析了Android 惡意應用的不同檢測技術,對使用人工智能技術檢測Android 惡意應用進行了回顧,還討論了Android 惡意應用阻礙分析、逃避檢測的能力與防護方法。此外,本文總結歸納了現有研究的優勢與不足之處,強調從研究中獲得主要見解,并提出未來的研究方向。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:24
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22
