一種基于物體追蹤的改進語義SLAM算法
2023-10-31 11:40:08杜小雙華云松
軟件導刊 2023年10期
杜小雙,施 展,華云松
(上海理工大學 光電信息與計算機工程學院,上海 200093)
0 引言
隨著機器人技術、無人駕駛、增強現實等領域的發展與普及,視覺SLAM 作為其應用的基礎技術之一[1],得到了學者們的廣泛關注與研究,并成為機器人定位與建圖研究領域的一個熱點[2]。
視覺同步定位與建圖(Simultaneous Localization and Mapping,SLAM)可以大致分為兩類:直接法和特征點法。直接法假設相鄰幀間光度值不變,用局部像素的梯度和方向進行計算并優化出相機位姿,如LSD-SLAM[3]、DSO[4]等。特征點法通過特征點提取,并使用描述子匹配特征點,通過匹配特征點解出幀間位姿并優化多幀位姿。由Mur-Artal 等[6-8]提出的ORB-SLAM 是一個適用于單目、雙目和RGB-D 相機的SLAM 系統,因出色的性能而得到了廣泛應用。
上述SLAM 算法都是基于靜態場景假設無法解決動態場景的問題,而隨著深度學習的快速發展,一些先進深度學習網絡,如DeepLab[9]、SegNet[10]和YOLACT[11]等可以精確進行像素級的語義分割,語義SLAM 即利用語義神經網絡分割出圖像物體掩碼,通過剔除動態物體掩碼上的特征點以實現正確的跟蹤。Yu 等[12]提出的DS-SLAM 在ORBSLAM2 的3 個線程基礎上新增語義分割和稠密建圖兩個新線程,使用SegNet 網絡分割出物體掩碼并結合移動一致性檢查方法以減少動態對象影響,從而提高動態環境下的跟蹤精度。此外,Bescos 等[13]提出的DynaSLAM 利用mask R-CNN[14]神經網絡和多視圖幾何檢測和剔除運動物體從而實現更精準的軌跡估計。
針對語義SLAM 僅停留在剔除動態物體特征點層面并沒有充分利用語義信息,無法解決分割錯誤對物體追蹤的影響,本文提出了一種基于物體追蹤的改進語義SLAM 算法,實現物體追蹤與定位,并通過剔除運動物體影響提高軌跡估計精度。本文貢獻如下:①提出一種物體動靜態檢測方法,對物體匹配特征點進行深度、重投影誤差和極線約束三重檢測實現精準的物體動靜態判斷;②提出一種物體追蹤狀態判別方法,通過物體的4 種追蹤狀態相互轉換,實現穩健的環境物體追蹤與定位;③在TUM RGB-D 數據集上進行實驗,證明本文所提方法的有效性。
1 系統設計
1.1 系統框架
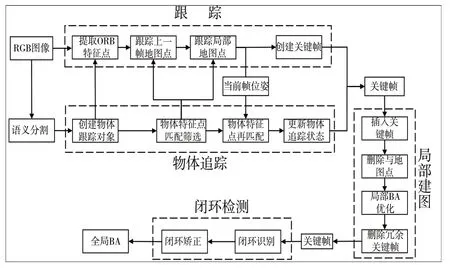
Fig.1 System architecture圖1 系統框架
1.2 語義分割網絡
針對室內動態環境中的物體分割,本文采用YOLACT[15]++網絡。YOLACT++網絡是一種簡單的全卷積實時語義分割網絡,使用Resnet101-FPN 作為主干網絡,使用在MS COCO 數據集上訓練得到的網絡參數進行物體檢測。假設YOLACT++網絡的輸入是一個x×y×3 的RGB 圖像矩陣,則網絡的輸出就是一個x×y×n的掩碼矩陣,其中n是圖像中物體的數量。對于網絡最后的每個輸出通道m∈n,都會得到一個對象的掩碼矩陣。
在實時性上,YOLACT++使用Resnet101-FPN 主干網絡在MS COCO 2017 驗證集上的檢測速度可以達到27.3幀/s[15]。同樣地,在TUM 數據集實驗中,使用YOLACT++分割RGB 圖像中的人物、椅子和屏幕3 種物體,速度也能夠滿足算法語義分割任務中的實時性需求。每幀圖像分割完成后,將得到的掩碼與定位框輸入本文算法。在本幀圖片提取特征點時,結合掩碼得到每個特征點的物體類別。為了特征匹配的準確性,剔除位于物體掩碼邊緣的特征點。
1.3 物體追蹤
物體追蹤模塊為本文核心算法,當出現新的物體時創建物體追蹤對象,其包含物體追蹤狀態信息、物體相鄰兩幀的物體特征點(當前幀與上一幀)和由物體特征點所創建的物體地圖點。再得到當前幀位姿后將上一幀追蹤物體特征點投影到當前幀上進行匹配,對匹配成功的特征點進行三重動靜態檢測以判斷其動靜態,之后根據特征點匹配點數量與動靜態點比例更新物體追蹤狀態。如果當前幀需要創建關鍵幀則將物體追蹤信息輸入關鍵幀中,在局部建圖中根據關鍵幀中物體追蹤信息新建替換與刪除地圖點。
1.4 三重動靜態檢測
在匹配物體特征點時,對匹配成功的物體特征點進行深度、重投影誤差和極線約束三重檢測以判斷是否為動態點,其中深度檢測為匹配特征點投影到當前幀上的深度值與當前幀的深度計算其差值后與深度閾值對比,差值超過深度閾值則認為該特征點為動態點。
1.4.1 重投影誤差
重投影誤差即將上一幀的匹配特征點投影到當前幀上與匹配點的直接平面距離差距。重投影誤差如圖2所示。
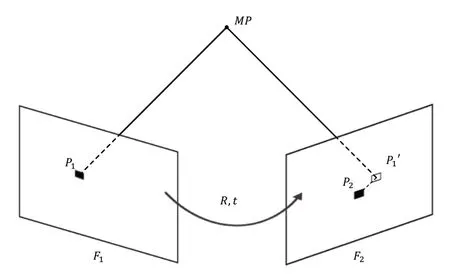
Fig.2 Schematic diagram of reprojection error圖2 重投影誤差示意圖
圖2 中,P1、P2為匹配特征點,MP為點P1投影到3D 空間中的地圖點和P'1在F2像素平面的投影,相機內參矩陣為K,F1到F2之間的旋轉矩陣為R,平移向量為t。其中,P1點的像素坐標為P1=[u1,v1],P1的像素坐標為P2=[u2,v2]。MP在空間中地圖點的坐標為MP=[X1,Y1,Z1],其中深度Z1通過RGB-D 相機的深度圖獲得。X1、Y1與像素坐標系的關系如下:
后來,朝廷下令,把撫順關馬市關閉了,這一關就是幾個月。馬市不開,女真人沒鹽,沒鐵器,沒馬匹,生活不了,他們就上書朝廷,要求開關,恢復交易。朝廷又重新開市,開市以后,地方上的守關明軍照樣勒索。王杲呢,再帶女真人去打。這樣,把朝廷又惹翻兒了,一面安撫,一面帶兵去圍剿女真人。李成梁受命帶領幾萬明軍,把古埒城團團圍住。
F1相機坐標系中的MP點坐標通過變換矩陣到F2幀相機坐標系下的坐標[X2,Y2,Z2]T為:
得到P'1點的投影坐標后與匹配點P2坐標求得匹配后的重投影誤差e為:
得到重投影誤差后與設定的誤差閾值對比則可進行判斷,如果其重投影誤差大于閾值該特征點為動態點。
1.4.2 極線約束
極線約束是攝像機運動學的重要組成部分,可用于檢查特征點的運動狀態。對極幾何示意圖如圖3所示。
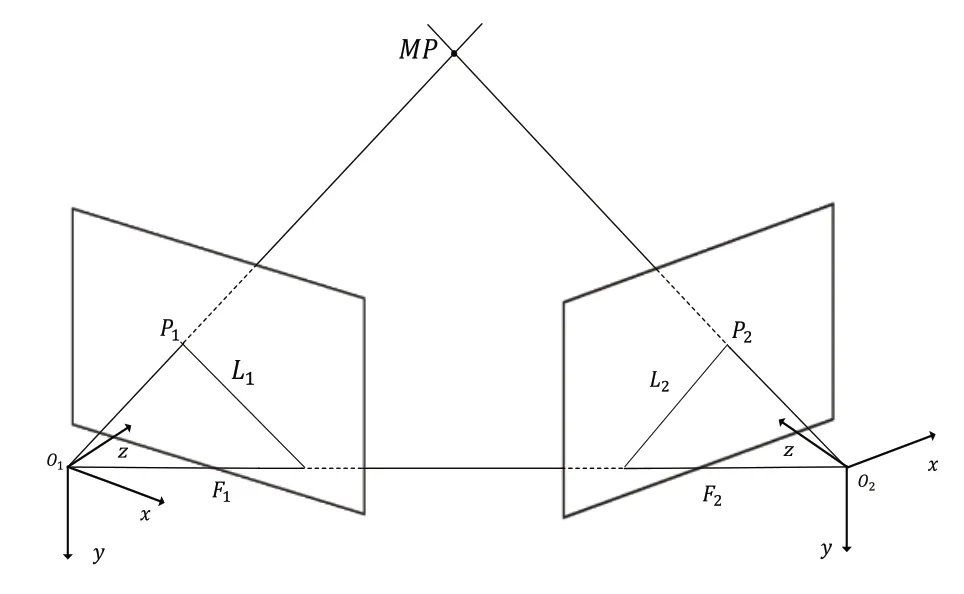
Fig.3 Schematic diagram of epipolar geometry圖3 對極幾何示意圖
對于匹配特征點,相鄰幀間基礎矩陣F為:
其中,K為相機內參,R、t為幀間的旋轉矩陣和平移向量。在得到基礎矩陣F后對每個物體掩碼的匹配特征點計算當前特征點的極線。上一幀的特征點通過基礎矩陣映射到當前幀的區域即為極線。設前一幀和當前幀中的匹配特征點分別表示為[u1,v1]和[u2,v2],u、v表示特征點的像素坐標值,而P1=[u1,v1,1],P2=[u2,v2,1]表示匹配特征點的齊次坐標形式。匹配特征點的極線約束如下:
則F2圖像平面上的匹配特征點P2對應極線L計算如下:
最后,當前幀的特征點到對應極線距離D如下:
判斷匹配特征點極線之間的距離是否大于閾值,如果距離大于閾值,則該特征點被視為動態點。
1.5 局部建圖
在局部建圖中,本文算法只對靜態地圖點進行操作。由于動態地圖點已經無法跟蹤優化,因此將其設置為壞點不加入關鍵幀與地圖點的局部優化,并且動態物體也不再新建地圖點,僅僅依靠幀間的物體特征點進行追蹤。如果動態物體在算法運行中由動態轉換為靜態,就可以正常新建地圖點進行跟蹤優化。對于消失在相機視野中的靜態物體,其物體地圖點得到保留,并且它們將被用于恢復物體跟蹤狀態。
2 基于語義分割與動靜態檢測的追蹤狀態轉換
在本文算法中,物體都具有4 種追蹤狀態:①靜態是匹配特征點、動靜態點在閾值范圍內;②動態是匹配特征點、動靜點比例超過閾值范圍;③即將丟失是當前幀未匹配到同類型掩碼;④已丟失是連續多幀未匹配同類型掩碼。
物體跟蹤狀態轉換過程如圖4所示。具體步驟如下:
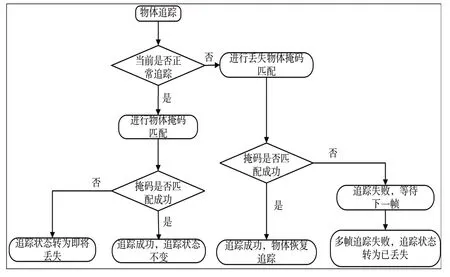
Fig.4 Schematic diagram of object tracking state transition圖4 物體追蹤狀態轉換示意圖
(1)當物體首次出現在相機視野時,本文算法會根據物體的類別創建跟蹤對象,并在創建的初始幀中確定物體所處的運動狀態。如果判斷為靜態物體特征點和地圖點,加入后續匹配跟蹤;反之,判斷為動態則刪除地圖點,其特征點不參與后續匹配跟蹤。
(2)正常追蹤的物體會根據當前幀間物體特征點匹配情況更新當前幀中的跟蹤狀態。如果匹配成功,則使用動靜態點比例判斷物體當前幀的運動狀態;反之,則判斷物體追蹤失敗,將物體轉為即將丟失狀態,并儲存物體信息用于丟失找回。
(3)當物體處于即將丟失狀態時,會儲存丟失前一幀的物體相關信息,在之后匹配過程中使用丟失幀的儲存信息進行匹配。如果成功匹配上相同類型的掩碼,則物體恢復追蹤狀態后正常追蹤;而對于超過十幀依然沒有匹配正確的物體掩碼,將物體的追蹤狀態轉為已丟失,不再對物體進行追蹤,動態物體直接刪除跟蹤信息,靜態物體則保留全局地圖點等待之后的召回。
在算法物體追蹤過程中,通過物體4 種追蹤狀態的相互轉換,可以有效地避免遮掩與分割掩碼錯誤導致的追蹤失敗,從而穩定地實現物體的追蹤與定位。
3 實驗與分析
對于本文所提出的SLAM 算法,將通過實驗證明其算法的準確性與穩定性,在公共TUM RGB-D數據集上進行兩個部分的實驗:①對TUM RGB-D 數據集中的walking_halfsphere 序列進行實驗,通過跟蹤物體定位框對本文算法的物體追蹤能力進行評估;②對TUM RGB-D 數據集中的8個sitting序列和walking序列進行定量分析。利用TUM數據集的官方評估工具對本文算法得到的軌跡進行評估,同時使用其他SLAM算法結果與本文算法結果進行比較。
3.1 物體追蹤實驗
在實驗中使用walking_halfsphere 序列集,此場景中人與相機既有運動又有靜止,物體間存在相互遮蓋和重合,相機自身運動包含平移和旋轉,這些要素的結合對于物體的分割、跟蹤都是一項較大的挑戰,因此選擇此序列集進行實驗能夠較為準確地評估基于本文算法的物體追蹤性能。圖5 是基于本文算法運行walking_halfsphere 序列時的圖像(彩圖掃OSID 碼可見)。

Fig.5 Operation diagram of the object tracking system圖5 物體追蹤系統運行圖
從圖5(a)可以看出,在實驗開始時,人和屏幕都被成功追蹤,其中動態物體為人,靜態物體為屏幕。圖5(b)中相機和人都在運動,先前追蹤的人已經丟失,此時刪除該追蹤信息,等到人再出現在相機視野中時,重新創建新的追蹤對象并追蹤。圖5(c)和圖5(d)中,兩個椅子進入相機視野,被成功追蹤并編號為一號椅子和二號椅子。之后,圖5(e)、圖5(f)與圖5(g)中兩人重新回到相機視野且其中一人坐回椅子,該人從動態轉變為靜態。圖5(h)是相機與人運動后的圖像。由此證明,本文所提出的算法可正常追蹤物體,同時具有更新物體追蹤狀態的能力。
3.2 軌跡估計誤差實驗
實驗中將對TUM RGB-D 數據集中的siting 和walking兩種類型共8 條序列進行實驗并將結果與ORB-SLAM3、DS-SLAM 和DynaSLAM 的軌跡估計誤差數據進行比較。
圖6 為本文算法和ORB-SLAM3 在高動態場景中軌跡估計誤差對比圖,其中黑色線段為真實軌跡,藍色線段為估計軌跡,而紅色表示真實軌跡與估計軌跡間的差值,紅色范圍越大表示誤差越大(彩圖掃OSID 碼可見)。

Fig.6 Schematic diagram of estimated trajectory error圖6 ORB-SLAM3系統的估計軌跡誤差示意圖
圖6 與圖7 為本文算法與ORB-SLAM3 在walking_halfsphere 和walking_xyz 兩圖像序列集下的估計軌跡誤差示意圖,可以看出本文算法與ORB-SLAM3 相比在動態環境中的軌跡誤差存在較大差距。因此,以ORB-SLAM3 為代表的傳統視覺SLAM 在處理動態環境上存在不足,同時表明對動態物體進行去除可使視覺SLAM 跟蹤精度得到極大提高。
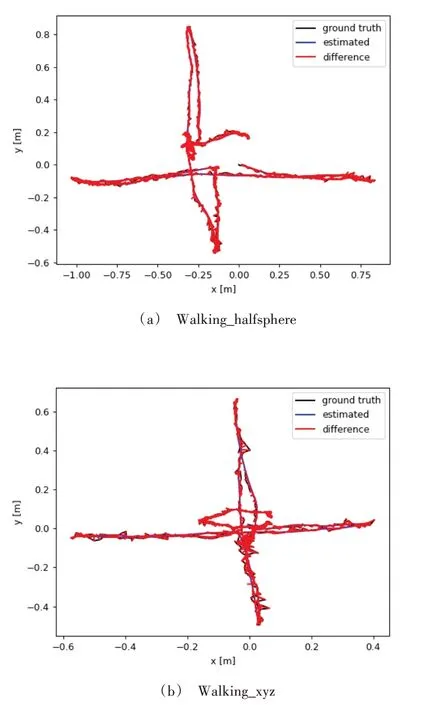
Fig.7 Schematic diagram of the estimated trajectory error of the algorithm in this paper圖7 本文算法的估計軌跡誤差示意圖
在該部分實驗中,將本文算法與ORB-SLAM3、DSSLAM、DynaSLAM 的結果進行比較,使用TUM 官方提供的誤差分析工具對估計軌跡與真實軌跡進行對比。其測量值為絕對軌跡誤差(Absolute Trajectory Error,ATE)與相對姿態誤差(Relative Pose Error,RPE),使用均方根誤差(Root Mean Square Error,RMSE)和標準差(Standard Deviation,SD)作為評估指標。結果如表1—表3 所示(“—”表示相關論文中沒有提供結果)。

Table 1 Comparison of ATE result of TUM RGB-D dataset表1 TUM RGB-D 數據集的絕對軌跡誤差結果比較
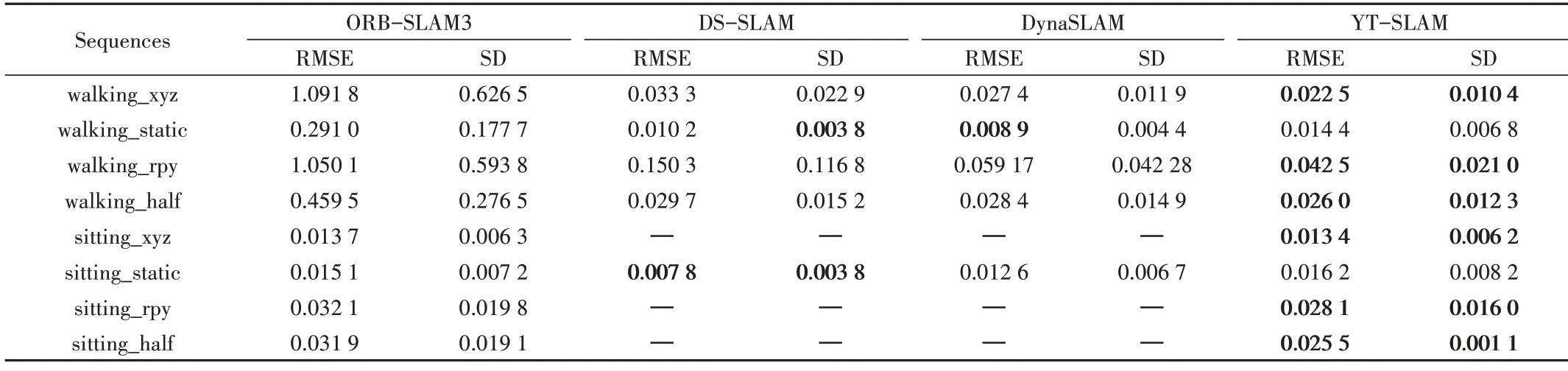
Table 2 Comparison of results of relative pose translation error of TUM RGB-D dataset表2 TUM RGB-D 數據集的相對姿態平移誤差結果比較

Table 3 Comparison of relative pose rotation error results of TUM RGB-D dataset表3 TUM RGB-D數據集的相對姿態旋轉誤差結果比較
從表1—表3 可以看出,與原版ORB-SLAM3 系統相比,語義SLAM 算法可以極大減少在動態場景下的絕對軌跡誤差與相對姿態誤差。本文算法與DS-SLAM 和DynaSLAM 相比,在4 個動態序列中的3 個(walking_xyz,walking_rpy 和walking_half)中的絕對軌跡誤差和相對姿態誤差都有不同程度的下降;而在靜態序列中,由于DS-SLAM與DynaSLAM 缺少相關數據,因而本文算法與ORBSLAM3 進行對比,在4 個靜態序列中由于本文算法在跟蹤中剔除了類別匹配錯誤的特征點,故在靜態場景下的估計誤差比ORB-SLAM3 更小,但當前視覺SLAM 算法在靜態場景中已經有較好的性能,因此可提升的空間有限。
4 結語
本文提出了一種基于ORB-SLAM3 的語義SLAM 算法,該算法使用YOLACT++獲取圖像中掩碼與定位框,對物體特征點匹配后通過三重檢測判斷其動靜狀態,再根據數量與動靜態比例更新當前物體跟蹤狀態,實現穩定的物體追蹤,同時剔除動態物體的影響以實現精準的軌跡估計。本文算法的實驗結果與其他視覺SLAM 算法的實驗結果相比,可以更加準確地估計相機運動軌跡并正確地追蹤到物體的運動狀態與位置,具有廣泛應用價值。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2011年6期)2011-01-29 02:49:50
