基于數據融合的不平衡連續手術動作分割識別
2023-11-04 02:26:36鄭嘉穎王杰付攀李楨邊桂彬
科學技術與工程 2023年29期
鄭嘉穎, 王杰, 付攀, 李楨, 邊桂彬*
(1.北京信息科技大學自動化學院, 北京 100096; 2.中科院自動化研究所, 北京 100190)
基于可穿戴傳感器的動作識別是目前研究人類行為及操作的重要部分,可以應用于醫療保健、娛樂等多個領域中,目的在于識別出一段數據序列中的動作或操作構成,以方便后續的分析及研究。當前的有關利用可穿戴傳感器數據的行為識別領域,需要分析的動作序列通常被拆解成單個動作進行識別,而真實情境下完成一個復雜的操作時通常需要連續完成多個動作,在連續的自然動作中,很難精密地控制每一個動作出現的頻率和持續的時間長度,因此采集到的數據總體長度不一致的同時也很容易出現樣本數據分布不平衡的問題。針對樣本不平衡的研究由來已久,例如在疾病診斷領域[1]以及故障診斷[2]領域,往往是正例多于負例,極端情況下可能會出現負例全部被判斷為正例,然而正確率依然很高的情況,這并不符合人們的期待。針對不平衡數據的問題,對數據集重采樣[3]或者進行數據增強[4]是常見的處理方法,即通過修正數據集中的樣本分布使其均衡,從而避免數據分布差異大引發少類數據的識別精度低于多類數據。但是重采樣并不適用于所有的情況,降采樣會丟失有效信息,過采樣則會加重過擬合現象。另一種改進方法是通過為損失函數增加權重,增加少數類數據判斷錯誤時的損失,如使用Focal Loss[5]或增加權重的交叉熵損失函數[6],但這兩種需要使用權重的損失函數需要花費較多精力調整權重參數,為訓練帶來了不小的負擔。
非平衡問題的出現,本質是因為少類數據中含有的信息量不及多類數據中含有的信息量豐富易得,因此在同樣的訓練進程中很難獲得相同的學習效果。近年來的研究結果證明,數據融合的方式可以有效提高識別的準確度與可靠性[7],因此現引入數據融合算法以提升少數類數據的特征提取效果。數據融合或多傳感器融合算法最早應用于軍事領域,但近年來由于傳感器技術的改進,該技術也被應用于導航、醫療等領域。如汽車自動行駛中各部分傳感器采集數據,實時融合并獲得分類或預測結果,以保障汽車在自動駕駛中的安全[8],醫療中則常用于各類穿戴設備輔助檢查疾病[9],研究證實,特征融合可以提高網絡的特征表達能力,如可以將行人識別任務中來自不同模塊的特征進行優勢互補,提升行人識別的效果[10]。
簡單的數據融合算法可以將從不同數據中提取的特征進行簡單的搭配,如特征拼接或特征相加等,除了這種基本融合方法外,還有以加權融合為核心的算法。Zadeh等[11]考慮充分利用各個模態中的特征,提出了一種矩陣融合策略張量融合網絡(tensor fusion network,TFN),該算法首先對每個模態進行維數擴展,并對不同模態求笛卡爾乘積,其缺點是融合的維數過高,會產生較多的冗余信息,需要消耗較多的內存。Liu等[12]針對上述缺點提出了基于低秩因子分解原理的多模態數據融合策略低秩權重融合(low-rank weight fusion,LWF)。LWF將常規全連接層中的權重矩陣分解為幾個維數較低的矩陣,即低秩因子,并使用低秩因子對各模態的特征矩陣進行運算,然后找到所有模態數據的點積。該融合策略充分降低了運算的復雜性,但特征長度過長時仍然會出現參數爆炸的情況。隨著注意力機制的開發與應用,近年來不斷有研究將注意力機制引入數據融合算法,如用于多模態情感識別[13]、行為識別[14], 語音識別[15]等領域中。自注意力和跨模態注意力通過捕捉樣本的全局特征并篩選出特征中真正重要的部分從而完成特征的有效融合。
綜上所述,針對連續動作的不平衡數據分類與識別問題,現設計一種基于數據融合算法的手術動作識別及分割算法。在驗證階段,因手術中的動作復雜而精細,很適合采集連續的動作數據用于驗證模型的效果,利用多種可穿戴的傳感器采集眼科醫生進行白內障撕囊操作的動作數據,建立連續手術操作多模態數據集。利用數據采集實驗中采集的連續手術動作數據對該模型進行模型效果對比驗證,證明該模型能夠處理小樣本情境下不平衡連續時間序列數據的分割與識別問題。
1 多模態連續手術動作的識別與分割算法
所提出的基于數據融合的連續動作分割識別模型總體結構如圖1所示。該模型可分為深層特征提取模塊、特征融合模塊和解碼器網絡3個部分,特征提取部分基于雙向長短時記憶網絡(bidirectional long short-term memory networks, Bi-LSTM)構建。長短時記憶網絡(long short-term memory networks, LSTM)屬于循環神經網絡,是處理時間序列數據的常用算法,能夠提取時間序列的時域特征,相關研究證明Bi-LSTM在人體活動識別任務中的分類效果優于LSTM[16]。因此使用Bi-LSTM作為基礎,并且利用網絡的多層堆疊技術充分擴充了網絡容量以提升數據特征的提取效果。各模態數據輸入特征提取模塊后獲得單模態特征,隨后兩兩配對輸入特征融合部分,獲得雙模態融合特征后與單模態特征拼接,輸入自注意力機制模塊獲得最終融合特征,解碼器模塊對最終融合特征進行解碼,將特征序列映射為動作序列作為模型輸出。
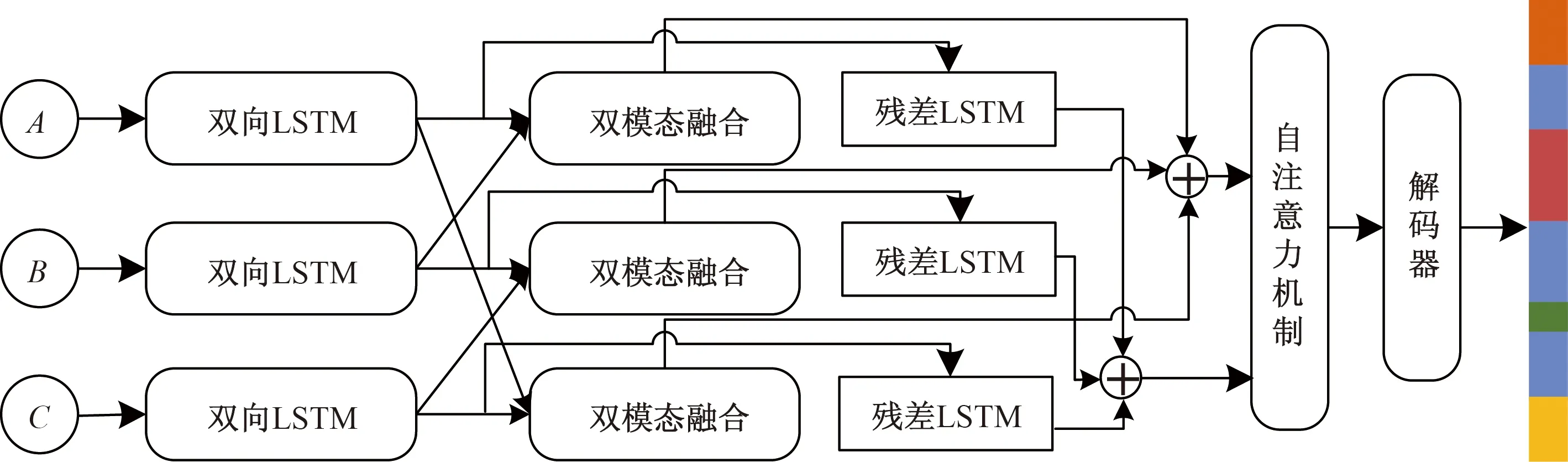
A、B和C表示不同模態的輸入數據
1.1 深層動作數據特征提取
為保證模型能夠提取深層次的數據特征將原始數據輸入堆疊的長短時記憶模塊,該模塊包含3層Bi-LSTM與1個殘差LSTM,殘差LSTM的結構如圖2所示,經過Bi-LSTM后的輸出數據與輸入數據拼接,作為下一層的輸入,單層Bi-LSTM的計算公式與LSTM相同,但會將序列反向輸入再次進行計算,最后的輸出是正向輸入的輸出與反相輸入的輸出的拼接,LSTM計算公式如式(1)~式(6)所示。
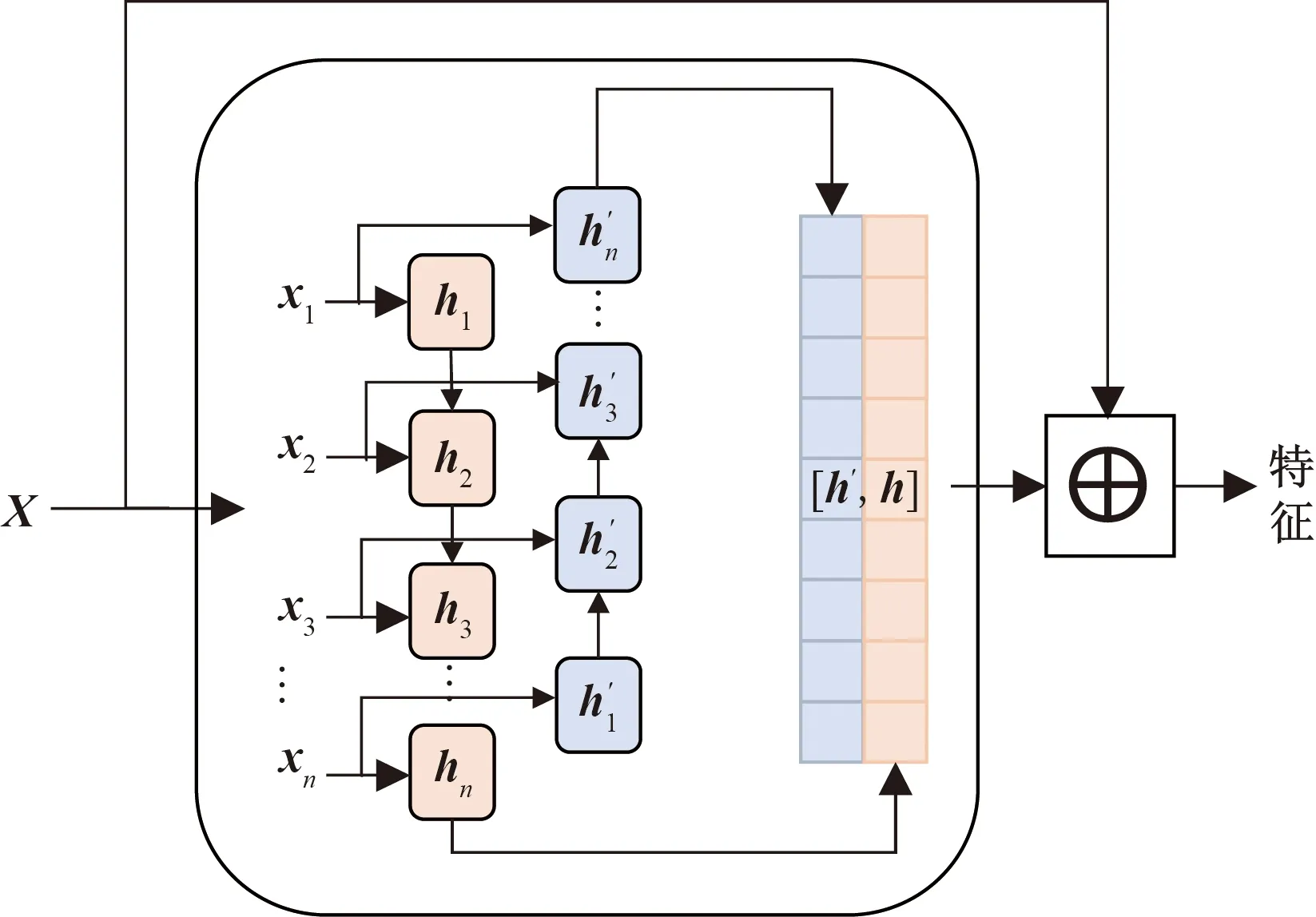
圖2 殘差LSTM模塊結構Fig.2 Residual LSTM module structure
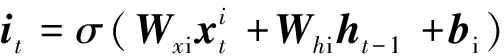
(1)
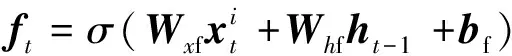
(2)
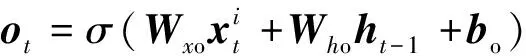
(3)
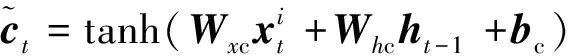
(4)
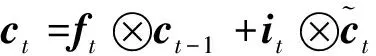
(5)
ht=ot?tanhct
(6)
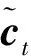
1.2 雙模態特征融合模塊
雙模態特征融合模塊結構如圖3所示。交互注意力機制用于融合雙模態特征,記模態α和模態β的特征分別為Zα∈RL×dα,Zβ∈RL?×dβ。其中,由于在數據處理過程中對齊了各模態的數據,各模態的時間長度均為L,dα和dβ分別為兩個模態的特征對應的維度。該模塊使用模態α計算查詢矩陣(Query),記為Qα,使用模態β計算鍵矩陣(Key),記為Kβ通過模態α和模態β的聯合計算值矩陣(Value),記為Vαβ。
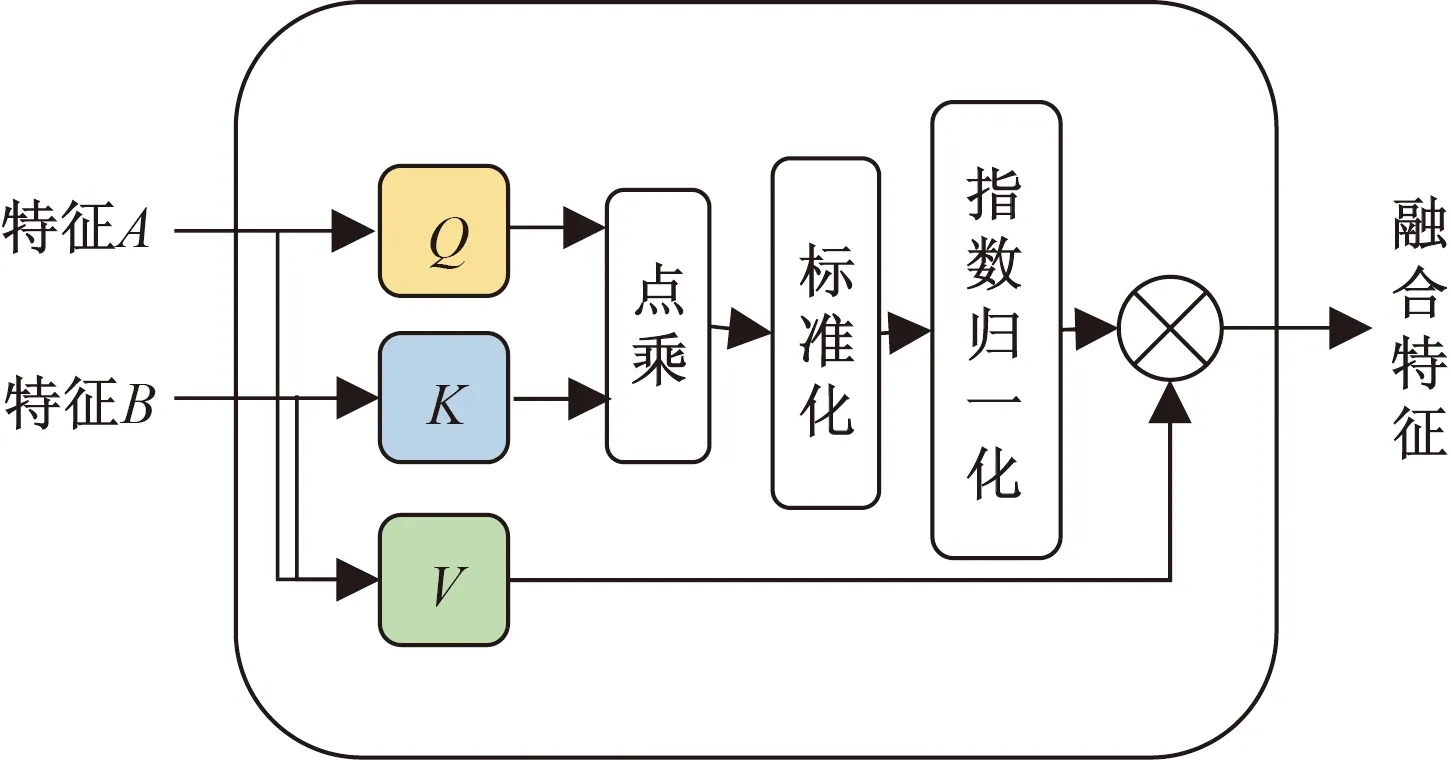
圖3 雙模態特征融合模塊Fig.3 Bimodal feature fusion module
Qα=ZαWQ
(7)
Kβ=ZβWK
(8)
Vαβ=[Zα,Zβ]WV
(9)
式中:WQ∈Rdα×dq、WK∈Rdβ×dk、WV∈R(dα+dβ)×dv為線性變換的權重矩陣;dq、dk和dv分別為線性變化后的輸出維度,其中dk=dq=d。模態α和模態β的交互注意力可以使用式(10)計算。

(10)
式(10)中:Aαβ為注意力分數矩陣。
最后將Value與使用注意力分數加權后的Value相加,經過層歸一化(LayerNorm)后得到跨模態特征Yαβ,計算過程如式(11)所示。
Yαβ=LayerNorm(Vαβ+AαβVαβ)
(11)
數據經過兩兩組合輸入雙模態特征融合模塊,得到3組初步融合后的特征,在最后的融合階段,還需要將各個模態單獨的特征向量與這3組雙初步融合進行拼接,并輸入自注意力[17]計算模塊進行最后的融合計算。
1.3 解碼器
經過提取多模態特征并融合之后,需要對特征進行解碼獲得最終的輸出。如圖4所示,解碼器模塊則由三層全連接層完成動作特征到動作標簽的映射,采用的激活函數為線性整流單元(ReLU),并插入丟棄正則化層(Dropout)以防止過擬合。
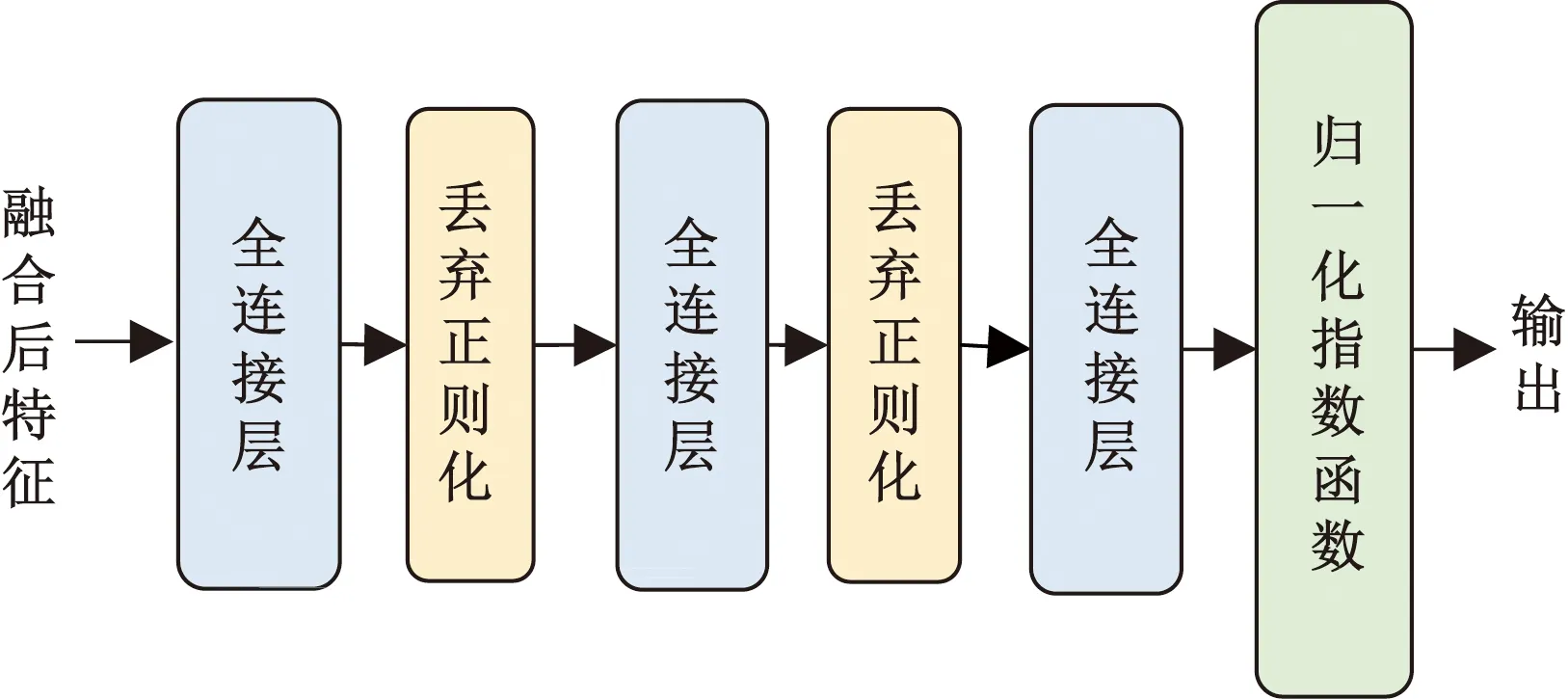
圖4 解碼器模塊結構圖Fig.4 Decoder module structure
2 連續動作分割識別實驗
2.1 數據采集與預處理
2.1.1 數據采集
為收集到能夠完整反映手術操作的動作數據,選擇光纖彎曲傳感器、光學定位系統和壓力傳感器等3種傳感器,分別收集醫生操作時的手指關節和手腕的活動、手部運動以及醫生手部與手術器械間的交互力。
數據收集實驗模擬真實的外科手術設計,以生理指標與人類較為相似的新鮮離體豬眼球作為數據收集模擬實驗的材料。數據采集如圖5所示,新鮮的離體豬眼球通過離體豬眼球固定基座固定在手術臺上,并與經過校準空間坐標的光學定位傳感器保持相對固定,3枚光學標記點,6枚光纖彎曲傳感器和2枚迷你型壓力傳感器分別安置在右手拇指、食指指尖、腕關節處,拇指、食指的近掌關節、指節關節和腕關節活動處,拇指、食指夾持手術器械的接觸點處,光纖彎曲傳感器安裝時需要注意軸線與手指關節軸線重合,以確保數據采集系統能收集到真實的動作數據。

圖5 數據采集Fig.5 Data acquisition
僅采集連續環形撕囊術操作,操作中眼科醫生右手持撕囊鑷,使撕囊鑷前端通過角膜緣切口進入眼球前房,用撕囊鑷尖端劃破晶狀體前囊膜并挑起可夾取的囊瓣,這一操作通常被稱為起瓣,隨后使用撕囊鑷尖端夾緊囊瓣并牽引囊膜沿圓形軌跡裂開,在牽引囊瓣中需要在合適的位置松開撕囊鑷并變更囊瓣夾取點,以確保撕囊過程中不失去對撕囊軌跡的控制,這一行為稱為換手,撕囊過程中牽引囊瓣和換手需要交替數次,直至撕囊結束后撕囊鑷夾持撕下的囊瓣并退出眼內空間。數據采集實驗分為4次,共計130組實驗,實驗中使用眼科顯微鏡記錄了手術中的圖像數據作為標記運動數據的依據,將動作數據標記為進入(I)、起瓣(MC)、換手(CP)、牽引囊瓣(T)、退出(O)共5種動作類型。最終篩選出用于驗證模型的數據共計29組,為17維變長時間序列。數據的構成比例如圖6所示,最大類T與最少類O之間的數量差接近10倍,為非平衡數據。
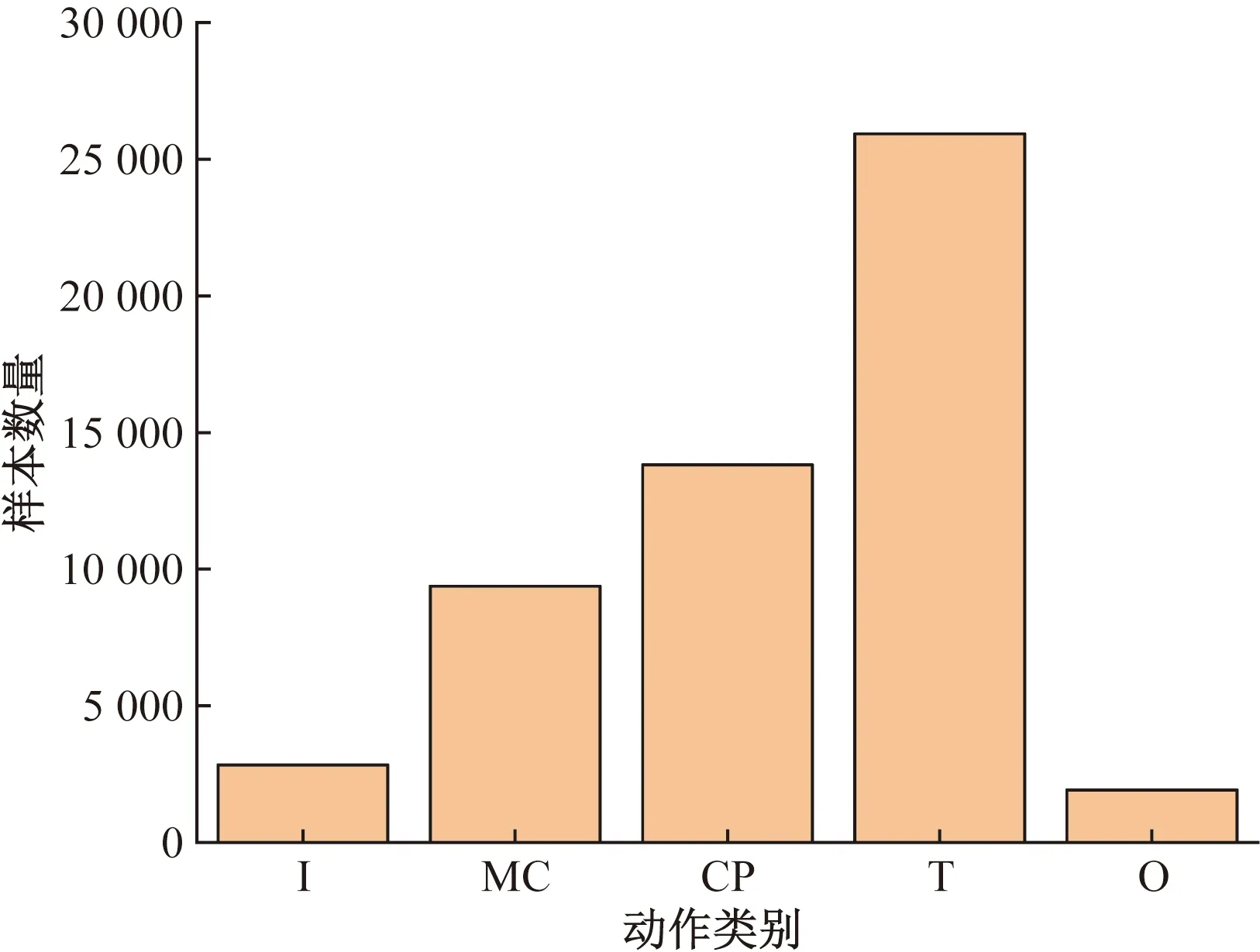
圖6 數據標簽比例Fig.6 Ratio of data labels
2.1.2 數據預處理
1)空間坐標轉換
因數據采集實驗共分4次進行,每次數據采集均需要重新校準光學定位儀的測量空間,因此每次實驗中的空間坐標系不一致,需要進行空間坐標的統一。利用布爾莎空間坐標轉換[式(12)和式(13)]將4次數據采集中獲得的手部運動數據轉換到統一的坐標系下。
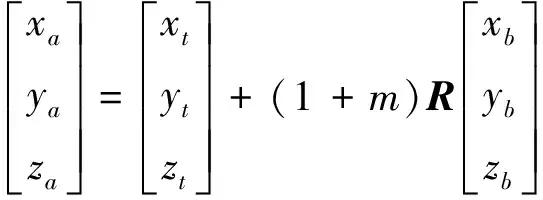
(12)
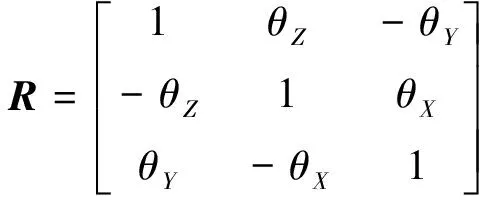
(13)
式中:(xa,ya,za)為坐標系A下某一點的三維坐標;(xb,yb,zb)為該點在坐標系B的三維坐標;(xt,yt,zt)為兩個坐標系間的平移參數;θx、θy、θz分別為坐標系B轉換到A時3個坐標軸的旋轉角度;R為空間坐標旋轉矩陣;m為坐標系轉換的比例參數。
2)時間域對齊
數據采集中使用的3種傳感器的采樣頻率接近但不一致,但是特征融合過程中必須按照時間匹配不同模態下的數據特征,因此需要建立一種時域對齊算法。光學定位傳感器的采集頻率為60 Hz,壓力傳感器的采集頻率為62 Hz,光纖彎曲傳感器的采集頻率為64 Hz,經過時域對齊后將3種數據的采集頻率統一為60 Hz,本時域算法的誤差小于等于4 ms,開始時輸入需要進行時域對齊的數據A與數據B各一組,數據A和數據B分別為長度為L1和L2的多維時間序列,以其中采樣率更低的數據的時間戳作為時域對齊的基準,假定數據A的采樣率更低,則將yti記為ti時刻的數據B,(i=0,1,…,L1)。記tj時刻的數據A為xtj,(j=0,1,…,L2)。遍歷數據A的時間戳數據,計算時間戳之間的誤差Δt=|ti-tj|,若Δt≤4 ms,則將xtj記錄為[xtj,yti]。若4 ms<Δt≤12 ms,則記錄xtj=[xtj,0.5(yti+yti±1)],若Δt>12 ms,則記錄xtj=[xtj,yti±1],其中的±由ti和tj的大小決定,若ti>tj則取負號,反之則取正號。
3)歸一化
為了保證數據特征的有效提取,加快訓練過程中模型的收斂速度,采取標準化將原始數據規范到標準分布。標準化計算如式(14)所示。
z=(x-μ)/σ
(14)
式(14)中:z為標準值;x為原始數據;μ為平均值;σ為標準差。
2.2 模型效果驗證
2.2.1 實驗環境與訓練策略
所提出的模型基于PyTorch平臺搭建(GPU: NVIDIA TITAN XP, RAM: 4×12 G, Driver Version: 515.65.01, CUDA Version: 11.7)。訓練中所有的模型中均使用Adam優化器,大小為1×10-5的L2正則化因子,dropout概率為0.2,損失函數使用交叉熵。訓練中將數據集劃分為訓練數據集和測試數據集,超參數的選擇部分使用十折交叉驗證,訓練數據集被劃分成為10個子集,每次取9個子集用于訓練模型,1個子集用于驗證模型。模型對比實驗中的評估指標包括分類準確度,每一類的F1分數,以及全局F1分數,全局F1分數表示模型整體的F1分數。提到的所有評估指標均由混淆矩陣計算得到。
2.2.2 基線模型與模型對比實驗
選擇的基線模型共計7種,其中①~③為數據層融合模型,隱藏元數量均設置為16,學習率均設置為0.001,總訓練次數為150,3個模態的原始數據經過預處理及標準化后直接按照維度拼接,隨后直接輸入基線模型,經全連接層降維后輸出分類結果;④~⑦為特征層融合模型,學習率為0.001,總訓練次數為350,分為特征提取部分與特征融合部分,特征提取均由隱藏元數量為16的單層長短時記憶網絡完成,融合后特征通過使用dropout策略的全連接層輸出分類結果。
7種基線模型詳細介紹如下:①LSTM(單層及雙層);②Bi-LSTM(單層);③GRU(單層);④LSTM-CONCAT,CONCAT為拼接算子,表示經特征提取單元提取的各模態特征通過拼接獲得融合后特征;⑤LSTM-ADD,ADD為帶有可學習權重的加法算子,表示經特征提取單元提取的各模態特征通過求加權和獲得融合后特征;⑥LSTM-TFN,TFN[11]是基于矩陣運算的特征融合算法,來自不同模態的特征矩陣的笛卡爾積作為融合后特征;⑦LSTM-LWF,LWF[12]是基于低秩矩陣分解的特征融合算法,將權重矩陣分解為低秩因子,低秩因子與特征相乘后累加獲得融合后特征。
模型對比試驗結果如表1及表2所示。由表1和表2中的數據可知,對比基線模型,提出的模型能夠取得最高的準確率和全局F1分數,在每一類的分類中也取得了最佳的F1分數,同時對類別O的分類效果提升尤其明顯,說明通過提取深度動作數據特征可以緩解樣本數量少難以學習帶來的分類精度不高的問題。特征融合模型由于特征提取部分完全一致,可以直觀地比較融合算法的效果,帶權重的加法算子優于拼接算子,LWF算法優于TFN算法。另外,由于總體數據量有限,當模型為雙層堆疊的LSTM時出現了嚴重的過擬合現象,分類效果與單層的LSTM相比準確率下降了3%,進入(I)和退出(O)的分類F1分數下降了15%以上。說明數量有限時提升模型參數量反而會使分類效果下降,但提出的模型中使用了3層堆疊的Bi-LSTM,理論模型參數遠大于基線模型,仍能取得最佳的分類成績,充分說明了所提出的模型具備結構上的合理性。
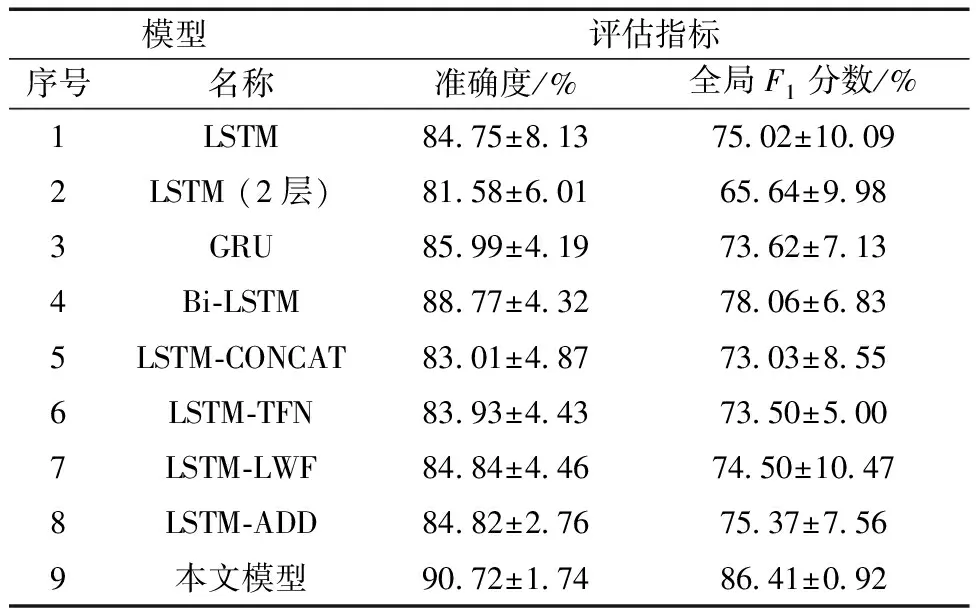
表1 模型分類效果評估
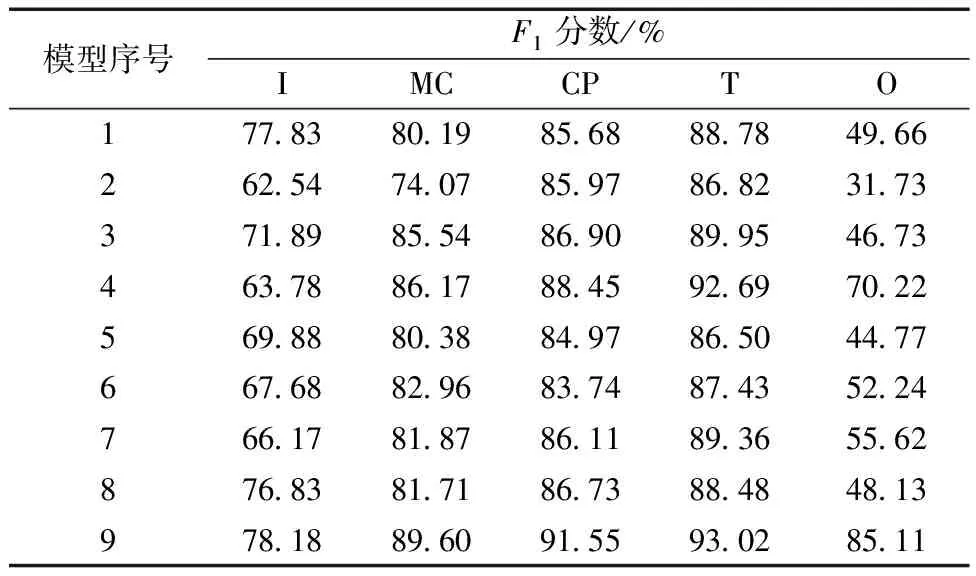
表2 5種動作類型F1分數
2.2.3 超參數調整
為找出最適合模型的超參數組合,對學習率以及L2正則化因子兩個超參數進行網格搜索,超參數搜索結果如圖7與圖8所示,F1分數受學習率影響較大,而準確度受超參數影響較小,學習率為0.009時,模型能取得最佳的分類準確率與F1分數。L2正則化因子為1×10-5時的準確度最高。
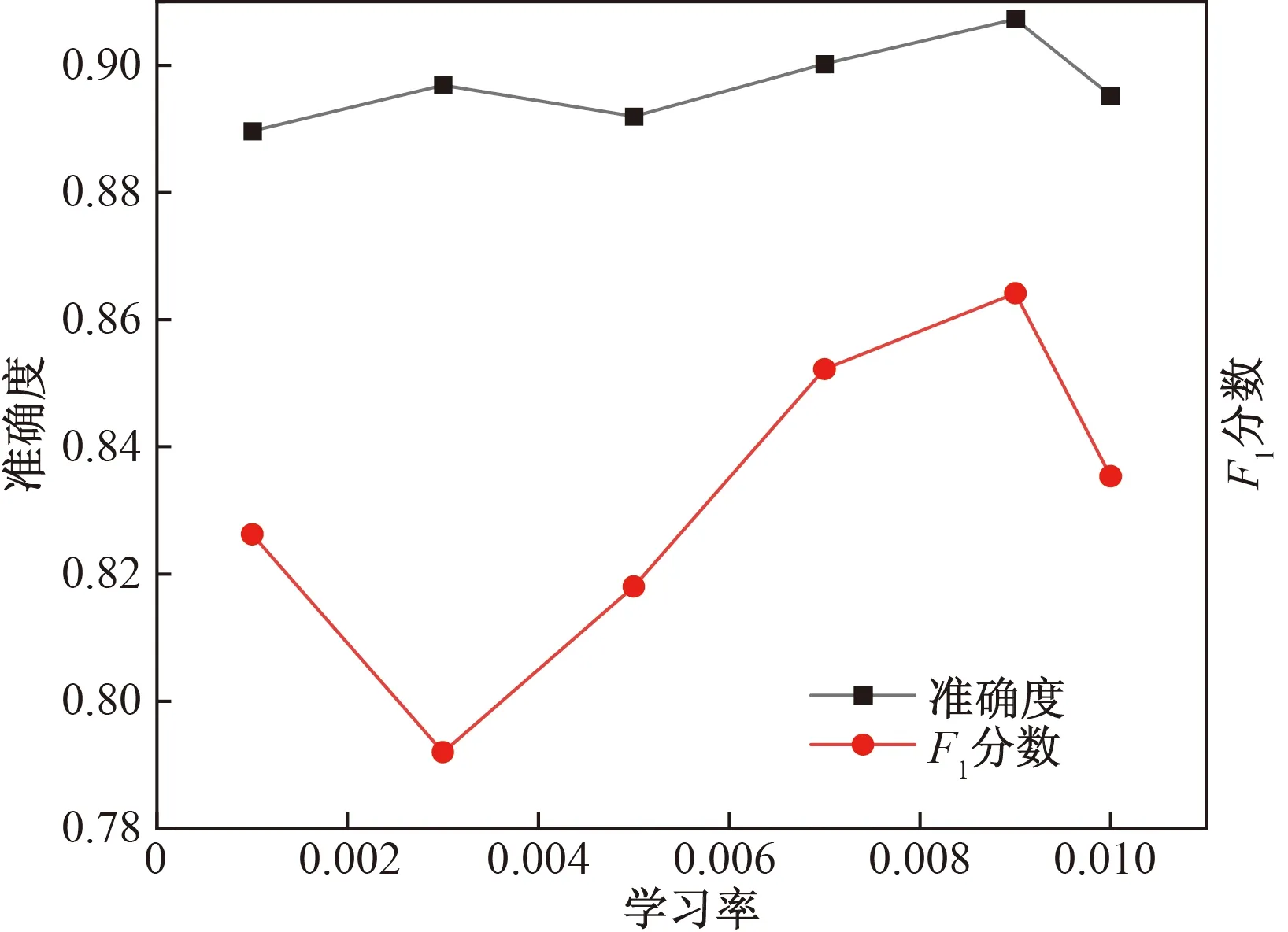
圖7 學習率-分類指標曲線Fig.7 Learning rate-classification indicators curve
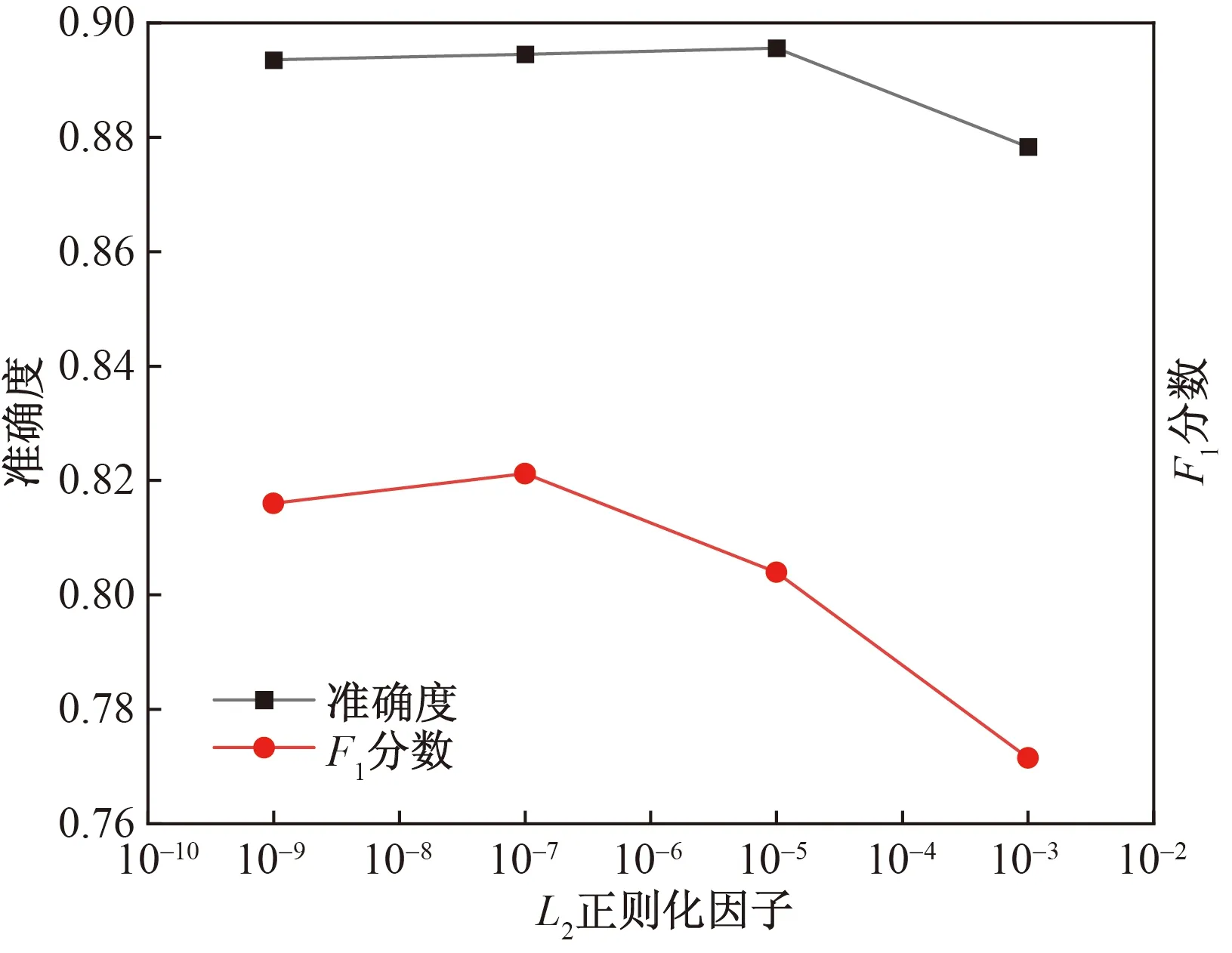
圖8 L2正則化因子-分類指標曲線Fig.8 L2 regularization factor-classification indicators curve
2.2.4 模型輸出結果可視化
對測試樣例的模型輸出的動作序列以及真實動作序列進行可視化對比,如圖9所示,將動作標簽映射為不同的色塊,上側序列為真實動作序列,下側為模型輸出的動作分類序列。對照顏色分布,所提出的模型識別出的動作序列與真實序列基本保持一致,序列中,眼科醫生在此次操作中共執行了5次換手及牽引囊瓣操作,撕下囊瓣后退出眼內空間。第三次換手動作和牽引囊瓣動作以及最后一次牽引囊瓣到退出兩次動作轉換銜接處出現較多的判斷失誤,推斷原因為動作轉換處特征區分不大,較易誤判。總體來看,提出的模型能夠完成連續動作序列分割與識別任務。

圖9 模型輸出可視化結果Fig.9 The visualization of model’s output action sequence
2.2.5 不同損失函數下的分類效果對比
為驗證提出模型使用不同損失函數時的分類效果,使用兩種針對數據集不平衡開發的損失函數進行測試,測試結果如表3和表4所示,WCE能夠提高模型的全局F1分數,而準確度出現輕微下降,說明帶權重的損失函數確實提高了模型分類的平衡性,但不同類的F1分數卻出現了較為有趣的現象,WCE和FL提高了少數類I的分類效果,但對少數類O的分類效果并不突出,其他多數類的分類效果也出現下降。
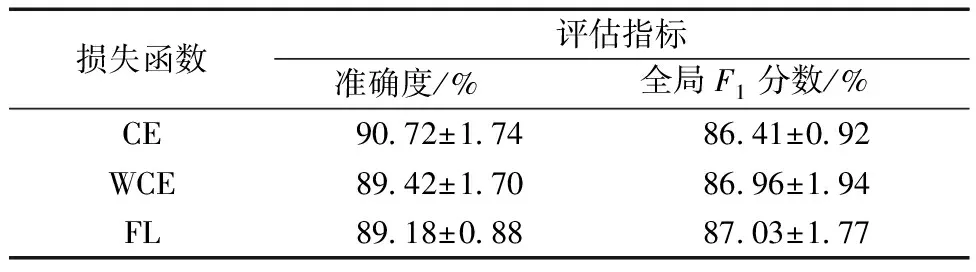
表3 3種損失函數下的分類效果
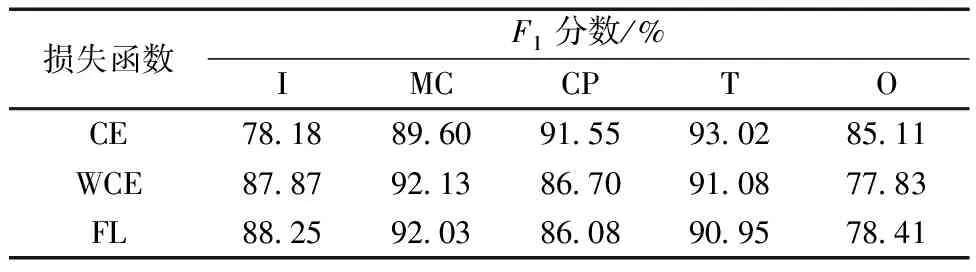
表4 3種損失函數下的5種動作類型F1分數
3 結論
針對數據集不平衡下的多分類問題與連續動作序列中的動作識別與分割問題,提出一種端到端多模態時間序列分割模型,此模型采用編碼器-解碼器結構,編碼器用于提取數據特征并融合,解碼器將融合后的特征映射到分類標簽。在編碼器中提出一種新的數據提取模塊和一種新的雙模態數據融合機制,可以有效提取多傳感器數據的時域特征并進行有效的融合。同時,通過多傳感器數據采集平臺采集了多傳感器連續環形撕囊術操作數據,利用該數據對所提出的模型進行驗證,實驗結果證明所提出的模型可以有效分割出連續手術操作中醫生的各個動作,并且能夠處理數據集標簽分布不平衡情況的多分類問題,實驗數據顯示,所提出的模型在模型效果對比實驗中取得了90.72%的準確率,優于基線模型。實驗同時對比了不同損失函數下的模型分類效果,同樣取得最優的分類準確率,結合可視化結果,充分證明了所提出模型的有效性。
在研究中得到以下結論。
(1)數據量較小時擴增模型參數量會導致過擬合,影響分類效果。
(2)提升特征提取的深度和粒度能夠有效改善樣本數量少帶來的分類困難。
(3)提出的模型夠有效提取并融合來自多模態數據的深度特征,有效提升分類效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
上海電機學院學報(2015年4期)2015-02-28 14:30:00
