一種基于光學字符識別技術的超聲報告自動化生成方法
2023-11-11 09:54:46黃友清楊輝虎魏達友羅文高張翠萍
醫療裝備 2023年19期
黃友清,楊輝虎,魏達友,羅文高,張翠萍
茂名市人民醫院 (廣東茂名 525100)
隨著計算機和醫學技術的發展,大部分醫院的超聲診斷儀均配備了圖文報告系統,超聲醫師可使用計算機編寫超聲報告。但近年來各醫院超聲檢查申請量不斷增加,造成超聲醫師的工作量逐漸增多[1]。編寫超聲報告在超聲醫師所有工作耗時中占比較大,部分醫院甚至為其配備了專門的報告助理,但使用超聲報告助理會增加醫院人力成本;此外,受專業知識、教育背景及超聲系統操作熟練程度等因素影響,超聲報告助理并不能快速、準確地輸出高質量超聲報告,若錄入速度跟不上檢查進度,還需超聲醫師進行二次檢查,影響工作效率[2]。超聲醫師(無助理)通常的工作流程如下:在檢查過程中采集具有病變信息及測量數據的圖像,完成檢查后,根據記憶及采集到的圖像回顧性生成報告。該超聲報告編寫方式不僅浪費時間,還可能因人為因素造成數據遺漏或輸入錯誤。基于此,石磊等[3]提出了一種基于光學字符識別技術的超聲報告數值自動讀取方法,通過連通區域檢測、數值區域提取、數值行劃分、文字識別、超聲報告自動生成等環節,最終實現了超聲報告數值自動讀取。該方法可取代醫師手動輸入超聲報告數值,避免人為錄入數據可能造成的錯誤,提高數據準確率及超聲醫師工作效率。本研究在上述研究的基礎上,使用具有觸摸屏的超聲診斷儀,在檢查的同時添加超聲診斷注釋,獲取超聲診斷及測量兩方面的信息,實現了計算機自動化生成超聲報告。
1 基于光學字符識別技術的超聲報告自動化生成方法的構建
1.1 設置超聲診斷儀觸摸屏上的注釋
使用Philips iU22 彩色多普勒超聲診斷儀,該設備的每個預設條件含2 張注釋頁,即完整診斷注釋(圖1)和組合診斷注釋(圖2),注釋項內容以拼音首字母表示,共56 個項目。在完整診斷注釋頁中設置常用的完整診斷,并可組合數字1、2、3,用于表示輕、中、重不同的程度;在組合診斷注釋頁中設置部位、病變、類型及位置,用于組合為完整的診斷注釋項。通過以上兩種方式生成常見的超聲診斷注釋。

圖1 觸摸屏上的完整診斷注釋(局部)

圖2 觸摸屏上的組合診斷注釋(局部)
1.2 配置超聲工作站
超聲工作站使用聯想啟天M430-B451 臺式計算機,操作系統為Windows 10,光學字符識別工具為Tesseract 4.1,編程工具為Python 3.6,使用SQLite 數據庫儲存超聲報告模板。超聲工作站使用南方醫科大學研制的超聲圖文報告系統。采集卡為MZ0380 PCI,輸入圖像的分辨率為1 680×1 050 像素;該報告系統可截取1 024×800 像素的圖像,并儲存于超聲工作站中。
1.3 建立超聲報告模板數據庫
超聲報告模板數據庫主要包含注釋項、超聲描述、超聲提示、檢查部位、操作方式等字段。注釋項為數據庫中的關鍵字段,用于檢索相應的超聲描述和超聲提示等內容。超聲描述和超聲提示是超聲報告的2 個重要組成部分,其中的大部分內容是固定不變的,對于可變部分內容,需于相應位置標記錨點,在生成報告時,替換為相應的位置、測量數據等內容。檢查部位用于加載默認模塊,生成正常報告。操作方式是根據不同的需要,在正常報告中進行覆蓋、替換、插入等。
1.4 文字識別
通過Python 程序逐張讀取當前檢查采集到的所有圖像,截取其中含有注釋字符及測量數據的部分圖像(注釋字符及測量數據在圖像中的位置是固定的),將截取的圖像進行簡單的二值化處理,即可使用Tesseract 軟件進行識別,再將得到的結果處理為相應的報告處理指令行。
1.5 自動生成超聲報告
在超聲檢查中,若遇到異常圖像,可在其中加入注釋;若需具體信息,可進行測量,測量結果顯示后,可采集圖像。檢查結束后,啟動編制的Python 程序,讀取圖像中的字符信息,根據識別出的診斷性文字在數據庫中檢索相應的報告模板,若包含測量數據,則將測量數據插入報告模板的相應位置,生成報告處理指令行,然后根據各項報告處理指令行自動化生成報告,通過接口輸出至超聲圖文報告系統中。采集的圖像及處理流程示例見圖3~4。
圖3 采集的圖像
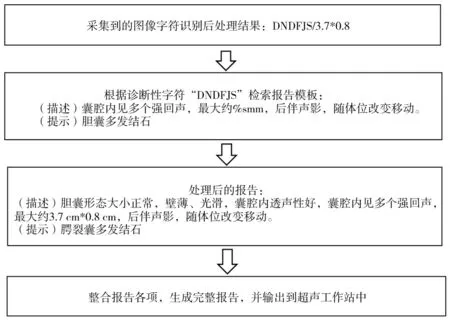
圖4 處理流程示例
2 應用效果
2.1 報告選取
選取我院超聲診斷科2022 年1 月17—21 日(5 個工作日)完成的361 例超聲檢查評價本研究超聲報告自動生成方法的應用效果。其中,心臟檢查198 例(心臟超聲、左心功能測定各99 例),腹部超聲檢查72 例,血管超聲檢查50 例,其他超聲檢查41 例。
2.2 評價方法
同一名超聲醫師在完成檢查后分別以手工處理(超聲醫師通過工作站中已設定常用報告模板、輸入法中已定義常用語句及詞組編寫報告)和自動化處理2 種方法生成超聲報告,并比較兩種報告處理方法的生成報告時長及點擊次數。此外,隨機選取其中的36 份超聲檢查結果,以采集圖像上的字符為參照,分析自動化處理方法的字符識別正確率。
2.3 統計學處理
采用SPSS 18.0 統計軟件進行數據分析。計量資料以±s表示,采用t檢驗。P<0.05 為差異有統計學意義。
2.4 結果
2.4.1 兩種報告處理方法的生成報告時長及點擊次數比較
自動化處理方法的報告時長短于手工處理方法,點擊次數少于手工處理方法,差異均有統計學意義(P<0.05),見表1。
表1 兩種報告處理方法的生成報告時長及點擊次數比較(±s,361 例)
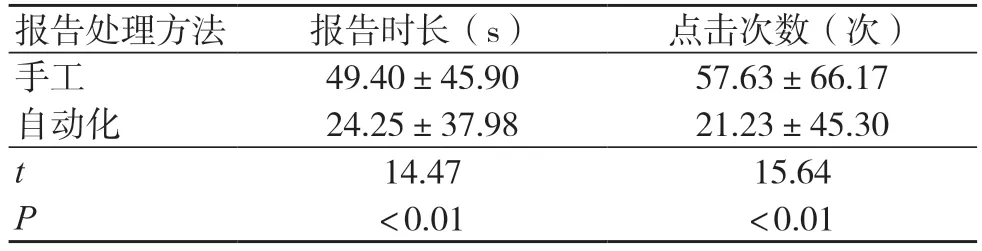
表1 兩種報告處理方法的生成報告時長及點擊次數比較(±s,361 例)
報告處理方法 報告時長(s) 點擊次數(次)手工 49.40±45.90 57.63±66.17自動化 24.25±37.98 21.23±45.30 t 14.47 15.64 P<0.01 <0.01
2.4.2 字符識別正確率
36 例超聲檢查圖像中,使用光學字符識別技術識別出感興趣區字符3 875 個,正確3 875 個,錯誤0 個,識別正確率為100%。
3 討論
人工智能是在計算機科學、控制論、信息論、神經心理學、哲學、語言學等多學科基礎上發展而來的一門綜合性較強的交叉學科,涉及新思想、新觀念、新理論、新技術[4-7]。近年來,人工智能發展迅速,已在醫學領域得到了廣泛應用,如輔助讀片系統、醫學專家系統、計算機輔助藥物設計及醫學機器人等。光學字符識別是一種電子字符識別技術,為人工智能在計算機視覺領域的重要應用之一。該技術利用光學和計算機技術通過檢測字符每個像素的暗、亮模式確定其形狀,然后用字符識別方法將形狀翻譯為計算機文字[8]。Tesseract 是一款由惠普實驗室開發,谷歌公司維護的開源光學字符識別引擎,其是少有的支持漢字識別的開源庫[9]。Tesseract 從4.0 版本開始采用了基于Long Short Term Memory(LSTM 網絡)的識別引擎,用戶可通過不斷訓練自己的數據庫,使圖像轉換為文本的能力不斷增強。
超聲報告用于描述超聲檢查的結果,可為醫師診斷及治療疾病提供重要依據。目前,超聲報告從手工編寫階段步入了計算機編寫階段,編寫逐漸規范、快捷,但由于超聲報告較復雜,常規計算機編寫報告方式仍需耗費超聲醫師大量時間和精力,且易出現錯誤。因此,自動生成超聲報告的技術受到了廣泛關注。
現階段,語音識別及光學字符識別是超聲報告自動化生成中常采用的2 種技術。語音識別技術發展較早,在實際應用時暴露出以下缺點:(1)識別準確率暫未達到95% 的預期效果;(2)環境噪聲對識別準確率影響較大[10-11];(3)需再次單獨使用語音重復測量數據,費時費力;(4)醫師的語音內容被患者聽到后可能會使其產生誤解。而光學字符識別技術發展亦較為成熟,若采集到的圖像分辨率較高,字符為規則字體,則可高效、準確識別。若采集到的圖像不清晰,會影響識別正確率,需對圖像進行處理,以提高正確率。此外,還可建立字符識別庫,并對識別過程進行訓練,隨著訓練樣本量的增加,正確率也會逐漸提高。與語音識別技術比較,光學字符識別技術具有以下優點:(1)準確率較高,一般可接近100%;(2)使用簡單、便捷,只需安裝Tesseract 即可;(3)不受超聲檢查環境影響;(4)對于測量數據的識別,可以直接得到結果;(5)不會對患者造成影響。
本研究應用效果顯示,自動化處理方法的報告時長短于手工處理方法,點擊次數少于手工處理方法,且識別正確率為100%。與手工處理方法比較,以5 個工作日為計算單位,自動化處理方法節省了50.9%的超聲報告編寫時間(9 079 s,即2.52 h,平均每天可節省0.50 h),減少了63.2%的報告編寫工作量。
本研究改進的基于光學字符識別技術的超聲報告自動化生成方法仍存在以下問題:(1)不同廠家、型號超聲診斷儀測量數據及注釋的顯示方式各不相同,不同醫院采用的超聲報告系統各異,本方法需具備一定計算機基礎的醫師或專業的計算機工作人員對超聲診斷儀及超聲圖像報告系統進行適配后才可使用,推廣受限,但其適配過程并不復雜;(2)部分超聲診斷儀無觸摸屏,或有觸摸屏但不便設置觸摸屏上的注釋,可通過平板電腦解決此問題,該方法在本項目后期已得到實現,且效果很好;(3)部分報告無法完全自動化生成,需輔以手工編寫方法完成,造成該問題的主要原因為觸摸屏設置及報告模板不完善,可予以改進。
綜上所述,使用光學字符識別技術獲取超聲圖像中的字符信息,可完成超聲報告自動化編寫工作,減少超聲醫師工作量,提高工作效率。若計算機專業相關人員共同參與超聲報告自動化生成技術的改進,該項技術可更加完善,或將取代超聲報告助理的相關工作。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
南方人物周刊(2017年32期)2017-10-28 22:48:36
南風窗(2016年26期)2016-12-24 21:48:09
Coco薇(2016年2期)2016-03-22 02:42:52
南風窗(2015年22期)2015-09-10 07:22:44
南風窗(2015年14期)2015-09-10 07:22:44
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
南風窗(2015年7期)2015-04-03 01:21:48
