面向天地融合網(wǎng)絡(luò)的無線資源智能分配方法
2023-11-13 09:36:44魏強(qiáng)廖瑛徐瀟審郝媛媛任術(shù)波張千繆中宇辛寧
航天器工程 2023年5期
魏強(qiáng) 廖瑛 徐瀟審 郝媛媛 任術(shù)波 張千 繆中宇 辛寧
(1 國防科技大學(xué) 空天科學(xué)學(xué)院,長沙 410073)
(2 中國空間技術(shù)研究院通信與導(dǎo)航衛(wèi)星總體部,北京 100094)
(3 中國人民解放軍32039部隊,北京 102300)
隨著通信需求向多空間、多方位的不斷擴(kuò)展,以及天基、空基、海基、地基等各種網(wǎng)絡(luò)服務(wù)的不斷涌現(xiàn)[1],構(gòu)建全球覆蓋、隨遇接入、按需服務(wù)的天地融合網(wǎng)絡(luò)是通信發(fā)展的重要趨勢[2]。天地融合網(wǎng)絡(luò)充分利用天基網(wǎng)絡(luò)和地基網(wǎng)絡(luò)在不同空間維度上的優(yōu)勢,不斷突破網(wǎng)絡(luò)邊界限制,在實現(xiàn)多維網(wǎng)絡(luò)互聯(lián)互通的同時為用戶提供全時全域的信息服務(wù)。然而,建設(shè)天地融合網(wǎng)絡(luò)需要大量的頻譜資源來滿足通信需求,而頻譜資源是有限且不可再生的,因此,設(shè)計天地融合網(wǎng)絡(luò)的無線資源智能分配方法,提高頻譜資源利用率,成為天地融合通信系統(tǒng)中亟需解決的關(guān)鍵難題之一[3]。
為了對有限頻譜資源進(jìn)行高效利用,文獻(xiàn)[4]中提出了天地融合網(wǎng)絡(luò)中的認(rèn)知無線電技術(shù),通過衛(wèi)星網(wǎng)絡(luò)與地面網(wǎng)絡(luò)之間的頻譜資源共享提升頻譜資源的利用率。認(rèn)知無線電技術(shù)旨在根據(jù)無線電環(huán)境調(diào)整參數(shù)以動態(tài)接入可用頻譜,具體來說,該技術(shù)允許未授權(quán)的衛(wèi)星用戶在不中斷已授權(quán)地面用戶通信的情況下訪問未使用的頻譜。根據(jù)授權(quán)用戶(地面用戶)和認(rèn)知用戶(衛(wèi)星用戶)的頻譜資源占用情況,認(rèn)知無線電技術(shù)可以分為覆蓋(Overlay)模式、底墊(Underlay)模式,以及兩者混合(Hybrid)模式[5]。Underlay模式允許授權(quán)用戶與認(rèn)知用戶同時使用同一頻段,但要求認(rèn)知用戶對授權(quán)用戶的干擾處于一個可接受的范圍;在Overlay模式下,認(rèn)知用戶通過頻譜空洞探測結(jié)果來決定是否接入授權(quán)用戶已經(jīng)占用的信道,以避免對授權(quán)用戶產(chǎn)生干擾;Hybrid模式即為Overlay模式與Underlay模式兼?zhèn)涞哪J健榱俗畲蟪潭鹊靥岣哳l譜利用率,本文采用Underlay模式實現(xiàn)天地融合網(wǎng)絡(luò)中的可用頻譜動態(tài)接入,即:如果衛(wèi)星用戶引起的干擾低于地面用戶預(yù)定義的干擾閾值,則允許并行傳輸。但是,對于授權(quán)頻譜的二次利用方式,可能會導(dǎo)致嚴(yán)重的同頻干擾問題,這對資源分配提出了嚴(yán)峻的挑戰(zhàn)。
近年來,利用認(rèn)知無線電技術(shù)深入研究天地融合網(wǎng)絡(luò)中的頻譜資源利用問題,在一體化頻譜感知、共享與管理方面已獲得一定的研究成果。文獻(xiàn)[6]中提出了一種基于衛(wèi)星和基站協(xié)作的頻譜感知方案,利用模糊神經(jīng)網(wǎng)絡(luò)確定最佳檢測概率。文獻(xiàn)[7]中研究了基于云的衛(wèi)星和地面頻譜共享網(wǎng)絡(luò),并提出了基于認(rèn)知無線電的智能頻譜共享方案,以減少用戶阻塞率和等待概率。但是,在實時操作中,頻繁的切換導(dǎo)致衛(wèi)星網(wǎng)絡(luò)的通信環(huán)境高度動態(tài)且復(fù)雜多變,難以用數(shù)學(xué)模型來建模和求解。為了解決該問題,有些研究嘗試將強(qiáng)化學(xué)習(xí)與認(rèn)知無線電網(wǎng)絡(luò)集成,以獲得最佳的資源管理策略。文獻(xiàn)[8]中提出一種認(rèn)知無線電物聯(lián)網(wǎng)(CR-IoTNet)框架,該框架將物聯(lián)網(wǎng)與認(rèn)知無線電技術(shù)融合,通過采用支持向量機(jī)(SVM)算法分析傳輸數(shù)據(jù)的潛在特征,以獲取傳輸網(wǎng)絡(luò)的頻譜狀態(tài)信息,更加智能地管理和優(yōu)化頻譜資源的利用。文獻(xiàn)[9]中利用認(rèn)知無線電技術(shù)提出一種衛(wèi)星通信的動態(tài)頻譜接入方法,采用雙深度(Q-learning)神經(jīng)網(wǎng)絡(luò)來自主感知當(dāng)前頻譜資源狀況并學(xué)習(xí)資源感知分配策略,實現(xiàn)頻譜利用率的提升。但是,以上研究將通信環(huán)境視為完全未知的,忽視了網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)信息的重要性,在大規(guī)模通信網(wǎng)絡(luò)中可能會出現(xiàn)性能下降甚至是失效的情況。
針對上述問題,本文將天地融合網(wǎng)絡(luò)建模為動態(tài)圖結(jié)構(gòu),將信號鏈路視為節(jié)點,干擾鏈路視為邊,利用圖結(jié)構(gòu)來保存通信環(huán)境中的時空拓?fù)湫畔?為資源分配提供先驗知識。然后,提出一種應(yīng)用圖卷積網(wǎng)絡(luò)深度強(qiáng)化學(xué)習(xí)的無線資源分配方法,利用智能體與通信環(huán)境之間的交互,自主感知頻譜資源狀態(tài)并探索最優(yōu)的信道選擇和功率調(diào)整策略,在實現(xiàn)衛(wèi)星網(wǎng)絡(luò)和地面網(wǎng)絡(luò)之間頻譜共享的同時提高天地融合網(wǎng)絡(luò)的頻譜資源利用率。
1 場景建模與問題優(yōu)化
1.1 系統(tǒng)模型
本文針對天地融合網(wǎng)絡(luò)的下行傳輸過程進(jìn)行研究,系統(tǒng)模型如圖1所示,由地面基站b∈{1,2,…,B}和每個基站服務(wù)的地面用戶u∈{1,2,…,U}構(gòu)成的地面網(wǎng)絡(luò)為主網(wǎng)絡(luò),由地球靜止軌道(GEO)衛(wèi)星s∈{1,2,…,S}和每顆衛(wèi)星服務(wù)的衛(wèi)星用戶v∈{1,2,…,V}構(gòu)成的認(rèn)知衛(wèi)星網(wǎng)絡(luò)為次網(wǎng)絡(luò),其中,B為地面基站數(shù),U為地面用戶數(shù),S為衛(wèi)星數(shù),V為衛(wèi)星用戶數(shù)。地面用戶作為主用戶,通常配備單副天線與基站通信;衛(wèi)星用戶作為次級用戶,采用定向天線與GEO衛(wèi)星進(jìn)行通信。此外,本文假設(shè)衛(wèi)星用戶采用Underlay模式與地面用戶共享頻譜資源,系統(tǒng)中的總帶寬為W,頻譜資源由集合n∈{1,2,…,N}表示,N為子信道的數(shù)量。
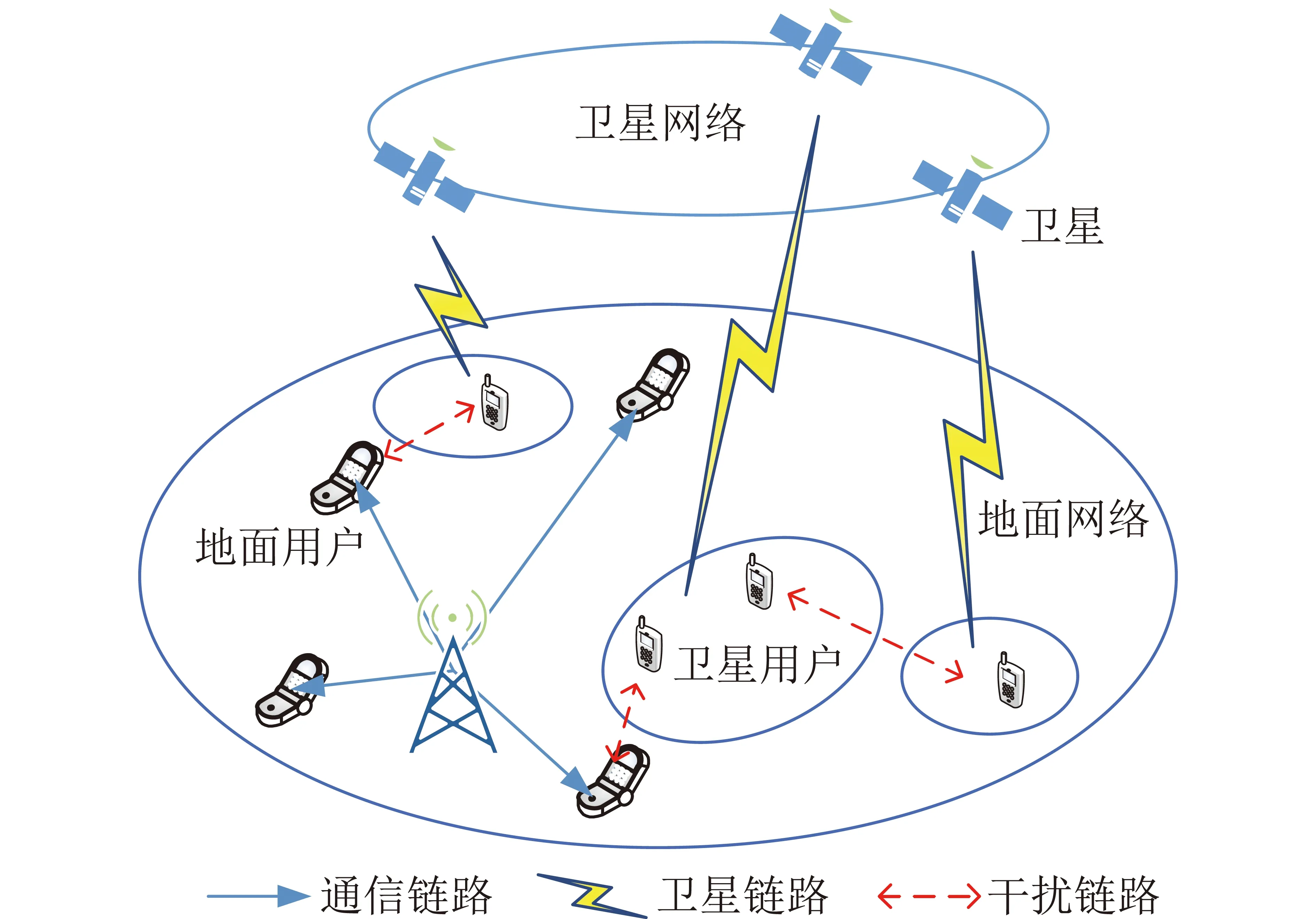
圖1 系統(tǒng)模型Fig.1 System model
1.2 信道模型
在天地融合網(wǎng)絡(luò)中存在2種類型的下行鏈路。①GEO衛(wèi)星與衛(wèi)星用戶之間的傳輸鏈路,采用自由空間傳播模型;②基站與地面用戶之間的傳輸鏈路,采用對數(shù)正態(tài)(Log-normal)陰影模型。
1)衛(wèi)星用戶信道模型
考慮自由空間損耗的影響,衛(wèi)星用戶下行鏈路的信道增益表示為
(1)
式中:GR為用戶接收天線增益;Gs,v為第s顆衛(wèi)星到第v個用戶的天線增益;ds,v為衛(wèi)星與用戶之間的距離;λ為工作波長。
2)地面用戶信道模型
考慮到陰影衰落和路徑損耗的影響,基站與用戶下行鏈路信道增益可以表示為
(2)
式中:K為陰影效應(yīng)的隨機(jī)變量;f為信道的中心頻率;L為信道模型的校正參數(shù);db,u為用戶和基站之間的距離;α為路徑損耗指數(shù)。
3)系統(tǒng)容量
在天地融合網(wǎng)絡(luò)中,衛(wèi)星用戶與地面用戶共享同一信道時會相互干擾。對于地面用戶來說,其主要干擾來源為次網(wǎng)絡(luò)中的衛(wèi)星用戶。假設(shè)衛(wèi)星用戶和地面用戶共享相同的資源塊n,則地面用戶u在資源塊n上遭受的干擾為
(3)
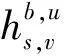
地面用戶u的數(shù)據(jù)速率為
(4)
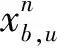
對于衛(wèi)星用戶來說,它會受到來自地面用戶的干擾,以及其他次網(wǎng)絡(luò)中的衛(wèi)星用戶的干擾。類似地,假設(shè)衛(wèi)星用戶和地面用戶共享相同的資源塊n,衛(wèi)星用戶v的干擾為
(5)
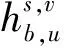
第v個衛(wèi)星用戶在資源塊n上的數(shù)據(jù)速率為
(6)
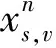
綜上所述,天地融合網(wǎng)絡(luò)的系統(tǒng)總數(shù)據(jù)速率為
(7)
1.3 優(yōu)化問題
本文的優(yōu)化目標(biāo)為:在保證主用戶通信不受影響的前提下,最大化整體網(wǎng)絡(luò)系統(tǒng)容量,因此優(yōu)化問題可表達(dá)為
(8)
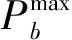
2 無線資源智能分配方法
本節(jié)提出了一種應(yīng)用圖卷積網(wǎng)絡(luò)深度強(qiáng)化學(xué)習(xí)的無線資源智能分配方法,流程如圖2所示。
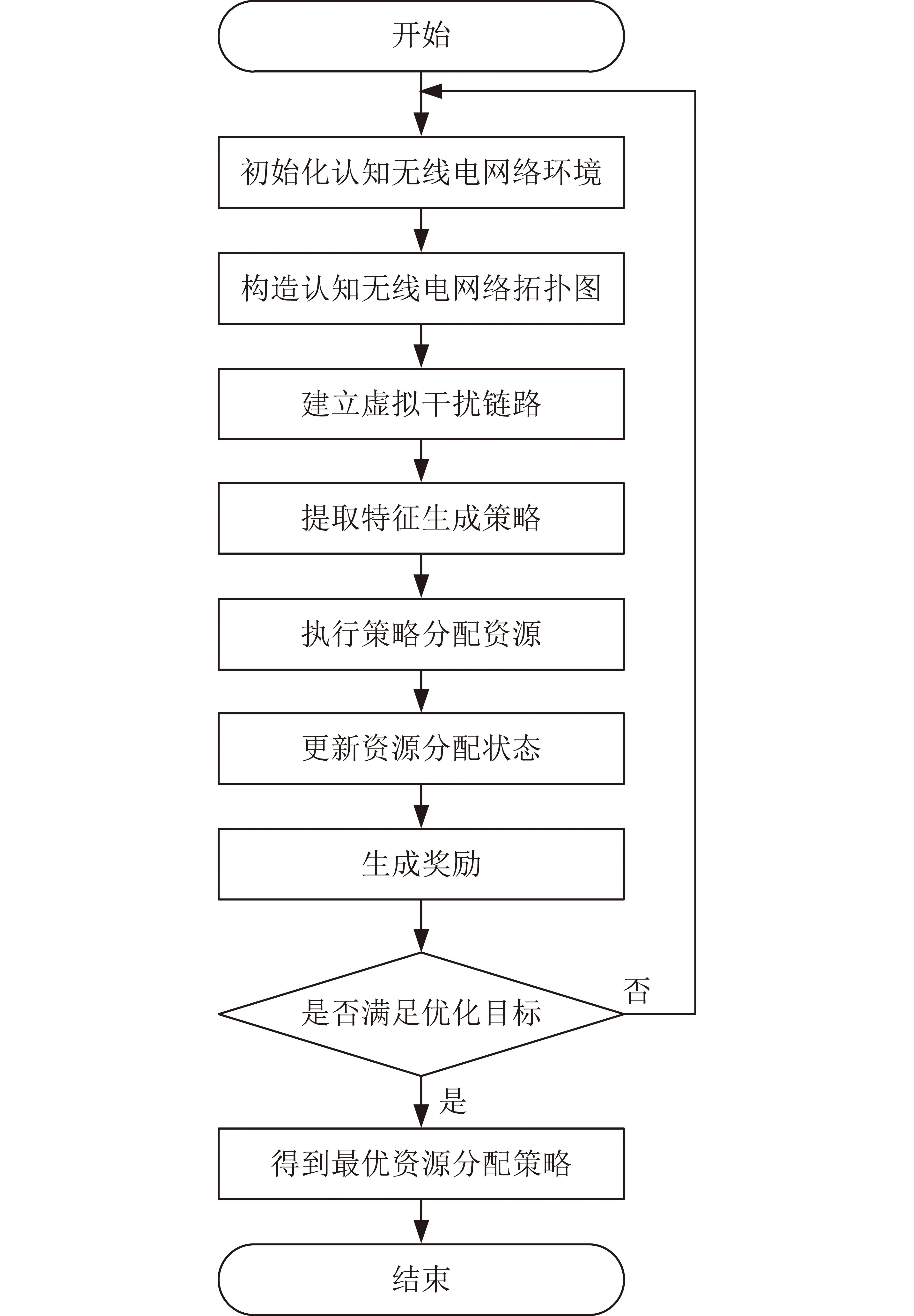
圖2 方法流程Fig.2 Method flow
在無線資源智能分配方法中,首先,初始化無線電網(wǎng)絡(luò)環(huán)境,利用動態(tài)圖結(jié)構(gòu)來構(gòu)建天地融合網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)模型和虛擬干擾鏈路;然后,設(shè)計應(yīng)用圖卷積網(wǎng)絡(luò)的深度強(qiáng)化學(xué)習(xí)端到端模型,通過特征提取生成資源分配策略;接著,執(zhí)行上述策略,得到當(dāng)前的資源分配狀態(tài);最后,通過獎勵計算判斷是否滿足優(yōu)化目標(biāo),并重復(fù)上述過程直到學(xué)習(xí)到最優(yōu)的資源分配策略。
2.1 應(yīng)用動態(tài)圖結(jié)構(gòu)的通信環(huán)境拓?fù)淠P蜆?gòu)建
動態(tài)圖結(jié)構(gòu)G表示為一組頂點C和邊E的集合,關(guān)系式為G={C,E}。為了更詳細(xì)地描述圖結(jié)構(gòu),使用鄰接矩陣M=[mpq]來表示這種關(guān)聯(lián),即
(9)
式中:epq為2個相鄰頂點cp和cq的邊;mpq=1表示cp和cq之間存在邊,反之,mpq=0。
動態(tài)圖結(jié)構(gòu)構(gòu)建完成之后,使用圖神經(jīng)網(wǎng)絡(luò)處理圖結(jié)構(gòu)數(shù)據(jù),圖神經(jīng)網(wǎng)絡(luò)通過聚集來自每個頂點的邊和相鄰頂點的特征,以迭代方式更新頂點的隱藏狀態(tài)。在每個時間t,圖中的每個頂點c的隱藏狀態(tài)嵌入都被更新,表示為hc,c∈C。在時間t+1,頂點c的隱藏狀態(tài)嵌入被更新為
(10)
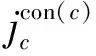
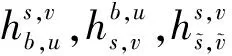
2.2 強(qiáng)化學(xué)習(xí)要素設(shè)計
本文將中央控制器視為智能體,負(fù)責(zé)調(diào)度認(rèn)知天地融合網(wǎng)絡(luò)中Underlay模式下主用戶和次用戶的頻譜和功率資源。強(qiáng)化學(xué)習(xí)框架中的狀態(tài)表示智能體可以從環(huán)境中獲取的信息。由于認(rèn)知無線電網(wǎng)絡(luò)的總數(shù)據(jù)速率受到同信道干擾的影響顯著,而同信道干擾包括衛(wèi)星、用戶之間的同層干擾,以及衛(wèi)星用戶和地面用戶之間的跨層干擾,這些干擾是用戶距離分布和資源占用的結(jié)果。
對于第i次迭代訓(xùn)練的時間t,有效狀態(tài)oi,t主要由用戶距離分布D(i,t)和資源占用情況X(i,t)組成。
oi,t={D(i,t),X(i,t)}
(11)
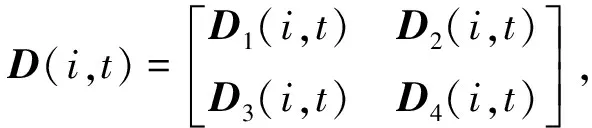
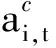
(12)
(13)
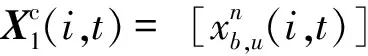
獎勵定義為認(rèn)知網(wǎng)絡(luò)的系統(tǒng)數(shù)據(jù)速率r(oi,t,ai,t)=Ctotal。
2.3 端到端的策略學(xué)習(xí)模型
在解決資源分配和干擾減緩問題中,認(rèn)知無線電網(wǎng)絡(luò)拓?fù)涞目臻g特征至關(guān)重要。圖4為應(yīng)用圖卷積網(wǎng)絡(luò)的端到端模型,用來聯(lián)合學(xué)習(xí)環(huán)境表示與資源分配策略。為了提取認(rèn)知無線電網(wǎng)絡(luò)拓?fù)渖系奶卣?采用圖卷積網(wǎng)絡(luò)作為基礎(chǔ),使用階數(shù)索引為1的2個圖卷積層,有效提取干擾特征,防止因堆疊層過少導(dǎo)致頂點缺失相鄰的特征信息或者堆疊層過多導(dǎo)致所有的頂點都被判斷為鄰點的問題。此外,使用3個全連接層作為局部輸出函數(shù),生成動作的概率分布,為了將輸出解釋為概率分布,本文在輸出層使用Softmax函數(shù)將實數(shù)向量映射為0~1范圍內(nèi)的向量。在學(xué)習(xí)模型中,每個動作有2個子目標(biāo),即信道選擇和功率調(diào)整,通過共享該模型的圖卷積網(wǎng)絡(luò)層和完全連接層實現(xiàn)這2個子目標(biāo),并且將這2個子目標(biāo)的損失和設(shè)置為整個模型的總損失函數(shù),使得權(quán)重可以通過反向傳播同時學(xué)習(xí)信道選擇和功率調(diào)整的策略。通過權(quán)重共享方法,能避免設(shè)計2個獨立學(xué)習(xí)模型的復(fù)雜性,使得模型更加高效。
通過構(gòu)建應(yīng)用圖卷積網(wǎng)絡(luò)的端到端學(xué)習(xí)模型,將表示學(xué)習(xí)和任務(wù)學(xué)習(xí)融合在一起,解決復(fù)雜的認(rèn)知無線電網(wǎng)絡(luò)資源分配問題。該模型不僅避免了頂點特征在連接中的不連貫性,還保持了強(qiáng)化學(xué)習(xí)框架的獎勵引導(dǎo)。通過多層特征提取,自動獲取最具代表性的空間特征,支持精確的資源分配決策。同時,模型通過整體獎勵驅(qū)動,實現(xiàn)了表示學(xué)習(xí)和任務(wù)學(xué)習(xí)的同時進(jìn)行。
2.4 應(yīng)用策略梯度算法的學(xué)習(xí)過程
(14)
(15)
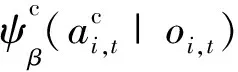
總損失與網(wǎng)絡(luò)參數(shù)更新公式為
(16)
(17)
式中:η為學(xué)習(xí)率。
最小化損失函數(shù)即為最大化累積獎勵,根據(jù)r(oi,t,ai,t)=Ctotal的獎勵設(shè)置,表明本文的優(yōu)化目標(biāo)為最大化系統(tǒng)數(shù)據(jù)速率,并且智能體在損失函數(shù)(累積獎勵)的驅(qū)動下不斷更新網(wǎng)絡(luò)參數(shù),直到學(xué)習(xí)到最優(yōu)的信道選擇和功率調(diào)整策略。
3 仿真結(jié)果與分析
在本節(jié)中,通過試驗來評估本文提出的資源分配方法,該方法是應(yīng)用圖卷積網(wǎng)絡(luò)的深度強(qiáng)化學(xué)習(xí)框架(GCN+DRL)實現(xiàn)的,仿真參數(shù)如表1所示。
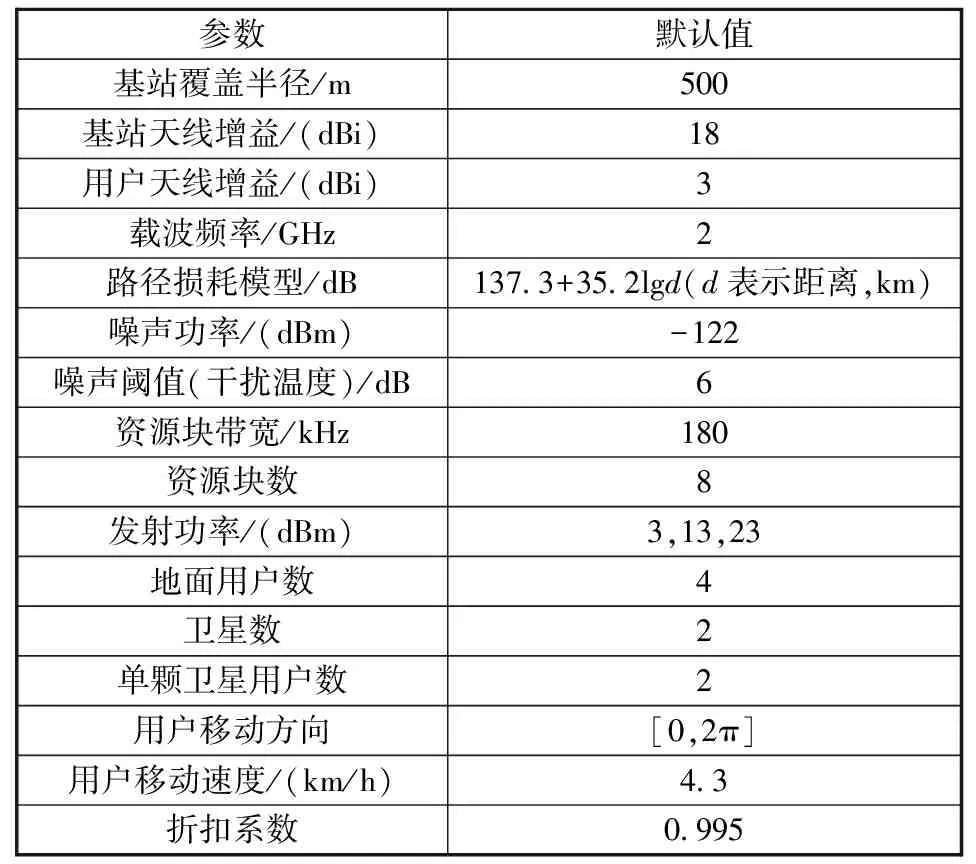
表1 仿真參數(shù)Table 1 Simulation parameters
將本文提出的GCN+DRL與以下幾種方法進(jìn)行比較:①隨機(jī)法(Random Strategy);②策略梯度法(PG Algorithm);③應(yīng)用卷積神經(jīng)網(wǎng)絡(luò)的深度強(qiáng)化學(xué)習(xí)法(CNN+DRL)。其中:Random Strategy以隨機(jī)策略選擇信道占用;PG Algorithm采用全連接網(wǎng)絡(luò),并利用梯度信息來改進(jìn)策略;CNN+DRL采用卷積神經(jīng)網(wǎng)絡(luò)與全連接網(wǎng)絡(luò)的混合結(jié)構(gòu),并利用PG Algorithm更新策略。此外,本文提出的GCN+DRL將通信環(huán)境的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)轉(zhuǎn)換為圖形式,并且采用圖神經(jīng)網(wǎng)絡(luò)與全連接網(wǎng)絡(luò)的混合設(shè)計來挖掘環(huán)境中潛在的干擾信息,以實現(xiàn)更高效的資源利用。
圖5展示了不同方法可達(dá)到的數(shù)據(jù)速率。在下行鏈路干擾受限的認(rèn)知網(wǎng)絡(luò)中,GCN+DRL表現(xiàn)最好。相比之下,Random Strategy收斂速度較快,但其實現(xiàn)的資源分配方案并不是最優(yōu)的;PG Algorithm在40000次迭代后收斂,但由于用戶移動而存在較大波動;CNN+DRL在收斂速度和資源分配性能上均次于GCN+DRL。
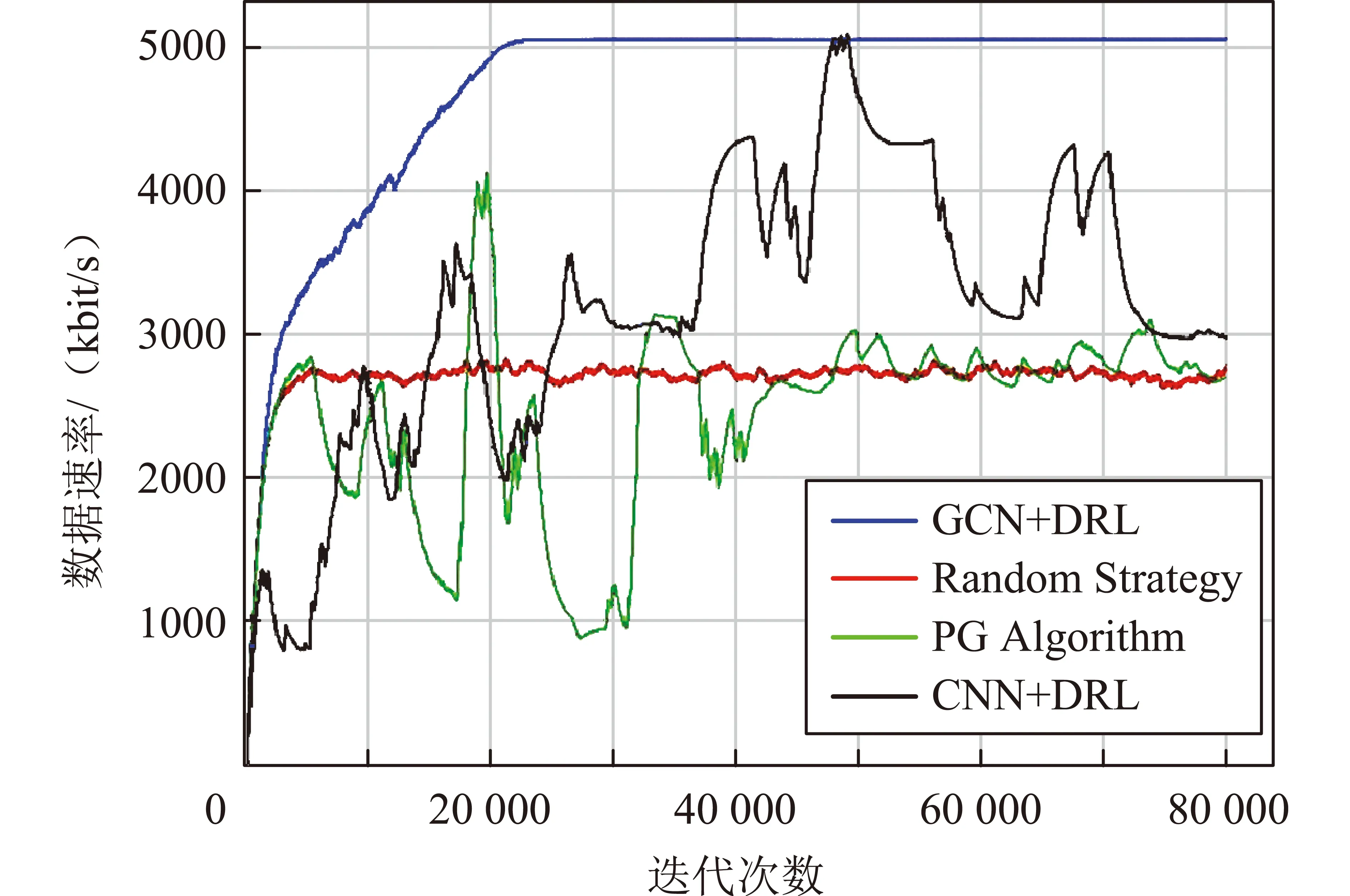
圖5 不同方法的可實現(xiàn)數(shù)據(jù)速率Fig.5 Achievable data rates for different methods
圖6描述了提出的聯(lián)合信道選擇和功率調(diào)整方法的收斂性,展示了隨著訓(xùn)練迭代次數(shù)的增加,每個訓(xùn)練步驟的預(yù)期回報。當(dāng)學(xué)習(xí)網(wǎng)絡(luò)剛開始訓(xùn)練時,預(yù)期回報值相對較小,并且方法處于探索階段。隨著培訓(xùn)過程數(shù)量的增加,預(yù)期回報值逐漸增加。訓(xùn)練20000次迭代后,預(yù)期回報值穩(wěn)定下來,這意味著本文方法將自動更新其決策策略并收斂到最優(yōu)。此外,表2給出了不同方法的收斂時間對比,Random Strategy雖然實現(xiàn)了快速的收斂,但是其系統(tǒng)數(shù)據(jù)速率性能較差;與其他方法相比,GCN+DRL具有更短的收斂時間,因為其利用圖神經(jīng)網(wǎng)絡(luò)可以挖掘通信環(huán)境中的潛在干擾信息,實現(xiàn)干擾避免并獲得較高的數(shù)據(jù)速率。

表2 不同方法收斂時間Table 2 Convergence time of different methods
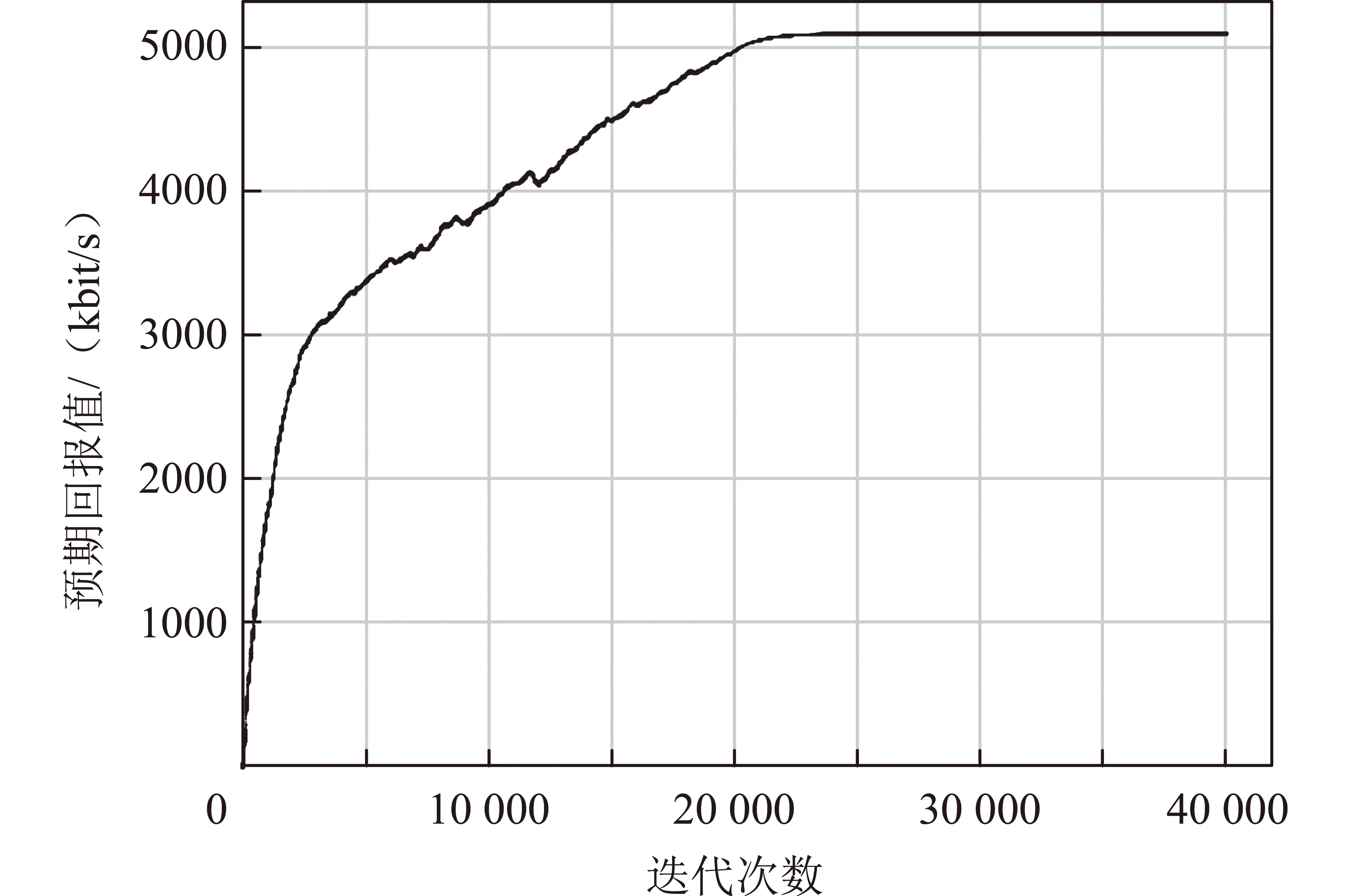
圖6 方法收斂性Fig.6 Convergence of the proposed method
圖7研究了本文方法分別在0.00001,0.00003,0.00005,0.00007學(xué)習(xí)率下的收斂性能。從圖7中可以看出:不同學(xué)習(xí)率的曲線之間存在相同的趨勢,但收斂時間略有不同。就趨勢而言,早期智能體主要負(fù)責(zé)嘗試,所以預(yù)期回報值較低;就收斂時間而言,學(xué)習(xí)率為0.00001的曲線收斂大約22000次迭代,學(xué)習(xí)率為0.00003的曲線收斂大約20000次迭代,學(xué)習(xí)率為0.00005和0.00007的曲線收斂迭代次數(shù)相對較小,大約18000次迭代,因此相對較大的學(xué)習(xí)率可以加速學(xué)習(xí)過程。但是,為了收斂到最優(yōu)學(xué)習(xí)策略,本文更傾向于犧牲收斂時間,選擇相對較小的學(xué)習(xí)率,得到較大的回報。
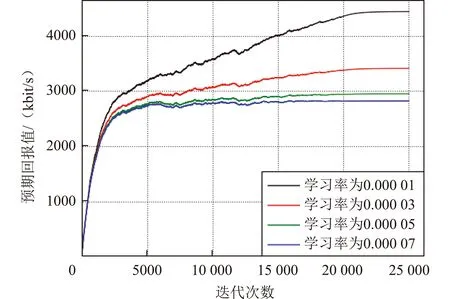
圖7 不同學(xué)習(xí)率的收斂性Fig.7 Convergence for different learning rates
4 結(jié)束語
本文基于認(rèn)知無線電技術(shù)提出一種應(yīng)用圖卷積網(wǎng)絡(luò)深度強(qiáng)化學(xué)習(xí)的資源分配方法,在保證主用戶服務(wù)質(zhì)量的前提下最大化系統(tǒng)數(shù)據(jù)速率。為了建模認(rèn)知無線電網(wǎng)絡(luò)的底層拓?fù)浣Y(jié)構(gòu),本文考慮地面網(wǎng)絡(luò)為主網(wǎng)絡(luò),衛(wèi)星網(wǎng)絡(luò)為次網(wǎng)絡(luò),將通信網(wǎng)絡(luò)建模為動態(tài)結(jié)構(gòu),使用隨機(jī)行走模型來模仿用戶的動作,利用結(jié)構(gòu)中包含的用戶距離分布來估計信道質(zhì)量信息,并且通過圖卷積網(wǎng)絡(luò)提取關(guān)鍵的干擾特征。最后,采用深度強(qiáng)化學(xué)習(xí)框架進(jìn)行模型學(xué)習(xí),探索最優(yōu)資源分配策略。試驗結(jié)果表明:本文方法在保證授權(quán)用戶遭受的干擾小于其噪聲閾值的前提下,顯著提升了天地融合網(wǎng)絡(luò)的系統(tǒng)數(shù)據(jù)速率。
猜你喜歡
吉林廣播電視大學(xué)學(xué)報(2021年4期)2022-01-14 02:35:48
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
