基于行政管理數據識別慢性病發病病例背景下確定洗脫期時長最佳策略的系統綜述
2023-11-14 07:54:18楊文怡王敬鑫艾麗梅萬霞
中國全科醫學 2024年4期
楊文怡,王敬鑫,艾麗梅,萬霞
100005 北京市,中國醫學科學院基礎醫學研究所 北京協和醫學院基礎學院
為了有效預防和控制糖尿病、腫瘤、慢性阻塞性肺疾病等多種慢性病,需要準確估計疾病的患病率和發病率。目前,已有一些研究者通過開展大型隊列、調查研究對疾病的患病、發病情況展開調查,但這種研究方式具有耗時長、耗資大的特點。因此,可考慮應用醫療保險報銷記錄、健康監測數據等行政管理數據對慢性病的流行病學特征進行分析。與患者從出生到死亡的全生命周期的醫療記錄不同,醫療保險數據多為有限年份下的記錄,且慢性病患者通常會反復就醫,從這些被截斷的、高度重復的記錄中有效識別出新發病例有一定難度。為解決這一問題,研究者一般以回顧期(look-back period),即洗脫期(wash-out time)為基礎確定新發病例。具體方法為:若在目標檢索年限內患者出現在某種慢性病的登記記錄中,即可認為其為疑似新發病例,以目標檢索年限為基礎,向前回顧,在限定的洗脫期內沒有與該病相關的記錄即可確定其為新發病例。目前,對于洗脫期的長短尚沒有統一結論[1-2]。洗脫期太短會造成發病率被高估,太長則會導致數據利用不足[3]。一些研究者認為不同疾病有不同的發展軌跡和特征[4-6],在使用不同類型數據確定不同疾病新發病例時,均應采用合適的方法確定最佳洗脫期時長。本研究系統綜述了確定洗脫期時長的方法,以期為我國研究者后續使用行政管理數據識別慢性病新發病例時確認洗脫期長短、正確識別新發病例提供思路。
1 資料與方法
1.1 文獻納入與排除標準
文獻納入標準:(1)所使用的數據為行政管理數據,包括醫療保險數據、疾病登記注冊數據、醫院登記數據等;(2)所聚焦的疾病為慢性病,同一患者因同種疾病產生多次記錄;(3)研究目的為探究疾病患病、發病情況,聚焦疾病流行病學特征;(4)涉及洗脫期。文獻排除標準:(1)非中、英文文獻;(2)所使用的數據為非官方數據,如通過隊列研究、病例對照研究獲得的調查數據等;(3)非原始研究,如評論、系統綜述等;(4)會議論文或以摘要形式發表的研究成果;(5)無法獲取原文的文獻;(6)重復發表的文獻;(7)所探討的內容與本研究關注的內容不相關,包括僅利用行政管理數據評估疾病負擔、開展隊列/病例對照研究等。
1.2 文獻檢索策略
于2021年10月,系統檢索3個英文數據庫(PubMed、Web of Science、EmBase)和3 個中文數據庫(中國知網、維普中文科技期刊全文數據庫、萬方數據知識服務平臺),獲取有關利用行政管理數據探究慢性病發病、患病情況的文獻,檢索時限均為建庫至2022-10-01。中文檢索詞包括:醫療保險數據、官方數據、行政數據、醫院數據、患病、發病,洗脫期、回顧期、窗口期。英文檢索詞包括:administrative data、insurance data、hospital data、Medicare,prevalence、incidence,lookback period、wash-out time、clearance time、disease-free time、observation time。以PubMed 為例,具體檢索策略如下:(incidence[Title/Abstract] OR prevalence[Title/Abstract])AND(insurance data[Title/Abstract]OR administrative data[Title/Abstract]OR hospital data[Title/Abstract]OR Medicare[Title/Abstract])AND(lookback period[Title/Abstract]OR wash-out time[Title/Abstract]OR clearance time[Title/Abstract]OR diseasefree time[Title/Abstract]OR observation time[Title/Abstract])。
1.3 文獻篩選與資料提取
由2 名研究人員獨立篩選文獻、提取資料,并交叉核對結果,如有分歧,通過與第3 名研究者討論解決。文獻篩選時,首先閱讀文題和摘要,在排除明顯不相關的文獻后,進一步通讀全文根據納入和排除標準確定納入分析的文獻。提取的資料包括:(1)文獻基本信息,包括作者、發表年份、聚焦疾病;(2)使用的數據庫的基本信息,包括國家(地區)、數據庫名稱、數據庫類型、使用數據的年份跨度、涵蓋人群(數);(3)研究設計,包括設定的洗脫期時長、洗脫期時長確定方法。
1.4 納入文獻方法學質量評價
由2 名研究人員獨立采用美國加利福尼亞大學提出的定性研究報告評價標準(standards for reporting qualitative research,SRQR)[7]對文獻方法學質量進行評價,如有分歧,通過與第3 名研究者討論解決。SRQR 共有21 個條目,研究者對每個條目做出“是”“否”“不清楚”的判斷,選擇“是”計1 分,選擇“否”“不清楚”計0 分,將各條目得分相加即得總分,得分范圍為0~21 分,最終納入SRQR 評分≥15分的文獻。
1.5 統計學方法
使用描述性分析法總結洗脫期時長確定方法。
2 結果
2.1 文獻篩選流程及結果
通過檢索各數據庫獲得中文文獻21 篇、英文文獻1 203 篇。經過初篩、復篩,獲得基于行政管理數據評估慢性病患病/發病情況等流行病學特征的文獻54篇,排除其中未涉及洗脫期的文獻28 篇,最終納入26篇[2-6,8-28]文獻。文獻篩選流程見圖1。
2.2 納入文獻基本信息及使用的數據庫的基本信息
納入的26 篇文獻均為英文文獻;所使用的數據主要來自加拿大、美國、澳大利亞等行政管理數據完整、豐富的國家(地區);所聚焦的疾病包括糖尿病、腫瘤、精神分裂癥等多種慢性病,其中聚焦心血管疾病的文獻有11 篇[2,4,6,8,14,17,19,22-23,25,28],5 篇[6,8,10,13,19]文獻聚焦糖尿病;研究目的主要為確定多種慢性病的發病、患病情況;12 篇[3,6,9-11,13,16,19-20,24,26-27]文獻所使用的數據為醫療保險數據,8 篇[2,4,8,12,22-23,25,28]文獻所使用的數據為醫院患者注冊登記數據,其余文獻所使用的數據為經注冊的居民健康項目數據[14-15]或經注冊的疾病調查項目數據[5,17-18,21];所使用的數據年份跨度較大,其中僅有2 篇[15,19]文獻所使用的數據年份跨度≤5 年,14 篇[2,5,8,10-12,14,16-17,21,24-26,28]文獻所使用的數據年份跨度≥10 年。納入文獻基本信息及使用的數據庫的基本信息見表1。
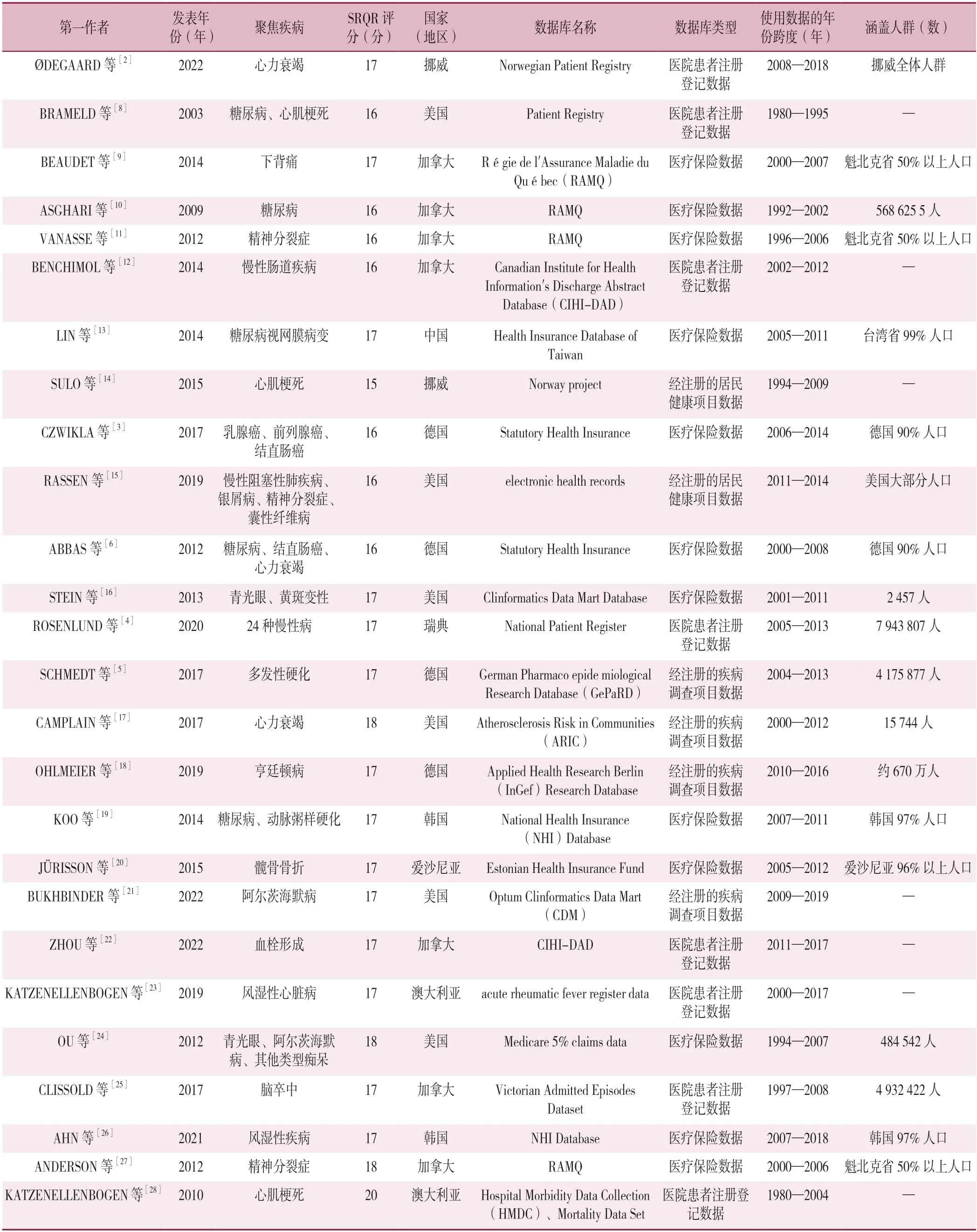
表1 納入文獻基本信息及使用數據庫的基本信息Table 1 Basic information of the included literature and the used database
2.3 納入文獻的方法學質量評價結果
納入文獻的SRQR 評分均≥15 分,中位SRQR 評分為17(16,17)分(受限于篇幅,本研究未通過單獨列表呈現納入研究的方法學質量評價具體結果),見表1。
2.4 最佳洗脫期時長確定方法
通過系統文獻回顧,發現目前確定洗脫期時長的方法主要包括直接限定法、一致性檢驗法和逆向生存函數法三大類。納入的26 篇文獻中,有15 篇[3,13-15,18-28]基于專家建議、臨床經驗、文獻回顧或因受限于數據,直接確定洗脫期時長;10篇[2,4-6,9-12,16-17]文獻使用一致性檢驗的相關指標,如Kappa 值、陽性預測值、過高估計率等評估不同洗脫期時長對發病率估計的影響、確定洗脫期時長;3 篇[8-10]使用逆向生存函數法確定最佳洗脫期時長。
2.4.1 一致性檢驗法:10 篇[2,4-6,9-12,16-17]文獻所采用的一致性檢驗相關指標包括Kappa 值、陽性預測值、過高估計率、陰性預測值、靈敏度、準確度。所有文獻均將基于數據實際所能達到的最長洗脫期期限作為洗脫期時長“金標準”,通過以上指標定量比較不同洗脫期時長下的發病人數(incident patient defined by different clearance period,IDD)與基于洗脫期時長“金標準”確定的發病人數(incident patient defined by golden criterion,IDG)之間的差異性。6 篇[2,4-6,16-17]文獻采用過高估計率[(IDD-IDG)/IDG×100%]作為一致性評價指標,3 篇[9-11]文獻所采用的一致性評價指標涉及Kappa 值,3 篇[9,11-12]文獻所采用的一致性評價指標涉及陽性預測值,1 篇[12]文獻所采用的一致性評價指標涉及靈敏度、準確度和陰性預測值。目前,僅有研究者基于Kappa 值提出了一致性的判斷標準。按照BYRT 等[29]提出的判斷標準:當Kappa 值為-1.00~<0時,可認為“一致性缺乏”;當Kappa 值為0~0.20 時,可認為“一致性不佳”;當Kappa 值為>0.20~0.40 時,可認為“低一致性”;當Kappa 值為>0.40~0.60 時,可認為“一致性一般”;當Kappa 值為>0.60~0.80 時,可認為“一致性較好”;當Kappa 值為>0.80~0.90 時,可認為“一致性好”;當Kappa 值為>0.90~1.00 時,可認為“一致性極好”。當Kappa 值為>0.90~1.00 時,所選洗脫期時長下的發病人數與基于洗脫期時長“金標準”確定的發病人數之間的一致性極好,所選洗脫期時長即為最佳洗脫期時長。
2.4.2 逆向生存函數法:一般通過Kaplan-Meier 法或壽命表法實現估計。在該方法中,終點事件為患者在洗脫期內被記錄,生存被定義為在給定的洗脫期內沒有捕捉到該患者的記錄(此時患者可被認為是新發病例)。具體來說,如計算j 年某慢性病i 的發病人數:a 代表某患者j 年第一次因疾病i 被記錄的日期,b 代表該患者洗脫期內離a 最近的一次因疾病i 被記錄的日期,c 代表洗脫期的開始日期。如果該患者在給定的洗脫期內被記錄,該患者的生存時間為lx=a-b;如果該患者在給定的洗脫期內沒有被記錄,則該患者被定義為“刪失”,即“生存”,刪失時間為lc=a-c。據此建立生存函數,使用Kaplan-Meier 法或壽命表法計算在給定洗脫期T下,研究對象的生存概率[S(t)],并繪制生存曲線。同時,BRAMELD 等[8]和BEAUDET 等[9]在研究中運用風險函數[h(t)]計算了生存時間已達到t 的個體在接下來的Δt 時間內發生終點事件的瞬時風險,并繪制了風險函數曲線。研究認為,若存在某一時點tf使得h(tf)趨近于零、S(tf)趨近于定值,該時點即代表最佳洗脫期時長。在實際研究中,BRAMELD 等[8]認為,當h(tf)<0.000 01 時,即可認為h(tf)趨近于0,而BEAUDET 等[9]則未給出具體標準。ASGHARI 等[10]未通過風險函數計算生存時間已達到t 的個體在接下來的Δt 時間內發生終點事件的瞬時風險,其認為當在某一時點tf下研究對象的生存概率不再變動,即趨于穩定時,該時點即代表最佳洗脫期時長。
2.5 洗脫期時長
納入文獻所設定的洗脫期時長為0.5~15.0 年。當不同文獻聚焦的疾病不同時,設定的洗脫期時長之間有明顯差異;但當不同文獻聚焦的疾病相同時,設定的洗脫期時長之間的差異也較大,如5篇[6,8,10,13,19]聚焦糖尿病的文獻所設定的洗脫期時長,最長為13.0 年,最短為1.0 年。納入文獻洗脫期時長確定方法及設定的洗脫期時長見表2。
3 討論
本次研究系統梳理了使用行政管理數據識別慢性病發病病例時確定最佳洗脫期時長的方法。目前,半數左右[48.1%(26/54)]基于行政管理數據評估慢性病患病/發病情況等流行病學特征的文獻在識別慢性病發病病例時設定了洗脫期,但對于洗脫期的時長目前尚沒有統一結論。納入的26 篇文獻所設定的洗脫期時長為0.5~15.0 年。確定洗脫期時長的方法主要包括直接限定法、一致性檢驗法、逆向生存函數法3 種,其中最常用的方法是直接限定法,逆向生存曲線法的使用率相對較低。
本次研究發現,半數以上[57.7%(15/26)]被納入文獻基于直接限定法給定洗脫期時長,在該方法下,研究者根據專家建議、文獻回顧結果等直接限定洗脫期時長。直接限定法雖具有便捷、易于操作的特點,但因缺乏量化的數據支持,一定程度上使限定的洗脫期時長不具有說服力。部分研究者也在研究局限性部分指出,直接限定洗脫期時長可能會導致發病率估計結果不準確[18,26];2 篇[14,23]文獻選擇直接以(可獲得數據的最大年份-可獲得數據的最小年份)為洗脫期時長,但此方法下研究者只能探討可獲得數據最大年份慢性病的發病情況,數據無法得到有效利用。部分文獻[38.5%(10/26)]基于一致性檢驗的相關指標確定最佳洗脫期時長[2,4-6,9-12,16-17],但不同的文獻所采用的一致性檢驗指標不同,目前被使用較多的一致性檢驗指標為Kappa 值和過高估計率,其中Kappa 值的判定標準為BYRT 等[29]1993 年提出的標準。多數研究者選擇Kappa 值>0.80(“一致性好”/“一致性極好”)作為確定洗脫期時長的標準[9-11],但有研究認為在識別高患病率疾病(如糖尿病、心血管疾病)發病病例時,高Kappa 值可能與疾病患病人數多有關,Kappa 值的穩定性有待進一步探究[10]。目前,尚缺乏基于除Kappa值外的其他一致性評價指標的洗脫期時長確定標準,如ABBAS 等[6]以過高估計率10%作為臨界標準,而在ROSENLUND 等[4]的研究中這一指標被設定為20%;對于陽性預測值,有研究者選擇80%作為界值[11];BENCHIMOL 等[12]則選擇準確度達到90%作為評判標準。僅有少部分研究[11.5%(3/26)]使用逆向生存函數法確定最佳洗脫期時長[8-10]。在BRAMELD 等[8]于2003 首次提出采用逆向生存函數法確定洗脫期時長后,該方法被陸續使用[9-10]。逆向生存函數法強調通過繪制生存曲線和風險函數曲線,并依據生存概率和風險概率確定最佳洗脫期時長。研究者認為該方法可以使數據得到最大限度的利用,并能夠確保研究者充分使用所有可獲得的記錄估計生存函數。同時,通過生存曲線和風險函數曲線可以直觀觀察到生存概率和風險概率的集中趨勢,有效、定量地判斷最佳的洗脫期時長。但該方法也存在一定的局限性,即判斷標準尚未得到完全統一。如BRAMELD 等[8]認為,若存在某一時點tf使得h(tf)<0.000 01,該時點即代表最佳洗脫期時長,按照此標準,其研究(聚焦糖尿病)中洗脫期長達13.0 年。ASGHARI 等[10](其研究亦聚焦糖尿病)并未使用這一標準,其根據研究對象的生存概率趨于穩定這一標準,確認洗脫期時長為5.0 年。值得注意的是,由于對洗脫期時長的確定方法、判斷標準尚未達成共識,許多研究者在探究最佳洗脫期時長時,選擇計算多個一致性指標的數值,并結合基于逆向生存函數法得出的結果進行綜合判斷[8-10]。
研究納入的文獻所設定的洗脫期時長為0.5~15.0年,聚焦不同疾病的研究設定的洗脫期時長之間的差異較大。有研究者認為,不同疾病的發展軌跡和特征不同是導致該現象出現的重要原因[6]。本研究同時發現,不同研究即使聚焦同一疾病,如糖尿病,所設定的洗脫期時長之間的差異也較大,其原因可能是不同研究所使用數據的收集方式不同且來源人群的就醫習慣存在較大差異。因此,在使用不同類型的數據識別不同疾病的發病病例時,均應選擇合適的方法探索最佳洗脫期時長,在此基礎上針對疾病流行病學特征進行進一步的研究,這與部分研究者的觀點相一致[2-3,16]。研究者后續在使用中國醫療保險數據、疾病登記注冊數據等行政管理數據進行慢性病的流行病特征相關分析時,應考慮到不同國家(地區)在醫療保險政策、環境、人種等方面存在明顯差異,不應直接應用其他國家研究者得出的洗脫期時長,應在數據的支持下,選擇合適的方法確定最佳洗脫期時長,并在此基礎上進行后續的分析研究。
行政管理數據作為寶貴的資源,涵蓋范圍廣、年份跨度大、可被便捷地獲取,相較于傳統的調查數據有一定的優勢。自2012 年改革醫療保險制度以來,中國大力推廣醫療保險政策,擴大參保人群覆蓋范圍[30-31],隨著改革的逐步深入,有效數據的積累量持續增加。但目前在萬方知識服務平臺、中國知網、維普中文科技期刊全文數據庫檢索到的利用醫保數據、醫院患者注冊登記數據等行政管理數據對慢性病流行病學特征進行分析的研究較少(截至2022-10-01 相關文獻僅21 篇),我國相關研究數量遠少于行政管理數據完備、研究范式成熟的其他國家(地區),說明中國在此方面仍處于探索階段,未來發展潛力巨大。同時,中國內地研究者在使用醫療保險數據等行政管理數據進行分析時,未重視洗脫期(在萬方知識服務平臺、中國知網、維普中文科技期刊全文數據庫檢索到的基于行政管理數據評估慢性病患病/發病情況等流行病學特征的文獻均未涉及洗脫期),此外也未有內地研究者探討利用中國人群醫療保險數據等行政管理數據對疾病流行病學特征進行分析時如何確定洗脫期時長。因此,本研究系統總結的3 種可用于確定洗脫期時長的方法,可為后續研究者基于中國醫療保險數據等行政管理數據準確識別慢性病新發病例、探究疾病流行病學特征提供相關思路和方法支持。
本研究存在一定的局限性。首先,由于行政管理數據具有特殊性,部分數據可能為內部數據、機密數據,在檢索文獻的過程中,一些未公開發表的文獻無法被檢索到,故未將其納入研究范疇,這可能會對研究結果產生一定的影響。其次,研究者僅對中、英文數據庫中的相關文獻進行了檢索,未檢索以其他語種發表的相關文獻,可能會導致檢索到的方法全面性不足。
作者貢獻:楊文怡提出研究選題方向,負責文獻檢索和整理,并撰寫論文初稿;王敬鑫進行文獻數據提取和信息整理;艾麗梅負責論文的修訂;萬霞負責文章的質量控制及審校,對文章整體負責;所有作者確認了論文的最終稿。
本文無利益沖突。
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
