面向內存表的可動態配置預寫日志框架
2023-11-16 00:51:30朱海銘黃向東喬嘉林王建民
計算機與生活 2023年11期
朱海銘,黃向東+,喬嘉林,王建民
1.清華大學 軟件學院,北京 100084
2.大數據系統軟件國家工程研究中心,北京 100084
預寫日志(write-ahead logging,WAL)[1]是一種能在設備故障中保障數據庫管理系統持久性和原子性的技術,所有對數據的修改都會在實際修改數據庫文件之前被記錄到預寫日志文件中。為減少磁盤的讀寫(input/output,I/O)開銷,數據庫通常會在內存(memory)中緩存對數據的修改操作,在積累到一定量形成內存表(memory table,MemTable)后再落入磁盤,如果數據庫在內存表落盤前發生故障,內存表中包含的數據就可能被丟失或損壞,預寫日志的用途就是保障這部分數據的持久性和原子性。
預寫日志是寫入請求與磁盤交互的第一關,因此預寫日志的寫入吞吐能力基本決定了數據庫整體的寫入性能上限。因此,如何讓預寫日志在變化的應用負載和計算環境下充分利用磁盤的I/O 性能成為了一個至關重要的問題。一般來講,優化I/O性能可以從以下幾個方向入手[2]:(1)批量寫入,增大每次系統調用寫入的數據量;(2)將磁盤的隨機I/O 轉換為順序I/O;(3)提高寫入內存的并發度。然而在很多NoSQL 數據庫的實現中,預寫日志和數據庫或數據分區間的對應關系是強耦合的,如LevelDB[3]中預寫日志和數據庫實例形成一對一關系,InfluxDB[4]中預寫日志和數據分片(shard)形成一對一關系,Apache-IoTDB[5-6]中預寫日志和時間分區(time partition)形成一對一關系等。這種內存表和預寫日志間強耦合的對應關系恰恰無法利用上述的優化手段,限制了數據庫在預寫日志上針對I/O 性能進行調優的可能性。當內存表數量因應用業務或計算環境發生變更而變化時,與之耦合的預寫日志的資源占用會一同發生變更,寫入請求被分散到不同的預寫日志上,不僅無法進行批量寫入,還降低了同一預寫日志中內存寫入的并發度。在極端情況下(如預寫日志數量達數千量級),零落分散的預寫日志還會產生大量磁盤隨機I/O,造成性能下降[7]。雖然當前有部分數據庫系統考慮到了將預寫日志與內存表解耦(如HBase[8]),但它們的解耦方式不僅無法在運行時動態調整預寫日志數量,還存在著因主動觸發低頻數據內存表落盤而導致查詢效率下降的缺陷。
針對上述問題,本文基于預寫日志中的重寫日志(Redo log)[9],提出了一種面向內存表的可動態配置日志框架:將預寫日志和內存表解耦,內存表可以動態地被分配給不同的預寫日志隊列,支持可變的對應關系。預寫日志模塊的資源占用更易控制,當計算環境和應用負載發生變化時,能夠在不重啟的情況下通過簡單地調整預寫日志的配置來快速實現動態性能調優。框架使用內存表快照來避免現有方案中主動觸發低頻數據內存表落盤帶來的查詢性能損失,既能控制日志文件的總大小,又能保障較高的查詢效率。同時,本文在使用日志結構合并樹(logstructured merge-tree,LSM-tree)[10-11]的Apache IoTDB上實現了預寫日志框架,并在合成的數據集和工作負載上進行了相關實驗。實驗結果表明:(1)與強耦合的預寫日志方案相比,該框架能夠更好地適配不同的計算環境和應用負載,通過調整預寫日志數量獲取最佳的寫入性能;(2)與已有的解耦方案相比,該框架不僅能夠在不重啟的情況下進行動態配置,還能在幾乎不影響寫入效率的同時更好地保障低頻數據的查詢效率。
1 相關工作
本文調研了多個使用LSM-tree 的存儲系統,包括LevelDB、InfluxDB、Apache IoTDB、HBase等。
LevelDB中預寫日志和數據庫實例個數相耦合,每個數據庫實例對應一個預寫日志。當寫入請求增多時,預寫日志很容易成為性能瓶頸,必須通過增加數據庫實例個數來提高寫入速度,而過多的數據庫實例又會產生大量磁盤隨機I/O,造成寫入效率下降,可配置性差。
InfluxDB中預寫日志和數據分片個數耦合,每個正在寫入的數據分片都會有自己對應的預寫日志文件。和LevelDB相比,InfluxDB的預寫日志管理粒度更細致,因此更容易因計算環境和應用負載變更暴露性能問題,當數據分片數量增加時,內存占用和I/O任務數會同時線性增加。
Apache IoTDB 和InfluxDB 類似,其預寫日志和正在寫入的數據文件個數耦合。除了存在與Influx-DB相同的問題外,IoTDB在開啟時間分區功能后,由于其不恰當的預寫日志內存管理機制,系統甚至可能因為發生內存溢出(out of memory,OOM)而進入不可用狀態,開啟時間分區后的系統可用性較差。
HBase雖然考慮了預寫日志與內存表的解耦,但其實現的解耦方案不夠徹底,且帶來了查詢效率降低、文件合并(compaction)[12]開銷大的隱患。在當前實現中,Hbase包含多個HRegionServer,每個HRegion-Server 包括HRegion 和HLog(對應預寫日志)兩部分,每個HRegion 中包含多個MemStore(對應內存表),系統啟動時可以指定HLog 實例的個數,每個HRegion 在創建時被固定地分配一個HLog 實例,在系統運行時永不變更。這樣的解耦方案主要有兩個缺點:首先,由于HRegion和HLog之間的關系在運行時是固定的,當系統啟動后,HLog 的個數無法變更,計算環境和應用負載變化后只能通過重啟系統來調整預寫日志;其次,HBase將多個MemStore的數據集中管理,當某個MemStore中的數據積累過慢時,預寫日志很容易占用大量的磁盤空間。為了避免歷史數據的大量累積,HBase 會通過觸發這些MemStore 的落盤來刪除歷史數據。由于這些MemStore通常保存著低頻數據,這樣粗放的管理方式會導致磁盤上產生很多小文件,不僅會大幅降低查詢效率,還加重文件合并的負擔。
因此,本文提出的預寫日志框架需要解決以下三點問題:(1)將預寫日志與數據庫邏輯模型、分區配置等解耦;(2)可在運行時動態配置預寫日志,無需停機重啟;(3)在保障讀寫性能的同時,使日志的磁盤占用總量可控可治。
2 預寫日志框架
2.1 架構概述
如圖1所示,每個預寫日志隊列包含一個阻塞隊列、兩個緩沖區、多個日志數據文件(.wal 文件)和一個日志控制文件(.ctrl文件)。
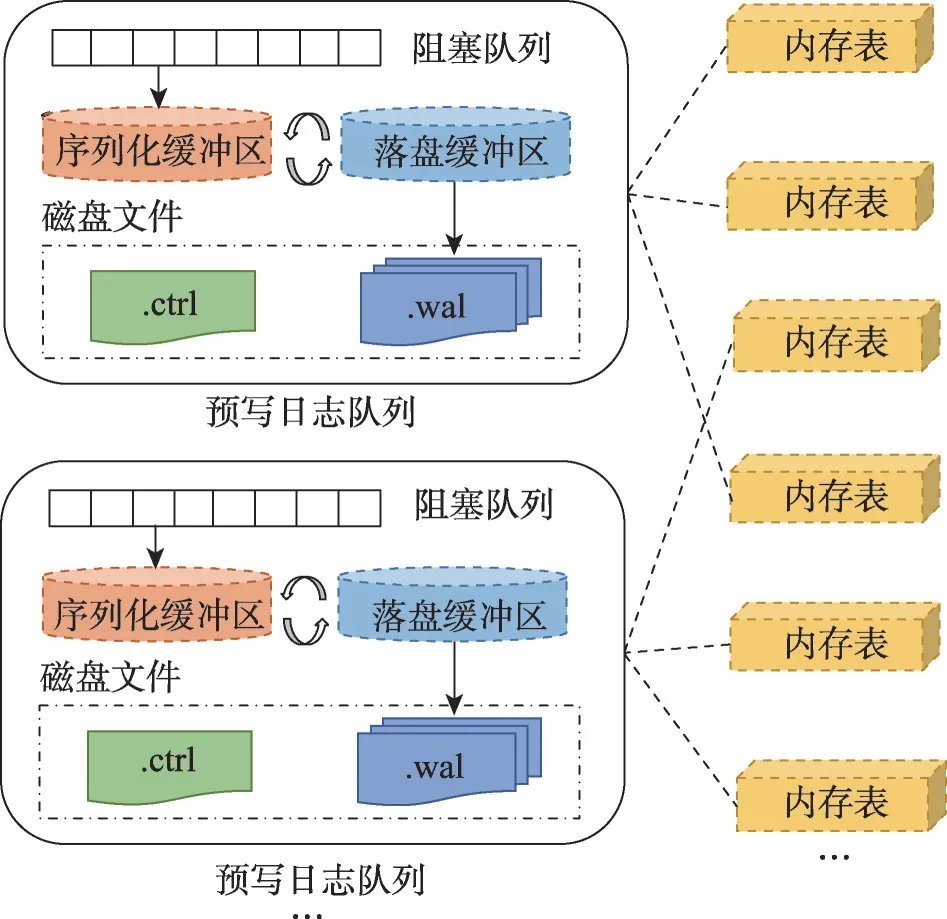
圖1 預寫日志框架架構Fig.1 Architecture of write-ahead logging framework
(1)阻塞隊列。為了增大每次系統調用寫入的數據量,使用阻塞隊列緩存內存表的數據項。序列化任務從隊列中批量取出數據項,序列化至緩沖區后落盤至預寫日志文件中。
(2)緩沖區。為增加并發度,從物理上將緩沖區分為大小相等的兩塊,分別用于序列化和落盤。存在兩類后臺線程,序列化線程負責將數據項序列化到序列化緩沖區中,磁盤同步線程負責將落盤緩沖區同步到磁盤。當序列化緩沖區需要落盤時,序列化線程會阻塞直至落盤緩沖區落盤成功,然后交換兩個緩沖區,清空已落盤的緩沖區用于保存新的序列化數據,最后通知磁盤同步線程將序列化好的緩沖區落盤。
(3)日志文件。預寫日志的數據項和控制項分開存儲,便于重啟時快速恢復控制信息。一個預寫日志隊列下會有多個日志數據文件和一個日志控制文件,日志數據文件存儲一個或多個內存表中的數據項,日志控制文件存儲內存表的創建和落盤信息。
預寫日志的個數可靈活配置,內存表被動態地分配給不同的預寫日志隊列,形成可變的對應關系,即一個預寫日志隊列可以處理任意數量內存表的預寫日志。
2.2 日志數據文件和日志控制文件
日志數據文件保存數據項二元組
日志控制文件保存內存表的相關信息,包括內存表的編號、落盤的目標文件和其初始數據項所在日志數據文件的編號。其中主要包含以下兩種日志信息類型:(1)
數據項和信息項的落盤順序必須滿足以下條件:(1)只有在
重啟恢復時先讀取日志控制文件,確定需要恢復的內存表(有創建信息但無落盤信息),然后讀取日志數據文件,過濾出待恢復的數據項,將數據項重新組成內存表后落盤即可。
2.3 日志數據文件的刪除
(1)理想情況。如圖2(a)所示,在理想的刪除流程下,只需要比較所有未落盤內存表初始數據項所在文件的編號,獲取其中最小的文件編號,然后刪除該編號前的所有無效日志數據文件即可。

圖2 日志數據文件刪除Fig.2 Logging data file deletion
(2)非理想情況。單個數據文件中包含一個或多個內存表的數據,因此在非理想情況下(如圖2(b)所示),只要有一個內存表未落盤,那么這個數據文件就無法被刪除。因此,如果存在內存表數據積累過慢的情況,那么預寫日志就會占用大量磁盤空間。HBase 采用主動觸發內存表的落盤來釋放預寫日志的磁盤占用,但是這種額外觸發落盤的行為會大幅降低查詢效率[13],因此本文考慮通過在預寫日志中引入內存表的快照來避免小內存表的落盤。對內存表做快照后,其全量信息被保存在最新的日志數據文件中,通過更新初始數據項所在的文件編號就可以安全地刪除大量積累的舊日志數據文件。由于做快照和正常寫入流程一樣使用預寫日志隊列的緩沖區進行序列化,不會產生額外的內存開銷。
此外,預寫日志文件的磁盤占用和內存大小正相關,當內存表占用的內存總量上升時,其對應的預寫日志磁盤占用也會上升,因此單純使用磁盤占用大小來觸發數據表的快照是不合適的。本文通過計算日志數據文件中有效信息的占比來控制預寫日志的磁盤占用,每次滾動數據文件時計算有效信息占比,當占比低于給定閾值時,主動觸發內存表的快照釋放文件占用,進而清理無效文件減少磁盤占用。其中,有效信息占比的計算方式為sizememory/(sizememory+sizedisk),這里可以直接使用內存大小指代磁盤大小,因為內存表大小sizememory與其磁盤占用大小sizedisk間存在固定的放縮比γ,即sizedisk=γ×sizememory。計算sizememory值可以通過對當前所有內存表的大小直接求和獲得。計算sizedisk需要額外給每個日志數據文件維護一個內存統計值,該統計值記錄了日志數據文件從開始寫入到封口期間所有落盤內存表的大小之和,這樣就可以將對sizedisk的計算轉換為對當前所有日志數據文件的內存統計值的求和。
2.4 在Apache IoTDB中的實現
SSTable 是LSM-tree 中的關鍵數據結構,用于保存一塊連續的數據,所有寫請求在寫入預寫日志后再寫入內存中的SSTable,這就構成了本文中預寫日志和內存表之間的對應關系。因此,只需要在任意一個基于LSM-tree實現的數據庫管理系統中實現本文提出的框架,就能驗證該框架的有效性。
本文選取Apache IoTDB 實現了預寫日志框架。Apache IoTDB是基于LSM-tree實現的,一體化收集、存儲、管理與分析物聯網時序數據的開源時序數據庫管理系統[14]。在Apache IoTDB 中,每個時間分區擁有一個內存表,預寫日志和內存表一一綁定,當內存表數量因計算環境和應用負載發生變更而變化時,預寫日志的資源占用隨之產生波動,很容易發生內存溢出和性能下降。在實現該框架后,預寫日志和內存表解耦,可針對不同計算環境和應用負載靈活調整出最佳實踐方案,下面將用實驗證明該結論。
3 實驗分析
本章首先驗證了不同應用負載和計算環境下,預寫日志隊列數量對寫入性能的影響,證明框架能夠在不同場景下找到最佳的配置方案。其次,設計實驗對比為低頻內存表做快照和直接刷盤相比讀寫性能的差異,證明與現有方案使用的刷盤策略相比,本文提出的快照策略能夠在幾乎不影響寫入效率的同時更好地保障查詢速度。
3.1 實驗環境與數據
本節的所有實驗都使用一臺配置如表1 的服務器,并使用時序數據庫性能測試工具IoTDBBenchmark[15]統計寫入和查詢的效率。在同一臺服務器上部署IoTDB-Benchmark 和Apache IoTDB,使用IoTDB-Benchmark 生成數據集,為每個內存表創建40 000 條時間序列(40 個設備,每個設備下1 000 個測點),并在每條時間序列內寫入10 000個數據點。

表1 實驗環境Table 1 Experimental environment
3.2 不同應用負載和計算環境寫入性能對比
本實驗通過變化內存表數量模擬不同的應用負載,通過固態硬盤(solid state disk,SSD)和機械硬盤兩種設備模擬不同的計算環境。分別在25 個內存表(占用4 GB內存,對應圖3(a))、50個內存表(占用8 GB 內存,對應圖3(b))、100 個內存表(占用16 GB內存,對應圖3(c))下對寫入性能進行測試,統計每秒寫入的數據點數,以耦合方案(25、50、100 個預寫日志隊列)下的寫入性能為基線對比不同隊列數量下寫入性能的差異。

圖3 不同應用負載和計算環境下寫入性能對比Fig.3 Write performance comparison under different application loads and computing environments
實驗結果如圖3 所示,最大性能提升如表2 所示。在使用SSD 的場景下,多隊列的寫入性能近似相同,只有使用1 個隊列時的寫入性能最佳,性能較耦合方案分別提升了約19%、11%、12%。在使用HDD 的場景下,大多數場景的寫入性能均好于耦合方案的寫入性能,其中分別是使用10、25、30 個預寫日志隊列的寫入性能最佳,性能較耦合方案分別提升了約8%、16%、8%,甚至能夠逼近相同配置下使用SSD 的寫入速度。綜合來看,在不同場景下,使用預寫日志框架可以找到比耦合方案更優的預寫日志配置方案。此外,結合三種場景來看,當應用負載(內存表數量)發生變化時,動態調整預寫日志隊列個數的方式能夠適應不同應用負載,實現性能調優。這一點可以從使用HDD 的計算環境下看出,當內存表個數在25、50、100 之間變化時,只需在10、25、30 之間調整預寫日志隊列的數量,就可保障最佳的寫入性能,可見該框架對動態性能調優的幫助。
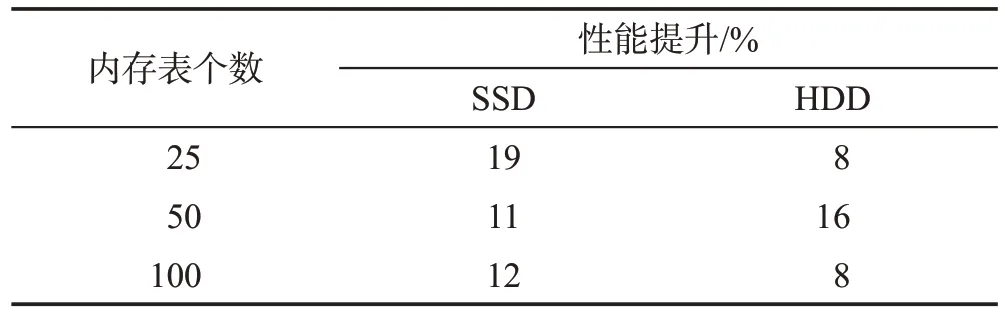
表2 最大性能提升百分比Table 2 Maxperformance improvement percentage
3.3 低頻內存表處理方案對比
本實驗使用1 個預寫日志隊列,并格外增加了1個內存表用于進行低頻數據寫入,從而模擬低頻內存表造成預寫日志文件堆積的情況。以現有方案采用的刷盤策略作為基線,通過統計讀寫操作的平均耗時,對比本框架提出的快照策略和現有方案使用的刷盤策略對讀寫性能的影響。查詢共包括以下10種類型:精確點查詢(Q1)、范圍查詢(Q2)、帶值過濾的范圍查詢(Q3)、帶時間過濾的聚合查詢(Q4)、帶值過濾的聚合查詢(Q5)、帶值過濾和時間過濾的聚合查詢(Q6)、分組聚合查詢(Q7)、最近點查詢(Q8)、倒序范圍查詢(Q9)、倒序帶值過濾的范圍查詢(Q10)。
實驗結果如圖4所示。從圖4(a)可以看出,雖然本框架提出的快照策略耗時略大于現有方案使用的刷盤策略,約慢1.08%,差異較小,但是結合圖4(b)可以看出,得益于不主動觸發內存表落盤,本框架提出的快照策略對查詢的收益是較大的,各類查詢均快于現有方案使用的刷盤策略,可降低2%~20%的查詢耗時。可見,快照策略能夠在幾乎不影響寫入效率的同時更好地保障數據的查詢效率。
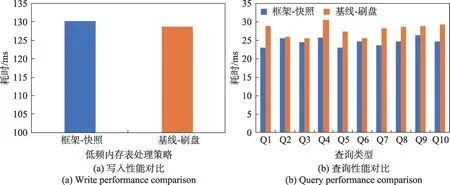
圖4 快照策略和刷盤策略的性能對比Fig.4 Performance comparison between snapshot strategy and flush strategy
4 結束語
本文提出了一種面向內存表的可動態配置日志框架,能夠將預寫日志和內存表解耦,能針對不同計算環境和應用負載動態調整預寫日志隊列個數,實現動態性能調優。為了驗證預寫日志框架的有效性,本文基于Apache IoTDB實現了該框架,并設計了相關實驗。實驗證明該框架能夠動態適配不同計算環境和應用負載,通過調整預寫日志數量保障最快的寫入性能。
計劃在未來從以下幾個方面進行改進:(1)使用增量快照替代全量快照。通過增量快照來避免因同一內存表被多次快照而導致的寫放大(write amplification)問題[16]。(2)實現內存表的智能分配。基于數據寫入頻率對內存表進行分類,讓寫入頻率相似的內存表共享預寫日志隊列,更智能地管理預寫日志及其磁盤文件大小。
