金融分布式數(shù)據(jù)庫異步全局索引研究
2023-11-16 00:51:30金磐石李博涵秦小麟李曉棟
計算機(jī)與生活 2023年11期
關(guān)鍵詞:數(shù)據(jù)庫
金磐石,李博涵,秦小麟,邢 磊,李曉棟,王 進(jìn)
1.中國建設(shè)銀行,北京 100010
2.南京航空航天大學(xué) 計算機(jī)科學(xué)與技術(shù)學(xué)院/人工智能學(xué)院/軟件學(xué)院,南京 211106
我國的數(shù)據(jù)庫市場曾經(jīng)被國外產(chǎn)品壟斷,國產(chǎn)數(shù)據(jù)庫市占率極低,主流數(shù)據(jù)庫產(chǎn)品如Oracle、DB2、SQLServer等均是來自國外。特別地,目前金融等關(guān)鍵行業(yè)也存在這種現(xiàn)象,其核心業(yè)務(wù)普遍采用“大/小機(jī)+Oracle/DB2”的集中式數(shù)據(jù)庫系統(tǒng)。而隨著國產(chǎn)數(shù)據(jù)庫技術(shù)的發(fā)展,尤其是移動端支付的發(fā)展,現(xiàn)有系統(tǒng)已無法滿足金融等關(guān)鍵行業(yè)的要求,因此,建設(shè)新型數(shù)據(jù)庫成為了重要的研究課題[1-2]。由于數(shù)據(jù)庫向下調(diào)用底層硬件資源,向上支撐應(yīng)用業(yè)務(wù),作為三大基礎(chǔ)軟件之一的數(shù)據(jù)庫是計算機(jī)功能實現(xiàn)的重要基礎(chǔ)。隨著數(shù)據(jù)庫國產(chǎn)替代不斷加速,其發(fā)展的主流之一便是分布式數(shù)據(jù)庫。分布式數(shù)據(jù)庫是傳統(tǒng)數(shù)據(jù)庫技術(shù)與計算機(jī)網(wǎng)絡(luò)的有機(jī)結(jié)合,在平滑擴(kuò)展、整體性能、高可靠、高可用、低成本等方面具有優(yōu)勢,特別是整體性能可突破集中式數(shù)據(jù)庫的瓶頸,具有很強的研究和應(yīng)用價值,目前很多數(shù)據(jù)庫企業(yè)研發(fā)了分布式數(shù)據(jù)庫產(chǎn)品,并在金融、電信、互聯(lián)網(wǎng)等關(guān)鍵行業(yè)進(jìn)行了成功應(yīng)用,具有良好的發(fā)展前景[3]。
索引是集中式數(shù)據(jù)庫性能優(yōu)化最常見的手段之一,它是加速查詢非常有效的手段[4]。但是索引本身也會帶來弊端,比如會導(dǎo)致寫放大和空間放大,同時過多的索引也會導(dǎo)致查詢優(yōu)化器的搜索空間增大,拖慢查詢優(yōu)化器的優(yōu)化效率,并且不合適的索引會誤導(dǎo)優(yōu)化器。在分布式數(shù)據(jù)庫中,計算節(jié)點和存儲節(jié)點分離情況下,如果缺乏必要的全局索引,由于網(wǎng)絡(luò)導(dǎo)致延遲更加嚴(yán)重,性能往往更加劣化。因此研究基于分布式數(shù)據(jù)庫的全局索引具有重大的現(xiàn)實意義[5]。伍賽等人于2009年提出了一種雙層索引框架[6],分為全局索引和本地索引兩層結(jié)構(gòu),后續(xù)的關(guān)于雙層索引方案的研究大都是基于該框架進(jìn)行的,如基于Raft 協(xié)議研究出的混合交易分析處理(hybrid transaction analytical processing,HTAP)數(shù)據(jù)庫TiDB[7]、基于Hash與B+Tree的雙層檢索結(jié)構(gòu)[8]以及基于并發(fā)跳表的雙層索引架構(gòu)[9]。但是當(dāng)前常用的全局索引采用同步寫入方式,會導(dǎo)致連接放大嚴(yán)重,并使得可以優(yōu)化的單節(jié)點事務(wù)退化成分布式事務(wù),這使得單表能夠支持的全局索引數(shù)量有限,且隨著數(shù)量增加性能下降嚴(yán)重。
金融分布式數(shù)據(jù)管理的主要應(yīng)用場景是交易場景,大部分任務(wù)在云端上進(jìn)行,其特點是峰谷流量差異很大,因此需要一個能夠用于云端的高效檢索索引框架[10]。在交易峰值時,如果全局索引和本地索引一樣,保持和主表數(shù)據(jù)完全同步的一致性寫入,將會導(dǎo)致數(shù)據(jù)庫的緩沖池負(fù)載較大,當(dāng)達(dá)到緩沖池的閾值時,需要向磁盤寫入臟頁,臟頁數(shù)量較多達(dá)到磁盤IO 的瓶頸時,將會產(chǎn)生比較明顯的事務(wù)響應(yīng)時間(response time,RT)抖動,在交易場景中這是不允許的。金融分布式數(shù)據(jù)管理的另一個典型場景是批量導(dǎo)入數(shù)據(jù),每天凌晨12 點后,需要限定時間內(nèi),導(dǎo)入100 GB以上的來自其他系統(tǒng)的前一天的數(shù)據(jù)到本數(shù)據(jù)庫中,而這些數(shù)據(jù)庫表上同樣存在一個或多個全局索引。實踐證明,同步寫入全局索引的話,尤其是有多個全局索引的情況下,會極大地影響效率,甚至無法在限定時間內(nèi)完成該操作。
針對以上兩個金融領(lǐng)域典型場景,當(dāng)前的分布式數(shù)據(jù)庫同步方式的全局索引存在以下不足:(1)單表支持的全局索引數(shù)量有限且隨著數(shù)量增加性能下降非常快;(2)交易場景下,全局索引的存在會增加寫入事務(wù)的時延,交易高峰容易出現(xiàn)明顯的RT抖動;(3)批量導(dǎo)入數(shù)據(jù)場景下,全局索引的存在會增加系統(tǒng)負(fù)載,降低系統(tǒng)吞吐量。為了解決上述問題,本文提出了一種異步的全局索引設(shè)計思路和方法,同時利用RDMA(remote direct memory access)網(wǎng)絡(luò)降低事務(wù)時延,滿足金融交易場景的需要,通過金融典型場景下的海量數(shù)據(jù)實驗表明,性能提高顯著,且資源消耗降低,為進(jìn)一步在生產(chǎn)環(huán)境中的商用奠定了良好的基礎(chǔ)[11-14]。
1 背景與相關(guān)工作
當(dāng)前全局索引設(shè)計思路主要分為兩大類:一類是索引和主表數(shù)據(jù)存在相同的存儲引擎下且同步更新,其優(yōu)點是和主表數(shù)據(jù)保持ACID(Atomicity 原子性,Consistency一致性、Isolation隔離性、Durability持久性)特性,缺點是會對數(shù)據(jù)庫的負(fù)載和RT造成不利影響;另一類是索引和主表數(shù)據(jù)不在相同的存儲引擎下,比如利用Redis做的鍵值(key value,KV)索引,利用ElasticSearch做倒排索引,優(yōu)點是查詢速度比較快,缺點是維護(hù)較為困難,無法和主表數(shù)據(jù)做到外部一致性。
1.1 同構(gòu)的全局索引
索引和主表數(shù)據(jù)在相同存儲引擎下,全局索引有兩種組織方式:全局非分區(qū)索引(global non-partitioned index)和全局分區(qū)索引(global partitioned index)[15-16]。
(1)全局非分區(qū)索引。索引數(shù)據(jù)不做分區(qū),保持單一的數(shù)據(jù)結(jié)構(gòu),但由于主表已經(jīng)做了分區(qū),會出現(xiàn)索引中的某一個鍵映射到不同主表分區(qū)的情況,即“一對多”的對應(yīng)關(guān)系。
(2)全局分區(qū)索引。索引數(shù)據(jù)按照指定的方式做分區(qū)處理,比如做哈希(hash)或范圍(range)分區(qū),將索引數(shù)據(jù)分散到不同的分區(qū)中。索引的分區(qū)和主表的分區(qū)是獨立的,因此對于每個索引分區(qū)來說,分區(qū)中的任一個鍵都可能映射到不同的主表分區(qū)(當(dāng)索引鍵有重復(fù)值時),索引分區(qū)和主表分區(qū)之間是“多對多”的對應(yīng)關(guān)系。
1.2 異構(gòu)的全局索引
索引和主表數(shù)據(jù)被獨立存儲在Cache 緩存系統(tǒng)和數(shù)據(jù)庫的存儲引擎中,具體有兩種實現(xiàn)方式:一種數(shù)據(jù)庫和外部Cache組件相互獨立[17],業(yè)務(wù)系統(tǒng)優(yōu)先到Cache 中查詢,如果Cache 中查詢不到,再查詢數(shù)據(jù)庫;另一種是直接在數(shù)據(jù)庫內(nèi)部集成Cache,典型的如MySQL 的innodb_memcached 組件[18]。兩種方式并沒有本質(zhì)區(qū)別,客戶端或應(yīng)用都需要維護(hù)兩條鏈路單獨訪問存儲引擎和Cache緩存組件,同時需要維護(hù)兩邊的數(shù)據(jù)一致性。除此之外,異構(gòu)環(huán)境下的并行離群點的檢測也需要一定的算法來實現(xiàn)[19]。
2 基于RDMA的低時延異步全局索引
為了解決以上全局索引數(shù)量有限、高峰期寫入事務(wù)RT抖動和資源占用集中度高等問題,本文中的全局索引設(shè)計為獨立于主表的一套分片表,和主表的元數(shù)據(jù)獨立,但是對于用戶不可見。使用局限性小于主表的二級索引,行的長度沒有限制,極端情況可以做成主表的聚集索引[20](clustered index,也稱聚類索引、簇集索引)完全覆蓋主表字段,避免網(wǎng)絡(luò)回表導(dǎo)致的性能衰減。其次,在提供對數(shù)據(jù)的事務(wù)性訪問中,采用動態(tài)時間戳[21]排序方式來提供可序列化,使得事務(wù)有更高的機(jī)會邏輯上可序列化的時間線。
在傳統(tǒng)的分布式數(shù)據(jù)庫或者并行數(shù)據(jù)庫環(huán)境中,一般采用計算和存儲分離的架構(gòu)設(shè)計,計算和存儲之間采用以太網(wǎng)連接,但網(wǎng)絡(luò)的傳輸速率遠(yuǎn)低于內(nèi)存訪問速率,而隨著RDMA等高速網(wǎng)絡(luò)技術(shù)的發(fā)展,網(wǎng)絡(luò)傳輸代價大幅度降低。此外,隨著非易失性存儲設(shè)備的發(fā)展,將索引放到非易失性存儲中并做索引結(jié)構(gòu)的重新設(shè)計也成為研究的熱點[22-24]。
本文基于RDMA的低時延全局索引設(shè)計的分布式數(shù)據(jù)庫系統(tǒng)的總體架構(gòu)如圖1 所示。整體架構(gòu)主要分為四部分,分別為:(1)計算集群,由1 到N個計算節(jié)點(computing node,CN)組成;(2)存儲集群,由1到M個數(shù)據(jù)節(jié)點(data node,DN)組成;(3)管理集群,核心模塊主要包含全局事務(wù)管理器(global transaction manager,GTM)模塊、元數(shù)據(jù)服務(wù)(meta data service,MDS)模塊以及本文新增的Cluster Cache 和Cluster MQ 模塊;(4)本文新增的全局索引構(gòu)建引擎Index Sinker 模塊,既可以單獨部署,也可以采用與管理集群合設(shè)的部署方式。
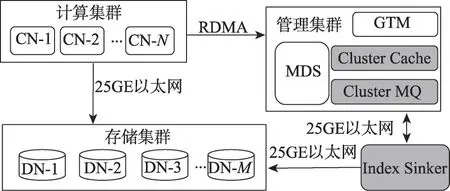
圖1 支持異步全局索引的分布式數(shù)據(jù)庫架構(gòu)Fig.1 Distributed database architecture supporting asynchronous global indices
本文的數(shù)據(jù)庫架構(gòu)中計算集群和管理集群之間采用RDMA連接,其余都采用25GE以太網(wǎng)連接。為了構(gòu)建異步低時延全局索引,新增加的3類節(jié)點的主要功能如下:
(1)Cluster Cache:集群緩存,用來存儲主表和索引表的日志的邏輯序列號(log sequence number,LSN)信息、時間戳(time stamp,TS)信息,以及Cache 類型的KV索引。
(2)Cluster MQ:集群消息隊列,用來緩存全局索引的數(shù)據(jù),采用appendOnly模式,寫入性能遠(yuǎn)高于直接寫入DN節(jié)點的B+Tree數(shù)據(jù)結(jié)構(gòu)。
(3)Index Sinker:全局索引構(gòu)建引擎,消費Cluster MQ 的索引信息,以批量方式寫入DN 集群,然后向MDS模塊更新該索引的LSN點位信息。
從應(yīng)用角度看,事務(wù)對應(yīng)的索引數(shù)據(jù)只要CN節(jié)點通過RDMA網(wǎng)絡(luò)寫入Cluster MQ之后就可以認(rèn)為事務(wù)已經(jīng)提交成功;而Index Sinker 采用異步模式根據(jù)一定規(guī)則把MQ 中的索引數(shù)據(jù)真正寫入DN 節(jié)點。本文設(shè)計的主要目的是為了降低事務(wù)的響應(yīng)時延和系統(tǒng)負(fù)載。
本文提出的全局索引總體結(jié)構(gòu)如圖2所示,由Hash(也可以采用列表、取模等方式組織)與B+Tree組成的兩層組成。其中Hash 層用來進(jìn)行分區(qū)路由,分區(qū)內(nèi)的索引則以B+Tree 的方式進(jìn)行組織。根據(jù)不同的查詢條件,這兩層索引配合的情況可以分成3 種:
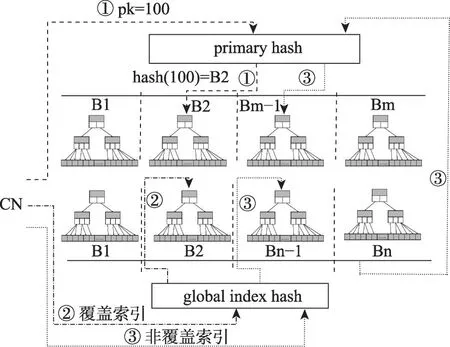
圖2 Hash和B+Tree結(jié)合的雙層全局索引架構(gòu)Fig.2 Hash and B+Tree two-layer global index structure
第一種情況,查詢語句中攜帶了可以直接路由的主鍵(primary key,PK)值,則如圖2的路徑①所示,先根據(jù)Hash算法,定位到對應(yīng)的B+Tree索引B2,再在B2中根據(jù)PK定位到具體的索引。
第二和第三種情況,如果全局索引的列可以覆蓋檢索字段,則如圖2 的路徑②所示,直接從全局索引返回數(shù)據(jù),否則如圖2 的路徑③所示,以主表的Distributed Key 和PK 作為邏輯指針,通過主表再查詢一次數(shù)據(jù)。
針對所有包含全局索引的表,如圖3 所示,在Cluster Cache中會維持一張Map映射表。CN節(jié)點會維護(hù)主表的LSN 和TS 信息。Index Sinker 會維護(hù)全局索引的LSN和TS信息。全局索引TS和主表TS之間差值,表示全局索引相對于主表落后。同時CN節(jié)點和Cache 緩存節(jié)點直接的網(wǎng)絡(luò)采用RDMA,利用RDMA API 用戶態(tài)驅(qū)動進(jìn)行通訊,避免內(nèi)核中斷,可降低網(wǎng)絡(luò)時延。針對Cache數(shù)據(jù)需要落盤的場景,由于不通過系統(tǒng)的IO 落盤,以Kernel Bypass 的方式直接寫入非易失性內(nèi)存主機(jī)控制器接口規(guī)范(nonvolatile memory express,NVME)硬盤,目的是為了降低磁盤開銷。
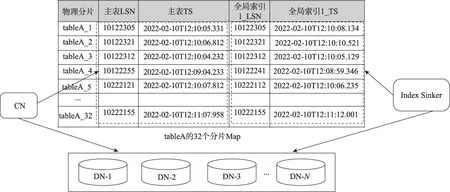
圖3 基于分片表的全局索引組織Fig.3 Global index organization based on sharded tables
2.1 全局索引讀取算法
優(yōu)化器在判斷表的元數(shù)據(jù)確認(rèn)含有全局索引情況下,需要加入全局索引的優(yōu)化規(guī)則。例如,全局索引掃描優(yōu)化規(guī)則GlobalIndexScanRule、全局索引連接優(yōu)化規(guī)則GlobalIndexJoinRule。CN節(jié)點在處理查詢語句時,判斷全局索引是否是覆蓋索引。
如果是覆蓋索引,查詢代價顯然是低于查詢主表,因此執(zhí)行計劃是否可以使用全局索引,只需要判斷全局索引數(shù)據(jù)和主表分片數(shù)據(jù)是否一致。在默認(rèn)情況下,需要滿足強一致性,即涉及到的主表分片的LSN=索引表LSN。業(yè)務(wù)SQL 上也可以增加hint 屬性,指定容忍索引數(shù)據(jù)落后多長時間閾值范圍內(nèi),可以路由到索引表。
如果是數(shù)據(jù)符合Cache索引,優(yōu)先查詢Cache,如果Cache 中存在,直接返回客戶端,如果Cache 中不存在,到DN節(jié)點上查詢一次。CN節(jié)點上使用RDMA API和Cluster Cache節(jié)點通訊,降低時延。
2.2 全局索引寫入算法
全局索引寫入時,Cluster MQ作為索引數(shù)據(jù)寫入的緩存管道,典型的先進(jìn)先出(first input first output,F(xiàn)IFO)隊列。CN節(jié)點負(fù)責(zé)向Cluster MQ寫入索引數(shù)據(jù),Index Sinker 節(jié)點負(fù)責(zé)向DN 節(jié)點寫入索引數(shù)據(jù)。由CN->Cluster MQ,Cluster MQ->DN,完成索引數(shù)據(jù)的二階段異步寫入,支持流控。在全局索引寫入過程中,CN節(jié)點算法如下:
算法1CN節(jié)點寫入數(shù)據(jù)(包含全局索引)
在用戶事務(wù)的主流程中,不涉及把全局索引的數(shù)據(jù)寫入DN 節(jié)點的流程,只需寫入主表的數(shù)據(jù)到DN 節(jié)點,全局索引數(shù)據(jù)寫入MQ 隊列。同時在Cluster Cache上推高主表數(shù)據(jù)的LSN點位,SQL優(yōu)化器在執(zhí)行查詢計劃的時候是否走全局索引,可以根據(jù)Cluster Cache 上存儲的LSN 點位信息精準(zhǔn)地判斷。LSN 的點位是以主表在每個DN 上涉及到的分表為key維度,LSN的MAP映射表,實現(xiàn)了一種無鎖化的數(shù)據(jù)結(jié)構(gòu),可以在CN節(jié)點上通過RDMA API以用戶態(tài)的方式高效寫入。在全局索引寫入過程中,Index Sinker節(jié)點算法如下:
算法2MQ上的索引數(shù)據(jù)寫入存儲引擎
判斷MQ 上的剩余數(shù)據(jù)量和DN 的節(jié)點的負(fù)載是否需要進(jìn)行索引數(shù)據(jù)同步。當(dāng)MQ 上的數(shù)據(jù)量過少并且距離上一次同步時間小于閾值(比如500 ms)時,跳過本次同步;同時如果DN 節(jié)點上的負(fù)載過大時,也跳過本次同步,等待DN 節(jié)點的負(fù)載滿足需求時才進(jìn)行同步。Index Sinker 從offset 點批量讀取Cluster MQ 上的Index 數(shù)據(jù),讀取的數(shù)據(jù)量需要參考DN節(jié)點的負(fù)載,考慮流控的因素(CPU負(fù)載、網(wǎng)絡(luò)流量、BufferPool負(fù)載),以免對TP的流量產(chǎn)生影響。從MQ 上讀取到的索引數(shù)據(jù),按照路由分組生成batchInsert 的數(shù)據(jù)結(jié)構(gòu),其中需要按索引鍵進(jìn)行排序,可以優(yōu)化B+Tree索引數(shù)據(jù)的寫入效率。寫入DN節(jié)點成功后,本文利用RDMAAPI向Cluster Cache更新LSN 點位和TS 時間戳信息,以及MQ topic 的offset信息。
3 實驗結(jié)果與分析
3.1 實驗設(shè)計
3.1.1 實驗環(huán)境和組網(wǎng)
本文搭建了基于RDMA 和以太網(wǎng)混合的3 主機(jī)實驗仿真環(huán)境,機(jī)器具體配置和網(wǎng)絡(luò)環(huán)境見表1,3個節(jié)點上部署的軟件模塊見表2。數(shù)據(jù)為脫敏后的真實銀行交易數(shù)據(jù)。在實驗對比中選取了典型的批量導(dǎo)入數(shù)據(jù)和交易場景,并分別與支持全局索引功能的Oracle 和CockroachDB 數(shù)據(jù)庫進(jìn)行對比。批量導(dǎo)入數(shù)據(jù)模型為:原表中含有40個字段,平均每條記錄為4 KB。建立1至3個全局索引,索引字段個數(shù)為10個。通過控制并發(fā)數(shù)調(diào)整導(dǎo)入的數(shù)據(jù)量,具體為每增加10個并發(fā),導(dǎo)入的記錄個數(shù)增加100萬條。

表1 實驗環(huán)境和組網(wǎng)Table 1 Experimental environment and networking
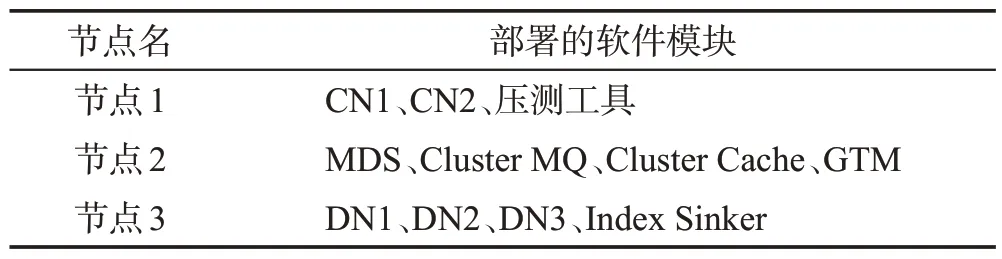
表2 網(wǎng)元分布Table 2 Network element distribution
3.1.2 實驗場景設(shè)計
實驗的測試項命名為GAGI(GoldenDB with asynchronous global index)。為了驗證GAGI 異步處理架構(gòu)的表現(xiàn),在實驗對比中選取了典型的批量導(dǎo)入數(shù)據(jù)和交易場景,并分別與支持全局索引功能的Oracle和CockroachDB數(shù)據(jù)庫進(jìn)行對比。CockroachDB架構(gòu)和GAGI結(jié)構(gòu)類似,都有CN、DN節(jié)點等,因此實驗涉及不同節(jié)點類型對比時,以CockroachDB 為主;Oracle 是單節(jié)點類型,涉及整體性能對比時,以O(shè)racle數(shù)據(jù)庫為主;其他情況則同時和這兩者對比。
批量導(dǎo)入數(shù)據(jù)模型為:原表中含有40個字段,平均每條記錄為4 KB。建立1至3個全局索引,索引字段個數(shù)為10 個。通過控制并發(fā)數(shù)調(diào)整導(dǎo)入的數(shù)據(jù)量,具體為每增加10 個并發(fā),導(dǎo)入的記錄個數(shù)增加100萬條。
交易場景為:金融行業(yè)使用頻率很高的快捷支付業(yè)務(wù)。如圖4 所示的模型簡要描述了該業(yè)務(wù)中查詢與插入全局索引表的操作,對私業(yè)務(wù)往往插入數(shù)據(jù)量隨機(jī)且有限,更加追求查詢和插入的性能。
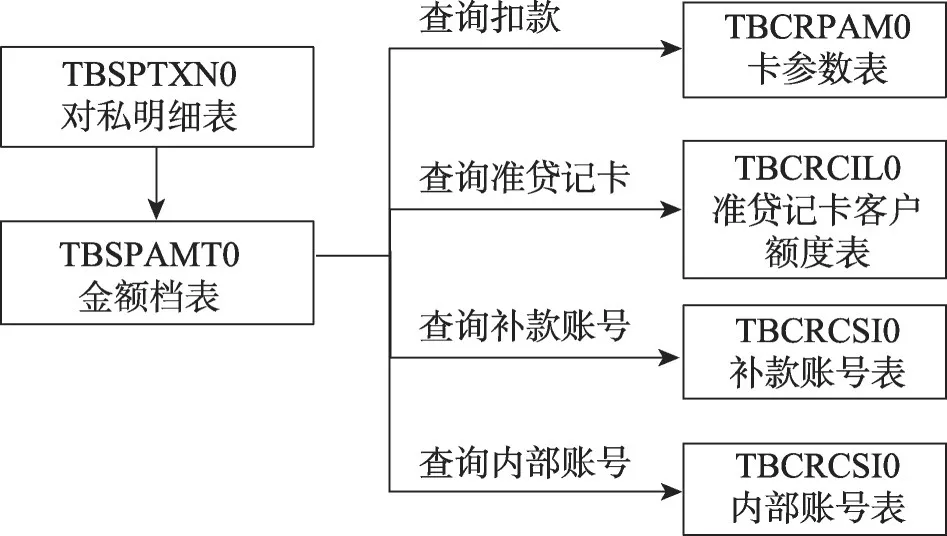
圖4 金融快速支付交易場景Fig.4 Financial fast payment transaction scenario
本文實驗所用的數(shù)據(jù)都來自國有大型商業(yè)銀行的真實環(huán)境,部分字段進(jìn)行了脫敏處理。下述的關(guān)系代數(shù)描述了此類交易對應(yīng)的事務(wù)模型,金額檔表TBSPAMT0(字段數(shù)>100 個,單條記錄>30 KB)是此交易事務(wù)的主要業(yè)務(wù)表,對該表的查詢操作單條記錄的數(shù)據(jù)量都在10 KB以上,最后的批量插入對私明細(xì)表TBSPTXN0操作的數(shù)據(jù)量在100 KB以上。
(1)查詢扣款
(2)查詢準(zhǔn)貸記卡
(3)查詢補款賬號
(4)查詢內(nèi)部賬號
由于金融交易場景的高并發(fā)需求,上述操作性能不能出現(xiàn)大幅下降,在TBSPTXN0 表上建立了全局唯一索引。為了驗證GAGI異步處理架構(gòu)的表現(xiàn),實驗重點對比了目前業(yè)界內(nèi)采取的同步處理全局索引表和二級索引子表。CockroachDB 架構(gòu)和GAGI結(jié)構(gòu)類似,都有CN、DN 節(jié)點等,因此實驗對比涉及不同節(jié)點類型對比時,以CockroachDB 為主;Oracle是單節(jié)點類型,涉及整體性能對比時,以O(shè)racle 數(shù)據(jù)庫為主,對比前兩者都做了相應(yīng)性能調(diào)優(yōu)。
3.2 實驗結(jié)果分析
Index Sinker模塊和異步機(jī)制的引入,使得GAGI在處理全局索引表的數(shù)據(jù)插入時能夠根據(jù)業(yè)務(wù)流量調(diào)節(jié)負(fù)載壓力。當(dāng)數(shù)據(jù)導(dǎo)入全局索引表主表引起網(wǎng)絡(luò)、磁盤和CPU等壓力超過一定范圍時,Index Sinker能夠通過感知DN節(jié)點側(cè)的流量,放慢或者暫停消費Cluster MQ端的消息的消費,從而達(dá)到提高業(yè)務(wù)承載能力的目的。
在實際金融場景中,高并發(fā)的數(shù)據(jù)導(dǎo)入和讀取全局索引表通常是錯開的,因此二級索引表的更新延時在一定區(qū)間內(nèi)是可以接受的。為了對比引入Index Sinker 等模塊后帶來的性能改變,本文建立了3.1.2小節(jié)中描述的兩種業(yè)務(wù)模型。第一種是為了模擬高并發(fā)情況下對多表導(dǎo)入數(shù)據(jù),以求獲得觸摸到服務(wù)器性能瓶頸的情況下兩種方案的表現(xiàn);第二種是模擬日常交易場景中的隨機(jī)讀寫,確認(rèn)新方案的引入對單表隨機(jī)讀寫的性能提升。本文通過調(diào)整并發(fā)度和全局索引的數(shù)目,驗證在新方案的改造下Index Sinker 的流控能力對GAGI 整體負(fù)載的保護(hù)和疏導(dǎo)能力。
3.2.1 批量導(dǎo)入數(shù)據(jù)性能提升結(jié)果分析
批量導(dǎo)入數(shù)據(jù)場景具備如下特征,即單次導(dǎo)入的數(shù)據(jù)大多分布在相同DN節(jié)點,單條記錄的數(shù)據(jù)大小幾乎相同,并且受其他業(yè)務(wù)干擾可以忽略不計。針對此類業(yè)務(wù)模型,本文所提出的方案參考了Index Sinker 的流控能力,使得其性能優(yōu)勢較為明顯。同時,由于二級索引表分布規(guī)則的限制(通過哈希等分布規(guī)則來平均各DN 節(jié)點存儲的數(shù)據(jù)量),同步架構(gòu)下全局索引表原表和二級索引表的插入通常情況下是分布式的,需要額外封裝分布式事務(wù)來保證數(shù)據(jù)的一致性。而將原表和二級索引表的數(shù)據(jù)導(dǎo)入分離開后,原表數(shù)據(jù)分布在相同DN節(jié)點的分布式事務(wù)會退化成單機(jī)事務(wù),減少了CN節(jié)點對分布式事務(wù)的控制處理、CN節(jié)點和DN節(jié)點的語句交互和DN節(jié)點刷臟處理等步驟,能夠進(jìn)一步提升數(shù)據(jù)導(dǎo)入的處理速度。
如圖5、圖6所示,通過對比兩種方案下的每秒事務(wù)數(shù)(transaction per second,TPS)和事務(wù)執(zhí)行平均耗時能夠發(fā)現(xiàn),異步處理全局索引表方案下分布式數(shù)據(jù)庫導(dǎo)入全局索引表的性能有了明顯的提升(圖5(b)和圖6(a),取表中帶有一個全局唯一索引的場景)。針對Index Sinker的流控作用和異步處理方式下取消了分布式事務(wù)的封裝兩個優(yōu)化點,圖5(a)(取10~60并發(fā)度下各數(shù)據(jù)庫的最高TPS進(jìn)行對比)中GAGI給出了明顯高于其他兩個產(chǎn)品的TPS,且其優(yōu)勢在增加全局索引個數(shù)后更加明顯。

圖5 全局索引個數(shù)和并發(fā)度對TPS的影響Fig.5 Influence of global index number and concurrency on TPS
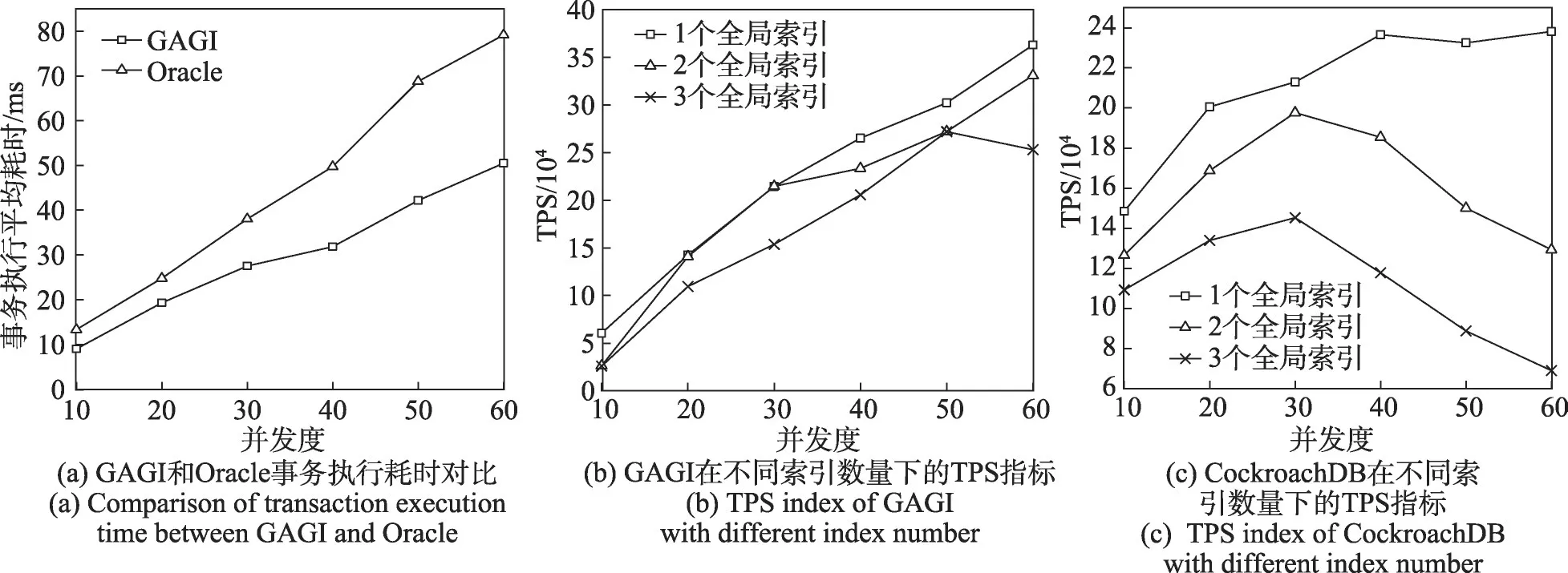
圖6 不同數(shù)據(jù)庫的全局索引性能對比Fig.6 Performance comparison of global indices in different databases
在擴(kuò)大全局索引的數(shù)目,即在數(shù)據(jù)庫內(nèi)部增加二級索引表的個數(shù)之后,在此測試場景下同步處理方式對CN 節(jié)點和DN 節(jié)點效率的負(fù)面影響更為明顯。全局索引個數(shù)達(dá)到兩個時,同步方案很快便觸及性能瓶頸(圖6(a),CockroachDB數(shù)據(jù)庫,單個全局索引的場景),對高并發(fā)的處理能力減弱,進(jìn)而導(dǎo)致TPS的回落。對于Oracle和CockroachDB來說,增加全局索引的個數(shù)不只是增加CN 節(jié)點整理和分發(fā)數(shù)據(jù)的壓力,更是帶來了導(dǎo)入DN 節(jié)點的數(shù)據(jù)量的增加。而新的處理架構(gòu)在全局索引數(shù)目達(dá)到3 個且并發(fā)較大時才觸及性能瓶頸,如圖6(b)所示。
通過監(jiān)控服務(wù)器上的CPU 使用率(N核CPU,則最大利用率為N×100%,本文實驗機(jī)器為64 核,因此最大利用率為6 400%,下同)和IO使用率可以看出,高并發(fā)多表導(dǎo)入場景下DN 節(jié)點接收端會出現(xiàn)長時間的網(wǎng)絡(luò)峰值,其寫入磁盤的效率會在磁盤寫入性能達(dá)到極限后迅速回落。此時CN 節(jié)點需等待接收DN 節(jié)點的處理結(jié)果,并進(jìn)行進(jìn)一步整合和計算,導(dǎo)致CN節(jié)點的CPU消耗增加,影響了其處理客戶端請求和向CN節(jié)點加大導(dǎo)入壓力的能力,同步處理模式下CN節(jié)點的CPU使用率低于GAGI,如圖7(a)所示。
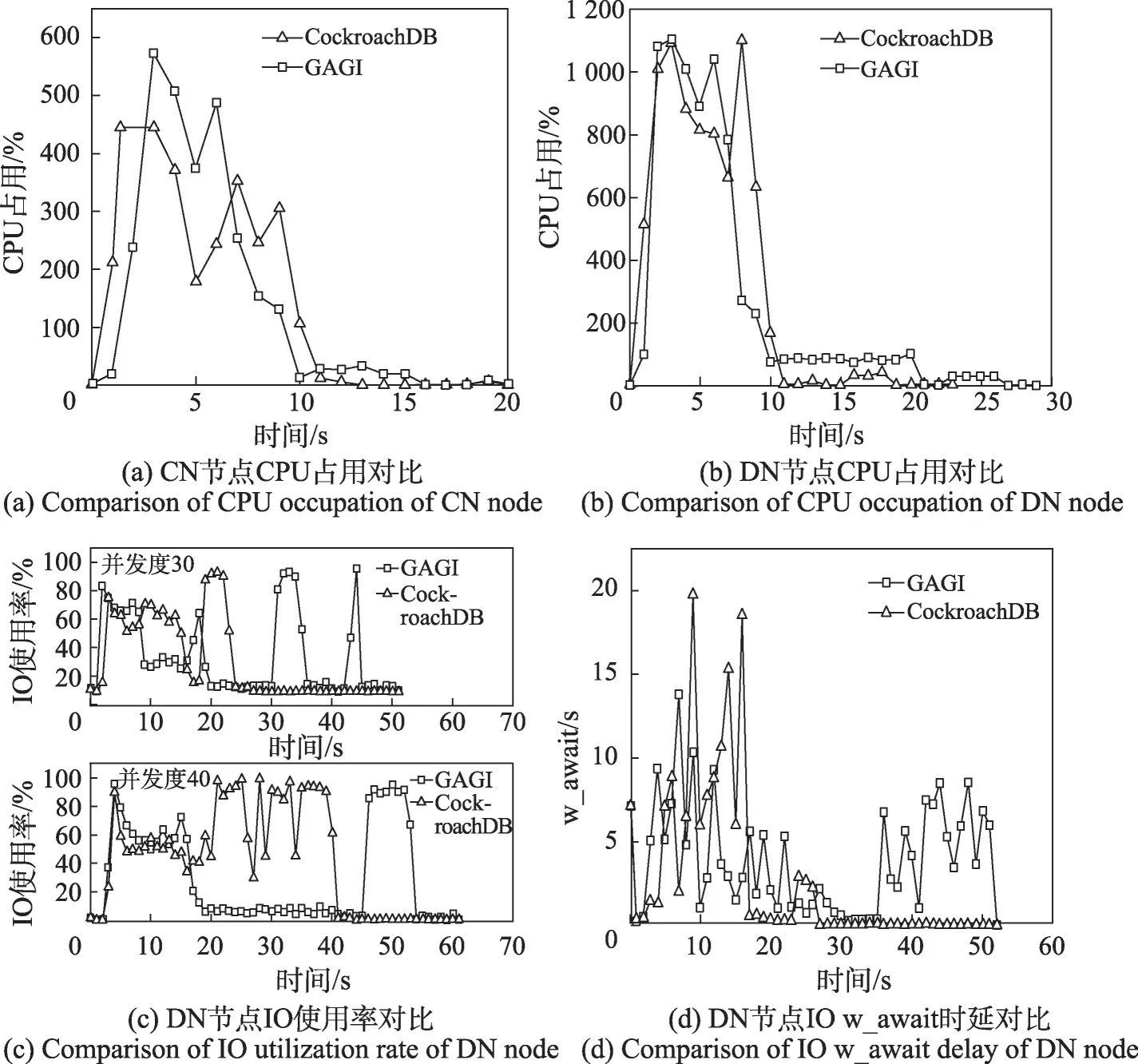
圖7 GAGI對資源的占用情況Fig.7 Occupancy of resources of GAGI
如圖7所示,通過(a)~(d)的對比,展示了異步處理架構(gòu)下GAGI內(nèi)部控制流量壓力的能力。CN節(jié)點的CPU 占用穩(wěn)定為0 代表著客戶端的業(yè)務(wù)壓力(30并發(fā)度)已經(jīng)結(jié)束,而該時間點后,在GAGI 的DN 節(jié)點的CPU 占用仍然存在且穩(wěn)定在一定的水平(圖7(a)、圖7(b))。相對應(yīng)的,磁盤的IO使用率在同步處理架構(gòu)下快速沖高和回落,而GAGI能夠在前端業(yè)務(wù)結(jié)束后仍然保持在較高的水平(圖7(c))。以上兩點充分說明GAGI 的異步處理方式能夠?qū)⑶岸藰I(yè)務(wù)壓力轉(zhuǎn)移到Index Sinker 后,由Index Sinker 根據(jù)DN 節(jié)點的壓力均勻地、異步地向其導(dǎo)入二級索引子表的數(shù)據(jù)。根據(jù)磁盤寫入等待時間的對比能夠看出(圖7(d)),同步處理架構(gòu)下數(shù)據(jù)庫在集中導(dǎo)入數(shù)據(jù)期間IO壓力過大導(dǎo)致寫入等待時間過長(約20 s),過度地占用資源反而會導(dǎo)致執(zhí)行效率的下降和嚴(yán)重影響其他并行的業(yè)務(wù)。而在新引入的異步處理架構(gòu)下DN節(jié)點的IO、CPU 和網(wǎng)卡等壓力不會在前端集中導(dǎo)入數(shù)據(jù)期間短時間內(nèi)過載,在Index Sinker合理分配DN節(jié)點的壓力后,GAGI不但提升了集中導(dǎo)入數(shù)據(jù)的效率,還能最大限度降低對并行業(yè)務(wù)的影響。
3.2.2 交易型場景性能提升結(jié)果分析
日常單表隨機(jī)讀寫測試更注重讀寫并行化,以模擬金融業(yè)務(wù)中并發(fā)交易的場景。其中3.2.1小節(jié)中描述的分布式事務(wù)優(yōu)化為單機(jī)事務(wù)的改進(jìn)點同樣適用于此模型。在此類測試架構(gòu)下,對于插入語句,優(yōu)化點在于二級索引表與原表的數(shù)據(jù)導(dǎo)入分離開來異步執(zhí)行,以及分布式事務(wù)退化為單機(jī)插入的處理;對于查詢語句,在二級索引表數(shù)據(jù)與全局索引表原表數(shù)據(jù)的導(dǎo)入時延處于較低的水平時,能夠通過精確化查詢策略、查詢二級索引表的方式保證處理效率。圖8(c)(單個全局索引情景)能夠充分證明優(yōu)化后的事務(wù)時延有了明顯的下降。

圖8 不同數(shù)據(jù)庫的全局索引對比測試Fig.8 Global index comparison test of different databases
引入Index Sinker和Cluster Cache組件后,GAGI處理涉及全局索引表的讀語句需要和Cluster Cache交互,獲取該表的當(dāng)前狀態(tài)從而確定查詢策略。在二級索引表導(dǎo)入時延較低的情況下,子表數(shù)據(jù)很快追上主表,從而推動CN 節(jié)點下發(fā)到DN 節(jié)點的查詢語句能夠包含索引字段,大大提升查詢速度;同時CN 節(jié)點能夠?qū)⒎植际讲樵兎植荚诙郉N 節(jié)點的原表,簡化為目的性更強的從確定DN節(jié)點撈取二級索引表的查詢策略,上述兩點優(yōu)化能夠彌補CN節(jié)點與Cluster Cache交互帶來的損耗,甚至能夠通過數(shù)據(jù)導(dǎo)入帶來的性能提升來推動整體讀寫操作的更優(yōu)表現(xiàn)(圖8(a),單個全局索引情景下的TPS對比)。
如圖8(b)所示,全局索引數(shù)目增大的情況下取10~60并發(fā)度下的最高TPS進(jìn)行對比,異步處理方案較之原有方案愈加懸殊的優(yōu)異表現(xiàn)能夠充分論證寫操作的性能提升對整體讀寫操作的影響。同時異步處理方案中CN 節(jié)點與Cluster Cache 的額外交互和二級索引表數(shù)據(jù)導(dǎo)入的時延,在可控范圍內(nèi)對業(yè)務(wù)模型沒有帶來明顯的沖擊。
相較于批量導(dǎo)入數(shù)據(jù)的測試模型,此交易模型下插入語句相對降低,且導(dǎo)入的數(shù)據(jù)量較小。如圖9所示,能夠看出在異步處理架構(gòu)下,客戶端業(yè)務(wù)停止后僅有小幅度的DN節(jié)點上的CPU占用,耗時相較于批量導(dǎo)入數(shù)據(jù)模型也更短。在導(dǎo)入數(shù)據(jù)語句更少、數(shù)據(jù)量更小的情況下GAGI 的異步處理架構(gòu)仍能夠帶來非常明顯的性能提升,也論證了此架構(gòu)下對于查詢語句的優(yōu)化效果。
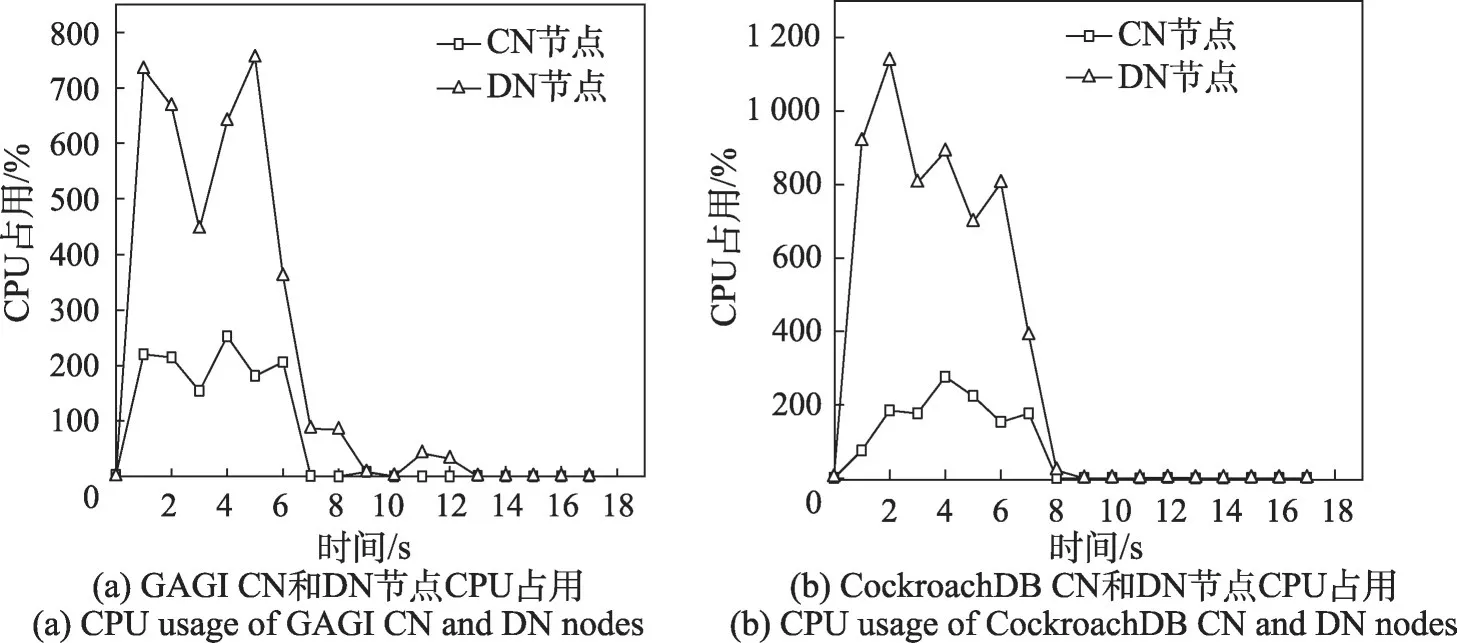
圖9 GAGI和CockroachDB的關(guān)鍵節(jié)點CPU占用Fig.9 CPU usage of key nodes of GAGI and CockroachDB
4 結(jié)束語
針對傳統(tǒng)的基于同步機(jī)制和以太網(wǎng)絡(luò)實現(xiàn)的全局索引方案,在金融核心業(yè)務(wù)典型的交易和批量導(dǎo)入數(shù)據(jù)場景下單表索引數(shù)量少、吞吐量降低、寫入事務(wù)時延加大等問題,本文提出了改進(jìn)的分布式數(shù)據(jù)庫中全局索引方法,將RDMA網(wǎng)絡(luò)引入CN和Cluster MQ 之間的通訊,以此顯著降低時延,將全局索引的實現(xiàn)方式修改成基于appendOnly的異步緩存隊列方式,通過對實驗測試數(shù)據(jù)的對比和分析,在同樣場景下比現(xiàn)有方法性能顯著提升,且對系統(tǒng)資源的峰值需求明顯降低。本文工作可以有效地提升分布式數(shù)據(jù)庫全局索引的可用性,有力促進(jìn)對現(xiàn)有傳統(tǒng)集中式數(shù)據(jù)庫的升級和替代進(jìn)程,支撐銀行金融業(yè)務(wù)的高質(zhì)量發(fā)展。
未來,計劃在全局索引緩存隊列中進(jìn)一步修改ElasticSearch 等組件,這樣可以更好支持全文索引,而且可以應(yīng)用于金融數(shù)據(jù)管理之外更廣闊的應(yīng)用領(lǐng)域。
猜你喜歡
財經(jīng)(2017年15期)2017-07-03 22:40:49
財經(jīng)(2017年2期)2017-03-10 14:35:35
華東師范大學(xué)學(xué)報(自然科學(xué)版)(2017年1期)2017-02-27 13:41:08
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
財經(jīng)(2015年3期)2015-06-09 17:41:31
財經(jīng)(2014年21期)2014-08-18 01:50:18
財經(jīng)(2014年6期)2014-03-12 08:28:19
財經(jīng)(2013年6期)2013-04-29 17:59:30
