超長指令字DSP標量訪存單元的設計與優化
2023-11-17 13:15:22陳海燕
計算機工程與科學 2023年11期
鄭 康,李 晨,陳海燕,劉 勝,方 糧
(國防科技大學計算機學院,湖南 長沙 410073)
1 引言
近年來,超大規模集成電路和計算機體系結構相關技術取得了前所未有的進步,計算系統的性能也隨之不斷提高。受制于工藝和器件特性,處理器和存儲器的發展邁向了2個不同的方向:一個重在提高運算的速度;另一個重在提升容量,而訪問速度的提升相對小很多。因此,處理器和存儲器的速度之差越來越大,限制了整個計算系統的性能,這即是“存儲墻”[1]問題。
數字信號處理器DSP(Digital Signal Processor)是一種專用微處理器,自問世以來便廣泛應用于圖像處理[2,3]、音頻處理[4]、汽車電子[5-7]等領域。目前的高性能DSP,如TI公司的C66x和CEVA公司的XC16等,均采用超長指令字VLIW(Very Long Instruction Word)架構而非超標量。VLIW架構將指令間的相關性檢測與調度等工作交由軟件完成,可以減小硬件資源與功耗,更適合嵌入式低功耗場景。此外,隨著AI(Artificial Intelligence)技術的發展與應用,VLIW在AI硬件加速器領域也顯現出了活力:Intel在其視覺處理器Movidius Myriad 2上就部署了多個VLIW向量處理器[8,9];Habana公司在其Gaudi和Goya系列產品上廣泛使用基于VLIW的SIMD(Single Instruction Multiple Data)張量處理器,用于加速AI訓練和推理過程[10]。
由于DSP的架構和應用場景與通用CPU存在差異,DSP并不適合直接采用CPU的訪存設計。針對DSP的架構和應用特點設計高效的訪存單元,以滿足其在訪存實時性、順序與固定延遲、高效數據一致性方面的需求,是提高DSP性能的關鍵。
DSP的應用非常廣泛,涵蓋了控制任務、實時處理、多線程等場景,處理實時數據的應用有著較高的實時性要求,采用CPU架構中單一的Cache訪存設計將嚴重影響這類應用的性能。VLIW的多發射方式對訪存指令的順序和延遲有明確要求,硬件若違反此要求將導致程序執行錯誤。存在多條延遲不同的訪存通路時,如何靈活、可靠地保證順序與固定延遲要求是硬件設計與優化的要點。DSP通過軟件維護多核Cache一致性,硬件提供Cache寫回功能為軟件提供支持,寫回操作的性能是實現多核DSP高效數據一致性的關鍵。
本文從高性能DSP常見的存儲結構出發,考慮VLIW架構和DSP應用場景的特點,設計了標量訪存單元,主要工作如下:
(1)采用Cache、靜態隨機訪問存儲器SRAM(Static Random Access Memory)可配置的設計,滿足訪存實時性要求,以適應不同應用需求。
(2)提出了基于ID的順序機制,保證訪存指令的順序與固定延遲,存儲開銷為87.5 B。
(3)通過尋找Cache狀態位(Valid、Dirty)按位與后第一個1(“首1”)的位置,直接定位Cache中的有效臟行,加速一致性寫回操作,提高了多核DSP數據一致性的效率。有效臟行占Cache容量25%,50%和75%這3種情況下,采用硬件“首1”寫回所消耗的時鐘周期數分別為272,528和785,為逐行掃描的26.4%,51.3%和76.2%,可見時間開銷只與有效臟行數量成正比,與Cache容量無關。
(4)搭建了基于SystemVerilog的驗證平臺,并驗證了設計實現的正確性。
2 相關工作
針對DSP的訪存設計,有許多工作都考慮到了應用程序的不同特點,設計了適用性更高的各類Cache,應用程序貼合Cache架構特點時,可以獲得更高的性能。
通過研究DSP應用中的計算模式和數據特征,可以指導高效的硬件設計。DSP因為高能效的乘加MAC(Multiply Accumulate)操作而廣泛用于邊緣卷積神經網絡系統,卷積神經網絡計算中存在大量為零的數據。據此,Lee等[11]提出了ZBS(Zero-Block-Skip)Cache,在寫入全零數據時將其地址記錄進ZBS Cache,后續讀取若命中ZBS Cache,則直接返回全零的數據,這樣可以降低DRAM訪問。ZBS Cache在包含大量零數據時可以有效提高性能并降低功耗,但處理不符合該特征的應用時反而會引入額外的功耗,對不同場景的適用性支持不夠。
硬件設計中,采用可配置的方式可以提高硬件對不同場景的適用性。Manjunatha等[12]設計了Cache組相連路數控制器,支持對Cache映射機制的動態調整,以便適應不同應用的特征。基于此,在Liang等[13]專為通信領域研制的一款DSP中,一級數據Cache為4路組相連,Cache容量可以配置,不同類型的應用可以根據自身的特點來配置Cache容量,未使用的Cache存儲體會通過時鐘門控的方法降低其產生的動態功耗。
在一款為移動應用設計的DSP中,Mohanmmad等[14]采用了路數可變的組相聯L1D Cache設計,通過選擇性地訪問存儲體來動態改變每組的路數,但Cache容量也會變化,路數減小則Cache容量也減小。數據的訪問在Cache命中判斷之后,只有命中的數據存儲體才會被訪問,借助時鐘門控可以降低功耗。
上述方案雖然支持Cache容量和組相連路數的靈活配置,但這些變量都不影響存儲器作為Cache的性質,對于數據復用性較差或實時性要求高的應用來說,性能提升十分有限。文獻[15]采用的可配置設計雖然考慮了訪存實時性,但其引入的仲裁邏輯面積占比為3.9%,有進一步提升空間。
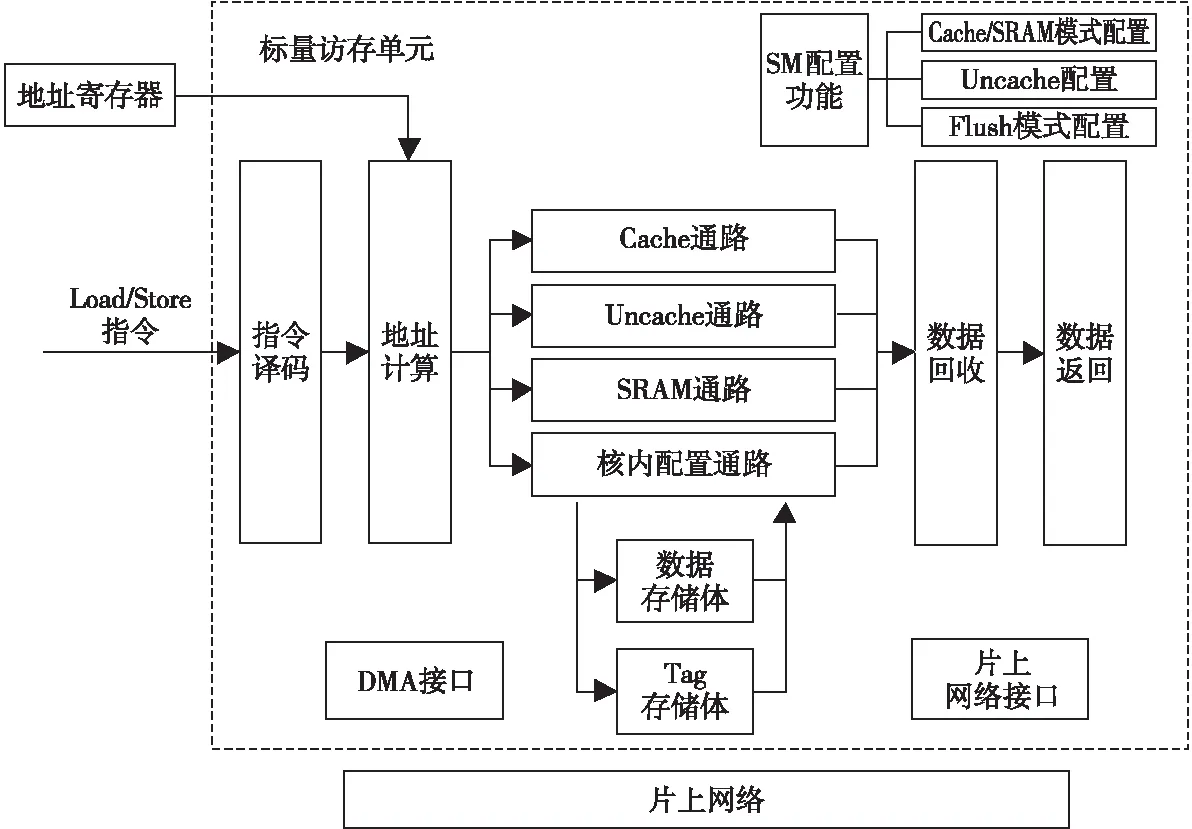
Figure 1 Overall structure of scalar memory unit圖1 標量訪存單元總體結構
3 標量訪存單元設計
標量訪存單元在DSP的存儲層次中屬于第一級數據存儲,DSP核對核外、核內數據的訪問都要經標量訪存單元完成。標量訪存單元內部實現了4條訪存數據通路,其總體結構如圖1所示,Cache通路與Uncache通路負責核外數據的訪問,SRAM通路與核內配置通路負責核內數據的訪問。為了滿足DSP的訪存實時性,通過可配置的設計使標量訪存單元能夠在Cache與SRAM之間切換,片上SRAM能夠滿足復用性差或實時性要求高的應用。在Cache/SRAM可配置的設計中,通過合理復用標量訪存單元的數據存儲體,能夠有效降低SRAM模式帶來的硬件開銷。
標量訪存單元的輸入為Load、Store訪存指令,支持Cache/SRAM 2種工作模式的配置,2種模式下均允許從字節到4字粒度的訪問。在SRAM模式下,還提供了DMA接口以實現大量數據的快速搬移。發送給標量訪存單元的訪存指令經譯碼、地址寄存器訪問、地址計算后得到訪存地址,指令將根據該地址及當前所處模式流向4條不同的訪存通路。針對核外數據的訪問由Cache通路與Uncache通路完成:
(1)Cache通路。Cache模式下,訪問核外可Cache數據的指令會流向此通路,若數據命中Cache則執行訪存操作;若數據缺失則停頓流水線,并通過片上網絡向下一級存儲請求數據。缺失時,如需將Cache中某一行替換出來為缺失行提供位置,則根據最近最少使用LRU(Least Recently Used)算法選擇被替換的行。
(2)Uncache通路。Cache模式下訪問核外不可Cache數據的指令、SRAM模式下訪問任意核外數據的指令都會流向此通路。該通路中,標量訪存單元直接通過網絡向下一級存儲請求數據。
針對核內數據的訪問由SRAM通路與核內配置通路完成:
(1)SRAM通路。SRAM模式下,訪問核內數據的指令會流向此通路,片上SRAM相當于一個永遠命中的Cache,此時流水線不會停頓,訪存指令一定能直接執行。
(2)核內配置通路。標量訪存單元內部有許多配置和狀態寄存器,例如控制Cache/SRAM模式的配置寄存器和Cache模式下命中、缺失信息統計寄存器等。這些寄存器都統一映射到地址空間中,針對特定地址的訪問會訪問這些寄存器,相應指令也就流向此通路。
對于Load指令,從各個通路獲得的數據將進入數據回收站,最后按照VLIW架構的順序與固定延遲要求將數據返回。標量訪存單元是DSP內核私有的,核外數據的訪問主要在Cache模式下完成,核內數據的訪問主要在SRAM模式下完成。
3.1 核外數據訪問
核外數據的訪問,如DDR(Double Data Rate)內的數據,主要在Cache模式下完成。在標量訪存單元內部,存儲體的組織結構設計優先考慮Cache模式。標量訪存單元作為Cache時,大小為32 KB,采用2路組相連映射,共512組,每路大小為32 B。在Cache通路中,為了能在一個時鐘周期內完成Cache命中情況的判斷,需要同時檢查2路Tag值,因此需要2個Tag存儲體。數據也使用了2個存儲體,數據訪問在判斷命中的下一個時鐘周期,由于此時命中情況已知,至多只需訪問其中一個數據體,另一數據體的使能信號可直接關閉,以降低功耗。

Figure 2 Arbitration of SRAM requests圖2 SRAM請求的仲裁
出現缺失時,整個流水線會停頓,由硬件狀態機完成向下一級存儲器請求數據的過程。寫入下一級返回的新數據時,替換策略采用LRU算法,因為Cache中1組只有2路,每組只需要添加1位LRU位,每次訪問后將LRU位置為本次未訪問的那一路,便可實現LRU算法。若被替換的舊數據是臟的,則還需將舊數據寫回到下一級,以保證數據的正確性。
Cache模式下還支持對核外某些地址范圍的數據是否可Cache進行配置,同樣由標量訪存單元內的配置寄存器實現。對于可Cache數據,其訪問由前述Cache通路完成;對不可Cache數據,其訪問由Uncache通路完成,計算出地址后就直接通過網絡向下一級存儲發出請求。Uncache通路中,若為讀操作,則停頓整個流水線,待數據返回時再恢復;若為寫操作,則流水線不會停頓,且只要網絡不繁忙,針對Uncache數據的寫支持連續執行。
標量訪存單元配置為SRAM模式時也可以訪問核外數據,此時數據體全部負責核內數據的存儲,因此針對核外數據的訪問全部進入Uncache通路,按照前述Uncache的方式處理。
3.2 核內數據的訪問
核內數據的訪問主要在SRAM模式下完成,此時標量訪存單元對應著地址空間中固定分配的32 KB核內數據空間,對該空間的訪問都會流向SRAM通路。Tag體將被忽略,2個數據體各負責16 KB,按高位交叉編址。
計算出訪存指令的地址后,先根據地址高位確定要訪問的數據落在哪一個數據體,再訪問被選中的數據體,此時另一個數據體的使能信號同樣可以關閉,以降低功耗。SRAM無需進行任何Cache管理,因而可以做到連續不斷地訪問,能滿足實時性。
作為SRAM時,為實現快速搬移大量數據,添加了DMA接口,包含讀、寫2個通道。若DMA讀、DMA寫以及訪存指令同時訪問數據,由于數據存儲體只有一個端口,可能會出現沖突,需要進行仲裁。仲裁邏輯的規則如下:
(1)Load、Store指令優先。訪存指令來自于程序的執行,為了保證程序的正常執行不受影響,訪存指令的優先級最高。不論訪存指令訪問哪個數據體,不論是否有DMA請求與其沖突,無條件執行訪存指令。
(2)DMA任意通道與訪存指令不沖突且DMA通道之間也不沖突時,可響應該DMA通道的請求。此種情況見于一個數據體由某一DMA通道訪問,另一數據體由訪存指令(或另一通道)訪問,2個數據體的訪問可以并行執行,互不影響。當另一數據體出現訪存指令與DMA沖突時,訪存指令無條件優先。
(3)DMA與訪存指令不沖突,但2個DMA通道之間沖突時,通過輪詢的方法進行仲裁。此種情況見于DMA讀、DMA寫訪問同一數據體(訪存指令不訪問)時。若上次沖突時讀優先,則此次寫優先;若上次沖突時寫優先,則此次讀優先。硬件通過1位寄存器記錄下次優先的通道,每次仲裁后將寄存器取反即可。
圖2列出了上述仲裁情形,虛線表示本次仲裁成功的請求。
標量訪存單元內部實現了許多核內配置和統計寄存器,這些寄存器都統一映射到地址空間中,可通過Load、Store指令直接訪問。在Cache、SRAM 2種模式下,針對核內寄存器的訪問都將流向核內配置通路,完成對寄存器的讀寫操作。
3.3 可配置的Cache/SRAM
Cache是緩解“存儲墻”問題的有效方案,其應用相當廣泛,幾乎所有的計算設備都包含Cache。Cache利用程序執行的時間局部性和空間局部性,將當前常用的數據存在一個容量小但速度快的存儲器中。這樣能夠快速響應大部分訪存指令,只在少數情況下訪存延遲較高[16]。
大部分的應用程序,如執行控制任務、處理靜態數據或復雜計算等,程序本身就擁有較好的局部性,在Cache的加持下可以取得較好的性能。但是,在處理流媒體數據、無線信號等場景下[17,18],程序訪存的時間和空間局部性較差,Cache缺失率會顯著增大,維護Cache所導致的時間開銷也會增加,從而嚴重影響程序性能。此外,出現Cache缺失所耗費的時間也難以滿足對實時性要求較高的場景。對于這類應用,片上SRAM比Cache更貼合其特征,針對SRAM的快速訪問與數據是否復用無關;由于不用維護任何Cache性質,沒有缺失,SRAM可以滿足實時性的要求。
上述2類程序都屬于DSP的應用場景,因此DSP的訪存設計應當兼顧這2類程序的特征,可配置的Cache/SRAM能夠以較小的開銷滿足需求。相比于同時包含Cache和片上SRAM,其硬件更簡單,資源和面積消耗小,2種不同模式可以共用同一存儲器件,利用率較高。此外,DSP很少有通用CPU的多用戶、多任務場景,其運行環境更為單一,在Cache和SRAM之間切換的頻率很低,也適合這種可配置的設計。
標量訪存單元內部利用一個模式控制寄存器(SMMCR)完成Cache/SRAM模式的配置。SMMCR與其他寄存器一樣被映射到地址空間中,程序通過Load、Store指令訪問其地址即可對其進行讀寫。圖3所示為Cache/SRAM模式切換過程。

Figure 3 Process of mode switching圖3 模式切換過程
(1)SMMCR=1時為SRAM模式,軟件先執行一條柵欄(fence)指令,再向SMMCR寫入0即可切換至Cache模式。柵欄的功能是排空標量訪存單元內正在執行的所有指令,保證切換前的指令都能正確執行。
(2)SMMCR=0時為Cache模式,軟件先執行一次寫回(flush為寫回宏)操作,再向SMMCR寫入1即可切換至SRAM模式。由于Cache中緩存的數據可能被修改過,故需要先執行寫回操作以確保數據一致性。
4 面向VLIW與數據一致性的優化
為確保VLIW架構所要求的順序與固定延遲,并實現多核DSP高效數據一致性,本文提出了2種優化方法:
(1)基于ID的順序機制。通過循環計數器為指令分配ID,利用ID隊列確保指令順序,根據ID與計數器值確保指令延遲,在多條延遲不同的通路匯聚時能有效解決亂序到達、提前到達的問題,靈活、可靠地滿足VLIW架構的需求,存儲開銷為87.5 B。
(2)數據一致性加速。通過對Cache中Valid、Dirty狀態位進行按位與得到有效臟行向量,利用硬件查找向量中的第一個1(即“首1”)快速定位待寫回行,加速了一致性寫回操作,提高了多核DSP數據一致性的效率。
下面詳細介紹這2種優化方法。
4.1 基于ID的順序機制
VLIW架構將指令間的相關性檢測和調度工作交給編譯器靜態完成,這就要求指令執行的時間(即延遲)在編譯時就必須確定。對Load指令而言,其取回的數據必須在固定的時間有效。為了固定指令的執行時間,微架構實現上通常采用鎖步的方式,任意功能單元停頓將造成整個DSP核停頓,讓所有功能單元經歷的非停頓節拍數相同。標量訪存單元接收到Load指令后,經過約定好的非停頓拍數才能返回數據,不能提前也不能推遲。為了方便討論,以圖1中的地址計算站為起點,標量訪存單元必須在計算完Load地址后的第6個非停頓節拍準時返回數據,這是固定延遲要求。此外,先執行的Load指令應當先返回數據,后執行的后返回,這樣才能保證寄存器狀態的修改符合匯編程序的語義,這是對順序的要求。
在圖1所示的流水線中,Load指令取回的數據會出現提前到達或亂序到達的情況。對SRAM通路而言,由于片上SRAM的訪問1拍即可完成,無需用完6拍就能返回數據;Uncache通路中,收到訪存請求后立即置位停頓信號,等到網絡返回數據后再清除停頓,也是不到6個非停頓節拍就能得到數據。如果數據提前到達后直接返回,就屬于提前返回,不滿足固定延遲要求。
在Cache模式下,假設未命中Cache的Load1指令緊跟訪問Uncache空間的Load2指令。Load1進入Cache通路經過判斷命中之后才能將停頓信號置位,而此時Load2已經進入了Uncache通路,向網絡請求數據并置位停頓信號。Load2停頓整個內核時,Load1也卡在Cache通路中不再流動。當網絡返回Load2數據后,Load1才繼續在Cache通路中流動。這種情況下,Load2的數據已經返回而Load1還在處理,Load2數據比Load1數據先到達數據回收站,出現了亂序到達,直接返回將違反順序要求。
為了保證VLIW架構的順序與固定延遲要求,設計了基于ID的順序機制,如圖4所示。該機制中最重要的3個部件為:
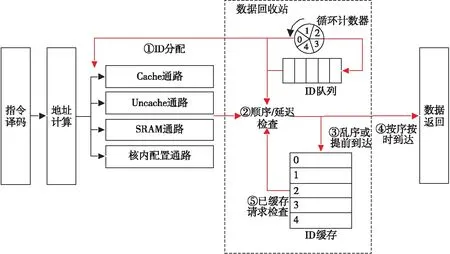
Figure 4 ID-based ordering architecture圖4 基于ID的順序機制架構
(1)循環計數器。循環計數器對非停頓節拍數進行計數,停頓時其值保持不變,非停頓時自增,當計數到4便跳回0。Load指令流向不同通路時,將當前節拍計數器的值作為其ID。
(2)ID隊列。Load指令流向不同通路時,其對應的ID同時發送到數據回收站中的ID隊列。Load指令是按序發送的,也將按序進入隊列,ID隊列記錄了Load指令的正確順序,隊首ID就對應下一個應當返回的Load。
(3)ID緩存。提前到達、亂序到達的數據,由于不能直接返回,因此需要將其暫存,這就是ID緩存的任務。ID緩存包含5條記錄,編號為0~4,與ID號一一對應,需要緩存的Load會被緩存至其ID對應的位置。
一條Load指令A經地址計算、ID分配后流入相應通路(①),經執行后其數據到達數據回收站,將接受順序和延遲檢查(②)。
ID隊列按序存放了流出指令的ID值,若A的ID值不等于隊首ID值,說明A不是下一條應該返回的指令,它是亂序到達的,因此需要將A的數據暫存至ID緩存,其在ID緩存中暫存的記錄編號等于其ID號(③)。若A的ID與隊首ID相同,說明A確實是下一條應當返回的指令,順序正確,還需進行延遲檢查。由于所有Load都要在非停頓的第6拍給出數據,A只有在非停頓的第5拍到達數據回收站才可以不暫存。若A在第5拍之前到達,則屬于提前到達,違反了固定延遲,仍需要暫存至ID緩存(③);若A恰好于第5拍到達,此時A按序按時到達,可以直接準備下一拍輸出(④)。
Load指令的ID值源自于非停頓節拍計數器,利用ID值和到達數據回收站當拍的計數器值即可確定該Load是否按時到達。若Load指令及隊首的ID為0,說明該Load是0時刻流出的,其非停頓第5拍時計數器應當為4,則ID為0與計數器值為4對應。其他ID值按同樣方法推導便可得到延遲檢查表,如表1所示。
除了對新到達的Load指令進行處理外,也要檢查已經暫存至ID緩存中的Load指令。若發現某條Load指令滿足順序和固定延遲,則下一拍就將其返回(⑤)。所有已暫存指令和新到達指令的處理過程是并行執行的,且兩者的比較原理和流程是一致的,如圖5所示。

Figure 6 Execution of two load instructions圖6 2條Load指令的處理
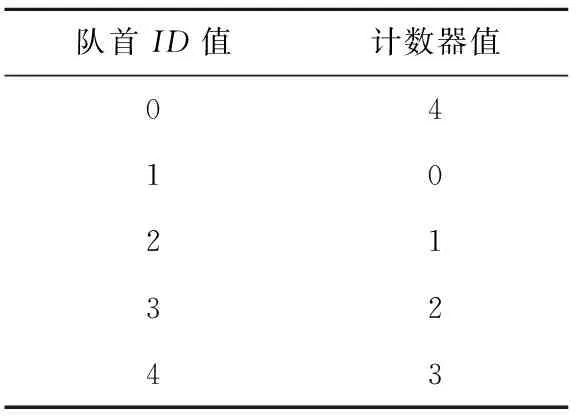
Table 1 Delay checking table
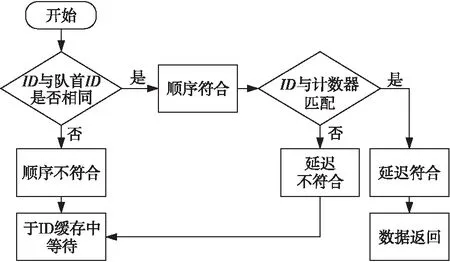
Figure 5 Check flow of load instructions圖5 Load指令檢查流程
圖6以未命中的Cache訪問緊跟Uncache訪問為例,說明該機制的工作流程。內核停頓及等待片上網絡響應的時間在圖6中已略去。以下按照時間先后描述圖6中各事件:
①訪問可Cache數據的Load指令發出,記為Load1,其ID為1,目的寄存器(圖中Rd)為5。
②訪問Uncache數據的Load指令發出,記為Load2,其ID為2,目的寄存器為6。
③Load2率先到達數據回收站,此時指令順序已亂,Load2將進入ID緩存,不會被直接返回。
④Load1到達回收站,此時Load2依然未返回。
⑤Load1先返回,寫目的寄存器5,循環計數器為1,恰好為Load1發出后的第6拍;隨后Load2返回,寫目的寄存器為6,循環計數器為2,為Load2發出的第6拍。
可以看出,2條順序發出的Load指令,亂序進入數據回收站,最終又順序返回,且返回時間符合固定延遲要求。基于ID的順序機制,將不能直接返回的Load進行暫存,待其滿足條件后再返回數據,保證了VLIW所要求的順序和固定延遲,存儲開銷為87.5 B。
4.2 數據一致性加速
在通用CPU中,多核Cache一致性通常由硬件負責,硬件采用Snoop、Directory等協議來實現一致性。一致性協議會讓Cache控制變得十分復雜,資源、面積和功耗等開銷也比較高,不太適合于嵌入式低功耗領域。為了讓硬件更簡單,DSP通常只提供寫回功能,可以將特定地址范圍內的數據從Cache作廢或者寫回到下一級存儲器。多個DSP核共享數據時,軟件需要利用寫回功能來維護多核DSP數據一致性。如圖7所示,核H1寫入某個共享變量后,應當將數據寫回到下一級存儲器;核H2讀取該共享變量時,需要先將其作廢,再發出讀請求,出現缺失時向下一級存儲器請求最新的值,從而避免讀到舊值。在基于多核DSP搭建的雷達[19]、聲吶[20,21]等系統中,圖7所示是常見的數據共享方式。
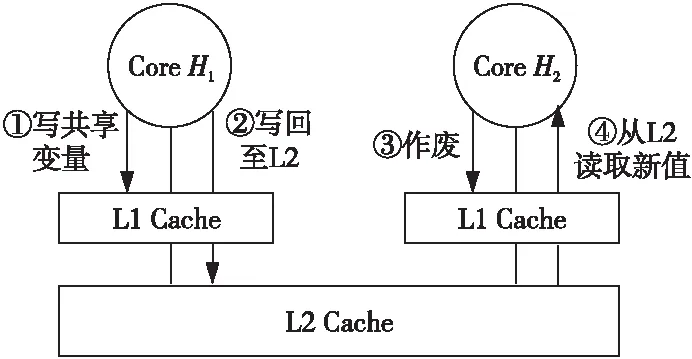
Figure 7 Sharing data consistency through write back圖7 利用寫回實現共享數據一致性
執行一致性寫回時,一種方法是對目標地址空間中的每一行都進行判斷,檢查其是否在Cache中,若在Cache中且為臟則寫回,否則便跳過。該方法的時間開銷與地址空間的大小成正比,當地址空間范圍很大時,如1 MB,需要檢查的行數是非常多的,時間開銷無法接受。當地址空間范圍超過Cache容量時,可以不對地址空間進行掃描,轉而對Cache逐行掃描,Cache中處在地址空間內的臟行將會被寫回,其余行則跳過。這樣,一致性寫回操作時間開銷的上限就由Cache的行數決定。對標量訪存單元而言,逐行掃描整個Cache的時間開銷至少為1 024個時鐘周期。
上述方法雖然在大地址空間時降低了時間開銷,但逐行掃描整個Cache依然要消耗不少時鐘周期。當Cache中有較多無效行或非臟行時,針對這些行的掃描完全是無效操作,因為它們不可能是寫回的對象。為進一步提高多核數據一致性的效率,設計了硬件查找“首1”的寫回方法,寫回時跳過Cache中的無效行和非臟行,使整個操作的時間大大減小。
一致性寫回操作關注的對象是Cache中的有效臟行,利用Cache中現有的Valid、Dirty狀態位進行與操作便可得到表示有效臟行的位向量,記為VD。通過當前寫回行的位置,可以直接定位到下一有效臟行,關鍵步驟如下:
①利用當前行的位置信息,可以得到一個mask向量,在這個向量中當前行及其之前的行為0,之后的行為1。
②用mask向量與VD向量進行與操作,則可以在VD中屏蔽掉當前行及其之前的所有行。
③針對屏蔽后的VD,利用硬件找出第一個1的位置,即為下一有效臟行,中間的無效行、非臟行均已跳過。

Figure 8 Consistency write back speed up圖8 一致性寫回加速
圖8說明了上述一致性寫回操作的加速過程,其中最關鍵的部分為mask向量的生成和硬件查找“首1”,這兩者的計算原理如圖9所示。

Figure 9 Computation of mask and leading one圖9 mask與“首1”的計算
已知某一行的位置時,將位置向量按位取反再加1,該位置之前會不斷進位至第一個0處,恰好為該位置,之后利用初始位置向量對該位置進行屏蔽即可得到mask向量。硬件查找“首1”通過二分法實現,以尋找4位向量中的“首1”為例,記輸入為一個4位向量VD,輸出為2位的索引index。先將VD分為2組,相鄰2位為一組。index的高位代表著“首1”出現在哪一組,這可以通過判斷每組是否為全0來實現。通過組內先非后與邏輯計算出代表每組是否全零的向量zero,若第1組為全0則index高位為1,否則為0。index的低位代表“首1”在某一組內的偏移,對組內低位取反即可得到該偏移,具體選擇哪一組的偏移由index高位控制。
向量長度較大時,通過多級二分法對向量進行分解,分解后的各部分之間能夠并行執行,避免關鍵路徑。硬件查找“首1”的機制,跳過了Cache中的無效行和非臟行,轉而只對其中的有效臟行進行處理,大大減小了一致性寫回操作的時間開銷,提高了多核DSP數據一致性的效率。
5 實驗和結果分析
5.1 驗證方案
為確保設計的正確性,使用SystemVerilog語言搭建了模塊級驗證環境,并在Linux環境下進行前端仿真、驗證,驗證環境如圖10所示。

Figure 10 Verification environment圖10 驗證環境
圖10中,LDST驅動負責生成隨機訪問的Load、Store指令,DMA驅動生成隨機的DMA請求。訪存指令和DMA請求送往標量訪存單元處理的同時,也會發給黃金模型,黃金模型通過軟件方法采用與標量訪存單元相同的機制來處理訪存指令和DMA請求。內存模型利用了SystemVerilog中的關聯數組,模擬了一個片上網絡和下級存儲的環境。Load指令及DMA讀通道從標量訪存單元和黃金模型讀出的值會進入記分牌進行比較,如果出現結果不一致將報告錯誤。此外,SVA斷言不斷檢測一些設計特性是否滿足,如一條Load指令是否在非停頓第6拍給出數據,若不滿足也會報告錯誤。
在Cache和SRAM 2種模式下,針對每條數據通路、核內核外空間都進行了百萬次激勵驗證,均已通過,可配置設計下的各數據通路訪問工作正常。
5.2 邏輯綜合
在12 nm工藝下對整個標量訪存單元進行綜合,其總面積開銷為183 978.954 2 μm2,功耗為61.332 4 mW,時鐘門控率達93.90%。圖11列出了主要模塊的單元面積占比。
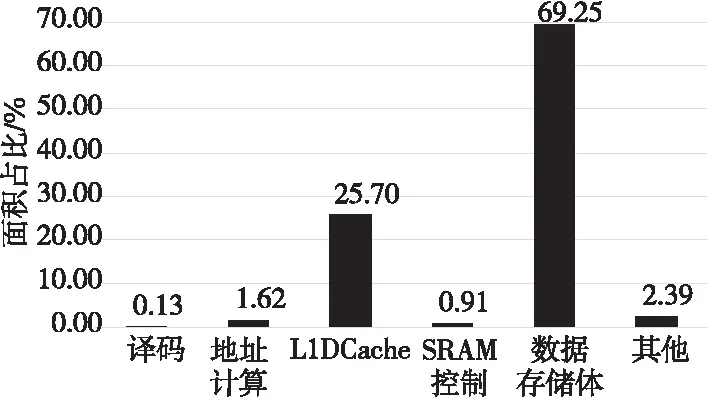
Figure 11 Area occupation of main modules圖11 主要模塊面積占比
與文獻[12-14]的相比,可配置的設計使得標量訪存單元適用的場景更加廣泛,能夠滿足訪存實時性需求。從圖11可以看出,SRAM控制邏輯的面積僅占總面積的0.91%,較之[15]的進一步降低。
5.3 基于ID的順序機制
4.1節介紹了基于ID的順序機制及其主要結構與工作流程,現對該機制的功能正確性進行證明,并分析其存儲開銷與優勢。
如圖12所示,設VLIW架構的固定延遲要求為指令發出后的第T+2(T≥0)個時鐘周期返回數據(包含發出與返回這2個時鐘周期,故至少為2)。循環計數器與ID值在0~T,計數器可以看作進行模T+1加法運算,故對任意的ID值,ID與(ID+T)mod(T+1)延遲匹配。設訪存流水線中共有N條通路,并記第i條通路的延遲為delayi,且0≤delayi≤T。

Figure 12 Case of N paths圖12 N條通路的情況
現有2條指令i、j,指令i于第Si時鐘周期發向通路i,其ID值為IDi,應當于第Si+T+1時鐘周期返回;指令j于第Sj時鐘周期發向通路,其ID值為IDj,應當于第Sj+T+1時鐘周期返回。假設指令i先發出,即:
Si (1) 2條指令發出后,ID隊列的狀態為(IDi,IDj),且2條指令到達數據回收站的時間如式(2)所示: (2) 當指令i到達回收站時,記循環計數器的值如式(3)所示: Cnti=(IDi+delayi)mod(T+1) (3) 以下對指令i不晚于指令j到達(Ei≤Ej)、指令i晚于指令j到達(Ei>Ej)2種情況分別進行討論。 5.3.1Ei≤Ej Ei≤Ej時,對應指令i不晚于指令j到達的情況。對指令i而言,由于ID隊列隊首為IDi,因此指令i的順序滿足。 (1)若delayi=T,由式(3)知此時計數器值為Cnti=(IDi+T)mod(T+1),與IDi恰好匹配,因此指令i將于下一時鐘周期返回。由式(2)知其返回時間為Ei+1=Si+T+1,符合延遲要求,故指令i按序、按時返回。 (2)若delayi [(IDi+T)mod(T+1)- (IDi+delayi)mod(T+1)]mod(T+1)= (T-delayi)mod(T+1)=T-delayi (4) 根據該剩余等待時間及指令i的到達時間Ei即可得到i的返回時間,如式(5)所示: T-delayi+Ei+1= T-delayi+Si+delayi+1= Si+T+1 (5) 可見指令i的返回時間依然符合固定延遲要求。因此,無論delayi取何值,指令i總能按序、按時返回。下面考慮指令j。 (3)若指令j到達時指令i已經返回,此時ID隊列隊首為IDj,指令j的處理過程將與指令i完全一致,故此時指令j也能按序、按時返回。 (4)若指令j到達時指令i仍在等待,由于ID隊列隊首依舊是IDi,故指令j也將進入ID緩存等待,且此時有式(6)成立: Ej=Sj+delayj≤Si+T (6) 式(6)表示指令j到達時指令i最多處于最后一個等待時鐘周期,還未返回。聯立式(1)與式(6),可得式(7): delayj (7) 故指令j與(2)中的指令i相同,其到達后應等待T-delayj個時鐘周期。指令i于Si+T+1返回時,ID隊列隊首變為IDj,指令j才有機會返回,此時指令j已等待的時間如式(8)所示: Si+T+1-Ej= Si+T+1-(Sj+delayj)= T-delayj+(Si-Sj+1)≤ T-delayj (8) 可見指令i返回后,指令j的實際等待時間不超過應等待時間,指令j仍需要在ID緩存等待延遲匹配。將式(8)中的已等待時間計入通路延遲,指令j等價于經過了一條延遲為T+1+Si-Sj的更長通路到達回收站,并且到達時指令i已經返回,由(3)可知指令j能按序、按時返回。 綜合上述4種情況的分析可知,當Ei≤Ej時,任意指令i、j都能按序、按時返回。 Ei>Ej時,對應指令i晚于指令j到達的情況。對指令j而言,由于ID隊列隊首為IDi,因此指令j將進入ID緩存。 待指令i到達時,其處理與Ei Sj+delayj (9) 再由式(1)和式(9)可得式(10): delayj (10) 這說明此時指令j的應等待時間仍為T-delayj,且指令i仍然于第Si+T+1時鐘周期返回,故式(8)仍然成立,其結論也仍然成立,指令j能按序、按時返回。 綜合Ei≤Ej和Ei>Ej的結果可知,基于ID的順序機制可以保證任意2條指令之間的順序與延遲。 5.3.3 靈活性與硬件開銷 在基于ID的順序機制中,最主要的硬件開銷為圖4中的ID緩存。假設數據寬度為B,當具有N條訪存通路、延遲要求為T+2時,ID緩存的大小為B(T+1),與通路條數N無關。 當N增加但T不變時,若直接根據流水線結構,對2N種可能到達情形加以辨別、處理,硬件邏輯將十分復雜,且容易出錯。但是,在順序機制中,計數器與ID位寬、ID緩存大小等均無需改變,硬件只需增加一些處理邏輯即可,具有較好的靈活性。在標量訪存單元中,基于ID的順序機制存儲開銷為87.5 B。 為評估數據一致性的性能提升效果,對標量訪存單元的一致性寫回操作耗時進行了實驗與統計。實驗中,標量訪存單元配置為Cache,片上網絡帶寬設為足夠大(每個時鐘周期都能接收一行),在有效臟行數據量為Cache容量的0%,25%,50%,75%和100%這5種情況下,對逐行掃描寫回和硬件“首1”寫回的耗時分別進行了統計。表2為2種寫回方式耗時的統計結果。圖13是以逐行掃描為基準的歸一化結果。 采用逐行掃描方式寫回整個Cache,其基本時間開銷為1 030個時鐘周期,即便沒有有效臟行,也依然需要消耗大量無效時鐘周期進行檢查。當有效臟行占比為100%時,總耗時為1 037個時鐘周期,多余部分為處理網絡寫響應的開銷。寫回時,網絡返回的寫響應需要得到處理。若實際寫回最后一臟行后,還要進行許多無效檢查,則網絡的寫響應處理隱藏在了無效檢查的時間內。若寫回最后一臟行后不再進行無效檢查,等待并處理網絡寫響應的時間就無法隱藏,將計入總耗時。 Table 2 Time consumption of write back 表2 寫回耗時 Figure 13 Normalized time consumption of write back圖13 歸一化寫回耗時 采用優化后的硬件“首1”寫回,在無有效臟行時,只需8個時鐘周期即可完成判斷并結束寫回。在有效臟行占比為25%,50%和75%這3種情況下,硬件“首1”消耗的時鐘周期數分別為272,528和785,為逐行掃描的26.4%,51.3%和76.2%。寫回整個Cache時,耗時1 041個時鐘周期,比逐行掃描僅多了4個時鐘周期。 與逐行掃描相比,“首1”式寫回需要使用更多的寄存器資源,查找“首1”的硬件邏輯也帶來了更多的資源消耗。一致性寫回操作需要輸入并修改Cache的Valid、Dirty狀態位,由于Cache行數較多,與狀態位相關的處理將使用較多的寄存器。采用流水化的逐行掃描方法時,狀態位與數據緩存帶來的寄存器消耗為4 608 bit,“首1”式寫回則需要5 120 bit,增加了11.1%。“首1”式寫回引入額外的查找“首1”硬件及11%的額外寄存器資源,將一致性寫回操作的耗時改進為只與有效臟行數量成正比,與Cache容量無關。跳過無效行、非臟行,可以避免無效掃描,加速了一致性寫回操作,提高了多核DSP數據一致性的效率。 本文針對超長指令字DSP在訪存實時性、順序與固定延遲、高效數據一致性方面的需求,設計了適用于DSP的標量訪存單元。采用可配置Cache/SRAM的方式以較低開銷滿足訪存實時性;基于ID的順序機制確保超長指令字架構對返回數據的順序與固定延遲要求;硬件查找“首1”的方法加速了Cache一致性寫回操作,實現高效數據一致性。在RTL級實現后,搭建了驗證環境以驗證功能的正確性,分析并證明了基于ID的順序機制的正確性,同時在不同有效臟行占比下測試了優化后數據一致性的性能提升。 標量訪存單元針對Uncache數據支持連續的寫,考慮到多核共享數據時,數據生產者對共享地址幾乎只進行寫,未來的工作可以在Cache管理策略方面展開。通過硬件檢測DSP核對某個地址范圍是否只寫,如果只寫則直接寫到下一級存儲,配合Uncache對連續寫的支持以獲得更好的性能,避免了寫分配、寫替換的時間開銷。5.3.2 Ei>Ej
5.4 數據一致性加速評估


6 結束語
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10公民與法治(2022年5期)2022-07-29 00:47:28教學考試(高考物理)(2021年5期)2021-11-08 10:31:22歷史教學問題(2021年4期)2021-11-05 07:02:34中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14測控技術(2018年5期)2018-12-09 09:04:26電子測試(2018年18期)2018-11-14 02:30:34中國公共安全(2017年11期)2017-02-06 05:28:08電信科學(2016年10期)2016-11-23 05:11:56燕山大學學報(2015年4期)2015-12-25 02:19:49
