一種基于共現關鍵詞的TextRank文摘自動生成算法
2023-11-17 13:21:54閻紅燦李鉑初谷建濤
計算機工程與科學 2023年11期
關鍵詞:文本
閻紅燦,李鉑初,谷建濤
(1.華北理工大學理學院,河北 唐山 063210;2.河北省數據科學與應用重點實驗室,河北 唐山 063000)
1 引言
文摘自動生成[1]是自然語言處理領域中一項重要研究內容。面對如今互聯網上日益增加的信息,文摘自動生成技術從海量的信息中提取有用的部分,可以提高人們獲取信息的效率,節省時間。
文摘自動生成[2]方法分為抽取式和生成式2類,前者是從原始文檔中提取關鍵句子、短語或單詞來組成摘要;后者是根據對原始輸入文本的理解來形成摘要。抽取式文摘自動生成方法生成的摘要通常可以保留原文中的重要信息,且保證了摘要句子語法正確,缺點是可能出現重復信息,且生成的摘要缺乏連貫性。生成式文摘自動生成方法是讓模型嘗試理解文本的內容后輸出摘要,這種方法可能生成原文中沒有的單詞,具有生成高質量摘要的潛力,但需要大量的訓練,并且生成的摘要可能會出現語法錯誤或病句。總體來說,抽取式文摘自動生成方法更適合對較長的文章進行摘要生成,生成式文摘自動生成方法更適合對短文本生成摘要。
常見的抽取式文摘自動生成方法有基于圖的方法、基于特征評分的方法和基于序列標注的方法等。其中,TextRank[3]算法是一種基于圖模型的算法,通過構建拓撲結構圖,以句子間的相似度作為權值進行迭代來對詞句進行排序,并選擇排序靠前的句子作為摘要。本文提出了一種基于共現關鍵詞的TextRank算法,通過word2vec模型、同類文章共現關鍵詞改進了原始TextRank算法向量化表示的問題,基于關鍵詞和句子長度對迭代后的節點進行了權重修正,使用最大邊緣相關算法對摘要句子選擇的不足之處進行了改進。
2 相關工作及研究
2.1 TextRank算法
TextRank算法的思想來源于網頁重要性排序算法PageRank[4]。PageRank算法基于其他網頁到該網頁的鏈接數量進行排序,以頁面之間的鏈接關系來計算每個頁面的重要性。而TextRank算法將每個句子或詞視為PageRank算法中的網頁,并將PageRank中的有向邊變為無向邊,根據詞之間的共現關系生成權重并構造TextRank網絡圖。其簡要步驟如下所示:
(1)將給定的文檔D分割成n個句子S1,S2,…,Sn,每個句子是由單詞組成的集合,之后構造網絡圖G=(V,E),其中,V是文檔的句子集合;E是節點之間的邊的集合,形如(Vi,Vj),代表節點Vi和節點Vj之間有一條邊。用式(1)計算句子之間的相似度作為邊的權值:
Wij=similarity(Si,Sj)=
(1)
(2)加入權值W,形成無向有權網絡圖G′=(V,E,W),迭代計算其中每個節點的累加權重 ,如式(2)所示:
(2)
其中,Wij表示2個節點Vi和Vj之間的權重,即2個句子Si和Sj間的相似度;In(Vi)表示指向節點Vi的邊的集合,Out(Vj)表示從節點Vj出發的邊的集合,其中Vi和Vj分別為待計算節點和待分享節點,故WS(Vi)為待計算節點權重,WS(Vj)為待分享節點權重;d為阻尼系數,表示從某一節點跳轉到任意節點的概率。
(3)用式(2)進行迭代計算來更新每個句子節點的權重直到收斂(即某節點前后2次計算得到的權重值之差小于給定閾值),收斂后停止迭代計算。
(4)將收斂后得到的權重值排序,選取前k個權重值的節點對應的句子作為摘要句,其中k為自定義變量。
在TextRank算法中,每個節點最終得到的累加權重由該節點的自身內容和與該節點連接的其他節點給該節點的傳遞權重共同構成。節點的最終權重值越高,表示該節點的內容越重要、與其他節點的關系越緊密,因此可以認為該節點代表的句子較能體現原文的主題。
國內外研究人員對TextRank算法中文本向量表示、詞頻權重和句子相似度計算等內容進行了深入研究。文獻[5]采用word2vec模型進行文本向量表示,結合詞頻逆句頻和詞向量共同計算句子節點權重,并采用最大邊緣相關MMR(Maximal Marginal Relevance)算法去除摘要中的冗余。文獻[6]采用TextRank算法抽取文章中的關鍵詞,并用BM25(Best Match 25)算法計算句子間相似度。文獻[7]使用自然語言預訓練模型BERT(Bidirectional Encoder Representation from Transformers)進行句向量編碼,根據句子位置、標題、專有名詞和總結詞等特征信息調整詞頻權重,最后將得到的摘要進行去冗余處理。文獻[8]訓練了GloVe(Global Vectors)詞向量并將其應用到傳統的TextRank算法中。文獻[9]用語料訓練word2vec模型并把句子轉化為向量形式,將句子中關鍵詞的覆蓋率和句子與文章標題的相似度加入句子的權值計算中。文獻[10]用句子長度、句子位置、特殊句子、句子與標題相似度以及每句中的主題詞是否在標題出現來調整詞頻權重。文獻[11]將標題、段落、特殊句子、句子位置和長度等信息特征引入到TextRank網絡圖的構造中。Barrios等[12]將句子間相同內容、最長公共字串、余弦相似度、BM25和BM25+等計算句子相似度的方法進行了對比。曹洋[13]對比了編輯距離、WordNet語義詞典和BM25等方法在TextRank算法中的效果。此外還有將TextRank算法與機器學習結合或考慮更多相似文章調整詞頻權重的算法。例如,文獻[7]用Doc2Vec模型進行文本向量化后,采用K-means算法對相似文本進行聚類,根據句子間的位置關系以及單句與標題相似度調整句子權重,最后從每類句子中選出權重最高的句子生成摘要;文獻[15]在計算句子權重時將有相同主張的句子加入權重計算。
國內外研究人員對于TextRank算法的研究有效改進了TextRank算法的幾個缺點:(1)原始的TextRank算法計算2個句子間相似距離時采用比較相同詞語個數的方法,沒有考慮語義信息,可能會使后續的迭代準確率下降;使用word2vec、BERT等模型表示文本有效解決了這一問題。(2)TextRank算法中句子節點的累加權重取決于句子間的相似度而未考慮其它特征;使用句子長度、句子位置、句子與標題相似度、總結詞等特征可以更全面地考慮句子間的關系等要素,降低了高頻詞對結果的影響。(3)TextRank算法提取的摘要中可能包含語義重復或相似的句子,可能導致摘要全面度下降;使用MMR算法可以有效解決該問題。已有的研究對于TextRank算法的句子表示、句子權重和去冗余方面均有改進,但對于數據預處理方面的改進較少,TextRank算法在分詞、停用詞選擇、節點初始權值設置等數據預處理方面仍有改進空間。
2.2 TF-IDF算法
TF-IDF(Term Frequency—Inverse Document Frequency)是一種統計方法,用以評估詞語在語料庫中的重要程度。
詞頻TF計算方法有2種,分別如式(3)和式(4)所示,表示詞在一篇文檔中出現的頻率,出現頻率越高,TF值越大。
(3)
(4)
逆文檔頻率IDF,計算方法如式(5)所示,IDF的值與詞在總的語料庫中出現的頻率成反比,出現頻率越小,說明這個詞的區分度越大,IDF值越大。
(5)
TF-IDF的計算公式如式(6)所示,其在關鍵詞抽取中的主要思想是:某個詞或短語在一篇文檔中出現的頻率高,而在其他文檔中出現的頻率低,則認為該詞或短語具有很好的類別區分能力,可以作為該文檔的關鍵詞。
TF-IDF=TF×IDF
(6)
2.3 最大邊緣相關MMR算法
MMR算法用于計算文本與文檔之間的相似度,其公式如式(7)所示:
(7)
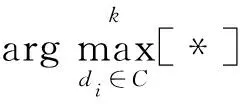
因為文章中可能會在多處用不同的語言表達文章的主要內容,這些句子相似度較高,因此抽取式文摘自動生成方法難免會產生意思重復的句子。 MMR算法多被用于去除摘要句中可能出現的冗余,使摘要的相關性和多樣性相對平衡。
2.4 word2vec模型
word2vec是Google在2013年發布的一個開源詞向量表征工具,可以將詞表征為實數值向量。word2vec采用的模型有連續詞袋CBOW(Continuous Bag Of Words)模型和Skip-Gram 2種。其中,CBOW模型能夠根據輸入周圍n-1個詞來預測這個詞本身,而Skip-gram模型能夠根據詞本身來預測周圍有哪些詞。
word2vec是從大量文本語料中以無監督的方式學習語義知識的一種模型。經過訓練后的word2vec模型可以把文本內容簡化為K維向量空間中的向量,而向量空間上的相似度可以用來表示文本語義上的相似度。因此,某些意思相近卻在傳統模型中毫無聯系的詞通過word2vec模型可以體現出較高的相似度。
3 基于共現關鍵詞的TextRank自動摘要生成算法
由于原始的TextRank算法只從一篇文章中提取摘要,且代表句子的節點的權重取決于該句子與其他句子的相似度,即在文中出現次數較多的詞所在的句子更可能被選中,這導致某些較重要但出現頻率較低的詞所在的句子不被重視,且生成的摘要中會存在重復信息。針對其存在的語義無法充分表達、句中高頻詞對結果影響較大及摘要冗余問題,本文對TextRank算法進行改進,提出一種抽取式自動摘要技術。首先,整理出各類新聞文章常用的專有名詞,在計算句子權重時,將該類文章的共現關鍵詞加入詞頻權重的計算中,同時考慮句子長度和關鍵詞等特征信息;然后,在抽取摘要后用MMR算法去除生成摘要中的冗余信息;同時,為了讓算法獲得更好的句向量表達,本文使用預訓練好的word2vec詞向量模型表示句向量。
3.1 算法流程
本文算法流程如圖1所示。
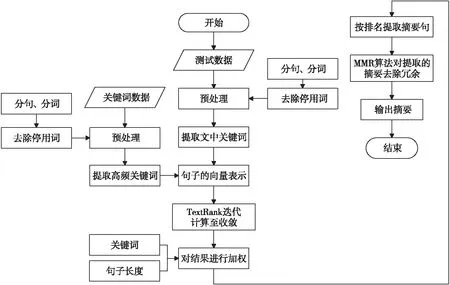
Figure 1 Flow chart of the proposed algorithm圖1 本文所提算法流程圖
具體步驟如下:
(1)對關鍵詞文檔的內容進行預處理。
①將關鍵詞文檔進行分詞,去除停用詞、標點符號以及分詞后長度為1的詞;
②采用TextRank算法對關鍵詞文檔中的每一條文檔提取10個關鍵詞;
③統計每一類關鍵詞文檔中的關鍵詞,依據Gini指數(Gini Impurity)與詞頻相結合的方法選取詞,組成該類文檔的共現關鍵詞詞庫。
(2)對測試文檔內容進行預處理。
①計算文檔中每個詞的TF-IDF值,選出前5個詞(若為停用詞,表中的詞順延)作為關鍵詞。
②將文檔用標點符號分割為句子,生成句子集合,再對集合中的句子進行分詞,去除停用詞、標點以及單字詞。
(3)將關鍵詞文檔與測試文檔的文本轉為詞向量,使文本變為特征向量。
(4)構建測試文檔中每個句子之間的相似度矩陣,在構建過程中加入共現關鍵詞向量。
(5)利用相似度矩陣構建圖結構,每個句子被視作一個節點,用式(8)對矩陣進行迭代計算直到收斂:
keyWS(Vi)=keywords*(1-d)+
(8)
其中,keywords表示當前輸入類文檔的共現關鍵詞得到的詞向量與該文本向量的余弦相似度,阻尼系數d在本文中默認取0.8。
(6)將迭代后的句子權重值進行調整,如式(9)所示:
WS′=WS*keyword*len
(9)
其中,WS表示之前計算出的句子的權值(其大小用于句子排序),keyword表示關鍵詞權重,len表示長度權重。
①keyword計算方法:首先計算每個句子中本文關鍵詞數量和共現關鍵詞數量,那么每個句子的關鍵詞權重=1+(本文關鍵詞數量+共現關鍵詞數量)/(所有句子本文關鍵詞數量和+所有句子共現關鍵詞數量和)。
②len計算方法:將長度大于最長句子長度*0.8且關鍵詞數量少于2的句子權重置為0。將長度小于最長句子長度*0.2且關鍵詞數量少于1的句子權重置為0。
(7)根據句子的權重值WS′選擇排名靠前的s個句子作為備選摘要,其中s取值為5~8。
(8)對s句備選摘要應用MMR算法進行重新排序,MMR算法在計算權重時會減去該句子與其前面句子的相似度。
(9)輸出排名靠前的3句作為最終摘要。
3.2 提取關鍵詞
關鍵詞抽取任務是從一段文本中自動抽出若干有意義的詞語或詞組。本文用TextRank和TF-IDF 2種算法提取文檔中的關鍵詞。Text- Rank算法抽取關鍵詞時采用共現關系構造任2點之間的邊,即:當2個詞語在長度為K的窗口中同時出現時,代表2個詞語的節點之間存在邊,其中K表示每次選擇詞匯時的窗口大小。文獻[16-18]采用TextRank算法進行關鍵詞的提取。文獻[16]考慮了詞句之間的文章結構信息。文獻[17]則考慮了詞頻、詞性和詞語間的語義關系等信息。文獻[18]在關鍵詞提取中加入了粗糙數據推理,分詞去重后對候選關鍵詞按照相似性劃分不同的等價類,將不同等價類中2個存在關聯的詞及其關聯值加入到關聯集合中,根據關聯集合構造關鍵詞圖進行迭代計算。TF-IDF算法的核心思想為:一個詞在一篇文檔中出現的頻率越高,它對文檔的貢獻就越大;一個詞在所有文檔中出現的頻率越高,它對于區分不同文檔的作用就越小。因此,一個詞的重要度隨著它在本篇文檔中出現的次數而增加,同時隨著它在語料庫出現的頻率反比下降。該算法抽取關鍵詞時有時更能抓住文章特有的關鍵詞。故本文采用TextRank算法抽取共現關鍵詞詞庫所需的關鍵詞,用TF-IDF算法抽取每篇測試文檔中的關鍵詞。
3.3 共現關鍵詞詞庫構建
考慮到網站對不同類型的新聞咨詢進行了分類,本文選取每種類型新聞的高頻關鍵詞組成共現關鍵詞詞庫。具體做法為:從同類文檔的每篇文檔中選取關鍵詞,統計每個關鍵詞在該類文檔中的出現頻率,選擇出現頻率較高的詞語作為該類文檔的共現關鍵詞。共現關鍵詞選取步驟如下:
(1)選取超高頻有意義詞:將關鍵詞中出現次數大于該類新聞總篇數/50的非停用詞加入關鍵詞表。
(2)通過計算每個詞在每個類中的Gini指數選取適合的中頻有意義詞:
①選取中頻詞:計算每個詞出現次數/該類新聞總篇數*1000,保留大于1的詞,并將結果記為頻次值count。為便于第②步計算,對count進行四舍五入取整。
②計算Gini值:計算每個類中每個詞的Gini值,如式(10)所示:
gini=1-(currentcount/total)2-
(othercount/total)2
(10)
其中,total表示所有類中該詞總數,currentcount為本類中該詞的頻次值,othercount為其它類中該詞的頻次值。
李偉:我剛才說了,肯定還會和順豐的市場戰略配合著進行。至于具體到什么公司會被收購,我做這樣的預測沒有太大的意義,又不是要買股票(笑)。但我想說,2018年順豐做得很成功,這是順豐一個里程碑的年份,相信明年順豐會做得更好。
③選出共現關鍵詞:選擇每類中Gini值小于0.2,且currentcount大于othercount的詞。
(3)結合(1)與(2)中選出的詞,得到各類的共現關鍵詞詞庫。
3.4 句子長度
考慮到某些過短的句子不包含文章的主要信息,以及某些過長的句子包含的主要信息較少,本文將句子長度系數SL小于0.2且不包含關鍵詞的句子和句子長度系數SL大于0.8且包含關鍵詞個數較少的句子去除。句子長度系數SL的計算如式(11)所示:
(11)
其中,S表示句子的長度,SM表示句子長度中位數。
4 實驗設計與結果分析
4.1 實驗數據
實驗使用到的數據集包括停用詞表、共現關鍵詞數據集和測試數據集。
(1)停用詞表:本文對網上現存的各種停用詞表(哈爾濱工業大學停用詞詞庫、百度停用詞表等)中的中文詞進行整理、去重,與通用符號一起組合成本文所用停用詞表。
(2)共現關鍵詞數據集:本文提取共現關鍵詞的數據集來自于清華大學自然語言處理實驗室推出的中文文本新聞數據集,共有14類總計約80余萬條新聞,從中選取娛樂、財經、體育、房產和教育類文章,從每篇文章中提取10個關鍵詞,累加每個詞出現的次數,依據3.2節的方法選取關鍵詞組成該類文章的共現關鍵詞詞庫。
(3)測試數據集:由于中文文摘自動生成沒有較為通用的評估語料,因此本文測試文本數據集取自上述中文文本新聞數據集,從娛樂、財經、體育、房產和教育5類文章中,找出有標題且不存在小標題的文章,各選取20~30篇句子數超過15的長文本組成測試集。
4.2 評價方法
由于測試數據集沒有參考摘要,無法用文摘生成通用評價指標ROUGE(Recall-Oriented Understudy for Gisting Evaluation)評價摘要質量。本文使用一種標題-有意義詞評價方法,該方法與文獻[19]中采用的評價方法的中心思想類似。由于標題往往代表著文章的中心思想,可以視為全文的簡要總結,因此本文將標題去除停用詞后剩下的詞視為“有意義詞”,并通過式(12)計算摘要效果:
(12)
其中,word表示“有意義詞”個數,word′表示摘要中包含的“有意義詞”個數,kw表示同時也是本文關鍵詞的“有意義詞”個數,kw′表示摘要中包含的kw詞個數。通過對總數據集中抽取200條帶標題的新聞進行預先評估,發現標題往往可被視作最精簡的“摘要”,證明了該評價方法有較強的可靠性。同時,本文抽取acc值較高和較低的一篇摘要人工查看摘要效果。
4.3 實驗設計
4.3.1 基于共現關鍵詞的TextRank算法與其它TextRank算法對比
本節將基于共現關鍵詞的TextRank算法與文獻[9,11,20]中的算法進行對比。綜合各個算法的優缺點,按照以下2個思路進行算法對比:(1)部分算法將關鍵詞覆蓋率、句子與標題相似度等引入到TextRank網絡圖的構造中;將特殊句子、句子位置等信息引入到權值傳遞中。(2)部分算法使用關鍵句子、與標題相似度、線索詞、句子位置和特殊句子等更多要素調整句子權重,并在選擇摘要時去除疑問句。需要說明的是,本文使用標題作為評判依據,并未使用其它文獻中計算每個句子與文章標題相似度這一屬性。
圖2展示了本文所提算法、網絡圖改進算法和句子權重改進算法在6類新聞上的實驗結果對比,可以看出,本文所提算法在大部分新聞類別上均有優勢。

Figure 2 Comparison of the proposed algorithm with other TextRank algorithms圖2 所提算法與其它TextRank算法對比
網絡圖改進算法:構造句子間的網絡圖時,采用式(13)代替原本的句子間相似度計算:
Wij=a×similarity(Si,Sj)+
(13)
其中,P(Sj)表示句子Sj中關鍵詞與總詞數比例,a+b=1。在網絡圖迭代時,文檔中特殊句子(文章前兩句與末句、獨立成段的句子)傳遞權值時權值擴大1.1倍。
句子權重改進算法:得到句子權重排名后,采用式(14)重新計算權重:
NWS=WS*keyword*len*position*cueWords
(14)
其中,position表示句子位置權重,cueWords表示總結詞權重,keyword和len的含義與本文所提算法的相同。
同時,再將本文所提算法與原始TextRank算法進行對比。為比較共現關鍵詞效果,還將本文所提算法分為加入與未加入共現關鍵詞進行對比。本文所提算法從原文中選擇5句作為備選摘要,從備選摘要中選擇3句作為最終摘要;TextRank算法從原文中選擇3句話作為摘要,分別計算其acc值。圖3顯示了3種算法在各類新聞上的acc值。從圖3可以發現,本文所提算法與原始TextRank算法相比,生成的摘要與標題的關聯度提升明顯,加入共現關鍵詞信息后在大多類新聞中的acc值均有所提升。
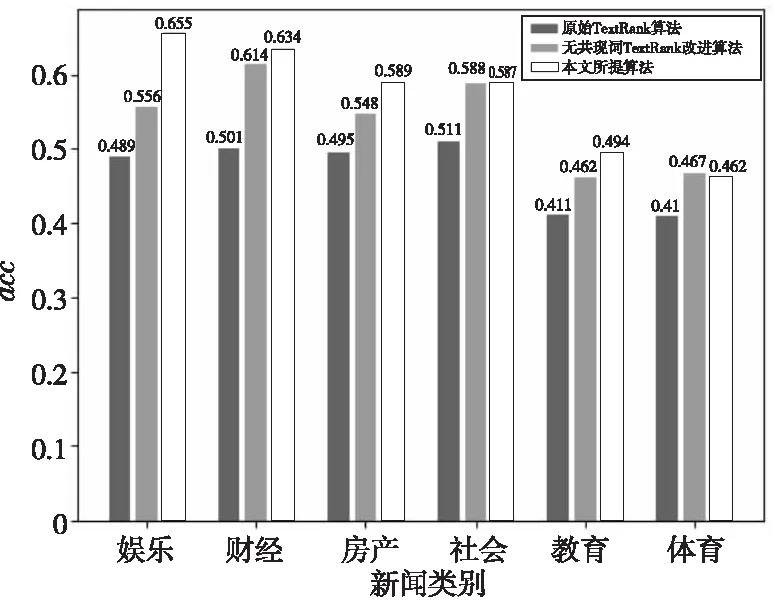
Figure 3 Experimental results comparison between the proposed algorithm and original TextRank algorithm圖3 共現關鍵詞TextRank算法 與原始TextRank算法實驗結果對比
表1和表2分別給出了acc值較高和較低的摘要結果示例。從表1可以看出,評分較高的共現關鍵詞TextRank算法生成的摘要包含了更多的標題內容,涵蓋的信息也更加全面。從表2可以看出,由于原文中大部分內容與標題關聯不大,因此摘要與標題關聯性較低,但與無共現關鍵詞TextRank改進算法及原始TextRank算法相比,本文所提算法生成的摘要表述更加全面,包含的信息也更多。
分析以上實驗結果,體育類新聞中足球與籃球新聞較多,因此共現關鍵詞詞庫中多為足球和籃球相關內容,而本文測試數據集中選擇的文章分類較為平均,因此共現關鍵詞反而影響了其他體育文章的摘要抽取。接下來,暫時排除測試數據中的體育與社會類文章,選取娛樂、財經、房產和教育4類加入共現關鍵詞后效果提升較多的文章,研究阻尼系數d、備選摘要句數量與文中關鍵詞數量對結果的影響。

Table 1 Abstract results with higher acc values表1 選擇acc值較高的摘要結果

Table 2 Abstract results with low acc values表2 選擇acc值較低的摘要結果
4.3.2 不同阻尼系數d與共現關鍵詞的作用對句子權重的影響
本節對比了式(8)中d(共現關鍵詞所占比重)取不同值對本文所提算法性能的影響。如圖4所示,d取0.3,0.6,0.8時,無論d增大還是減小,acc值變化不大,但均高于不計算共現關鍵詞文本時的acc值,表明共現關鍵詞對原始TextRank算法的迭代計算權值起到了優化效果。
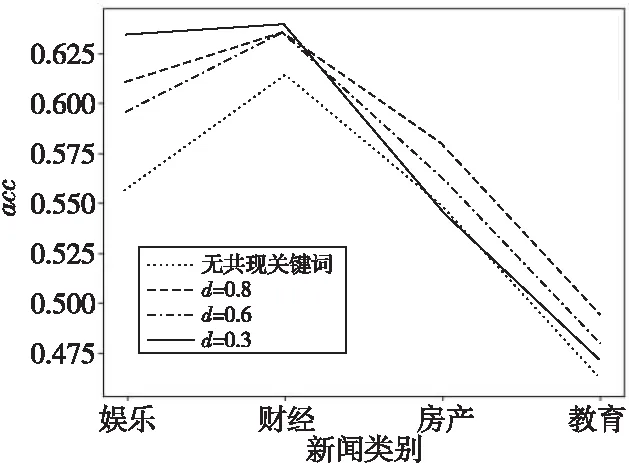
Figure 4 Influences of proportion of co-occurrence words on summary quality圖4 共現詞所占比重對摘要質量影響
4.3.3 MMR算法去除冗余的有效性
本節選擇不同數量的句子作為備選摘要,均通過MMR算法抽取3句生成最終摘要,以測試MMR算法的有效性。從圖5可以看出,備選摘要句越多,生成的最終摘要acc值越高,表明備選摘要句越多,生成的摘要內容越豐富,與標題關聯度越大,實驗結果表明了MMR算法可以有效去除句子中的重復部分,在信息較多時可以保證生成信息的全面性。
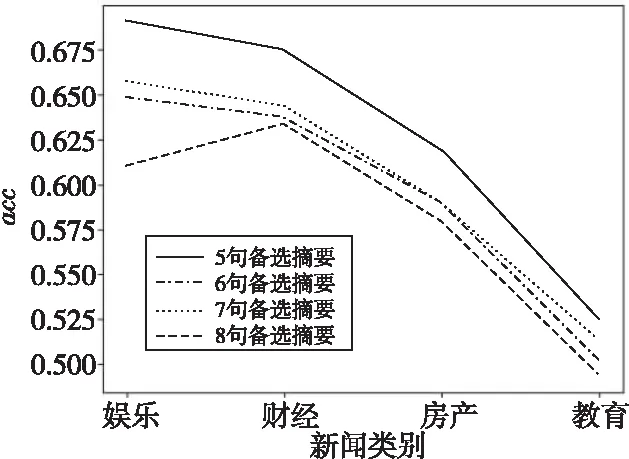
Figure 5 Influence of different number of alternative summaries on summary quality圖5 不同數量備選摘要對摘要質量影響
4.3.4 測試文本中選取不同數量關鍵詞
本文算法用文中的關鍵詞來調整迭代收斂后的句子權重值,通過比較圖6中選取不同數量關鍵詞得到的acc值可知,更多的關鍵詞(即更多的文中信息)可以提高生成摘要的準確性。該結論與常識中包含越多關鍵詞的句子越重要相符。
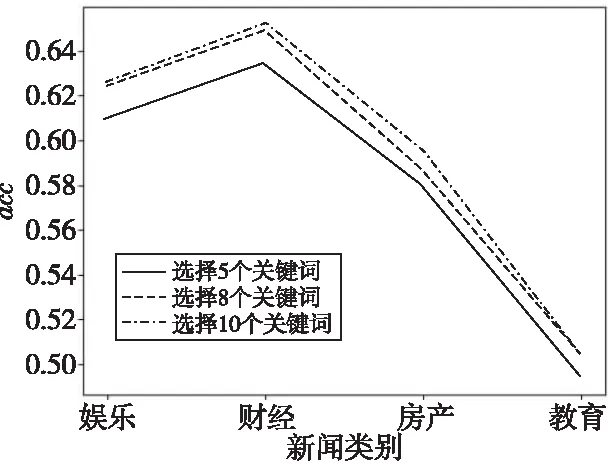
Figure 6 Influence of different number of keywords on summary quality圖6 不同數量關鍵詞對摘要質量影響
實驗數據對比表明,本文所提算法中采用的加入關鍵詞文本計算、根據句中包含的關鍵詞數量調整權重和MMR算法均可以提升摘要質量,證明了本文所提算法的有效性。
4.3.5 測試關鍵詞與句子長度對句子權重的修正效果
為驗證關鍵詞與句子長度對句子權重的修正效果,本節比較是否修正句子權重在各數據集上的輸出結果。由圖7的結果可知,在大多數類別上經過關鍵詞與句子長度的調整后生成的摘要質量有所提升。
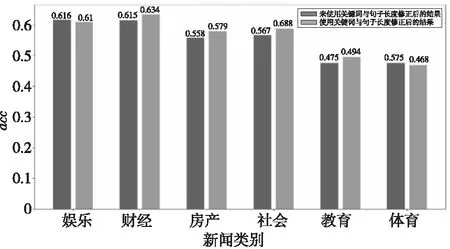
Figure 7 Influence of keywords and sentence length weight on summary quality圖7 關鍵詞與句子長度權重對摘要質量影響
具體比較是否使用關鍵詞和句子長度修正句子權重排序的結果發現,絕大多數修正后的句子權重排序有所變化,如果將排名前5~8句的句子作為整體考慮,約有40%的結果發生變化。人工校對部分結果表明,權重修正起正面效果的占多數,與圖7中的結果相吻合,表明關鍵詞與句子長度對句子的權重能起到修正作用。
5 結束語
本文在綜合對比應用TextRank算法自動生成摘要的過程中,找出其關鍵技術是句子的權重計算,提出了一種將該類文章共現關鍵詞加入計算,同時考慮了文中關鍵詞和句子長度,并加入了最大邊緣相關算法去除冗余的算法。實驗結果表明,生成摘要的全面性和準確性均有所提升,可以較好地反映原文主要內容。但是,本文所提算法依然有抽取式摘要自動生成方法普遍存在的句子之間通順性較差、可能存在重復信息等問題。下一步擬與生成式摘要自動生成方法相結合,將摘要內容進一步縮短且保留其主要信息。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
