基于異構信息網絡的推薦研究綜述
2023-11-17 13:15:28汪春播溫繼文
計算機工程與科學 2023年11期
汪春播,溫繼文
(北京林業大學經濟管理學院,北京 100083)
1 引言
推薦作為大數據時代的一種數據服務方式,有效解決了用戶面臨的信息過載問題[1],因此受到國內外研究人員的廣泛關注,并在電子商務、社交媒體和科研教育等領域扮演著重要角色。推薦系統的概念最早由Resnick等[2]提出,其主要思想是依據用戶的歷史行為或相似性關系來給用戶推薦其可能感興趣的項目。傳統的推薦方法主要有基于內容的推薦方法、基于協同過濾的推薦方法和混合推薦方法3種。基于內容的推薦方法利用推薦對象之間的特征相似度,通常需要進行復雜的對象特征建模和提取,其有效性和可擴展性有限;基于協同過濾的推薦方法則是從用戶的歷史行為偏好中發現規律以進行推薦,但會面臨用戶和物品之間行為關系數據稀疏的問題,以及面對新用戶或推薦新物品時的冷啟動問題;而混合推薦方法是將能夠獲取到的多源輔助信息融合到推薦方法中,雖然能一定程度應對數據稀疏和冷啟動問題,但因為輔助信息的多模態、異構性、規模大、不均勻等特點,混合推薦方法的研究還需要攻克很多難點[3]。
異構信息網絡的提出為推薦系統的進一步優化創造了可能性[4]。異構信息網絡的不同類型的節點和鏈接代表了不同類型的對象和關系,將豐富的語義集成在了一起,通過對異構信息網絡的分析能捕捉更多的重要信息[5],使推薦系統達到更好的效果。相比于傳統的推薦技術,基于異構信息網絡的推薦技術能夠克服數據稀疏問題,能夠較好應對推薦系統的冷啟動問題,且具有可解釋性,充分利用項目之間的語義信息,獲得準確且多樣的推薦結果[6]。
目前,國內外基于異構信息網絡的推薦研究已積累了一定的成果。本文基于文獻調研和文獻題錄信息統計工具SATI(Statistical Analysis Toolkit for Informatics)[7]和社會科學統計軟件包SPSS(Statistical Package for the Social Sciences)Statistics的計量分析結果進行綜述,將當前研究分為算法研究和應用場景2大類。異構信息網絡推薦算法主要有基于聚類、隨機游走、元路徑、矩陣分解和網絡嵌入的算法;應用場景主要有學術科研、興趣點、Web服務和社交好友等。最后提出未來的研究展望。
2 相關概念
2.1 異構信息網絡
當前大多數關于網絡科學、社交和信息網絡的研究,通常假設網絡中的節點都是相同實體類型的對象,其中關系都是相同關聯類型。然而,實際生活中的大多數網絡節點或關系并不是相同類型的,因此稱之為異構信息網絡(Heterogeneous Information Network)。
一個有向圖G=(V,E),有對象類型映射函數φ:V→A和鏈接類型映射函數ψ:E→R,其中,V為對象集,E為邊集,A為對象類型集,R為鏈接類型集。每個對象v∈V具有特定的類型φ(v)且φ(v)∈A,每條邊e∈E具有特定的類型ψ(e)且ψ(e)∈R。假設2個鏈接是相同的類型,則構成鏈接的起始對象和結束對象的類型都必須相同[4]。當信息網絡中的對象類型滿足|A|>1或者關系類型滿足|R|>1時,即為異構信息網絡,否則為同構信息網絡。網絡模式可以描述異構信息網絡中不同類型的對象和鏈接,是網絡G=(V,E)的一個元模板,形為TG=(A,R)。以文獻網絡為例,它包含4種類型的實體:文章(P)、刊物(V)、作者(A)和術語(T),其網絡模式以及該網絡的一個實例如圖1所示。
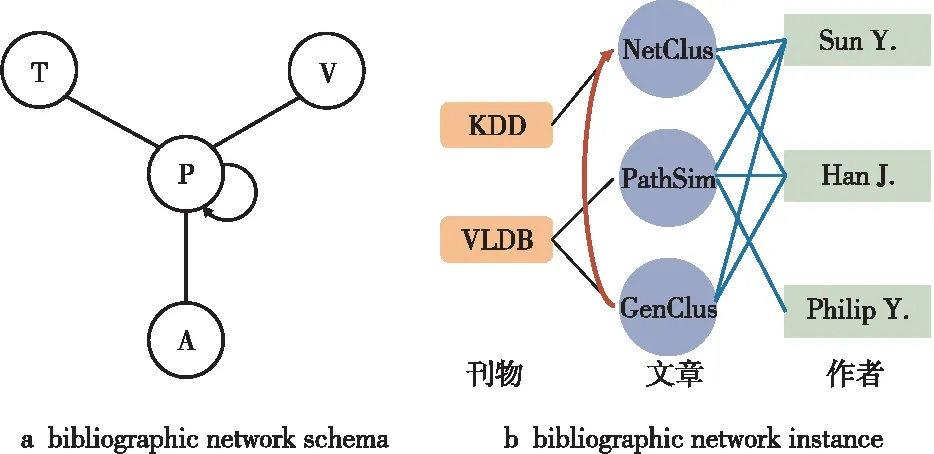
Figure 1 Bibliographic network schema and bibliographic network instance圖1 文獻網絡模式和文獻網絡實例
2.2 基于異構信息網絡的推薦
在常見的推薦場景下,“用戶-項目”的異構信息網絡包含了用戶、項目以及用戶和項目之間的相互連接,因此通過網絡挖掘可以發現用戶和項目之間的深層關系[8],從而彌補了協同過濾推薦中的用戶與項目交互數據稀疏和冷啟動的問題。另外,利用網絡中多個鏈接組成的路徑,可以描述用戶和項目之間的不同語義關系,依據這種語義關系進行推薦使得推薦系統更具可解釋性。由于基于異構信息網絡的推薦系統的獨特優勢,使其逐漸受到學術界和商業領域的重視。
基于異構信息網絡的推薦過程主要有3個環節:(1)網絡建模:依據實際的推薦場景的實體與相互關系確定異構信息網絡模式,將實體映射到網絡中的節點,將關系映射為網絡中的鏈接。(2)網絡分析:決定使用何種算法分析網絡,如實行隨機游走獲得節點排名[9,10]、構造元路徑度量節點之間的相似度[8,11,12]、使用網絡嵌入得到節點的特征表示再計算相似度[13,14]等。(3)生成推薦列表:利用節點的排名或相似度得到Top-K推薦列表,有研究人員結合用戶項目的交互數據實現協同過濾推薦[15-19],或結合用戶興趣和反饋信息實現個性化推薦[20-23]。
3 研究概況分析
本文采用文獻計量和可視化圖譜對基于異構信息網絡的相關文獻進行分析。國內研究選擇CNKI核心期刊和學位論文作為數據源,以“(異構信息網絡+異質信息網絡)*推薦”為檢索項對主題進行檢索;國外研究選擇Web of Science核心合集作為數據源,以“主題:(heterogeneous information network) AND 主題:(recommendation)”為檢索項對主題進行檢索。檢索時間為2021年1月30日,初步收集中文文獻110篇,英文文獻226篇,人工剔除與目標研究主題無關的文獻,最后選取74篇中文文獻和61篇英文文獻作為本文的文獻來源。
在文獻計量分析中,利用SATI進行文獻描述統計、字段抽取、矩陣生成;利用社會網絡分析工具Ucinet和NetDraw繪制關鍵詞網絡知識圖譜;利用SPSS Statistics進行關鍵詞聚類分析。
3.1 文獻數量統計
文獻發表時間的統計結果可以直觀反映出研究領域的熱度變化趨勢。國內外基于異構信息網絡的推薦研究的文獻時間分布如表1所示。從2014年至2020年,研究數量的增長態勢表明這一主題的研究一直在升溫,研究內容也更加深化,技術應用更加廣泛。

Table 1 Annual distribution of literature quantity表1 文獻數量的年度分布
3.2 關鍵詞抽取與頻次統計
關鍵詞是文獻內容的核心體現,能夠很大程度反映研究的重點與熱度。本文依據文獻關鍵詞出現的頻次高低分別列出國內外基于異構信息網絡推薦研究的前30個高頻關鍵詞,如表2和表3所示。本文采用SATI中默認的數據預處理方法,只對標點符號、大小寫、單復數及詞干提取的形變進行處理。

Table 2 High frequency keywords list of domestic research 表2 國內研究高頻關鍵詞列表
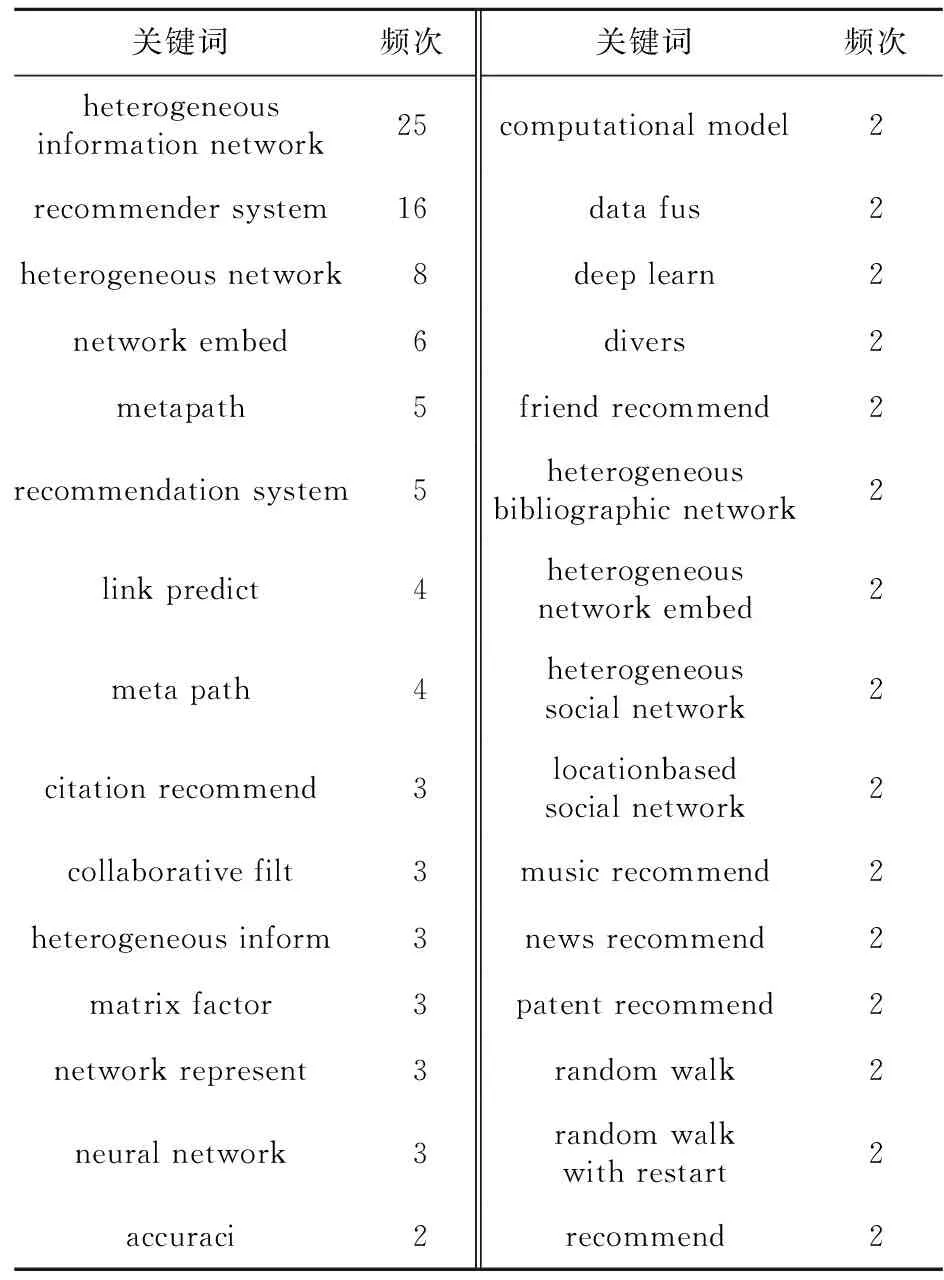
Table 3 High frequency keywords list of foreign research 表3 國外研究高頻關鍵詞列表
3.3 共現網絡知識圖譜
共現關鍵詞可以形成共詞網絡,引入社會網絡分析方法能夠探究領域內研究主題的中心程度。這里使用SATI抽取30個高頻關鍵詞字段,計算得到關鍵詞的等價共現相似矩陣(30×30),將其導入Ucinet和NetDraw中繪制網絡知識圖譜,生成圖譜如圖2所示。網絡中節點代表關鍵詞,節點位置越居中表示關鍵詞越核心,節點大小代表中心度的高低,節點之間連線粗細代表關鍵詞之間的緊密程度。

Figure 2 Co-occurrence network knowledge graph of high frequency keywords圖2 高頻關鍵詞共現網絡知識圖譜
從圖2a可以看出,“元路徑”的位置靠近共現網絡的中心,有很高的中心度,與“異構網絡”和“異質信息網絡”連接緊密,靠近共現網絡中心的還有“矩陣分解”“協同過濾”“深度學習”。從圖2b可以看出,關鍵詞“network embed”“neural network”“citation recommend”較為靠近網絡中心,并與“recommender system”和“heterogeneous information network”有較多聯系。
3.4 聚類分析
聚類分析通過聚類算法將相近的主題聚集形成類團,基于文獻關鍵詞的共現聚類分析能夠識別研究領域的主題結構。利用SPSS Statistics軟件對等價共現相似矩陣進行系統聚類,其中聚類處理方法為組間連接,數據度量標準為計數(卡方度量)。圖3為SPSS Statistics系統聚類得到的使用平均連接(組間)的樹狀圖。
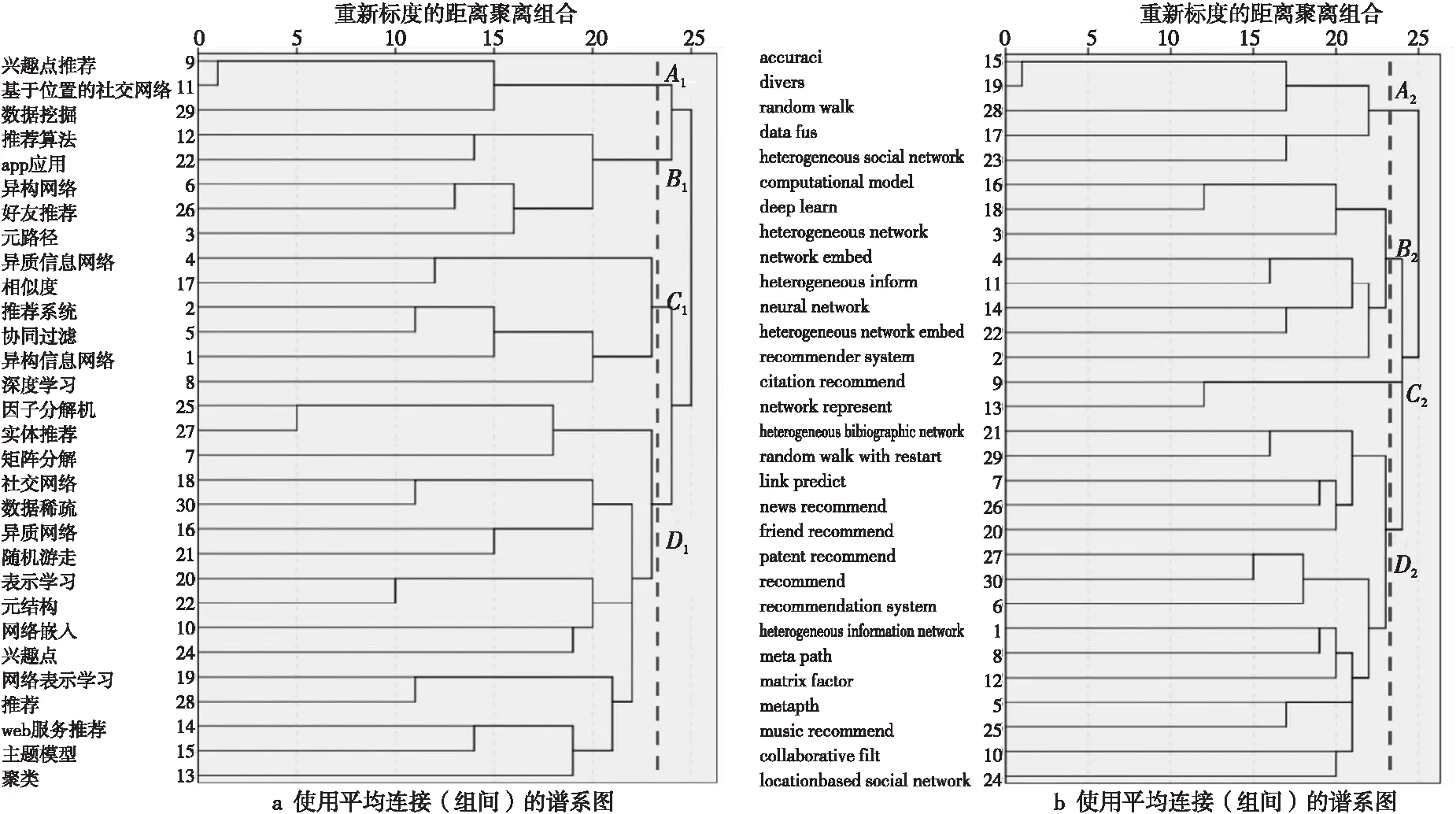
Figure 3 Cluster tree of high frequency keywords圖3 高頻關鍵詞聚類樹狀圖
依據高頻關鍵詞聚類樹狀圖,國內和國外研究的聚類類團分別劃分為A1、B1、C1、D1和A2、B2、C2、D2。依據各個類團的關鍵詞可以將其分為2類,其中類團C1、D1和A2、B2對應的研究主題為基于異構信息網絡推薦的算法研究,包含的關鍵詞有:相似度、協同過濾、深度學習、因子分解機、矩陣分解、數據稀疏、隨機游走、表示學習、元結構、網絡嵌入、網絡表示學習、主題模型、聚類、random walk、data fus、deep learn、network embed、neural network和heterogeneous network embed等;類團A1、B1和C2、D2對應的研究主題為基于異構信息網絡推薦的應用研究,包含的關鍵字有:興趣點推薦、基于位置的社交網絡、app應用、好友推薦、citation recommend、heterogeneous bibliographic network、news recommend、friend recommend、patent recommend、music recommend和locationbased social network等。
4 基于異構信息網絡的推薦算法研究
基于異構信息網絡推薦的算法研究的關鍵技術包括網絡聚類、在網絡中實行隨機游走、基于元路徑度量節點相似度、矩陣分解,以及網絡嵌入算法等。
4.1 基于聚類的推薦算法
Sun等[24]提出的異構信息網絡聚類算法RankClus能夠在雙類型信息網絡中實現聚類,通過排序和聚類的迭代實現排序和聚類質量的共同提升。NetClus算法[25]則拓展實現了對包含3種及以上類型對象的網絡的聚類。
RankClus和NetClus的提出為異構信息網絡的推薦提供了新的思路,即采用迭代的排序和聚類算法來得到推薦候選列表,如有研究人員依據NetClus算法實現了商品推薦[26]和藥物推薦[27]。類似地,趙煥[28]改進NetClus后提出了MAO-NetClus算法,以應對多個同類型節點連接單個目標節點的情況,并將聚類結果結合協同過濾實現Web服務推薦。
在異構信息網絡中實施聚類分析,覆蓋網絡范圍更廣,具有一定全局性,可以結合協同過濾進行推薦,同時聚類算法還需要解決大規模數據的耗時問題,另外排序函數的質量對推薦效果也至關重要,針對不同領域問題算法需重新考慮排名函數的規則。
4.2 基于隨機游走的推薦算法
隨機游走是從指定節點開始,以某一概率隨機向相鄰節點游走,持續這種游走行為就會達到一個穩定的狀態,可以依據穩定狀態下節點被到達的次數進行節點排名。ROUND算法[9]在異構信息網絡中實行重啟隨機游走來表征對象節點和用戶節點之間的關聯強度,在“對象-用戶”的雙類型信息網絡中實現個性化推薦,其中面臨的不可靠鏈接使用k近鄰策略來剔除。Trinity[10]在此基礎上拓展到包含3種類型的“對象-用戶-標簽”網絡。另外Zhou等[29]設定重要度量來加權網絡中的鏈接,從而決定隨機游走的重啟概率。
基于異構時空圖的重啟隨機游走RWR-HST(Random Walk with Restart on Heterogeneous Spatio-Temporal)算法[30],可以充分捕獲“用戶-用戶”相似性和“用戶-位置”相關性。趙海燕等[31]提出的時間和位置感知的個性化活動推薦TLAR(Time and Location-aware Activity Recommendation)算法,能夠在包含用戶、地點、時間、活動、朋友關系的異構信息網絡中利用隨機游走算法進行推薦,相較于流行活動推薦和基于社會關系的活動推薦優勢明顯。
隨機游走的過程可以探索對象之間的潛在鏈接,度量較遠對象的關聯程度,且適用于大多數異構網絡模型,但基于隨機游走算法的缺點在于計算復雜度較高,且冷啟動問題依然存在。
4.3 基于元路徑的推薦算法

元路徑描述了節點之間的關聯性,不同的元路徑包含節點間不同的語義關系,通過元路徑查找相似節點為異構信息網絡的推薦打開了新的突破口。Shi等[32]引入了加權異構信息網絡和加權元路徑的概念,設計了基于語義路徑的個性化推薦SemRec(Semantic path based personalized Recommendation)算法,不僅能靈活地集成異構信息,還可以學習路徑上用戶偏好的優先權和個性化權重。有研究人員將注意力機制引入基于元路徑的推薦算法中,使得重要的元路徑語義更加突出,為推薦模型帶來更好的可解釋性[33-35]。人工選擇元路徑時,常存在路徑權重優化的過度擬合問題,Liu等[36]提出通過權重優化來自動選擇和組合元路徑,提高了元路徑語義的多樣性和推薦的性能,此外三重注意力神經網絡TANN(Tri-Attention Neural Network)推薦算法[37]還可以通過螺栓遺傳算法自動選擇元路徑。
基于元路徑的推薦算法通過選擇或加權、組合不同的元路徑來為不同的應用模型實現語義推薦,靈活度高,是近年基于異構信息網絡的推薦研究工作的重要基礎。但是,基于元路徑的算法依賴于節點間路徑的可達性,在路徑稀疏或混亂的網絡中的推薦結果可能并不理想。
4.4 基于矩陣分解的推薦算法
矩陣分解技術采用低維特征向量來表示用戶對項目的偏好程度以及用戶和項目擁有的屬性特征,基于異構信息網絡分析的“用戶-用戶”相似矩陣與“用戶-項目”評分矩陣結合后得到一個擬合評分矩陣,從而預測用戶對項目的評分。如張邦佐等[38]和王根生等[39]分別利用HeteSim和 PathSim計算用戶間的相似度矩陣,再與評分矩陣融合進行矩陣分解,實現協同過濾推薦。Shi等[40]提出基于矩陣分解的雙重正則化框架SimMF,通過采用用戶和物品的相似性作為對用戶和物品潛在因子的正則化,從而靈活地集成不同類型的信息。基于注意力的正則化矩陣分解ARMF(Attention-based Regularized Matrix Factorization)[41]以雙線性方式將注意力機制引入到矩陣分解中構建推薦模型。不同用戶評分的物品數量不同,因而用戶之間的相似關系是非對稱的。趙傳等[42]提出在均方差相似度公式的基礎上使用非對稱系數,結合加權元路徑衡量用戶的非對稱相似度。
雖然矩陣分解算法需要提升計算海量數據的效率,但矩陣分解和異構信息網絡分析相結合的方法很好地解決了傳統協同過濾推薦的數據稀疏和冷啟動問題。
4.5 基于網絡嵌入的推薦算法
隨著網絡規模擴張,網絡中每個節點與很少的節點關聯,傳統網絡表示方法的特征向量將是超高維且稀疏的。網絡嵌入的目的在于將網絡中的每個節點映射為低維空間上的特征向量,并保留了網絡的結構信息,通過網絡嵌入還可以繼續進行網絡的節點重要性、社區發現和鏈接預測等研究工作。同構信息網絡的嵌入研究較早,代表性的算法有DeepWalk[43]、大規模信息網絡嵌入LINE(Large-scale Information Network Embedding)算法[44]和node2vec[45]等。metapath2vec[46]和HIN2Vec[47]最早實現了異構信息網絡的嵌入。網絡嵌入技術的引入,可以更好地提取異構信息網絡中節點的特征。
利用網絡嵌入來生成異構信息網絡的潛在特征表示,將潛在特征表示向量結合評分預測算法或相似性度量算法,從而得到推薦列表。Shi等[13]提出的推薦算法從異構信息網絡中依據幾組對稱元路徑抽取相同類型的節點,形成幾個同構信息網絡,對其使用DeepWalk得到對象的潛在特征,再將幾組不同的潛在特征集成到矩陣分解中,實現評分推薦。異構網絡嵌入推薦HetNERec(Heterogeneous Network Embedding-based Recommendation)算法[14]提取多個用戶和物品的共現關系來構造共現網絡,通過將多個異構網絡嵌入的特征表示集成到單個特征表示的方法提高推薦性能。鄭誠等[48]采用異構Skip-Gram模型,并引入神經網絡算法替代矩陣分解處理加權融合后的特征向量實現評分預測。Xie等[49]的注意力元圖嵌入推薦AMERec(Attentive Meta-graph Embedding Recommendation)算法,利用注意力機制學習每個元圖的權重,然后通過用戶和項目基于元圖的上下文的低維和多維交互信息來預測評分,增加了推薦算法模型的可解釋性。
基于網絡嵌入的推薦算法有效克服了網絡的稀疏性問題,可用于復雜網絡,捕獲更豐富的語義,并能集成多種輔助信息,是基于異構信息網絡推薦研究的熱點。基于異構信息網絡的推薦算法研究總結如表4所示。另外,深度學習的發展促進了有用數據潛在特征表示的自動學習,可以降低異構信息網絡中復雜任務的計算成本,已有不少研究人員將深度學習應用到推薦算法中。龍方正[50]以自動編碼機作為基礎提出嵌入圖AAGE(Autoencoder based Attributed Graph Embedding)算法,設計了基于嵌入網絡推理的ENBI(Embedding Network-Based Inference)算法并應用在二部圖的推薦任務中;呂振[18]實現了將貝葉斯深度學習和節點特征學習方法相結合來進行推薦;溫玉嬌[51]提出的基于神經網絡模型的協同過濾推薦HINCF(Collaborative Filtering based onHeterogeneous Information Network)框架,可以在面對新用戶時發揮較好效果;陳星合[17]提出了基于信任網絡的深度矩陣分解算法和基于路徑的深度協同過濾推薦算法,前者能對用戶間的信任關系進行預測,后者結合用戶和物品的特征向量及其上下文信息的特征向量使用全連接層進行評分預測。
5 基于異構信息網絡的推薦應用場景
基于異構信息網絡推薦的應用研究,主要是在特定場景中圍繞具體推薦對象,解決實際推薦問題。表5展示了異構信息網絡推薦的應用場景、相關研究數量、代表研究及其關鍵技術。
5.1 學術科研
隨著學術科研的發展,引文推薦和科研合作推薦逐漸受到了學界的關注。異構文獻網絡主要包含文獻、研究人員、刊物、主題和所屬機構等實體,主要的關系有研究人員與文獻之間的著作關系、文獻與文獻之間的引用關系、文獻與刊物之間的刊登關系、文獻與主題之間的包含關系,以及研究人員和所屬機構的隸屬關系等。
(1)引文推薦。
日益增長的科學文獻數量帶來了很大的檢索困難,研究人員需要快速準確地找到相關參考文獻。當前的文獻推薦的工作常會將異構文獻網絡和很多輔助信息結合,如利用文獻的內容信息和研究人員的描述信息[63]以及用戶的隱式反饋[64]等,基于異構網絡嵌入的文獻推薦PR-HNE(Paper Recommendation based on Heterogeneous Network Embedding)模型[54]還從多個信息網絡中捕捉研究人員和論文的動態。在引文推薦中,新文獻由于沒有被引記錄和瀏覽記錄等歷史信息,以往算法對其推薦的效果并不理想,文獻[53]通過合并元路徑的方法針對性地解決了新文獻推薦的冷啟動問題。當2篇文獻之間沒有可達路徑時,基于元路徑的算法無法度量其相似性,而基于引文傾向的推薦算法可以解決這一問題[52],且其性能也要優于前者[65]。

Table 4 Key technologies and typical algorithms of recommendation based on heterogeneous information network表4 基于異構信息網絡推薦的關鍵技術和典型算法

Table 5 Application scenarios and representative researches of recommendation based on heterogeneous information network表5 基于異構信息網絡推薦的應用場景和代表研究
(2)合作推薦。
當前,科研合作的最常見形式是基于文獻的研究人員合作[66],也就是基于異構文獻網絡進行科研合作推薦。根據合作目的的不同,科研合作推薦可以分為2種:一種是推薦其研究方向相似的研究人員,以幫助其在該領域實現高水平研究成果,常見思路是在網絡中度量研究人員之間的相似度,試圖推薦相似的研究人員,如利用重啟隨機游走算法[29]、融合多種元路徑[67]和采用網絡表示學習[55]等技術;另一種是出于促進多學科交叉融合的目的,組建來自不同領域擁有不同技能的科研團隊,如團隊形成算法SkillsFirst[68]將異構信息網絡轉化為一個完全圖,依據項目工作要求的技能來構建最小生成樹去選擇成員組成團隊。除了基于文獻的研究人員合作,Xu等[69]立足在線學術社區,進行“學術朋友”的推薦以促進科研合作。
在學術科研領域的推薦研究中,常使用的數據集有計算機科學文獻庫DBLP(Digital Bibliography &Library Project)和計算語言學協會年會文集網絡AAN(ACL Anthology Network)。DBLP由計算機科學和相關領域的文獻數據組成,目前涵蓋超過500萬篇文獻;AAN規模較小,包含計算語言學和自然語言處理相關的23 766篇文獻。
5.2 興趣點
基于LBSN(Location-Based Social Network)的個性化興趣點推薦是近幾年的研究熱點。興趣點是指現實生活中的地點,通過興趣點的推薦,不僅幫助用戶快速了解周圍環境,而且為服務提供者招攬更多客戶。用戶和興趣點是LBSN中最主要的2類實體,用戶在興趣點簽到,同時用戶之間存在好友關系,興趣點之間有相關關系。由于每位用戶訪問的興趣點數量有限,使得簽到數據非常稀疏,有研究人員使用加權異構網絡模型[70]、二分網絡嵌入算法[56]以及將社交關系、用戶互動以及用戶評論納入推薦考慮[71],以解決數據稀疏性的問題。由于用戶興趣是動態變化的,需要將時間因素引入到推薦模型中,康來松等[72]提出使用加權元路徑對地理位置、社交關系和時間周期進行建模;李全等[73]將時間信息融入到用戶和興趣點的語義關系中,進而實現動態的興趣點推薦。興趣點推薦研究中使用的數據集一般來自于基于位置的社交平臺,用戶在平臺中向好友分享簽到信息以及位置信息,常見的數據集有Gowalla、Foursquare、Weeplaces和Brightkite等,它們主要記錄了用戶在某一地區的興趣點的簽到數據。
5.3 Web服務
Web服務是應用程序開發的基本元素,是一個開放性、跨平臺、低耦合和可重復使用的軟件功能。隨著Web服務數量的快速增長、類型的不斷變化以及請求者需求的個性化,服務的推薦對基于服務的系統開發至關重要[57]。基于異構信息網絡的Web服務推薦模型通常包括服務、用戶、服務提供商和服務類型等多種實體。由于服務資源數量巨大且語義稀疏,有研究人員使用聚類技術來進行服務推薦[28,74]。用戶興趣也是Web服務推薦的關鍵點,Xie等[75]利用群組偏好來實現個性化推薦。一些公開的Web服務平臺如PWeb和Mashape(已更名為 Kong Inc.)為Web服務推薦研究提供了數據基礎,另外有研究使用香港中文大學開發的WS-Dream數據集,其可用于Web服務的可靠性評估和其他相關研究。
5.4 社交好友
好友推薦是社交網絡平臺中的重點研究內容。在當前的好友推薦研究中,主要有3個出發點:友情、興趣和位置。基于友情的好友推薦主要考慮好友關系和社交相似度等;基于興趣的好友推薦主要依據用戶間的興趣相似度;基于位置的好友推薦則考慮用戶訪問地點的相似性。楊家紅等[76]考慮了用戶之間的好友關系、用戶與簽到點的簽到關系和簽到點之間的相關關系來進行好友推薦;Kefalas等[30]構建了包括用戶、位置和會話的三元異構時空社交網絡,設計了一種基于時間維度的新穎推薦算法以捕捉用戶隨時間變化的偏好;朱文強等[59]提出的用戶本地信任網絡模型ULTNM(User Local Trust Network Model)融合了用戶社交圈相似度和興趣偏好相似度等特征。當前的社交好友推薦研究使用的公共數據集主要來自于消費者點評網站如Yelp和Epinions,以及社交平臺如Gowalla和Foursquare等,這些數據集記錄了用戶的興趣、評分以及好友關系等信息。
5.5 專利交易
專利推薦一定程度上解決了專利交易中的信息不對稱問題,實現了供需雙方的精確匹配,成為促進專利交易的重要手段。當前研究主要利用專利技術交易信息中的專利技術、專利主體和專利購買方等實體,以及技術領域、專利引文等屬性來構建異構專利網絡。Wang等[77]依次采用了元路徑語義的推薦來滿足專利購買方的不同動機;何喜軍等[60]從專利主體之間的有效對接出發,以專利主體為對象進行推薦,并通過實證研究證明考慮主體間技術鄰近、經濟圈鄰近、主體間從屬關系、共申請關系以及印證關系可以使推薦結果精度更高。如何區分相同詞在不同上下文中的意思,以及將表示相同意思的不同詞聯系起來,是專利推薦面臨的一大困難。Chen等[61]利用專利主題詞結構學習和詞嵌入解決了這個問題。專利交易推薦研究大多使用科技創新情報平臺IncoPat和美國專利商標局USPTO(United States Patent and Trademark Office)公開的數據集。
5.6 新聞
新聞推薦的特殊性在于2點:一是新聞的更新頻繁使得用戶與其交互數據稀疏,二是不僅要考慮用戶的長期興趣還要捕捉用戶對新聞熱點的短期興趣。Hu等[62]提出使用用戶、新聞和主題之間的交互行為來構建網絡,將新聞主題與用戶興趣結合以減輕用戶和新聞交互數據稀疏性的影響,并利用用戶點擊和閱讀歷史來確定用戶的長期興趣和短期興趣。Symeonidis等[78]則構建了一個由用戶、新聞、新聞類別、地點和會話組成的動態異構網絡,從中捕捉用戶會話所隱藏的短期興趣。新聞推薦研究的實驗數據基本來自于新聞平臺,如Adressa數據集,由挪威科技大學和當地報紙Adressavisen合作發布。
6 結束語
由于異構信息網絡蘊含了不同類型節點和關系的復雜語義,使其在推薦系統中的應用逐漸受到學界和商業領域的重視。當前異構信息網絡的推薦主要基于聚類、隨機游走、元路徑、矩陣分解和網絡嵌入的算法,一定程度克服了傳統推薦算法的冷啟動、數據稀疏以及可解釋性的問題,另外在學術科研、興趣點、Web服務和社交好友等推薦場景實現了廣泛的應用,但在不同場景面臨著不同難點。目前異構信息網絡的推薦研究并未完全成熟,還有較大發展空間,未來的研究重點主要有3個方面:
(1)動態異構信息網絡的推薦系統。
當前的異構信息網絡推薦研究大多是立足靜態的數據,在訓練和測試推薦系統時也是使用提前獲取的歷史數據,這并不能滿足實時變化的推薦需求,如興趣點推薦、新聞推薦、商品推薦等場景的對象更新頻繁,對推薦的實時性有較高要求。另外不斷生成的用戶反饋數據也值得利用。結合用戶偏好和項目特征的動態變化構建動態異構信息網絡,并利用實時的反饋數據及時優化推薦結果將是未來的研究趨勢之一。
(2)融合深度網絡表示學習。
在異構信息網絡中使用網絡表示學習算法來完成推薦的方法已被很多研究人員采用,但目前研究中的網絡表示學習算法主要是以DeepWalk、Skip-Gram和matapath2vec等淺層模型為基礎[79],而隨著數據量不斷擴增,網絡中將會有更多數量且更多種類的節點和關系,網絡規模不斷擴大,網絡結構也更加復雜,數據稀疏問題更加突出,在這種情況下引入深度神經網絡來進行網絡表示學習將給推薦系統帶來更好的性能。
(3)拓寬應用場景。
異構信息網絡推薦在學術科研、社交好友和Web服務場景有較多的應用,但是目前在電商平臺、生物科學和社會標簽等常見推薦場景的研究成果不多。不同推薦場景具有不同難點,未來需要突破不同場景下構建網絡的特殊性和計算復雜性,拓展異構信息網絡推薦的更多應用。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
