差分變異和領地搜索的平衡優化算法及其機器人路徑規劃
2023-11-17 13:15:30閔華松張新明
計算機工程與科學 2023年11期
張 貝,閔華松,張新明
(1.武漢科技大學機器人與智能系統研究院,湖北 武漢 430081;2.河南師范大學計算機與信息工程學院,河南 新鄉 453007)
1 引言
優化問題在現實生活中無處不在,如二次指派問題[1]和機器人路徑規劃[2]等都是典型的優化問題。
一般說來,優化問題可以分為線性、非線性、連續、離散、單目標、多目標、有約束和無約束等優化問題[3]。而解決好無約束單目標問題是解決所有其它優化問題的基礎[4],故本文主要討論此類優化問題。
解決優化問題的方法稱為優化方法。優化方法一般分為確定性方法和隨機性方法。傳統的確定性方法不能很好地解決全局優化問題,且還需要優化問題的大量信息[4]。因此,隨機性優化方法引起了人們廣泛的關注。元啟發式算法MA(Meta- heuristic Algorithm)屬于隨機性優化方法范疇。MA由于其簡單性、靈活性和無需太多優化問題的信息等優點,在許多領域得到廣泛的應用。因此,研究人員提出了許多MA,如差分進化算法[4]、粒子群優化PSO(Particle Swarm Optimization)算法[5]、人工蜂鳥算法AHA(Artificial Hummingbird Algorithm)[6]和堆優化算法HBO(Heap-Based Optimizer)[7]等。隨著社會的快速發展,需要解決的優化問題越來越多,且越來越復雜和多樣化。另外,根據無免費午餐定理[8],一個算法在一類優化問題上可能有杰出的表現,但在另一類優化問題上可能表現不佳,沒有一種MA可以解決所有的優化問題。因此,新的和改進的MA不斷被提出。
平衡優化算法EO(Equilibrium Optimizer)是由Faramarzi等人[9]在2020年提出的一種新型的MA,受啟發于受控容器中液體的動態質量守恒模型,即在受控容器中進入、離開和產生的液體質量總和保持不變。在EO中,每種液體成分類似PSO中的粒子充當搜索個體,而這些成分的濃度類似PSO中的粒子位置。每個粒子通過5個精英粒子的引導來更新其濃度,最終達到平衡狀態(最優結果)。與現有的MA相比,EO具有獨特的搜索機制,在解決經典的優化問題時優勢明顯[9]。然而,EO提出的時間較短,還有許多地方值得深入研究。因此,國內外一些研究人員提出了一些EO的改進算法,擴展了其應用范圍。例如,Gupta等人[10]提出了一種具有突變策略的EO,使種群保持足夠的多樣性,增強了EO的全局搜索能力;Wunnava等人[11]將一種自適應EO——AEO(Adaptive EO)應用于多閾值圖像分割,擴展了EO的應用范圍;Fan等人[12]基于反向學習策略和新穎的更新規則提出了一種改進的EO,該算法在最優解為零向量的問題上非常有效;羅仕杭等人[13]提出了一種多策略的EO——MEO(Multi-strategy EO),在經典的優化問題上獲得更好的性能;Zhang等人[14]提出了一種強化信息使用的EO——ISEO(Information utilization Strengthened EO),提升了EO的搜索能力。雖然這些EO的改進算法在不同程度上改善了EO的優化性能或擴展了其應用范圍。然而,它們仍存在搜索能力不足等缺陷。此外,它們大多都是在經典函數上驗證其有效性,幾乎沒有關于在CEC(Congress on Ewlntionary Computation)復雜優化問題的測試集上測試EO改進版本的研究,而且目前也無EO在機器人路徑規劃上應用的研究。綜上所述,對EO的研究非常必要且有較大實際意義。
針對EO在解決復雜優化問題時存在搜索能力不足和搜索效率低等問題,本文提出了一種改進的EO,即差分變異和領地搜索的EO——DTEO(Differential mutation and Territorial search EO)。
2 平衡優化算法
EO中粒子的濃度更新方式是依據質量守恒定律所構建的一階常微分方程推導而成[9],如式(1)所示:
(1)
其中,Xi為第i個粒子更新后的濃度;Ci為其已有的濃度,i∈[1,N],N為種群規模;Ce是從精英池(Cpool)中隨機選取的精英粒子的濃度;F為縮放因子向量;G為生成速度;λ為周轉速率;V表示容器的體積,常取值為1個體積單位;?表示2個向量中的對應分量相乘。這些符號詳述如下:
精英池(Cpool)由5個精英粒子的濃度組成,如式(2)所示:
Cpool={Cα,Cβ,Cδ,Cγ,Cφ}
(2)
其中,Cα、Cβ、Cδ和Cγ分別為當前種群中最優、次優、第3優和第4優粒子的濃度,最后一個精英的濃度Cφ通過式(3)計算獲得:
Cφ=(Cα+Cβ+Cδ+Cγ)/4
(3)
縮放因子向量F的計算如式(4)和式(5)所示:
F=a1×sign(r-0.5)?[e-z×λ-1]
(4)
z=(1-t/T)(a2×t/T)
(5)
其中,a1和a2為調整參數;sign(·)是符號函數;r與λ都是D維隨機向量,其每個分量是均勻分布在[0,1]的隨機數;t為當前迭代次數;T為最大迭代次數。
生成速度G的表達式如式(6)~式(8)所示:
G=G0?F
(6)
G0=RG×(Ce-λ?Ci)
(7)
(8)
其中,RG為生成速度的控制參數,由參數生成概率PG決定;r1和r2為均勻分布在[0,1]的隨機數。
從式(6)~式(8)可以看出,當r2小于PG時,G為零向量,故式(1)可以改寫為式(9):
(9)
根據式(1)~式(8)可知,式(1)右側的第1項是隨機選擇精英粒子的濃度,第2項和第3項包含了這個精英粒子和第i個粒子濃度之間的差值。EO的偽代碼如算法1所示。
算法1EO算法
輸入:參數V,a1,a2和PG等的值。
輸出:最優解Cα。
1.隨機初始化種群中每個粒子的濃度;
2.計算粒子適應度值,確定Cα、Cβ、Cδ、Cγ和Cφ,構建精英池;
3.FORt=1 TOTDO
4.FORi=1 TONDO
5. 依據式(9)更新粒子的濃度,并對更新后的濃度進行邊界控制;
6.ENDFOR
7.FORi=1 TONDO
8. 計算粒子的適應度值,用貪婪算法選擇更新種群和更新精英池;
9.ENDFOR
10.ENDFOR
根據以上描述可知,EO具有以下優點:(1) 具有獨特的新解產生機制,如式(1)所示。(2) 具有一定的信息引導能力。從式(1)可以看出,在一定程度上精英粒子的信息可以引導其他粒子搜索。(3) 有較強的局部搜索能力。式(1)右側的3項都包含精英粒子的濃度,這表明精英粒子會引導種群朝著良好的方向搜索。(4) 具有一定的全局搜索能力。其一,在演化早期階段,F的各分量值較大且精英粒子與其他粒子之間的差異也較大,這有助于擴大搜索范圍;其二,更新方程包含的一些隨機因素也增強了種群多樣性和有利于全局搜索。(5) 具有較強的靈活性和通用性,較多的可調參數可以調整算法使其適應多種優化問題。
3 改進的平衡優化算法
EO雖然在經典函數上有較好的優化性能,但在解決復雜的優化問題時仍然存在一些不足:(1) 在EO中僅使用5個精英粒子與其他粒子共享信息,這種信息共享方式不僅單一,而且共享程度較低,導致搜索能力不足;(2) 濃度更新方程的計算復雜度高,同時搜索能力不足使得EO的搜索效率較低;(3) EO有較多參數需要調整,導致EO的可操作性較差。因此,針對EO在解決復雜優化問題時存在的缺點,本文提出了4種改進策略:(1)融合領地搜索的隨機差分變異策略,提升最優個體;(2)信息共享的隨機差分變異策略,提高算法的搜索能力;(3)簡化EO更新方程策略,提高算法的可操作性,降低計算復雜度;(4)精英與最差個體的差分變異策略,強化最差個體。
3.1 融合領地搜索的隨機差分變異策略
在EO中,所有粒子濃度的更新都是由精英粒子引導的,最優個體屬于精英群中一員,發揮著重要的作用。若最優個體位于局部最優點,可能會使EO陷入局部最優。所以若能強化最優個體,則通過式(9)中的精英信息引導能夠提升其它個體的搜索能力,故本文采用一種新型差分變異策略來更新最優個體的濃度,以提升最優個體。差分變異策略就是將2個解的差分向量經過縮放加到第3個解向量上,對其每維的值進行變異,從而得到一個新解。差分變異有多種形式,被廣泛應用于MA中[4]。本節僅討論將2個隨機選擇粒子的濃度差分向量縮放后加到當前粒子的濃度上,產生新濃度,表達式如式(10)和式(11)所示:
Xi=Ci+fr×(Cs-Cl)
(10)
fr=0.5×(sin(2π×0.25×t)×(t/T)+1)
(11)
其中,Cs和Cl分別為從當前種群中隨機選擇的2個粒子的濃度,且s≠l≠i;fr為正弦模型的縮放因子[15]。
由文獻[15]可知,正弦模型使得fr的值在0.5上下波動。在迭代前期,波動幅度不大,但周期性的波動有利于算法跳出局部最優點,準確定位全局最優點;在迭代后期,fr波動幅度較大,有時其值接近1,有時其值近似0,在算法陷于局部最優時,接近1的縮放因子值有利于算法跳出局部最優,當算法搜索到有希望的全局最優點時,接近0的縮放因子值有利于精確搜索。因此,正弦縮放因子能夠很好地平衡探索與開采能力。
融合領地搜索隨機差分變異策略的基本原理是:在一個隨機數rand小于0.5或者Cs和Cl為零向量時,最優個體進行領地搜索,否則采用隨機差分變異策略更新其濃度。在前期,各個粒子濃度之間的差異較大,Xi遠離Ci,搜索范圍較大,有利于全局搜索。但是,到了后期各個粒子濃度之間的差異變小,有利于局部搜索,但無差異時,Xi=Ci為無效解。為了應對這種情況,本文將領地搜索策略融入到差分變異策略中。
領地搜索思想來自人工蜂鳥算法[6],其靈感來自于蜂鳥的領地覓食行為。在蜂鳥吃完了目標花源的花蜜之后,它有可能在其附近搜索新的花源。因此,蜂鳥在它的領地里會移到當前食物源附近,搜索也許更好的食物源作為候選解。這種搜索策略在本文稱為領地搜索策略,其表達式如式(12)所示:
Xi=Ci+fα×Di?Ci
(12)
其中,fα是領地搜索因子,服從標準的正態分布,即均值為0、方差為1的高斯分布;Di為第i個蜂鳥的飛行方向向量,模擬蜂鳥3種飛行方式(軸向飛行、對角飛行和全向飛行),即當一個均勻分布在0~1的隨機數小于1/3時,蜂鳥采用對角飛行,當這個隨機數大于2/3時采用全向飛行,否則采用軸向飛行。在Di中,若一個隨機維的值為1,其它維的值全為0,則表示軸向飛行;若幾個隨機維的值為1,其它維的值為0,則表示對角飛行;若所有維的值全為1,則表示全向飛行。
從式(12)可知,Di是0-1向量,即每個分量要么是0,要么是1,故產生的新解Xi是在Ci自身的某些維或者全維變異獲得。這種搜索是一種局部搜索,能夠提升算法的收斂速度和解的精度。
將領地搜索融入到差分變異中的過程如算法2所示。
算法2融合領地搜索的差分變異策略
輸入:當前最優粒子。
輸出:更新后的最優粒子濃度。
1.隨機選擇2個粒子;
2.IF(隨機選擇的2個粒子濃度相同) or (rand<0.5);
3. 采用式(12)領地搜索更新最優粒子的濃度;
4.ELSE
5. 采用式(10)的隨機差分變異策略更新最優粒子的濃度;
6.ENDIF
從算法2可以看出:(1) 領地搜索的差分變異策略替換式(9)僅用于最優粒子的濃度更新,由此最優粒子的濃度更新是得益于種群中其它粒子的信息和自身信息。(2) 在差分值為0和rand小于0.5時采用領地搜索,解決了差分變異策略尤其在迭代后期易產生無效解的問題。(3) 從式(12)可以看出,領地搜索作用于最優粒子上,更能發揮領地搜索的作用,在最優粒子的濃度周圍進行精搜索更能加快算法收斂和提高解的精度。(4) 由于前期個體之間的差異較大,隨機選擇的2個個體的濃度相同的概率較低,這樣前期采用差分變異策略的機會較大,這有利于提高算法的全局搜索能力。(5)在迭代后期,采用領地搜索的概率較大,而領地搜索是一種局部搜索,所以在整個迭代過程中算法能夠從全局搜索自動轉換到局部搜索。(6) 無論前期還是后期,差分變異和領地搜索隨機交替執行,即全局搜索和局部搜索交替進行,有利于平衡探索與開采能力。
3.2 信息共享的隨機差分變異策略
MA通過群體中的信息共享和個體與環境的適應性等來搜索整個空間,從而找到最優解或者次優解[14]。因此,為了增強EO中粒子之間的信息共享程度,除了最優粒子和最差粒子外,本文在其它粒子的濃度更新上采用一種信息共享的隨機差分變異策略,其數學模型如式(10)所示。
雖然信息共享的隨機差分變異策略仍然采用3.1節的式(10),但由于這種隨機差分變異策略作用在多個粒子上,且Cs和Cl的隨機選擇滿足均勻分布,隨著迭代次數的增加,使得種群中所有粒子都有可能被選擇。這些差分值是種群內所有粒子貢獻的信息,如此增強了種群內粒子之間的信息共享。
3.3 簡化EO濃度更新策略
為了更好地與信息共享的隨機差分變異策略融合,增強可操作性和縮短運行時間,本文在保證EO優勢的情況下,提出一種簡化EO更新策略,其表達式如式(13)所示:
Xi=Ce-(Ce-Ci)?F+
0.5×r1×(Ce-Ci)?F?(1-F)
(13)
F=2×sign(r-0.5)×[e-η-1]
(14)
η=(1-t/T)(t/T)
(15)
從式(13)~式(15)可以看出,與原EO更新策略相比,簡化更新策略有以下差異:(1) 舍棄了λ、V、a1、a2和PG等參數,只保留了F、r和r1。這3個參數不需要人工調整,大幅度提高了EO的可操作性。(2) 去掉了參數λ,式(13)~式(15)減少了許多基于維度和基于指數的運算,這些都大幅度降低了計算量。(3) 由式(13)可知,簡化后的更新策略是精英粒子濃度與當前粒子濃度的差分向量,經過縮放后加到精英粒子的濃度上,這實際上也是一種差分變異策略,更加突出了精英粒子的引導作用,如此強化開采能力。
雖然簡化操作保持了EO較強開采能力的優勢,降低了計算復雜度,提高了可操作性,但它并沒有改變EO的整體搜索模式。此外,簡化策略去掉了隨機參數λ并采用一種更新模式,降低了種群的多樣性,在一定程度上削弱了EO的全局搜索能力。為了增強全局搜索能力,本文通過動態調整的方法將信息共享的隨機差分變異策略和簡化EO更新策略相結合。動態調整融合2種策略的流程圖如圖1所示。其中,η是融合2種更新策略的動態調整參數,如式(15)所示,隨著迭代次數的增加,它從1遞減到0;r2是均勻分布在[0,1]的隨機數。從圖1可以看出,當r2≥η時,使用簡化EO更新策略對當前粒子的濃度進行更新;否則,使用信息共享的隨機差分變異策略進行更新。在迭代初期,η值較大,大部分粒子采用信息共享的差分變異策略更新其濃度,少數粒子采用簡化EO更新策略更新其濃度。此時粒子之間的差異也較大,種群具有較強的多樣性,有助于全局搜索。在迭代后期,η值較小,大部分粒子采用開采能力強的簡化EO更新策略更新,少數粒子采用信息共享策略更新。此時粒子之間的差異較小,信息共享的差分變異策略也在一定程度上有利于算法的局部搜索。因此,動態調整2種策略有效地平衡算法的探索和開采能力,在提高全局搜索能力的同時保持了原算法局部搜索能力強的優勢。另外,為了防止差分變異操作產生無效解,在式(10)和式(13)中的差分向量為零向量時采用領地搜索,發揮領地搜索的優勢。

Figure 1 Process of hybrid differential mutation and simplified updating strategies圖1 融合差分變異策略和簡化更新策略的過程
3.4 精英與最差個體的差分變異策略
強化最差個體能夠提高算法的整體性能,進而提升算法的搜索效率[1]。故針對最差個體,本文提出了一種精英與最差個體的差分變異策略。如此有別于其它個體的更新方式,使最差粒子的搜索能力大幅度提高。其數學模型如式(16)所示:
(16)
其中,Xw為最差粒子更新后的濃度,Cw為最差粒子原有的濃度,r3為均勻分布在[0,1]的隨機數,fr的含義如式(11)所示。
從式(16)可以看出,在最差粒子原有濃度的基礎上,添加一個精英粒子與最差粒子的濃度差分值,這可以保證最差粒子在精英信息的引導下向著最優方向趨近,強化最差個體的開采能力。同時,在0.5的概率下,其差分值受到(0.5+0.5×rand)和fr縮放因子的擾動,如此縮放最差粒子的搜索范圍,以此在強化最差粒子局部搜索能力的同時兼顧全局搜索能力。因此,精英與最差個體差分變異策略能夠有效地增強最差個體的性能,減少最差粒子對整個種群的不利影響。同樣當差分為零向量時,采用領地搜索,以避免產生無效解。
3.5 DTEO流程
DTEO的流程圖如圖2所示。
由圖2可知,DTEO采用了4種濃度更新方式:融合領地搜索的隨機差分變異策略用于更新最優粒子的濃度;精英與最差粒子的差分變異策略用于更新最差粒子的濃度;而信息共享的隨機差分變異策略主要用于其它個體在迭代前期的濃度更新;簡化EO更新策略主要使用在迭代后期。雖然這4種改進策略都使用了差分變異策略和領地搜索,但隨機差分變異策略在搜索前期主要用于全局搜索,而領地搜索主要用于局部搜索,也為了避免差分變異策略產生無效解。所以,在DTEO中,差分變異策略與領地搜索有機結合能夠提高搜索效率。總之,DTEO在保持EO優勢的同時,增強了種群中的信息利用率,克服了EO的不足,較好地平衡了探索和開采性能。

Figure 2 Flow chart of DTEO圖2 DTEO算法流程圖
4 實驗與結果分析
4.1 實驗環境與評價標準
為了驗證DTEO的性能,將其用于CEC2014復雜函數測試集的優化實驗。CEC2014包含4類函數:單峰函數(f1~f3)、多峰函數(f4~f16)、組合函數(f17~f22)和復合函數(f23~f30),具體細節見文獻[16]。主頻3.4 GHz的Intel?CoreTMi7-3770 CPU和8 GB內存的PC機實驗環境下,操作系統采用64位的Windows 10系統。用于統計分析的軟件是IBM SPSS Statistics 24,編程語言采用MATLAB2014A。
本文采用均值(Mean)、方差(Std)、排名(Rank)、平均排名和總排名等指標來評價一個MA的優化性能好壞。對于一個極小值問題,一個MA所獲得的均值越小,表示它的優化性能越好。方差越小,穩定性越強。排名規則如下:在每個函數上,算法得到的均值越小,排名靠前;若幾個算法的均值相同,再比較方差,方差越小,則排名靠前;如果均值和方差相同,則排名相同。
4.2 對比算法及參數設置
為了全面評價DTEO的表現,包括優化性能、運行時間和搜索效率等,本文選擇了一些最先進的代表性算法作為其對比算法。它們包括EO[9]及其改進算法AEO[11]、MEO[13]和ISEO[14],也包括其它最新的優秀算法AHA[6]、DDHBO(Differential Disturbance HBO)[7]、XPSO(eXpanded PSO)[5]和BWCOA(Best and Worst coyotes strengthened Coyote Optimization Algorithm)[1]。XPSO是具有多榜樣學習的PSO變體,而PSO是經典智能優化算法的代表。AHA是人工蜂鳥算法,是最新提出的MA,它和DTEO都采用了領地搜索策略。BWCOA是強化最優和最差個體的郊狼優化算法,它和DTEO都采用了強化最優和最差個體策略。DDHBO是最新的HBO改進變體,它與DTEO都采用了差分變異策略。ISEO是強化信息使用的EO,它與DTEO的共同目的就是強化信息使用,且它和MEO都是2022年提出的算法。這些對比算法均具有極強的代表性和可比性。
為了公平比較,根據文獻[16]的公共參數最佳設置建議,所有算法的公共參數設置相同:最大函數評價次數(Mnef)為D×10000,獨立運行次數為51。算法的不同參數設置將導致不同的實驗結果,因此對比算法的其他參數設置是根據相應參考文獻中的最佳推薦進行設置的,如表1所示。

Table 1 Parameters setting of 9 comparison algorithms表1 對比算法的參數設置
4.3 與其不完全算法的性能對比
為了驗證每種改進對DTEO優化性能的貢獻,本節將DTEO與其不完全算法在CEC2014的30維函數上進行實驗對比。不完全算法的描述如下:DTEOwd為無信息共享差分變異策略的EO,DTEOww為無精英與最差個體差分變異策略的EO,DTEOwb為無融合領地搜索差分變異策略的EO。表2給出了DTEO與其不完全算法的Wilcoxon符號秩檢驗結果,顯著性水平值設為0.05。3種不完全算法及EO的參數設置與DTEO的保持一致。“n”表示CEC2014測試集函數的數目30,“+”表示DTEO優于對比算法,“≈”表示DTEO與對比算法的實驗結果近似,“-”表示DTEO劣于對比算法。表3列出了5種算法的平均排名結果。
由表2可知,DTEO優于4種對比算法,例如DTEO優于和劣于EO的個數分別是27和3,說明本文對EO的改進是有效的。
從表3可以看出,EO、DTEOwd、DTEOww、DTEOwb和DTEO的平均排名值分別為4.27,3.23,2.6,2.57和1.93。DTEO排名第一,DTEO在5種算法中獲得了最好的優化性能,EO排名最后,其性能最差。這表明本文的改進是有效的,并且每種改進缺一不可,其中信息共享的隨機差分變異策略對DTEO的貢獻最大,而融合領地搜索差分變異策略貢獻最小。
4.4 與最先進算法的優化性能對比
為了驗證DTEO的有效性,本節將其在CEC2014的30維函數上進行實驗,并將結果與最先進算法的結果進行對比。對比算法包括AEO、AHA、BWCOA、XPSO、ISEO、MEO和DDHBO。表4列出了DTEO與對比算法的實驗結果,其中最優結果以粗體顯示。
由表4可知,在平均排名上,DTEO為2.43,總排名第一,而MEO、AEO和ISEO分別為6.47,5.57和3.57,這表明它們在解決復雜問題上搜索能力不足,而本文提出的DTEO在解決復雜優化問題上比3種已有的EO改進算法更優。在3個單峰函數上,DTEO在f1上排名第一,在f2和f3上都排名第二。這說明DTEO具有更強的局部搜索能力,這得益于EO自身開采能力強的優勢、領地搜索和精英粒子對最差粒子的引導等。在多峰函數f6和f14上,DTEO獲得的結果均優于其對比算法的結果,雖然在其它多峰函數上獲得的結果優勢不明顯,但比MEO和AEO的結果要好得多。顯然,信息共享的差分變異策略使得DTEO具有不錯的全局搜索能力。在混合和組合函數上,DTEO在10個函數f17、f18、f20、f21、f23~f25和f27~f29上排名第一,且排名第一的次數最多。這表明DTEO較好地平衡了探索和開采能力,能更好地處理更為復雜的優化問題。DTEO的平均排名為2.43,XPSO、DDHBO、BWCOA、AHA、ISEO、MEO和AEO的平均排名分別為6.07,3.73,3.23,4.63,3.57,6.47和5.57。顯然,與最先進的算法相比,DTEO獲得了最好的優化性能。這再次說明本文的4種改進策略是有效的,與EO及其改進算法相比,DTEO具有更強的搜索能力。

Table 2 Statistical results of DTEO and its incomplete algorithms表2 DTEO vs不完全算法的統計結果
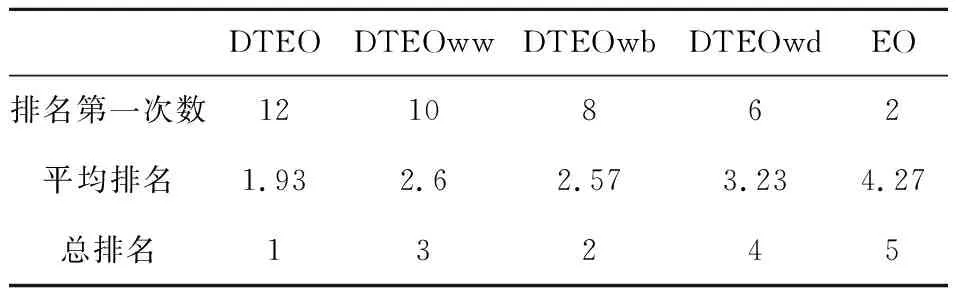
Table 3 Ranking results of DTEO and its incomplete algorithms表3 DTEO與不完全算法的排名結果
4.5 運行時間對比分析
為了討論DTEO的運行時間,直接采用4.4節的實驗,本節僅記錄DTEO及其對比算法在CEC2014測試集30維函數上的運行時間。9種算法獨立運行51次獲得的平均運行時間如圖3所示,時間單位為s。
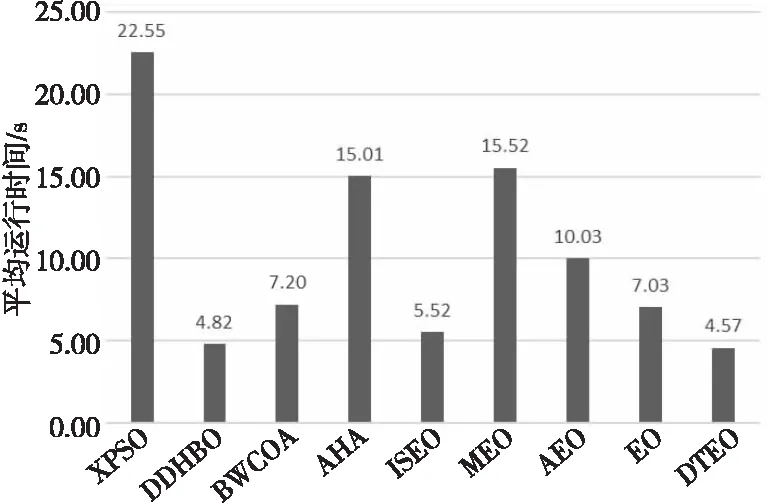
Figure 3 Comparison of average time of 9 algorithms on 30-demensional functions圖3 9種算法在30維函數上的平均時間對比
從圖3可以看出,DTEO的運行時間比EO、 AEO、MEO和ISEO的少,且在9種算法中,其耗時也是最少的。按耗時的升序排名,DTEO排名第一,隨后是DDHBO、ISEO、EO、BWCOA、AEO、AHA、MEO和XPSO,耗時最多的是XPSO。DTEO的耗時(4.57 s)分別是EO(7.03 s)、AEO(10.03 s)、MEO(15.52 s)、ISEO(5.52 s)、DDHBO(4.82 s)、BWCOA(7.20 s)、AHA(15.01 s)和XPSO(22.55 s)的65.00%,45.56%,29.45%,82.79%,94.81%,63.47%,30.45%和20.27%。限于篇幅,本節僅簡單討論DTEO耗時少的原因。DTEO耗時少的主要原因是:(1) 本文提出的改進策略都是替代策略,不是添加策略,即用本文提出的更新策略替換原來的更新策略,沒有增加額外的計算;而AEO、MEO和ISEO都添加了新操作,例如AEO為每個粒子與當前種群平均適應度值進行比較,故耗時比EO的耗時長。而ISEO添加了交叉操作,故在耗時上比DTEO的長。(2) 雖然引入了4種新的濃度更新方式,但任何更新方程都比EO的更新方程更簡單。(3) 對EO更新方程的簡化處理,大幅度降低了計算復雜度,節省了運行時間。而EO中包含大量的向量運算和指數運算,造成了EO的運行時間長。
4.6 Wilcoxon符號秩檢驗
為了測試DTEO與對比算法的顯著性差異,本節進行差異性統計分析。Wilcoxon符號秩檢驗是一種非參數統計檢驗[1],它常用于檢驗2種算法之間差異的顯著性。本節采用此方法檢驗DTEO與表4中對比算法之間的顯著性。當DTEO的性能優于對比算法時,其秩為正;性能劣于對比算法時,其秩為負;性能與對比算法持平時,對應的秩平分。表5列出了DTEO與對比算法的Wilcoxon符號秩檢驗結果,顯著性水平值設置為0.05。其中,p為實際顯著性水平值,R+和R-分別表示正秩和負秩,“n/w/l/t”表示在n個函數上DTEO優于和劣于對比算法分別為w次和l次,相同結果為t次。如果p<0.05,則表明DTEO顯著優于對比算法。相反,DTEO與對比算法無差異或更差。
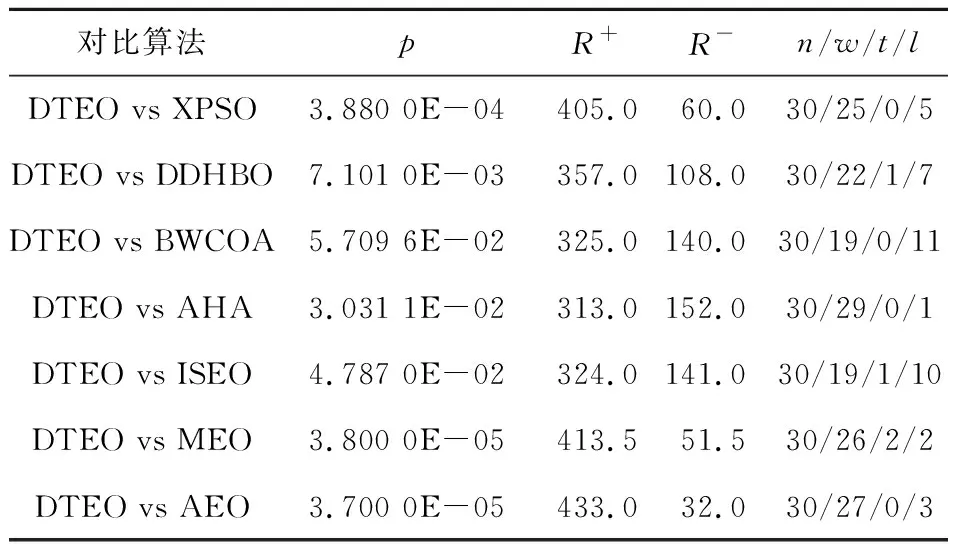
Table 5 Wilcoxon signed rank test results表5 Wilcoxon符號秩檢驗結果
從表5可以看出,在30個函數上DTEO優于XPSO、DDHBO、BWCOA、AHA、ISEO、MEO和AEO的函數個數分別為25,22,19,29,19,26和27。并且除了BWCOA的p值為5.709 6E-02外,DTEO與其它對比算法相比的p值均小于0.05,這表明DTEO顯著優于這6種對比算法。
5 DTEO應用于機器人路徑規劃
隨著科技的快速發展,移動機器人被廣泛應用到諸多領域,替代或協助人類完成很多危險或復雜等工作。機器人路徑規劃RPP(Robot Path Planning)是受多種因素影響且難以求解的問題,所以在特定的環境下找到更為高效和安全的方法具有較強的實際意義。目前因MA有許多優勢,已被廣泛應用到路徑規劃中[2]。
5.1 MA運用到機器人路徑規劃的基本原理
機器人路徑規劃的主要目的是在環境地圖中搜索出一條從起點到終點的距離最短的安全無碰撞路徑。圖4是機器人路徑規劃的示意圖。起點和終點分別用方形和星形表示,障礙物用圓表示。在二維直角坐標系中,每個圓可以用式(17)表示:
r2=(x-a)2+(y-b)2
(17)
其中,(x,y)為點坐標,(a,b)為圓心坐標,r為半徑。
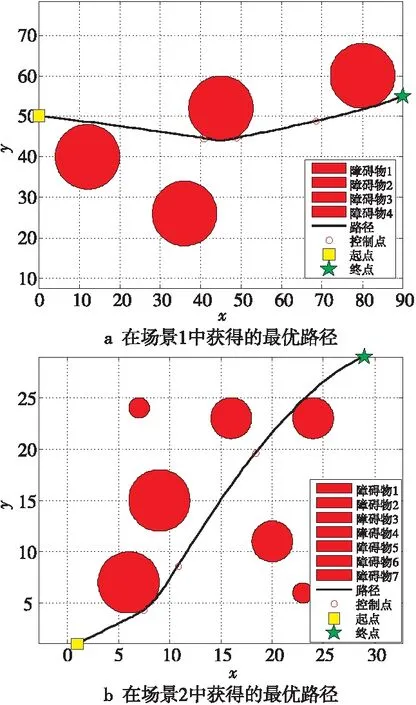
Figure 4 Best path maps of DTEO in two scenes圖4 DTEO在2個場景中獲得的最優路徑圖
RPP要求確定一條由起點(x0,y0)到終點(xn+1,yn+1)的路徑{(x0,y0),(x1,y1),(x2,y2),…,(xn,yn),(xn+1,yn+1) },使決策目標最優,其中,(x1,y1),(x2,y2),…,(xn,yn)為待優化的控制點坐標。控制點的數量n決定了RPP的維度。為了降維和使路徑更加精確,常引入插值方法。本文在每次迭代中,在兩兩控制點間采用Spline插值法插入100個點。RPP的決策目標是以帶約束的線路長度作為目標函數,并在其中引入懲罰函數法構建規避障礙物約束,以便機器人避開障礙物,該數學模型如式(18)所示:
(18)
其中,v(k)為避障約束函數,r(k)為第k個障礙物的半徑,(ak,bk)為第k個障礙物的圓心坐標。m為障礙物個數;ε為懲罰系數,在本文設置為100。
將一個MA運用到RPP的主要步驟如下:(1) 將式(18)作為目標函數,求此函數的最小值對應的決策變量;(2) 將起點到終點之間n個控制點的坐標,包括橫坐標和縱坐標作為決策變量,在本文中n=3,則優化問題的維度為2n;(3) 確定這n個點坐標對應的上界和下界;(4) 輸入以上信息到一個MA中;(5) 運行MA;(6) 輸出最優解所對應的坐標。
5.2 機器人路徑規劃的仿真結果及分析
為了檢驗DTEO在路徑規劃中的性能,將其應用到大量較為復雜的路徑規劃中。為了簡要說明問題,以2個場景的路徑規劃為示例進行描述:場景1:4個障礙物的圓心坐標分別是(12,40),(36,26),(45,52)和(80,60),其半徑都為8。起點(x0,y0)=(0,50),終點(xn+1,yn+1)=(90,55)。場景2:7個障礙物的圓心坐標分別是(6,7),(20,11),(23,6),(9,15),(7,24),(16,23)和(24,23),其半徑分別為3,2,1,3,1,2和2。起點(x0,y0)=(1,1),終點(xn+1,yn+1)=(29,29)。對比算法見表1。對比算法的公共參數設置相同:Mnef為10 000,獨立運行次數為30。DTEO獲得的最優路徑如圖4a和圖4b所示,9種算法在2個場景中的性能分別如圖5a和圖5b所示。其中為了更清晰反映各個算法的性能,采用了各個算法獲得的實際路徑長度與它們獲得最好路徑長度之差(誤差)的對數值。9種算法獲得的均值、方差、最大值和最小值如表6所示。
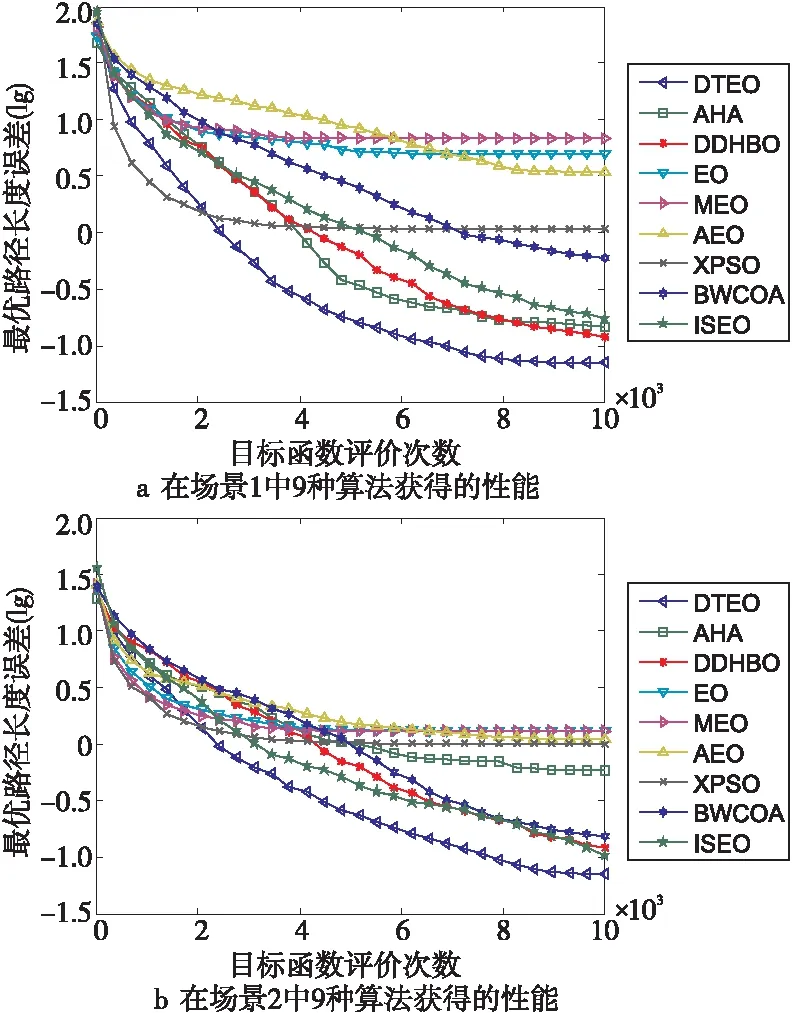
Figure 5 Performance curves of different optimization algorithms圖5 不同優化算法的性能曲線
從表6可以看出,除了場景2方差排名第二外,在其它方面,DTEO都排名第一,平均排名值為1.13,總排名第一,在9種算法中獲得了絕對優勢。而EO的平均排名值為8.13,總排名第九,再次證明DTEO提升了EO的搜索能力,所提出的改進策略是有效的。
從圖5a和圖5b也可以直觀看到,在9種對比算法中,無論在場景1還是在場景2中,DTEO的收斂曲線隨著目標函數評價次數的增加,都是下降最快的,即收斂速度最快,獲得了最好的收斂性能。
總的來說,DTEO在解決RPP時,優于對比算法。這表明DTEO能夠更好地處理復雜的問題RPP,具有更強的競爭性。
6 結束語
針對EO中存在搜索能力不足、可操作性差和搜索效率低的問題,本文提出了一種改進的EO,即差分變異和領地搜索的EO。它包括4種新型濃度更新策略:(1)融合領地搜索的隨機差分變異策略,提升最優個體;(2)信息共享的隨機差分變異策略,提高算法的搜索能力;(3)簡化EO更新方程策略,提高算法的可操作性,降低計算復雜度;(4)精英與最差個體的差分變異策略,強化最差個體。在CEC2014測試集30維函數上的實驗結果表明,與EO以及一些最先進的優化算法相比,DTEO具有更好的優化性能。機器人路徑規劃的實驗結果也表明,DTEO具有更強的競爭力,由此證明本文的改進是有效的。2類實驗結果表明,DTEO采用的4種濃度更新方式是有效的,不僅增加了新解方式的多樣性,也增強了種群多樣性,有利于全局搜索和解決不同的優化問題。盡管DTEO的整體優化性能優于對比算法的,但其優勢在CEC2014測試集多峰函數上并不明顯。因為EO是最近提出的算法,許多方面還需要進一步研究,如理論研究、改進研究和應用研究。本文僅是一種改進研究的嘗試。另外,在CEC系列的其它復雜函數測試集和其它實際優化問題上效果如何也是今后的研究內容。
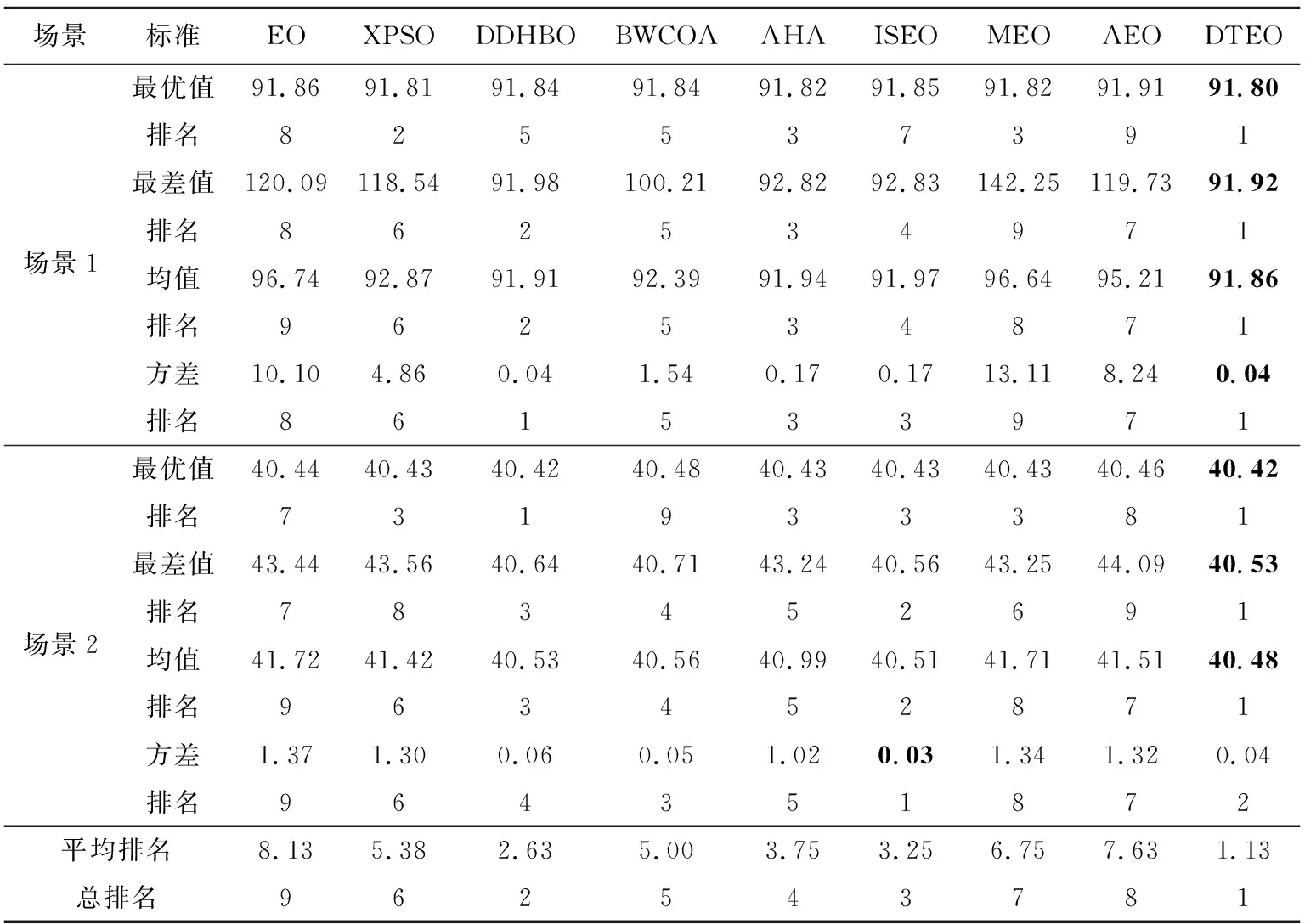
Table 6 Experimental results of DTEO and 8 comparison algorithms on RPP表6 DTEO與8種對比算法在路徑規劃上的實驗結果
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
