基于多尺度特征融合網絡的HEVC幀內編碼單元快速劃分研究
2023-11-17 13:15:26劉雨墨劉劍飛郝祿國曾文彬
計算機工程與科學 2023年11期
劉雨墨,劉劍飛,郝祿國,曾文彬
(1.河北工業大學電子信息工程學院,天津 300131;2.河北工業大學電子與通信工程國家級實驗教學示范中心,天津 300131; 3.廣東工業大學信息工程學院,廣東 廣州 510006;4.天津大學電氣自動化與信息工程學院,天津 300072)
1 引言
高效視頻編碼HEVC(High Efficiency Video Coding)作為一個新的視頻壓縮標準,首次被ITU-T (International Telegraph Union Telecommunication standardization sector)和 ISO/IE(International Organization for Standardization/ International Electro technical Commission)聯合發布[1]。與上一版本H.264相比,HEVC引入了很多新的技術模塊,能夠在保證視頻編碼質量的前提下,壓縮率提高40%~50%,但其復雜度也顯著增加。在龐大的數字視頻數據量的環境下,許多的電子設備,包括便攜式設備都要傳輸和存儲數字視頻,因此對數字視頻進行高壓縮率處理的同時,還需要降低HEVC的編碼復雜度。
在HEVC新引入的諸多技術模塊當中,最核心的模塊之一是基于四叉樹的編碼單元CU(Coding Unit)靈活劃分結構。根據編碼特性的不同,視頻圖像中包括了平緩區域和復雜區域。HEVC為了適應不同區域,將圖像劃分為互不重疊、大小相等的正方形塊,稱作編碼樹單元CTU(Coding Tree Units)[2]。CTU基于四叉樹劃分結構繼續向下劃分出若干個CU。編碼單元劃分采用遞歸劃分方案,其中每個編碼單元的節點又可以遞歸地細分為4個新節點,直到達到最小的CU。CU的大小一般為64×64,32×32,16×16和8×8。若HEVC采用遞歸方式,編碼區需要掃描所有可能的CU,并通過自上而下的率失真優化RDO(Rate Distortion Optimization)成本計算以及自下而上的成本比較,來選擇最優結果。這個過程包含了大量的冗余計算,且非常耗時,占據了80%以上的編碼時間。
為了降低HEVC的編碼復雜度,優化編碼單元劃分過程,研究人員提出了多種針對HEVC編碼單元劃分的快速方法,大致上可以分為2種:基于啟發式的方法和基于機器學習的方法。基于啟發式的方法是根據當前CU的中間特性以及相鄰CU的空間相關性實現跳過或提前終止某些模式。Shen等[3]根據CU與內容的關聯程度,跳過一些內容中很少使用的CU深度等級。文獻 [4-6] 采用貝葉斯決策對所有的CU深度等級進行提前終止和裁剪。文獻 [7] 引入絕對變換誤差成本計算進行模式選擇和雙向深度搜索,來實現CU的早期終止。這類方法相較于RDO遞歸過程節省了大量計算,但其不能全面地考慮各類視頻序列中的分割特性,導致在特定場景下RD(Rate Distortion)精確度不佳的問題尤為明顯。為克服這類方法的缺點,一些研究人員采用機器學習的方法完成加速編碼過程。文獻 [8,9] 采用支持向量機SVM(Support Vector Machine)快速提取圖像特征,根據特征對應的CU復雜程度建立分類器再進行CU深度決策。文獻 [10]利用在線學習構建精確模型以跳過不必要的模式。文獻 [11] 通過數據挖掘技術訓練分類器實現早期CU分類。文獻 [12] 利用隨機森林分類器跳過或終止當前CU深度等級。在基于機器學習的方法中,分割效果相當程度上依賴輸入的特征,而特征的提取和功能設計需要大量的工作和經驗。諸多研究利用卷積神經網絡CNN(Convolutional Neural Network)自動學習特征的特點,在幀內編碼的過程中主要作用于提前預測CU劃分,從而避免RDO的冗余計算,降低HEVC的編碼復雜度。文獻 [13,14]利用淺層CNN結構并提出了一種友好的VLSI(Very Large Scale Integration)快速決策算法,以此來預測CU塊邊緣的概率向量,并跳過部分分割模式,但該方法并沒有完全擺脫RDO遞歸計算過程。文獻 [15] 利用CNN模型在CU搜索過程中預測3種類型的CU劃分結果,將模型作為CU分區過程的分類器。文獻 [16,17]嘗試跳過RDO的遞歸過程,將CTU分成3種尺度輸入到CNN,每種尺度深度等級不同,同時得到3個分割標志,用3個CNN來判斷不同深度等級是否需要進行分割,但分割標志是基于當前塊決定,不考慮整個CTU的信息。
為簡化窮舉法的RDO計算過程,本文利用深度學習方法對幀內編碼單元劃分進行提前預測,即使用具有很強泛化能力的CNN有效地對視頻中不同紋理復雜程度的圖像進行自適應劃分,以此來降低HEVC的編碼復雜度。實驗結果表明,本文設計的CNN網絡模型能夠有效泛化于不同分辨率的視頻序列,同時很大程度上縮短了視頻編碼的時間。本文工作可總結如下:
(1)選取5種不同分辨率的38個視頻序列,將視頻序列和對應的編碼信息構建成用于訓練CNN模型的大規模數據集。
(2)根據CU劃分特點和U-Net網絡結構優勢,設計出多尺度特征融合的UcuNet(U-shape code unit Net)網絡結構,有效提取不同尺度的CTU特征并進行拼接融合,同時引入非對稱卷積AC(Asymmetric Convolution)和CBAM(Convolutional Block Attention Module)注意力機制來提高網絡預測能力。
(3)通過實驗驗證了上述設計的有效性,與HEVC官方測試模型(HM16.20)相比,該設計縮短了68.13%的編碼時間,BD-BR(Bitrate- Distortion Bound Rate)的影響在可接受的2.63%范圍內。
2 UcuNet算法設計
本文提出基于多尺度特征融合的網絡(UcuNet)來優化HEVC結構。在編碼一幀時,添加新的線程啟用UcuNet,使其對輸入的一整幀圖像進行處理。UcuNet是由不同視頻序列所構建出的數據集訓練得來。
UcuNet的流程如圖1所示。首先,視頻的每一幀圖像輸入后,被裁剪成大小為64×64的互不重疊的CTU,隨后進行CTU編碼;然后,利用所提出的CNN網絡模型預測出所有CU的深度信息;最后,利用預測的深度信息進行CU編碼,得到輸出的編碼結果。HEVC編碼過程中,原始的線程負責判斷,新的線程預測是否完成,待預測完成后,直接將預測的深度信息作為CU劃分深度進行編碼。整個過程循環往復,直到所有編碼完成。

Figure 1 Flow chart of UcuNet for fast partitioning of coding units圖1 UcuNet實現編碼單元快速劃分的流程圖
2.1 數據集構建
為了訓練預測CU劃分的深度學習模型,需要構建一個由圖像塊和對應的深度信息組成的數據集。為了產生足夠多的訓練樣本,同時防止訓練過程出現過擬合,本文剔除了常用的JCT-VC(Joint Collaborative Team on Video Coding)測試序列,構建了一個大規模的數據集。該數據集包含了5種不同分辨率的38個視頻序列,分辨率分別為:352×288, 704×576, 1280×720, 1920×1080和3840×2160。將這些序列分成3個子集,其中23個用作訓練集、8個用作驗證集和7個用作測試集。使用不同分辨率的視頻序列來制作數據集是為了保證訓練數據的多樣性,從而提高CTU劃分的高效性。使用HEVC官方測試模型HM16.20在量化參數QP(Quantization Parameter)(4種取值:37,32,27,22)下對以上所有視頻序列進行全幀內編碼。將得到的每一個CTU劃分結構情況和原始的64×64亮度像素值一起作為一個樣本。收集并統計所有CTU劃分的樣本情況。由于視頻圖像具有時間相關性,相鄰幀之間具有高度相似性,為了數據集的合理性,以及避免在訓練時產生過擬合,采用隨機方式抽取部分幀進行處理獲取隨機樣本RS(Random Samples)。這樣做的好處是,可以去除大部分重復數據,同時增加樣本間的差異性。表1列出了不同分辨率下的視頻序列個數、總幀數、獲取到的原始樣本總量以及隨機抽取幀獲得的樣本總量。

Table 1 Information of the samples in the dataset表1 數據集中樣本的信息
基于隨機抽取幀獲取的樣本中,訓練集、測試集和驗證集的樣本數量分別占樣本總量的82%,8%和10%。
2.2 UcuNet網絡
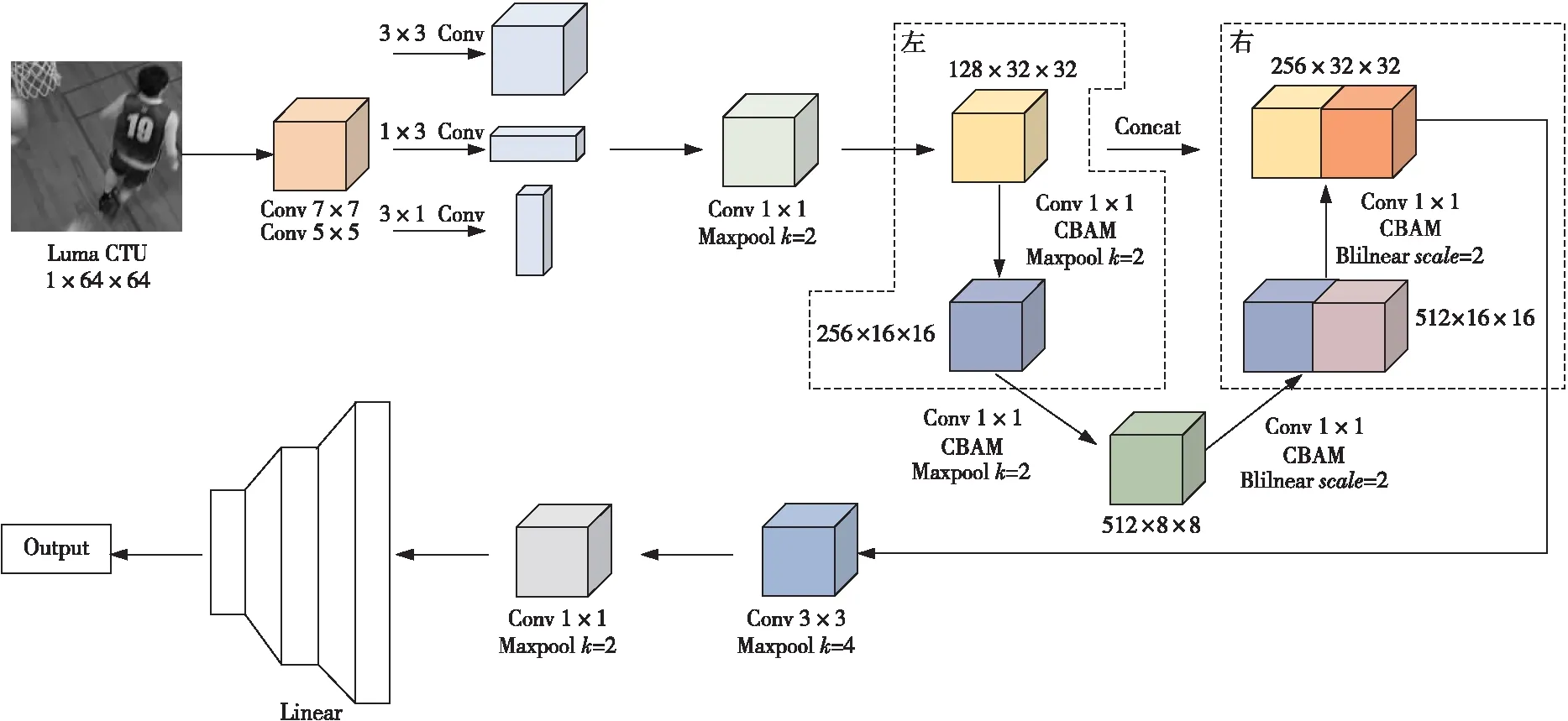
Figure 2 Structure of UcuNet圖2 UcuNet結構
由于CU劃分的深度很大程度上與視頻圖像中的紋理復雜程度相關,分析圖像的特征可以預測CU深度信息。CNN已經被證實是一個能從圖像內容中提取特征的強大工具,因此本文利用CNN設計了一個多尺度特征融合的網絡模型UcuNet來預測CU深度。圖2為UcuNet結構。整體結構除包含輸入層、卷積層、池化層和全連接層外,還為了滿足不同尺度的特征提取,尤其是CU特有的尺寸64×64,32×32,16×16和8×8,引入了非對稱卷積、下采樣和上采樣的處理方法,增加了卷積核的表征能力和特征圖的多樣性。輸入是處理原始CTU后得到的64×64 CTU亮度,即YUV(Y表示亮度,U表示色度,V表示濃度)視頻中Y分量組成的亮度像素塊。首先,通過7×7和5×5的卷積層獲取淺層特征,然后利用非對稱卷積AC模塊增強特征擬合,減少參數量和計算量的同時,引入非線性激活函數來提高網絡模型的表達能力,然后再利用1×1的卷積層進一步提取更深的特征并減少計算量,同時對特征通道升維。根據CU尺寸的特點,經過卷積處理后的特征進入到本文網絡模型的主體部分,將其進行下采樣后,對不同尺寸進行卷積層和池化層的操作,然后采用雙線性插值法的上采樣后,繼續進行卷積層和池化層的操作,最后將得到的每個尺寸下的特征進行拼接融合,有效提升模型的特征學習能力。
接下來,通過1×1的卷積將特征通道升維后,再進行全局池化,進一步精簡特征。本文采用了卷積核為4的池化層處理,將所獲取的特征進行過濾,能夠達到在保留主要特征的前提下減少大量冗余參數的效果。最后,通過全連接層把前面獲取的特征綜合起來進行權重矩陣的匹配。整個過程均采用全局歸一化BatchNorm和ReLU非線性激活操作,以使訓練數據更快地收斂。
本文UcuNet中的主干網絡是U型對稱的,其設計思路來源于U-Net[18]。U-Net在2015年的IEEE國際生物醫學成像研討會ISBI(International Symposium on Biomedical Imaging)比賽中應用于圖像分割領域并獲得了冠軍。本文將U-Net結合CU劃分的特點加以修整。圖2左側稱為壓縮路徑,采用最大池化層進行下采樣操作,其目的是提取低分辨率的特征信息。右側是擴展路徑,采用雙線性插值法進行上采樣操作,其目的是提取高分辨率的特征信息。通過2條不同類型的路徑,使得網絡能夠進行端到端的訓練,同時可以較為精確地獲取圖像中的上下文信息和精確的定位。整個過程包含了3種特征尺寸,分別為32×32,16×16和8×8,對應CU劃分的深度1,2和3。每次下采樣過程包含了2個1×1的卷積層,相應地,上采樣過程包含了2個1×1的卷積層(卷積與雙線性插值結合實現反卷積操作),并將擴展路徑和壓縮路徑的同尺寸特征圖進行基于通道的拼接處理。
最后,網絡利用CTU矩陣中重復數值塊最小的尺寸捕捉其紋理復雜度特征信息。其輸出的標簽數值所取范圍均為0~3,表征每個CTU中所有CU劃分的深度信息。
為了讓網絡充分學習不同像素類別、通道特征以及上下文特征信息,在上采樣和下采樣的過程中引入CBAM注意力機制[19],CBAM的結構如圖3所示。在每個尺寸特征圖中加入注意力機制,可以讓網絡對不同特征信息添加不同的權重,并且更為全面地獲取特征信息。CBAM是基于卷積模塊的注意力機制,相較于SENet(Squeeze-and-Excitation Networks)[20],CBAM的優勢是同時結合了空間和通道的注意力機制模塊,且與原輸入特征圖相乘實現了自適應特征修正。

Figure 3 Structure of CBAM圖3 CBAM的結構
通道注意力模塊結合了全局平均池化(AvgPool)和最大池化(MaxPool)的處理,隨后將結果輸出到多層感知器MLP(MultiLayer Perceptron)進行基于像素的相加處理,最后利用Sigmoid激活函數生成該模塊的特征圖F。它的數學計算公式如式(1)所示:
F=S(MLP(MaxPool(x))+
MLP(AvgPool(x)))
(1)
其中,x表示輸入特征,S表示Sigmoid函數。
空間注意力模塊與通道注意力模塊相互補充,通道注意力模塊的輸出和原始的輸入特征相乘后作為空間注意力模塊的輸入,然后利用全局平均池化和最大池化處理后拼接起來,再送入到卷積層將通道數變成1,最后利用Sigmoid函數激活后生成最終的特征F,如式(2)所示:
F=S(f7×7([MaxPool(x);AvgPool(x)]))
(2)
其中,f7×7表示卷積核為7×7大小的卷積層。
經過CBAM的注意力機制后,輸出的新特征圖獲得通道和空間維度上的注意力權重,極大地增強了在通道和空間層面上每個特征之間的聯系,提高了獲取的目標特征的有效性。
3 實驗與結果分析
為了評價UcuNet CU劃分深度預測中的性能,本文將訓練好的模型嵌入到HEVC官方測試模型HM16.20[21]中進行多次實驗。本文實驗的硬件環境配置為:1.6 GHz主頻的Intel?CoreTMi5-8265U CPU、8 GB運行內存和64位Windows操作系統。在訓練過程中,采用BP (Back Propagation)算法對CNN模型進行迭代更新,并選擇Adam算法進行優化。優化器的動量衰減和重量衰減因子分別設為0.9和0.005。初始學習率設置為0.001,并且激活NVIDIA?GeFore?GTX 1080Ti GPU加速CNN模型的訓練過程。CNN模型的訓練和測試過程是在PyTorch架構下完成的,其中配置文件采用encoder_intra_main.cfg,原因是本文只考慮降低HEVC幀內編碼過程的復雜程度。實驗共計對17個測試序列進行實驗比較。這些測試序列均來自標準JCT-VC測試集[22],其中包含5個類別,分別是A、B、C、D和E類。為了評估算法編碼效率、復雜度和主觀視頻質量,分別使用指標ΔT、BD-BR和BD-PSNR對所提出的基于深度學習的幀內編碼單元劃分算法和官方測試模型HM16.20算法進行比較。3個指標定義如下:
(1)ΔT:表示相較于原始編碼方式的編碼縮短時間,同時也表示編碼中計算復雜度的降低程度,計算公式如式(3)所示:
(3)
其中,Tprop表示本文提出算法對應的實際編碼時間,THM16.20表示使用官方測試模型HM16.20算法對應的編碼時間。編碼時間越短,表示復雜度的降低程度越高。
(2)BD-BR:表示在目標視頻質量相同的情況下,優化算法與對比算法相比的比特率增量,計算公式如式(4)所示:
(4)
其中,DH和DL分別為RD輸出曲線的最大值和最小值,r1和r2為2個相對應的比特率。BD-BR指保證相同圖像質量的前提下對應碼率的相對值,該值越小代表碼率越小,意味著編碼效率更佳。
(3)BD-PSNR(Bitrate-Distortion Peak Signal- to-Noise Ratio):表示在相同比特率下,優化算法與對比算法相比視頻質量的客觀改善程度,計算公式如式(5)所示:
(5)
其中,rH和rL分別為輸出碼率最大值和最小值,D1(r)和D2(r)為2個相對應的RD輸出曲線。BD-PSNR指在保證相同碼率的前提下亮度分量對應的峰值信噪比的大小,該值越小表示圖像視頻質量損耗越小。
根據以上參數,使用本文算法在4種QP值(22,27,32,37)下分別對A(2560×1600)、B(1920×1080)、C(832×480)、D(416×240)、E(1280×720)5類測試序列(選取其中14個測試視頻的前50幀)使用全幀內編碼配置進行編碼測試實驗,以充分測試不同視頻編碼方法的效果。
表2列出了利用本文設計對測試序列進行編碼實驗的結果,其中包含了BD-BR、BD-PSNR以及4種QP值下的編碼時間縮短量ΔT。結果表明,A和E類的編碼復雜度降低最多,C類和D類的編碼質量損失最小。在測試序列中最多可縮短79.49%的編碼時間,最小編碼質量損失BD-BR為1.19%,對應BD-PSNR為-0.1 dB。
為了評估UcuNet在CU劃分預測上的表現,本文完成了4組消融實驗。4組實驗分別采用了不同的CNN網絡結構設置,如表3所示。具體來說,采用U-Net結合CU劃分尺寸特性的3層結構中UcuNet-T是網絡主干,UcuNet-E1和UcuNet-E2表示不同模塊的消融,UcuNet-E3表示最終提出的方案。各模型結果需要在4種不同的QP值(22,27,32,37)下對每個序列的前10幀進行測試。測試序列為隨機抽取的5種不同分辨率大小的視頻,具體視頻序列信息如表4所示。各網絡對應的BD-BR和BD-PSNR測試結果如圖4所示,圖中數據越偏左上方對應的預測效果越好。可以看出,對于CU劃分的深度預測,網絡模型中不同模塊的使用都有明顯效果,其中最終網絡UcuNet-E3效果最佳。

Table 3 Configuration of 4 ablation experiments 表3 4組消融實驗配置
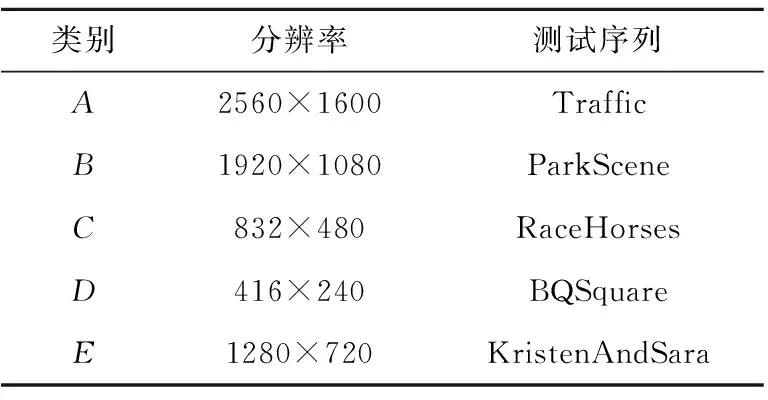
Table 4 JCT-VC test sequences used in ablation experiments表4 消融實驗使用的JCT-VC測試序列

Figure 4 Performance of each model of the ablation experiments圖4 消融實驗各模型的性能結果
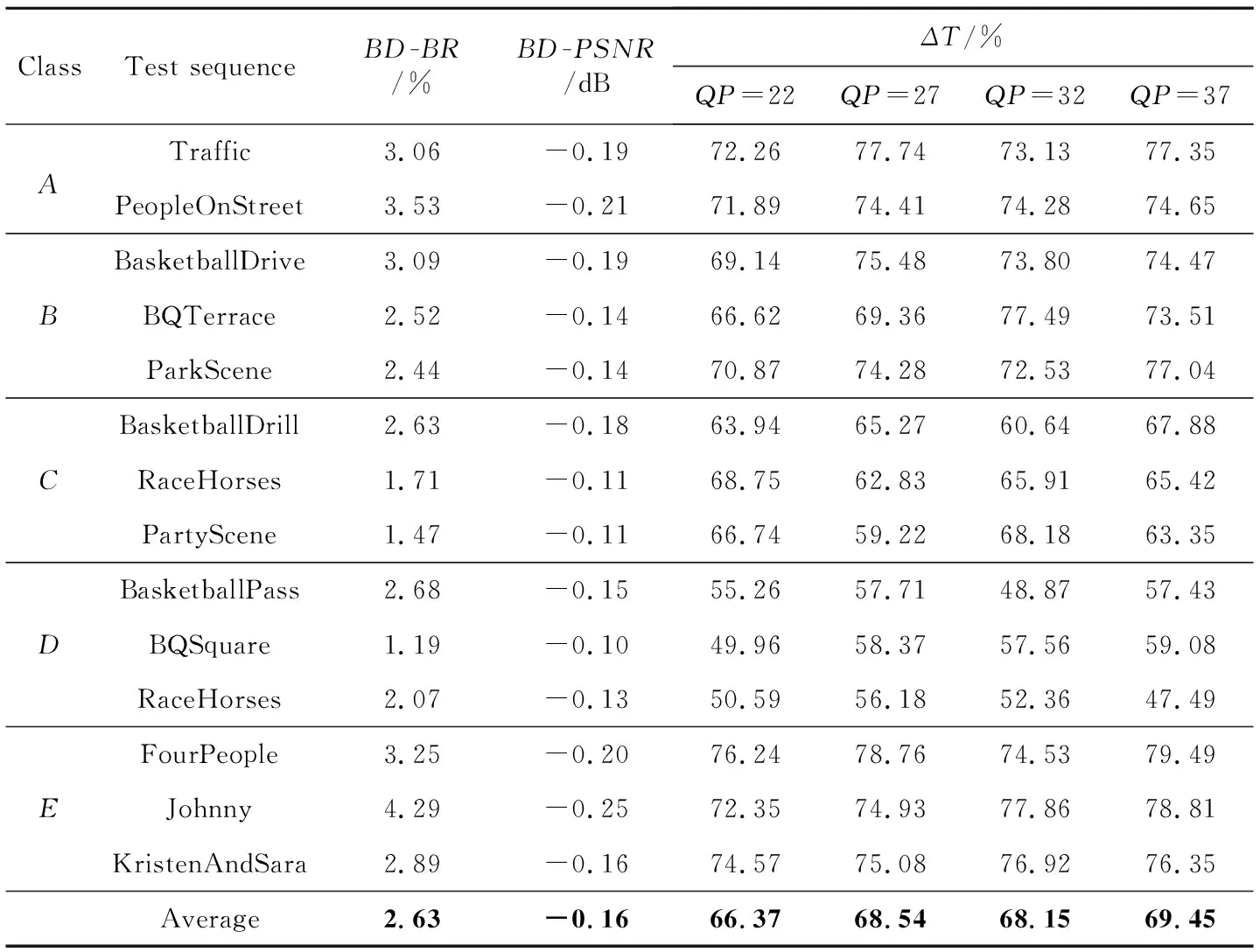
Table 2 Experimental results of UcuNet on JCT-VC testset
表5列出了本文設計和其他文獻中算法關于以上性能的比較,其中ΔTAve表示4種QP值下ΔT的平均值。整體上與之前工作相比,在通用測試條件下本文設計算法性能提高較為顯著,在編碼復雜度的降低程度上也表現更好,同時編碼質量也只有相對較小程度的降低。主要原因是UcuNet-E3可以通過CNN網絡提取CTU塊不同尺度的特征,從而一次性完整地預測各個類型的CU深度并進行編碼,減少了CU劃分過程中大量的冗余計算。由此可以看出,本文算法可以將編碼損耗控制在可接受范圍,更適合分辨率較高、實時傳輸方面的應用場景。

Table 5 Performance comparison of UcuNet and other algorithms表5 UcuNet和其他算法性能比較
4 結束語
本文提出了多尺度特征融合的UcuNet網絡模型用于CU劃分的高效預測,跳過了原始HEVC幀內編碼中大量的冗余計算。整體結構以亮度塊像素為基準,通過分層提取并拼接融合不同尺度CTU亮度塊的特征,并利用了非對稱卷積AC和CBAM注意力機制減少網絡的參數量,同時提高了特征提取能力。模型利用了38個視頻序列中的CTU和對應的編碼信息作為樣本進行訓練。本文將此設計嵌入到HEVC官方測試模型HM16.20中進行實驗。實驗結果表明,本文設計用可接受范圍內的編碼性能損失為代價,縮短了68.13%的編碼時間。目前本文設計的深度學習模型僅限于應用在幀內編碼當中的CTU分區,未來的工作可以擴展到幀內和幀間編碼部分中的PU(Prediction Unit)和TU(Transform Unit)分割預測,實現RD性能下降在可接受范圍內,同時進一步降低HEVC的復雜度。另外,此設計還可以擴展到H.266/VCC中,但VCC中的分區過程比HEVC的更為復雜,未來需要開展更多相關的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
