一種基于自適應結構感知池化圖匹配的圖相似度計算模型
2023-11-17 13:15:26李曉楠李冠宇
計算機工程與科學 2023年11期
關鍵詞:模型
賈 康,李曉楠,李冠宇
(大連海事大學信息科學技術學院,遼寧 大連 116000)
1 引言
圖因為其獨一無二的表達能力在社交網絡、知識圖譜和推薦系統等領域的數據建模中受到了極大的關注。因此,很多圖分析技術被開發,用于學習和提取圖中有價值的數據。其中,最有挑戰的問題之一是計算2個圖之間的相似度。圖的相似度學習已經在許多實際應用中得到了研究,如化學信息學中的分子圖分類、用于疾病預測的蛋白質-蛋白質相互作用網絡分析以及計算機安全中的二值函數相似度搜索等。為了解決這一問題,許多關于圖相似的方法被提出,例如圖編輯距離[1]、最大公共子圖[2,3]和圖同構[4,5]等。然而這些度量的計算都是NP-hard(Non-deterministic Polynominal-hard)問題,因此很難擴展到超過16個節點的大型圖中去。此外,傳統的方法沒有考慮到豐富的節點特征信息,丟失了一些潛在的語義相似性。
隨著深度學習技術的出現,圖神經網絡已經成為學習不同結構圖表示的一個強大的新工具,包括節點分類[6,7]、圖分類[8]和圖生成[9]等。然而,利用圖神經網絡學習2個圖之間相似度得分的研究較少。要了解2個輸入圖之間的相似度,一種簡單而直接的方法是:首先通過圖神經網絡將每個圖編碼為圖級嵌入的向量,然后將2個輸入圖的2個向量表示結合起來進行決策。這種方法探索了包含2個輸入圖重要信息的圖級交互特性,可用于圖相似度學習。
當前的圖神經網絡缺乏以分層方式聚合節點信息的能力。這種架構依賴于通過圖神經網絡學習到的節點表示,然后聚合節點信息來生成圖表示[10-12]。但是,以分層的方式學習圖表示對于捕獲圖中的局部子結構是很重要的。例如,在一個有機分子中,一組原子在一起可以作為一個官能團,在決定圖的類別方面起著至關重要的作用。為了解決這一問題,研究人員新提出的池化架構DiffPool(Differentiable graph Pooling)[13],作為一個可微池操作符,學習將每個節點映射到一組集群的軟分配矩陣,但這個分配矩陣是密集的,不容易擴展到大型圖[14]。TopK[15]學習了每個節點的標量投影分數,并選擇排名前k的節點。它們解決了DiffPool的稀疏性問題,但不能有效地捕獲豐富的圖結構。SAGPool(Self-Attention Graph Pooling)[16]提出了一種基于TopK的架構,利用自我注意力網絡學習節點分數。雖然局部圖結構用于評分節點,但它仍然不能有效地用于確定池化圖的連通性。本文自適應結構感知池化[17]在保持稀疏性的同時能有效捕獲豐富的圖結構。
最近,SimGNN(Similarity computation via Graph Neural Network)[18]嘗試通過直方圖信息考慮低級節點-節點交互,同時使用神經張量網絡NTN(Neural Tensor Network)關聯了2個輸入圖的圖級嵌入。GraphSim(Graph Similarity matrix generation)[19]通過構建節點相似矩陣,避免圖級嵌入的產生。GMN(Graph Matching Networks)[20]通過合并另一個圖的隱式注意鄰居來改進一個圖的節點嵌入。本文的結點-圖匹配網絡[21]通過比較一個圖的上下文節點嵌入和另一個圖的注意力圖級嵌入,能夠有效地學習更豐富的輸入圖對之間的跨層交互,集成輸入圖對之間交互的多級粒度,以端到端方式計算圖的相似度。
本文的主要工作如下:
(1)利用一種自適應結構感知池化方法[17],通過學習對每一層的節點進行稀疏軟集群分配,從而有效地池化子圖,形成池化圖。該模型利用池化圖來捕獲不同級別子圖之間的細粒度相關性,而不是在普通圖中進行節點比較。
(2)利用一種新穎的圖匹配網絡[21]學習圖相似度。該網絡有效地學習一個圖的每個節點與另一整個圖之間的跨層交互以提取圖間相似度。
(3)在4個數據集上進行了綜合實驗,驗證模型的有效性和優越性。實驗結果表明,所提出的模型性能比所知的最先進的基線模型的更好。
2 相關工作
2.1 圖神經網絡
目前,研究人員已經提出了光譜法和非光譜法2種不同的GNN(Graph Neural Network)公式。光譜方法的原理是用傅里葉變換和圖形拉普拉斯算子定義卷積運算,但不能直接推廣到不同結構的圖[22]。非光譜方法通過圖中節點周圍的局部鄰域定義卷積,比光譜法速度快,而且易于推廣到其他圖形。GNN也可以被視為消息傳遞算法,節點通過邊迭代聚合來自相鄰節點的消息[23]。GCN(Graph Convolutional Network)[6]將切比雪夫多項式進一步簡化為一階,從而實現高效的逐層傳播。對于空間方法,圖卷積是通過聚集其空間鄰域節點來表示的。例如,GraphSAGE(Graph Sample and AggreGatE)[24]是一個歸納框架,對來自其本地鄰域的表示進行采樣聚合;GAT(Graph ATtention networks)[25]引入注意力機制自適應聚合節點的鄰域表示。
2.2 圖池化
池化層克服了GNN無法按層次結構聚合節點的缺點。GNN中的圖池化機制[13,26]旨在將圖轉換為粗化圖,并捕獲其層次圖表示。DiffPool[13]利用圖神經網絡將節點軟聚為一組。TopK基于一個可學習的投影向量對節點進行評分,并對得分較高的節點進行抽樣。它避免了節點聚合和計算軟分配矩陣,能保持圖操作的稀疏性。圖U-Nets[15]和SAGPool[16]保留最重要的top-K節點,并在圖中進行節點采樣。由于TopK和SAGPool不進行節點聚合,也不計算軟邊權值,因此不能有效地保留節點和邊緣信息。為了解決這些局限性,本文利用了自適應結構感知池化ASAP(Adaptive Structure Aware Pooling)[17]。ASAP具有層次池的所有可取特性,同時不影響圖操作的稀疏性。
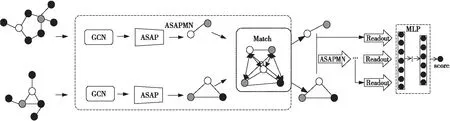
Figure 1 Overall framework of ASAPMN圖1 ASAPMN的總體架構
2.3 圖相似度學習
圖相似度學習的目標是學習一個度量2個圖對象之間相似度的函數。傳統的圖編輯距離GED(Graph Edit Distance)和最大公共子圖MCS(Maximum Common Subgraph)通常具有指數級的時間復雜度,無法擴展到較大的圖。最近,GNN被引入用于執行圖相似度學習。SimGNN[18]利用直方圖特征和神經張量網絡[27]分別對節點級和圖級交互進行建模。GraphSim[19]通過合并卷積神經網絡來擴展SimGNN,以捕獲復雜的節點級交互。GMN[20]提出不僅在每個圖中傳播節點表示,還在其他圖的注意鄰居之間傳播節點表示。本文利用圖池化結構的優勢來進行池化圖圖匹配,而不是專注于節點間的比較。這一點在使用GNN進行圖相似度學習的場景中很少被研究。
3 模型介紹
3.1 符號與公式

3.2 總體框架
圖1為本文ASAPMN(Adaptive Structure Aware Pooling graph Matching Network)的總體架構。ASAPMN由3個主要部分組成:(1)圖卷積。學習節點表示;(2)
圖池化。利用ASAP模型有效地池化子圖,形成池化圖;(3)子圖匹配。學習2個子圖之間的跨層交互,提取圖間相似度。3個部分共同組成模型ASAPMN來獲得圖在一個層級上的表示。本文需要保留3個層級上的表示,一個圖向量需要經過3次ASAPMN模型計算才能得到最后的圖級表示。然后,本文設計了一個注意力讀出函數來匯總每個圖在不同層級上的表示,最終的圖級表示是2個圖的不同層級表示的串聯。最后,將級聯的圖級表示輸入到多層感知器MLP(MultiLayer Perceptron)中,以執行圖-圖分類和圖-圖回歸任務。下文將詳細介紹不同組件。
3.3 圖卷積網絡
本文使用圖卷積網絡(GCN)[6]來提取特征。GCN定義如式(1)所示:
(1)

3.4 圖池化
首先圖中的每個節點vi視為聚類ch(vi)集合的中間體,使得每個聚類只能代表h跳固定半徑內的局部鄰居集合,即ch(vi)=Nh(vi)。給定一個聚類ch(vi),通過自注意力機制學習聚類分配矩陣S,通過關注集群中的相關節點來學習聚類ch(vi)的整體表示。T2T(Token2Token)[27]和S2T(Source2Token)[28]注意力機制不能利用任何集群內信息。因此,本文利用了一種新的自注意力變體M2T(Master2Token)[17]。在M2T框架中,首先創建一個主查詢向量mi∈Rd代表聚類中所有節點:
mi=fm(x′j|vj∈ch(vi))
(2)
其中,x′j為節點特征向量xj通過一個單獨的GCN在聚類ch(vi)捕捉到的結構信息;fm(·)是一個主函數,它結合并轉換vj的特征表示x′j找到mi,mi用附加注意力關注所有組成節點vj∈ch(vi),具體定義如式(3)所示:
(3)
聚類ch(vi)中vj的權重α(i,j)計算如式(4)所示:
α(i,j)=softmax(wTσ(Wmi‖x′j))
(4)
其中,wT和W分別是可學習的向量和矩陣。
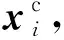
(5)

(6)
其中,W1,W2,W3為可學習的矩陣,N(vi)表示節點vi的鄰居節點集合。
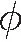
(7)

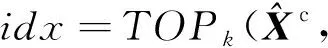
(8)
(9)
本文對聚類進行采樣后,通過式(10)找到池化圖Gp的新鄰接矩陣Ap:
(10)
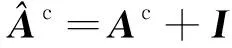
3.5 子圖匹配層
這一層通過比較一個子圖的每個上下文節點嵌入與另一個子圖的整個圖級嵌入,以及定義的多視角匹配函數,有效地學習一個圖的每個節點與另一整個圖之間的跨層交互,以提取圖間相似度。這一層通常有2個步驟:(1)計算圖的圖級嵌入向量;(2)將一個圖的節點嵌入與另一個完整圖的相關圖級嵌入向量進行比較,然后生成相似度特征向量。本文首先計算G1子圖中的節點vi∈V1和G2子圖中的所有節點vj∈V2之間的交叉圖注意力權重αi,j。同理,計算G2子圖中節點vj∈V2和G1中所有節點vi∈V1之間的交叉圖注意力權重βj,i。具體來說,這2個交叉圖注意力系數可以用注意力函數fs(·)獨立計算,如式(11)所示:
(11)

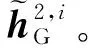
(12)

(13)
3.6 注意力聚合層和輸出層
為了進一步聚合子圖匹配層的交叉圖交互信息,本文設計了一個注意力讀出函數來生成全局圖級表示。由于不同的節點通常在圖中表現出不同的重要性,本文利用一個簡單的注意力機制可以得出rk,如式(14)所示:
(14)
其中,σ(·)是sigmoid函數,Watt表示可訓練注意力權重矩陣,hn表示節點級別向量,rk表示圖級向量,k表示網絡層數。
然后,將不同級別的輸出連接起來,形成最終的匹配表示,如式(15)所示:
(15)

最后,將帶有sigmoid激活函數的多層感知機用于執行圖分類任務和圖回歸任務,如式(16)所示:
(16)

4 實驗和結果分析
4.1 數據集
本文在4個數據集上評估模型。表1總結了數據集的統計數據,其中,#of graphs表示數據集中包含的圖的數量,#of function表示數據集的函數個數,Avg #of nodes 表示數據集的平均節點數,Avg #of edges 表示數據集的平均連邊數,Initial feature dimensions表示數據集的初始特征維度。FFmpeg和OpenSSL[21,29]被用于圖形分類任務,這2個數據集由2個流行的開源軟件FFmpeg和OpenSSL 生成。實驗在不同的設置下編譯源代碼函數,例如不同的編譯器(例如gcc或clang)和不同的優化級別可以生成多個二元函數圖。因此,將從相同源代碼編譯的2個二進制函數視為語義相似的函數,即S(G1,G2)=+1;而不同的二進制函數對是從不同源代碼編譯的圖,即S(G1,G2)=-1。這樣,將二元函數之間的圖相似度學習問題轉化為圖分類任務。此外,根據圖對的大小范圍將每個數據集分成3個子集(即[3,200],[20,200]和[50,200])來研究圖大小的影響。
在圖回歸任務中使用AIDS700和LINUX1000這2個數據集,其中每個圖分別代表一種化合物或程序函數。每個數據集包含每對圖形之間的圖編輯距離(GED)分數。對于AIDS700和LINUX1000,A*算法用于計算精確的GED。為了進一步將GED轉換為相似度值,本文使用文獻[25]中的方法將其標準化為(0,1]的數。圖回歸任務的目標是學習任何2個圖之間的GED。

Table 1 Information of dataset 表1 數據集信息
4.2 基線模型和實驗設置
4.2.1 基線模型
為了評估本文模型的有效性,本文考慮了4種最先進的基線模型進行比較,如下所示:
(1)SimGNN[18]:采用多層GCN,并采用2種策略來計算2個圖之間的GED,一種使用神經張量網絡來捕捉圖與圖之間的交互,另一種使用從2組節點嵌入中提取的直方圖特征;
(2)GMN[20]:采用了消息傳遞神經網絡的一種變體,并通過合并另一個圖的關注鄰域信息來改進一個圖的節點嵌入;
(3)GraphSim[19]:首先將2組節點嵌入轉化為相似矩陣,然后用CNN處理矩陣,擴展了SimGNN;
(4)MGMN(Multilevel Graph Matching Networks)[21]:由一個節點圖匹配網絡和一個孿生圖神經網絡組成,有效地學習一個圖的每個節點與另一整個圖之間的跨層交互,以及一個連體圖神經網絡用于學習2個輸入圖之間的全局級交互。
4.2.2 實驗和參數設置
本文將每個數據集隨機分成3個不相交的子集,分別占比80%,10%和10%,用于在圖分類任務中進行訓練、驗證和測試。對于圖回歸任務,本文使用文獻[18]中的拆分,即分別將60%,20%和20%的圖對分別用作訓練集、驗證集和測試集。為了公平比較,本文使用MGMN作者發布的源代碼,并在每個基線模型的驗證集上調整他們的超參數。本文將所有數據的節點表示維度設置為100,提出的模型用PyTorch Geometric實現,用Adam optimizer優化模型參數。本文在{0.1,0.01,1e-3,1e-4,1e-5}范圍內研究學習率和權值衰減,池化率r∈[0.1,1.0],神經網絡層數L∈[1,5]。MLP由3個完全連接的層組成,每層的神經元設置為200,100和50。本文在一臺具有128 GB RAM和NVIDIA?GeForce?RTXTM3090 GPU的Windows機器上完成實驗。在訓練過程中,本文使用早期停止標準進行模型優化,即:如果驗證損失在100個連續時間段內沒有減少,將停止訓練。
4.2.3 評估指標
為了評估和比較 ASAPMN的性能,本文使用了以下指標評估:
(1)均方誤差MSE(Mean Square Error):用于計算式(16)中定義的預測分數與真實值之間的損失。
(2)Spearman的排名相關系數(ρ)[30]和 Kendall 的排名相關系數(τ)[31]:用于衡量預測排名結果與真實排名結果的匹配程度。這2個系數越大表示預測數據和真實數據越接近,效果越好。p@10表示返回前10個結果的精確度,p@20表示返回前20個結果的精確度。
(3)AUC(Area Under the receiver operating Characteriic)[32]和ROC(Receiver Operating Characteristic):ROC曲線用來衡量當分類閾值變化時,分類器系統的判別能力。ROC曲線對樣本是否平衡不敏感,適用于樣本類別不均衡時對分類器性能的評價。AUC指的是ROC曲線下的面積,取值一般在 0.5到1之間。分類器的AUC是指將隨機選擇的正例排在隨機選擇的負例前面的概率。
以上5個評估指標中,均方誤差MSE越小越好,相關系數(ρ和τ)、p@10、p@20和AUC越大越好。
4.3 圖分類任務
對于圖形分類任務,本文重復實驗5次,取ROC曲線(AUC)下面積的平均值和標準差,例如0.982±0.040中0.982表示平均值,0.040表示標準差。實驗結果如表2所示。

Table 2 AUC scores of graph-graph classification 表2 圖-圖分類任務的AUC值
首先,本文提出的ASAPMN在所有設置下在2個數據集上獲得的性能都最好。與原始解決方案MGMN和經典模型SimGNN、GMN和GraphSim相比,ASAPMN在FFmpeg和OpenSSL數據集的所有6個子數據集上都明顯達到了最先進的性能。這表明此前用于圖相似度學習的全局圖級交互不能很好地捕捉底層圖的語義相似性,因此有必要對輸入圖對之間的細粒度低級交互進行建模。ASAPMN優于具有不同的節點級比較方法,將性能提升歸因于子圖匹配機制的優勢。與整個圖的節點匹配不同,池化操作保留了關鍵子圖的子集,然后在整個圖中進行匹配,其中子圖通常包含豐富的局部子結構信息,對于圖的語義相似度學習非常重要。特別是,當圖的大小增加時,基線模型的性能降低。然而,與最先進的基線模型相比,本文提出的模型仍然實現了相對更好和更魯棒的性能。
4.4 圖回歸任務
對于計算2個輸入圖之間的相似度得分GED的圖-圖回歸任務,本文統計了MSE、ρ、τ和p@k這些指標值。圖回歸性能如表3所示。本文還在圖回歸任務中將所提ASAPMN與最先進的基線模型進行比較。從表3可以看出,盡管GraphSim在LINUX1000數據集上τ有更好的性能,MGMN在AIDS700數據集上ρ和τ有更好的性能,但ASAPMN在AIDS700和LINUX1000數據集上的大多數評估指標值都優于基線模型的。ASAPMN由于其精心設計的池化機制和池化圖上的子圖匹配機制,獲取了更好的性能。
4.5 消融實驗
4.5.1 僅考慮池化方法
本文對不使用圖匹配網絡的原池化機制ASAP和本文的模型做了對比,如表4所示。可以看出,僅考慮池化機制的ASAP在2個數據集上無法獲得令人滿意的性能,實驗性能大幅下降,說明加入圖匹配網絡可以學習到更多有效的信息。

Table 4 Graph-graph regression results of ASAPMN and ASAP表4 ASAPMN和ASAP圖回歸任務結果
4.5.2 考慮不同的池化方法
為了研究不同池化方法的影響,本文選擇了幾種廣泛使用的圖池化模型進行對比實驗:DiffPool[13]、TopK[15]、SAGPool[16]和AttPool[33]。如表5所示,DiffPool[13]和ASAP[17]基于節點聚類的池化機制效果好于TopK[15]、SAGPool[16]和AttPool基于節點選擇的池化機制的。ASAP[17]通過節點聚類、稀疏性問題的解決以及對注意力機制的改進可以更好地捕捉到圖的層級信息,與分層級的圖匹配機制結合得到了更好的結果。

Table 3 Graph-graph regression results 表3 圖-圖回歸任務結果
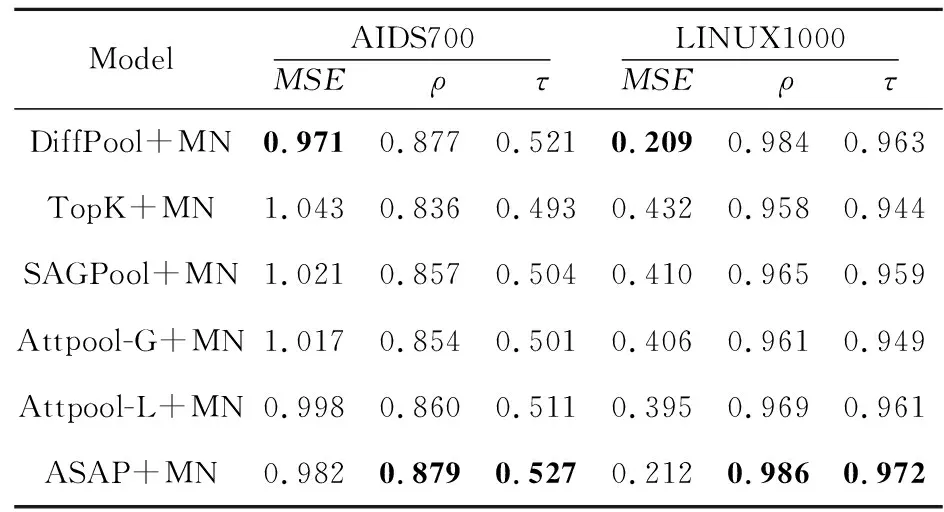
Table 5 Graph-graph regression results when using different pooling methods表5 使用不同池化方法的圖回歸任務結果
4.5.3 超參數分析
本節測試了2個關鍵的超參數對OpenSSL子集的影響。特別地,研究了圖池化率r和池化層數L對圖的分類結果的影響情況。如圖2和圖3所示,當設置r=0.8和L=3時,ASAPMN可以在所有數據集上獲得最佳性能。當不使用池機制時,r=1.0時,性能也會下降。

Figure 2 Sensitivity analysis of pooling ratio r圖2 圖池化率r敏感性分析

Figure 3 Sensitivity analysis of number of layers L of graph convolutional neural network圖3 圖卷積神經網絡層數L敏感性分析
5 結束語
本文研究了圖分類和圖回歸任務中的圖相似度學習問題,該問題需要模型對一對輸入圖進行聯合推理。本文提出了一個新的框架ASAPMN,將圖池化后再進行子圖匹配。在ASAPMN中,先利用ASAP模型執行池化操作,再利用節點-圖匹配網絡有效地學習一個圖的每個節點與另一整個圖之間的跨層交互以提取圖間相似度。通過這樣一個過程,可以以端到端的方式評估任意結構圖對的相似性。在4個常用數據集上的實驗結果表明,與一系列最先進的基線模型相比,它是有效的。之后還將考慮如何應用 ASAPMN解決相關的圖相似性挑戰,例如蛋白質分子查找、程序流程圖的安全性等。對于這些實際應用,圖結構的相似性研究至關重要。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
