融合標簽信息的分層圖注意力網絡文本分類模型
2023-11-17 13:15:28楊春霞馬文文
計算機工程與科學 2023年11期
楊春霞,馬文文,徐 奔,韓 煜
(1.南京信息工程大學自動化學院,江蘇 南京210044;2.江蘇省大數據分析技術重點實驗室,江蘇 南京 210044)
1 引言
作為自然語言處理文本分類核心任務之一,單標簽文本分類SLTC(Single Label Text Classification)旨在準確預測文本信息的類別傾向,在情感分析、新聞檢測和垃圾郵件識別等多個場景均有廣泛應用。由于近年來推特、微博和博客帖子等在線內容量爆發式增長,大量未經規范的文本數據、與用戶交互的數據無疑增加了分類的難度。因此,為了更高效地分析、處理這些觸手可及的文本數據,需要進一步完善和提高分類技術的研究。
SLTC按照文本自身所含內容進行分類。例如,一篇新聞評論報道可歸屬為“娛樂”“飲食”或“軍事”等主題。分類準確的關鍵在于有效地挖掘文本特征信息。對于文本特征信息的提取,目前越來越多的研究人員[1-3]熱衷于使用圖神經網絡算法構建模型,提升文本分類精度。雖然目前基于圖神經網絡模型可以直接從文本的圖結構數據中有效挖掘其局部或全局信息,獲取文本主要特征信息,但是直接把文本作為長序列進行處理,不僅會降低模型性能,同時也會忽略文本層次結構中包含的信息。因此,Ding等人[4]在詞和句子2個層面,利用分層圖注意力網絡進行文本分類,取得了不錯的分類效果。然而,分層圖注意力網絡在訓練過程中通常隨機初始化一個參數向量作為所有類別的目標向量,不能較好地關注到具有明顯類別的詞,所以如何通過優化圖注意力網絡更好地對文本特征進行提取是目前亟待解決的一個問題。
除了對文本進行特征信息的提取,最近Xiao等人[5]在多標簽文本分類任務中將所有文本標注的標簽信息融入到文本信息中,也取得了不錯的效果。但是,現有的SLTC任務大多忽略了標簽信息在分類方面的作用,如何通過捕獲文本與標簽之間的聯系以進一步凸顯文本特征是現階段需要研究的一個難點。
針對以上2個問題,本文提出融合標簽信息的分層圖注意力HGAT-Label (Hierarchical Graph ATtention network integrating Label)網絡文本分類模型,主要工作如下:
(1)通過詞級圖注意力網絡獲取的句子向量表示是以原有隨機初始化的目標向量為基礎,同時利用最大池化提取句子特定的目標向量,使得獲取的句子向量具有更加明顯的類別特征。
(2)利用GloVe[6]模型對所有文本的標簽信息進行向量化處理,然后將所有文本的標簽表示與文本的特征表示進行交互,以獲取具有文本特征的標簽信息表示,最后將其與文本特征融合進一步凸顯文本特征表示。
(3)在5個公開英文數據集上進行實驗,并與HGAT-Label模型相關的其它主流基線模型作對比。實驗結果表明,本文提出的HGAT-Label模型明顯優于其它主流基線模型。
2 相關工作
如今大多數文本分類研究均是圍繞深度學習開展的,隨著深度學習技術的發展,基于圖神經網絡的研究方法已逐漸成為主流。

除了對文本信息進行提取,現有有關SLTC的研究很少會將所有文本標注的標簽信息與文本內容信息相結合。而在多標簽文本分類任務中,如覃杰[13]結合文本與標簽嵌入表示的相似度計算任務,進一步提高多標簽文本分類任務的實驗精度。You等人[14]通過構建淺而寬的概率標簽樹來解決大量標簽可擴展性問題,然后利用自注意力機制捕捉與標簽相關聯的文本特征信息,取得了不錯的分類效果;肖琳等人[15]通過標簽語義注意力機制捕獲具有文本語義聯系的標簽信息表示,從而提升了文本分類的效果。在以上多標簽分類任務中,均因標簽信息的融入使分類效果得到明顯提升,從而也進一步驗證了Zhang等人[16]所提出的標簽信息的融入可以有效提升模型分類性能的結論。受其啟發,本文嘗試在SLTC任務中將所有文本標注的標簽信息與文本特征信息進行交互、融合,以提升分類的準確率。
3 HGAT-Label模型實現
本文提出的HGAT-Label模型主要由詞(文本或標簽)嵌入層、鄰接矩陣構建層、雙重圖注意力層、池化層和文本特征增強層組成。模型總體框架如圖1所示。
(1)詞(文本或標簽)嵌入層:將輸入的文本、標簽數據樣本分別轉化為詞向量H∈RVmax×d和l∈RN×d,其中,Vmax表示同一批次樣本中文本句子包含的最多單詞數目,d表示詞向量維度。
(2)鄰接矩陣構建層:依據句子關鍵詞與主題關聯性構建鄰接矩陣A∈RVmax×Smax,其中Smax表示同一批次樣本中文本包含的最多句子數目。

(4)池化層:采用平均池化層對更新后的文本信息進行提取,以對所有特征信息進行綜合判斷。
(5)文本特征增強層:將池化層輸出的文本特征Tq與標簽矩陣l用于計算交互注意力,獲取具有文本語義特征聯系的標簽信息表示L;然后采用融合策略將標簽信息表示L與文本特征信息表示Tq相結合,從而獲得文本的分類特征表示T。

Figure 1 Framework of HGAT-Label model圖1 HGAT-Label模型框架
3.1 任務定義
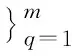
3.2 詞嵌入層
本文使用GloVe模型對樣本進行向量化,對于文本Cq,將其映射為向量矩陣H∈RVmax×d,即每個詞被映射為一個低維稠密向量。同理,標簽信息則由詞嵌入矩陣l∈RN×d表示。根據GloVe的共現特性,初始化后的文本與標簽表示仍具備一定的語義信息。
3.3 鄰接矩陣構建層
為了捕捉文本的序列、結構與語義信息,需要對不規則的文本數據進行建模。本文首先以文本中每個句子Sj作為邊,然后將句子中包含的單詞(節點)按原有句法結構一一連接起來,這樣就可以保留原有文本的序列信息和結構信息。為了進一步捕捉其語義信息,本文利用隱含狄利克雷分布[17]挖掘每個文本潛在的主題并將其作為邊,而在每一句話中,與主題相關程度較大的詞作為主題(邊)連接的節點,這樣既能捕獲文本的序列信息和結構信息,又可以獲取文本上下文語義信息。基于上述原理,定義圖G=(V,E),其中,V={v1,v2,…,vi-1,vi,…,vVmax}是詞節點集合,E={e1,e2,…,ej-1,ej,…,eSmax}是與詞節點相連的主題邊集合。因此,本文由圖G的拓撲結構所構成的鄰接矩陣A∈RVmax×Smax的表示如式(1)所示:
(1)
其中,Aij=0時表示句子中的詞節點與主題邊不相關,Aij=1時則表示兩者相關聯。
3.4 雙重圖注意力層
雙重圖注意力層由詞級GAT和句子級GAT組成,其中GAT是將注意力機制引入到空間域的圖神經網絡,僅需要通過圖上一階鄰居的表征信息來更新節點特征。
3.4.1 詞級圖注意力層
由于從句子中提取的關鍵詞信息對分類目標的貢獻程度不一樣,因此在詞級圖注意力層,本文利用圖注意力機制為句子中的關鍵詞計算注意力得分,然后通過帶有權重的關鍵詞信息生成句子的向量表示。
首先,隨機初始化一個目標向量uw,在訓練的過程中通過不斷學習來找出哪些關鍵詞對于分類任務更為重要。特別地,在詞級圖注意力層,除了使用目標向量uw之外,本文還通過最大池化提取句子Sj的主要特征,作為其特有的目標向量u′wj。計算過程如式(2)和式(3)所示:
(2)
(3)

得到2個目標向量uw和u′wj后,緊接著通過圖2所示的深度架構網絡GAT分別計算關鍵詞節點和2個目標向量的相似度并歸一化,得到針對2個目標向量的注意力得分,具體計算過程如式(4)~式(6)所示:
(4)
(5)
(6)


Figure 2 GAT model圖2 GAT模型
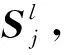
(7)
其中,θ1j和θ2j分別表示第k個關鍵詞通過2種方式獲取的注意力分數αjk與α′jk對構成句子j的最終表示的重要程度,σ(·)表示ReLU函數。
3.4.2 句子級注意力層
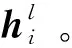
(8)
(9)
(10)

3.5 池化層
在獲取新文本表示后,為了一方面考慮文本的全局信息,另一方面減少重要特征的遺漏,本文采用平均池化層對更新后的文本信息進行提取,以對所有特征信息進行綜合判斷。計算方法如式(1)所示:
(11)
其中,Tq表示第q個文本主要特征表示,f(·)表示平均池化函數。
3.6 標簽文本交互融合層
交互注意力機制的實質是通過對2個句子關聯的相似特征進行提取,從而捕獲對應句子內部重要的語義信息。因此,本文將標簽信息表示與文本特征表示用于計算交互注意力,獲取具有文本語義特征聯系的標簽信息表示。
如圖3所示,首先取池化層輸出的文本特征Tq與標簽矩陣l的點乘結果為信息交互矩陣M,其中Mqn表示第q個文本特征信息與第n個標簽信息的相關性。然后分別對M的行、列進行softmax歸一化處理,獲取文本特征信息對標簽信息和標簽信息對文本特征信息的注意力分數αqn和βqn。計算過程如式(12)~式(14)所示:
M=Tq⊙l
(12)
(13)
(14)
其中,⊙表示點乘運算,αqn和βqn分別表示第q個文本特征信息對第n個標簽信息的注意力權重和第n個標簽信息對第q個文本特征信息的注意力權重。

Figure 3 Interactive attention model圖3 交互注意力模型

(15)
(16)
L=γ⊙l
(17)
為了進一步凸顯文本主要特征的表示,本文采用融合策略將標簽信息L與文本特征信息Tq相結合,從而獲得文本的分類特征T,如式(18)所示:
T=Tq⊕L
(18)
3.7 模型訓練
模型最后通過softmax函數對T進行標簽預測:
(19)

本文使用交叉熵損失函數對模型進行訓練,如式(20)所示:
(20)
4 實驗
4.1 實驗環境
本文實驗基于PyTorch深度學習框架,具體實驗環境如表1所示。
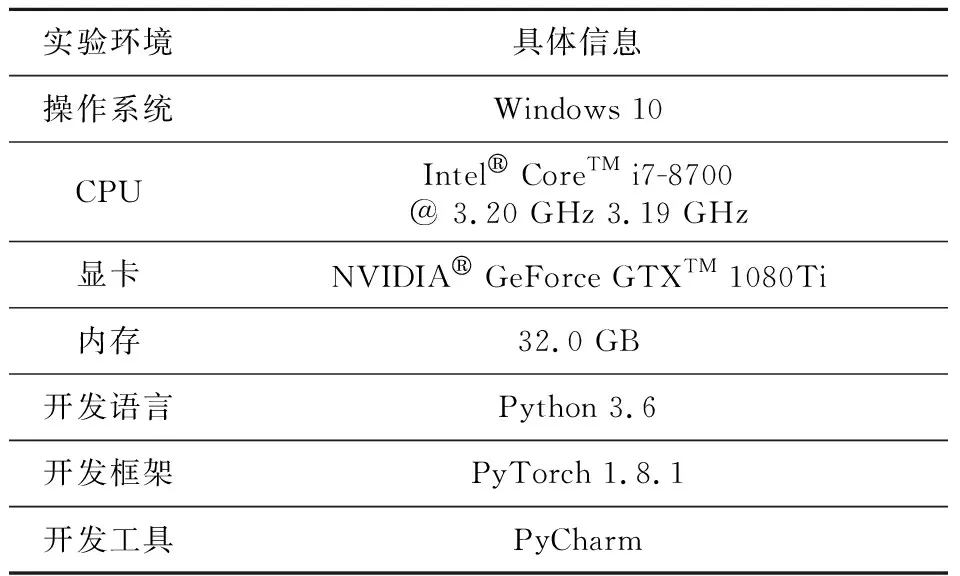
Table 1 Experimental environment表1 實驗環境
4.2 實驗數據
本文選用R8、R52、20NG、Ohsumed與MR 5個公開數據集進行模型性能評估,5個數據集的具體情況如表2所示。

Table 2 Information of five datasets表2 5個數據集信息
(1)R8與R52:由路透社新聞專線文件組成,分別包括8類和52類。
(2)20NG(20NewsGroups):由20個英文新聞組所組成,該數據集文本相似度高,分類難度大。
(3)Ohsumed:來源于醫學文獻庫MEDLINE,每篇醫學摘要包含23類心血管疾病中的1類或者2類。
(4)MR:由5 331個正面電影評論和5 331個負面電影評論所組成,其中每條評論僅包含1個句子[18],每個句子分別用1(正面)或0(負面)進行標注,適用于二元情感分類任務。
4.3 實驗參數與評估指標
本文使用Adam優化器進行參數優化,使用2層雙重GAT對文本特征進行提取,2層GAT嵌入維度分別為300和100,使用Dropout來防止過擬合。具體參數設置如表3所示。
為了驗證HGAT-Label模型的優越性,本文使用準確率Acc(Accuracy)作為評估指標,計算方法如式(21)所示:
(21)

Table 3 Experimental parameters setting表3 實驗參數設置
其中,TP為被正確分類的正樣本數目;FP為被錯誤分類的負樣本數目;TN為被正確分類的負樣本數目;FN為被錯誤分類的正樣本數目。通常,Acc值越大,分類效果越好。
4.4 對比模型
為驗證本文模型在SLTC任務上的分類性能,在同樣實驗環境中將其與以下8個主流基線模型進行對比實驗:
(1)SWEM(Simple Word-Embedding-based Model)[19]:采用詞嵌入(Word Embedding)+池化(Pooling)的方式對文本信息進行建模分類。
(2)LEAM(Label-Embedding Attentive Model)[20]:該模型將文本與標簽信息聯合嵌入到同一空間,然后利用文本與標簽的相關性構建文本特征表示。
(3)LSTM(Long Short-Term Memory)[21]:在多任務目標學習中,設計了3種基于LSTM信息的共享機制來提高相關文本分類任務的性能。
(4)BiLSTM(Bidirectional LSTM)[22]:利用BiLSTM具有記憶上下文語義信息和條件隨機場(CRF)可以映射句子間不同標簽關系的特點,將BiLSTM輸出的語義特征信息直接輸入到CRF層,使模型可以根據前后單詞的標簽信息有效預測當前詞的標簽信息。
(5)TextGCN(Graph Convolutional Network for Text classification)[10]:首先依據詞與詞和詞與文檔的關聯性構建文本異構圖,然后使用2層GCN提取其特征信息。
(6)Graph-CNN(Convolutional Neural Network on Graphs)[23]:基于譜圖的CNN算法,將低維規則化數據轉化成高維不規則圖結構數據,并利用CNN提取其局部組成特征。
(7)Text-level GNN(Text level Graph Neural Network)[24]:改變TextGCN的構圖方式,以每個輸入文本為單位進行構圖,然后通過圖的消息傳播機制將單詞節點表示以及節點與節點之間的權重信息進行更新,從而提高模型在新文本數據上的分類預測能力。
(8)HyperGAT(Hierarchical Graph ATtention network)[4]:使用分層GAT對文本特征信息進行提取。
4.5 對比實驗與結果分析
在5個公開數據集上,本文提出的HGAT-Label模型與8個主流基線模型的實驗結果如表4所示。
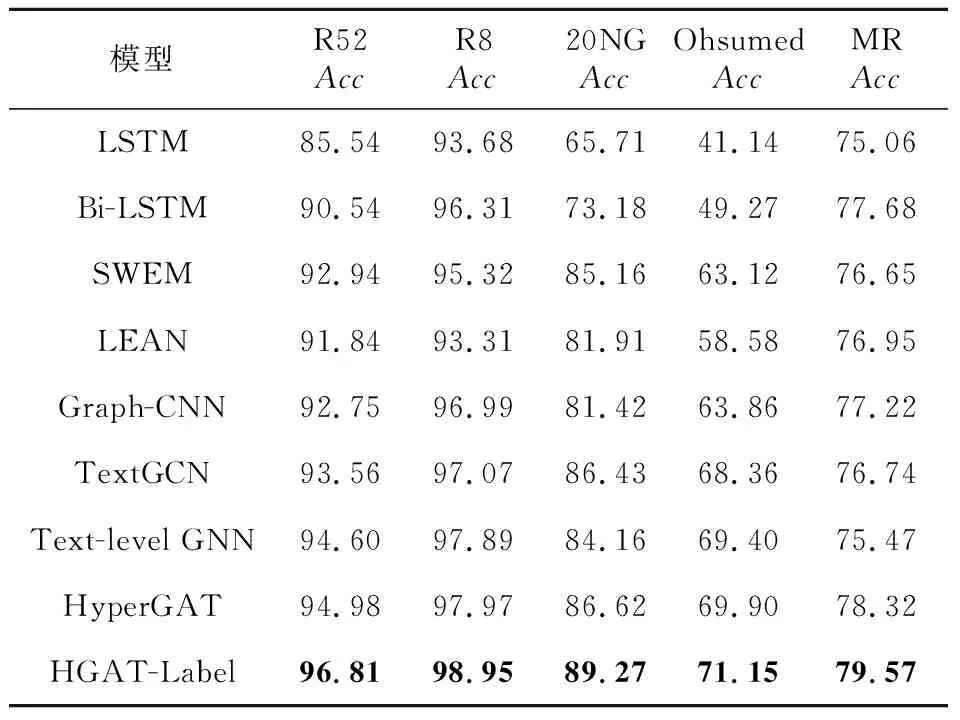
Table 4 Experimental results of different models表4 不同模型的實驗結果 %
從表4可以看出,HGAT-Label模型相較最好的基線模型HyperGAT準確率分別提高了1.83%,0.98%,2.65%,1.25%和1.25%,驗證了HGAT-Label模型分類性能的優越性。
在基線模型中,LSTM與BiLSTM在5個數據集上的整體效果最差,原因在于這2個模型僅對文本連續詞序列信息進行提取,缺乏全局信息之間的關聯性。BiLSTM是從正反2個方向對文本信息進行提取,比從單向提取信息的LSTM模型分類效果更好。與上述2個模型相比,SWEM與LEAN模型可以取得較好結果是因為二者使用的均是基于預訓練詞嵌入方法,預訓練詞嵌入方法是有利的文本表示方式,可以有效捕捉單詞的語義與語法信息。此外,SWEM模型以不同池化的方式獲取文本主要特征信息,而LEAN模型考慮文本特征信息的同時還利用注意力機制將文本標注的標簽信息與文本信息進行交互,用以捕捉文本主題信息,所以SWEM與LEAN模型更有益于文本特征的劃分。以上模型均是按時序類數據進行處理,對于非規則的文本數據而言,Graph-CNN、TextGCN、Text-level GCN和HyperGAT模型在分類任務處理中可以取得更好的效果,這是因為它們更擅長從非規則文本數據中捕捉長距離和非連續單詞的關聯性,實驗結果可以驗證這一點。但是,在MR數據集上,Graph-CNN、TextGCN和Text-level GCN模型的分類性能卻沒有得到很好的提升,再結合HyperGAT模型較好的分類效果,可以很容易看出,在情感分類任務上,利用圖注意力機制更有利于捕捉文本的情感特征;另外,融合序列或詞嵌入方法的圖神經網絡模型比直接在圖上進行卷積操作效果會更好。
本文的HGAT-Label模型之所以優于HyperGAT模型,一方面是因為本文的詞級圖注意力網絡結構是在原有的全局目標特征向量基礎上同時利用最大池化提取句子特定的目標向量,使得獲取的句子向量具有更加明顯的類別特征;另一方面是因為將所有文本標注的標簽信息與文本主要特征信息進行交互,用以獲取具有文本特征的標簽信息表示,然后將其與文本主要特征融合并進一步凸顯文本特表示,從而達到最優分類效果的目的。從整體上看,文本特征的優化與標簽信息的融入有著緊密的聯系,有效提取文本特征信息的同時也能很好地學習標簽信息的表示,當兩者融合時效果最佳,所以HGAT-Label模型是優越的。
4.6 HGAT-Label模型的有效性驗證
為了研究HGAT-Label模型的整體效果,本文分別去除目標向量模塊和標簽信息模塊進行消融實驗。其中w/o u表示在進行詞級圖注意力時,去除通過最大池化獲取的目標向量u′w模塊;w/o Label表示去除標簽信息模塊。本文以3個數據集(R52、R8和20NG)為例,研究各模型的分類性能。
由圖4和圖5可知,引入目標向量和融合標簽信息2種方式均可使得模型效果有所改善,而將兩者相結合的效果取得了進一步提升,說明本文的HGAT-Label模型在整體上是更有效的。因為標簽是文本的表現形式,文本是標簽的具體內容,兩者相互依存有著緊密連接關系,所以將兩者相結合更有利于文本特征的劃分。

Figure 4 Experimental results of target vector ablation圖4 目標向量消融實驗結果

Figure 5 Experimental results of label information ablation圖5 標簽信息消融實驗結果
分模塊來看,融合標簽信息后對文本的分類效果影響最大,準確率分別提升了1.28%,0.48%和2.03%。這是因為標簽信息與文本主要特征的交互可以有效學習標簽信息表示,然后通過與文本主要特征的融合降低了原有特征損失,凸顯文本的主要特征信息。此外,也進一步驗證了基線模型LEAN在融入標簽信息后明顯優于基于連續序列信息提取的LSTM與BiLSTM模型。引入目標向量后,準確率分別提高了0.66%,0.25%和1.17%。目標向量的引入,通過與原有隨機初始化目標向量的自適應融合可以更加突出不同句子的類別特征,從而優化了文本特征信息的表示。對于SLTC任務來說,文本的分類效果主要取決于是否很好地學習到了關鍵特征信息的向量表示,所以目標向量的引入有益于文本特征的劃分。以上對比與消融實驗,驗證了本文提出的HGAT-Label模型的優越性與有效性。
5 結束語
為了更好地對文本特征進行提取,以及如何通過文本與標簽之間的聯系進一步凸顯文本特征,本文提出融合標簽信息的分層圖注意力網絡模型來完成SLTC任務。本文一方面通過優化圖注意力網絡結構,使獲取的句子向量具有更加明顯的類別特征;另一方面利用GloVe模型對所有文本標注的標簽信息向量化,然后將其與文本的主要特征信息進行交互、融合以減少原有特征損失,更好地表示整個文本特征信息。通過對比實驗,驗證了本文所提模型的優越性,同時消融實驗也進一步驗證了引入目標向量和融入標簽信息的有效性與合理性,且兩者結合效果最佳。
目前,SLTC任務已經取得較好的分類效果,但是隨著文本內容日益豐富,對文本分類的要求也愈發提升。因此,下一階段將對豐富的文本信息進行更細粒度特征劃分,同時對模型算法進一步優化處理,提升訓練速度。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
