一種基于MLP的高效高精度三維視線估計方法
2023-11-17 13:15:26吳志豪張德軍吳亦奇陳壹林
計算機工程與科學 2023年11期
吳志豪,張德軍,吳亦奇,陳壹林
(1.中國地質大學(武漢)計算機學院,湖北 武漢 430078; 2.智能機器人湖北省重點實驗室(武漢工程大學),湖北 武漢 430205)
1 引言
視線是最重要的非言語交際線索之一,它包含豐富的人類意圖信息,使研究人員能夠深入了解人類的認知和行為,已被廣泛應用于醫療[1]、輔助駕駛[2]、市場營銷[3]和人機交互[4]等領域。高精度的視線估計方法對其應用至關重要。為此,研究人員針對視線估計展開了大量研究。根據不同的場景,視線估計方法分為3類:二維注視點估計[5]、注視目標估計[6]和三維視線估計[7-19]。二維注視點估計根據輸入的圖像估計出視線聚焦的落點。注視目標估計是要檢測出輸入人物的注視對象。三維視線估計方法是通過雙眼圖像或人臉圖像估計出三維視線方向。本文旨在設計一個高效高精度的三維視線估計方法。
三維視線估計方法主要分為基于幾何的方法和基于表觀的方法2大類。基于幾何的方法通過檢測眼睛的眼角、虹膜位置等關鍵點估算三維視線[7],然而這類方法對圖像分辨率要求較高。因此,基于表觀的方法受到研究人員更多的關注。基于表觀的方法直接學習一個將圖像表觀映射到三維視線的模型,在低分辨率和高噪聲的圖像上表現更好。
近年來,基于表觀的深度學習三維視線估計方法成為研究熱點。與傳統的基于表觀的三維視線估計方法[8-11]相比,基于表觀的深度學習三維視線估計方法顯示出了許多優勢:(1)它能夠從圖像中提取出高層次的抽象三維視線特征。(2)它能夠學習從眼睛表觀到三維視線的非線性映射函數。這些優點使得它比傳統方法更加健壯和精確。隨著卷積神經網絡CNN(Convolutional Neural Network)在計算機視覺領域的崛起,以及大量數據集的公開,研究人員開始將CNN用于基于表觀的三維視線估計方法[12-19]。由于CNN結構復雜、模型加載速度不夠快等原因,這類方法在實時性要求較高的場合還有待進一步改進。Tolstikhin等[20]提出的MLP-Mixer(MultiLayer Perceptron Mixer)給計算機視覺領域帶來了新的選擇。MLP-Mixer是一種僅基于多層感知機MLP(MultiLayer Perceptron)的深度學習模型,結構更為簡單、模型加載速度也快于CNN和Transformer模型的,但性能與CNN和Transformer模型的相當。
本文提出一種基于MLP的高效高精度的視線估計方法UM-Net(Using MLP Network)。UM-Net包括3條支路,利用MLP模型分別對人臉圖像、左眼圖像和右眼圖像進行特征提取,對得到的特征進行融合后回歸出三維視線。實驗結果表明,對MPIIFaceGaze數據集和EyeDiap數據集中包含的31位不同相貌的受試者使用UM-Net進行視線估計,其精度比肩基于CNN方法的,甚至在某些受試者上的精度表現更好,并且在視線估計的速度上具有明顯的優勢。
2 相關工作
2.1 基于表觀的三維視線估計
Zhang等[12]最早利用神經網絡來進行視線估計。他們提出用CNN對輸入的單眼圖像進行特征提取,然后將頭部姿態信息與提取出的眼睛特征進行拼接,回歸出相機坐標系下的三維視線。Cheng等[13]提出了一個基于雙眼圖像的非對稱回歸視線估計方法,主要思想是由于光照等原因2只眼睛的視線估計精度不同,因此網絡在訓練中對2只眼睛對應的損失函數賦予不同的權重。基于幾何的方法是通過檢測眼睛關鍵點特征信息來估計三維視線的。這啟發了研究人員使用額外的語義信息來提高視線估計的精度。Park等[14]提出了一種基于眼睛圖形表示的視線估計方法,通過神經網絡將眼睛抽象為一個由視線真實值幾何反推出的眼球圖形表示來提升視線估計精度。Yu等[15]提出了一種基于約束模型的視線估計方法,基于多任務學習的思想,即在估計視線的同時檢測眼睛關鍵點信息,2個任務同時進行訓練和信息交流,在一定程度上得到了共同提高。
上述視線估計方法都需要以單眼/雙眼圖像為輸入,這存在2個不足:需要額外的模塊檢測眼睛區域;需要額外的模塊估計頭部姿態信息。因此,Zhang等[16]提出了基于注意力機制的全臉視線估計方法,其主要思想是通過一條支路學習人臉區域各位置的權重,目標是增大雙眼區域的權重,抑制其他與視線無關區域的權重,網絡的輸入為人臉圖像并采用端到端的方式直接學習出相機坐標系下的三維視線。Zhu等[17]也提出了一個全臉視線估計的方法,與上述方法不同之處在于除人臉輸入外,該方法同時需要輸入眼睛圖像。Zhu等認為文獻[12]將視線特征與頭部姿態簡單拼接的方式并不能準確地反映兩者之間的幾何關系,因此該方法利用一個視線的幾何變換層將人臉支路學習到的頭部姿態信息與眼睛支路學習到的人臉坐標系下的視線進行幾何分析,得到最終相機坐標系下的三維視線。
為了進一步提高三維視線估計的準確性,Chen等[18]提出了空洞卷積網絡Dilated-Net,使用空洞卷積對人臉和雙眼進行特征提取,通過使用深度神經網絡從眼睛圖像中提取更高分辨率的特征來提高基于表觀的三維視線估計的準確性。Cheng等[19]為了減少與視線無關因素的干擾,提出了一個即插即用的自對抗框架實現視線特征的簡化,降低光照、個人外貌甚至面部表情對視線估計的學習的影響。
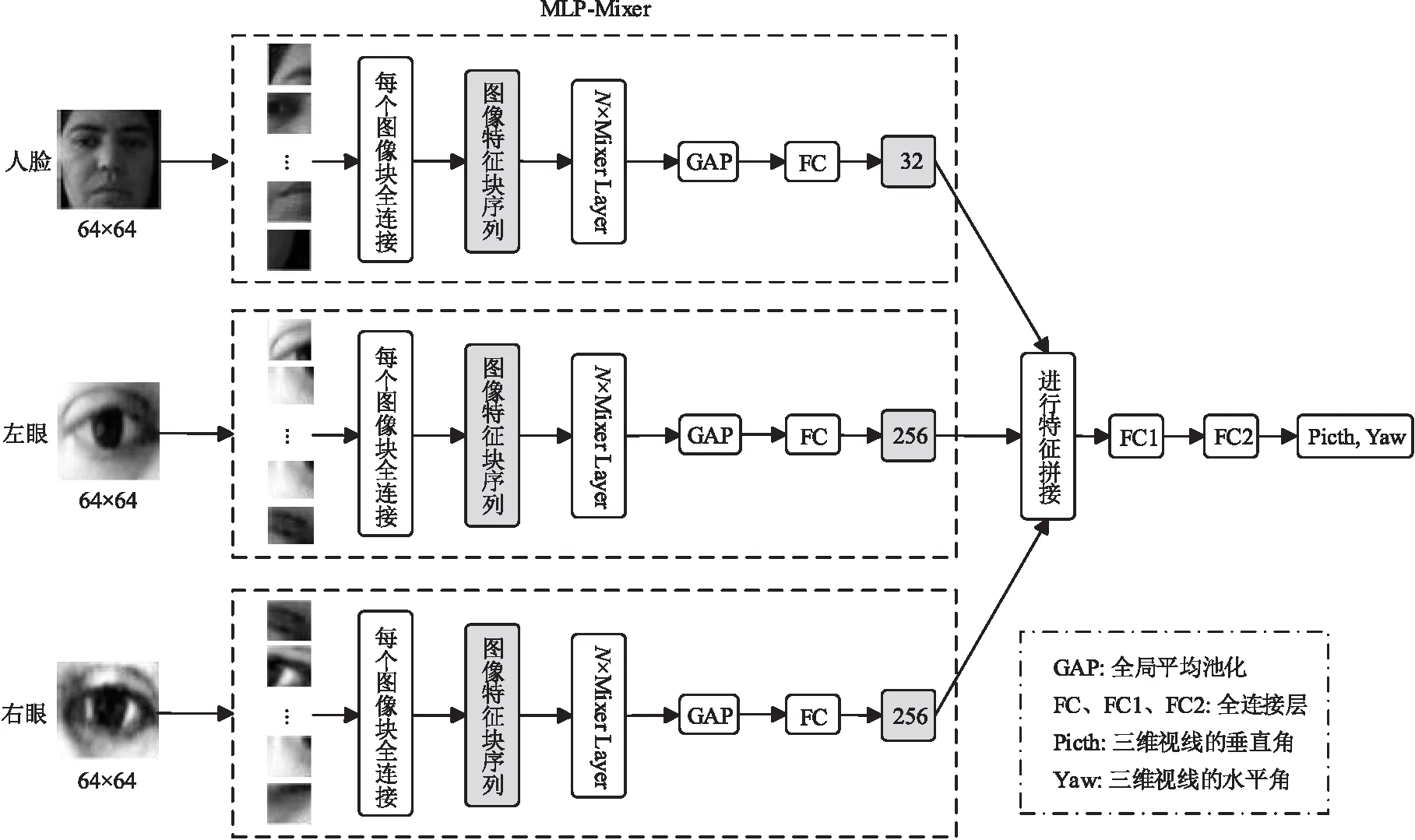
Figure 1 The proposed UM-Net method圖1 本文提出的UM-Net方法
2.2 MLP模型
目前,CNN已成為計算機視覺領域的首選模型。但是,近年來興起的Vision Transformer[21]提供了新的思路,該方法對輸入的圖像進行分塊并展平為序列,然后將其輸入到Transformer模型的編碼器部分,緊接著在全連接層進行圖像分類,實驗結果表明該方法性能優異。該研究表明將深度神經網絡直接應用于圖像塊序列時,Transformer模型也能很好地執行圖像分類任務。
另外,Tolstikhin等[20]也提出了一種區別于CNN和Transformer的新模型MLP-Mixer。MLP-Mixer是一種極具競爭力且概念與技術簡單新穎的模型,它無需卷積與自注意力,僅依賴MLP進行圖像處理工作。MLP-Mixer包含2種類型的模塊:一種是獨立作用于圖像塊的MLP,即用于融合每個圖像塊位置的特征信息;另一種是跨圖像塊作用的MLP,即用于融合圖像序列空間信息。與CNN、Transformer等相比,MLP-Mixer的性能并不是最優的,但MLP-Mixer在僅使用結構更為簡單的MLP的條件下,不僅取得了與當前最佳CNN和Transformer模型相當的性能,模型加載速度也快于CNN和Transformer模型的,可見其適用于視線估計這個強調精度也重視速度的領域。
3 本文方法
基于表觀的視線估計面臨許多挑戰,例如頭部運動和主體差異,尤其在無約束環境中時,這些因素對眼睛表觀有很大影響,并使眼睛表觀復雜化。傳統的基于表觀的視線估計方法擬合能力較弱,無法很好地應對這些挑戰。神經網絡在視線估計中展現出了良好性能。不同于其他的方法使用CNN,本文提出的UM-Net使用結構更為簡單的MLP模型進行視線估計。如圖1所示,UM-Net采用3條支路分別對左眼圖像、右眼圖像和人臉圖像進行特征提取,然后對提取到的特征進行拼接,最后利用2個全連接層回歸出三維視線方向。接下來,本節將詳細介紹本文提出的三維視線估計方法。
3.1 特征提取模塊
特征提取對大多數基于學習的任務至關重要。由于眼睛表觀的復雜性,從眼睛表觀中有效地提取特征是一個挑戰。提取的特征質量決定了視線估計的準確性。
UM-Net的特征提取模塊先將輸入的圖像拆分為多個圖像塊(每個圖像塊之間不重疊[20]),以便于對圖像中的信息進行交換以及特征整合。假設輸入圖像的分辨率為(J,K),拆分后的圖像塊分辨率為(P,P),那么圖像塊的數目H計算如式(1)所示:
(1)
本文輸入UM-Net的原始圖像分辨率為(64,64)。首先將輸入圖像拆分為16個分辨率為(16,16)的圖像塊,然后通過全連接將每個圖像塊投影到512維空間,所有圖像塊都使用相同的投影矩陣進行線性投影,投影之后圖像特征塊序列X∈R16×512。全連接操作將不重疊的圖像塊投影到更高的隱藏維度,不僅保留了圖像的關鍵特征,還有助于后續局部區域的信息融合。
接下來將圖像特征塊序列送入N(8≤N≤24)個Mixer Layer。Mixer Layer未使用卷積或自注意力,僅使用了結構簡單的MLP,并將之重復應用于空間位置或特征通道。3.3節詳細介紹了Mixer Layer模塊。
UM-Net利用Mixer Layer模塊中的token-mixing MLP模塊和channel-mixing MLP模塊分別對圖像特征塊序列進行列方向的特征提取和行方向的特征提取。這些操作是交替堆疊進行的,有助于2個輸入維度間的交流。將圖像特征塊序列反復經過N個Mixer Layer,提取圖像特征信息。接著UM-Net使用全局平均池化對整個網絡模型在結構上進行正則化以防止過擬合,最后使用全連接層分別回歸出所需要的圖像特征。
3.2 網絡支路
本文利用上述特征提取模塊從雙眼圖像和人臉圖像中提取圖像特征。
雙眼特征提取支路(左眼支路和右眼支路):視線方向與眼睛表觀高度相關,視線方向的任何擾動都會導致眼睛表觀發生變化。例如,眼球的旋轉會改變虹膜的位置和眼瞼的形狀,從而導致視線方向的改變。這種關系使得能夠從眼睛的表觀來估計視線。使用MLP模型可以直接從眼睛圖像中提取深度特征,對環境的變化更具魯棒性。因此,UM-Net使用特征提取模塊分別從左眼圖像、右眼圖像提取256維特征。但是,隨著環境變化,眼睛圖像特征也會受到冗余信息的干擾。
人臉特征提取支路:三維視線方向不僅取決于眼睛的表觀(虹膜位置、眼睛開合程度等),還取決于頭部姿態。人臉圖像包含頭部姿態信息,所以UM-Net使用特征提取模塊從人臉圖像中提取32維特征以補充更豐富的信息。3條特征提取支路參數共享。
UM-Net使用3條特征提取支路回歸出左眼圖像特征、右眼圖像特征和人臉圖像特征之后,將提取到的特征進行拼接,然后將544維特征輸送到第1個全連接層降至256維之后,再使用第2個全連接層回歸出三維視線方向。這個三維視線方向是由垂直方向上的pitch角和水平方向上的yaw角來表示的,如式(2)所示:
(pitch,yaw)=δ(C{φθ(f)+φθ(l)+φθ(r)})
(2)
其中,f,l和r分別表示模型輸入的人臉圖像、左眼圖像和右眼圖像;φθ(·)表示網絡的特征提取模塊;C表示對提取到的左眼圖像特征、右眼圖像特征和人臉圖像特征進行連接操作;δ(·)表示使用全連接層回歸出三維視線方向。
UM-Net (no face):由于三維視線與雙眼圖像信息高度相關,為了提高視線估計的速度,可以去除人臉支路,僅將左眼圖像和右眼圖像作為輸入,特征提取之后再進行特征拼接,回歸出三維視線方向,如式(3)所示:
(pitch,yaw)=δ(C{φθ(l)+φθ(r)})
(3)
另一方面,本文認為人臉支路有助于提供頭部姿態等更豐富的信息,去除人臉支路之后會降低視線估計精度。因此在實驗部分,本文對去除人臉支路前后的網絡進行視線估計精度和速度對比,評估人臉支路的有效性。
在UM-Net估計出pitch角和yaw角之后,可以計算出代表視線方向的三維向量a=(x,y,z), 如式(4)~式(6)所示:
x=cos(pitch)cos(yaw)
(4)
y=cos(pitch)sin(yaw)
(5)
z=sin(pitch)
(6)
該向量與真實的方向向量b之間的夾角即為三維視線估計領域常用的評價指標,即視線角度誤差θ,如式(7)所示:
(7)
損失函數采用均方損失函數MSELoss(Mean Squared Error Loss),如式(8)所示:
(8)
其中,i表示訓練樣本集的大小。
3.3 Mixer Layer模塊
當前深度學習模型對圖像特征進行融合的方式主要分為3類:對不同通道進行融合;對不同空間位置進行融合;對不同通道、空間位置都進行融合。不同的模型作用方式不同。在CNN中,使用1×1卷積進行不同通道融合,對于不同空間位置融合則使用S×S(S>1)卷積或池化,使用更大的卷積核進行上述2種特征融合。在Vision Transformer等注意力模型中,使用自注意力層可以進行不同通道融合和不同空間位置融合;而MLP則只能進行不同通道融合。Mixer Layer模塊的主要思想是利用多個MLP實現上述2種特征融合并且作用過程分離進行。反復經過Mixer Layer模塊,交替實現上述2種特征的融合,即可提取出圖像特征信息。
Mixer Layer結構如圖2所示,其中左虛線框內是token-mixing MLP模塊,右虛線框內是channel-mixing MLP模塊。token-mixing MLP模塊先對圖像特征塊序列X∈R16×512進行轉置,然后將MLP1作用在圖像特征塊序列的每一列上,實現圖像特征塊序列不同空間位置間的交流,并且所有列共享MLP1參數。得到的輸出再進行轉置,然后在channel-mixing MLP模塊中將MLP2作用在圖像特征塊序列每一行上,實現圖像特征塊序列不同通道間的交流,所有行共享MLP2參數。

Figure 2 Mixer Layer module圖2 Mixer Layer模塊
Mixer Layer模塊中還使用了跳躍連接(Skip-Connection)和層規范化(Layer Normalization)。跳躍連接可以緩解梯度消失的問題,層規范化可以提高模型的訓練速度和精度,使模型更加穩健。對于輸入的圖像特征塊序列X∈R16×512,Mixer Layer模塊作用過程如式(9)和式(10)所示:
U*,i=M1(LayerNorm(X)*,i),i∈[1,512]
(9)
Yj,*=M2(LayerNorm(U)j,*),j∈[1,16]
(10)
其中,M1(·)和M2(·)表示MLP1模塊和MLP2模塊,LayerNorm(X)*,i表示圖像特征塊序列經過層規范化后的第i列,LayerNorm(U)j,*表示圖像特征塊序列經過層規范化后的第j行。
3.4 MLP模塊
UM-Net中每個MLP模塊都包含2個全連接層和1個非線性激活函數GELU(Gaussian Error Linear Unit),如圖3所示。對于MLP模塊的輸入?,作用過程如式(11)所示:
σ=W2(Φ(W1(?)))
(11)
其中,Φ(·)表示作用于輸入元素的非線性激活函數,W1和W2表示MLP模塊中的全連接層。

Figure 3 MLP module圖3 MLP模塊
4 實驗與結果分析
4.1 數據集
MPIIFaceGaze數據集[16]:MPIIFaceGaze數據集與MPIIGaze數據集使用的是同一批數據,只是增加了全臉圖像,如圖4所示。MPIIFaceGaze數據集是基于表觀的三維視線估計方法中常用的數據集。MPIIFaceGaze數據集包含15個文件夾,分別對應15位外貌差異明顯的受試者。每個文件夾包含一個受試者的3 000組數據(包含人臉圖像、左眼圖像、右眼圖像)。受試者圖像收集歷時幾個月,因此圖像具有不同的光照條件和頭部姿態。

Figure 4 Face images of 15 subjects in MPIIFaceGaze dataset圖4 MPIIFaceGaze數據集中的15名受試者全臉圖像
EyeDiap數據集[22]:與MPIIFaceGaze數據集不同,EyeDiap數據集是在實驗室環境中收集的,包含16位外貌差異明顯的受試者,如圖5所示。利用深度攝像頭標注RGB視頻中的眼睛中心點位置和乒乓球位置。把這2個位置映射到深度攝像頭記錄的三維點云中,從而得到對應的三維位置坐標。這2個三維位置坐標相減后即得到三維視線方向。

Figure 5 Face images of 16 subjects in EyeDiap dataset圖5 EyeDiap數據集中的16名受試者全臉圖像
采取leave-one-subject-out方式進行實驗,即選取數據集中1個文件夾內容作為測試集,剩下的文件夾內容作為訓練集。依次將每個文件夾選取為測試集,分別進行測試,對得到的每個測試集的三維視線角度誤差取平均值作為最后的結果。
4.2 數據集預處理
本文首先對數據集進行預處理,采用與先進的視線估計方法相同的圖像歸一化方法[16,23]。首先對相機進行虛擬旋轉和平移,使虛擬相機以固定距離面對參考點,并抵消頭部的滾動角。本文將MPIIFaceGaze數據集和EyeDiap數據集中的圖像參考點分別設置為面部中心和2只眼睛的中心。在對人臉圖像進行歸一化之后,本文從人臉圖像中裁剪出眼睛圖像,眼睛圖像經過直方圖均衡對對比度進行調整。視線角度真實值也進行歸一化。
4.3 各方法比較
本節在MPIIFaceGaze數據集和EyeDiap數據集上將UM-Net與以下幾種先進的視線估計方法進行對比:
(1)Gaze360[24]:一種基于視頻的使用雙向長期短期記憶LSTM(Long Short-Term Memory)的視線估計模型。它提供了一種對序列進行建模的方法,其中一個元素的輸出取決于過去和將來的輸入。在文獻[24]中,利用7個幀的序列來預測中心幀的視線。
(2)RT-GENE(Real-Time Gaze Estimation in Natural Environments)[25]:基于表觀的視線估計的主要挑戰之一是在允許自由動作的前提下,準確地估計自然外表的受試者的視線。文獻[25]提出的RT-GENE允許在自由觀看條件和大鏡頭距離下自動標注受試者的真實視線和頭部姿態標簽。
(3)FullFace[16]:基于注意力機制的全臉視線估計方法。文獻[16]中的注意力機制主要思想是通過一條支路學習人臉區域各位置的權重,其目標是增大眼睛區域的權重,抑制與視線無關區域的權重。
(4)CA-Net[26]:一種由粗到細的視線方向估計模型,從人臉圖像中估計出基本的視線方向,并利用人眼圖像中相應的殘差對其進行改進。在該思想指導下,文獻[26]引入二元模型來處理視線殘差和基本視線方向,并引入注意力分量來自適應地獲取合適的細粒度特征。
實驗結果如圖6所示。從圖6可以看出,雖然UM-Net沒有使用CNN,而是使用MLP模型,旨在提高視線估計的速度,但UM-Net的視線估計精度接近這些先進的視線估計方法的。另外,圖7還展示了實驗圖像的三維視線可視化示例,其結果表明,對于不同角度的人臉圖像,UM-Net有良好的視線估計精度。

Figure 6 Performance comparison of different methods on two datasets圖6 在2個數據集上不同方法的性能對比

Figure 7 Example of 3D gaze visualization圖7 三維視線可視化示例
4.4 MLP模型與CNN在視線估計中實驗對比
本節在MPIIFaceGaze數據集和EyeDiap數據集上比較UM-Net與基于CNN的方法在視線估計中的精度和速度。
本文選擇Dilated-Convolutions[18]和ResNet50[27]中的CNN替換MLP模型作為UM-Net中的特征提取器。Chen等[18]提出的Dilated-Net表明Dilated-Convolutions在視線估計中有著優越的性能。ResNet50作為經典的CNN結構,因其強大的性能有著廣泛的應用。本文使用Dilated-Net對人臉圖像和雙眼圖像進行特征提取,使用ResNet50模型(ResNet50-Net)代替MLP模型同樣對分辨率為64×64的人臉圖像、左眼圖像和右眼圖像分別提取32,256,256維特征。

Figure 8 Average angle error comparison on MPIIFaceGaze dataset圖8 在MPIIFaceGaze數據集上的平均角度誤差對比

Figure 9 Average angle error comparison on EyeDiap dataset圖9 在EyeDiap數據集上的平均角度誤差對比
實驗結果如圖8和圖9所示。可以看到,使用不同受試者所在的文件夾作為測試集,得到的結果也不同。在MPIIFaceGaze數據集上,UM-Net的綜合平均角度誤差為4.94°,Dilated-Net的為4.51°,ResNet50-Net的為5.49°。在EyeDiap數據集上,UM-Net的為6.66°,Dilated-Net的為6.17°,ResNet50-Net的為6.21°。以上結果表明,UM-Net在MPIIFaceGaze數據集和EyeDiap數據集上的平均角度誤差比肩基于CNN方法的,并且在某些受試者上的預測精度占據優勢。
另外,在視線估計的效率表現上,實驗結果如圖10所示。在MPIIFaceGaze數據集上,UM-Net的綜合平均預測時間為3.74 s,Dilated-Net的為5.23 s,ResNet50-Net的為23.69 s。UM-Net處理MPIIFaceGaze數據集中3 000組數據的時間平均為3.74 s,即平均每秒能處理800組數據,證明本文方法能夠很好地滿足視線估計實時性的要求。
在EyeDiap數據集上,UM-Net的綜合平均預測時間為6.91 s,Dilated-Net的為11.12 s,ResNet50-Net的為47.52 s。實驗結果表明,UM-Net在MPIIFaceGaze數據集和EyeDiap數據集上的預測時間都明顯優于Dilated-Net的,大幅度優于ResNet50-Net的。以上結果表明,UM-Net視線估計速度快,在三維視線估計實時性較強的應用場景有良好的前景。
綜上,UM-Net使用MLP模型提取圖像特征,在視線估計領域中,預測精度比肩基于CNN的方法的,預測速度處于領先地位。
4.5 模型參數量對比
本文計算了UM-Net、Dilated-Net和ResNet50-Net的參數量。模型參數量是模型訓練中需要訓練的參數總數。本文利用THOP庫(PyTorch中的第三方庫)統計模型的參數量。網絡參數統計結果如圖11所示,UM-Net所需的參數量顯著低于ResNet50-Net的。UM-Net參數量也明顯低于Dilated-Net的。

Figure 11 Parameter quantities comparison圖11 參數量對比
4.6 人臉支路有效性驗證
為了驗證人臉支路的有效性,本文去除人臉支路,保留剩下的2條眼部支路進行視線估計,實驗結果如表1所示。可以看到,去除人臉支路后的平均視線角度誤差為5.93°,高于UM-Net的4.94°,平均預測時間為3.13 s,與UM-Net的3.74 s差距較小。因此,加入人臉支路可以補充雙眼圖像以外的特征信息,對視線估計精度有較為明顯的提高,但對預測時間的影響較小,驗證了人臉支路的有效性。另一方面,該實驗結果也表明,在追求視線估計速度的場景,可以去除UM-Net中的人臉支路。

Table 1 Experimental results comparison of methodsafter removing face branches表1 去除人臉支路的實驗結果比較
5 結束語
在三維視線估計領域中,如何在保持高精度的同時,設計一個高效的模型是值得思考的問題。結構較CNN更為簡單但性能相當的MLP模型帶來了啟發。本文方法無需CNN、使用基于MLP模型的方法(UM-Net)進行視線估計。實驗結果表明,對MPIIFaceGaze數據集和EyeDiap數據集中包含的31位不同相貌的受試者圖像,使用UM-Net進行視線估計,精度比肩基于CNN的方法的,并且在視線估計速度上具有明顯的優勢,在需要視線估計實時性的領域有很好的應用前景,如在醫療領域,漸凍癥患者可以通過實時性強的眼動儀來與外界進行交流。本文探索了MLP模型在視線估計領域中的潛力,未來將繼續挖掘MLP模型在視線估計中的應用前景。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
