基于BERT語(yǔ)義分析和CNN的短文本分類(lèi)研究
2023-11-21 04:54:36景永霞茍和平
景永霞,茍和平,劉 強(qiáng)
(1.瓊臺(tái)師范學(xué)院 信息科學(xué)技術(shù)學(xué)院,海南 海口 571100;2.瓊臺(tái)師范學(xué)院 教育大數(shù)據(jù)與人工智能研究所,海南 海口 571100)
文本分類(lèi)是自然語(yǔ)言處理的主要任務(wù)之一,應(yīng)用在很多場(chǎng)景,如人機(jī)對(duì)話(huà)、情感分析、垃圾郵件過(guò)濾和搜索引擎等領(lǐng)域,特別是近年來(lái)智能化應(yīng)用的不斷發(fā)展,文本分類(lèi)受到許多學(xué)者的廣泛關(guān)注。短文本作為一種特殊的文本類(lèi)別,主要存在口語(yǔ)化、文本短小和語(yǔ)法不規(guī)范等特點(diǎn),這為文本特征的有效學(xué)習(xí)帶來(lái)很大困難。傳統(tǒng)的機(jī)器學(xué)習(xí)方法,如支持向量機(jī)(SVM)[1]和k最近鄰算法(kNN)[2]等算法都是常用的文本分類(lèi)模型,但這些傳統(tǒng)的機(jī)器分類(lèi)模型沒(méi)有獲得文本上下文的語(yǔ)義關(guān)系,特別是針對(duì)短文本數(shù)據(jù),產(chǎn)生高維稀疏數(shù)據(jù)表示等問(wèn)題,造成分類(lèi)計(jì)算開(kāi)銷(xiāo)大。目前,深度學(xué)習(xí)技術(shù)已經(jīng)成為主流的文本分析模型,如研究人員采用CNN[3]、RNN、RNN與CNN融合等模型[4],將深度學(xué)習(xí)應(yīng)用到短文本分類(lèi)中,采用基于深度學(xué)習(xí)的良好特征選擇算法,提高文本分類(lèi)的精度。但是對(duì)于短文本來(lái)說(shuō),單純地通過(guò)增加網(wǎng)絡(luò)深度來(lái)獲取文本表示特征,難以提高分類(lèi)效果。研究人員采用基于詞向量的短文本分類(lèi)方法[5],融合基于詞向量和主題模型,提高文本特征向量的語(yǔ)義表征能力。基于Transformer的BERT預(yù)訓(xùn)練模型能夠很好地獲取文本上下文語(yǔ)義信息,特別是獲得長(zhǎng)距離的語(yǔ)義信息,如采用BERT和特征投影網(wǎng)絡(luò)的特征提取方法[6]。采用基于深度學(xué)習(xí)的文本分類(lèi)算法是目前流行的文本分類(lèi)算法,但需要大規(guī)模的語(yǔ)料進(jìn)行訓(xùn)練。本文提出一種基于BERT預(yù)訓(xùn)練模型文本分類(lèi)方法,通過(guò)領(lǐng)域數(shù)據(jù)集的微調(diào),獲得文本向量表示,然后將文本向量送入到CNN網(wǎng)絡(luò)中進(jìn)行文本分類(lèi),使得CNN獲取更好的分類(lèi)特征,提高分類(lèi)效果。
1 文本表示模型
在文本分類(lèi)過(guò)程中,將文本輸入分類(lèi)模型前需要實(shí)現(xiàn)文本向量化表示,才能實(shí)現(xiàn)后續(xù)文本分類(lèi)模型的相關(guān)計(jì)算操作,核心是獲得的向量能夠充分實(shí)現(xiàn)文本語(yǔ)義表達(dá)。
1.1 基于統(tǒng)計(jì)的表示模型
傳統(tǒng)的文本向量化方法有獨(dú)熱(One-hot)模型、詞袋(Bag of Word)模型、TFIDF模型等,存在問(wèn)題主要表現(xiàn)為:① 文本表示稀疏,形成稀疏矩陣,造成計(jì)算開(kāi)銷(xiāo)大;② 文本語(yǔ)義分析不足,難以解決一詞多義在文本分類(lèi)中的干擾現(xiàn)象;③ 上下文語(yǔ)義關(guān)系理解不夠。
特別是對(duì)于短文本,隨著文本數(shù)量的增加,文本表示更稀疏,且由于文本數(shù)量巨大,而每一條文本的詞量少,文本之間的語(yǔ)義關(guān)系挖掘困難,文本分類(lèi)效果不佳。
1.2 基于神經(jīng)網(wǎng)絡(luò)的表示模型
通過(guò)神經(jīng)網(wǎng)絡(luò)模型獲取文本特征,能夠有效地解決文本特征語(yǔ)義問(wèn)題,特別是預(yù)訓(xùn)練模型的使用,能夠更好地獲得文本語(yǔ)義表示,有效解決文本分類(lèi)過(guò)程中的一詞多義帶來(lái)的分類(lèi)問(wèn)題。
目前廣泛使用的基于神經(jīng)網(wǎng)絡(luò)文本表示模型是根據(jù)上下文與目標(biāo)詞之間的關(guān)系進(jìn)行建模,常用的模型有Word2Vec和BERT。
Word2Vec是一種淺層神經(jīng)網(wǎng)絡(luò),根據(jù)給定語(yǔ)料庫(kù),通過(guò)網(wǎng)絡(luò)訓(xùn)練將文本數(shù)據(jù)中的每個(gè)分詞(token)轉(zhuǎn)化為k維空間上的向量,Word2Vec采用CBOW和Skip-gram兩種訓(xùn)練模型。CBOW模型是根據(jù)目標(biāo)單詞(token)的上下文,輸出目標(biāo)單詞的預(yù)測(cè)。Skip-gram模型根據(jù)已知目標(biāo)單詞(token),預(yù)測(cè)其上下文。
BERT是谷歌公司2018年提出的一種基于深度學(xué)習(xí)的語(yǔ)言表示模型,與Word2Vec類(lèi)似,是一種預(yù)訓(xùn)練語(yǔ)言模型,通過(guò)給定語(yǔ)料庫(kù)訓(xùn)練獲得文本向量表示,很好地捕獲文本上下文之間的語(yǔ)義關(guān)系。BERT模型是基于是Transformer多層雙向編碼器[7],結(jié)構(gòu)如圖1所示。

圖1 BERT模型架構(gòu)
Ei(i=1,2,3,…,N)是文本向量表示,是經(jīng)過(guò)字符向量、字符類(lèi)型向量、位置向量相加獲得向量表示。Trm表示Transformer處理,多個(gè)雙向Transformer進(jìn)行文本處理,主要獲得文本上下文信息。Ti(i=1,2,3,…,N)表示經(jīng)過(guò)多層雙向Transformer進(jìn)行編碼后輸出的文本字符向量。BERT模型采用兩種無(wú)監(jiān)督任務(wù)進(jìn)行預(yù)訓(xùn)練[7]:掩碼語(yǔ)言模型(Mask Language Model,ML),隨機(jī)屏蔽每個(gè)句子一定百分比的輸入標(biāo)記,然后再根據(jù)上下文(剩余的標(biāo)記)預(yù)測(cè)那些被屏蔽的標(biāo)記;下句預(yù)測(cè)(Next Sentence Prediction,NSP),許多重要的下游任務(wù)都是基于對(duì)兩個(gè)句子之間關(guān)系的理解,如問(wèn)答系統(tǒng)和自然語(yǔ)言推理,為了訓(xùn)練一個(gè)能夠理解句子關(guān)系的模型,訓(xùn)練數(shù)據(jù)選擇兩個(gè)句子,其中選擇一定比例的數(shù)據(jù)表示一個(gè)句子是另一個(gè)句子的下一句,剩余的是隨機(jī)選擇的兩個(gè)句子,判斷第二個(gè)句子是不是第一個(gè)句子的下文。
2 基于BERT和CNN的短文本分類(lèi)
獲取短文本中良好的文本特征、實(shí)現(xiàn)文本向量化表示是實(shí)現(xiàn)分類(lèi)的關(guān)鍵,CNN的應(yīng)用能夠很好地獲取文本特征,但需要大量語(yǔ)料庫(kù)進(jìn)行訓(xùn)練模型,以獲取良好的特征。BERT模型能夠獲得文本詞之間的深層語(yǔ)義關(guān)系,解決一詞多義問(wèn)題。本文提出了一種融合BERT和CNN的短文本分類(lèi)模型,通過(guò)BERT模型通過(guò)微調(diào)獲取短文本詞向量表示,再將文本詞向量送入CNN模型去實(shí)現(xiàn)文本分類(lèi)。基本流程如圖2所示。
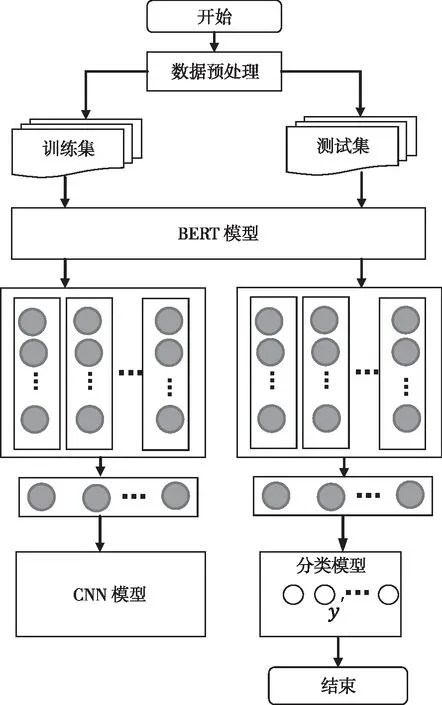
圖2 基于BERT和CNN的短文本分類(lèi)流程
CNN模型的基本結(jié)構(gòu)如圖3所示,分別采用256個(gè)大小為3加5的卷積核對(duì)文本表示向量進(jìn)行兩次卷積,同時(shí)采用256個(gè)大小為2的卷積核對(duì)文本表示向量進(jìn)行卷積操作,最后對(duì)兩個(gè)卷積結(jié)果進(jìn)行連接操作。
采用BERT和CNN的短文本分類(lèi)方法,把BERT關(guān)注文本上下文語(yǔ)義信息和CNN模型關(guān)注局部信息二者結(jié)合起來(lái),實(shí)現(xiàn)文本特征的加強(qiáng)語(yǔ)義表示。對(duì)于包含K個(gè)類(lèi)別的短文本數(shù)據(jù)集D={Ci{i=1,2,…,K},實(shí)現(xiàn)分類(lèi)過(guò)程如下:
(1)首先采用數(shù)據(jù)集D對(duì) BERT模型的微調(diào),使其能夠更好地適應(yīng)應(yīng)用數(shù)據(jù)集。
(2)根據(jù)微調(diào)后的BERT模型實(shí)現(xiàn)短文本數(shù)據(jù)的向量化表示。對(duì)于包含m個(gè)分詞(tokens)的任意文本d∈D,其表示為
d={w1,w2,…,wm}
(1)
對(duì)于分詞wi,其表示向量為
(2)
則文本d通過(guò)BERT模型的輸出d′表示為
(3)
式中:d′的維度為m×n,即數(shù)據(jù)集D中的每一條文本數(shù)據(jù)的維度為m×n;m表示文本的長(zhǎng)度(tokens的數(shù)量),長(zhǎng)度超過(guò)m的文本將會(huì)被截?cái)啵儆趍的進(jìn)行補(bǔ)齊;n表示向量的長(zhǎng)度,就是BERT模型最后一層隱層的hidden_size。
(3)獲得文本數(shù)據(jù)集的向量表示,即一條文本就表示為二維向量,將其作為CNN模型的輸入,CNN分別采用不同卷積核進(jìn)行卷積操作,獲得不同層面的文本特征,最后對(duì)特征進(jìn)行連接操作。
(4)通過(guò)全連接層(FC)和Softmax處理,獲得最后的分類(lèi)結(jié)果。經(jīng)過(guò)全連接層處理獲取的輸出
y=WTd′+b
(4)
W為768×15維的權(quán)重矩陣,b為偏置項(xiàng)。則有
(5)
(6)
3 實(shí)驗(yàn)與分析
3.1 實(shí)驗(yàn)環(huán)境及數(shù)據(jù)
實(shí)驗(yàn)采用Anaconda集成環(huán)境、Python 3.9。文本預(yù)訓(xùn)練模型為:BERTBASE(L=12,H=768,A=12,Total Parameters=110 M),模型微調(diào)實(shí)驗(yàn)數(shù)據(jù)來(lái)自今日頭條短文本數(shù)據(jù)集。
今日頭條短文本數(shù)據(jù)集(TNEWS),包含 15個(gè)類(lèi)別共382 691條數(shù)據(jù),其中訓(xùn)練集267 882條,驗(yàn)證集57 404條,測(cè)試集57 405條。BERT訓(xùn)練和CNN分類(lèi)相關(guān)參數(shù)如表1所示。

表1 參數(shù)設(shè)置表
3.2 評(píng)價(jià)指標(biāo)
短文本分類(lèi)算法評(píng)價(jià)采用精確率precision、召回率recall、綜合評(píng)價(jià)指標(biāo)F1(F1-measure)、宏平均及其加權(quán)平均。
3.3 實(shí)驗(yàn)結(jié)果
基于BERT和基于BERT與CNN的文本實(shí)現(xiàn)的文本分類(lèi)算法,算法的訓(xùn)練損失和驗(yàn)證損失、訓(xùn)練準(zhǔn)確率、驗(yàn)證準(zhǔn)確率如圖4和圖5所示。
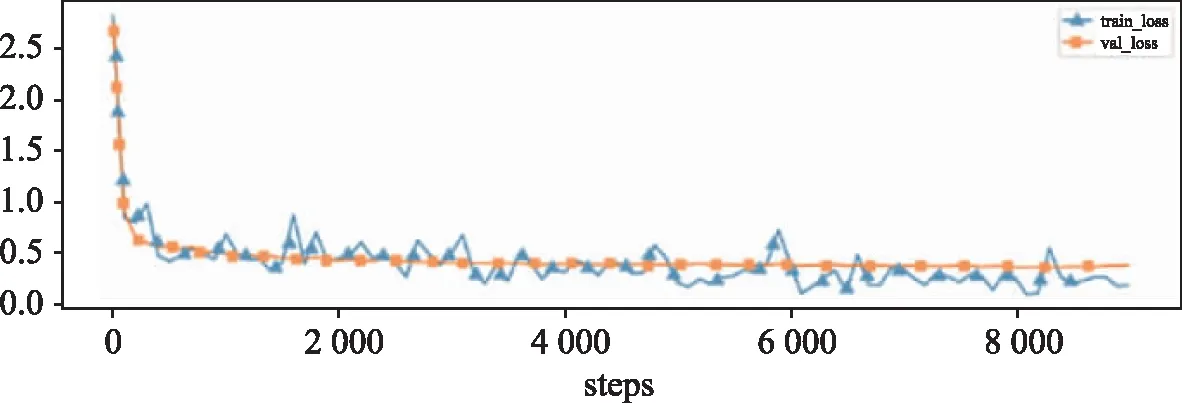
(a)損失
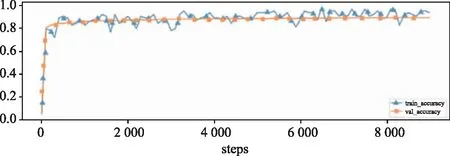
(b)準(zhǔn)確率
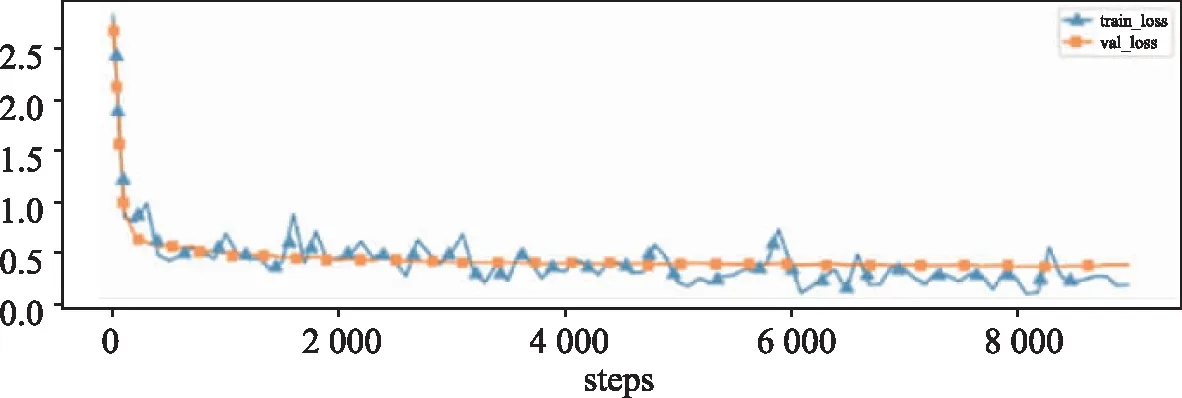
(a)損失
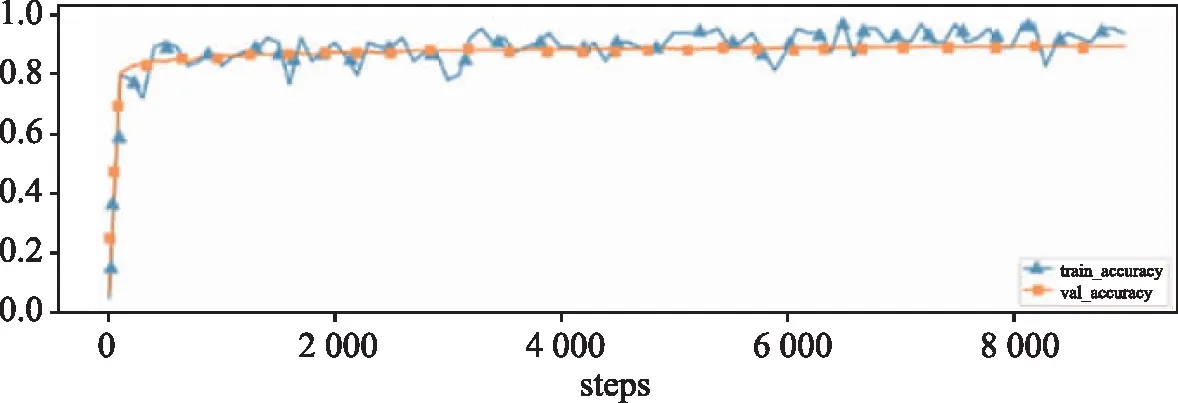
(b)準(zhǔn)確率
對(duì)比分析基于BERT的文本分類(lèi)算法和基于BERT和CNN的文本分類(lèi)算法,其測(cè)試的精確率、召回率、F1值的宏平均(Macro avg)和加權(quán)平均(Weighted avg)如表2和表3所示。

表2 基于BERT的文本分類(lèi)測(cè)試結(jié)果

表3 基于BERT和CNN的文本分類(lèi)測(cè)試結(jié)果
與BERT分類(lèi)相比較,本文實(shí)現(xiàn)算法的分類(lèi)準(zhǔn)確率(accuracy)達(dá)到89.42%,高于單純采用BERT算法的分類(lèi)準(zhǔn)確率。15個(gè)類(lèi)別的F1-score值的宏平均和加權(quán)平均達(dá)到82.93%和89.38%。采用本文提出的結(jié)合BERT模型和CNN的短文本分類(lèi)算法,能夠很好地把短文本中的全局和局部語(yǔ)義信息結(jié)合起來(lái)獲取文本特征,有效地提高算法的分類(lèi)效果。
4 結(jié) 語(yǔ)
提出的短文本分類(lèi)方法采用BERT預(yù)訓(xùn)練模型微調(diào)獲得文本特征抽取,主要目標(biāo)是解決數(shù)據(jù)量小的情況下采用BERT模型可獲得文本語(yǔ)義表征的向量,再將這些經(jīng)過(guò)特征提取后的數(shù)據(jù)特征向量作為CNN模型的輸入,采用不同大小卷積核進(jìn)一步提取分類(lèi)語(yǔ)義特征,此方法能夠有效地提高文本分類(lèi)效果。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
