基于神經網絡模型的永安市小流域水環境質量預測的研究
2023-11-22 03:38:34涂新前
皮革制作與環保科技 2023年20期
涂新前
(三明市永安生態環境保護綜合執法大隊,福建 三明 366000)
引 言
“十四五”以來,國家地表水監測網絡采用“9+X”監測評價新體系,實行手工監測和自動監測數據融合評價考核模式,監測評價和質量控制方法發生了全新變化。2022年為了進一步完善地表水環境質量考核體系,進一步解決汛期面源污染等深層次的問題,推動實現水環境質量的持續改善,生態環境部創新性提出了汛期污染強度的考核制度,精準識別汛期面源污染強度高造成河流水質波動反彈的水體,助力對面源污染治理進行精準施策。良好的水環境狀態是人類社會經濟可持續發展的前提和必備因素,在河流水環境不斷被污染和破壞的前提下,水質的預測工作格外關鍵[1]。對河流水質污染指標未來變化趨勢的準確預測是水環境管理和治理一個重要手段,但在實際工作中存在著空白。
水質預測工作是根據采集到的歷史水質監測數據、水文氣象數據和實時水質自動站監測數據,通過構建預測模型等手段預測未來的水質變化趨勢,以達到掌握水質現狀及發展趨勢的目的[2]。時間序列預測模型主要包括多元線性回歸模型(MLR)、自回歸差分移動平均模型(ARIMA)和人工神經網絡法等[3]。然而由于天然河流水質指標變化通常具有不穩定性和非線性的特點,傳統的統計學預測模型在水質預測方面存在一定難度。
本文基于永安市文川溪和巴溪兩條重點流域歷史監測數據和水質自動監測實時數據,結合氣象參數、水文數據、入河排污口在線監測數據,將溶解氧、高錳酸鹽指數、氨氮、總磷等4項指標作為預測對象,基于長短期記憶神經網絡構建水質預測模型,對永安兩條流域考核斷面水質指標濃度未來變化進行預測。
1 水質模型的構建
水質預測與時間序列相關,即預測結果除了與當前時刻的輸入水質指標變化有關,還與之前某一時刻或一段時間內的輸出水質指標變化相關。水質問題基于時間序列存在一定的周期性和規律性,傳統的全連接深度學習模型難以將時序上的關聯性考慮在內。循環神經網絡是一類以序列數據為輸入,在序列演進方向進行遞歸的神經網絡。與普通全連接神經網絡相比,其對時序關聯的問題進行了考慮,增加了記憶單元。
普通循環神經網絡(RNN)模型雖然能夠建立時間順序的關聯關系,但難以將跨度較大的時間關聯關系納入模型之中,對模型預測能力有較大影響。門控循環神經網絡在普通循環神經網絡的基礎上,調整了網絡結構,增加了門控機制,以控制信息在神經網絡中的傳遞。通過門控機制來控制模型中記憶單元需要保留的信息有多少和丟棄的信息有多少,以及需要更新多少新信息到記憶單元中等。這使得具有門控機制的循環神經網絡可以訓練與學習相對較長跨度,具有長時間依賴關系。常見門控循環神經網絡模型有:長短期神經網絡(LSTM)和門控循環單元(GRU)[4]。
LSTM模型是由循環神經網絡(RNN)改進后得到的,LSTM模型在RNN的基礎上增加了3個門控機制,分別是“遺忘門”“輸入門”和“輸出門”。LSTM模型能夠記憶長期依賴關系,其中輸入門和遺忘門是關鍵。GRU模型結構相比LSTM模型更簡單。GRU模型舍棄了一個門控機制,將LSTM模型中的輸入門和遺忘門融合成一個新門控機制,稱為更新門。更少的參數使得GRU模型訓練效率更高,LSTM模型則更能記住長距離依賴,兩者各有優劣,往往與具體的數據集、研究區域相關,需要經過實驗來進行比較。LSTM模型在氣象、環境質量和水文等多個領域得到應用,其中在黃河、鄱陽湖撫河、西麗水庫等流域建立了相應的水質預測模型 。
1.1 LSTM的水質預測模型整體流程
設各水質指標按時間(t)順序排列,將各指標數據構成一個時間序列Ci(t)=[Ci(1),Ci(2)…Ci(t)],i對應不同的水質指標,如Ci可以代表溶解氧、氨氮、總磷等,Ci(t)代表相應水質指標第t時刻的監測濃度。若以t時刻為當前時刻,n為滑動時間,則水質指標Ci的t-n時刻到t時刻的時間序列表示為:
使用單指標進行水質預測時,依據滑動時間n的大小將時間序列Ci(t)傳入LSTM模型的輸入層,可以得到該時間序列下一時刻t+1的預測值Pi(t+1)。例如當t=6時,預測模型使用前五個時刻的監測數據預測第六個時刻的值,即使用時間序列表示為:
預測下一時刻t+1的預測值Pi(t+1),以此類推。該模型使用Logistic作為激活函數(б),值域為(0,1),LSTM模型原理圖如圖1所示。
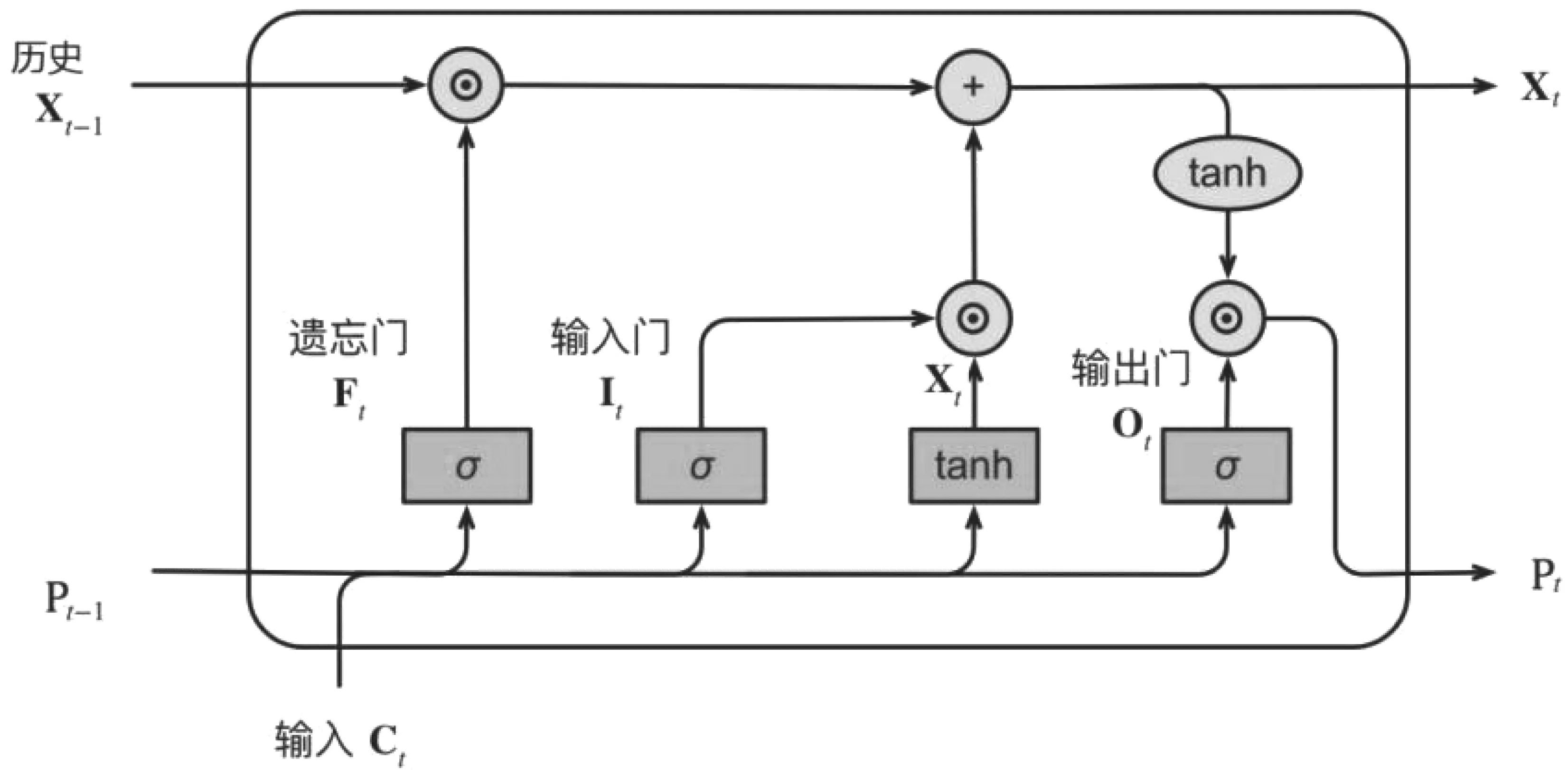
圖1 LSTM模型原理圖
1.2 GRU的水質預測模型整體流程
GRU采用門控機制融合歷史信息與當前時刻觀測記錄(C)獲得下一時刻的預測值p,能夠有效建模時間序列的長程依賴性。輸入的歷史時間序列C和未來時刻預測值Y分別表示為[5]:
式中:t為時刻;d為滯后窗口;n為預測步長。
GRU模型在構建實測值和預測值間映射關系的函數f:
GRU模型中重置門和更新門使用sigmoid函數來激活(б)。GRU模型原理圖如圖2所示。

圖2 GRU模型原理圖
1.3 水質預測模型工作的基本流程
使用水質預測模型進行水環境質量預測整體工作流程為:(1)對輸入模型多元數據集進行數據清洗;(2)根據歷史監測數據定義一個訓練集;(3)初步構建水質預測原始模型,確定模型中各項指標基本參數;(4)使用前期已有的監測數據對預測模型進行訓練,基于輸出相關誤差評價對模型相應參數進行更新;(5)輸入水質要素序列Ci的前n個數據監測值組成的序列Ci(t)到訓練好的水質模型中,獲得Pi的第t+1的預測值Pi(t+1);(6)隨著在線實時監測數據不斷輸入模型,不斷反向訓練計算輸出誤差,采用反向傳播算法將誤差傳遞給模型隱藏層神經元更新權重參數。通過不斷對模型訓練和迭代,逐步提高模型預測的精度,當滿足預設精度要求時訓練完成。水質預測模型工作流程如圖3所示。

圖3 LSTM模型工作流程
2 永安市主要流域概況
永安市溪流密布,河流眾多,主要有沙溪、尤溪、九龍江三大水系,轄區內匯流面積50平方公里以上有21條,見圖4。其中沙溪、巴溪和文川溪匯流面積達500平方公里以上。

圖4 永安市水系分布圖
巴溪、文川溪、胡貢溪、益溪和后溪等五條主要支流匯入沙溪,流域面積占83%。文川溪發源于連城縣曲溪鄉經小陶鎮進入永安境內,經小陶鎮、洪田鎮、燕西街道吉山村匯入沙溪;巴溪發源于永安市西洋鄉,流經桂口村進入永安市城區匯入沙溪,流經城區10公里,永安市小流域主要概況如表1所示。河水溫年變動5~33 ℃,常年平均水溫為18~22 ℃。永安年平均降雨量1 538.9毫升,其中3~6月降雨量877.6毫米,占全年年降雨量50%以上,日最大降水量244.7毫米,全市多年平均徑流深為755~1 061 毫升,分布特點與降水情況接近。

表1 永安市小流域主要概況
3 模型數據的輸入
模型采用多元化數據采集方式,分別接入文川溪口、洪田貴湖、山峰電站、巴溪口等四個水質自動站數據。選取的水質指標為水溫、pH值、溶解氧(DO)、總磷(TP)、氨氮(NH3-N)、高錳酸鹽指數(CODMn)。接入兩條小流域匯流流域內的9家企業的排放口(入河排污口)實時監測數據,及兩條流域匯流區域內西洋鎮、大煉村、上吉村、洪田鎮、小陶鎮等8個氣象站數據(氣溫、氣壓、風速、降水)和未來7天氣象數據預測;同時接入流域內外洋電站、黃歷電站、洪田電站等12座水電站實時下泄流量數據。流域內面源污染主要來源于水稻種植、煙葉種植、蔬菜種植、果林、竹林和城鎮生活源。
4 輸入數據的處理
模型所使用的監測數據的質量,直接決定著模型預測結果的可靠性和準確率。預測模型將用到大量實時和人工監測數據,主要包括水質自動站數據、水質人工監測數據等,為了保證輸入數據的有效性和足夠敏感性,避免某些異常數據導致模型在計算時產生偏離。手工監測數據全部經人工審核后導入模型,自動監測數據均采用福建省生態云平臺審核后的有效數據,以確保監測數據的質量,進而完成多源數據的融合入庫。
基于水環境質量預測模型建設,實現對水質監測站點的監測指標(高錳酸鹽指數、氨氮、總磷和溶解氧)進行預測,研判未來水質情況,實現針對各斷面水質的短期預報。
5 模型評價指標
本文對于水質預測模型的預測結果做出合理評價,采用水質自動監測站實測值和模型預測結果的均方誤差(MSE)、均方根誤差(RMSE)和平均絕對百分比誤差(MAPE)來進行量化。
均方誤差(MSE)計算公式為:
均方根誤差(RMSE)計算公式為:
平均絕對百分比誤差(MAPE)計算公式為:
式(6)(7)(8)中pi為模型預測值,Ci為實測值,n為訓練集個數。
6 結果與分析
6.1 LSTM模型預測實例
訓練的數據為2021年5月至2022年文川溪口、巴溪口、洪田貴湖、山峰電站等四個水質自動站數據,同時輸入2018年1月至2022年6月以來文川溪和巴溪的山峰電站、洪田貴湖、下洋村、文川溪口、巴溪口等10個監測斷面手工數據進行修正,將2022年7月~12月數據作為水質模型的測試數據,2023年1月~7月作為模型預測的驗證數據。為了充分驗證LSTM模型的性能,使用相同數據以GRU模型作為對比模型。表2和表3展示不同模型對文川溪和巴溪兩種不同類型水質中高錳酸鹽指數、氨氮、總磷、溶解氧的預測結果。

表2 不同模型對巴溪水質指標預測效果對比

表3 不同模型對文川溪水質指標預測效果對比
通過對比表2和圖5中LSTM模型和GRU模型在巴溪流域對高錳酸鹽指數、氨氮、總磷、溶解氧的預測結果,可以較為直觀地看出LSTM模型對高錳酸鹽指數、氨氮、溶解氧的預測結果與實測值擬合效果較好;GRU模型對總磷的預測結果與實測值擬合效果較好。
由表2可知,LSTM模型對4項水質指標較GRU模型的預測精度高。以GRU作為比較模型,高錳酸鹽指數MSE和RMES提高29.6%和15.9%,氨氮MSE和RMES降低64.3%和29.7%,總磷MSE和RMES提高2%和28.9%,溶解氧MSE和RMES提高49.6%和28.2%。
通過對比表3和圖6中LSTM模型和GRU模型在文川溪流域對高錳酸鹽指數、氨氮、總磷、溶解氧的預測結果,可以較為直觀地看出LSTM模型對高錳酸鹽指數、氨氮、總磷、溶解氧預測的趨勢結果與實測值擬合效果較好。GRU模型對總磷、溶解氧的預測趨勢結果與實測值擬合效果較好。
由表3可知,LSTM模型對4項水質指標的預測精度高于GRU模型。以GRU作為比較模型,高錳酸鹽指數MSE和RMES提高54.3%和33.3%,氨氮MSE和RMES提高20%和10%,總磷MSE和RMES提高20%和9.1%,溶解氧MSE和RMES提高13.8%和7.4%。
通過對比LSTM模型和GRU模型分別對文川溪和巴溪的預測結果評價,LSTM模型相比GRU模型在水環境質量預測運用中具有更高的準確率。
6.2 LSTM模型效果評價
由表4可知,LSTM模型在預測文川溪和巴溪兩條流域時,文川溪除高錳酸鹽指數的MEAP比巴溪高10.8%,氨氮、總磷和溶解氧的MEAP分別低了29.5%、8.1%和18.6%;文川溪高錳酸鹽指數、氨氮、總磷和溶解氧的MSE值比巴溪低0.86、0.22、0.003、和0.02;文川溪高錳酸鹽指數、氨氮、總磷和溶解氧的RMSE值比巴溪低0.55、0.47、0.03、和0.01。

表4 LSTM模型對不同河流類型水質指標預測效果對比
LSTM模型在預測文川溪氨氮和總磷時均方誤差大幅低于其他指標,預測精度較高。該流域建設了背景斷面、消減控制斷面和入河考核斷面3座水質自動監測站,8個水電站水流量的輸入和匯流區域內5個重點入河排污口在線數據實時輸入,使得模型對文川溪的預測精度進一步提高。巴溪流域的模型預測效果不如文川溪,主要原因在于巴溪有10公里流經的區域在城區,城市內管網收集率不高、管網破損、污染來源多樣,該流域僅在入沙溪河口建設了一個水質自動監測站,其他數據更多依靠人工監測數據的輸入,給模型的預測過程增加了不確定性。
7 結論
從兩個模型的預測數據和評價指標可知,LSTM水質預測模型特有的門控機制可處理長時間序列監測數據,同時擁有更多的記憶單元,可將水質季節性變化、節假日效應等因素考慮在內,提高了模型的預測能力,該模型在永安市小流域中預測趨勢結果較GRU模型更有優勢。LSTM模型在預測多種評價指標時,對于所預測的各時刻數據均表現出較高的精確度及穩定性。對于途徑城區區域的河流,GRU模型在預測總磷和溶解氧方面精度較好,因此在實際應用過程中,需要根據不同河流的情況結合不同模型進行綜合判斷,不能依靠單一模型,需要多模型結合提高預測的準確度。
隨著水質自動監測系統的不斷建設,自動監測逐漸替代人工監測,水質監測數據的獲取量呈幾何倍數增長,使得LSTM模型能夠獲得大量的數據進行訓練,提高預測的精度,LSTM模型基于多元數據的輸入,使水質預測準確度得到明顯提高。
在實際應用中,建立水環境質量預測預警平臺,隨著模型的不斷自我學習和迭代優化,可以輸出未來七天流域水質指標的預測結果,提前發現流域潛在的水質變化,第一時間發出相關河流水質預警,同時可以對超標的河流進行污染過程復盤,提高相關部門應對水環境風險的能力,進一步完善治理規劃體系,推動水流域環境保護高質量發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
當代水產(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規劃與設計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
