數字人文視角下藏醫學古籍知識發現研究
——以《四部醫典》為例
2023-11-24 06:34:34梁世豪李昕娛王文欣宋雪雁
現代情報 2023年11期
沈 旺 梁世豪 李昕娛 王文欣 宋雪雁
(吉林大學商學與管理學院,吉林 長春 130012)
藏醫學古籍是藏族人民醫學智慧的匯集,是我國寶貴的醫學資源。從古至今遺留下來的藏醫學經典古籍有《醫學大全》《無畏的武器》《月王藥診》《四部醫典》《晶珠本草》等,蘊含著大量可挖掘利用的內容信息。數字人文(Digital Humanities)起源于人文計算(Humanities Computing),其目的是將數字技術融入學術研究,以解決人文領域存在的問題。在數字人文領域,研究熱點涉及文化遺產、GIS技術應用、語料庫建設、數字檔案以及數字圖書館等,相關技術包括知識圖譜、關聯數據、IIIF、人工智能等。數字人文技術的發展,推動著人文社科領域相關資源開發利用新途徑的發現。本文以藏醫學經典古籍《四部醫典》為例,運用統計分析、關聯分析、聚類分析、可視化技術等方法工具,挖掘藏醫學古籍中的病癥關系、病因關系、用藥規律以及可能的新處方,并通過可視化圖片呈現,擬為研究藏醫學古籍知識發現提供一種可行的思路,有助于藏醫學古籍的開發與利用,也有利于藏醫學的發展與傳播。
1 研究回顧
1.1 藏醫學古籍研究
通過對國內外藏醫學古籍以及數字人文領域現有文獻研究的梳理發現,由于藏醫學古籍的民族特性,國外相關研究甚少,僅有Dhondrup W等[1]利用層次分類對《四部醫典》中5種疾病的病因關系進行了可視化分析。國內相關研究較為豐富,曹明澤等[2]梳理了藏藥發展史,占堆等[3]以時間為線梳理了藏醫藥學的發源、發展以及未來。梁成秀[4]對《四部醫典》的編撰進行了解讀,不過更多學者的研究重點在挖掘藏醫藥古籍中蘊含的用藥思想與規律。文成當智等利用復雜網絡等分析方法,發掘出藏醫學用藥傾向“食療加藥物,藥物加治法”的規律,從藏醫藥學的“味性化味”理論出發,揭示藏醫學用藥規律的科學內涵[5-6]。旦增米吉等[7]從《四部醫典》中含有印度獐牙菜的處方出發,挖掘藏醫學用藥配伍規律。
1.2 數字人文研究
數字人文主要指的是以數字化的資源為對象,利用一系列的數字技術對其進行收集、加工和利用,以此來實現知識發現的過程[8]。數字人文相關研究主要涉及數字人文工具開發、數字人文整體情況研究、數字人文項目借鑒研究以及人文資源實例研究。
首先在工具開發方面,國外研究較豐富。Moretti G等[9]開發了能幫助人文學者在數字環境中進行大量文本數據分析的工具——ALCIDE。基于3個不同的數字人文項目,Zwaan J M等[10]介紹了可視化工具Storyteller,相較于其他可視化工具,其具有能交互式展示復雜數據的優勢。Terras M等[11]為解決人文學者在計算上存在的技術障礙,通過實例研究探索最能滿足人文學者研究需求的高性能計算設施。Arnold T等[12]將重點放在對詞袋、詞頻模型的超越,通過使用核心編程語言編寫的軟件包R,以便能對數字人文相關的文本分析進行更人性化的研究。
其次在數字人文的整體情況研究方面,Joo S等[13]運用文本挖掘技術,聚焦數字人文近10年的研究熱點與趨勢,發現文化遺產、地理信息、語義網等關鍵詞。國內,劉煒等[14]為促進數字人文的整體發展,將數字人文的理論結構與方法論在宏觀層面進行了深入探討。周晨[15]ADDIN以WoS核心合集數據為基礎進行內容分析,發掘了目前國際上數字人文的發展現狀、研究熱點等情況。鄧君等[16]以CNKI的文獻為數據基礎,利用文獻計量學等方法技術研究了我國數字人文的研究熱點與發展情況,并進行了可視化展示。Su F L[17]通過社會網絡分析并借助可視化工具,對數字人文研究中有關跨國合作的主題、模式、結構等進行了深度研究。李娜[18]回顧并梳理了國際數字人文近20年的文獻研究,探尋了其熱點主題、演化路徑以及知識基礎等內容。
數字人文項目借鑒研究,文獻研究主要在國內。郭金龍等[19]在綜述數字人文領域文本挖掘技術的相關應用后,重點介紹了歐美發達國家(地區)在其中的前沿實踐,期望為我國數字人文的發展與轉型尋找可借鑒之處。徐志瑋[20]以“挖掘數據挑戰”項目為例,研究了國際合作視角下數字人文的研究現狀,為國內相關部門提供決策參考。
最后,對于數字人文的研究更多集中于案例研究。國外,Earley-Spadoni T[21]通過實例研究的方法探討了如何通過數字人文拓寬地理空間技術在考古上的應用,使考古學家受益。Hoeve C D[22]論證了利用數字人文技術進行家譜和家族史研究的可行性以及重要性,為家譜研究提供了思路。Hu S F等[23]利用有關尼泊爾語言的文獻資料,展示了一種基于Web的多媒體制圖,在集成地理空間數據的同時還可以集成多媒體數據。Fedeli A[24]通過語言編碼與數字編輯對古蘭經手稿文本進行了研究,并提供了一個可進行多協作工作的跨國、跨文化系統,在數字編輯手稿以及數據多協作處理方面有重要意義。Plets G等[25]通過實例,研究出了針對于大量考古文本的文本挖掘方法,幫助追蹤、分析以及情境化考古術語的變化。國內,趙思淵[26]利用《中國地方歷史文獻數據庫》闡明數據化與文本挖掘的實現路徑,并提出以元數據為基礎的針對數據庫這一新文獻形態的方法論。鄧君等[27]利用中國歷史人物傳記資料庫(CDBD)中的清代進士數據源并借助于數字技術對其進行剖析,實現了對于清代進士群體的社會網絡關系的知識發現,為傳統的人文研究提供了新的研究范式。夏翠娟等[28]以兩氏家譜為例,詳細闡釋了關聯數據在家譜中的應用與作用。歐陽劍以大量古籍文本為基礎,采用一定分析挖掘方法,幫助深層次開發與利用古籍,是一次對模式創新的嘗試。Huang J J等[29]提出一個新的社會網絡研究框架,幫助人們理解和分析歷史人物的社會關系,并通過中國傳記數據庫中的項目數據驗證了其有效性。張毅等[30]以方志數據庫的建設為例,結合國內外數字人文發展情況,對如何活化利用特藏資源進行了說明。李斌等[31]以《左傳》知識庫為研究對象,利用各種語言處理技術,為古籍文本內容的標記和結構化人文知識庫的構建提供了創新性方法。常博林等[32]以《資治通鑒》為研究對象,成功構建了基于詞和實體檢索并且能夠進行知識挖掘的知識庫,同時利用時間序列分析,挖據出了歷史中人、地、事所蘊含的信息。岑蕭萍等[33]以《易經》為例,利用文本挖掘以及可視化,挖掘并展示了六十四卦中存在的聯系,提供了新的中醫古籍挖掘思路。湯萌等[34]以《石倉契約》為研究對象,利用元數據和可視化等方法技術,率先探索了這些方法在進行民間賬簿資源挖掘的可行性。
從上述研究中可以看到,采用數字人文的方法對古籍文獻進行深度開發與利用是當前的研究趨勢。因此,本文選擇藏醫學古籍資源作為研究對象,運用數據挖掘可視化分析方法,提出數字人文視角下的藏醫學古籍知識發現過程并進行可視化分析,展現藏醫學古籍數據價值的內涵。
1.3 知識發現研究
隨著不斷的完善,知識發現的定義也在隨著社會的進步不斷地發展。最初的定義追溯到了1996年法耶德所認為的,知識發現是從大量的數據中鑒別出有效模式的非凡的過程[35]。而國內研究對于知識發現的定義則更為貼切,大多數的學者認為知識發現是指對大量的積累的數據進行挖掘和分析,并從其中獲取有效的、有用的以及新穎的可以理解的知識[36]。近年來,互聯網的進步帶來了海量的數據,挖掘其中有價值的知識已經成為眾多學者研究的熱點。尤其是在醫學領域中,為了支持和輔助臨床決策,大量的學者對疾病、病癥以及藥物的內在關聯進行挖掘和研究,誕生了眾多研究成果。虞紅蕾等[37]構建了經方領域的消渴病知識圖譜,并在此基礎上進行知識發現和知識查詢,對于中醫藥智能問診、臨床輔助決策都有重要的意義。安欣宇等[38]采用路徑發現,鏈路預測從知識圖譜中挖掘了知識之間的隱含關聯,發現了38種治療精神分裂癥的藥物之間存在隱含關聯,為發現潛在的治療精神分裂癥疾病的藥物提供了相應的幫助。蔡妙芝等[39]提出了基于SPO語義三元組的疾病知識發現模型,以糖尿病為例揭示了糖尿病相關的以及常見的并發癥、檢測手段及治療方式,為疾病的臨床診療和日常防控提供了借鑒。
從上述研究來看,對醫學領域中相關知識進行挖掘對于疾病的治療和預防都有十分重大的意義,這也是本文將《四部醫典》作為研究對象的原因之一。
2 研究對象與研究過程
2.1 研究對象
本研究以藏醫學古籍《四部醫典》為研究對象,選用版本[40]為1987年上海科學技術出版社出版的,由宇妥·元丹貢布等著、馬世林等譯注的中譯本,在超星圖書館獲得電子資源。此譯注版本以多個版本的藏文《四部醫典》為基礎進行譯注,行文更符合現代漢語習慣,在保證內容完整性的前提下更易于理解與分析內容。《四部醫典》是公元8世紀由著名藏醫藥學家宇妥·元丹貢布編著,被譽為“藏醫藥百科全書”。全書共有4部,包括《總則本》《論述本》《密訣本》和《后序本》,共156章。第一部綱領性地介紹了人體的生理、病理、診斷及治療。第二部詳細介紹了人體的生理解剖及疾病發生的原理、原因和途徑等。第三部詳細論述了各類疾病的診斷和治療。第四部介紹脈診、尿診及各種方劑的配方、功效和用途以及外傷的療法等。《四部醫典》中包含藏醫學種種,有著關于藏醫學方面最根本、最完整、最系統的理論體系,其內容可以為藏醫學古籍知識發現提供充分的數據支持。研究數據主要來源于《四部醫典》的第三部《密訣本》和第四部《后序本》。《密訣本》中依照內科疾病、熱疾、腑臟疾病、私處疾病、零星雜癥、瘡癥等分別敘述病因、病緣、癥狀、治法等。《后序本》中從脈診、尿診開始,再敘述湯劑、散劑、丸劑等消除疾病的方法,以及催吐藥、滴鼻藥劑、各類導劑等疾病排除方法,最后再是針刺放血、灸法、藥浴等外用治療方法。此兩部分內容是《四部醫典》中重點敘述的部分,占據大部分篇幅,包含了藏醫學關于疾病診斷、治療、用藥等幾乎所有內容,保證了內容分析的全面性。
2.2 研究過程
本文主要利用Python、Gephi、R語言等工具軟件,按照文檔識別與校對、數據分詞與提取、數據存儲、數據分析處理、數據可視化、結果闡釋的研究過程,最終實現知識發現。
藏醫學古籍知識發現的過程如圖1所示。①文檔識別與校對階段:主要是對《四部醫典》PDF資源進行OCR識別與人工校對,重點對將進行數據分析的部分校對;②文本分詞與提取階段:針對分析需要,從第三部《密訣本》中分詞提取了疾病名稱、疾病癥狀、疾病部位以及部分疾病病因等相關實體。從第四部《后序本》中分詞提取了方劑類型、處方用藥以及主治疾病等相關實體,存儲在對應數據庫或工具表中為數據分析處理做準備;③數據分析處理階段:這一部分主要是針對古籍中的不同內容采取不同的方法分析處理。病癥關系分析進行了疾病癥狀的聚類分析以及疾病部位的關聯分析。病因關系分析進行了詞云分析以及關聯分析。用藥規律分析進行了方劑類型、藥材種類、主治疾病的統計,然后進行藥材的聚類分析以及關聯分析。最后通過聚類分析和關聯分析的綜合運用進行新處方的預測分析。該環節主要使用Python軟件以及R語言來完成,是整個研究的核心部分;④數據可視化及結果闡釋階段:針對分析結果利用相關可視化工具方法得到可視化結果圖以及結合藏醫學基本理論,闡釋分析結果,完成藏醫學古籍知識發現,可視化的過程包括利用Python的Matplotlib繪制條形圖、散點圖來實現可視化。利用其中的Wordcloud庫進行詞云可視化,以及利用Gephi軟件和R語言以及SPSS26.0進行關聯網絡圖可視化。
3 藏醫學古籍《四部醫典》知識發現
3.1 文本識別及人工校對
文本識別和人工校對是研究的起點,其結果直接影響了研究的準確性。因此,在本階段當中,筆者依托于超星圖書館所獲得的《四部醫典》的電子資源,其版本在上一章中進行了具體說明,利用Acrobat Pro DC來進行OCR識別。為了保證本研究的真實性和權威性,對OCR的結果按照電子資源進行人工校對以避免出現識別結果和真實電子資源不符的情況。此外,還選取了其他平臺同版本的電子資源同OCR結果進行比較,最大程度上保證了文本識別結果和數據資源的一致性。
3.2 文本分詞及實體提取
藏醫學古籍《四部醫典》的知識發現主要是通過兩個部分來呈現的,首先是文本的分詞以及實體提取,這一部分的結果是整個研究的基礎,其次是數據處理和可視化階段。
醫學古籍不同于其他的文本形式,在《四部醫典》中無論是在病癥、病因還是處方當中,許多詞匯是以標點符號來進行分割的,因此這在一定程度上減輕了分詞的工作量。所以在文本分詞中,本研究利用Python的Jieba分詞的基礎上,同時采用標點符號劃分的方法來對經過OCR后的文本進行分詞。如在原始文本的處方中,藥材之間用“、”“,”來進行隔斷,因此可以根據標點來將不同的藥材進行分割,根據標點分詞在一定程度上減輕了分詞的工作量且提升了效果。對于較為生僻的藥材以及詞匯,采用輸入詞典的方法來確保不會出現預期以外的單詞,如對于“喜馬拉雅紫茉莉”的處理,將其規定為一個詞組以避免其出現“喜馬拉雅”和“紫茉莉”拆分為兩個詞組的情況。
在實體提取階段,由人工方式來對涉及的實體進行識別和提取,主要對《四部醫典》的《密訣本》《后序本》中所涉及的疾病的病因、病癥、藥方等進行提取得到了相應的疾病病因、疾病病癥以及藥方實體。
在數據處理和可視化的階段,本文通過對藏醫學古籍《四部醫典》的內容進行聚類分析、關聯分析、詞云分析、統計分析,得到了病癥關系、病因關系、用藥規律、預測新處方等分析的分析結果,然后采用相應的技術手段將其進行了可視化展示并對其結果進行了相應的解讀和闡釋。
3.3 病癥關系分析及可視化
在本節中,針對疾病的癥狀、疾病的發生部位分別進行聚類分析以及關聯分析。在聚類分析中使用K-means聚類方法以期獲得不同疾病的癥狀之間的區別和聯系。在關聯分析中采用Apriori算法并根據不同疾病發病部位的信息建立了關聯網絡,以期獲得不同疾病發病部位之間的潛在關聯。最后,利用Matplotlib函數與Gephi軟件分別進行散點圖和關聯網絡圖可視化,更好地解讀聚類分析和關聯分析的結果。疾病癥狀聚類散點圖中,同一形狀顏色的點代表同一類別。疾病部位關聯圖中,每個節點代表一個部位,節點越大代表疾病部位出現次數越多,節點間連線,反映了疾病部位之間聯系的強弱,權重越大代表聯系越強。
3.3.1 疾病癥狀類別分析可視化
由于不同的疾病在癥狀上存在一定的相似性,因此病癥聚類分析利用疾病癥狀的相似性聚類,以期將疾病劃為多個類,探索同一類別下疾病與癥狀間的情況,以此更好地區分不同疾病的相似癥狀,提高診斷的準確性。病癥關系分析中,提取了《密訣本》中的不同疾病及其癥狀的實體,采用手肘法確定了聚類所形成的簇為4,利用Python進行K-means聚類分析,如圖2所示。疾病癥狀聚類結果中,藍色圓點、綠色圓點、紅色五角星和天藍色圓點分別屬于聚類類別0、1、2、3。
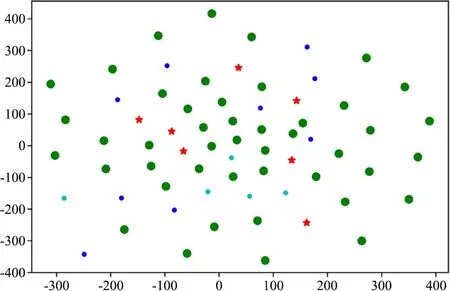
圖2 疾病癥狀聚類結果
從整個聚類分析的結果來看,可以直觀看到類別1數量最多,而類別0中的疾病有不消化癥、胃病、大腸病、便秘等,癥狀排在前幾的也是呃逆、疼痛、腸鳴、不消化,與腹瀉、腸胃等疾病有關,此類別下還有痼疾痞塊、脾病等,說明它們之間在癥狀表現上有一定相似性。類別1的數量較多,有45種疾病,涉及的疾病種類更多樣化,如頭部疾病、口腔病、眼病、鼻病、耳病等,癥狀上多是疼痛、腫脹、發癢、發熱、刺痛、口苦等,說明這些疾病常見的癥狀主要是疼痛發癢等。類別2癥狀上多是疼痛、腫脹、刺痛、腸鳴、脹滿,涉及的疾病相比較而言多是與潰爛、瘡癥等相關,還有就是臟腑、內臟等疾病。類別3多是失眠、熱癥、疼痛、刺痛、尿色等癥狀,全是與熱癥有關的疾病。
關于疾病的診斷,從癥狀上來看,疼痛、刺痛等相關癥狀出現頻率最高,這也是身體最直觀的反應。從整體上來看,不同的疾病的癥狀表現有其特殊性,病癥聚類分析通過疾病癥狀進行聚類,可以幫助梳理疾病在癥狀表現上具有的相似性,提高診斷的準確性。
3.3.2 疾病部位關聯網絡可視化
疾病的發生往往涉及到多個部位,因此在疾病部位的關聯分析中,本節利用從《密訣本》中提取的疾病及其發病部位的實體信息,據此建立了不同疾病發病部位之間的關聯并進行了可視化的分析。圖3為關聯可視化圖,可以清晰地看到藏醫學對疾病的認知是從身體的各個部位出發的,在進行疾病診斷時需要多方面考慮。
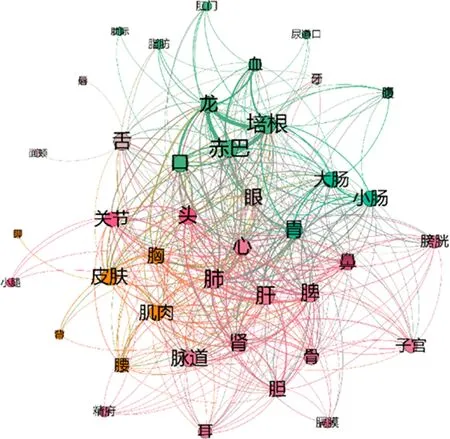
圖3 疾病部位關聯圖
藏醫學理論中,龍、赤巴、培根是藏醫學獨特的身體部位稱呼。在圖3中看到代表它們的點不僅碩大,并且之間的連線權重也大,說明它們不僅在疾病部位描述中出現的次數多,而且經常同時出現,聯系十分緊密。這種情況也再次印證了龍、赤巴、培根是藏醫學基礎理論的三大因素。此外,可視化中心部分呈現的疾病部位——口、頭、心、眼、胃等,也涉及到身體各個部位,連線亦錯綜復雜,體現了藏醫學認為身體部位不是孤立的而是相互聯系的思想。
3.4 病因關系分析及可視化
本節主要選取了《密訣本》中部分疾病的“病因”“病緣”“疾病分析”3個部分內容進行病因關系分析,選擇的疾病與熱癥相關——未成型熱癥、陳舊熱癥、擴散熱癥、虛熱癥、伏熱癥、熱癥擴散、濁熱癥、紊亂熱癥8種疾病。
在藏醫學理論當中,疾病的病因主要是指產生疾病的根本原因,而病緣則是指被引發的條件,可以具體劃分為“生發”“積發”“具體外緣”。生發是指可以使得疾病多樣化的條件,積發是指可以讓疾病集聚明顯的爆發的條件,具體的外緣則主要指的是可以使得疾病明顯、迅速的爆發。這3種形式均為藏醫學理論中的病緣,僅僅是因為表現的形式有所區別。
病因往往和疾病的產生相關,而病緣往往與疾病的發生相關,了解和把握疾病病因的關系,厘清疾病病緣的產生,對于把握整個疾病的爆發具有十分重要的意義。所以,在本節中,首先對疾病的病因在分詞的基礎上進行了詞云展示,以期迅速獲得與病因相關的信息中藏醫所重點關注的對象。其次,針對于病因病緣間的關系進行了關聯分析及可視化。關聯可視化的節點有疾病名稱、疾病病因、疾病病緣以及疾病分類,權重相同,著重展示疾病在病因方面的聯系。
3.4.1 病因詞云分析可視化
病因的詞云分析當中,利用《密訣本》中與熱癥相關的病因實體,對病因中所出現的詞匯進行了詞頻統計,然后利用Python形成了熱癥的詞云圖。病因詞云分析突出展示了在藏醫學中被反復高頻提及的詞匯,有利于迅速抓住藏醫學中的核心要素。在詞云圖中可以直觀地看到龍、赤巴、培根這三大藏醫學專用名詞在病因分析中也占突出位置,再次印證龍、赤巴、培根在藏醫學中的重要地位,是藏醫學的理論基礎。還可以清晰地看到此次分析的疾病種類——未成型熱癥、陳舊熱癥、擴散熱癥、虛熱癥等。除了上述的關鍵詞之外,年齡、自性、境域、時刻、飲食、起居等病因病緣也較為突出,展現了藏醫學在診斷疾病病因時的基本情況。詞云展示結果如圖4所示。

圖4 熱癥詞云圖
3.4.2 病因病緣關系分析可視化
病因關系分析可視化有助于了解疾病產生上的相似性,幫助疾病預防。在病因關系分析當中,提取《密訣本》中有關熱癥的疾病及其病因的實體,因為不同的熱癥在病因、病緣及病緣的產生上存著一定的相似性,因此,據此且基于Apriori算法建立不同熱癥的病因、病緣之間的關聯并進行可視化分析。如圖5所示,不同的疾病中涉及到了不同的病緣,但是不同的病緣的產生存在著相似趨向,因此從這個角度來看,虛熱癥、未成型熱癥、紊亂熱癥、熱癥擴散以及伏熱癥在外緣形成上存在一定的相似性。如虛熱癥的外緣為外緣虛熱,其形成多與年齡、境遇、時刻、病體等因素相關。未成型熱癥的外緣為外緣未成型以及外緣擴散,其形成多與自性、年齡、時刻等因素相關。伏熱癥的外緣為外緣隱伏其產生多與年齡、病體等因素相關。因此,上述闡述所涉及的熱癥及其外緣的產生上幾乎受到了一致因素的影響。其中紊亂熱癥、伏熱癥、熱癥擴散在病因涉及部位上更具相似性,其大多都涉及到了肝、腎、心等部位;未成型熱癥、陳舊熱癥、濁熱癥、擴散熱癥間在病因病緣上存在著一定的關聯,如未成型熱癥和陳舊熱癥之間存在著夾風陳舊熱癥的表現,而濁熱癥和陳舊熱癥在外緣上都是外緣陳舊等諸如此類的關聯。了解病因關系有利于醫生全面把握不同疾病之間的關系,判斷其他潛在疾病,從整體上制訂治療方案,這也體現了藏醫學中相互聯系的思想。
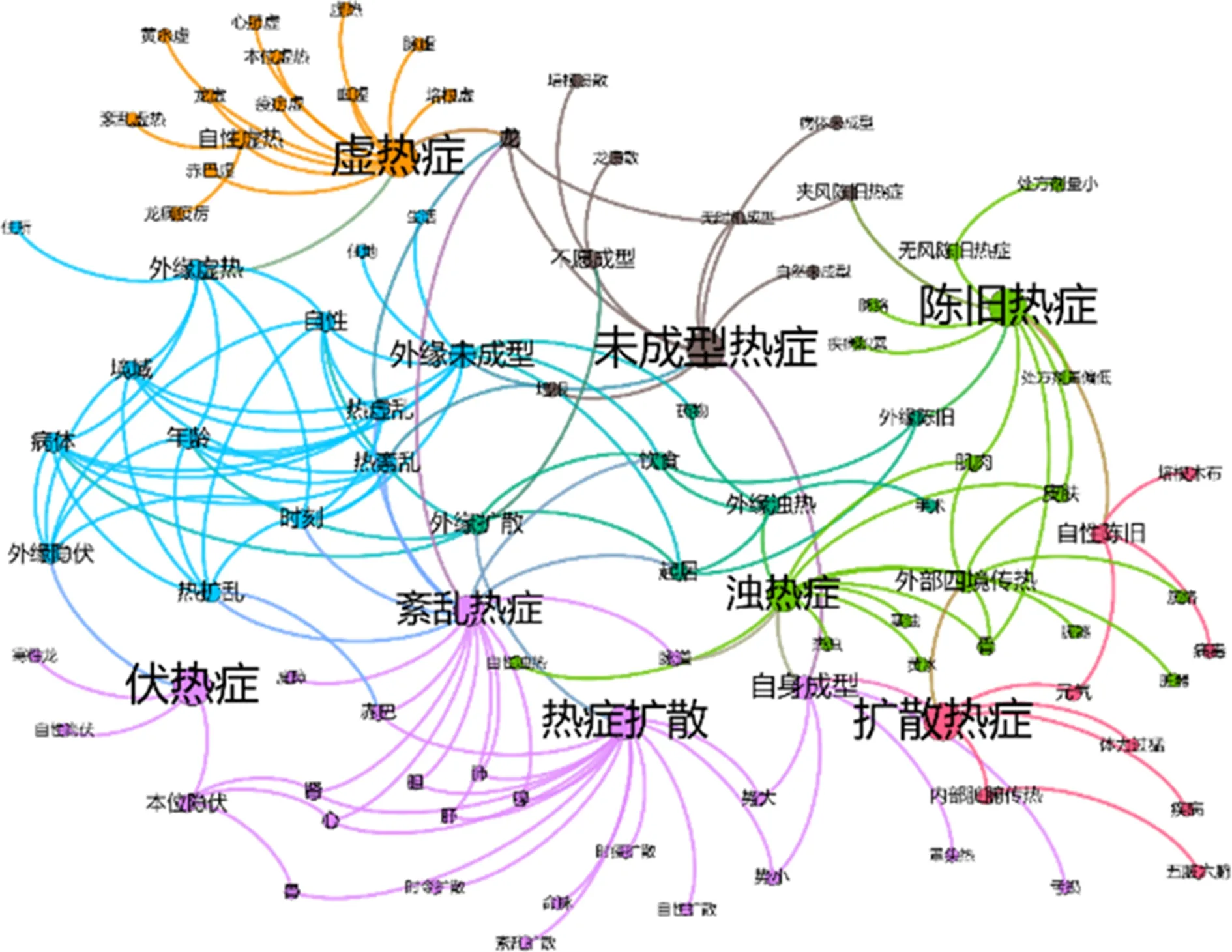
圖5 熱癥病因關系圖
3.5 用藥規律分析及可視化
關于用藥規律的分析首先進行用藥基本情況統計,之后再依據每組處方的藥材情況分別進行聚類分析與關聯分析。本節中,K-means聚類分析展現的是用藥相似性之間表現的主治疾病、方劑類型的關聯情況,而基于Apriori算法的關聯分析展現了藏醫學的常用藥材與常用藥材組合,節點代表的每一種藥材,權重代表使用的藥材之間的關聯強弱程度。
3.5.1 用藥基本情況統計
用藥基本情況分別對方劑類型、處方用藥以及主治疾病進行了統計。如圖6所示,用以分析的用藥數據中方劑類型共有15種,數量從多到少依次是散劑、湯劑、瀉藥配方、草藥配方等。其中散劑配方數量遙遙領先,共有123方,接著是湯劑74方,瀉藥配方50方,草藥配方40方等,方劑種類大多還是消除疾病的處方。
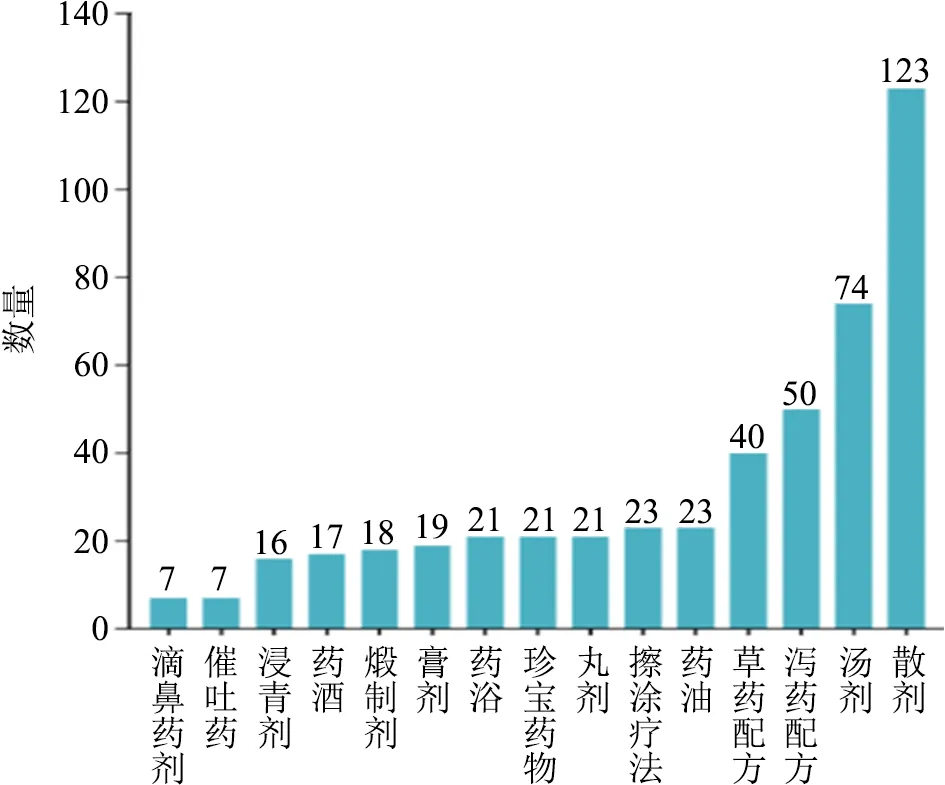
圖6 方劑類型統計情況
其次,對處方整體用藥情況進行統計。因涉及藥材種類繁多,只截取了前20進行可視化展示。如圖7所示,可以清楚地看到訶子、蓽茇、小豆蔻、紅花、白糖的數量相比較其他藥材明顯更多且差距較大,而后續藥材使用數量的差距就開始變小,但其他藥材使用量差距較小。從表1剩余部分藥材統計情況中,也可以觀察到藥材使用頻次的差距也是十分小的。
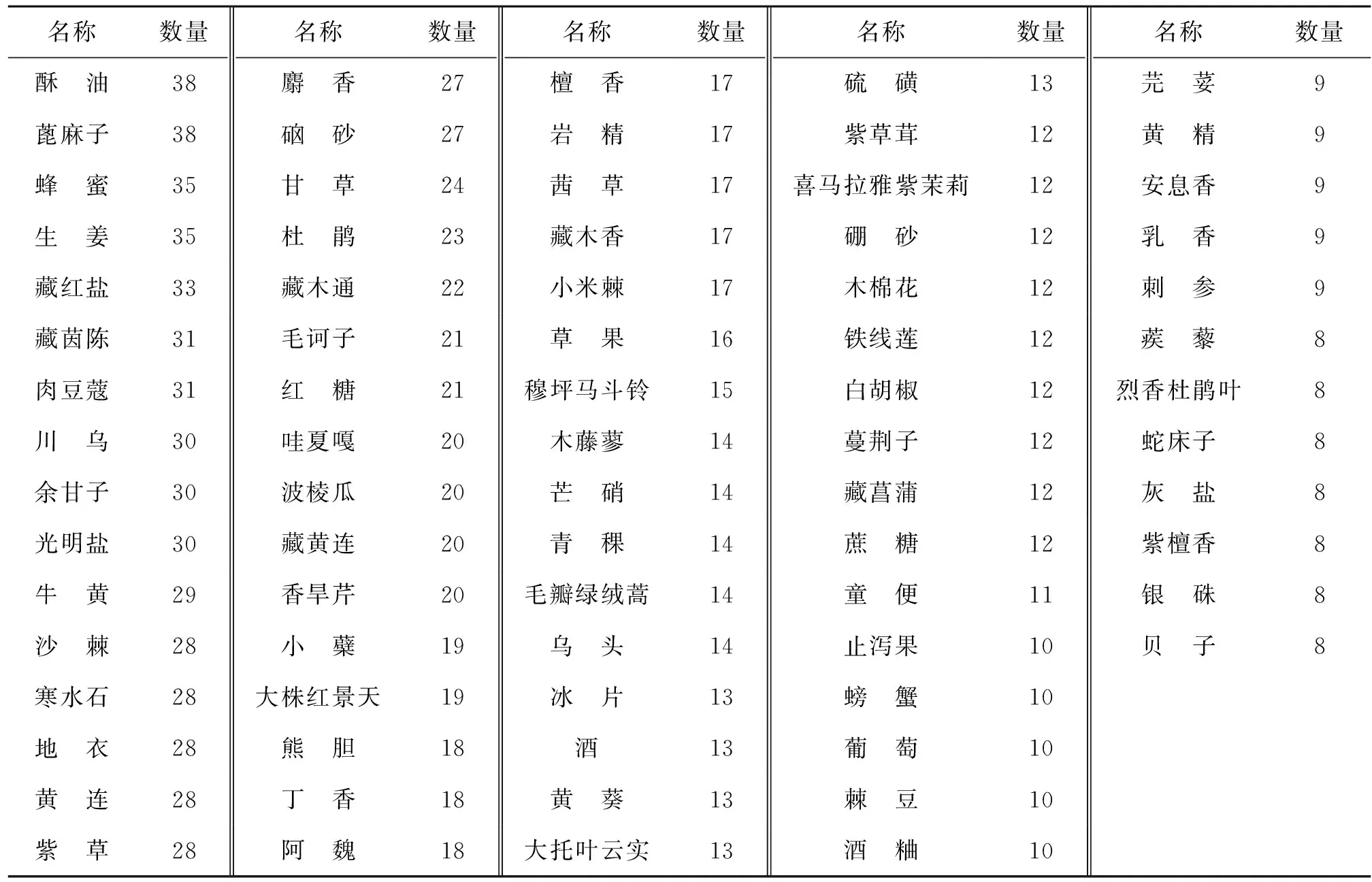
表1 剩余部分藥材統計情況
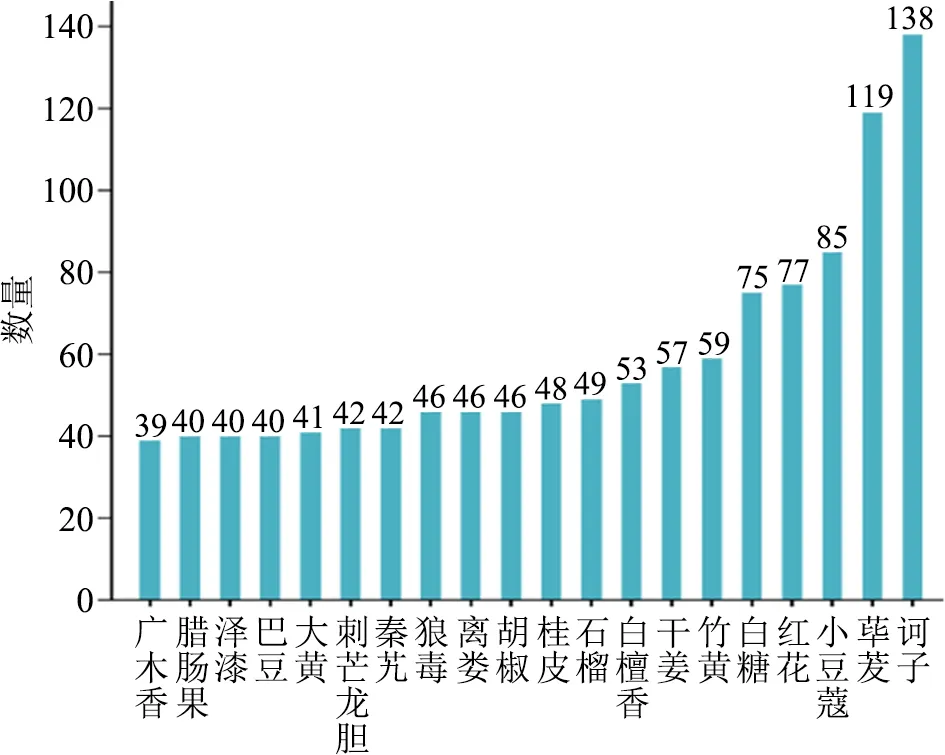
圖7 藥材統計情況
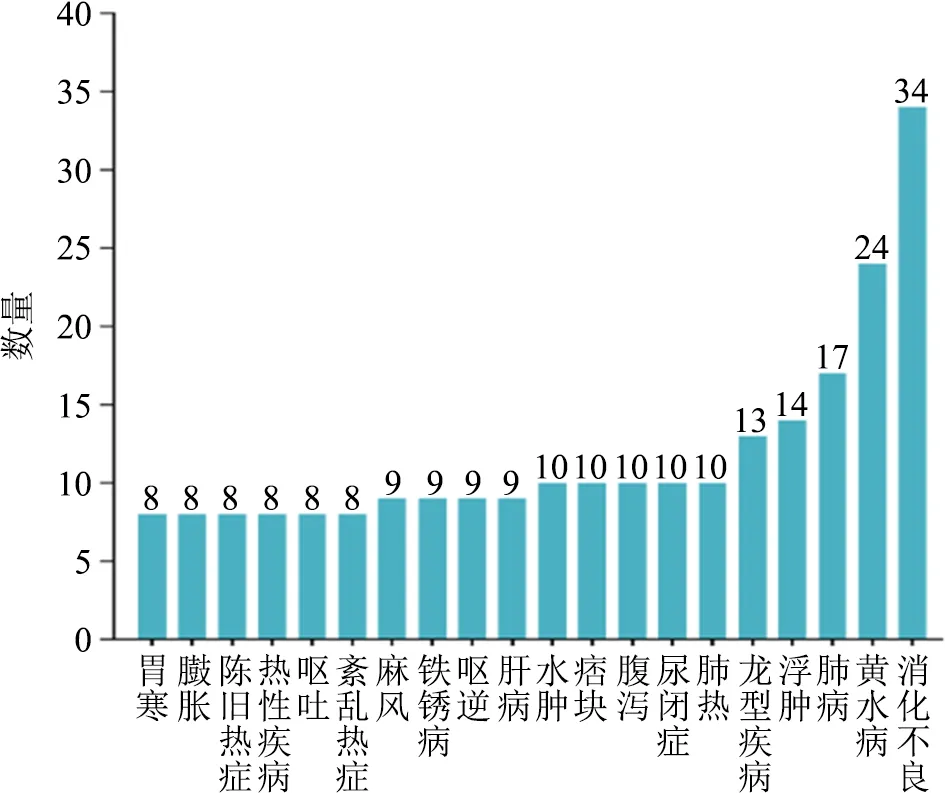
圖8 主治疾病統計情況
用藥藥材的統計是對藏醫學用藥的整體了解,這可以看出藏醫學用藥偏向于生活常見食材,這反映藏醫學優先考慮以食養病的思想。同時藥材統計中一些較為罕見的藥材,也將藏醫學與其他醫學用藥方面的特殊性區分開來。
最后是對主治疾病的統計,可以看到消化不良以及黃水病排在前列,數據中也有不少關于熱癥的疾病。《密訣本》中就提到很多關于熱癥的講述——熱癥的總治法、未成型熱癥、虛熱癥、伏熱癥、陳舊熱癥等,因此《后序本》中關于熱癥治療也不少。此部分的統計是對藏醫學主治疾病的基本了解,也為后續新處方預測分析的疾病選擇做了前期了解。
3.5.2 藥材關聯分析可視化
基于Apriori算法的藥物關聯分析,其目的是探尋藏醫學在治療疾病時所使用藥材間存在的關聯與規律。藥材關聯分析利用了《密訣本》中不同疾病治療所需的藥方實體,根據不同的藥材在不同處方的共現來建立不同藥材之間的關聯并進行了可視化分析。如圖9所示,可以清晰地看到較為突出的點有訶子、紅花、蓽茇、白糖、小豆蔻、白檀香、竹黃等,這些藥材同樣是出現頻次最高的幾類藥物,說明它們是藏醫學用藥的重要藥材。接著觀察線條的權重,可以直觀地看到藥材間關聯的緊密程度,即哪些藥材之間同時使用的頻率更高。
藍色線條中,以訶子為中心的藥物——刺芒龍膽、離婁、巴豆、臘腸果、澤漆、白檀香等,相互之間聯系就很緊密。此外,紅花、竹黃、小豆蔻、蓽茇之間的聯系同樣十分緊密,再向外桂皮、胡椒、石榴、白糖等的聯系也較為突出。從圖中還能觀察到部分藥材的聯系是獨立的,由于參數設置的原因,不能說這些獨立的藥材與其他藥物之間沒有聯系,只能說明關聯很弱。
可視化結果直觀地展現了藥材的重要性以及藥材之間關聯的強弱,這些關系反映出藏醫學用藥的常用藥材以及常用藥材組合,為理清藏醫學用藥規律有極大幫助。
3.5.3 藥材類別分析可視化
在藥物類別分析中提取了《密訣本》中不同處方的方劑類型實體以及藥材實體,是根據處方用藥情況進行K-means聚類,觀察聚類結果中同一類別下藥劑類型和主治疾病的情況。圖10為聚類可視化結果,藍色圓點、綠色圓點、紅色五角星、天藍色圓點、紫色五角星分別代表聚類類別0、1、2、3、4。圖中可以直觀地看到天藍色圓點最多,即類別3數量最多,結合整個聚類分析結果,類別0中數量最多的藥劑類型是散劑與丸劑,主治疾病大多是消化不良,用藥藥材前幾有胡椒、蓽茇、生姜、藏紅鹽、小豆蔻等;類別1中則是瀉藥配方數量最多,主治疾病中脈病、頭部疾病以及涉及五臟六腑的占比較多,藥材中澤漆、訶子、刺芒龍膽、大黃、狼毒等排在前列;類別2最多的仍是散劑,其次是膏劑、藥油,疾病上突出的是熱癥相關疾病,藥材則是紅花、竹黃、白糖、訶子、牛黃等;類別3中是湯劑、散劑,主治疾病上主要是黃水病、消化不良和龍型疾病,藥材主要有訶子、秦艽、地衣、紫草、黃連等;類別4最多的仍是散劑,主治疾病則是消化不良、嘔逆、肺病、腹瀉和痔瘡,藥材主要有蓽茇、小豆蔻、干姜、桂皮、石榴等。
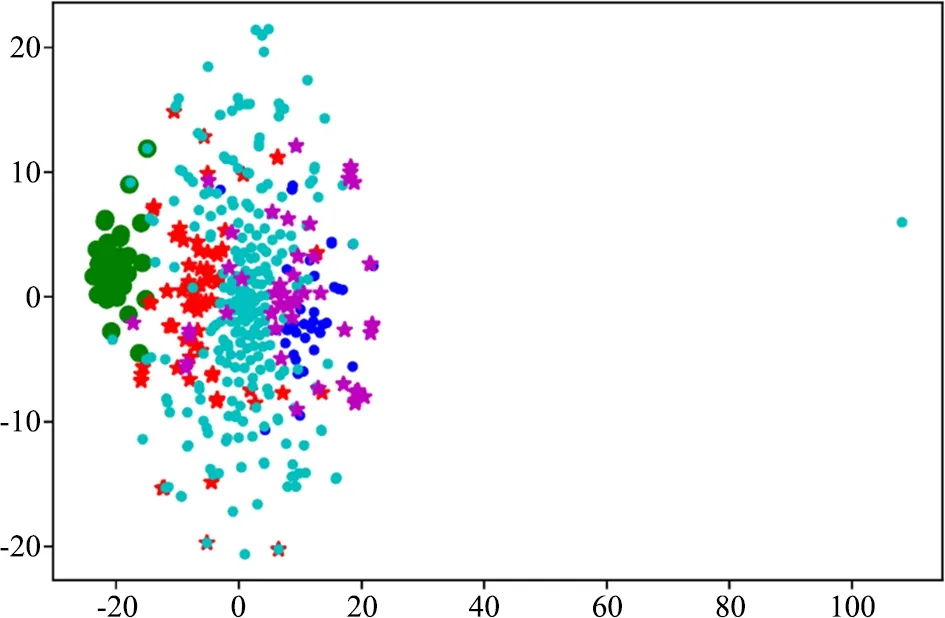
圖10 藥物聚類結果
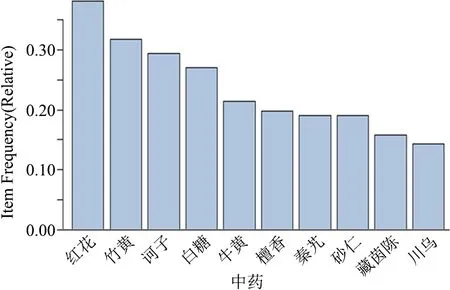
圖11 中藥使用頻率統計圖
聚類結果體現出了不同主治疾病之間的聯系,并且對于發現同類疾病新的治療藥物具有一定的參考價值,這同時也體現了不同的藥劑類型在治療不同疾病時的一種相似性,如研究發現散劑在治療消化不良以及與消化系統相關的疾病中使用最多,瀉藥的配方多和內臟相關等,這些發現對于理解藏醫的醫學思想有巨大的幫助。當然不同疾病需要不同類型的藥劑,這同時也說明了在藏醫學中認為,不同的藥劑類型對于疾病的治療效果也是存在著差異的。
3.5.4 方劑藥材偏向性分析
考慮到每一類方劑數量不等,對各種類型方劑在不同類別中的占比進行了統計,如表2所示。方劑類別占比情況有助于了解不同方劑中使用藥材的偏向性。類別分布中,瀉藥配方在類別1中占比最大,而其他方劑幾乎沒有出現在此類別中,可以看出瀉藥配方在藥材使用上與其他方劑差異較大。
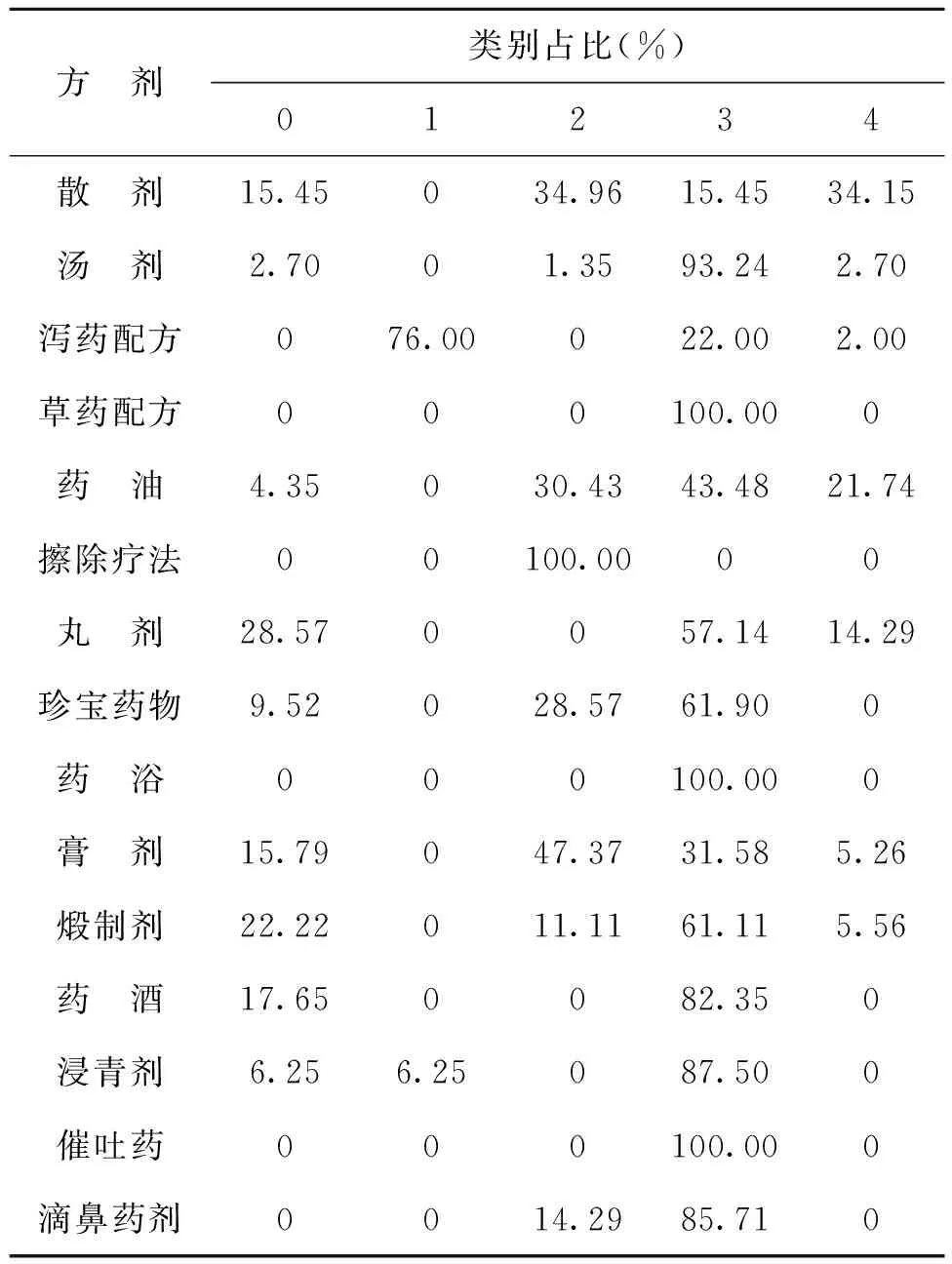
表2 各方劑類別占比情況
從表1來看,藥材的使用偏向性除了受到疾病的影響以及藥物作用效果的影響,同樣也受到了藥物使用方法的影響,不同的藥物要根據其特性來組成不同的藥劑,以此來最大程度地保留藥材效用。如湯劑在類別3中占比最大,該類目下的訶子、秦艽、地衣、紫草、黃連、廣木香、沙棘等藥材都是湯劑慣常使用或可考慮使用的藥材。
3.6 新處方預測分析
新處方預測是利用該類疾病現有處方的用藥規律預測新的用藥處方[41],本研究選取的是主治疾病與熱癥相關的處方進行新處方預測分析。數據主要來源于《四部醫典》的《密訣本》以及《后序本》與治療熱癥相關的處方,共有124個處方被錄入到R語言中進行數據分析。
這些處方所處理的熱癥包括熱癥總治、陳舊熱癥、擴散熱癥、伏熱癥、紊亂熱癥、寒熱、濁熱癥、熱癥擴散治療法、虛熱癥、未成型熱癥共10個方面。
這些數據輸入到R語言中進行數據分析,同時也對處方中的藥材名稱進行了統一,以此來確保藥方的準確性。同時,為了保證研究的嚴謹性,也對相應的處方根據《中華本草》進行了合理完善。藥材規范如表3所示。

表3 藏醫藥材規范表
首先利用R語言的itemFrequency的數據分析功能,對與治療熱癥相關的藥物進行用藥頻次統計,結果如表4所示。
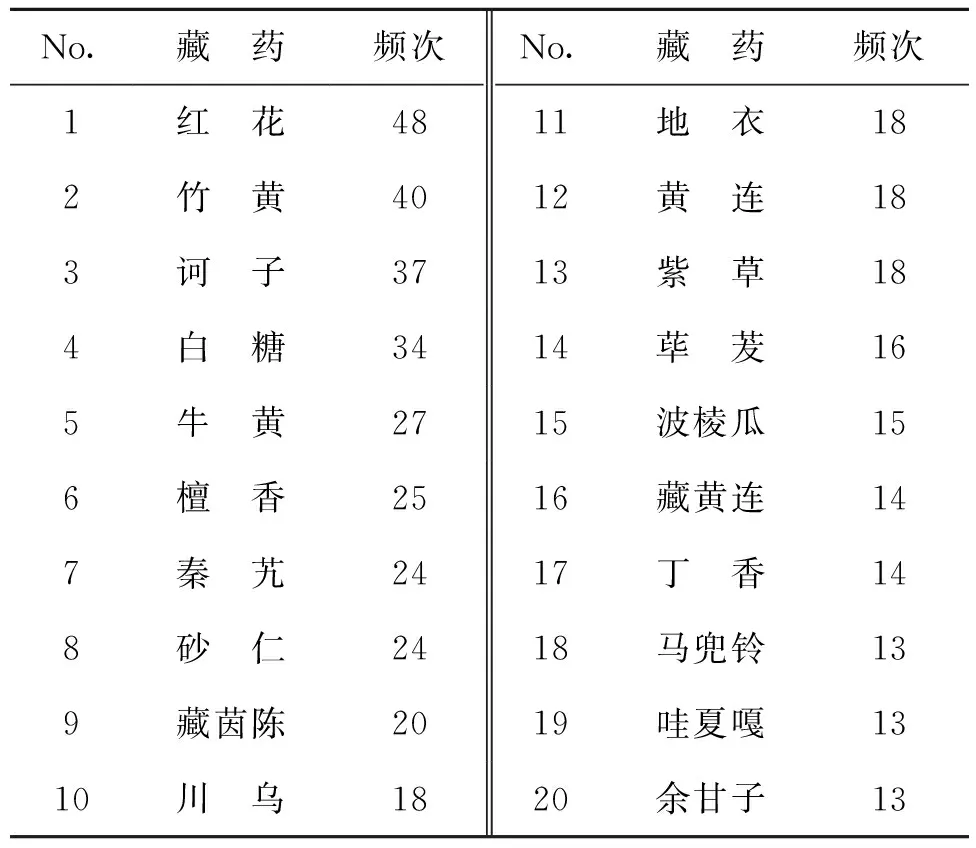
表4 藏醫治療“熱癥”方劑中使用頻次前20的藥材
使用頻次從高到低排列,依次為紅花、竹黃、訶子、牛黃、檀香、秦艽、砂仁、藏茵陳、川烏,這體現這些藥物在治療熱癥方面為藏醫比較常用的藥材。“紅花”作為藏醫中治療“熱癥”最為常用的一味藥材,它的使用率達到了30%左右,紅花是藏醫中應對熱癥效果比較出眾的一味藥材。當然,其中也發現一些有趣的現象,如在藏醫用藥中大部分的藥物均為藏醫比較獨特的藥材,如藏茵陳、哇夏嘎等,但白糖在藏醫治療熱癥方面使用頻率較高,與此相類似的是中醫藥中的“白砂糖”也是一味清熱的藥物,從這一方面來看,可以看到除藏醫其用藥的獨特性以外,在某些方面與傳統的中醫還存在一些關聯。
基于關聯規則的藏醫治療“熱癥”的組方規律分析中,將支持度設為0.06,置信度設為0.09,得到基于124個處方的58條關聯規則數據。在關聯數據的處理中使用了比較經典的Apriori模型,在這一模型中常用的衡量標準有支持度(Support)、置信度(Confidence)以及提升度(Lift),支持度在本研究中被認為是某一藥物出現的頻次,置信度則是指某對或者某幾個藥物共同出現的頻率,提升度則是指前一個藥物出現對于后一個藥物出現的提升水平,這反映出關聯規則的有效性。下面給出支持度、置信度以及提升的公式定義[42]:
Sup(藏藥)=P(藏藥)
ConF(關聯規則)=P(后一味藏藥|前一味或幾味藏藥)
Lift(關聯規則)=P(后一味藏藥|前一味或幾味藏藥)/P(藏藥)
將前10條的關聯規則按照其提升度的從低到高排序,如表5所示。
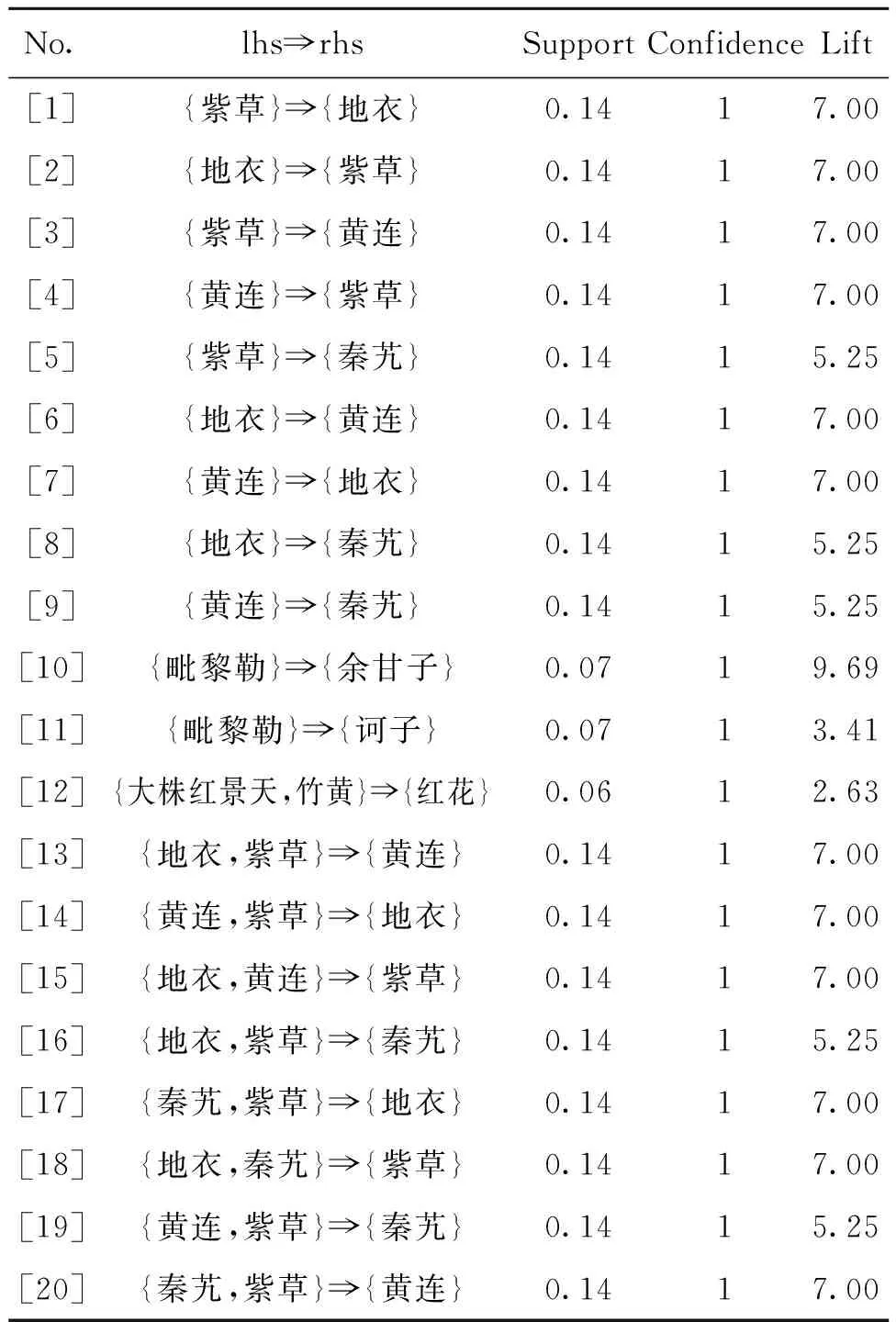
表5 Confidence>0.09前20關聯規則排序
在上述的藥物關聯圖中,可以看到節點的大小表示該節點的置信度的大小,而顏色的深淺則表示關聯規則的提升度,基于124個處方所發現的關聯規則提升度均在合理的區間。
從圖12可以看到,不同的藥物根據其之間的相似性分別成為了不同的類別,地衣、黃連、秦艽、紫草、大株紅景天的距離比較近,說明這幾味藥材在治療熱癥方面是比較常用的藥材組合。中間的部分,以紅花為中心,向外擴展鏈接了竹黃、牛黃以及丁香等,這說明紅花作為一個重要的中心節點,在藏醫中常常與其他藥材進行組配治療。右邊則是訶子、毗黎勒以及余甘子,這3味藥材是藏醫中俗稱的“三果”,是治療熱癥中極為常用的藥材組合。

圖12 “熱癥”藥物關聯圖
通過上述的關聯規則的展示以及可視化,可以直觀地看到藏醫在治療“熱癥”方面比較常用的藥物組合以及藏醫常用的核心藥物,這對于理解藏醫的用藥思路以及治病思路有很大的幫助。
通過關聯規則的呈現得到了藏醫的核心藥物,在此基礎上選取治療熱癥中使用率較高的前20味藥材來進行新處方的知識發現。
首先對前20味的藥材進行數據處理,本文將這20個藥材在每個處方中出現的情況,定義為二分類變量,結果如下:

將處理好的數據輸入到Spss26.0中進行數據處理,利用系統聚類的方法進行聚類,將最小聚類數量約定為5,最大聚類數量約定為10,利用組間鏈接的方法形成新的聚類,結果如圖13所示。

圖13 新方生成的層次聚類結果
此部分目的在于,依托于高頻的治療熱癥的藥材,根據他們之間的相似度距離來形成新的處方,先前的研究將新處方生成均為3~5味的藥材組合[43],所以據此將本研究新處方的藥材組合約定為3味、4味以及5味藥材,形成的備選處方如表6所示。以上就是利用藏醫治療熱癥的處方所形成的新處方預測,從數據處理的角度看來,利用藥物之間的關聯規則形成新的治療方案,是未來值得去探索的一個方向。這些研究成果有利于醫學領域發現新的治療方案,為現有的治療提供一個參考。本研究只是從數據層面提供一個基本的探索方向,新處方的具體效用還需實踐進行檢驗。

表6 基于層次聚類的藏醫治療“熱癥”的新處方預測
4 結 語
本研究從數字人文視角出發,以《四部醫典》這一經典藏醫學古籍為內容主體,利用文本分詞、統計分析、關聯分析、聚類分析、可視化技術等相關工具方法,對《四部醫典》中的《密訣本》《后序本》分別進行病癥關系分析、病因關系分析、用藥規律分析以及新處方預測分析,挖掘藏醫學古籍價值內涵,推動藏醫學古籍的傳承和利用。
在技術上,利用統計分析、關聯分析、聚類分析等方法,提取藏醫學古籍中可用的數據信息,對數據進行整理,得到可進行分析的結構化數據,為藏醫學古籍內容挖掘提供了一個可探索的方向。在內容成果上,主要有以下幾點:①對疾病癥狀的聚類分析不僅能得到疾病的類目情況,還梳理出疾病在癥狀表現上具有的相似性,有助于疾病診斷;②病癥的關聯分析印證了龍、赤巴、培根在藏醫學中的重要地位,還體現出人體是一個整體的系統,身體各部位之間緊密聯系;③病因分析中,龍、赤巴、培根等是重要的疾病發病的部位,境域、時刻、年齡等是大部分疾病的病緣,這些也體現出藏醫在診斷疾病病因中的基本情況信息;④病因關系的分析展示了不同熱癥之間的關聯關系,這有利于了解不同疾病在疾病產生時的相似性,幫助疾病預防;⑤從用藥統計情況來看,藏醫的處方種類比較多,其中散劑、湯劑類別的處方最多,從藥材來看,訶子、蓽茇、小豆蔻、紅花、白糖等是藏醫最常見的藥材,而這些藥材的統計也體現了藏醫以食養病的思想,在治療方面,消化不良、黃水病以及與熱癥相關的疾病是處方主治最多的疾病;⑥藥物的關聯分析,直觀地展現了訶子、紅花、蓽茇、白糖、小豆蔻、白檀香、竹黃等各種藥材的重要程度和關聯情況,有助于了解藏醫學藥物組合情況以及新處方預測;⑦藥物的聚類分析,得到了藥材相似性體現出的主治疾病之間的聯系,并且這種藥材的相似性,有利于挖掘出同類疾病下新的治療藥物,以及能幫助了解不同方劑中使用藥材的偏向性;⑧新處方預測是對關聯分析與聚類分析的綜合運用,得到了熱癥疾病的核心藥物組合,進而得到新的用藥處方,為新處方的開發提供了參考方向。
本文以藏醫學古籍《四部醫典》為例,探索藏醫學古籍知識發現的新路徑,對藏醫學古籍資源乃至中醫學古籍資源的開發利用有一定貢獻,但還存在一定的提升空間。藏醫學古籍《四部醫典》共四部,其中第一、二部主要內容是藏醫學基本理論,第三、四部主要內容是疾病的治法和藥方,本文依據數據挖掘需要,將數據來源劃定為第三部和第四部,未來需要將第一、二部納入到研究范圍,進一步完善研究成果。除此之外,藏醫學領域中的其他有價值的古籍也是值得關注的研究對象,從而構建完整的藏醫學古籍知識發現和利用體系。
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
當代陜西(2021年17期)2021-11-06 03:21:36
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
電子制作(2018年18期)2018-11-14 01:48:24
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
山東工業技術(2016年15期)2016-12-01 05:31:22
