基于混合深度學習的藏醫古籍命名實體識別研究
2023-11-24 06:42:42邊俊伊
現代情報 2023年11期
關鍵詞:模型
劉 佳 邊俊伊
(吉林大學商學與管理學院,吉林 長春 130012)
藏醫的研究由來已久,因藏族地區獨特的地理人文環境而充滿神奇的色彩,藏醫與青藏高原文化生活環境密切相關,反映了千百年來藏族人民對自然、健康和生命的認知、探索,以及戰勝疾病的智慧與經驗成果。藏醫不僅在藏族地區廣泛流傳,更在維吾爾族、蒙古族,甚至在其他的國家和地區都有傳播,經過長期的沉淀,已經成為世界傳統醫學中不可分割的一部分。藏醫文獻數量巨大,在對少數民族醫藥文獻整理中,55個少數民族的醫藥古籍一共3 100種,其中藏醫就占了2 700種。但由于歷史久遠,保存條件簡陋,藏醫古籍文獻霉變、腐蝕、蟲蛀、損毀、遺失等現象十分嚴重。2022年4月,中共中央辦公廳國務院辦公廳印發的《關于推進新時代古籍工作的意見》[1],2022年10月全國古籍整理出版規劃領導小組制定的《2021—2035年國家古籍工作規劃》[2]等都提出要加強古籍保護與開發利用。對藏醫古籍知識的保護與傳承,深度開發與利用,對藏醫的文化教育、科學研究、臨床實踐、藥物開發,對維護國家文化主權與安全,弘揚中華優秀傳統文化,鑄牢中華民族共同體意識,具有重要意義。
本文以藏醫古籍文獻為對象進行命名實體識別(Named Entity Identification,NER)研究,利用深度學習技術識別、提取藏醫古籍中具有特定意義的實體,如疾病、癥狀、病因等,為藏醫古籍知識的深度挖掘與利用提供基礎與支持。
1 研究現狀
1.1 傳統的藏醫文獻研究方法
傳統藏醫文獻研究主要采用統計分析、可視化分析和知識組織等方法。在基于統計規則的方法中,才讓南加等[4]對《四部醫典》中治療“痞瘤”方劑配伍規律進行研究,利用統計和關聯規則的方法,抽取出相關的高頻次的藥物與方劑,以總結治療規律,這種方法對藏醫藥規律研究具有重要意義,但傳統的統計方法無法挖掘出潛在的、豐富的藏醫古籍文獻知識。文成當智等[5]以藏醫“味性化味”理論對《四部醫典》的用藥規律進行可視化的分析,詳細從“味性化味”理論視角,應用Gephi v0.8.2可視化軟件等方法梳理3 000余函藏醫古籍文獻,作者從藏醫更核心的理論對藏醫古籍內容、規律進行梳理與分析,但限于目前藏醫古籍文獻的數字化開發程度,所涉獵的古籍文獻量仍局限于一部古籍。娘本先[6]研究了藏醫古籍本草知識的描述方法,并利用其所構建的知識元和知識體模型,構建藏醫古籍本草知識庫,實現基于規則庫的知識檢索功能。上述研究中,對藏醫知識內容的研究多采取人工抽詞與統計的方式,準確性高,但是無法為大規模的藏醫知識抽取與開發利用提供支持。
1.2 基于機器學習的傳統醫學文獻命名實體識別方法
相較于傳統的藏醫文獻研究方法,基于機器學習的自然語言處理技術應用于傳統醫學文獻研究,為藏醫知識提取、檢索、問答系統構建以及元數據標注等提供了重要的參考。目前,命名實體識別方法在傳統醫學文獻的應用多集中在對傳統醫學文獻中的疾病、藥物的抽取上。羅計根等[7]提出,一種融合梯度提升樹的雙向長短期記憶網絡的關系識別算法(BiLSTM-GBDT),開始了機器學習方法在識別中醫文本實體領域的嘗試。Tao Q等[8]通過構建BERT-CNN-LSTM的文本建模框架,從上下文中學習字符的表示,來進行中醫藥說明書的文本實體識別。Chen T等[9]利用生物創造與化學疾病關系語料庫、中醫文獻語料庫和i2b2 2012時間關系挑戰語料庫,進行關系提取的預訓練模型BERT微調訓練。肖瑞等[10]采用BiLSTM-CRF模型對中醫文本中的疾病、草藥、癥狀3類實體進行實體抽取,獲得較高的測試結果。謝靖等[11]對古代中醫繁體文獻進行增強的SikuBERT預訓練模型研究,有效提高了中醫命名實體識別的效率。何家歡等[12]通過中國知網獲取藏藥藥理相關文獻155篇,構建中文藏醫藥藥理實體識別語料庫,設計基于BiLSTM-CRF深度學習模型的藏藥藥理命名實體識別方法,采用信息抽取技術從科技文獻中提取并識別藏藥藥理,為藏醫藥文獻研究提供新途徑。
上述研究為藏醫古籍的實體識別研究提供了方法與思路的借鑒。目前基于機器學習的藏醫古籍文獻研究成果仍較為匱乏。作為世界四大傳統醫學之一,藏醫學有其獨特的診療與用藥方案,完全復用中醫文獻的研究方法不能夠準確地反映藏醫學的知識特點,也不能精準地識別藏醫文獻中的實體與關系。
綜上,針對藏醫古籍文獻的內容分析仍以統計分析與共現分析方法為主。藏醫文獻體例的獨特性導致藏醫知識及其關系呈現分散、不明確等特點,無法直接復用傳統醫學文獻的方法進行實體識別。目前收錄藏醫資源的開放數據庫較少,尚未建立專門的藏醫語料庫,使得利用深度學習模型進行藏醫知識提取與深度分析研究方面的進展緩慢。而藏醫古籍文獻作為藏族文化與智慧的載體,包含豐富的傳統醫學知識,具有重要的挖掘價值,因此,基于藏醫古籍文獻的實體識別還有待更深入的研究。基于此,本文以小樣本的藏醫古籍文獻資源為研究對象,將人工標注與深度學習方法相結合,嘗試構建ALBERT-BiLSTM-CRF模型對藏醫古籍《四部醫典》中的疾病、癥狀、藥物、方劑等進行實體識別實驗,并與BERT-BiLSTM-CRF、BiLSTM-CRF、BERT 3種目前普遍使用的實體識別模型進行比較分析,以確定藏醫古籍文獻實體識別的最優模型,解決傳統命名實體識別方法準確率低的問題。
2 關鍵技術與藏醫古籍命名實體識別模型構建
本文利用Albert、BiLSTM、CRF模型等深度學習模型與自然語言處理技術構建藏醫古籍命名實體識別模型,旨在為藏醫領域知識圖譜的構建、知識檢索、知識推理等提供基礎與方法支持。
2.1 關鍵技術
2.1.1 ALBERT模型
ALBERT(A Lite BERT)[19]是BERT的改進版本,它擁有3個方面的創新。
首先是參數共享,降低Transformer Block的整體參數量級。BERT的Transformer編碼器是一個包含了Encoder-Decoder結構的編碼器,同時使用了多頭自注意力層以便處理更長的序列信息[20],而ALBERT模型只保留了Encoder的部分,降低了原來BERT的多層Block的迭代,使參數降低,從而實現參數共享。
其次是詞向量分解,有效降低詞向量層參數量級。BERT中的隱藏層(H)和編碼層(E)是相等的,如果詞表的大小是V,當V很大時,E參數變大,即V*H=V*E。在ALBERT中通過降低E的緯度進行因式分解,當H≥E時,即V*E+E*H,降低了模型的參數,提高了模型的性能。
最后是使用句子順序預測的自監督損失(Sentence-Order Prediction,SOP)方法,可以增強文中句子的上下文聯系。在BERT中使用的是下句話預測(Next Sentence Predict,NSP),NSP主題預測任務會使在學習中出現知識重疊的現象。而SOP避免了主題預測,使句子之間更具有連貫性,提高了ALBERT下游多語句編碼任務的性能。
2.1.2 BiLSTM模型
BiLSTM(Bidirectional LSTM)雙向長短期記憶網絡模型是由循環神經網絡模型LSTM改進得到的一種新模型。LSTM(Long Short-Term Memory)是長短期記憶網絡,在RNN(Recurrent Neural Network,RNN)循環神經網絡的基礎上增加了3個門結構,分別為輸入門、遺忘門和輸出門。分別控制變量的輸入、輸出和細胞單元的狀態[21]。門結構可以解決對于較長輸入的反向傳播過程中RNN出現梯度消失和梯度爆炸的問題。BiLSTM是雙向的LSTM模型,向前可以獲得輸入序列的上文信息,向后可以獲得輸入序列的下文信息。在Forward層從1時刻到t時刻正向計算一遍,獲得并保存每一個時刻向前隱含層的輸出。在Backward層沿著時刻t到時刻1反向計算一遍,獲得并保存每一個時刻向后隱含層的輸出[22]。最后在每一個時刻結合Forward層和Backward層的相應時刻輸出的結果獲得最終的輸出。
2.1.3 CRF模型
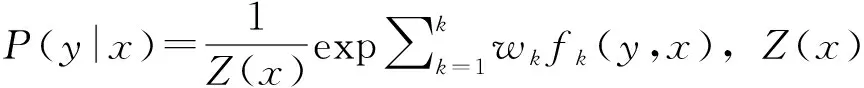
2.2 藏醫古籍命名實體識別模型構建
針對藏醫古籍文獻樣本量小、內容多樣,且語義復雜等特點,本文的命名實體識別算法以預訓練模型ALBERT為基礎,構建ALBERT-BiLSTM-CRF模型進行藏醫古籍文本的命名實體識別研究。
本文所使用的實體識別模型共有3層,如圖1所示,第一層是ALBERT層,先將輸入文本進行句子標記,句首標注[CLS],句尾標注[SEP],句子的上層抽象信息作為最終的最高隱層輸Softmax中,通過詞向量分解降低參數量級。ALBERT將每一層Transformer Encoder Block參數共享,之后學習的每一層,通過重用第一層并進行共享,使每一層都學習到了第一層的信息,相當于只學習了一層。最后將文本轉化為字向量X1、X2、X3…與BiLSTM層相連接。
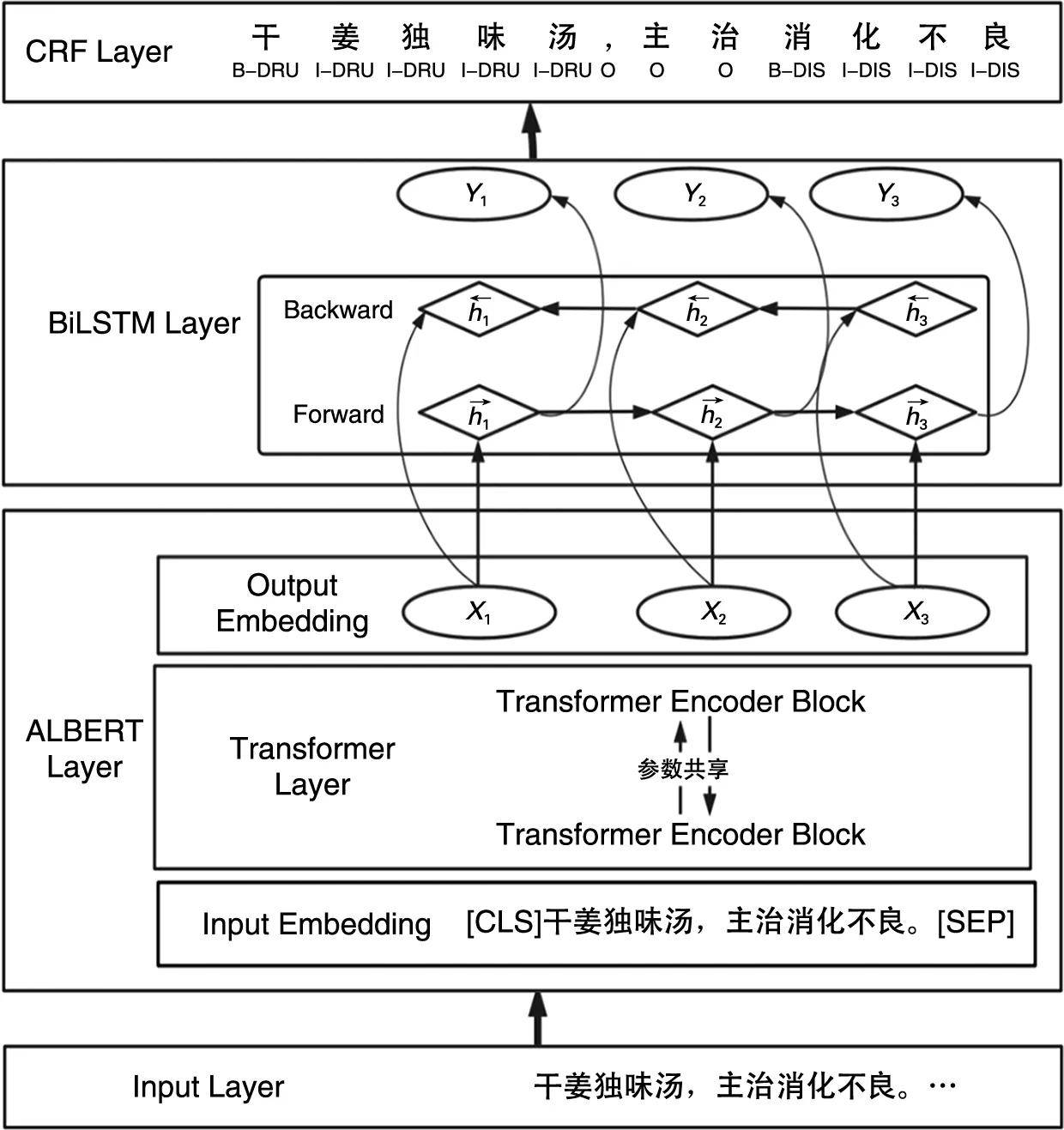
圖1 ALBERT-BiLSTM-CRF模型
第二層是BiLSTM層,通過學習正向的h(h1、h2、h3…)信息和反向的h(h1、h2、h3…),提取出上下文本特征,計算最大概率值,輸出Y(Y1、Y2、Y3…)。
第三層是CRF層,準確對BiLSTM輸出內容進行解碼,做實體類型的序列標注,為每個字符輸出最可能的實體標簽。
3 實驗與結果分析
模型實驗之初,需要確定數據來源并進行數據預處理,構建實驗數據集;然后針對藏醫古籍知識特點,設計、訓練、優化實體識別模型。
3.1 數據來源
藏醫古籍文獻種類繁多、復雜,多為半結構化的信息文本。目前中醫領域已經建立了不同規模的中醫語料庫,極大地推動了人工智能技術在中醫文獻知識挖掘、知識關聯與深度開發中的應用。然而,藏醫古籍中記載的藏藥、疾病名稱等有其獨特的命名規則與記錄方式,其語料在語法與內容編寫方面,與中醫語料存在較大的差異,因此需要對藏醫文獻預先進行精確標注,構建以藏醫語料為基礎的數據集,為后續智能化處理提供數據基礎。
《四部醫典》是一部藏醫理論與實踐相結合的經典著作,也是藏醫學的奠基之作,內容廣泛,涉及藏醫理論知識、臨床經驗、藥物功能、治療方法等。藏醫學的診療方法主要以《四部醫典》為依據,是藏醫研究中不可或缺的文獻,因此,本文選擇1987年出版的,由宇妥·元丹貢布等著、馬世林等譯注的《四部醫典》[13]為主要語料來源,輔之參考相關研究論文與參考資料,構建藏醫古籍實體識別實驗的數據集,以確保所構建的命名實體識別模型具有普適性與推廣性。
3.2 實體類型
在確定數據來源的基礎上,根據數據集特點來定義實體類型。命名實體識別的概念目前還沒有統一的定義,Marrero等總結了前人對命名實體的定義,通過分析和舉例等方式,最終得出應用方面的需求目的是定義命名實體唯一可行的標準[14]。本文以此為依據,通過分析《四部醫典》的內容,并參考相關傳統醫學命名實體研究,確定藏醫古籍的實體類型。
《四部醫典》中記載了許多臨床治療方法,除藥物治療外,還包括藥浴治療法、催吐療法、放血療法、灌腸法、鼻藥療法等特色療法。在藥物性能方面,《四部醫典》記載了湯劑、丸劑、散劑、膏劑等3 000余種方劑,對草藥的功效、屬性、氣味等都有詳細的記載。在專家的指導下,根據文獻內容特點,本文制定了命名實體識別模型中的實體類型及其標識,將具有藏醫特色的實體類型歸納為6類,疾病、病因、癥狀、藥物、方劑、療法,如表1所示。
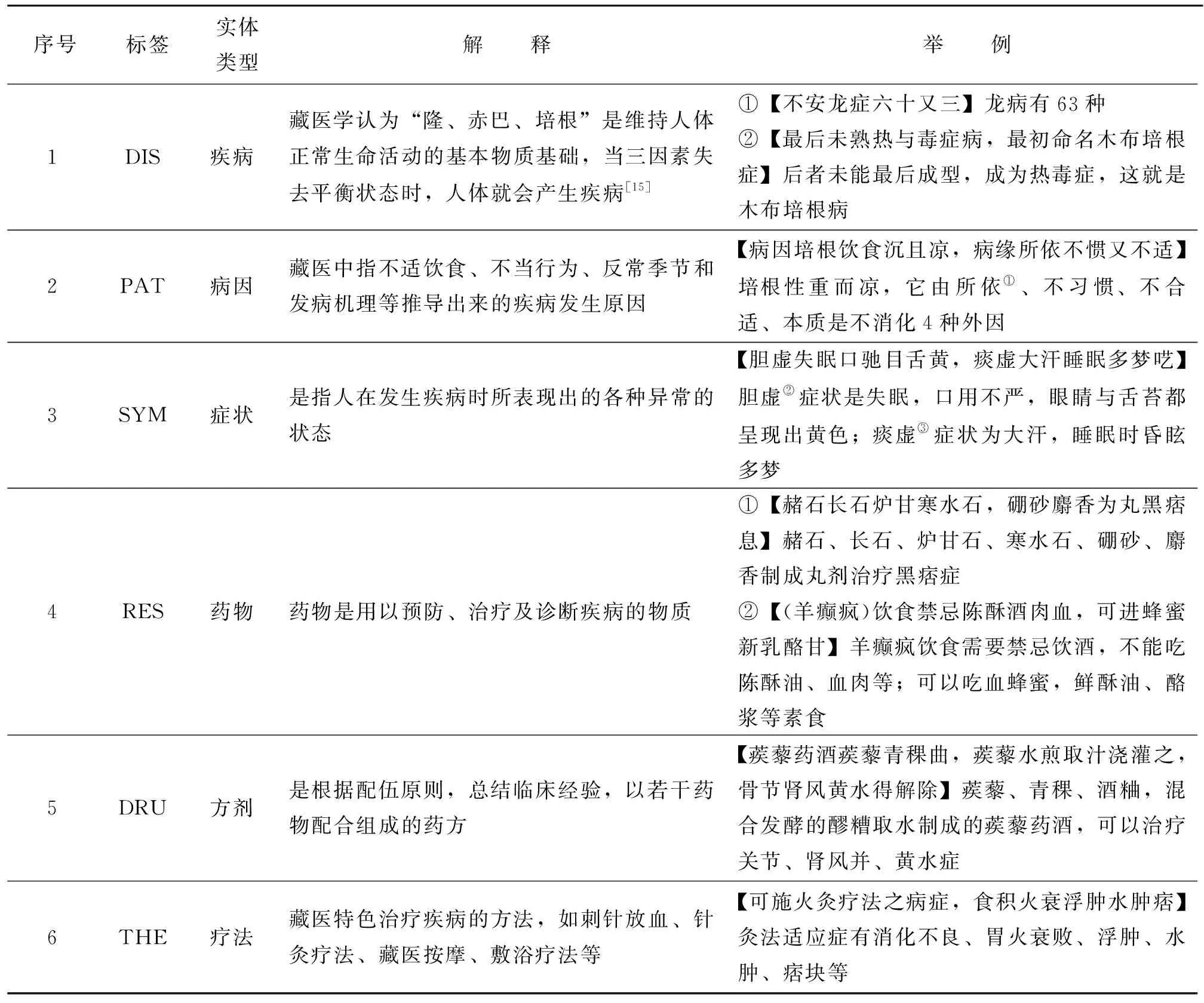
表1 《四部醫典》實體類型
3.3 數據標注
數據標注是使未經處理的文本能夠被機器識別和學習的信息處理過程,通常包括自動標注和人工標注兩種方式。自動標注是利用機器和算法對文本內容進行識別的方式;人工標注是標注人員利用標注工具對文本內容進行標識的方式。人工標注與自動標注相比具有高效、準確的優勢,但是在標注效率上要遠遠低于自動標注方式。鑒于上文所述藏醫古籍體例的獨特性,本文采用人工標注方式進行數據標注。
按照上文所制定的實體類型,對《四部醫典》進行人工標注。《四部醫典》共4部,分別是《總則本》《論述本》《密訣本》和《后序本》,包括基礎理論、生理解剖、疾病診斷治療的原則和方法、預防、藥物等內容。本文主要對《四部醫典》三、四部中約3萬字內容進行了人工標注,得到4 350條數據,并邀請具有藏醫背景的專業人員對數據集進行多輪的檢驗與修正,構建出藏醫詞表。具體標注示例如表2所示。

表2 人工標注示例
本文采用BIO標注法進行隨機標注,其中“B”表示實體的首部(Begin),“I”表示實體的中間(Inside),“O”則表示該元素不屬于任何實體類型(Outside)。在對文本數據進行分句的基礎上,對分句后的結果按照標注規則對語料庫中的疾病和藥物等進行序列標注。對語料中詞語的標注采用B/I-XXX的形式,B/I表示此詞是實體的內容,XXX表示實體的類型。O表示該詞不是實體中的內容。使用Label Studio平臺標注《四部醫典》三、四部,得到24 918個實體,其中,疾病類實體14 049個,病因類實體506個,癥狀類實體209個,藥物類實體8 919個,方劑類實體236個,療法類實體999個。標注示例如圖2所示。
3.4 實驗方法與參數設置
本文的實驗平臺為恒源云(GPUSHARE)云服務器Linux操作系統、2080ti(11G)GPU(顯卡)類型、16G運行內存、Python3.7.10編程語言、Tensorflow1.15.5深度學習框架。主要模型參數設置如下:字符向量長度為128,ALBERT隱藏層的大小為768,ALBERT學習率為2e-5。為了測試ALBERT-BiLSTM-CRF模型的性能,將標注語料按8∶2的比例劃分為訓練集和測試集,用于模型的訓練與測試,并從訓練集當中隨機抽出20%作為驗證集來評估模型效果。
3.5 評價指標
本文采用自然語言處理當中常用的精確度(Precision,P)、召回率(Recall,R)和F1-score作為度量指標,檢驗各個模型在命名實體識別中的效果[23],具體內容如下:
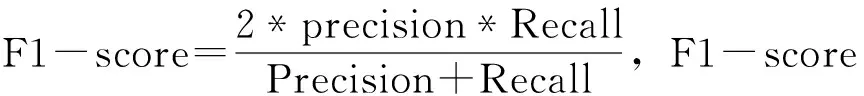
3.6 實驗結果分析
為檢驗本文所提出的藏醫古籍命名實體識別模型的性能,統一使用標注好的藏醫語料數據集,對目前命名實體識別研究中常用的BERT-BiLSTM-CRF、BiLSTM-CRF、BERT模型進行訓練和比較。4個模型的F1-score、Precision、Recall值如表3所示。
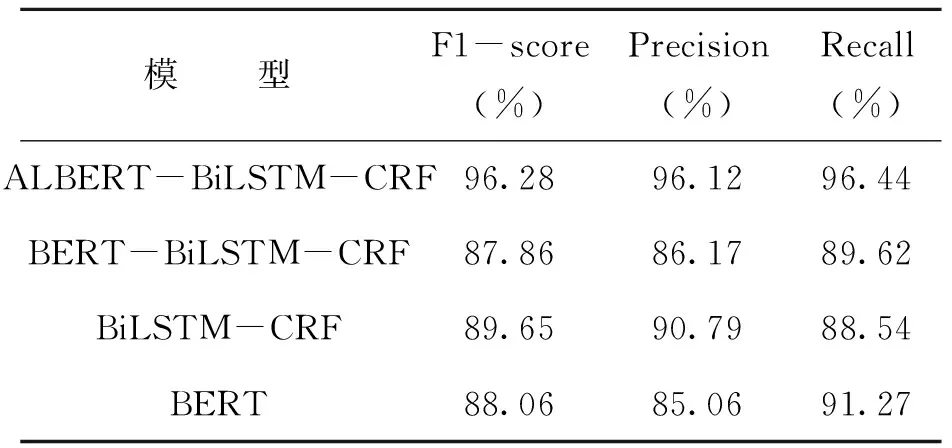
表3 模型對比結果
由實驗結果可知,4種深度學習模型在藏醫古籍文獻實體識別上存在一定的差異。其中達到最優效果的是ALBERT-BiLSTM-CRF模型,F1-score達到96.28%,說明該深度學習模型在藏醫古籍文獻這種小樣本數據集命名實體識別中取得的效果較好,可以實現較優性能。此外還觀察到,BERT模型與BiLSTM-CRF模型一起使用時,對F1-score沒有提升作用,反而造成F1-score降低。而BiLSTM與CRF的結合使用,則會對F1-score和Precision值有一定的提升作用。
如圖3所示,進一步分析ALBERT-BiLSTM-CRF、BERT-BiLSTM-CRF、BiLSTM-CRF、BERT 4種深度學習模型對不同實體類型的識別效果。以F1-score作為指標進行比較,由實驗結果可見,藥物(RES)類型的實體在各模型中識別效果最優。這是因為在《四部醫典》中,對藥物的描述較為集中,并且語義簡單,識別效果較好。而療法(THE)類型實體的識別結果在4種模型中的F1-score相對都比較低。在《四部醫典》中,療法數據較為復雜、分散,有的在介紹藥物效果中出現,有的在疾病治療方法中出現,療法描述的不規則性導致模型在識別療法時的難度增加,因此影響了模型訓練的效果。在今后的研究工作中,還需要進一步擴大訓練數據規模,標注更多語料來進行研究,從而改善和提高模型的識別效果。
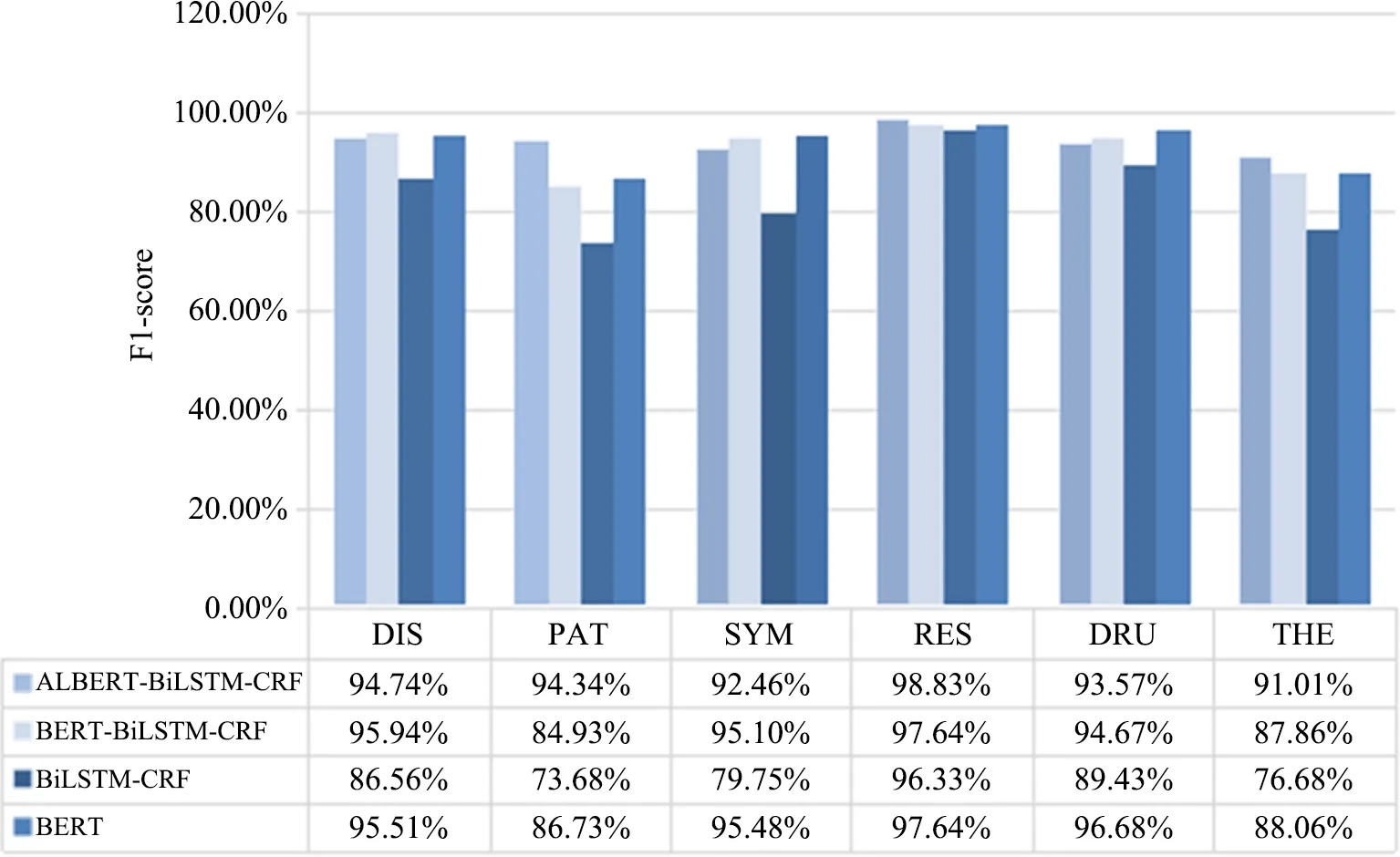
圖3 各實體F1-score對比
4 藏醫古籍命名實體的應用
運用機器學習與人工標注相結合的藏醫古籍命名實體識別方法,可以在藏醫古籍文本中識別出更多的藏醫知識實體。本文進一步對實體之間的關系進行分析,構建了藏醫古籍實體關系模型,如圖4所示。
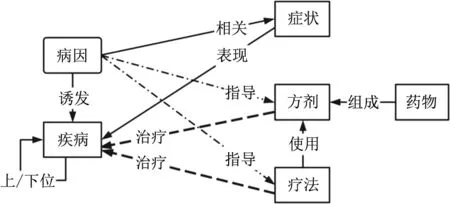
圖4 藏醫古籍實體關系模型
以《中醫藥學語言系統語義網絡框架》[24]作為標準,并借鑒其他中醫語義網絡模型,結合藏醫文本自身的特點,對藏醫實體間的關系進行規范化定義,如表4所示。
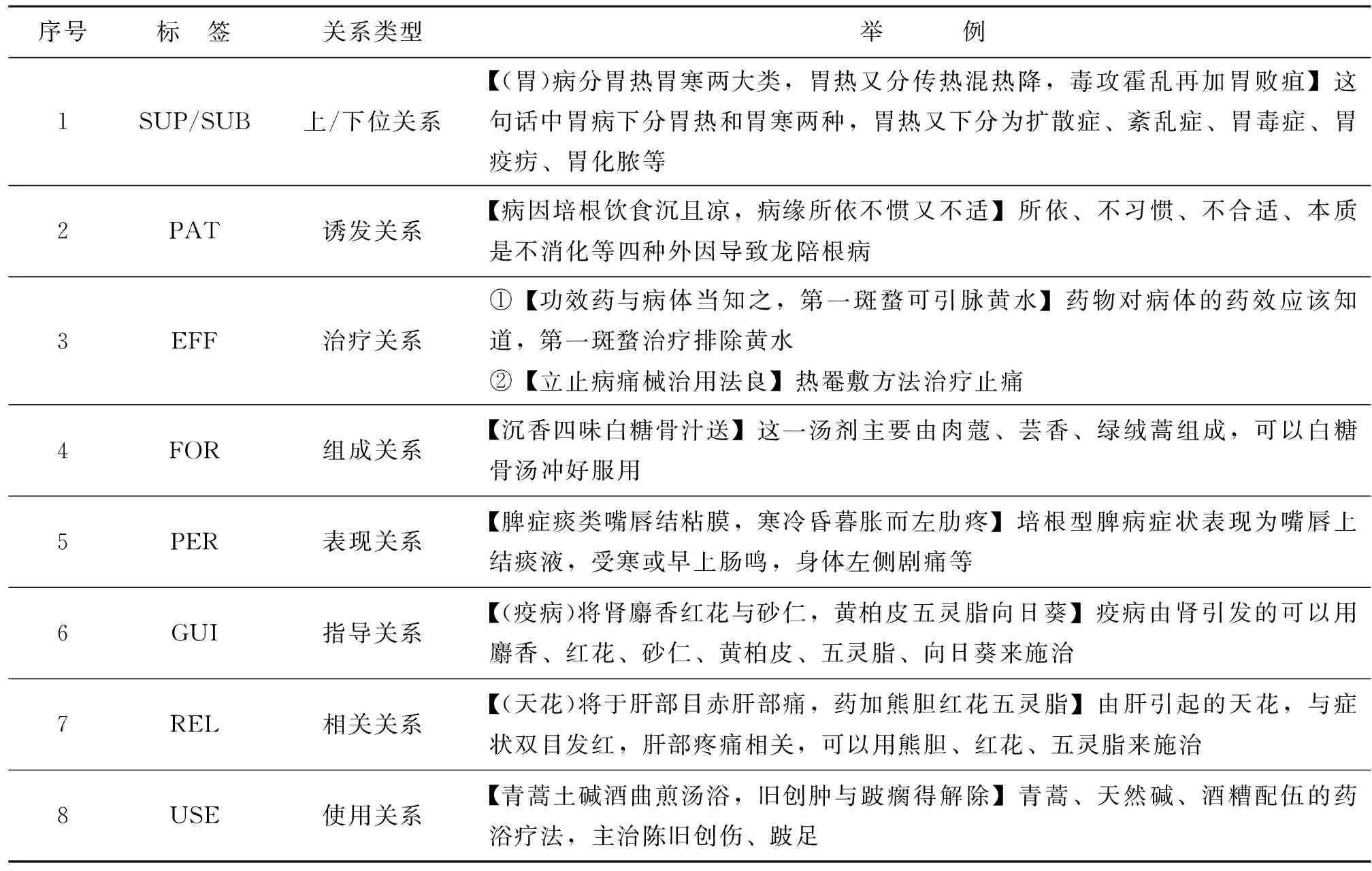
表4 《四部醫典》關系類型
本文利用Neo4j圖數據庫建立《四部醫典》知識庫。Neo4j本質上是一種由節點(實體)和邊(實體之間的關系)組成的關系圖,可以用來揭示知識之間的關系[25]。將《四部醫典》中識別出的實體存儲于圖數據庫中,依據關系類型表對不同實體類型進行關系的識別和連接,實現藏醫實體的關聯,并進行可視化展示。圖5是本文所構建的部分藏醫古籍知識圖譜。從該圖可以看出,圖中的節點向“龍”“赤巴”“培根”3個節點聚合,顯示出“龍”“赤巴”“培根”作為藏醫中的3個核心因素,在藏醫病理與診療中的重要地位與作用。對照藏醫古籍文獻內容,“龍”“赤巴”“培根”構成了人的生命三要素,疾病也是由于這三要素失衡所致。由此可見,藏醫古籍知識圖譜能夠反映出藏醫古籍文獻中的核心知識內容與知識關聯。
圖6是與疾病“熱癥擴散”相關的部分知識圖譜。圖譜清晰地顯示出,“熱癥擴散”包括“心臟熱疾擴散”“命脈熱疾擴散”“肝臟熱疾擴散”等類型的疾病,這類疾病由“赤巴”引起;由“赤巴”導致的疾病多呈現“口渴”“嘔吐膽汁”“口苦”等癥狀,圖譜中的“熱疾擴散”類疾病也多呈現出這樣的癥狀。通過觀察各種方劑的藥物構成可以發現,“紅花”節點周圍匯聚了多種方劑,可以初步判斷“紅花”是治療各類“熱癥擴散”疾病的核心藥物,可作為供藏醫研究者進一步進行實驗研究的依據。通過知識圖譜還可以對比分析不同疾病的病因與癥狀表現,指導方劑與療法的選擇,輔助藏醫工作者研究病機、病理,挖掘疾病用藥的規律等。藏醫古籍命名實體識別模型為藏醫古籍知識的挖掘與知識圖譜的構建提供了不可或缺的數據支持。
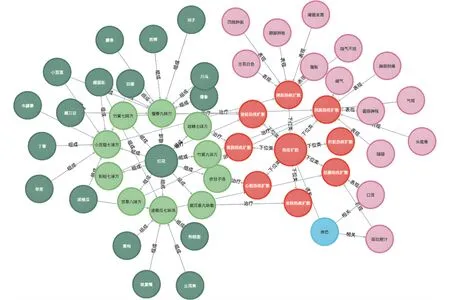
圖6 熱癥擴散知識圖譜
5 結 語
本文針對藏醫古籍知識的特點,將人工標注與深度學習的方法相結合,構建了基于深度學習的命名實體識別模型。基于4種深度學習模型,選擇具有“藏醫百科全書”之稱的、集藏醫理論與實踐知識于一體的藏醫古籍《四部醫典》進行實體識別實驗,以確保所構建的命名實體識別模型具有通用有效性。結果表明,ALBERT-BiLSTM-CRF模型對藏醫領域的實體識別效果最優。利用實體識別結果,構建了藏醫古籍知識庫與知識圖譜,為藏醫學的深入研究提供支持,也為藏醫知識的進一步深度開發與利用提供了語料基礎。
后續研究可以從以下幾個方面展開:擴大語料規模,提升藏醫實體識別模型的效果;進一步擴充、細化數據模型,以更全面地挖掘藏醫古籍文獻中的知識資源,支持藏醫古籍知識的研究;在已有的數據集上進一步訓練和優化模型,以提高模型在藏醫古籍中命名實體識別任務中的性能;對藏醫古籍命名實體識別系統進行功能模塊的開發,使其能夠被廣泛應用于藏醫潛在知識推理、醫學自動問答、輔助決策等領域。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
