基于改進YOLOv5s的飾品檢測算法研究
2023-11-25 11:56:26凡寧寧孫成宇陳虹宇
大連民族大學(xué)學(xué)報 2023年5期
凡寧寧,劉 爽,劉 佳,孫成宇,陳虹宇
(大連民族大學(xué) 計算機科學(xué)與工程學(xué)院,遼寧 大連 116650)
近年來,隨著深度學(xué)習(xí)技術(shù)的快速發(fā)展,目標(biāo)檢測技術(shù)已經(jīng)在許多領(lǐng)域中得到廣泛應(yīng)用。然而,在復(fù)雜場景中進行人物飾品檢測仍然是一個具有挑戰(zhàn)性的問題。人物飾品外觀特征復(fù)雜多變,尺寸比例有較大差異,在面臨多個人物和飾品的交叉遮擋、姿態(tài)變化、光照變化等影響因素時,大多數(shù)檢測模型的效果并不理想。因此,研究一種更準(zhǔn)確的人物飾品檢測算法具有重要意義。
在傳統(tǒng)的飾品檢測方法中,基于Haar-like[1]特征和HOG[2]特征的方法已經(jīng)被廣泛使用,但是這些方法需要手工選擇特征和調(diào)整參數(shù),存在工作量較大且準(zhǔn)確率較低等問題。相比之下,深度學(xué)習(xí)方法不需要人為地設(shè)計特征,可以直接從數(shù)據(jù)中學(xué)習(xí)到最優(yōu)的特征表示,因此在飾品檢測算法研究中也得到了廣泛的應(yīng)用。
主流的深度學(xué)習(xí)目標(biāo)檢測方法主要分成兩種類別。一類是one-stage算法,例如YOLO[3]和SSD[4]是基于回歸思想的單階段檢測算法;另一類是two-stage算法,例如R-CNN[5]、Faster R-CNN[6]和Mask R-CNN[7]是基于候選框的兩階段檢測方法[8]。針對飾品識別任務(wù),研究者們通過對YOLO系列算法進行改進,提高了飾品檢測的精度和實時性。賈世娜等人[9]使用多級特征融合和多尺度檢測等方法來提高YOLO算法針對小目標(biāo)的檢測效果。改進后的算法在一定程度上提高了精度,但是模型體積較大。陳勃旭[10]通過增加數(shù)據(jù)增強方法,提出一種新的小目標(biāo)數(shù)據(jù)集擴展與數(shù)據(jù)增強方法并采用anchor自適應(yīng)算法進行訓(xùn)練。同時岳茜[11]設(shè)計了一種新的損失函數(shù),提高生成框的采集水平,進一步優(yōu)化算法的性能。
YOLO系列算法在實際的檢測任務(wù)中由于硬件資源的限制,當(dāng)面對復(fù)雜的檢測環(huán)境時仍存在模型體積較大、準(zhǔn)確率不高,容易誤檢等問題。為解決當(dāng)前的技術(shù)難點,依據(jù)YOLOv5s算法的高性能特點,本文設(shè)計了一種基于改進的YOLOv5s的人物飾品檢測算法,采用輕量化的骨干網(wǎng)絡(luò)縮小模型體積,同時優(yōu)化注意力機制與空間金字塔池化結(jié)構(gòu)提升網(wǎng)絡(luò)的精度,最后改進損失函數(shù)提高模型對目標(biāo)尺寸的魯棒性。在人物飾品檢測數(shù)據(jù)集中進行驗證,并于其他檢測算法對比,驗證本文方法的有效性。
1 YOLOv5s目標(biāo)檢測算法
YOLO算法從總體上看,是單階段端到端的基于anchor-free的檢測算法。將圖片輸入網(wǎng)絡(luò)進行特征提取與融合后,得到檢測目標(biāo)的預(yù)測框位置以及類概率。而YOLOv5是YOLO系列中應(yīng)用最廣泛的,其擁有模型小,檢測速度快的特點。根據(jù)網(wǎng)絡(luò)結(jié)構(gòu)的大小以及特征圖寬度分成YOLOv5s、YOLOv5m、YOLOv5l。整體網(wǎng)絡(luò)結(jié)構(gòu)由主干網(wǎng)絡(luò)(Backbone)、頸部網(wǎng)絡(luò)(Neck)、預(yù)測輸出端(Head)組成。
2 改進YOLOv5s模型設(shè)計
本文主要從骨干網(wǎng)絡(luò)輕量化、注意力機制、特征融合和損失函數(shù)四個方面對YOLOv5s進行優(yōu)化。傳統(tǒng)的卷積網(wǎng)絡(luò)對硬件的要求較高,在設(shè)備資源限制下,較大的飾品檢測模型無法正常運行,所以提出基于Ghost卷積模塊的輕量型骨干網(wǎng)絡(luò),對整個網(wǎng)絡(luò)進行輕量化處理。為了更加充分的利用骨干特征網(wǎng)絡(luò)的原始特征信息,采用SPPFCSPC模塊充分融合不同尺度的特征信息,以提升模型檢測精度。在兼顧不同尺度的特征信息的同時特征信息之間的交互會被弱化。為了進一步增強特征圖上的有效信息,將注意力模塊CBAM嵌入到檢測模型中,在通道和空間兩個維度上進行特征的注意力權(quán)重融合,使網(wǎng)絡(luò)聚焦有意義的特征抑制無用信息。改進的YOLOv5s模型結(jié)構(gòu)圖如圖1。
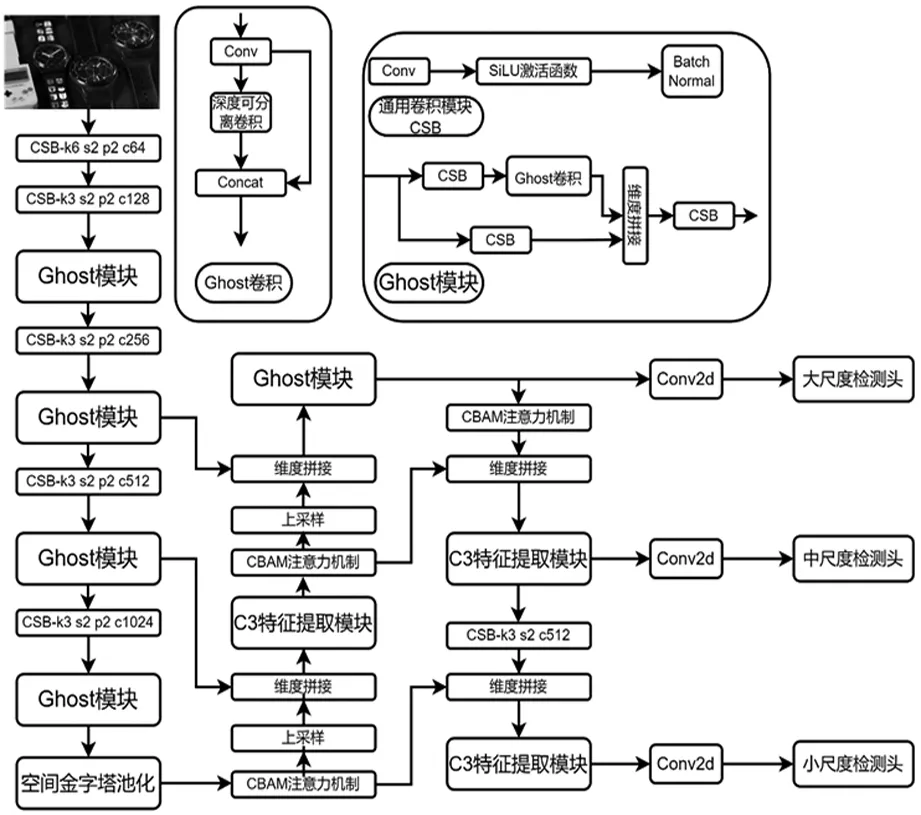
圖1 改進的YOLOv5s模型結(jié)構(gòu)示意圖
2.1 YOLOv5s模型主干網(wǎng)絡(luò)優(yōu)化
YOLOv5s中使用的CSPDarkNet53主干網(wǎng)絡(luò)是在DarkNet53網(wǎng)絡(luò)中引入跨階段局部網(wǎng)絡(luò)[12](Cross Stage Partial Network,CSPNet),提取有效的深度特征信息。但傳統(tǒng)的卷積網(wǎng)絡(luò)存在特征信息冗余,計算量大和模型參數(shù)大的問題,對硬件資源的要求較高,所以需要縮小模型體積減少參數(shù)量。Ghost卷積是GhostNet[13]的核心模塊,與傳統(tǒng)卷積不同,Ghost卷積從特征圖冗余問題出發(fā),利用特征圖的相似性,通過少量計算產(chǎn)生大量特征圖。由此Ghost卷積被設(shè)計為一種分階段的卷積計算模塊,Ghost卷積將特征提取與廉價的線性運算并行執(zhí)行后的兩組特征圖進行拼接,產(chǎn)生大量特征圖。以此消除特征圖冗余,獲得更加輕量的模型。
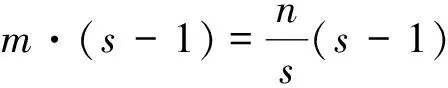
(1)
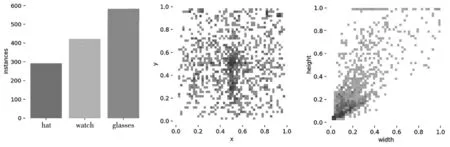
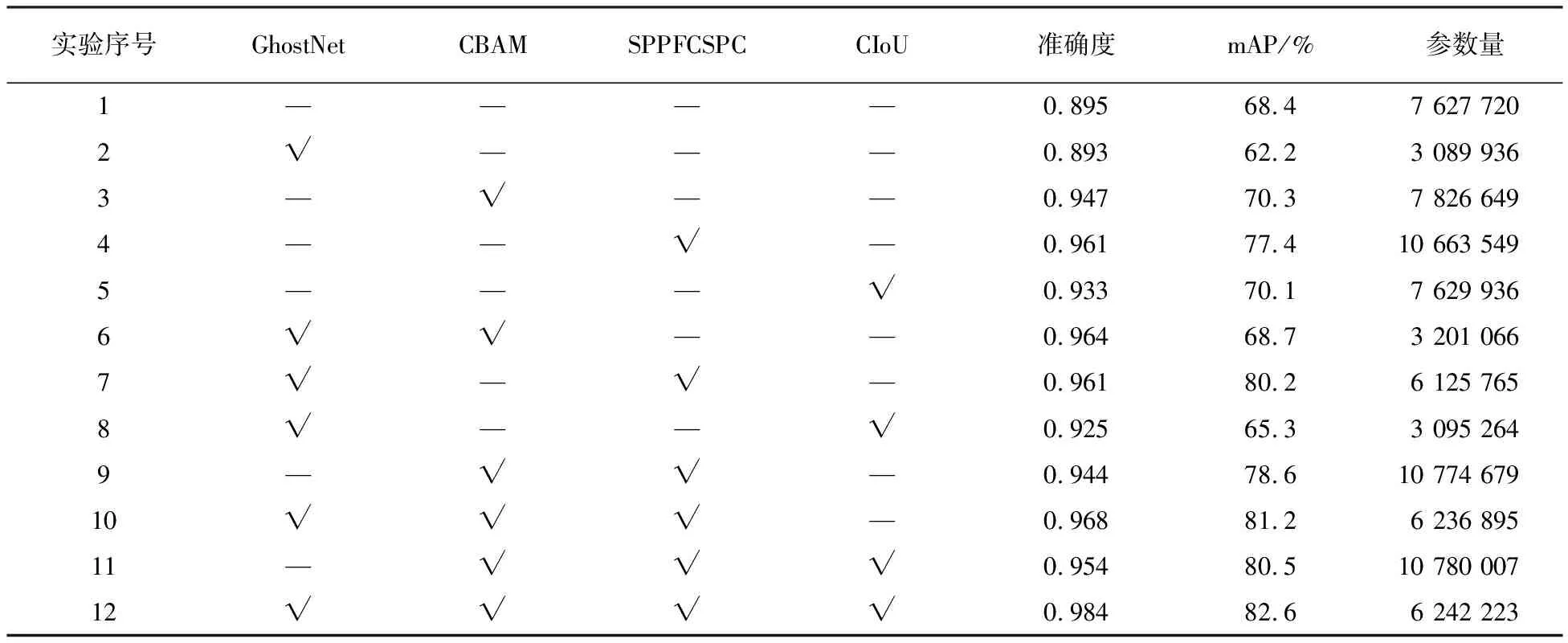
式中,d·d的幅度與k·k相似,且s< (2) 由公式(1)、(2)的化簡結(jié)果可得一般卷積的參數(shù)量和計算量大致為Ghost卷積的s倍。因此,本文基于Ghost卷積的輕量化優(yōu)勢,使用Ghost卷積替換YOLOv5s算法網(wǎng)絡(luò)中的普通卷積再結(jié)合CSPNet結(jié)構(gòu),搭建出適用于YOLOv5s的Ghost卷積結(jié)構(gòu),具體結(jié)構(gòu)如圖2。 圖2 Ghost卷積結(jié)構(gòu)示意圖 相比于YOLOv5s中原生的輕量級注意力機制SE-Net只注重通道像素的重要性,CBAM[14](Convolutional Block Attention Module)注意力機制作為一種輕量級的注意力模型,綜合考慮了不同通道像素和同一通道不同位置像素在重要性上的區(qū)別。輸入特征會沿著順序結(jié)構(gòu)依次融合沿通道和空間兩種維度上的注意力權(quán)重,然后再將注意力特征向量和輸入特征向量相乘來實現(xiàn)自適應(yīng)特征優(yōu)化。 在YOLOv5架構(gòu)中,Neck部分進行多尺度特征融合,其目的是將淺層網(wǎng)絡(luò)的強位置信息和深層網(wǎng)絡(luò)的強語義信息傳遞給其他網(wǎng)絡(luò)層,沿著這個思路把CBAM模塊添加在Neck部分。整體添加注意力機制示意圖如圖3。注意力機制通過對特征圖的通道維度進行自適應(yīng)的加權(quán),調(diào)整特征圖在不同通道上的表示權(quán)重,使模型更好地捕捉到飾品目標(biāo)區(qū)域的重要特征。同時通過對特征圖的空間維度進行自適應(yīng)的加權(quán),調(diào)整特征圖在不同空間位置上的表示權(quán)重。使模型更好地定位飾品目標(biāo)區(qū)域,并抑制無關(guān)的背景信息。 圖3 添加CBAM結(jié)構(gòu)示意圖 為了更加充分的利用主干網(wǎng)絡(luò)提取的特征,采用SPPF[15]空間金字塔池化結(jié)構(gòu)對各階段直接增加由自底向上和自頂向下的路徑。CSPNet結(jié)構(gòu)利用跨階段特征融合策略和截斷梯度流技術(shù)增強不同網(wǎng)絡(luò)層間學(xué)習(xí)特征的可變性,從而減少冗余梯度信息的影響,增強網(wǎng)絡(luò)學(xué)習(xí)能力。一方面,CSPNet在減少計算量、減少內(nèi)存成本的同時,優(yōu)化網(wǎng)絡(luò)檢測精度,所以在改進YOLOv5s模型時將該思想運用到SPPF模塊,優(yōu)化梯度信息,強化其特征聚合能力。 SPPFCSPC模塊就是綜合SPPF模塊與CSP模塊。首先將特征分為兩部分,其中的一個部分進行常規(guī)的處理,另外一個部分進行SPPF結(jié)構(gòu)的處理,最后把這兩個部分拼接在一起,使模型能在保持感受野不變的情況下獲得速度與精度的提升,SPPFCSPC模塊結(jié)構(gòu)如圖4。 圖4 SPPFCSPC模塊結(jié)構(gòu)圖 YOLOv5s的損失是由分類損失(Classes loss)、置信度損失(Objectness loss)和定位損失(Location loss)三部分進行加權(quán)相加構(gòu)成,而定位損失對應(yīng)的邊界框位置預(yù)測是目標(biāo)檢測中最主要的任務(wù)。YOLOv5s使用DIoU Loss[16]作為邊界框回歸損失函數(shù),用以評判預(yù)測檢測框與真實檢測框的檢測效果。其計算公式如式3所示: (3) 式中:gt表示真實檢測框;pb表示預(yù)測檢測框;ρ2(*)表示求歐式距離;bgt表示檢測框的中心點;bpb表示預(yù)測框的中心點;wpb、hpb分別表示檢測框的寬度和高度;c表示預(yù)測框和真實框的最小包圍框的最短對角線長度。 在實際的檢測任務(wù)中,回歸定位損失應(yīng)該考慮到3種幾何參數(shù):重疊面積、中心點距離、長寬比,DIoU僅考慮了前兩者,CIoU在DIoU的基礎(chǔ)上加入了對回歸框的長寬比,這樣預(yù)測框就會更加的符合真實框。CIoU示意圖如圖5。圖中黑色實線框表示真實檢測框,黑色虛線框表示預(yù)測檢測框。 圖5 CIoU示意圖 CIoU計算公式如下: (4) (5) (6) 式中:ρ2(*)表示求歐式距離;bgt表示檢測框的中心點;bpb表示預(yù)測框的中心點;wpb、hpb分別表示檢測框的寬度和高度;c表示預(yù)測框和真實框的最小包圍框的最短對角線長度;α表示一個正平衡參數(shù);v表示預(yù)測框和真實框的長寬比的一致性。 在本次研究中采用自制數(shù)據(jù)集進行訓(xùn)練和測試。自制數(shù)據(jù)集中包含手表、眼鏡、帽子3個類別,其中眼鏡圖像584張,手表圖像410張,帽子圖像296張。數(shù)據(jù)集圖像類別數(shù)量和圖像標(biāo)注錨框的分布情況如圖6。三種類別的圖像數(shù)量分布如圖6a。類別分布在收集數(shù)據(jù)時充分考慮不同視角下的大小和形狀問題,以及各種燈光和有其他物體遮擋時的情況,從而進一步提高模型的魯棒性和精度。數(shù)據(jù)集包含1 290張JPG格式圖片,圖像大小為1 920×1 080,按照8:2的比例劃分為訓(xùn)練集和測試集。數(shù)據(jù)采用VOC數(shù)據(jù)集格式,使用LabelImg標(biāo)注工具為每幅圖像標(biāo)注真實目標(biāo)框。 a)類別數(shù)量分布圖 b)圖像錨框中心分布圖 c)圖像錨框大小分布圖圖6 數(shù)據(jù)集圖像類別數(shù)量和圖像標(biāo)注錨框的分布情況 為了更加了解數(shù)據(jù)集中圖像和錨框的分布情況,對數(shù)據(jù)集進行分析。目標(biāo)中三種飾品類別圖像數(shù)量分布相對均勻,無異常數(shù)據(jù),針對較難識別的小目標(biāo)類別如眼鏡和手表,采集這兩種類別圖像占比80%,如圖6a。圖像標(biāo)注錨框中心點位置分布相對均勻,且大都分布在圖像的中下方如圖6b;錨框大小方面總體上中小錨框居多如圖6c。說明數(shù)據(jù)集是有利于模擬真實場景下的人物飾品檢測任務(wù)的。 為了增強數(shù)據(jù)多樣性,防止模型過擬合。采用Mosaic和Cutout方法進行數(shù)據(jù)增廣,同時在訓(xùn)練時采用對稱翻轉(zhuǎn)、改變對比度和亮度、添加噪聲,大小縮放的操作對原始數(shù)據(jù)集進行預(yù)處理以豐富數(shù)據(jù)集。具體操作見表1。 表1 數(shù)據(jù)集擴充操作 實驗使用AutoDL云計算平臺進行訓(xùn)練和測試,系統(tǒng)配置見表2。 表2 實驗環(huán)境 本次實驗選取了直接評估模型檢測水平的常用評價指標(biāo),對改進后的YOLOv5s飾品檢測網(wǎng)絡(luò)模型進行評價。 (1)精確度(Precision,P)、召回率(Recall,R)。 (7) (8) 式中:TP為目標(biāo)被正確檢測出來的數(shù)量;FP為被誤檢的目標(biāo)數(shù)量;FN為未被檢測出的樣本數(shù)量。 (2)平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)為 (9) (10) 式中,N=3為類別個數(shù),在采用精確度和召回率兩個值作為橫縱坐標(biāo)的P-R曲線中,P-R曲線與坐標(biāo)軸圍成的面積等于AP值大小。平均精度(mAP)是所有類別預(yù)測精準(zhǔn)度的平均值,將每一類的AP值都計算出來以后,將其平均就得到mAP。 本次實驗對YOLOv5s模型的主干網(wǎng)絡(luò)、注意力機制、特征融合方法進行了改進,同時優(yōu)化了損失函數(shù)。為評估不同模塊改動和不同模塊互相組合對于算法性能優(yōu)化的程度設(shè)計了消融實驗。實驗的基準(zhǔn)模型為YOLOv5s模型。為保證實驗準(zhǔn)確性,每組實驗?zāi)P途捎孟嗤挠?xùn)練參數(shù)和數(shù)據(jù)集,且每組實驗做三次取其平均值進行對比。消融實驗數(shù)據(jù)見表3。 表3 消融實驗對比結(jié)果 對本文提出的四種不同的優(yōu)化方法進行單獨實驗和組合實驗,實驗結(jié)果表明每種改進都對模型性能產(chǎn)生了不同程度的影響。主要表現(xiàn)在以下幾個方面。 實驗2表明更換GhostNet骨干網(wǎng)絡(luò)之后模型整體參數(shù)量下降60%,但模型的平均精度和準(zhǔn)確率都有所下降。實驗3~5表明三種優(yōu)化方法單獨使用都可以提升模型的mAP。其中加入SPPFCSPC模塊之后參數(shù)量有所增加同時mAP提升了9%,準(zhǔn)確度提升了6.6%。CBAM注意力機制和CIoU激活函數(shù)mAP分別提升1.9%和1.7%。 根據(jù)組合不同模塊進行實驗的實驗結(jié)果發(fā)現(xiàn),使用不同的組合使模型的整體性能提升呈現(xiàn)正向優(yōu)化。在實驗9中使用原生骨干網(wǎng)絡(luò),在優(yōu)化了CBAM注意力機制和SPPFCSPC模塊之后mAP提升了10.2%,準(zhǔn)確度提升了4.9%,但是參數(shù)量有大幅增加,其中大部分參數(shù)量來自SPPFCSPC模塊;實驗11在實驗9的基礎(chǔ)上優(yōu)化損失函數(shù)為CIoU之后mAP提升了1.9%。這說明三種優(yōu)化策略組合使用可以提升模型性能。 為了降低模型參數(shù)量的同時,提升模型的mAP與精確度,在使用GhostNet骨干網(wǎng)絡(luò)之后進行了實驗。實驗結(jié)果顯示不同的模塊組合產(chǎn)生的優(yōu)化效果也不同。實驗6表明在GhostNet骨干網(wǎng)絡(luò)下添加注意力機制準(zhǔn)確度提升了1.7%,但是mAP下降了1.6%。實驗7、實驗8也是相同的表現(xiàn),這說明使用GhostNet骨干網(wǎng)絡(luò)降低了參數(shù)量但是對于mAP的提升并不理想。實驗10和實驗12同時采用多種優(yōu)化策略,從結(jié)果來看雖然會削弱單個優(yōu)化策略的提升程度,但在整體上達到了最優(yōu)效果。特別是實驗12,mAP提升了14.2%,準(zhǔn)確度提升了8.9%,同時整體參數(shù)量降低了18.2%,達到了在本次實驗中較為理想的結(jié)果。 為直觀展現(xiàn)本文算法的檢測效果,從測試集的檢測結(jié)果中選取三張具有代表性的場景進行檢測如圖7。其中左列為原圖,右列為檢測結(jié)果。圖7a展示了在室外光照和陰影變化場景下的檢測結(jié)果;圖7b展示了在室內(nèi)檢測目標(biāo)分布密集時的檢測結(jié)果;圖7c展示了在復(fù)雜背景下檢測目標(biāo)被遮擋時的檢測結(jié)果。 a)光照變化場景下的飾品檢測 為了對比本文提出的改進YOLOv5s模型與其他相關(guān)工作的模型的效果,使用SSD(MobileNetV2)、Faster-RCNN(ResNet50)、YOLOv4(DarkNet53)、YOLOv5s(DarkNet53)4個模型設(shè)計了對比實驗。在人物飾品檢測數(shù)據(jù)集上進行實驗,實驗采用相同的運行環(huán)境。每個模型進行三次實驗取其平均結(jié)果進行對比,結(jié)果見表4。 從對比實驗的結(jié)果可以看出,優(yōu)化后的YOLOv5s模型準(zhǔn)確率最高,模型體積最小。遠遠小于Faster-RCNN和YOLOv4,而且比YOLOv5降低了18.2%的參數(shù)量。和同為輕量級架構(gòu)的SSD相比,雖然兩者體積近似但是優(yōu)化后的YOLOv5s的mAP提升了14.3%。總體分析,本文提出的改進YOLOv5s模型檢測效果更好,總體性能更佳。 針對目標(biāo)檢測模型在進行人物飾品檢測時效果差的問題,提出了一種改進的YOLOv5s模型進行人物飾品檢測。在自制數(shù)據(jù)集上進行模型訓(xùn)練,使用GhostNet進行特征提取來降低模型參數(shù)量,同時降低輕量化對模型準(zhǔn)確率的負面影響,使用CBAM注意力機制和優(yōu)化Neck層的特征融合網(wǎng)絡(luò)結(jié)構(gòu),增加模型的特征提取與特征利用能力,引入損失函數(shù)提升模型性能。實驗結(jié)果表明:改進的YOLOv5s模型能在降低模型參數(shù)的同時提升檢測的準(zhǔn)確度。后續(xù)工作將對模型結(jié)構(gòu)和參數(shù)進一步優(yōu)化,在自制數(shù)據(jù)集中增加更多復(fù)雜環(huán)境下的數(shù)據(jù)和更多種類的數(shù)據(jù)以提升模型的魯棒性和泛化能力。
2.2 YOLOv5s模型注意力機制改進
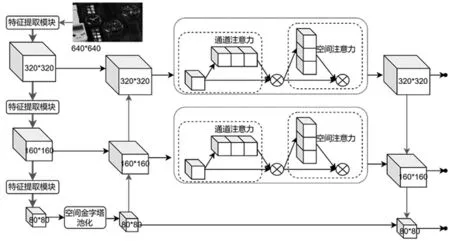
2.3 YOLOv5s模型空間金字塔池化改進
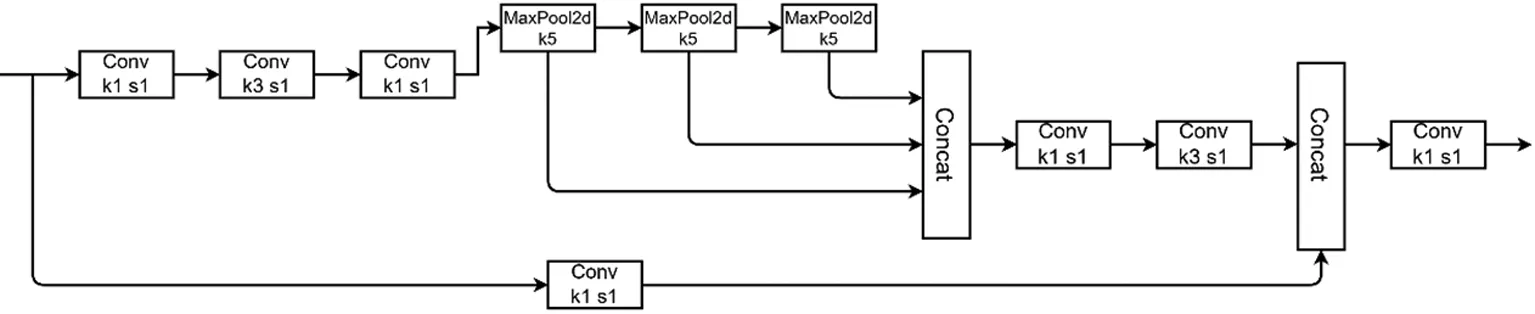
2.4 YOLOv5s模型損失函數(shù)改進

3 實驗與實驗結(jié)果分析
3.1 數(shù)據(jù)預(yù)處理
3.2 實驗環(huán)境
3.3 模型評價指標(biāo)
3.4 改進YOLOv5s消融實驗

3.5 不同模型對比實驗
4 結(jié) 語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
