基于Swin Transformer的知識蒸餾模型在垃圾分類上的應用
2023-12-07 12:11:08杜峰付天生
電腦知識與技術 2023年30期
杜峰,付天生
(福建理工大學,福建 福州 350118)
0 引言
隨著經濟發展,中國的城市化進程也在提速,在城市化的過程中,環境惡化問題需要提前防范,其中城鎮生活垃圾泛濫成災則是當中比較嚴峻的環境問題之一。目前垃圾處理的主要方法是填埋和焚燒。對于垃圾填埋處理,若沒有經過提前分類流程,不僅浪費更多的土地資源,而且會使得處理費用大增,更糟糕的是塑料垃圾、有害金屬垃圾進行填埋處理不僅長期難以降解,還會污染土地,使大量土地無法耕種,另外,填埋的有害垃圾還會污染地下水資源,給整個社會帶來健康隱患。對于焚燒處理方法,如果有害垃圾不進行分類處理,則會增加大量的碳排量和廢氣,同時伴隨嚴重的空氣污染,對垃圾進行分類處理是解決城市化環境問題的必要手段,對城市垃圾分類回收將是未來的發展趨勢。
近幾年,我國部分城市把生活垃圾必須進行分類作為規定,并且國家也開始從試點城市向周邊更多城市推廣垃圾分類做法。垃圾分類的規定自推行以來,效果不佳。究其原因,問題主要出在生活垃圾分類操作中的實際人工成本較大,并且即使居民愿意投入時間精力,依舊有許多人不能準確地區分各種生活垃圾的類別,生活垃圾的實際分類準確率不太理想。
在科技的發展過程中,人工智能技術突飛猛進,使用計算機技術解決社會生產過程中遇到的實際問題做法越來越得到各界的重視。比如,計算機視覺相關技術在許多領域如人臉識別[1]、車輛檢測[2]、智慧醫療[3]等許多行業都取得了不可忽視的成績,因此在垃圾分類問題上使用計算機視覺方法將是一個值得考慮和選擇的方案。將計算機視覺方法運用到生活中的垃圾分類問題上,將大大改善當前的垃圾分類人工成本過高和人工分類準確率有限的問題。
計算機視覺的發展可以分為基于統計學和基于深度學習兩個階段。早期基于統計學的計算機視覺主要研究圖像分類問題。傳統圖像分類算法[4]一般包含特征提取、特征構造、分類器設計3個階段。這種傳統算法是基于簡單統計學特征對圖像數據進行提取,使用統計學方法進行降維壓縮等特征處理操作,再使用經典的統計分類模型作為相應的分類器進行圖像分類判斷。這類基于統計學的算法要求投入大量的人工成本進行特征提取,并且最終的模型穩定性較差。隨著人工智能研究的深入和計算機運算性能的發展,基于深度學習的計算機視覺算法也得到了長足進步。基于深度學習的圖像分類方法通常是使用算法對圖像自動提取特征,并在同一個算法框架中使用提取的特征對圖像進行分類,得到完全從訓練數據中學習圖像的層級結構性特征。其中最具代表性的是卷積神經網絡[5](Convolution Neural Network,CNN) ,相較早期的基于統計學方法的算法,卷積神經網絡更擅長在圖像中提取關鍵特征,這種特征提取操作是自動提取的,并且因為沒有引入人為因素偏差模型也有更強的穩定性。在CNN模型中,越深層的網絡通常包含越抽象的高級特征,越深層的網絡越能表現圖像主題語義,從而獲得更強大的識別能力。
在2012年,Hinton提出了基于CNN結構的AlexNet[6]深度模型,并以15.4%的低失誤率成為當年 ILSVRC算法比賽的冠軍。AlexNet的成功則論證了基于CNN 的深度學習網絡在圖像分類的有效性。在此之后,不斷有學者對深度學習結構進行創新,包括隨后發展起來的VGG[7]、GoogleNet[8]、ResNet[9]、DenseNet[10]等深度學習網絡也在圖像分類上取得了優秀的成績。基于大量的深度學習算法,計算機視覺方法在人臉識別、智慧醫療等領域得到了廣泛的應用,并取得了良好的效果,然而,隨著應用處理的圖像質量和尺寸的不斷提升,基于CNN結構的深度學習的網絡需要堆疊大量的層數才能較好地感知圖像的整體特征,然而大量層數堆疊也給基于CNN的深度學習網絡帶來了參數過多、預測性能下降、運算時間過長等問題。
基于此缺點,學者提出了基于transformer 的圖像分類方法ViT[11](Vision Transformer) ,此方法只需少數幾層就可以獲得需要大量堆疊層數的CNN 全局的感受野。基于Transformer 的網絡結構擁有較好的并行運算性質,此類結構可以更好地利用GPU、TPU 之類的硬件進行加速運算。然而基于Transformer 的網絡結構的self-attention計算機制會導致較大的計算資源和存儲資源占用問題,因此原始的ViT 模型無法很好地應用在大圖像處理問題上。有學者則針對ViT的不足進行改進,提出了Swin Transformer[12]模型。此模型利用了移動窗口的原理大大降低了self-attention計算開銷,能較好地處理高質量大尺寸圖像,此模型一經提出,就受到了學術界和工業界的廣泛歡迎。為了探究深度學習在高質量大尺寸圖像處理上的應用,本文將預訓練Swin Transformer模型用于垃圾分類問題中,使用實際垃圾圖像數據對模型進行遷移學習訓練。為了進一步提升模型的實際部署應用性能,本文在訓練好的基礎Swin Transformer 模型上使用知識蒸餾方法Knowledge Distillation[13]對模型進行壓縮,進一步減小模型的體積,加快模型的計算效率,提高了模型的實用性。
1 算法介紹
1.1 ResNet模型
圖像處理中的CNN 結構主要就是通過一個個由卷積核組成的filter,不斷地在圖像上提取特征,隨著層數的堆疊可以獲得從局部特征到總體的特征,從而實現圖像識別等功能。卷積神經網絡CNN 通常包括獨有的卷積層和池化層以及全連接層的輸入和輸出層,相對全連接層,卷積層具有參數量更少的特性。卷積神經網絡在圖像識別、語義分割、圖像分類、圖像檢索等領域都有較為成功的應用,這主要得益于其自動提取圖像特征、自動更新、共享權值的特性。CNN網絡的底層提取的特征主要包括通用的色彩、紋理特征提取,以及一些圖像數據都有的共性特征。在深度CNN 模型中,隨著層數的堆疊,模型特征的表達能力越來越強,這使得越頂層則越能適應特定任務。AlexNet 是深度CNN 的開山之作,后續學者提出了VGG 模型,然而隨著模型深度的增加,模型會出現性能退化的問題,即增加模型的層數換來的是更差的性能表現。從實證角度看,神經網絡的深度和層數對模型的性能異常重要。隨著網絡深度的加深,更加復雜的特征模式可以被模型提取出來。因此,理論上隨著模型深度增加模型可以取得更好的性能。然而,許多實驗卻又表明深度網絡存在退化問題(Degradation problem) ,即隨著網絡深度增加,模型性能出現飽和或者下降。針對深度網絡性能退化問題,學者在AlexNet 的基礎上提出了深度殘差網絡(Deep residual network, ResNet) 。
ResNet 的架構借鑒了VGG 網絡架構,是在VGG基礎上進行了改進,并設計了短路機制,加入了殘差模塊,如圖1所示。從圖1可以看到,ResNet模型相比以往的網絡,每兩個相鄰層間加入了短路機制,從而形成了殘差學習。實驗結果表明,這種短路機制可以很好地解決深度網絡中的退化問題。相較于VGG 網絡,ResNet在結構上的區別主要為ResNet直接使用了步長大于1的卷積操作,這種操作能起到特征壓縮的作用,另外還使用了global-average-pooling 層代替全連接層。ResNet 的一個重要設計原則是:當feature map大小縮小為原來的1/2時,feature map的通道數增加一倍,這保持了模型的特征表達能力。

圖1 殘差網絡模塊
1.2 Vision Transformer模型
自深度學習大為流行以來,CNN一直是計算機視覺領域的主流模型,而且取得了很好的效果,與此同時, Transformer 結構則在NLP 取得了突破性的進展,并且基于Transformer 結構的GPT 和Bert 的大語言類模型在工業界得到了廣泛應用。近年來,越來越多的學者不斷研究如何在NLP 之外領域復制Transformer在NLP 上的成功。在2020 年,Google 提出了ViT[11](Vision Transformer) , 直接將Transformer 應用在圖像分類問題上。
ViT 模型先把圖像分成固定大小的patchs,類似于NLP 的詞嵌入向量化做法,ViT 通過線性變換對每個圖像patchs進行patch-embedding向量編碼。接著,將圖像的patch-embedding送入Transformer Enconding模塊中進行特征提取。最后,連接全連接層作為分類器進行圖像分類,具體的ViT模型原理如圖2所示。
繼ViT 之后,基于Transformer 結構的模型開始在CV 領域大放異彩,其中包括應用于圖像分類的Swin Transformer,目標檢測的DETR,語義分割的SETR 等模型。
在計算機視覺問題上, Transformer 結構的核心Self-Attention 計算機制的優勢是可以獲得圖像序列的long-range 信息而不是像CNN 結構要通過不斷堆積層數來獲取更大的感受野。更好的long-range特征提取意味著在高質量大尺寸圖像問題上能獲得更好的表現,然而ViT 的Self-Attention 計算機制也帶來了計算開銷過大的問題,模型還需要進一步被完善。
1.3 Swin Transformer模型
基于Transformer 結構的ViT 模型主要存在不同場景的大尺寸圖像表現不穩定和高質量大尺寸圖像的全局自注意力機制的計算導致計算開銷較大兩大問題。針對這兩個問題,Liu[12]提出了一種滑窗操作的層級架構模型Swin Transformer。傳統的Transformer都是基于全局來計算Self-Attention的,因此,隨著圖片尺寸的增大,注意力的計算復雜度將十分高。而Swin Transformer則將注意力的計算限制在每個窗口內(Window Attention) ,進而減少了計算量。Swin Transformer中滑動窗口包括不重疊的Local-Window,和重疊的 Cross-Window。將自注意力計算限制在一個窗口中,一方面能引入類似CNN網絡的局部性,另一方面能大大減小計算開銷。圖3 左側是Swin Transformer 模型的Window-Attention 示意圖,右側是VIT 模型的全局Self-Attention示意圖。
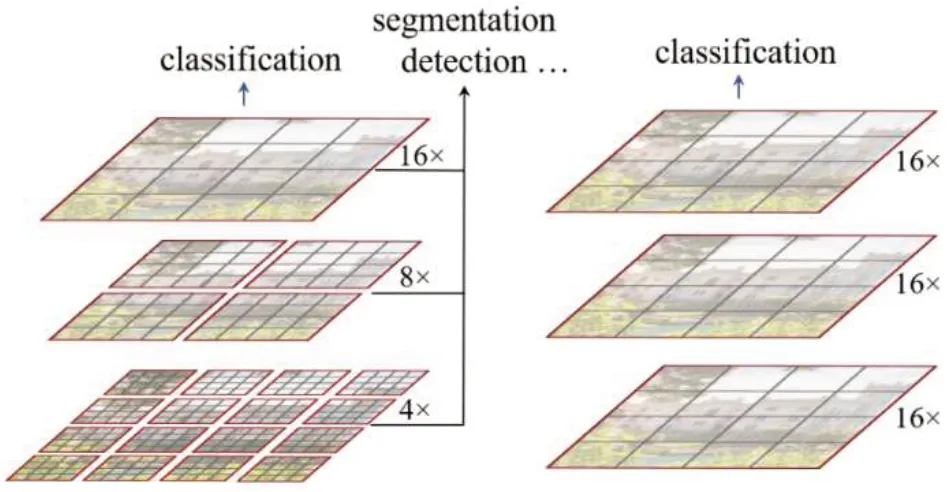
圖3 兩種注意力機制的對比
Window-Attention是在每個窗口內分別計算注意力,但是為了更好地和其他Window進行信息交互,擴大模型感受野,Swin Transformer 還引入了Shifted-Window操作,具體操作如圖4所示。
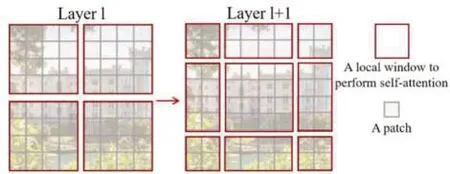
圖4 Shifted-Window操作
圖4左邊是沒有重疊的Window-Attention,而右邊則是將窗口進行移位的Shift-Window-Attention。可以看到移位后的窗口包含了原本相鄰窗口的元素,即兩層之間的不同窗口可以交換特征信息,其中Encoder 的倒數第一層使用的是全局注意力機制,經過計算全局注意力后,模型可以獲得圖像整體的特征,模型最后一層則接入全連接層作為分類器進行圖像分類。
其中,本文使用的基礎Swin Transformer模型架構圖如圖5所示,模型可分為4個階段,每個階段又包含若干個Swin Transformer 模塊,每個模塊都進行Shift-Window-Attention 計算。在最后一個模塊中,圖形特征的維度縮小為原來的1/32,通道數擴大為原來的8倍。
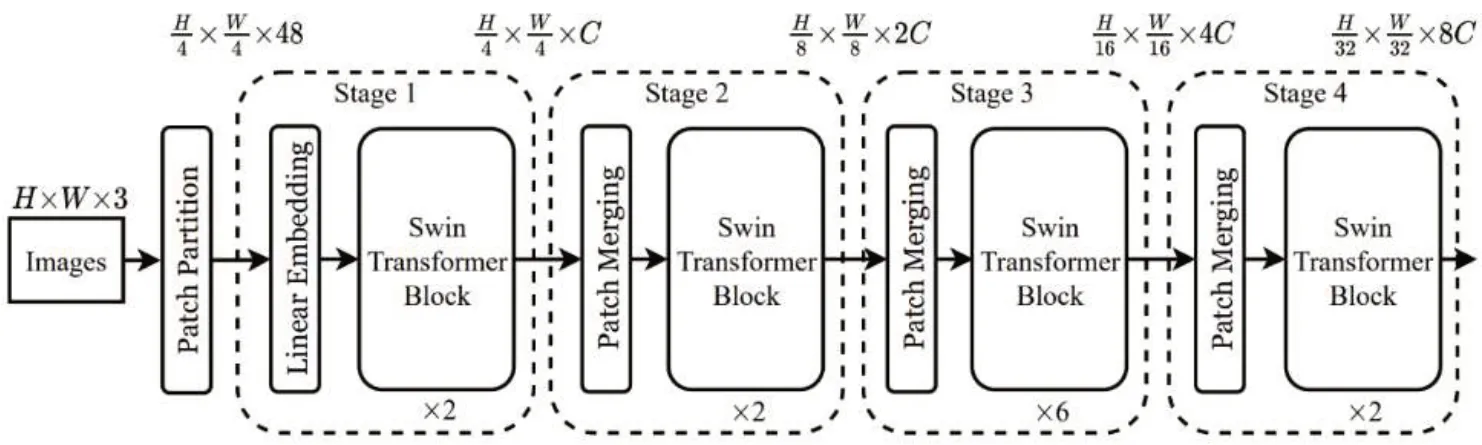
圖5 Swin Transformer模型架構
1.4 知識蒸餾
在深度模型流行的當下,大模型雖然具有更強的性能,但是也要求計算機具有較高的計算性能。然而在實際應用中,客戶端的計算性能有限,通常無法承載大模型的推理過程,一般的做法是對訓練好的大模型進行壓縮,以減少其對設備性能的要求。
其中,知識蒸餾Knowledge Distillation[13](KD) ,是一種表現優越的模型壓縮方法,主要基于“教師-學生”的訓練方法。并且因為其簡單有效,無論在學術界還是工業界都受到了廣泛應用。從字面意義上理解,知識蒸餾就是要將知識(Knowledge)從已經訓練好的大模型中提取出來,并壓縮蒸餾(Distill)到學生小模型中,知識蒸餾訓練方法的流程圖如圖6所示。
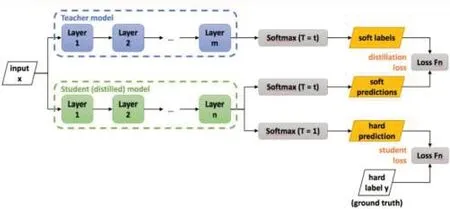
圖6 知識蒸餾示意圖
在知識蒸餾中,由于已經有了一個泛化能力較強的教師網絡Teacher model,使用Teacher model 來蒸餾訓練學生網絡Student model 時,可以直接讓Student model去學習Teacher model的泛化能力。一個直接且高效的泛化能力遷移的方法就是使用Softmax 層輸出的類別概率來作為Soft-Target。
相較于真實標簽只有正例信息的Hard-Target,模型的Softmax 層的輸出同時包含了正例和負標簽。而負標簽帶有大量的信息,比如某些負標簽對應的概率遠遠大于其他負標簽。而在傳統的訓練過程(Hard-Target)中,所有負標簽都被統一對待,信息是不完整的,也就是說,KD 的訓練方式使得每個樣本給Student model帶來的信息量大于傳統的訓練方式。
2 實驗和結果分析
2.1 實驗數據
本文使用的數據來源于華為云垃圾分類圖像公開數據集,其中數據包含可回收物、廚余垃圾、有害垃圾和其他垃圾4大分類,每大類別又有細分類別,共有40 個細分垃圾類別,一共有14 402 張帶標簽的圖片。本文實驗按4:1 的數據比例劃分為訓練集和測試集,即11 522 張圖像作為訓練數據,2 880 張圖像作為測試集數據。
2.2 圖像數據處理
原始數據中每個圖像的大小并不統一,本實驗對所有圖片進行重采樣操作調整每張圖片的尺寸為224×224。另外,為了增加模型的穩健性,本實驗和其他主流計算機視覺模型訓練流程一樣,使用了剪裁、翻轉、縮放、融合等數據增強操作。
2.3 實驗環境
本文的實驗硬件環境為:Intel Xeon 12 核CPU,GPU 為NVIDIA A100,內存大小為32GB。其中軟件環境為Python-3.7,深度學習框架為百度的 Paddle-Paddle-2.4.0,GPU加速驅動為cuDNN-8.2。
2.4 圖像數據處理
2.5 實驗結果及分析
本實驗的主要研究模型是基礎Swin Transformer模型(swin_base) ,并且實驗還選取了4 個主流計算機視覺模型進行性能對比,對比模型包括GoogLeNet、ResNet50、ResNet101、VGG11。為了保持可比性,各個模型的訓練參數設置和Swin Transformer 模型的訓練參數設置保持一致,具體取值如表1所示。另外,在實驗的最后還加入知識蒸餾訓練學習對swin_base 模型進行壓縮,最終得到壓縮后的模型swin_distill。圖7~圖10展示了不同模型的訓練收斂情況以及模型在測試集上的性能表現。
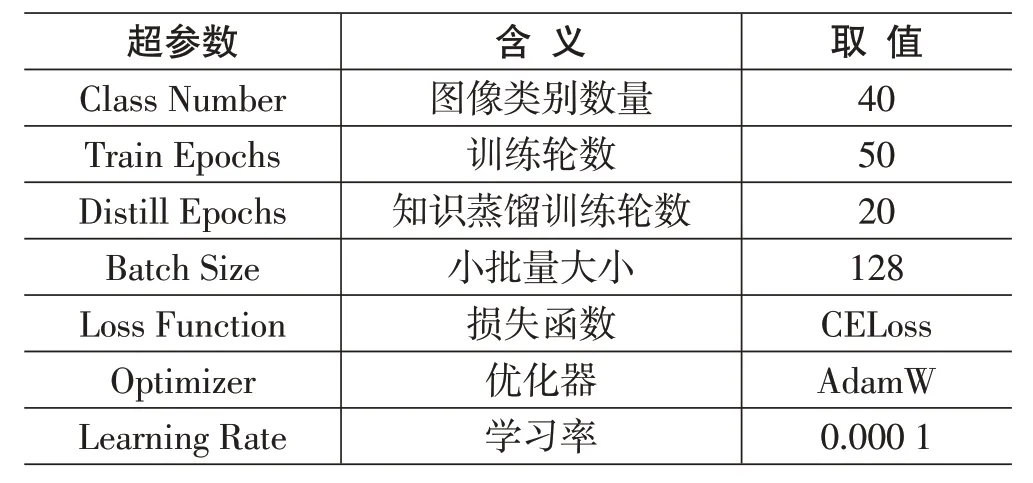
表1 實驗的超參數說明
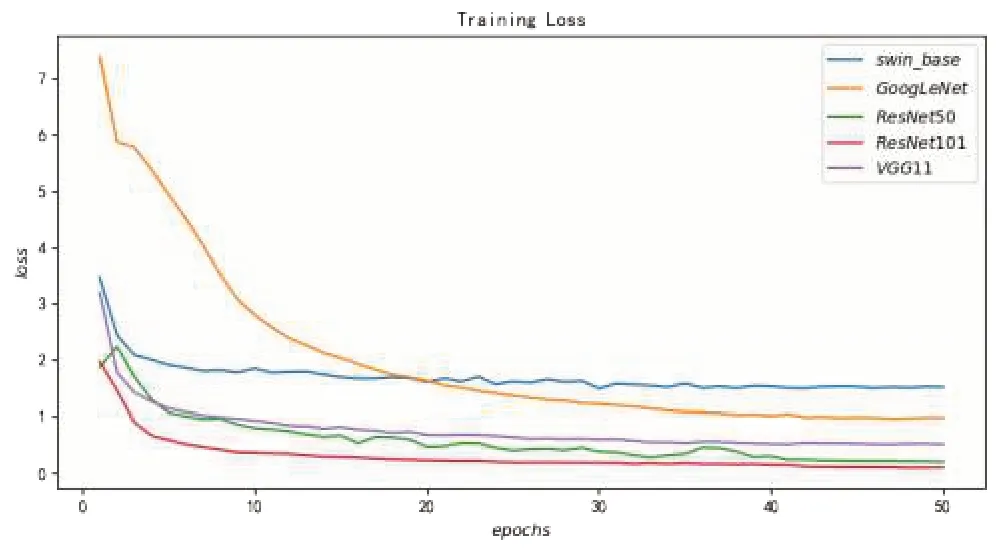
圖7 各個模型的訓練誤差收斂情況
從圖7看到,經過50 個輪次的迭代訓練,所有模型的訓練損失都收斂到了一個較低的水平,說明所有模型都得到了充分的訓練,并都達到了各自的最優水平。
圖8則從側面進一步說明,經過50個輪次的迭代訓練,所有模型都得到了充分的訓練,并能在測試集上表現出最優水平。
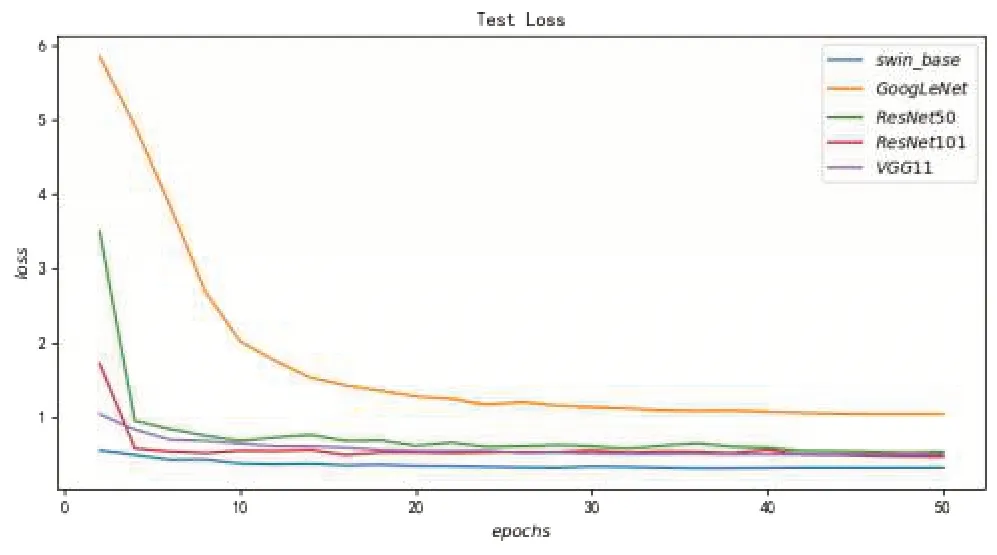
圖8 各個模型在測試集的損失表現
從圖9可以看出,swin_base模型在測試集數據的準確率最高,表現最好,并且和其他模型保持了較大的優勢差,說明實驗中的swin_base 模型的性能最好,這驗證了基于Transformer 結構的深度學習模型更擅長處理高質量大尺寸的圖像數據。
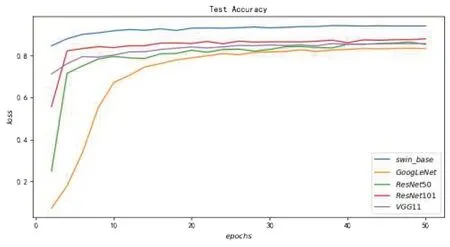
圖9 各個模型在測試集的準確率表現
從圖10 可以看出,學生模型swin_distill 只經過20個訓練輪次就收斂在較高的準確率,說明知識蒸餾訓練方法引入了信息含量更豐富的Soft-Target 可以大大減少學生模型訓練過程的訓練次數。知識蒸餾訓練方法不僅能訓練出高性能的學生模型,還能大量地減少訓練開銷。
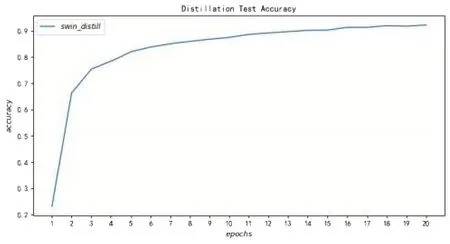
圖10 知識蒸餾學生模型在測試集的準確率表現
表2 是各模型性能表現和模型大小的橫向比較。從表2 可以看到,swin_base 模型的準確率為0.944,表現最優,而基于CNN結構的4個深度學習模型準確率都沒有超過0.88,和swin_base 模型存在較大的落差。在模型大小上,swin_base 模型相比基于CNN 結構的模型并沒有優勢,但是經過知識蒸餾訓練壓縮后的swin_distill 模型在體積上相較swin_base 模型則存在巨大的改進,模型壓縮后參數量把基礎模型縮小為原來的1/3,并且依舊保持了較高的準確率。因為swin_distill 模型體積相對較小并且準確率相對較高,所以swin_distill 模型更適合在垃圾圖像分類實際應用中進行部署。
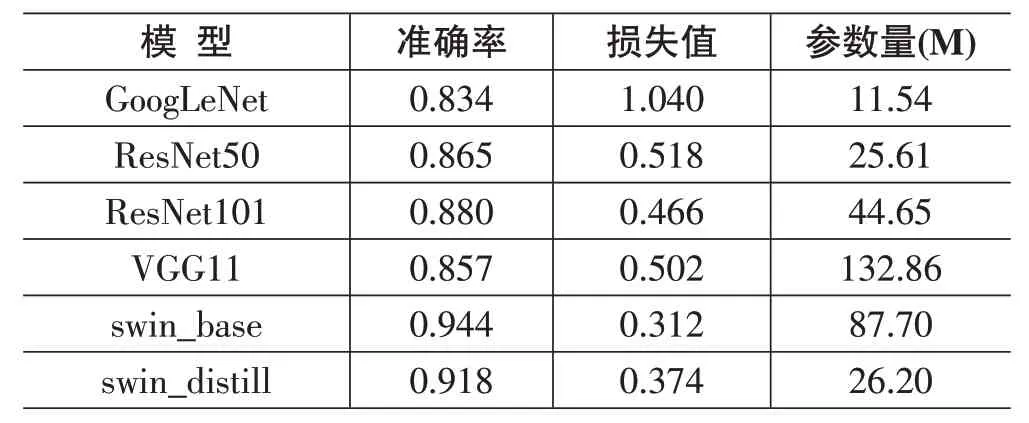
表2 各模型性能表現和模型大小
3 結論
本文以垃圾圖像分類問題作為研究導向,使用實際數據對多個深度學習模型進行了比較分析。可以發現,包含著更豐富的信息大尺寸垃圾圖像在圖像分類模型上確實表現更優。主流的基于CNN 的深度學習模型雖然在小尺寸圖像上表現不錯,但是難以從大尺寸圖片中提取長序列特征。
最終經過實驗檢驗,本文設計的基于Swin Transformer模型的算法框架不僅很好地解決了長序列特征提取問題,還通過知識蒸餾方法解決了大模型在實際應用中體積過大難以部署的問題。本文的基礎Swin Transformer 模型準確率達到94.4%,大大優于基于CNN結構的模型,說明基于Transformer結構的深度學習模型在處理大尺寸圖像上具有較大的優勢。而針對實際應用的知識蒸餾方法可以大大減小模型的體積并且保持較高的預測性能。最終實驗結果表明本文設計的基于Transformer 架構的Swin Transformer 的模型能較好地應用在大尺寸圖像分類問題中,并且基于Swin Transformer 的知識蒸餾模型能很好地在垃圾分類問題上得到應用,從而助力國家的環境治理進程。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
