基于決策樹C4.5模型的數據挖掘技術在學生成績分析中的應用研究
2023-12-07 12:11:12田飛展金梅
電腦知識與技術 2023年30期
田飛,展金梅
(1.海南經貿職業技術學院,海南 海口 571127;2.瓊臺師范學院,海南 海口 571127)
0 引言
在這個人工智能快速發展的時代,每所高校都擁有自己的教務管理系統,里面儲存了學生在校期間的所學課程信息及考試成績等數據,而很多高校只是用這些數據評價一個學生是否達到評優的標準、是否達到畢業標準等簡單的審核與查詢功能。其實,這些數據中還蘊含了許多更重要的信息,比如:影響學生學習的主要因素有哪些?這些因素又反映出什么問題?學校的校領導、教學管理者以及教師迫切希望從這些數據中挖掘出自己所關注的信息,這些信息可以通過決策樹C4.5模型的數據挖掘技術來獲得。
近年來,國內外許多學者運用數據挖掘技術分析學生的考試成績方面進行得如火如荼,在中國知網總庫中,同時以“數據挖掘”“學習成績”檢索,共檢索出中文文獻467 篇,其中學術期刊184 篇,學位論文279篇,會議論文4 篇;外文文獻42 篇。其中,班文靜等(2022) 基于多算法的在線學習成績預測框架,融合神經網絡、決策樹、K-近鄰、隨機森林和邏輯回歸算法預測學習者在線學習成績,并進行了預測性能分析[1]。趙磊等(2021) 基于數據挖掘的MOOC 學習者學業成績的行為指標及算法模型、群體學習特征和教學干預策略進行了探究[2];李海洋等(2020) 利用Apriori 算法建立關聯分析挖掘模型,通過SPSS Clementine 軟件學生成績與洗浴時間關聯性[3],何普亮、張戰勝(2019) 從教育數據挖掘的一般過程、教育數據挖掘的典型方法、常用工具以及目前國內外的相關典型應用等幾個方面,對大數據時代的教育數據挖掘進行介紹和分析[4]。
1 數據挖掘技術
數據挖掘技術是人工智能快速發展時代的熱點問題,它是利用深度學習、機器學習、神經網絡、人工智能等理論及方法,借助Matlab、Python、SPSS 等相關軟件,從龐大的數據庫中,提取有效數據,進行科學的深度分析,為了尋求人們以前沒有發現的,但對今后的工作是非常有用的知識的過程[5-6]。
數據挖掘是一個反復進行、不斷優化的過程,主要包括數據準備、數據處理、數據挖掘和結果反饋四個階段,如圖1所示。

圖1 數據挖掘流程圖
2 決策樹C4.5模型[7]
C4.5 算法是對Ross Quinlan 開發的ID3 算法的改進,是用在機器學習、數據挖掘的分類問題中的算法,由J.Ross Quinlan提出,它與ID3算法一樣使用了信息熵的概念,并通過學習數據來建立決策樹。
2.1 信息熵
它是信息的數學期望,一般用來表示信息混亂、無序的程度。設數據樣本集T,類別屬性具有m個不同值C1,C2,…,Cm,則信息熵的計算公式為:
數據樣本集S的一個屬性A有k個不同取值a1,a2,…,ak,利用屬性A將數據樣本集T劃分為k個子集T1,T2,…,Tk,而且對于任意一個子集Tj類別屬性也具有m個不同值Cj1,Cj2,…,Cjm,則Tj的信息熵計算公式為:
2.2 條件熵
以屬性A為根進行分類的信息熵,其計算公式為:
2.3 信息增益
以屬性A的信息增益定義為:
2.4 信息增益率
屬性A的信息增益率定義為:
3 實例分析
3.1 數據準備
文中數據采用海南省某高校21 級軟件專業2 個班級90名學生考試信息,主要包括學生的學號、實驗成績、考勤成績、課堂表現、考試成績等,如表1所示。

表1 學生成績信息表
3.2 數據處理
由于學生退學、當兵、休學、緩考、缺考等原因,導致部分學生成績信息不完整,從學生成績信息表中剔除這些數據,剩下81條符合條件的數據,從21級軟件1 班、2 班分別選取30 名同學的考試成績信息作為訓練集數據,其余21 名同學的考試信息作為測試集數據。
為了方便構建決策樹C4.5 模型,對81 條有效數據進行預處理,實驗成績(A≥88,優秀,82 ≤A< 88,一般,A< 82,差),考勤成績(B= 100,好,95 ≤B<100,中,B< 95,差),課堂表現(C≥90,好;80 ≤C<90,中;C< 80,差),考試成績(T≥75,優良,60 ≤T<75,及格,T< 60,不及格)。得到學生成績分析表,如表2所示。
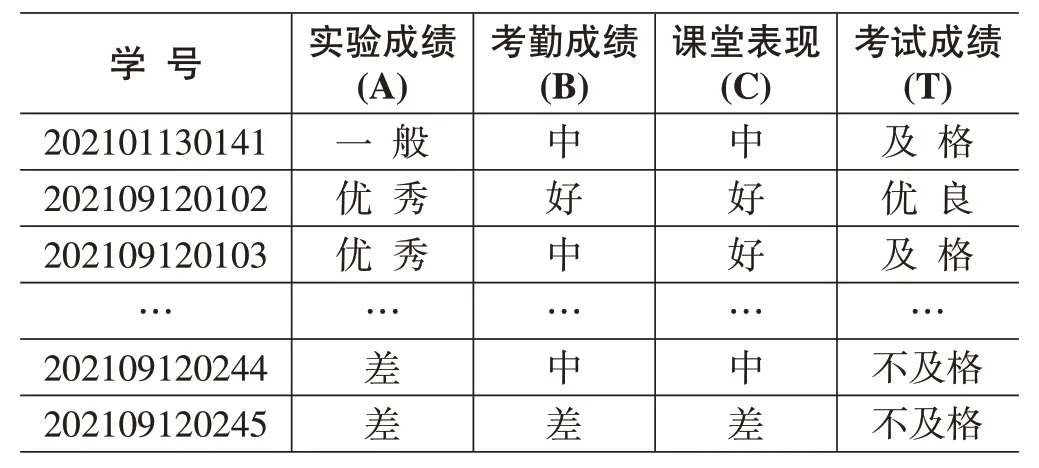
表2 學生成績分析表
3.3 數據挖掘
借助于matlab軟件,對表2進行數據挖掘,分別計算信息熵、條件熵、信息增益與信息增益率。
1) 信息熵
神意存在于永恒當中。《劍橋哲學研究指針:中世紀哲學》第二章中給出了兩種類型的永恒定義:“‘不間斷’的永恒(P-eternity)——一種沒有開端或沒有終結或兩者都沒有的永恒;或是(O-eternity)——一種存在于時間之外,不受時間規定的永恒”。經過理性理智之辨,波愛修開始了對永恒的探討。這里的永恒更類似于上面所說的“O-eternity”。
考試成績(T) 分為優良、及格和不及格三個等級,其中優良有6人、及格18人、不及格36人。根據公式(1) 計算得到信息熵為
對于實驗成績(A) 也分為優秀、一般、差三個等級,根據公式(2) 分別計算實驗成績優秀、一般、差的條件下考試成績的信息熵為:
2) 條件熵
利用公式(3) 計算以實驗成績(A) 分類的條件熵:
3) 信息增益
利用公式(4) 計算實驗成績(A) 的信息增益:
利用公式(5) 計算實驗成績(A) 的信息增益率為:
運用同樣的辦法,分別計算考勤成績(B) 、課堂表現(C) 的信息增益率分別為:
3.4 結果與反饋
由于GainR(C) >GainR(B) >GainR(A),所以選擇課堂表現(C) 作為決策樹的根節點,然后在每個分支上重復采用3.3的方法遞歸計算,構建決策樹如圖2所示。
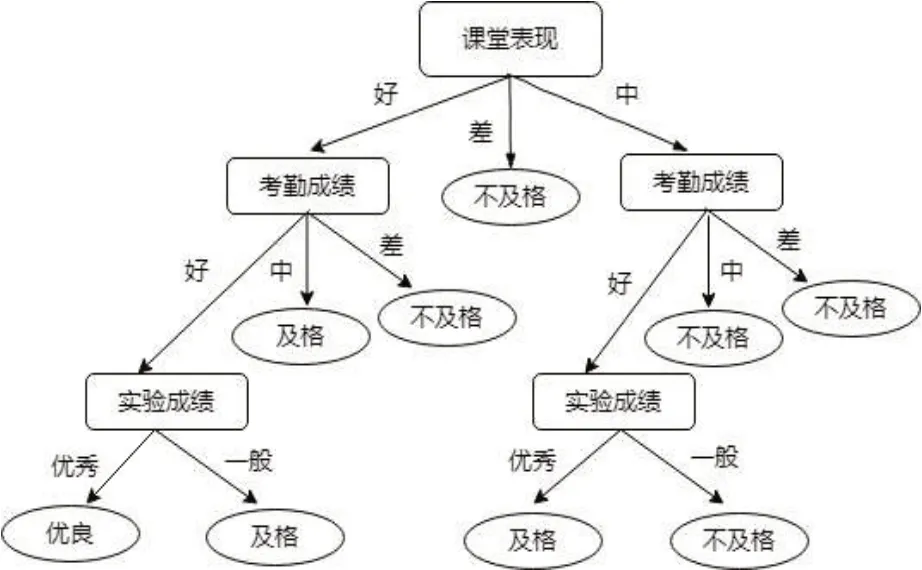
圖2 學生成績分析決策樹
為了避免決策樹C4.5模型對訓練集30名同學的考試成績信息實現較好的預測,而對測試集21名同學的考試信息預測較差,即出現“過渡擬合”現象,需要對圖2的決策樹進行剪枝操作,決策樹的剪枝策略分為預剪枝和后剪枝兩種。在此,采用后剪枝的方法對圖2決策樹進行剪枝,保留課堂表現、考勤成績對學生成績影響較大的屬性值,剪去影響較小的屬性值實驗成績,得到決策樹圖3。

圖3 修剪后的學生成績分析決策樹
通過決策樹圖2、圖3可以發現,學生只有課堂表現、考勤成績、實驗成績同時為優的時候,最終考試成績才能達到優良水平,有一項為一般水平的情況下考試成績為及格,兩項及以上表現不好,考試成績就會不及格。實際上,在訓練集60名學生的考試信息中,優良的人數僅有6 人,不及格的人數卻高達36 人,學生的考試成績偏低,導致這一結果的原因可能是由于試卷的難度過大,還需進一步深度地挖掘。
最后采用測試集21 名學生的考試信息對該決策樹進行檢驗,準確率達到了85%以上,說明該模型是有效的。
4 結論
文中構建了決策樹C4.5 模型,對21 級軟件81 名同學的考試信息進行深度挖掘,并驗證了該模型的可行性,該模型表明學生的期末考試成績與課堂表現、考勤和平時實驗有著密切的關系,因此,各任課教師應該加強過程管理,首先,課堂上調動學生積極參與到的教學過程中來,主動回答問題;其次,要加強考勤,避免學生出現遲到早退現象,有事要提前請假;最后,要注重平時實驗指導,提高學生的動手操作能力。這對提高學生考試成績有著至關重要的作用。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
信息通信技術(2015年6期)2015-12-26 01:16:46
中外會展(2014年4期)2014-11-27 07:46:46
電子設計工程(2014年18期)2014-02-27 12:00:13
故事作文·低年級(2009年10期)2009-10-20 04:28:46
