基于Pandas的農產品產銷數據預處理研究
2023-12-07 12:11:18胡世洋劉威
電腦知識與技術 2023年30期
胡世洋,劉威
(賀州學院,廣西 賀州 542899)
0 引言
隨著我國農業現代化的加速推進[1],農業產業化、市場化程度的提高,農產品數據的規模和復雜程度不斷增加,這給農產品生產和流通帶來了前所未有的機遇和挑戰。然而,這些數據來源多樣,存在規范化、標準化程度低等問題,這給數據的處理和分析帶來了很大的難度。為了更好地理解和應用農產品數據,研究者們已經開始探索和應用各種數據處理和分析方法,其中基于Pandas 庫的數據預處理方法已逐漸成為一個熱門領域。Pandas 作為一種快速、靈活、高效的數據處理和分析工具,在清洗、去重、缺失值處理、異常值處理、特征提取等方面都有著得天獨厚的優勢[2]。因此,本文旨在應用Pandas 庫中的各種數據處理方法,以實現對農產品產銷數據快速、準確和可靠地處理。
1 問題的概述
收集來的農產品數據往往需要二次加工,其原因包括以下幾個方面:第一,農作物成熟之后也可以成為農產品的一部分,所以農作物數據表有時候需要與農產品數據表合并在一起分析。第二,需要將原來農產品信息表與農產品產量表合并在一起形成一個更全面的農產品數據表。第三,需要將農產品數據表、商家數據表、顧客數據表、商品銷售表合并為一個寬表。第四,需要將數據表中記錄重復的、特征重復的數據刪除掉。第五,需要用可信賴的方式填充某些為空的字段值。第六,需要用可信賴的方式將明顯脫離正常范圍的字段值糾正到正常范圍。第七,需要將不同量綱的字段標準化處理。第八,需要將非連續字段轉換成虛擬變量[3]。第九,需要將連續數值離散化從而利于回歸分析。由于Pandas 可以高效地處理數據集。所以要以Python作為開發語言,以Pandas為數據分析工具來解決這些問題。
2 數據預處理過程
由于數據存放在MySQL數據庫中,所以要連接到MySQL數據庫。首先安裝pymysql工具包。其次利用sqlalchemy 庫中的create_engine 函數建立Python 程序與MySQL 數據庫的連接[4]。最后利用Pandas 中的read_sql_table讀取MySQL數據庫中的任意數據表。
2.1 合并數據
1) 縱向堆疊
農產品既包括農作物又包括對農作物進行二次加工過的產品,因此農產品應包括農作物里的內容。采用縱向堆疊的方式將農作物數據表的信息堆疊進農產品數據表之中。首先連接到MySQL數據庫,把農產品數據表和農作品數據表讀出來并放在DataFrame對象里面。其次使用Pandas 中的concat 函數來實現堆疊,設axis=0 可實現縱向堆疊,由于農產品和農作物的數據表字段未必完全一致,在此僅取它們兩張表字段的交集,因此將join參數設置為inner。最后將堆疊后形成的DataFrame 對象能過Pandas 中的to_sql 函數重新寫回到MySQL數據庫中的農產品數據表,此時設置if_exists 參數值為replace,從而刷新整個數據表中的數據,縱向堆疊過程如圖1所示。
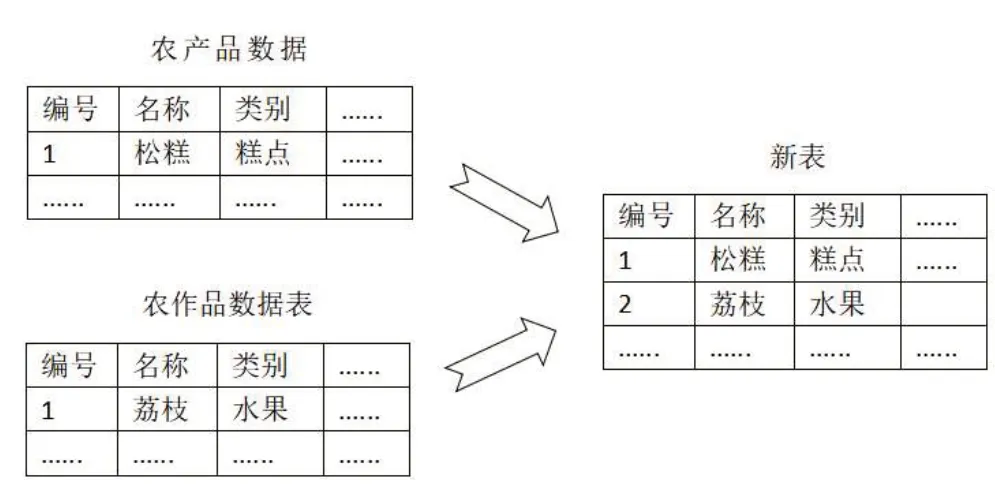
圖1 縱向堆疊示意圖
2) 橫向合并
原來收集的農產品數據表未涉及數量級別的字段,而農戶產量統計表中涉及農戶所管理的農產品數量內容。如果能將這兩個數據表合并成一個表,那么所生成的新的數據表將具備農產品特性和數量兩種類別的字段。這里采用橫向堆疊的方式來解決這個問題。將農產品數據表和農戶產量統計表在X 軸上進行拼接。首先連接到MySQL數據庫,把農產品數據表和農戶產量統計表讀出來并放在DataFrame對象里面。其次使用Pandas中的concat函數來實現堆疊,設axis=1實現橫向堆疊。在堆疊時排除掉農戶產量統計表中的編號一列。最后將堆疊后形成的新的DataFrame 對象重新寫回到MySQL 數據庫中,橫向堆疊過程如圖2所示。
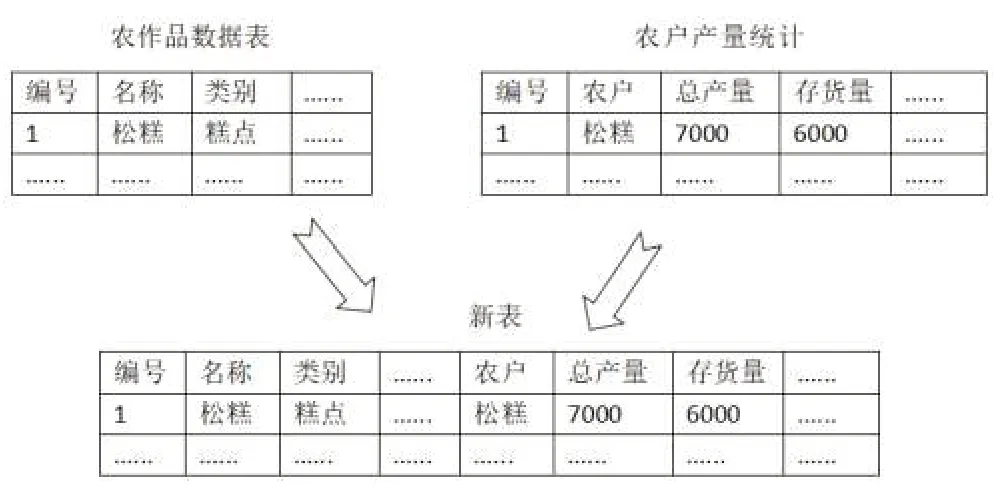
圖2 橫向堆疊示意圖
3) 主鍵合并
在數據分析時需要多個表連接在一起形成一個寬表。主鍵合并就是將多個數據集通過它們關聯的鍵連接起來。本文將以農產品數據表、商家數據表、顧客數據表、商品銷售表為例進行主鍵合并。利用農產品數據表中的主鍵“編號”和商品銷售表中的外鍵“商品”,可以將兩個表連接起來。利用商家數據表中的主鍵“編號”和商品銷售表中的外鍵“賣家”,可以將兩個表連接起來。利用顧客數據表中的主鍵“編號”和商品銷售表中的外鍵“買家”,可以將兩個表連接起來。在這個過程中,使用Pandas 中的merge 函數來實現數據的主鍵合并。最后將主鍵合并后形成的寬表重新寫回到MySQL 數據庫中,主鍵合并過程如圖3所示。

圖3 主鍵合并示意圖
2.2 清洗數據
1) 記錄重復
在數據收集過程中由于數據的來源是多方面的,而且前期數據模型的設計難免有不周到地方,這樣就會造成數據的部分重復。記錄重復在數據重復中比較常見,那些重復出現的數據記錄需要被刪除掉[5]。在這個過程中需要使用Pandas中的drop_duplicates函數來實現記錄去重。由于寬表的字段特別多,全面匹配才認為是重復的做法是不可取的。因此選取幾個重要的字段比如商品編號、賣家、買家和交易時間,作為是否重復的判斷依據。由于同一交易時間不可能出現兩次相同的交易,所以這些選取的字段出現了重復就認為這條記錄是重復的,可以被刪除掉。最后將去重后的DataFrame 對象能過Pandas 中的to_sql 函數重新寫回到MySQL數據庫中農產品銷售寬表,記錄重復如圖4所示。
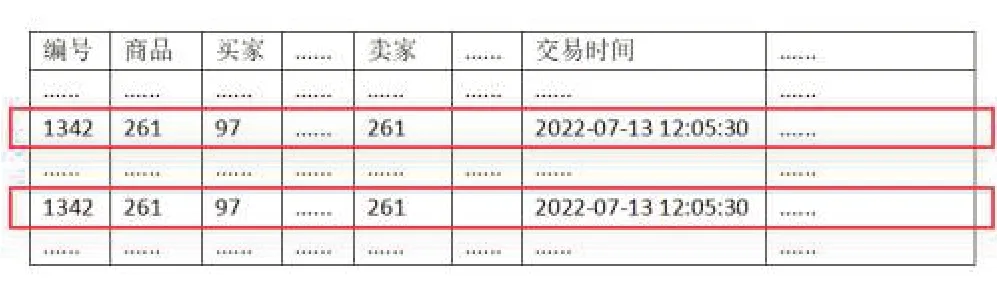
圖4 記錄重復示意圖
2) 特征重復
將農產品數據表、商家數據表、顧客數據表、商品銷售表四合表進行主鍵合并,從而形成農產品銷售寬表。這個寬表里面的數據必然存在冗余的情況。例如:原農產品數據表中的“編號”和原商品銷售表中的“商品”這兩個字段在新的寬表里面顯然是重復的。這些冗余的字段不僅造空間的浪費而且不利于后面的數據分析與挖掘。所以這些冗余字段需要被找出來并刪除掉。在這個過程中,需要建立一個行和列都等于農產品銷售寬表列數的布爾數組。通過DataFrame.equals 方法將農產品銷售寬表的不同列進行比較,如果值都相等就將布爾數組對應的行和列的元素置為“真”,否則置為“假”,這樣就得到一個布爾矩陣。然后遍歷這個布爾矩陣,將重復的字段找出來,并使用Pandas的drop函數刪掉。最后將去重后的DataFrame 對象寫回到MySQL 數據庫中,特征重復如圖5所示。
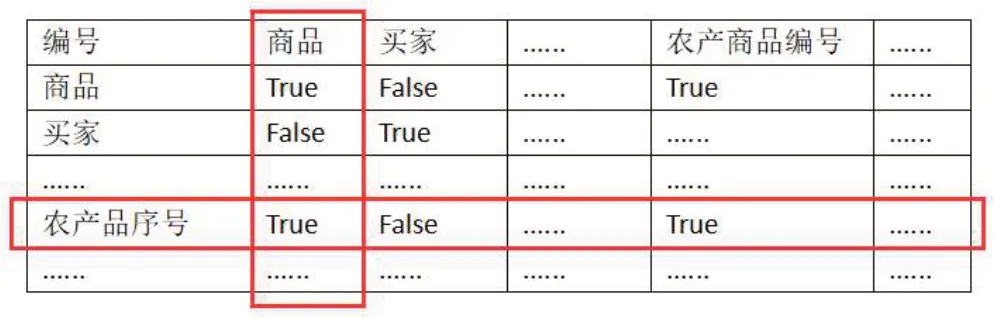
圖5 特征重復示意圖
3) 檢測與處理缺失值
收集到的數據可能存在缺失值,即某幾條記錄的某些字段值為空。解決這些空值有多種方法。比如刪除法、替換法和插值法等。刪除法是利用Pandas中的dropna 方法將含有空值的記錄刪除掉。這樣做存在明顯不合理之處,存在空值的記錄不一定都要刪除,該記錄的其他非空字段很可能也存在重要的研究價值。替換法則是利用該字段下的平均數、中位數等統計量來填充記錄中的空值。利用平均數、中位數等來填充空值可能會影響數據的標準差,導致信息的波動。插值法是通過求解多項式來得到一個值,然后讓這個值來替換記錄中的空值。此處采用插值法來解決這個問題。要使用插值法需要找到與本字段相關的另一個沒有空值的字段。以商品信息表為例,存貨量存在空值,找到跟存貨量有一定關聯的字段,即總產量。首先要根據總產量和存貨量這兩個字段擬合出來一個多項式函數。再根據存在存貨量為空的記錄對應的總產量和多項式函數計算出該記錄存貨量的值,將這個值再插入數據表里面。
4) 檢測與處理異常值
在農產品數據表里面也會出現明顯偏離正常的數值。這些數值可能來源于數據收集時的錯誤,或者程序調試時遺留的臟數據。這樣的數值也稱為離群點[6]。這些離群點的存在會給以后的數據分析帶來極大的隱患,甚至會導致預測的結果出現偏差。可以使用3σ 原則來進行數值的異常檢測,也可以使用箱線圖分析法來進行數值異常檢測。此處以農產品的銷售金額為例,使用箱線圖分析法來闡述異常數值檢測與矯正過程。首先從數據庫讀取農產品銷售表。其次計算箱線圖的五個統計量。使用quantile函數再加上0.25 的參數可以計算出下四分數(即QU) ,如果參數改成0.75可算以上四分數(即QL) 。由上四分數減下四分數可計算機中位數(即IQR) 。利用公式QU +1.5×IQR 可計算出最大值,如果數值超過了最大值就用上四分數來替代其原有值。利用公式QL-1.5 ×IQR可計算出最小值,如果數值超過了最小值就下四分數來替代其原有值。最后將新的DataFrame對象寫回到數據庫當中,日銷金額箱線圖如圖6所示。
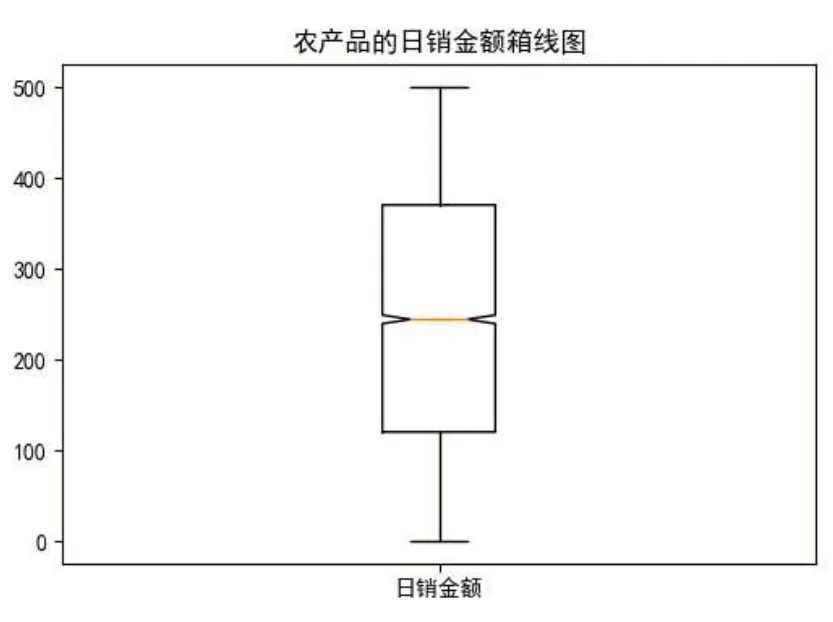
圖6 農產品日銷金額箱線圖
2.3 標準化數據
想要根據農產品的存貨量、總產量和日銷量等這些因素來分析農戶的年度利潤就會面臨特征字段量綱不同的問題。存貨量和總產量的數值遠遠高于日銷量。但是日銷量對年度利潤的影響也很大。為了不影響以后數據分析的準確性,就需要消除這些量綱的差異,即進行數據標準化處理。數據標準化處理常用的方法有離差標準化[7]、標準差標準化、小數定標標準化等。為了不改變數據原有的分布情況,這里采用小數定標標準化處理方法[8]。小數定標標準化轉換公式如公式1所示:
通過這個公式可以看出小數定標標準化的關鍵是k值的確定。把待處理的這列數據作為一個Series對象。再對Series對象里面數值的絕對值的最大值求10 的對數作為k 的取值。按照轉換公式對相關字段進行標準化處理,最后將處理的DataFrame 對象通過tosql函數重新寫回數據庫中。
2.4 轉換數據
1) 啞變量處理
為分析不同地區農產品價格的差異,把字段“市”進行啞變量處理。因為“市”作為一個地區類別的字段并非連續型的。非連續字段的值不能做加減計算,不利于以后對農產品銷售情況進行回歸分析,因此需要將“市”這個區域類別轉換成虛擬變量。再利用這些虛擬變量做回歸分析。這個過程需要利用Pandas的get_dummies 函數轉換成啞變量DataFrame,將啞變量DataFrame與原商品信息進行橫向合并。最后將最終的DataFrame 對象寫回數據當中,啞變量處理過程如圖7所示。

圖7 啞變量處理示意圖
2) 離散化連續性數據
分析農產品在8月份的銷量變化情況需要將7、8月份農產品的銷量數據離散化。按照銷售量的大小將其分成幾個區間,然后用變量表示每個區間的銷售量范圍,啞變量作為自變量,以時間為因變量,進行回歸分析,以評估銷售量區間之間的相關性和趨勢。通過這種方法,可以更好地理解銷售量的變化趨勢和影響因素。在具體處理過程中,利用聚類分析法將商品信息統計表中的銷量一列數值劃分為5個類別,形成一個新的Series。然后將新的值再進行啞變量處理。將處理后形成的DataFrame再與商品信息統計表進行橫向堆疊。最后將形成的最終DataFrame寫入數據庫當中,離散化處理過程如圖8所示。
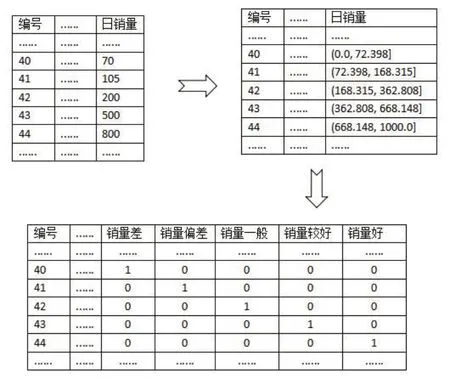
圖8 離散化連續性數據示意圖
3 結束語
本文介紹如何利用Pandas 技術來實現農產品產銷數據預處理。經過預處理之后的數據可以更為方便地被理解和分析。這也為將來對農產品市場的預測、供應鏈的優化、市場競爭力的提升提供技術支持,這也利于農產品的市場監管和市場推廣。同時探索、研究和應用更加先進的數據處理方法,也是農業數據化建設和現代化進程的必然要求。
猜你喜歡
口腔護理用品工業(2021年4期)2021-11-02 08:22:56
機械工業標準化與質量(2018年5期)2018-05-30 09:48:17
中國公路(2017年9期)2017-07-25 13:26:38
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
質量與標準化(2015年7期)2015-07-12 12:21:02
汽車維修與保養(2015年8期)2015-04-17 03:32:51
