基于LSTM和灰色模型的股價時間序列預(yù)測研究
2023-12-16 04:46:36韓金磊熊萍萍孫繼紅
南京信息工程大學(xué)學(xué)報 2023年6期
韓金磊 熊萍萍 孫繼紅
股價預(yù)測;綜合預(yù)測;文本分析;誤差修正;長短期記憶網(wǎng)絡(luò)(LSTM);灰色模型
0 引言
股權(quán)融資是直接融資的一種重要渠道,能夠?qū)F(xiàn)實生活中多余的資金籌集起來,緩解融資約束.在一個成熟的市場上,股票的價格應(yīng)當(dāng)反映股票的內(nèi)在價值.然而,內(nèi)在價值的判定涉及折現(xiàn)率等一系列問題,很難做出精確的度量.在投資時,多數(shù)投資者所關(guān)注的僅是些常見的技術(shù)性指標(biāo)和基本財務(wù)指標(biāo),但即使在資本市場發(fā)達的美國依然很難達到強有效或者半強有效市場,股票價格不免遭到國家政策、地緣政治、投資者情緒等突發(fā)性宏觀或微觀因素的影響.因此,在進行投資時,對股價做一個較為綜合的考量,能幫助投資者降低投資風(fēng)險,具有一定現(xiàn)實意義.
股價數(shù)據(jù)具有非線性、非平穩(wěn)、高噪聲、強時變性等非常顯著的特征,對股價的預(yù)測具有一定挑戰(zhàn).縱觀已有研究,早期的研究主要運用技術(shù)分析或經(jīng)典時間序列模型.其中,技術(shù)分析是結(jié)合股票的成交量、成交價格等常見的市場指標(biāo)來判定股價走勢.研究者常結(jié)合時間序列模型來預(yù)測股價,常用的模型有差分整合移動平均自回歸(ARIMA)模型[1]、針對金融數(shù)據(jù)波動聚集效應(yīng)的廣義自回歸條件異方差(GARCH)模型[2]及ARIMA模型的變種——向量自回歸(VAR)模型[3].除傳統(tǒng)的計量模型外,灰色模型[4]、BP神經(jīng)網(wǎng)絡(luò)模型[5]以及模糊理論[6]在股價預(yù)測中也有較多應(yīng)用,但這些模型存在一定的缺陷,即對非線性、長期時間序列的效果較差.
隨后,學(xué)者們對各種模型進行了結(jié)合與改進.針對模型中存在的多重共線性問題,使用主成分分析(PCA)[7]或LASSO方法[8]進行變量的降維篩選.參數(shù)的優(yōu)化也是其中的改進方向之一,智能優(yōu)化算法借鑒自然中常見的現(xiàn)象設(shè)計算法,因原理簡單、收斂速度快成為較常用的工具,其中,細菌群體趨藥性、果蠅、遺傳優(yōu)化等算法在處理模型的最優(yōu)權(quán)值結(jié)構(gòu)中有廣泛的應(yīng)用,且多應(yīng)用于超參數(shù)較多的BP、Elman神經(jīng)網(wǎng)絡(luò)以及非線性支持向量機等機器學(xué)習(xí)模型[9-12].鑒于模型各有針對性,有學(xué)者運用ARIMA、GM(1,1)、RBF神經(jīng)網(wǎng)絡(luò)等多個模型構(gòu)成了一個集成預(yù)測結(jié)果[13].有研究提出一種聯(lián)合卷積神經(jīng)網(wǎng)絡(luò)(CNN)和長短期記憶網(wǎng)絡(luò)(LSTM)方法的預(yù)測模型,使用CNN提取股價的圖像特征,使用LSTM提取股價的時序特征[14].針對股價非線性非平穩(wěn)的特征,研究者使用小波分析對股價自身或者是股價的影響因素先進行分解,再建立ARIMA模型、BP神經(jīng)網(wǎng)絡(luò)或支持向量回歸機(SVR)模型進行預(yù)測與重構(gòu),也獲得了不錯的效果[15-18].同小波分解一樣,經(jīng)驗?zāi)B(tài)分解(EMD)原是工程領(lǐng)域用于分解復(fù)雜信號的一種方法,由于其對非線性非平穩(wěn)序列更好的適用性廣受研究者青睞,與長短期記憶網(wǎng)絡(luò)(LSTM)、非線性孿生支持向量回歸機(TSVR)等模型結(jié)合可以有效地預(yù)測股價[19-20].
隨著人工智能和機器學(xué)習(xí)的發(fā)展,更多研究涉及深度學(xué)習(xí)[21].長短期神經(jīng)網(wǎng)絡(luò)(LSTM)能有效提取股價序列中的信息且在一定程度上緩解循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)梯度消失和梯度爆炸的問題[22],在股價時間序列中得到了廣泛應(yīng)用.有研究選取技術(shù)性、基本面指標(biāo)基于LSTM、門控循環(huán)單元結(jié)構(gòu)(GRU)模型構(gòu)建混合神經(jīng)網(wǎng)絡(luò),同時,多延遲嵌入張量處理技術(shù)(MDT)與注意力機制(CBAM)也被較好地與LSTM模型相結(jié)合[23-24].近年來,研究者開始關(guān)注一些投資者心理方面的因素.百度搜索指數(shù)、新浪微博情緒指數(shù)被證實對股價的短期預(yù)測具有一定的作用[25-27].機器學(xué)習(xí)為這種非結(jié)構(gòu)化數(shù)據(jù)的處理提供了技術(shù)支持,媒體報道、公司新聞、微博評論等非結(jié)構(gòu)化數(shù)據(jù)被用于提取情緒時間序列[28-30].隨后,有研究在此基礎(chǔ)上考慮了財務(wù)指標(biāo)、技術(shù)性指標(biāo)和網(wǎng)絡(luò)輿情3種信息來源,使用支持向量分類器(SVM)對股價的漲跌進行預(yù)測[31].
結(jié)合已有文獻,不難發(fā)現(xiàn)研究中還存在著值得改進的方面.首先在考慮特征變量時存在過于隨意或考慮不足的問題.其次,結(jié)合文本對股價進行分析的文獻相對較少,且對股價的文本分析往往只采用詞典法,然而所用的金融詞典并不完善,在反映投資者情緒時效果可能欠佳.另外,殘差項作為預(yù)測值與真實值的誤差往往包含了許多未被利用到的有用信息,但大多數(shù)研究者對此關(guān)注甚少.針對上述問題,本文提出了以下解決方案:1)考慮基本面和技術(shù)分析及投資者情緒等多層面指標(biāo)作為特征對股價問題進行分析和預(yù)測,從多個層面選取特征變量;2)嘗試創(chuàng)建股市語料庫,并使用樸素貝葉斯的方法進行訓(xùn)練,對投資者的每日情緒指數(shù)進行較為精確的測算,以便更好地衡量投資者情緒;3)運用對小樣本常用的灰色GM(1,1)模型對預(yù)測與真實值的殘差項進行修正,更加充分地挖掘股價內(nèi)在信息.
1 方法與原理
1.1 LSTM模型
步驟1:決定細胞中丟棄的信息,該操作由遺忘門來完成.首先讀取當(dāng)前輸入xt和前神經(jīng)元信息ht-1,由遺忘門ft來決定丟棄的信息,具體計算公式如下:
ft=σ(Wf[ht-1,xt]+bf).
(1)
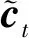
it=σ(Wi[ht-1,xt]+bi),
(2)
(3)
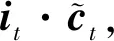
(4)
步驟4:確定輸出,使用sigmoid層確定細胞狀態(tài)中輸出的部分,接著將細胞狀態(tài)通過tanh進行處理,并將其和sigmoid層輸出相乘,具體計算公式如下:
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ot·tanh(ct).
(6)
1.2 GM(1,1)模型
灰色系統(tǒng)理論是一種針對小樣本、貧信息的數(shù)據(jù)挖掘方法,在部分信息已知,部分信息未知的灰狀態(tài)下,具有十分優(yōu)良的性能.GM(1,1)是經(jīng)典灰色模型,能夠簡單有效地挖掘出數(shù)據(jù)的內(nèi)在信息[33],主要的建模步驟如下:
設(shè):X(0)=(x(0)(1),x(0)(2),…,x(0)(n))為系統(tǒng)特征變量序列,其中:x(0)(k)≥0,k=1,2,…,n;X(1)為X(0)的一階累加生成(1-AGO)序列;Z(1)為X(1)的緊鄰均值生成序列,見式(7)—(8).
(7)
k=2,3,…,n.
(8)
(9)
k=1,2,…,n.
(10)
進一步,對式(10)進行累減還原,并求出對應(yīng)X(0)的時間響應(yīng)式,計算過程見式(11)—(12),其中α(1)表示一階累減生成算子.
k=1,2,…,n,
(11)
k=1,2,…,n.
(12)
1.3 綜合預(yù)測與殘差修正的主要步驟
本文所采取的綜合預(yù)測與殘差修正的主要步驟如下:
1) 獲取基本面指標(biāo);
2) 爬取東方財富網(wǎng)的股評、百度指數(shù);
3) 使用SnowNLP模型進行情緒指數(shù)的計算;
4) 使用自適應(yīng)提升法(AdaBoost)模型進行特征變量的提取,并參考方差膨脹因子(VIF)進行取舍;
5) 使用多變量LSTM模型對股價進行預(yù)測;
6) 對預(yù)測結(jié)果的殘差項進行修正;
7)評估模型.
預(yù)測模型的技術(shù)路線如圖2所示.
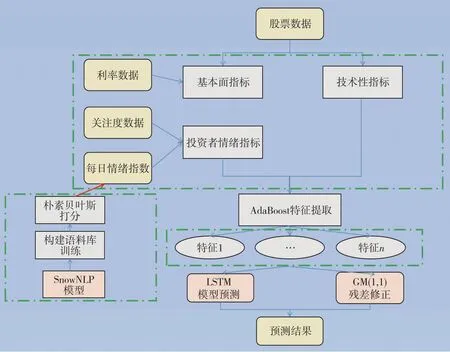
圖2 預(yù)測模型的技術(shù)路線Fig.2 Technical route of stock price time series prediction model
2 模型構(gòu)建
2.1 數(shù)據(jù)來源
本文所選的數(shù)據(jù)大致有3個來源,其中:股價用R語言中的pedquant包進行獲取,計算相關(guān)技術(shù)性指標(biāo)和基本的財務(wù)指標(biāo)(財務(wù)指標(biāo)如權(quán)益凈利率等僅在年報、半年報、季報才能獲得,而股價是日度數(shù)據(jù),因此,僅選取市盈率等指標(biāo));利率選取了上海銀行間同業(yè)拆放利率作為市場無風(fēng)險利率,其對應(yīng)的數(shù)據(jù)來源于官網(wǎng)(https://www.shibor.org/shibor/),匯率的數(shù)據(jù)來源于中國貨幣網(wǎng)(https://www.chinamoney.com.cn/),選取的是人民幣兌美元的匯率;投資者情緒相關(guān)的數(shù)據(jù)源于東方財富網(wǎng)(http://guba.eastmoney.com/)及百度指數(shù)官網(wǎng)(https://index.baidu.com/),這些數(shù)據(jù)主要使用Python爬取及處理,將在下一部分進行詳細描述.?dāng)?shù)據(jù)時間范圍為2021年7月12日至2022年4月25日,剔除不交易的日期,共計191天.為驗證模型的穩(wěn)健性,選取上證指數(shù)(1A0001)以及格力電器(000651)兩組數(shù)據(jù),并著重對格力電器的股價進行分析及預(yù)測.
2.2 變量篩選
為防止過擬合、多重共線性等問題,按照以下步驟進行變量的篩選.首先進行相關(guān)性及顯著性檢驗;接著,為防止多重共線性,使用計量中常用的方差膨脹因子(VIF)進行判斷,進行變量的篩選;隨后,使用AdaBoost模型觀察變量的重要程度.限于篇幅,相關(guān)性及方差膨脹因子的相關(guān)數(shù)據(jù)這里不作展示.在圖3中,按照變量的重要程度進行排序,發(fā)現(xiàn)對上證指數(shù)影響較大的特征變量分別為adx_adx、macd_signal、cci_20、emv_maemv、obv_、atr_atr、ex_rate、r_f.格力電器(圖3)亦按照變量的重要性由小到大的順序進行排列,發(fā)現(xiàn)影響較大的特征變量分別為pe_trailing、atr_atr、obv_、ex_rate、dpo_20、r_f.表1是變量的含義及描述性統(tǒng)計[34].對特征變量繪制變量的依賴關(guān)系,如圖4所示.
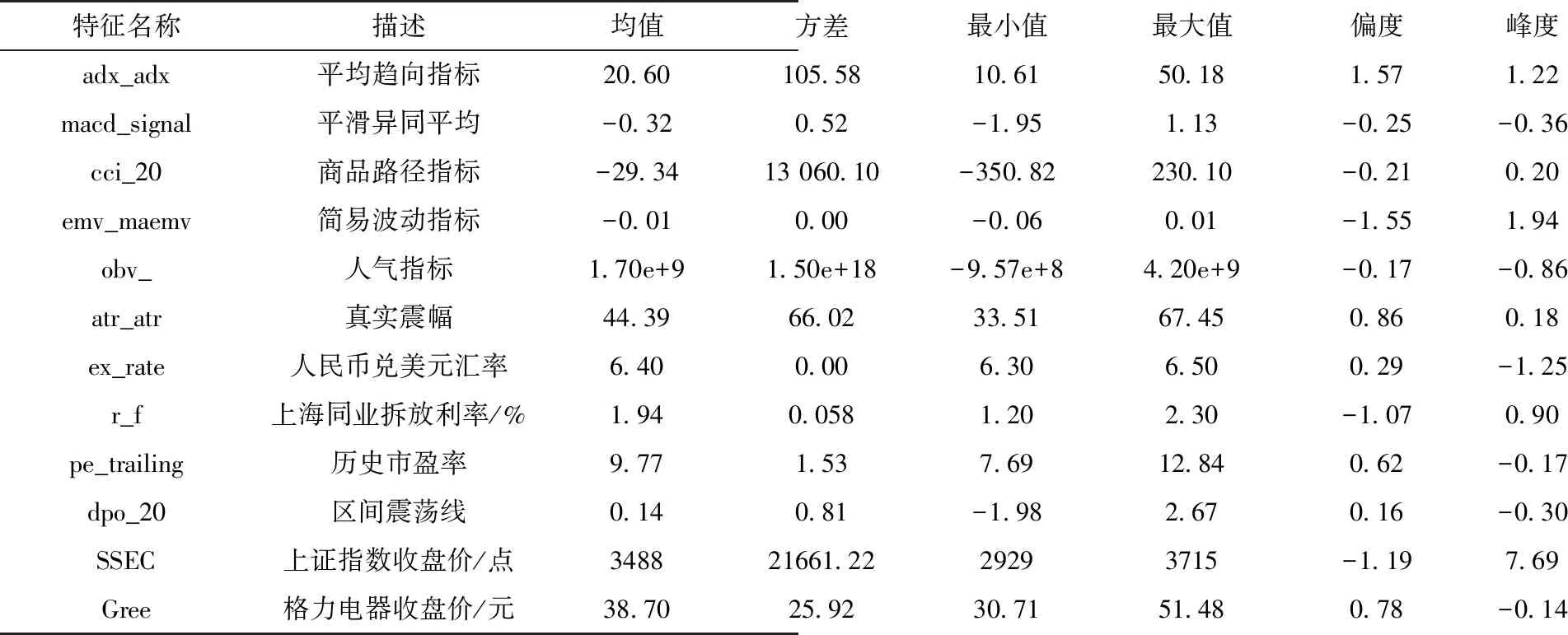
表1 重要特征變量以及響應(yīng)變量的描述性統(tǒng)計[34]
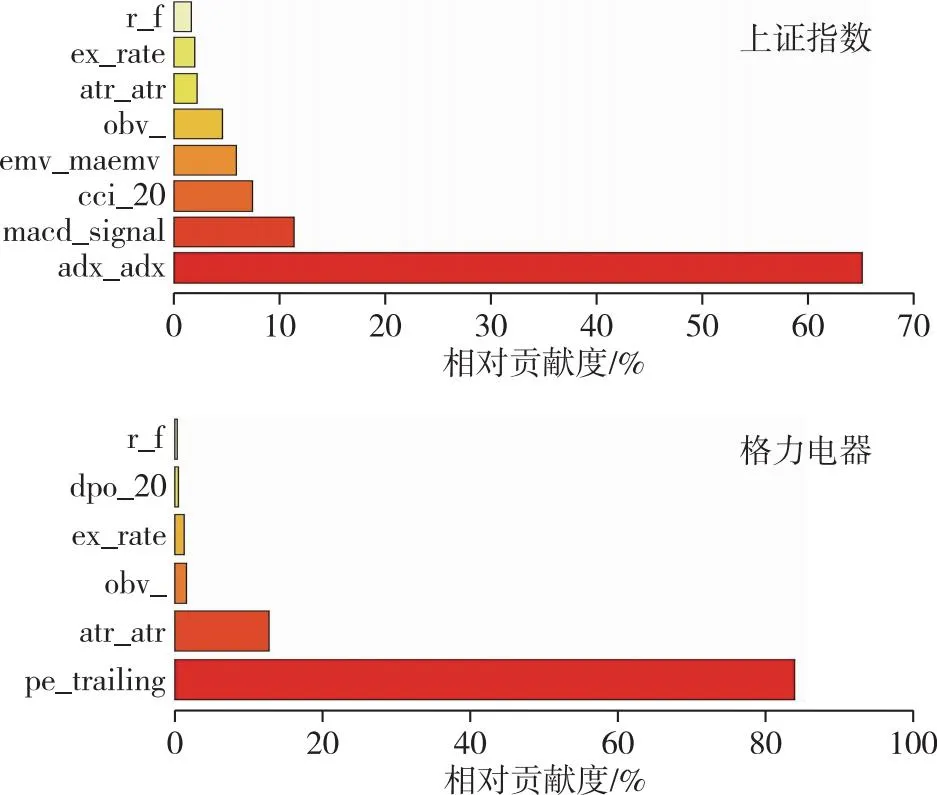
圖3 上證指數(shù)及格力電器重要特征變量Fig.3 Key characteristic variables of SSE index and Gree Electric Appliances
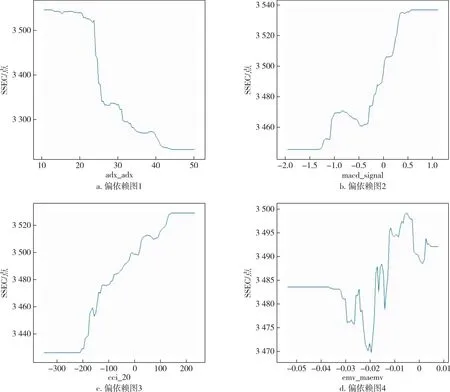
圖4 上證指數(shù)重要特征變量偏相關(guān)依賴圖Fig.4 Partial correlation dependence of key characteristic variables for SSE Index
從圖4中可以看出反映超買超賣的cci_20以及趨勢型指標(biāo)macd_signal兩個指標(biāo)和上證指數(shù)SSEC大致呈現(xiàn)出正向相關(guān)的態(tài)勢,而反映趨勢強度的adx_adx指標(biāo)與上證指數(shù)之間的關(guān)系大致是負向,其中,反映成交量與人氣的emv_maemv指標(biāo)和上證指數(shù)SSEC之間的關(guān)系存在顯著的非線性關(guān)系.投資者在進行投資時可以著重關(guān)注這些影響較大的技術(shù)性指標(biāo).與此同時,在圖5中也能看出反映公司價值的基本面指標(biāo)pe_trailing與格力電器Gree的股價是正向的,因此投資者在進行投資時,不應(yīng)該過于追求安全性,僅選市盈率較低的股票進行投資.反映震蕩幅度的指標(biāo)atr_atr、人氣型指標(biāo)obv_及匯率ex_rate與格力電器Gree的股價之間的關(guān)系比較復(fù)雜,在一定程度上反映了市場上不同投資者的態(tài)度以及產(chǎn)品的銷售狀況.
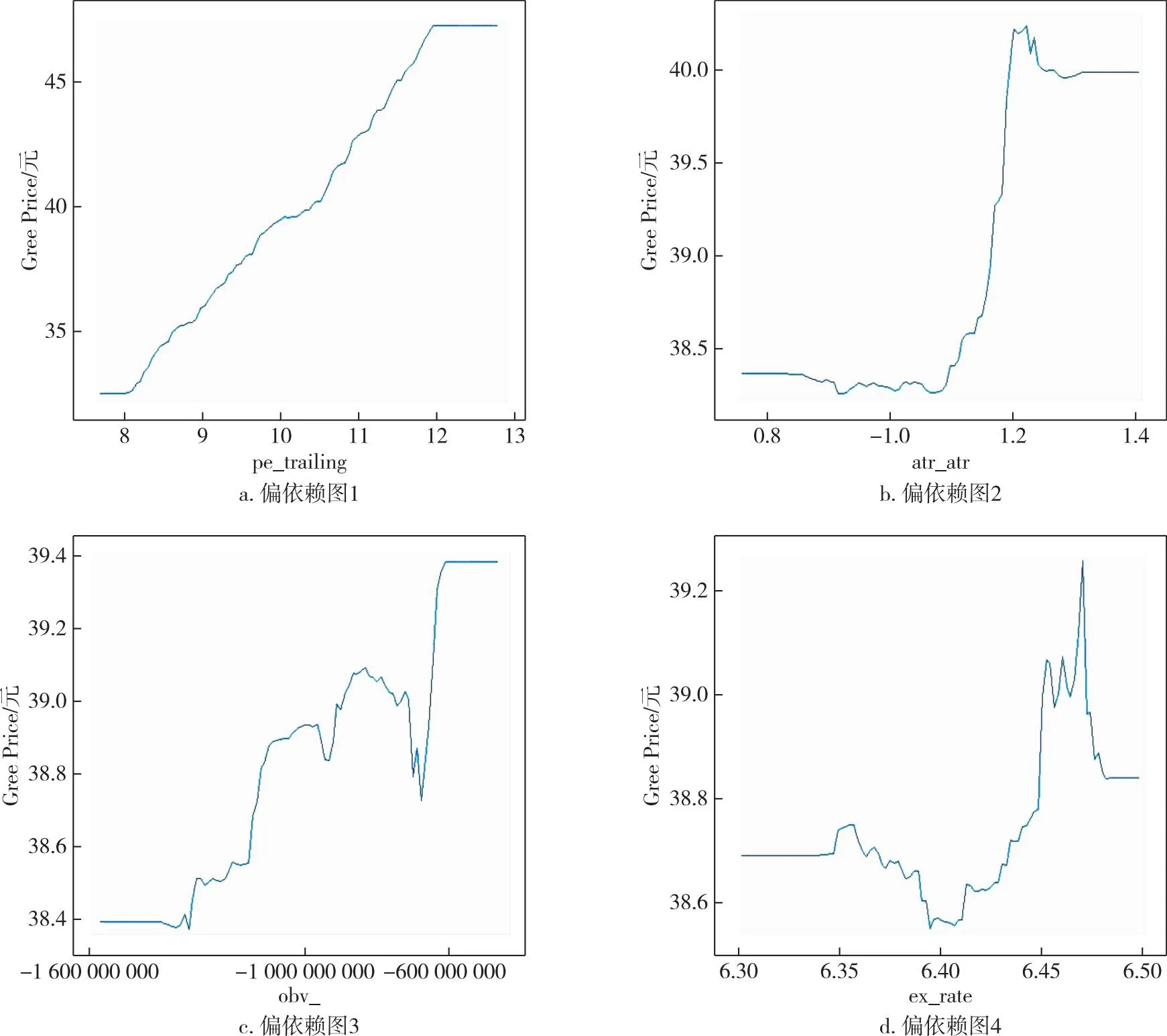
圖5 格力電器重要特征變量偏相關(guān)依賴圖Fig.5 Partial correlation dependence of key characteristic variables for Gree Electric Appliances
從表1能夠看出:1)平滑異同平均(macd_signal)、簡易波動指標(biāo)(emv_maemv)、區(qū)間震蕩線(dpo_20)與人氣指標(biāo)(obv_)、真實震幅(atr_atr)、上證指數(shù)(SSEC)在量綱上差距較大,后續(xù)在處理特征變量和響應(yīng)變量時將進行歸一化處理;2)數(shù)據(jù)都存在一定程度的左偏或者右偏,其中,上證指數(shù)相對正態(tài)分布呈現(xiàn)出“尖峰厚尾”的特征;3)量綱接近的指標(biāo)中平均趨向指標(biāo)(adx_adx)以及真實振幅(atr_atr)兩個指標(biāo)的方差較大,數(shù)據(jù)較為分散.
2.3 評價指標(biāo)
本文采用如下的評估指標(biāo)來評價模型預(yù)測效果:
1)均方根誤差(RMSE):
(13)
2)平均絕對百分比誤差(MAPE):
(14)
2.4 文本情緒指數(shù)計算
東方財富網(wǎng)股吧(https://guba.eastmoney.com/)是我國最大的股市投資者交流貼吧,本文選擇其中的帖子來計算情緒指數(shù).對爬取的文本進行預(yù)處理,去除一些沒有意義的圖片、數(shù)字及標(biāo)點符號,通過整理每天的帖子計算每日的情緒指數(shù).
常見的文本情緒指數(shù)計算有兩種方法:一種是機器學(xué)習(xí)的方法,即先對文本進行分類選出積極消極的文本,通過支持向量機、樸素貝葉斯等模型進行訓(xùn)練,然后用訓(xùn)練完的模型進行應(yīng)用,計算每天的情緒指數(shù);另一種是運用詞典的方法進行判定,構(gòu)建情感詞典,運用構(gòu)建的情感詞典篩選出每日的積極情感詞和消極的情感詞[35],其關(guān)鍵是情感詞典的構(gòu)建,構(gòu)建一個詳盡的中文金融情感詞典十分重要.本文采用前一種方法,通過搜集一些已有文本,再加上作者標(biāo)注的文本,構(gòu)建積極和消極的語料并使用樸素貝葉斯進行分類,部分打標(biāo)簽的語料如表2所示.

表2 部分語料歸類
本文抓取的上證指數(shù)以及格力電器的帖子時間跨度為2021年7月12日至2022年4月25日,除去其中沒有交易的天數(shù),共計191天,上證指數(shù)和格力電器帖子的條數(shù)分別為1萬余條及12萬余條,部分?jǐn)?shù)據(jù)內(nèi)容及打分如表3所示,效果較好,優(yōu)于一般的情感詞典法(情緒指數(shù)范圍為0~1).

表3 部分帖子內(nèi)容
通過計算整理得出每日的情緒指數(shù).由于量綱的差異,先對變量進行標(biāo)準(zhǔn)化處理,并計算文本情緒指數(shù)em與響應(yīng)變量(收盤價)之間的灰色關(guān)聯(lián)度[36],經(jīng)計算,得出上證指數(shù)與格力電器文本情緒指數(shù)與各自收盤價的灰色關(guān)聯(lián)度分別為0.71和0.70,有較大關(guān)聯(lián)性.股價關(guān)注度也是投資者情緒的一種體現(xiàn)[37],因此計算了投資者的關(guān)注度att,計算方式見式(15)[38],其中,AbbrSVL表示股票簡稱搜索量,CodeSVL表示股票代碼搜索量.發(fā)現(xiàn)投資者關(guān)注度att與對應(yīng)的收盤價也有較強的關(guān)聯(lián),因此將投資者情緒em以及投資者關(guān)注度att共同作為特征變量.
att=ln(AbbrSVL+CodeSVL).
(15)
2.5 LSTM模型參數(shù)設(shè)置
使用多變量LSTM模型在深度學(xué)習(xí)平臺Tenorflow上搭建神經(jīng)網(wǎng)絡(luò).構(gòu)建3層的神經(jīng)網(wǎng)絡(luò),其中2層為隱藏層,第3層為輸出層,第1層包含80個神經(jīng)元,第2層包含了100個神經(jīng)元,用表1中選擇的變量作為特征變量,使用默認(rèn)的學(xué)習(xí)率0.01,使用Adam優(yōu)化器,選擇均方誤差作為損失函數(shù),迭代次數(shù)epoch以及每次喂入的數(shù)據(jù)batchsize分別為50和64.
2.6 誤差修正
為進一步減小模型的誤差,首先選出誤差較小的基準(zhǔn)模型,再使用滾動GM(1,1)模型進行修正,用前7天的誤差預(yù)測第8天的誤差,充分挖掘殘差項的信息.對于其中出現(xiàn)的負的殘差項,首先對數(shù)據(jù)加上一定的正數(shù)進行建模,再對殘差進行相應(yīng)的預(yù)測,預(yù)測出對應(yīng)的數(shù)據(jù)后再減去原來加上的正數(shù)還原,得出最終預(yù)測的殘差項.
3 實證分析
3.1 股價時間序列預(yù)測
本文選擇格力電器的收盤價作為響應(yīng)變量進行預(yù)測,因為格力電器作為A股市場的白馬股具有一定的代表性.從191天的數(shù)據(jù)中,選取樣本中前140天的數(shù)據(jù)作為訓(xùn)練集,后51天的數(shù)據(jù)作為測試集.采用滾動預(yù)測的方法,用前7天特征變量的數(shù)據(jù)預(yù)測第8天的標(biāo)簽,即收盤價的數(shù)據(jù).根據(jù)前面的工作,選擇的特征變量分別為pre_trailing、atr_atr、obv_、ex_rate、dpo_20、r_f以及后面加入的情緒相關(guān)變量att、em及其自身的收盤價共計9個特征變量.具體的預(yù)測結(jié)果如圖6所示.為了說明模型的穩(wěn)健性,本文加上了同為電器行業(yè)的飛科電器(603868)以及美的集團(000333)的股價,采用同樣的方法在同一時間段內(nèi)進行預(yù)測,預(yù)測結(jié)果分別如圖7和圖8所示,其中Gree、Flyco、Midea分別表示格力電器、飛科電器、美的集團三支股票.
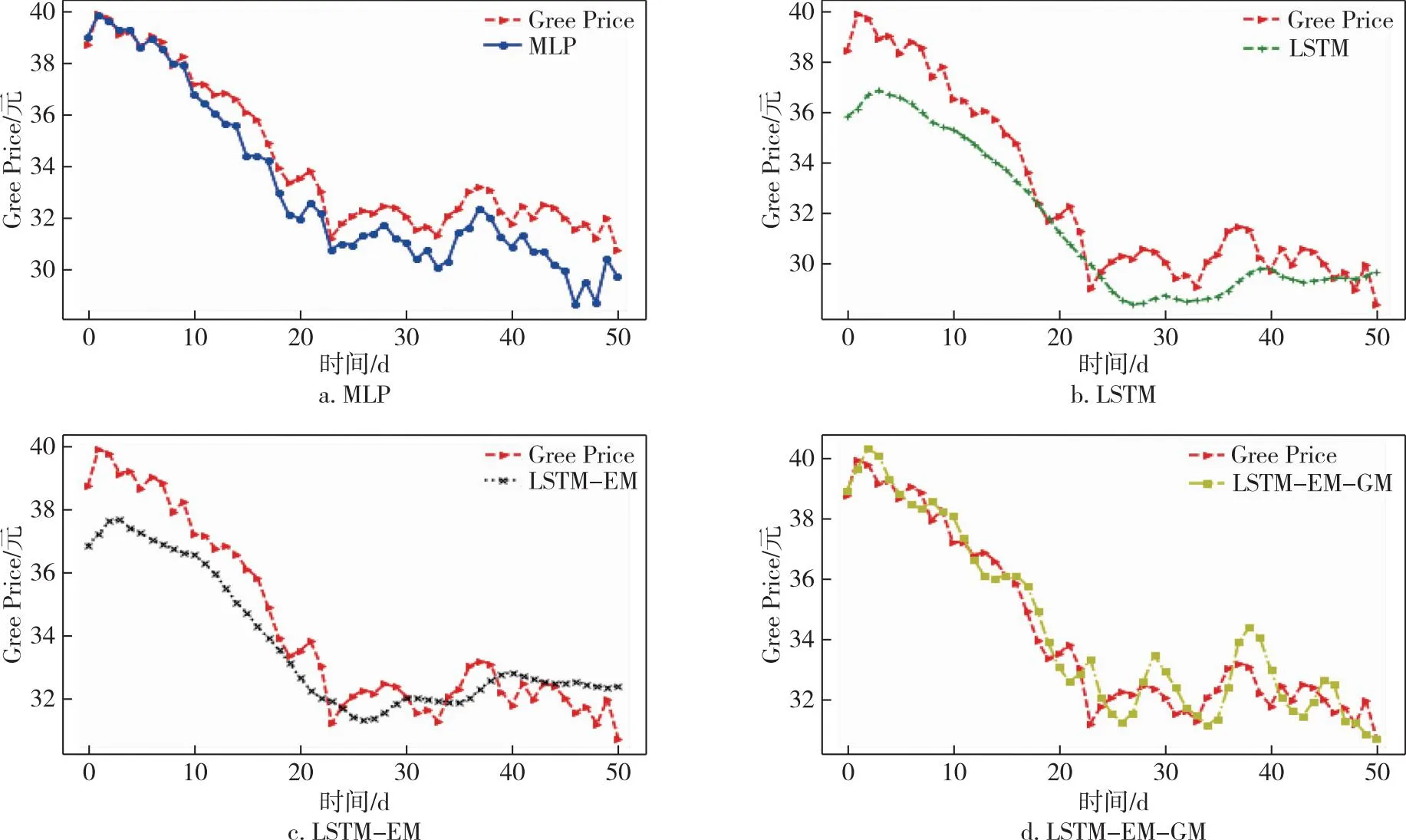
圖6 不同模型格力電器股價預(yù)測比較Fig.6 Comparison of Gree Electric Appliances stock prices forecasted by different models
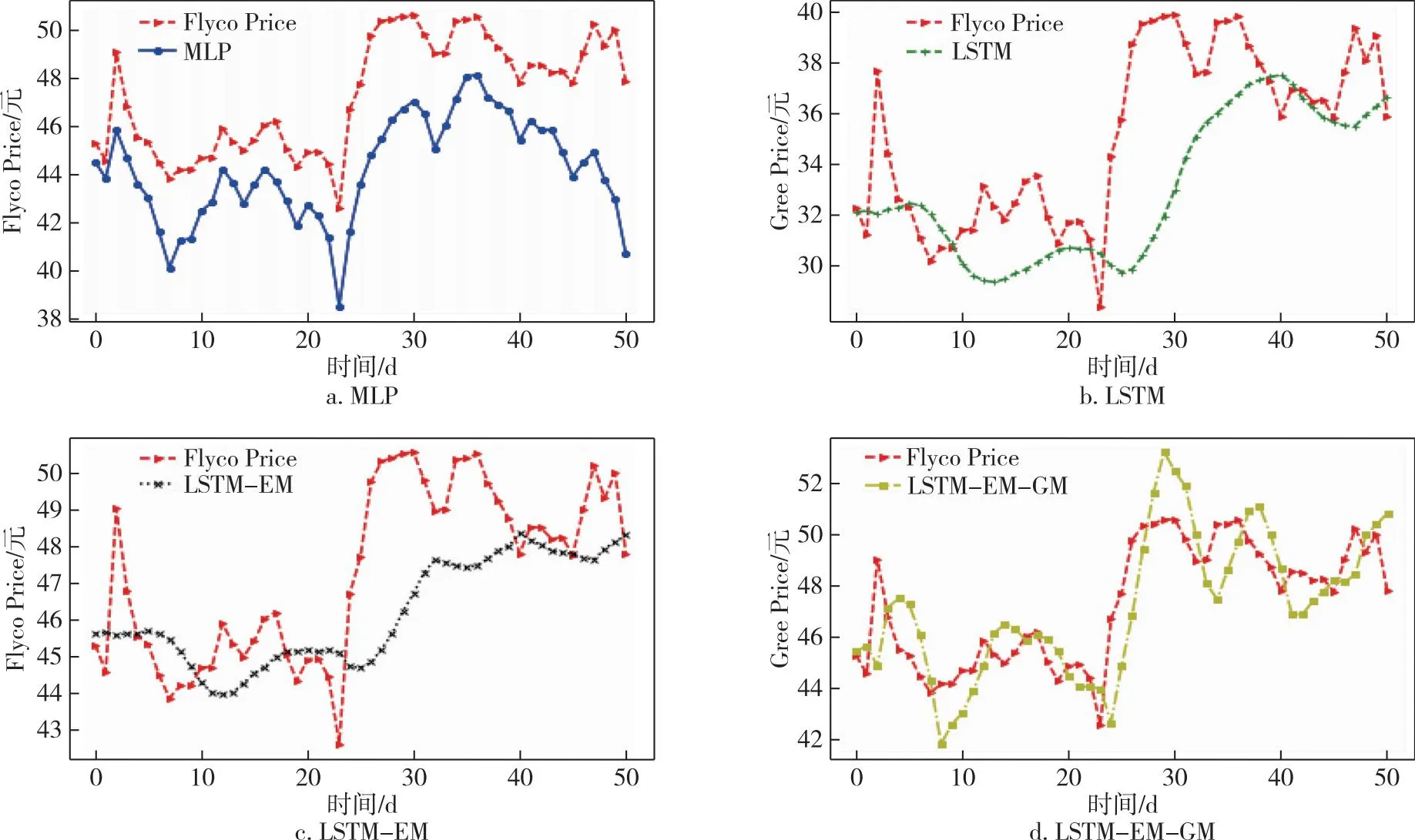
圖7 不同模型飛科電器股價預(yù)測比較Fig.7 Comparison of Flyco Electric Appliance stock prices forecasted by different models
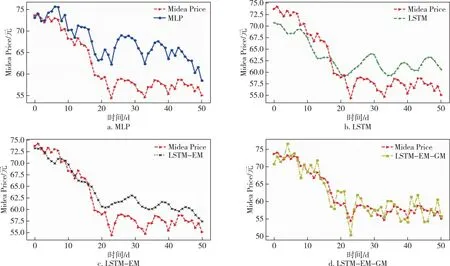
圖8 不同模型美的集團股價預(yù)測比較Fig.8 Comparison of Midea Group stock prices forecasted by different models
本文首先選擇的是MLP(Multilayer Perceptron)基礎(chǔ)神經(jīng)網(wǎng)絡(luò)[39]與LSTM模型進行比較,發(fā)現(xiàn)即使沒有添加情緒相關(guān)的指標(biāo),LSTM的預(yù)測效果也相對較好;接著分別對比加入情緒指數(shù)、投資者關(guān)注度的模型LSTM-EM以及在此基礎(chǔ)上對誤差修正的模型LSTM-EM-GM,具體評測指標(biāo)的數(shù)值如表4所示.
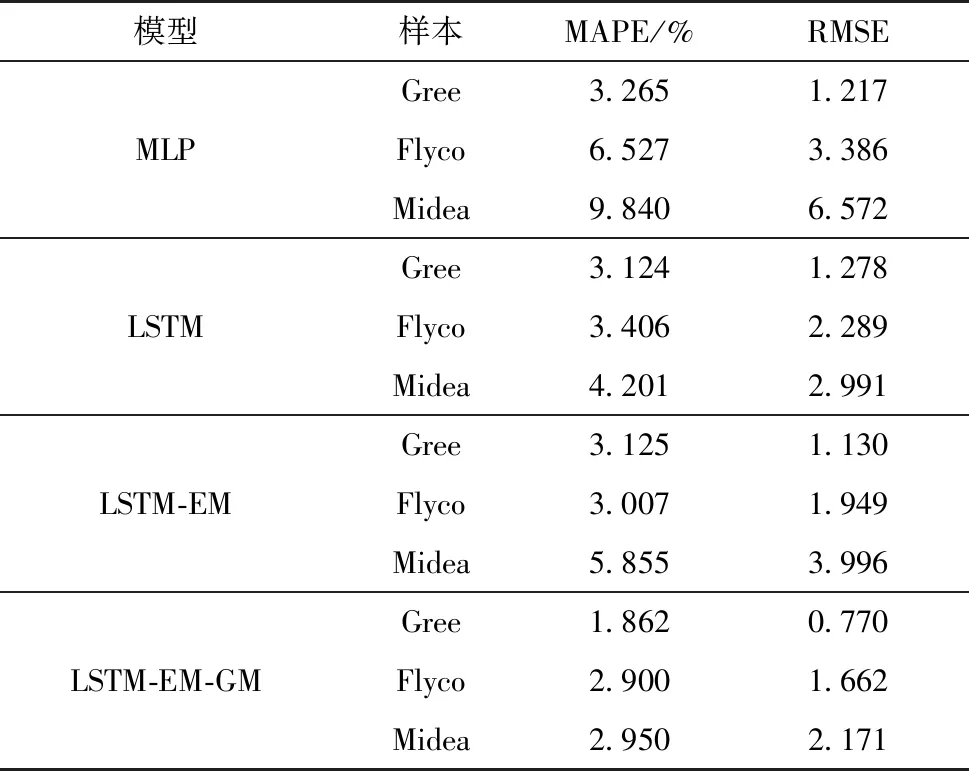
表4 不同模型預(yù)測結(jié)果對比
從表4中能夠看出:在格力電器(Gree)的股價預(yù)測中,沒有加入情緒指數(shù)的LSTM模型的MAPE、RMSE分別為3.124%、1.278,加入了情緒指數(shù)的MLP模型的MAPE、RMSE分別為3.265%、1.217.加入情緒指數(shù)em、投資者關(guān)注度att的模型LSTM-EM模型的MAPE以及RMSE分別為3.125%、1.130,相較于MLP模型,無論是MAPE還是RMSE指標(biāo)都有了顯著的提高,因此選用LSTM模型為基準(zhǔn)模型.而相對于LSTM模型,LSTM-EM模型雖然MAPE沒有顯著變化,但RMSE有了較大下降.進一步,使用GM(1,1)模型對LSTM-EM進行修正后的模型LSTM-EM-GM模型的MAPE及RMSE分別為1.862%、0.770,都相對之前的模型有了更為顯著的下降,為最優(yōu)模型.在飛科電器(Flyco)及美的集團(Midea)的股價預(yù)測中,LSTM-EM-GM也是最優(yōu)的預(yù)測模型,反映其預(yù)測誤差大小的指標(biāo)中MAPE分別為2.900%及2.950%,RMSE指標(biāo)的值分別為1.662及2.171,相對于對比模型MLP以及原始模型LSTM,誤差都有所下降.
從上述的對比中能夠發(fā)現(xiàn),相較于MLP,具有記憶性的LSTM模型能夠?qū)蓛r數(shù)據(jù)進行更好的預(yù)測,且投資者情緒與投資者關(guān)注度與格力電器的股價之間有較為明顯的關(guān)聯(lián),將其作為特征變量加入到模型中能在一定程度上提高模型的預(yù)測精度.同時,由于選用灰色GM(1,1)模型,充分挖掘了殘差項中的信息,使得模型的預(yù)測精確度有了較為顯著的提高.結(jié)合所選取的電器行業(yè)的3個案例,發(fā)現(xiàn)模型對于波動劇烈且下降的格力電器股價、波動下降但降幅略小的美的集團以及波動上升的飛科電器股價,都能進行較好的預(yù)測,驗證了模型的穩(wěn)健性.
3.2 模型普適性研究
上述研究預(yù)測了近2個月的股票收盤價.為更好地說明模型的適用性,縮短預(yù)測時間,僅預(yù)測2天的數(shù)據(jù)量,選擇上證指數(shù)SSEC作為響應(yīng)變量進行驗證.同樣使用LSTM-EM-GM模型,除了迭代輪數(shù)epoch變?yōu)?00,滾動窗口設(shè)置為5,其余參數(shù)同上.選擇的特征變量分別為adx_adx、macd_signal、cci_20、emv_maemv、obv_、atr_atr、ex_rate、r_f以及投資者情緒指數(shù)em、投資者關(guān)注度att和自身收盤價共計11個特征變量.具體預(yù)測結(jié)果如表5所示.由于數(shù)據(jù)量較小,這里不再繪圖展示.
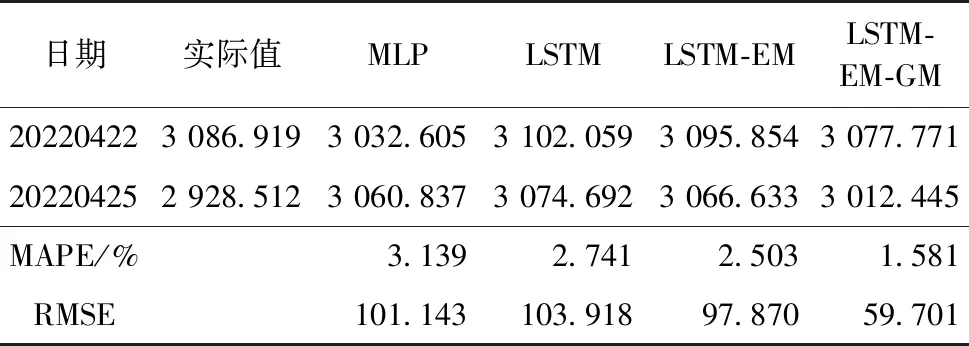
表5 不同模型短期預(yù)測結(jié)果對比
從表5中能夠看出,對于上證指數(shù)的預(yù)測,由于量綱的問題導(dǎo)致RMSE的指標(biāo)都相對較大.總的來說MLP模型的效果依然相對較差,其MAPE及RMSE指標(biāo)的數(shù)值分別為3.139%及101.143,LSTM-EM-GM模型的效果依然最好,MAPE及RMSE的數(shù)值分別為1.581%及59.701.LSTM-EM-GM模型在更短期的預(yù)測中取得不錯的表現(xiàn),驗證了模型的普適性.
4 結(jié)論
基于股票市場的技術(shù)性指標(biāo)、基本面指標(biāo)以及投資者情緒和投資者關(guān)注度對格力電器和上證指數(shù)進行了分析,并對變量篩選后的模型進行了殘差項的修正.通過實證分析得出如下結(jié)論:
1)投資者在進行投資時除了關(guān)注市場行情、了解大盤指數(shù),也可以關(guān)注與股指關(guān)聯(lián)性較大的指標(biāo),如反映超買超賣的cci_20、反映趨勢的macd_signal以及adx_adx等指標(biāo);在投資個股時除了關(guān)注匯率、市盈率等基本面的指標(biāo),也應(yīng)適當(dāng)關(guān)注對各股影響較大的技術(shù)性指標(biāo),如反映震幅的指標(biāo)atr_atr、人氣型指標(biāo)obv_等.
2)情緒指數(shù)以及投資者關(guān)注度與股價之間存在較強的關(guān)系,將其作為特征變量能在一定程度上提高模型的預(yù)測精度,所以,在投資時應(yīng)當(dāng)時刻關(guān)注市場上的投資者情緒,適時操作.
3)通過對殘差項進行修正,能顯著地提高模型的預(yù)測效果,說明殘差項中蘊含著豐富的信息,且使用GM(1,1)模型對于沒有明確分布的時間序列具有較好的特征提取作用.
本文雖然在特征變量選取方面及情緒指數(shù)的計算方面具有一定的科學(xué)性,考慮了可能存在的多重共線性以及各個特征變量的貢獻程度,整理了相對完善的語料庫而未使用詞典法計算情緒指數(shù),但也存在一定的不足之處:首先,影響股市的因素錯綜復(fù)雜,可能還有許多影響重大的因素未得到體現(xiàn);其次,文本分析及情緒指數(shù)的計算還缺乏成熟的體系.這是后續(xù)研究值得完善的方面.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
風(fēng)流一代·青春(2018年2期)2018-02-26 15:27:06
風(fēng)流一代·青春(2017年6期)2018-02-14 19:28:55
風(fēng)流一代·青春(2017年5期)2018-02-14 09:32:37
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
