一種基于RippleNet模型的推薦精度提高方法
2023-12-27 12:59:42安文濤陳珊珊
計算技術(shù)與自動化 2023年4期
安文濤,陳珊珊
(南京郵電大學(xué) 計算機學(xué)院,江蘇 南京 210023)
由于計算機技術(shù)的高速發(fā)展,計算機技術(shù)在給人們生活提供便利的同時,也給人類日常生活帶來了一些麻煩,其中數(shù)據(jù)大爆炸所帶來的數(shù)據(jù)過載現(xiàn)象尤為明顯。推薦系統(tǒng)作為信息過濾系統(tǒng),能夠高效地處理數(shù)據(jù)過載事件。
基于大數(shù)據(jù)分析的信息推薦系統(tǒng)已廣泛應(yīng)用于社會各個領(lǐng)域,如閱讀[1]、電影[2]、音樂[3]、新聞[4]推薦等。推薦功能的實現(xiàn)主要依靠協(xié)同過濾和聚類模型思維[5]。由于數(shù)據(jù)稀疏、冷啟動困難等一系列問題在以往的推薦模型中普遍存在[6],因此后期的研究逐漸將知識圖譜加入推薦系統(tǒng)模型。
知識圖譜(Knowledge Graph,KG),是為表達實體之間語義關(guān)系的一種結(jié)構(gòu)化語義數(shù)據(jù)庫,“實體-關(guān)系-實體”三元組是知識圖譜的基本組成單位,其中包含豐富的語義知識,可用于推薦系統(tǒng),使其具有可解釋性、多樣化和準確的特點[7]。基于知識圖譜的推薦系統(tǒng)主要通過引入實體之間的語義相關(guān)性,有助于發(fā)現(xiàn)它們的潛在聯(lián)系,提高推薦項目的準確性。由于存儲在知識圖譜中實體間的語義關(guān)系種類具有多樣性,知識圖譜連接用戶的歷史記錄和推薦的歷史記錄,故可以為推薦系統(tǒng)帶來可解釋性。現(xiàn)有的知識圖譜推薦可分為兩類:第一類基于路徑的推薦方法[8],探索知識圖譜中各個實體之間的連接關(guān)系,然后利用連接關(guān)系來計算節(jié)點相似性,從而進行推薦,但是該方法嚴重依賴于手動設(shè)計的元路徑,實踐過程中很難優(yōu)化;第二類基于嵌入的方法[9],它使用知識圖譜嵌入(Knowledge Graph Embedding,KGE)算法對知識圖譜進行預(yù)處理,并將學(xué)習(xí)到的實體嵌入合并到推薦框架中,采用知識圖譜嵌入算法一般情況更適用于圖內(nèi)應(yīng)用,但是該類模型在推薦的過程中并沒有利用到知識圖譜的多跳關(guān)系,這使得結(jié)果的可解釋性缺乏。
為了使知識圖譜中的數(shù)據(jù)利用更全面,Wang Hong-wei等[10]2018年提出RippleNet模型,首次將基于嵌入的思想通過對圖譜的語義表示與路徑鏈接信息結(jié)合,RippleNet模型通過“偏好擴散”的思想在創(chuàng)建好的知識圖譜中創(chuàng)建,RippleNet模型借助知識圖譜節(jié)點間語義關(guān)系在節(jié)點之間傳播得到了很好的效果。但是隨著數(shù)據(jù)的增多,構(gòu)建的知識圖譜的冗余數(shù)據(jù)會隨著增長,為了提高數(shù)據(jù)的相關(guān)性,從而提高RippleNet模型的推薦精度,本文提出新的改進方法,開展了如下工作:
1)添加子網(wǎng)提取算法對數(shù)據(jù)進行預(yù)處理,通過提取概念圖譜的最大聯(lián)通子網(wǎng)來去除數(shù)據(jù)冗余。
2)在RippleNet模型的基礎(chǔ)上,利用算法處理后的數(shù)據(jù)和原數(shù)據(jù)進行對比試驗,證明該方法的有效性。
1 相關(guān)工作
RippleNet背后主要的思想是偏好傳播,如圖1所示,RippleNet模型以一個項目和一個用戶作為輸入,接著將項目經(jīng)過嵌入轉(zhuǎn)化為低維向量,然后將該向量不斷地同用戶周圍的n跳項目轉(zhuǎn)化后的向量進行交互運算,得到該用戶的向量表示,然后將用戶的向量表示與項目的轉(zhuǎn)化向量進行計算,得到用戶的點擊概率,從而完成推薦。

圖1 RippleNet的總體框架
RippleNet模型涉及相關(guān)實體:U={u1,u2,…}表示用戶集合;V={v1,v2,…}表示物品集合;Y={yuv|u∈U,v∈V}表示用戶和物品的交互矩陣,被定義為隱式反饋,其中:

(1)
如果yuv的值為1,則表示用戶u和物品v之間存在隱式的交互作用,如點擊、游覽、觀看等行為。
RippleNet模型利用水波紋的傳播思想,以用戶所感興趣的物品作為種子(seed),在知識圖譜中以種子物品作為中心像水波紋一樣向外擴散到其他物品上,整個過程為偏好傳播。外層的物品屬于用戶潛在的偏好,應(yīng)該被添加到計算過程中。

pi=softmax(vTRihi)=
(2)

(3)

(4)
最后得到用戶u和物品v交互的概率:
(5)
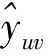
2 優(yōu)化改進
在RippleNet模型的基礎(chǔ)之上,利用子網(wǎng)提取算法處理后的數(shù)據(jù)替換未經(jīng)處理的原始數(shù)據(jù)。如圖2所示,首先對未經(jīng)處理的概念圖譜文件進行一次預(yù)處理,利用子網(wǎng)提取算法[11]對原概念圖譜數(shù)據(jù)進行最大連通子網(wǎng)抽取,從而去除冗余數(shù)據(jù),使得數(shù)據(jù)之間的相關(guān)性得到提高。利用處理后得到的最大連通子網(wǎng)數(shù)據(jù)文件進行知識圖譜的構(gòu)建,以得到知識圖譜,然后利用RippleNet模型進行計算。

圖2 加入數(shù)據(jù)處理后RippleNet整體框架
RippleNet模型利用水波紋的特點模擬用戶的偏好傳播,以一個用戶和一個物品作為輸入,輸出用戶與物品交互的預(yù)測概率,概率越高,表示用戶與物品的相關(guān)性概率越高。如圖2所示,在構(gòu)建所需的知識圖譜之前對數(shù)據(jù)文件進行一次預(yù)處理,獲取最大連通子網(wǎng),去除一些無關(guān)聯(lián)的冗余節(jié)點。通過獲取概念圖譜網(wǎng)絡(luò)的最大連通子網(wǎng)來提高數(shù)據(jù)的相關(guān)性。本文利用子網(wǎng)提取算法,以概念圖譜文件作為輸入,最大連通子網(wǎng)節(jié)點集合作為輸出。
算法:子網(wǎng)提取算法
輸入:概念圖譜文件Concept_graph
輸出:最大連通子網(wǎng)節(jié)點集合MaxSubNet
(1)從Concept_graph中抽取出度值的節(jié)點所在的三元組,將該三元組所包含的節(jié)點作為最大連通子圖的中心層Sublayeri(當前i=1,表示中心層),并加入集合MaxSubNet。
(2)尋找Sublayeri集合中的相鄰節(jié)點,將查找到對應(yīng)的鄰居節(jié)點加入集合NeighborSeti中。
(3)判斷集合NeighborSeti中是否有新的不在集合MaxSubNet中的節(jié)點,若有,將NeighborSeti并入MaxSubNet中,并用集合MaxSubNet與集合NeighborSeti的差集替換Sublayeri,i=i+1,然后跳轉(zhuǎn)到步驟(2);若無,則繼續(xù)步驟(4)。
(4)返回MaxSubNet.
首先利用子網(wǎng)提取算法可以得到最大連通子網(wǎng)的節(jié)點集合MaxSubNet,然后根據(jù)MaxSubNet從概念圖譜文件Concept_graph中提取出最大子網(wǎng)的邊的集合,對于每一條邊依舊采用Concept_graph中三元組形式并存儲在文本文件Concept_graphLink中,然后根據(jù)MaxSubNet和Concept_graphLink構(gòu)建圖3所示的最大連通子網(wǎng)。其中,中心層(CentralLayer)為包含度值最大的三元組節(jié)點;第二層(Layer 2)為中心層各個節(jié)點的鄰居節(jié)點集合;第三層(Layer 3)為第二層節(jié)點的鄰居節(jié)點集合。以此類推,直到最外層(Outermostlayer)。
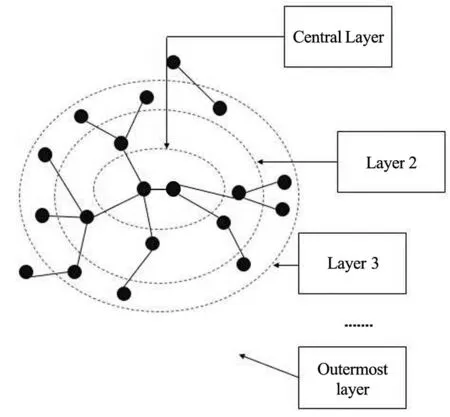
圖3 最大連通子網(wǎng)邏輯結(jié)構(gòu)
通過算法抽取出圖譜網(wǎng)絡(luò)的最大連通子網(wǎng),提高了節(jié)點之間的相關(guān)性,從而能夠更真實地描述其網(wǎng)絡(luò)特性。根據(jù)子網(wǎng)提取算法得到最大連通子網(wǎng)的節(jié)點集合,再根據(jù)Concept_graph中提取邊的集合GraphLink,最后生成知識圖譜網(wǎng)絡(luò),然后利用RippleNet模型對生成的知識圖譜網(wǎng)絡(luò)進行運算。
3 實驗驗證
3.1 實驗評價標準
分類問題中的混淆矩陣如表1所示,其中TP(True Positive)表示實際結(jié)果為1,預(yù)測也為1;FP(False Positive)表示實際結(jié)果為0,預(yù)測為1;FN(False Negative)表示實際結(jié)果為1,預(yù)測為0;TN(True Negative)表示實際結(jié)果為0,預(yù)測為0。Top-k列表推薦的具體評價標準:精準率、召回率、F1計算公式如式(6)~式(8)所示。CTR(Click Through Rate)點擊率預(yù)測的評價標準,準確率和AUC的計算公式如式(9)、式(10)所示。
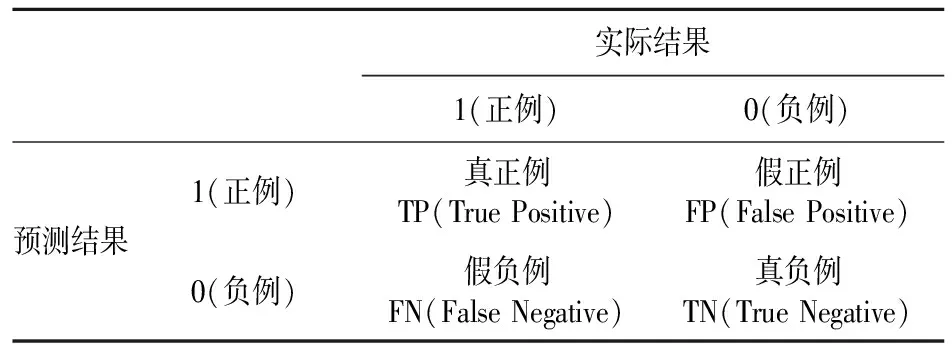
表1 混淆矩陣
(6)
(7)
(8)
(9)
(10)
式(8)中F1值是精確率和召回率的合成指標,綜合了二者的結(jié)果,F1值越高,代表模型綜合性能越好。式(10)中的insi表示正樣本,rankinsi表示預(yù)測第i個樣本的概率排名,T表示正樣本的總數(shù),F表示負樣本的總數(shù)。
3.2 實驗數(shù)據(jù)
實驗中使用了MovieLens-1M數(shù)據(jù)集,見表2。

表2 數(shù)據(jù)集的基本統(tǒng)計
采用子網(wǎng)提取算法對所構(gòu)建的概念圖譜網(wǎng)絡(luò)進行最大連通子網(wǎng)抽取實驗,具體實驗環(huán)境為64位Win11系統(tǒng),8 GB內(nèi)存,Python開發(fā)環(huán)境。
3.3 實驗結(jié)果
由算法(SNEBF)根據(jù)概念圖譜的數(shù)據(jù)文件MovieLens-1M生成的最大子網(wǎng)包含節(jié)點結(jié)果MovieLens-1M_MaxSubNet如表3所示。

表3 最大連通子圖提取結(jié)果
根據(jù)MovieLens-1M數(shù)據(jù)文件生成的最大子網(wǎng)占原概念圖譜網(wǎng)絡(luò)節(jié)點和邊的83.23%和92.69%,由MovieLens-1M所生成的最大子網(wǎng)覆蓋了原概念圖譜網(wǎng)絡(luò)大部分的邊和節(jié)點,能較好地反映整個網(wǎng)絡(luò)特征。
使用原數(shù)據(jù)集MovieLens-1M 和消除冗余后的數(shù)據(jù)集MovieLens-1M_MaxSubNet在RippleNet模型上進行計算,其中CTR(Click Through Rate)點擊率預(yù)測結(jié)果評價標準,AUC和精準度結(jié)果如表4所示;Top-k推薦中的精準度、召回率、F1的結(jié)果如圖4所示。

表4 CTR預(yù)測的AUC和精準度結(jié)果

圖4 Top-k推薦中的精準率、召回率、F1對比
綜上,通過提取最大連通子網(wǎng)消除冗余數(shù)據(jù),提高數(shù)據(jù)集的相關(guān)性,為RippleNet的偏好傳播提供更相關(guān)數(shù)據(jù),有效地降低了數(shù)據(jù)的不確定性,提升了概念圖譜對數(shù)據(jù)用戶特征描述的精準度。
4 結(jié) 論
在RippleNet模型的基礎(chǔ)上,通過子網(wǎng)提取算法提取最大連通子網(wǎng),消除冗余數(shù)據(jù),提高數(shù)據(jù)相關(guān)性,從而提升RippleNet模型推薦性能。使用MovieLens-1M數(shù)據(jù)集進行預(yù)處理后,通過與原數(shù)據(jù)進行實驗對比,使得RippleNet模型性能得到提升。后續(xù)可以將RippleNet模型與其他推薦模型相結(jié)合,在此基礎(chǔ)上探索是否可以在準確率上繼續(xù)提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
