基于LSTM+Word2vec的微博評論情感分析
2024-01-01 00:00:00王劍輝閆芳序
沈陽師范大學學報(自然科學版) 2024年2期





摘要:微博作為當今熱門的社交平臺,其中蘊含著許多具有強烈主觀性的用戶評論文本。為挖掘微博評論文本中潛在的信息,針對傳統的情感分析模型中存在的語義缺失以及過度依賴人工標注等問題,提出一種基于LSTM+Word2vec的深度學習情感分析模型。采用Word2vec中的連續詞袋模型(continuous bag of words,CBOW),利用語境的上下文結構及語義關系將每個詞語映射為向量空間,增強詞向量之間的稠密度;采用長短時記憶神經網絡模型實現對文本上下文序列的線性抓取,最后輸出分類預測的結果。實驗結果的準確率可達95.9%,通過對照實驗得到情感詞典、RNN、SVM三種模型的準確率分別為52.3%、92.7%、85.7%,對比發現基于LSTM+Word2vec的深度學習情感分析模型的準確率更高,具有一定的魯棒性和泛化性,對用戶個性化推送和網絡輿情監控具有重要意義。
關鍵詞:情感分析; Word2vec; 長短時記憶神經網絡; 社交平臺; 微博
中圖分類號:TP391.9文獻標志碼:A
doi:10.3969/j.issn.16735862.2024.02.007
CUI Song LYU Yan CHEN Lanfeng WANG Jianhui, YAN Fangxu
(1. College of Physical Science and Technology, Shenyang Normal University, Shenyang 110034, China)
(College of Mathematics and Systems Science, Shenyang Normal University, Shenyang 110034, China)
Abstract:Weibo is a popular social platform, contains many subjective user comments. In order to explore the potential information in the comment text of weibo, a deep learning sentiment analysis model based on LSTM+Word2vec is proposed to solve the problems of semantic loss and excessive dependence on manual annotation in the traditional sentiment analysis model. The CBOW(continuous bag of words) model in Word2vec is used to map words into vector space by using the context structure and semantic relationship of context, so as to enhance the density between word vectors. LSTM is used to realize the linear capture of the text context sequence, and finally yield the result of classification prediction. As a control experiment, the accuracy of the three models of sentiment dictionary, RNN and SVM is 52.3%, 92.7% and 85.7% respectively. It is found that the accuracy of the deep learning sentiment analysis model based on LSTM+Word2vec is higher, which has certain robustness and generalization. It is of great significance for user personalized push and network public opinion monitoring.
Key words:sentiment analysis; Word2vec; long shortterm memory(LSTM); social platform; Weibo
互聯網的飛速發展使得眾多社交平臺躋身熱門應用行列,社交媒體的興起促使用戶在網絡平臺上針對其興趣領域自發、實時、自由地發表評論,其中最具代表性的當屬新浪微博。用戶評論往往具有強烈的主觀性,其中蘊含著豐富的感情色彩。對此進行研究分析,利于挖掘文本中隱含的用戶需求,在監控輿情、品牌認知、定向推送、商品評論等領域發揮著重要作用。情感分析技術作為自然語言處理的一種應用,能夠迅速抓取、整合互聯網上海量的非結構化評論數據,挖掘帶有情感傾向的主觀性文本,實現分析、處理、歸納和推理的過程[12]。
實現情感分析技術的重難點為文本向量的表示和預測模型的選取。傳統的情感分析模型對人工處理的語料和先驗知識背景依賴程度較深,且采用稀疏矩陣進行文本向量表征,導致向量的維度過高,不利于計算機的讀取和存儲。Word2vec模型將文本內容處理轉化為計算機可讀取的稠密矩陣。LSTM(long shorttenm memory)模型具有一定的記憶功能,針對句法層面進行順序及位置的調整進而捕捉深層的語義信息[3]。基于此,本文提出一種基于LSTM+Word2vec的微博評論文本情感分析模型,
將微博評論文本轉化成向量數據,作為LSTM模型的輸入,經過長短時記憶神經網絡模型對語義信息的學習過程和捕捉處理,最后輸出預測結果。實驗證明,該模型具有較強的泛用性和魯棒性。
1相關研究
1.1情感分析技術
情感分析技術是自然語言處理中的一項重要研究內容,其目的在于從文本中挖掘出更多的主觀信息,從而判斷出作者的情緒。情感分析技術在多個領域都有著廣泛的應用性,如商業領域的商品評論,文化領域的書評、影評,社會領域的輿情監督,信息領域的趨態預測以及企業中職員的情緒管理等。主要的分析方法有3種:基于情感字典的分析方法、基于機器學習的分析方法和基于深度學習的分析方法。
1.1.1基于情感字典的分析方法
該方法通過計算詞語的褒貶性進行加權求和進而確定整個段落或者整篇文章的情感傾向。目前主要采用人工標注、知識庫和語料庫3種方式來構造情感詞典。Hu等[4]將詞集編入情感字典,通過對評價結果的極性進行判別,該判別方法的準確率達84.2%。Ding等[5]把情緒詞匯和話題詞匯之間的距離作為衡量標準,其對亞馬遜網站數據的預測精度達到了92.0%。
1.1.2基于機器學習的分析方法
該方法主要適用于有監督學習,主要分為3個步驟:預處理、文本表示(特征選擇、特征簡約、特征權重設置)與分類器訓練。其中一般按照特征值是否出現用數值0或1表示,或者按詞頻信息取TF、TFIDF值等進行特征權重設置。Pang等[6]首次提出了一種基于機器學習的情緒分類算法,將 SVM和 Unigrams特征相結合,識別率達到82.9%。Ye等[7]采用二類Bigram,并結合樸素貝葉斯可達到95.67% 的精確度。
1.1.3基于深度學習的分析方法
基于深度學習的方法有seq2seq模型、transformer、Bert預訓練加微調模型、GPT模型以及本文所應用的LSTM模型等。自2006年以來,神經網絡模型在文本處理方面取得了重大的進展。近年來,中文情感分析的應用主要集中在對短文本的處理中,如:趙明等[8]基于Word2vec 和 LSTM 對食譜文本進行分類預測;張英[9]建立LSTM模型針對微博做情感分析。
1.2Word2vec模型
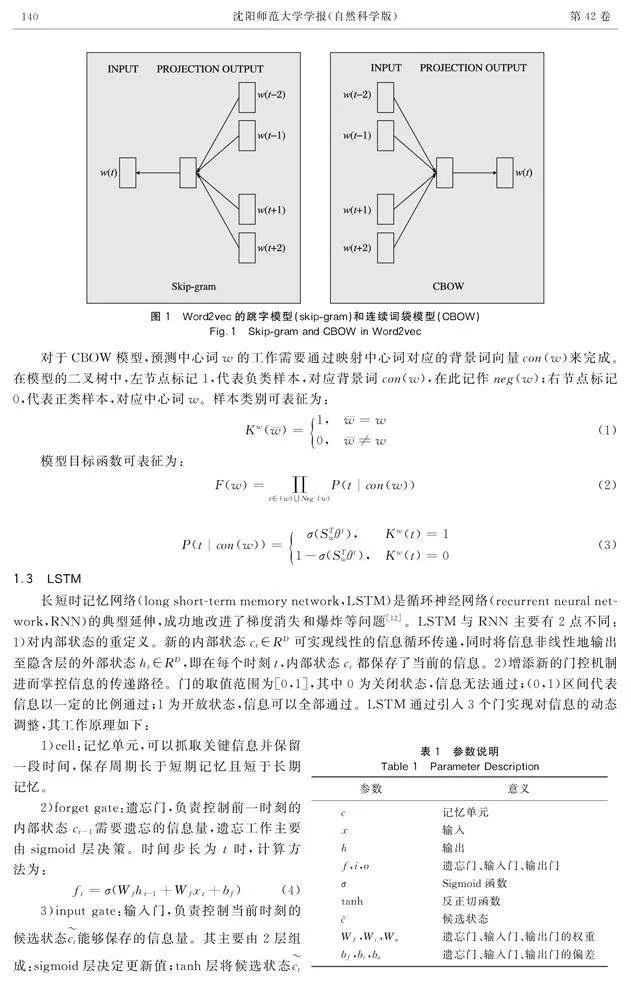
Word2vec 是自然語言處理任務的一個重要模型,是由谷歌公司于2013年提出的一款基于深度學習的詞向量技術。它主要利用某一語境的上下文結構及語義關系,實現詞語語義和語法的系統抓取,并且能夠投入到大型的語料庫進行集中化的無監督學習[10]。通過學習訓練,模型將高維詞映射為低維詞,統一為向量化表示,并計算余弦距離進而度量詞向量之間的相似程度。如圖1所示,該模型主要分為2種架構實現:跳字模型(skipgram)和連續詞袋模型(continuous bag of words,CBOW)。Skipgram模型利用最大化分類方法,在給定的范圍內預測中心詞的前后詞。另外,句子中較遠處的詞與中心詞之間關聯度較低,因此在訓練中分配給這些詞語的權重較低。而CBOW模型則是將中心詞對應的上下文詞語按順序排列,將所選窗口內的上下文詞語投射到同一位置,并對其向量求平均值,輸出的結果即為中心詞的詞向量[11]。由于CBOW模型的訓練速度更快,本文采用該模型進行訓練。
1.3LSTM
長短時記憶網絡(long shortterm memory network,LSTM)是循環神經網絡(recurrent neural network,RNN)的典型延伸,成功地改進了梯度消失和爆炸等問題[12]。LSTM與RNN主要有2點不同:1)對內部狀態的重定義。新的內部狀態ct∈RD可實現線性的信息循環傳遞,同時將信息非線性地輸出至隱含層的外部狀態ht∈RD,即在每個時刻t,內部狀態ct都保存了當前的信息。2)增添新的門控機制進而掌控信息的傳遞路徑。門的取值范圍為[0,1],其中0為關閉狀態,信息無法通過;(0,1)區間代表信息以一定的比例通過;1為開放狀態,信息可以全部通過。LSTM通過引入3個門實現對信息的動態調整,其工作原理如下:
2實驗驗證與分析
在Python的TensorFlow環境中,搭建運行LSTM+Word2vec情感分析模型。首先對評論文本進行預處理,主要包括讀取、分詞、去停用詞等步驟,再利用Word2vec模型向量化表示文本,作為輸入參數至LSTM模型中進行訓練與評估。
2.1數據來源
本文數據源自github公開社區,共計119989條評論記錄,其中包含正向評論59993條,負向評論59996條,如表2所示。由于評論文本中含有中文、英文、俚語、數字符號、特殊表情以及空缺值、冗余值等,因此需要對文本數據進行一定的處理。
2.2數據預處理
2.2.1分詞
分詞的目的是將一段話或一句話劃分成彼此獨立的詞語的集合。對于中文語境,jieba分詞工具適配度較高,因此本文采用jieba庫的精確模式對文本數據進行分詞,實現代碼如下:
2.2.2去停用詞
2.3詞向量化
2.4基于LSTM的分類模型
2.4.1劃分數據集
微博評論語料已由文本數據轉化為詞向量,接下來將數據劃分為測試集和訓練集。由于微博的文本數據較為特殊,本文應用sequence.pad_sequences()方法實現句子長度的統一,然后調用sklearn庫中的train_test_split()函數實現80%訓練集和20%測試集的劃分。
2.4.2模型結構
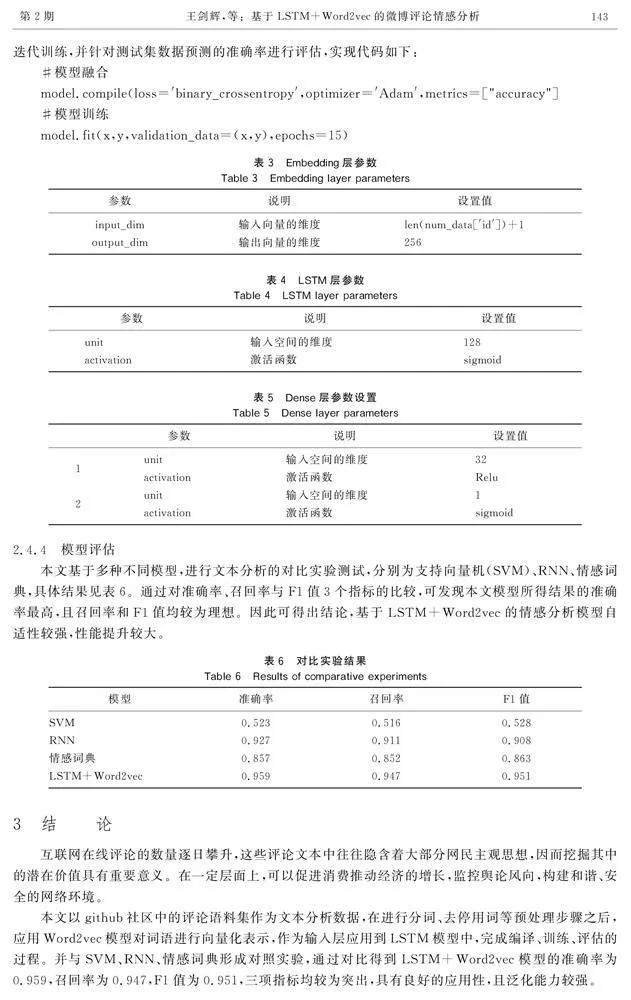
LSTM模型的堆疊順序一般為:輸入層(Embedding層)、隱含層(全連接層和LSTM層)、輸出層(全連接層和輸出層)。輸出層確定輸入神經網絡的數據形態,數據特征被隱含層提取并進行特殊處理,根據神經網絡的輸出規則進行一維向量化變換,最后實現全連接并輸出預測結果。參數的具體設置見表3、表4、表5。
2.4.3模型編譯與訓練
2.4.4模型評估
本文基于多種不同模型,進行文本分析的對比實驗測試,分別為支持向量機(SVM)、RNN、情感詞典,具體結果見表6。通過對準確率、召回率與F1值3個指標的比較,可發現本文模型所得結果的準確率最高,且召回率和F1值均較為理想。因此可得出結論,基于LSTM+Word2vec的情感分析模型自適性較強,性能提升較大。
3結論
互聯網在線評論的數量逐日攀升,這些評論文本中往往隱含著大部分網民主觀思想,因而挖掘其中的潛在價值具有重要意義。在一定層面上,可以促進消費推動經濟的增長,監控輿論風向,構建和諧、安全的網絡環境。
本文以github社區中的評論語料集作為文本分析數據,在進行分詞、去停用詞等預處理步驟之后,應用Word2vec模型對詞語進行向量化表示,作為輸入層應用到LSTM模型中,完成編譯、訓練、評估的過程。并與SVM、RNN、情感詞典形成對照實驗,通過對比得到LSTM+Word2vec模型的準確率為0.959,召回率為0.947,F1值為0.951,三項指標均較為突出,具有良好的應用性,且泛化能力較強。
參考文獻:
[1]陳龍,管子玉,何金紅,等.情感分類研究進展[J].計算機研究與發展,2017,54(6):11501170.
[2]楊立公,朱儉,湯世平.文本情感分析綜述[J].計算機應用,2013,33(6):15741578.
[3]柴源.基于LSTM和Word2vec的圖書評論文本情感分析研究[J].信息技術,2022(7):5964.
[4]HU M Q,LIU B.Mining and summarizing customer reviews[C]//Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:Association for Computing Machinery,2004:168177.
[5]DING X W,LIU B,YU P S.A holistic lexiconbased approach to opinion mining[C]//Proceedings of the 2008 International Conference on Web Search and Data Mining.New York:Association for Computing Machinery,2008:231240.
[6]PANG B,LEE L,VAITHYANATHAN S.Thumbs up? Sentiment classification using machine learning techniques[C]// Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing.Philadelphia:Association for Computational Linguistics,2002:7986.
[7]YE Q,ZHANG Z Q,LAW R,et al.Sentiment classification of online reviews to travel destinations by supervised machine learning approaches[J].Expert Syst Appl,2009,36(3):65276535.
[8]趙明,杜會芳,董翠翠,等.基于Word2vec和LSTM的飲食健康文本分類研究[J].農業機械學報,2017,48(10):202208.
[9]張英.基于深度神經網絡的微博短文本情感分析研究[D].鄭州:中原工學院,2017.
[10]王仁武,宋家怡,陳川寶.基于Word2vec的情感分析在品牌認知中的應用研究[J].圖書情報工作,2017,61(22):612.
[11]ADEWUMI T,LIWICKI F,LIWICKI M.Word2vec:Optimal hyperparameters and their impact on natural language processing downstream tasks[J].Open Comput Sci,2022,12(1):134141.
[12]王劍輝,蔣杏麗.基于LSTM模型對印度新冠肺炎疫情的預測[J].沈陽師范大學學報(自然科學版),2022,40(6):554557.
[13]鄧三鴻,傅余洋子,王昊.基于LSTM模型的中文圖書多標簽分類研究[J].數據分析與知識發現,2017(7):5260.
[14]曾蒸,李莉,陳晶.用于情感分類的雙向深度LSTM[J].計算機科學,2018,45(8):213217.
[15]YU Y,SI X S,HU C H,et al.A review of recurrent neural networks:LSTM cells and network architectures[J].Neural Comput,2019,31(7):12351270.
【責任編輯:孫可】
